Serviço Amazon OpenSearch introduzido recentemente Multi-AZ com espera, uma opção de implantação projetada para fornecer às empresas maior disponibilidade e desempenho consistente para cargas de trabalho críticas. Com esse recurso, os clusters gerenciados podem atingir 99.99% de disponibilidade e, ao mesmo tempo, permanecer resilientes a falhas de infraestrutura zonal.
Nesta postagem, exploramos como a pesquisa e a indexação funcionam com Multi-AZ com Standby e nos aprofundamos nos mecanismos subjacentes que contribuem para sua confiabilidade, simplicidade e tolerância a falhas.
BACKGROUND
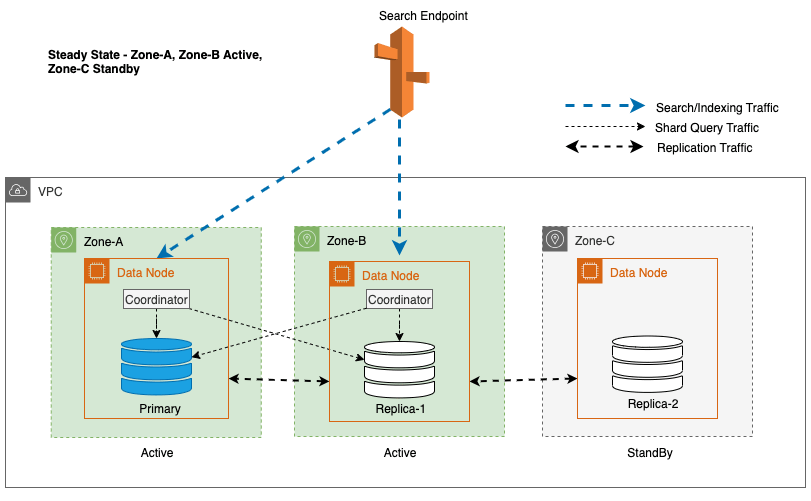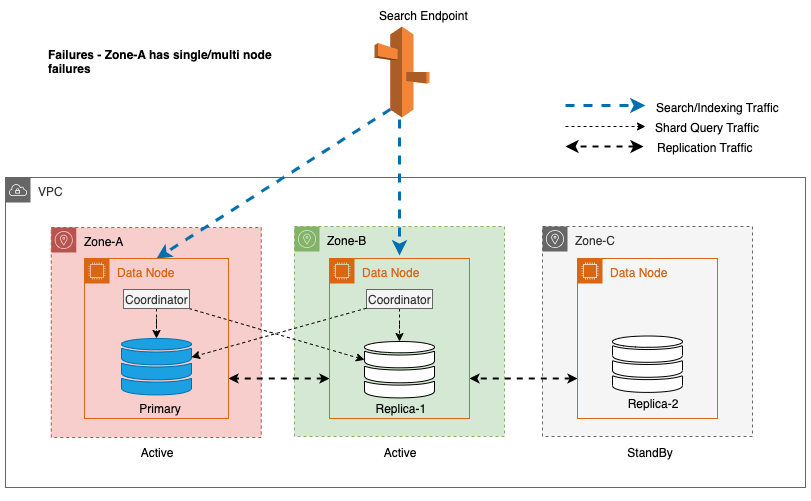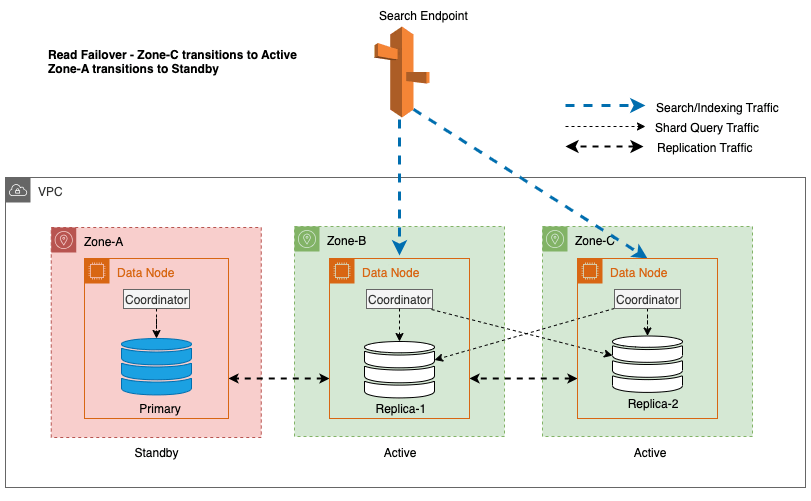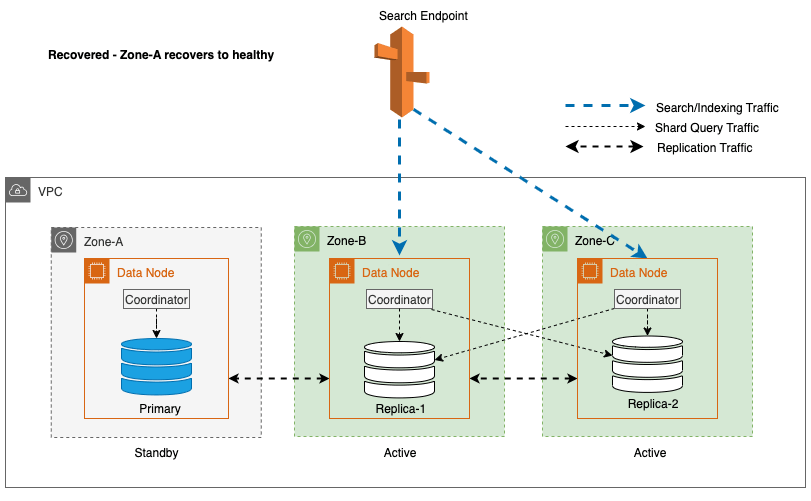
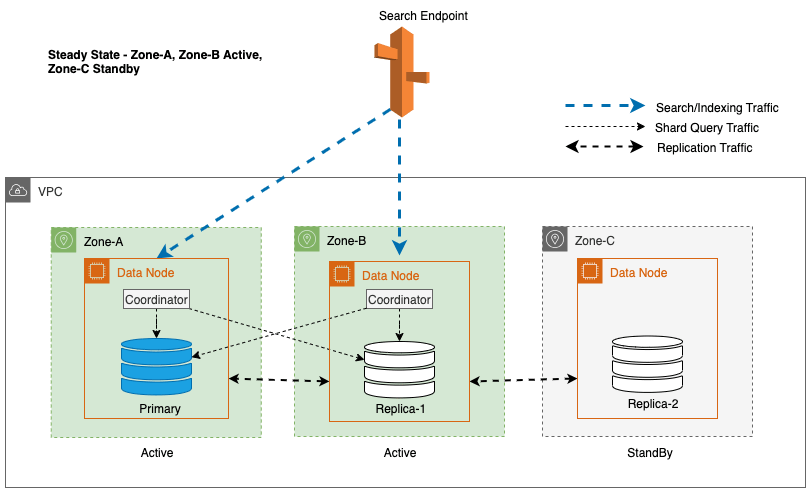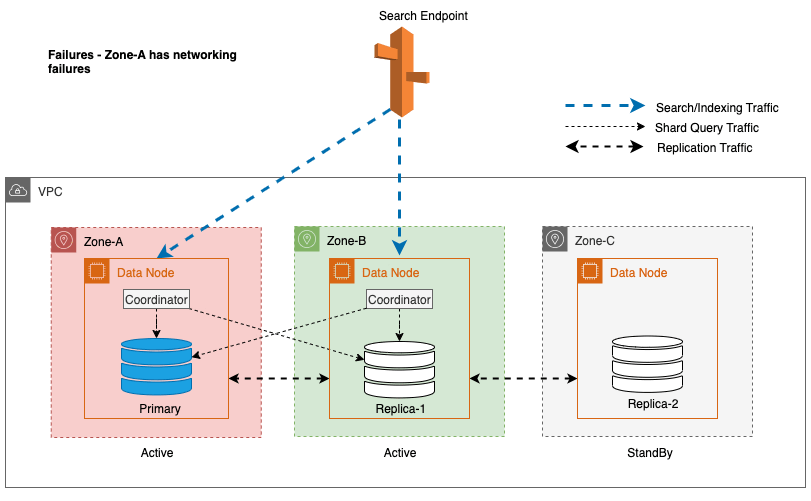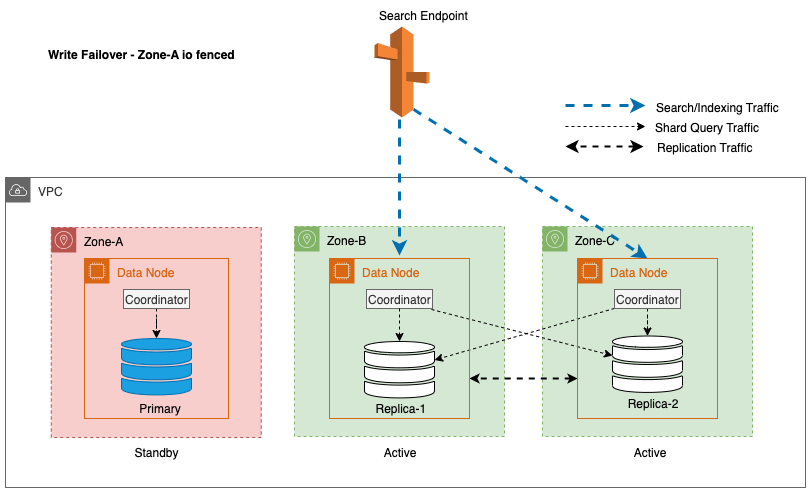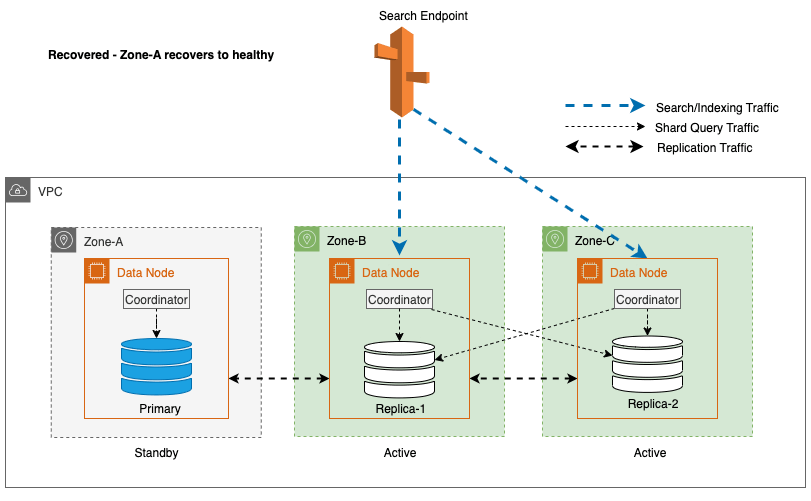
O Multi-AZ com Standby implanta instâncias de domínio do OpenSearch Service em três zonas de disponibilidade, com duas zonas designadas como ativas e uma como standby. Esta configuração garante um desempenho consistente, mesmo em caso de falhas zonais, mantendo a mesma capacidade em todas as zonas. É importante ressaltar que esta zona de espera segue um projeto estaticamente estável, eliminando a necessidade de provisionamento de capacidade ou movimentação de dados durante falhas.
Durante as operações regulares, a zona ativa lida com o tráfego do coordenador para solicitações de leitura e gravação, bem como para o tráfego de consulta de fragmentos. A zona de espera, por outro lado, recebe apenas tráfego de replicação. O OpenSearch Service utiliza um protocolo de replicação síncrona para solicitações de gravação. Isso permite que o serviço promova imediatamente uma zona de espera para o status ativo no caso de uma falha (tempo médio para failover <= 1 minuto), conhecido como failover zonal. A zona anteriormente ativa é então rebaixada para o modo de espera e as operações de recuperação começam para restaurar seu estado íntegro.
Pesquise roteamento de tráfego e failover para garantir alta disponibilidade
Em um domínio do OpenSearch Service, um coordenador é qualquer nó que lida com solicitações HTTP(S), especialmente solicitações de indexação e pesquisa. Em um domínio Multi-AZ com Standby, os nós de dados na zona ativa atuam como coordenadores para solicitações de pesquisa.
Durante a fase de consulta de uma solicitação de pesquisa, o coordenador determina os fragmentos a serem consultados e envia uma solicitação ao nó de dados que hospeda a cópia do fragmento. A consulta é executada localmente em cada fragmento e os documentos correspondentes são retornados ao nó coordenador. O nó coordenador, responsável por enviar a solicitação aos nós que contêm cópias dos shards, executa o processo em duas etapas. Primeiro, ele cria um iterador que define a ordem em que os nós precisam ser consultados em busca de uma cópia de fragmento, para que o tráfego seja distribuído uniformemente entre as cópias de fragmento. Posteriormente, a solicitação é enviada aos nós relevantes.
Para criar uma lista ordenada de nós a serem consultados em busca de uma cópia de fragmento, o nó coordenador usa vários algoritmos. Esses algoritmos incluem seleção round-robin, seleção de réplica adaptativa, roteamento de fragmentos baseado em preferência e round-robin ponderado.
Para Multi-AZ com Standby, o algoritmo round-robin ponderado é usado para seleção de cópia de fragmento. Nessa abordagem, as zonas ativas recebem um peso 1 e a zona de espera recebe um peso 0. Isso garante que nenhum tráfego de leitura seja enviado aos nós de dados na zona de disponibilidade em espera.
Os pesos são armazenados nos metadados do estado do cluster como um objeto JSON:
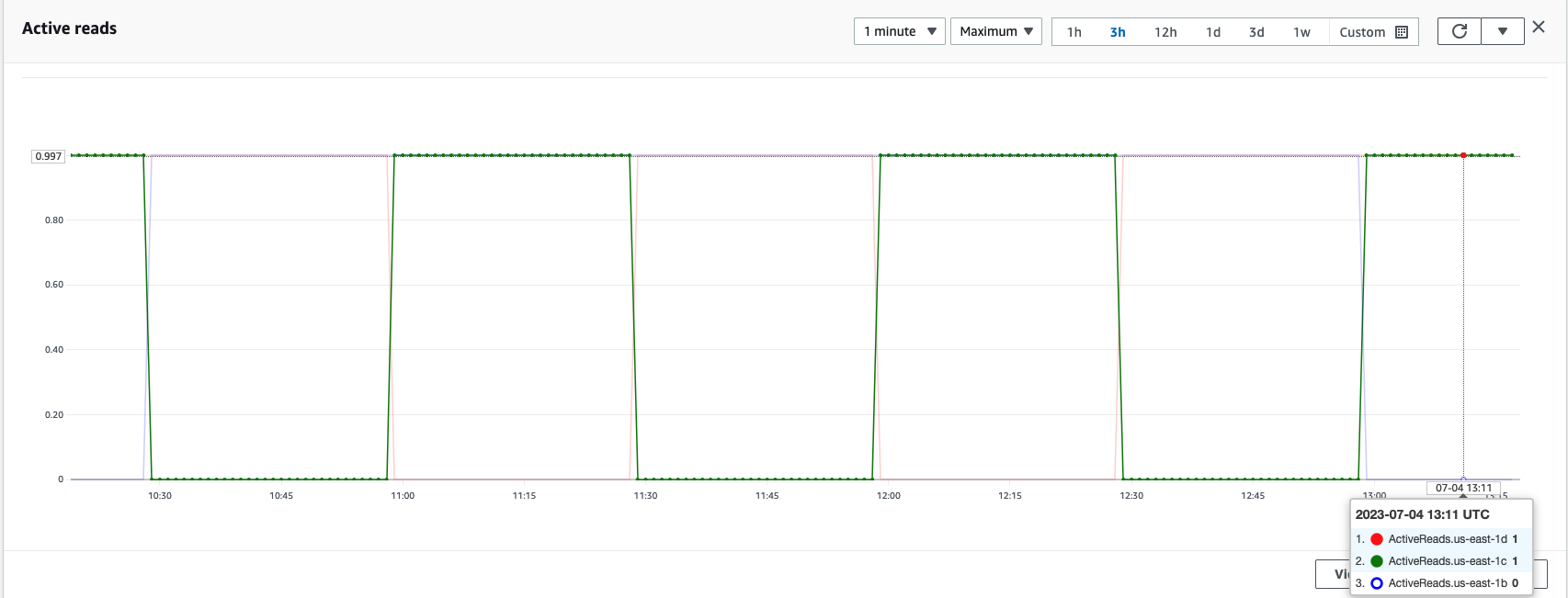
Conforme mostrado na captura de tela a seguir, o us-east-1b A região tem seu status de zona como StandBy, indicando que os nós de dados nesta zona de disponibilidade estão em estado de espera e não recebem solicitações de pesquisa ou indexação do balanceador de carga.

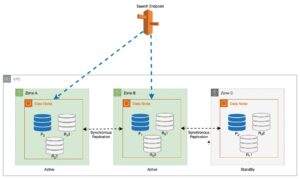
Para manter as operações estáveis, a zona de disponibilidade em espera é alternada a cada 30 minutos, garantindo que todas as partes da rede sejam cobertas pelas zonas de disponibilidade. Esta abordagem proativa verifica a disponibilidade de caminhos de leitura, aumentando ainda mais a resiliência do sistema durante possíveis falhas. O diagrama a seguir ilustra essa arquitetura.
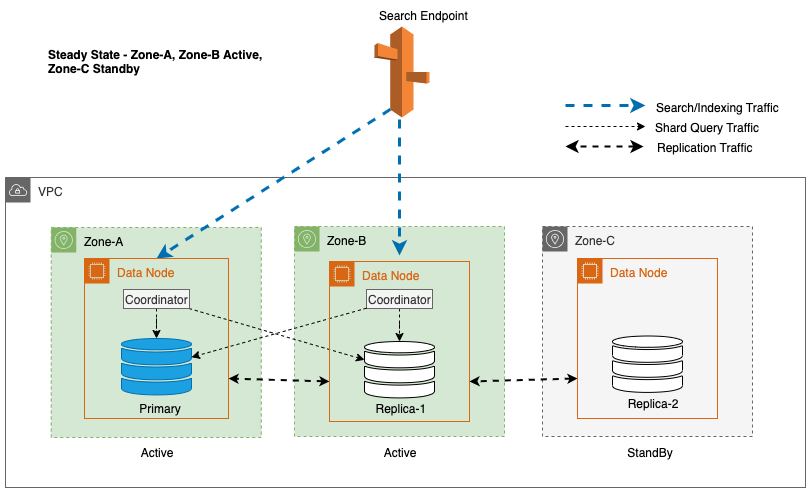
No diagrama anterior, a Zona-C tem um peso round-robin ponderado definido como zero. Isso garante que os nós de dados na zona de espera não recebam nenhum tráfego de indexação ou pesquisa. Quando o coordenador consulta os nós de dados em busca de cópias de fragmentos, ele usa um peso round-robin ponderado para decidir a ordem em que os nós serão consultados. Como o peso é zero para a zona de disponibilidade em espera, as solicitações do coordenador não são enviadas.
Em um cluster do OpenSearch Service, as zonas ativas e de espera podem ser verificadas a qualquer momento usando métricas de rotação da zona de disponibilidade, conforme mostrado na captura de tela a seguir.
Durante interrupções zonais, a zona de disponibilidade em espera alterna perfeitamente para o modo de falha aberta para solicitações de pesquisa. Isso significa que o tráfego de consulta de estilhaços é roteado para todas as zonas de disponibilidade, mesmo aquelas em espera, quando uma cópia de estilhaço íntegra não está disponível na zona de disponibilidade ativa. Essa abordagem de falha aberta protege as solicitações de pesquisa contra interrupções durante falhas, garantindo um serviço contínuo. O diagrama a seguir ilustra essa arquitetura.
No diagrama anterior, durante o estado estável, o tráfego de consulta de shard é enviado para o nó de dados nas zonas de disponibilidade ativas (Zona-A e Zona-B). Devido a falhas de nós na Zona-A, a zona de disponibilidade em espera (Zona-C) falha ao abrir para receber o tráfego de consulta de fragmentos para que não haja qualquer impacto nas solicitações de pesquisa. Eventualmente, a Zona-A é detectada como não íntegra e o failover de leitura alterna o modo de espera para a Zona-A.
Como o failover garante alta disponibilidade durante problemas de gravação
O modelo de replicação do OpenSearch Service segue um modelo de backup primário, caracterizado por sua natureza síncrona, onde a confirmação de todas as cópias de fragmentos é necessária antes que uma solicitação de gravação possa ser confirmada ao usuário. Uma desvantagem notável deste modelo de replicação é a sua suscetibilidade a lentidão no caso de qualquer comprometimento no caminho de gravação. Esses sistemas dependem de um nó líder ativo para identificar falhas ou atrasos e então transmitir essas informações a todos os nós. O tempo necessário para detectar esses problemas (tempo médio para detecção) e subsequentemente resolvê-los (tempo médio para reparo) determina em grande parte por quanto tempo o sistema operará em estado prejudicado. Além disso, qualquer evento de rede que afete as comunicações entre zonas pode impedir significativamente as solicitações de gravação devido à natureza síncrona da replicação.
O OpenSearch Service utiliza um protocolo interno de comunicação nó a nó para replicar o tráfego de gravação e coordenar atualizações de metadados por meio de um líder eleito. Conseqüentemente, colocar a zona sob estresse em modo de espera não resolveria efetivamente o problema de comprometimento de gravação.
Failover de gravação zonal: cortando o tráfego de replicação entre zonas
Para Multi-AZ com Standby, para mitigar possíveis problemas de desempenho causados durante eventos imprevistos, como falhas zonais e eventos de rede, o failover de gravação zonal é uma abordagem eficaz. Essa abordagem envolve a remoção elegante de nós na zona impactada do cluster, cortando efetivamente o tráfego de entrada e saída entre zonas. Ao cortar o tráfego de replicação entre zonas, o impacto das falhas zonais pode ser contido na zona afetada. Isso proporciona uma experiência mais previsível para os clientes e garante que o sistema continue a operar de maneira confiável.
Failover de gravação elegante
A orquestração de um failover de gravação no OpenSearch Service é realizada pelo nó líder eleito por meio de um mecanismo bem definido. Este mecanismo envolve um protocolo de consenso para publicação do estado do cluster, garantindo um acordo unânime entre todos os nós para designar uma única zona (em todos os momentos) para descomissionamento. É importante ressaltar que os metadados relacionados à zona afetada são replicados em todos os nós para garantir sua persistência, mesmo durante uma reinicialização completa no caso de uma interrupção.
Além disso, o nó líder garante uma transição suave e graciosa, colocando inicialmente os nós nas zonas impactadas em espera por um período de 5 minutos antes de iniciar o isolamento de E/S. Esta abordagem deliberada evita que qualquer novo tráfego de coordenador ou tráfego de consulta de fragmentos seja direcionado para os nós dentro da zona impactada. Isso, por sua vez, permite que esses nós concluam suas tarefas contínuas de maneira elegante e lidem gradualmente com quaisquer solicitações em andamento antes de serem retirados de serviço. O diagrama a seguir ilustra essa arquitetura.
No processo de implementação de um failover de gravação para um nó líder, o OpenSearch Service segue estas etapas principais:
- Abdicação do líder – Se o nó líder estiver localizado em uma zona programada para failover de gravação, o sistema garantirá que o nó líder deixe voluntariamente sua função de liderança. Esta abdicação é feita de forma controlada, sendo todo o processo entregue a outro nó elegível, que se encarrega das ações necessárias.
- Impedir a reeleição de líder a ser destituído – Para evitar a reeleição de um líder de uma zona marcada para failover de gravação, quando o nó líder elegível inicia a ação de failover de gravação, ele toma medidas para garantir que quaisquer nós líderes a serem desativados não participem de nenhuma eleição adicional. Isto é conseguido excluindo o nó líder a ser desativado da configuração de votação, impedindo-o efetivamente de votar durante qualquer fase crítica da operação do cluster.
Os metadados relacionados à zona de failover de gravação são armazenados no estado do cluster e essas informações são publicadas em todos os nós no cluster distribuído do OpenSearch Service da seguinte maneira:
A captura de tela a seguir mostra que durante uma lentidão de rede em uma zona, o failover de gravação ajuda a recuperar a disponibilidade.
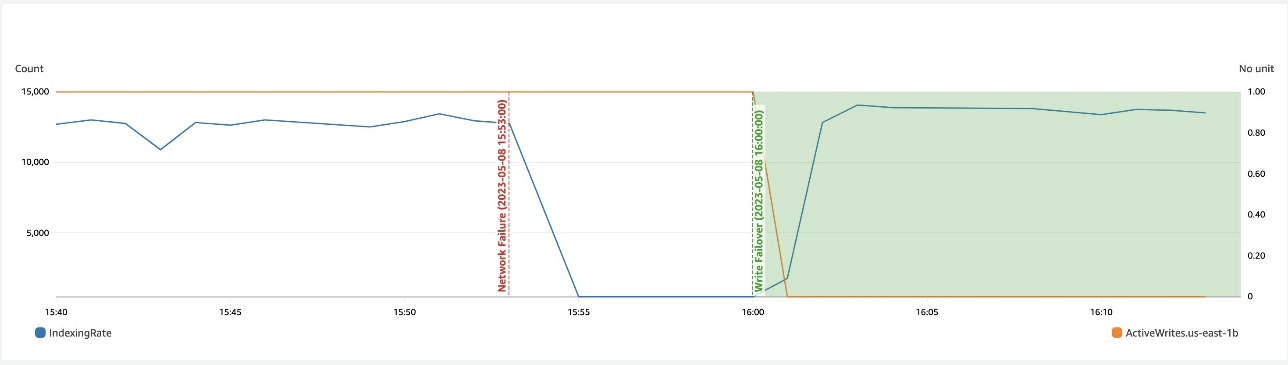
Recuperação zonal após failover de gravação
O processo de recomissionamento zonal desempenha um papel crucial na fase de recuperação após um failover de gravação zonal. Depois que a zona impactada for restaurada e considerada estável, os nós que foram previamente desativados voltarão a ingressar no cluster. Esse recomissionamento normalmente ocorre dentro de um período de 2 minutos após o recomissionamento da zona.
Isso permite que eles sincronizem com seus nós pares e inicie o processo de recuperação de fragmentos de réplica, restaurando efetivamente o cluster ao estado desejado.
Conclusão
A introdução do OpenSearch Service Multi-AZ com Standby oferece às empresas uma solução poderosa para alcançar alta disponibilidade e desempenho consistente para cargas de trabalho críticas. Com esta opção de implantação, as empresas podem melhorar a resiliência da sua infraestrutura, simplificar a configuração e o gerenciamento de clusters e aplicar as melhores práticas. Com recursos como seleção ponderada de cópias de fragmentos round-robin, mecanismos de failover proativos e zonas de disponibilidade em standby com falha aberta, o OpenSearch Service Multi-AZ com Standby garante uma experiência de pesquisa confiável e eficiente para ambientes corporativos exigentes.
Para obter mais informações sobre Multi-AZ com Standby, consulte Amazon OpenSearch Service sob o capô: Multi-AZ com espera.
Sobre o autor
 Anshu Agarwal é um engenheiro de software sênior que trabalha no AWS OpenSearch na Amazon Web Services. Ela é apaixonada por resolver problemas relacionados à construção de sistemas escaláveis e altamente confiáveis.
Anshu Agarwal é um engenheiro de software sênior que trabalha no AWS OpenSearch na Amazon Web Services. Ela é apaixonada por resolver problemas relacionados à construção de sistemas escaláveis e altamente confiáveis.
 Rishab Nahata é um engenheiro de software que trabalha em OpenSearch na Amazon Web Services. Ele é fascinado por resolver problemas em sistemas distribuídos. Ele é colaborador ativo do OpenSearch.
Rishab Nahata é um engenheiro de software que trabalha em OpenSearch na Amazon Web Services. Ele é fascinado por resolver problemas em sistemas distribuídos. Ele é colaborador ativo do OpenSearch.
 Bukhtawar Khan é engenheiro principal e trabalha no Amazon OpenSearch Service. Ele está interessado em sistemas distribuídos e autônomos. Ele é um contribuidor ativo do OpenSearch.
Bukhtawar Khan é engenheiro principal e trabalha no Amazon OpenSearch Service. Ele está interessado em sistemas distribuídos e autônomos. Ele é um contribuidor ativo do OpenSearch.
 Ranjith Ramachandra é um gerente de engenharia que trabalha no Amazon OpenSearch Service na Amazon Web Services.
Ranjith Ramachandra é um gerente de engenharia que trabalha no Amazon OpenSearch Service na Amazon Web Services.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :tem
- :é
- :não
- :onde
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Sobre
- Alcançar
- alcançado
- reconhecido
- em
- Aja
- Açao Social
- ações
- ativo
- adaptativo
- Adicionalmente
- endereço
- afetado
- Depois de
- Acordo
- algoritmo
- algoritmos
- Todos os Produtos
- permitir
- Amazon
- Amazon Web Services
- entre
- an
- e
- Outro
- qualquer
- abordagem
- arquitetura
- SOMOS
- AS
- atribuído
- At
- Autônomo
- sistemas autônomos
- disponibilidade
- consciência
- AWS
- backup
- balanceador
- BE
- Porque
- sido
- antes
- ser
- MELHOR
- melhores práticas
- entre
- ambos
- transmissão
- Prédio
- negócios
- by
- CAN
- Capacidade
- transportado
- causado
- caracterizado
- carregar
- verificado
- Agrupar
- Comunicação
- Comunicações
- completar
- Configuração
- Consenso
- Consequentemente
- considerado
- consistente
- cônsul
- contida
- continua
- contínuo
- contribuir
- contribuinte
- controlado
- coordenando
- Coordenador
- coordenadores
- cópias
- coberto
- crio
- cria
- crítico
- crucial
- Clientes
- corte
- dados,
- decidir
- profundo
- mergulho profundo
- Define
- atrasos
- mergulhar
- exigente
- desenvolvimento
- implanta
- designado
- projetado
- desejado
- descobrir
- detectou
- determina
- dirigido
- Rompimento
- distribuído
- Sistemas distribuídos
- mergulho
- do
- INSTITUCIONAIS
- domínio
- domínios
- não
- down
- dois
- duração
- durante
- cada
- Eficaz
- efetivamente
- eficiente
- eleito
- Eleições
- elegível
- eliminando
- habilitado
- permite
- aplicar
- engenheiro
- Engenharia
- aumentar
- aprimorada
- aprimorando
- garantir
- garante
- assegurando
- Empreendimento
- Todo
- ambientes
- especialmente
- Éter (ETH)
- Mesmo
- Evento
- eventos
- eventualmente
- Cada
- excluindo
- vasta experiência
- experimentando
- explorar
- falha
- Falha
- falhas
- Característica
- Funcionalidades
- esgrima
- Primeiro nome
- seguinte
- segue
- Escolha
- QUADRO
- da
- cheio
- mais distante
- gif
- Gracioso
- gradualmente
- garanta
- mão
- manipular
- Alças
- acontece
- he
- saudável
- ajuda
- Alta
- altamente
- capuz
- hospedagem
- Como funciona o dobrador de carta de canal
- http
- HTTPS
- identificar
- if
- ilustra
- Impacto
- impactada
- prejuízo
- implementação
- importante
- in
- incluir
- indicador
- INFORMAÇÕES
- Infraestrutura
- inicialmente
- Inicia
- iniciando
- instâncias
- interessado
- interno
- para dentro
- introduzido
- Introdução
- envolve
- emitem
- questões
- IT
- ESTÁ
- jpg
- json
- Chave
- conhecido
- largamente
- líder
- Liderança
- como
- Lista
- carregar
- localmente
- localizado
- longo
- a manter
- manutenção
- gerenciados
- de grupos
- Gerente
- maneira
- marcado
- correspondido
- significar
- significa
- medidas
- mecanismo
- mecanismos
- metadados
- Métrica
- minuto
- minutos
- Mitigar
- Moda
- modelo
- mais
- movimento
- Natureza
- necessário
- você merece...
- rede
- networking
- Novo
- não
- nó
- nós
- notável
- objeto
- of
- WOW!
- on
- ONE
- contínuo
- só
- aberto
- operar
- operação
- Operações
- Opção
- or
- orquestração
- ordem
- Outros
- Fora
- interrupção
- Interrupções
- Acima de
- participar
- peças
- apaixonado
- caminho
- caminhos
- perscrutar
- atuação
- persistência
- fase
- colocação
- platão
- Inteligência de Dados Platão
- PlatãoData
- desempenha
- Publique
- potencial
- poderoso
- práticas
- precedente
- Previsível
- evitar
- impedindo
- impede
- anteriormente
- primário
- Diretor
- Proactive
- problemas
- processo
- a promover
- protocolo
- fornecer
- fornece
- Publicação
- publicado
- Colocar
- consultas
- Leia
- receber
- recebe
- recentemente
- Recuperar
- recuperação
- recuperação
- referir
- região
- regular
- relacionado
- relevante
- confiabilidade
- confiável
- depender
- remanescente
- remoção
- reparar
- responder
- replicado
- réplica
- solicitar
- pedidos
- requeridos
- resiliência
- resiliente
- resolver
- responsável
- restaurar
- restaurado
- restauração
- Tipo
- roteamento
- Execute
- é executado
- s
- proteções
- mesmo
- escalável
- programado
- sem problemas
- Pesquisar
- doadores,
- envio
- envia
- senior
- enviei
- serviço
- Serviços
- conjunto
- ela
- mostrando
- de forma considerável
- simplicidade
- simplificar
- solteiro
- Desacelere
- lentidão
- Liso
- So
- Software
- Engenheiro de Software
- solução
- Resolvendo
- estável
- Estado
- Status
- estável
- Passos
- armazenadas
- estresse
- Subseqüentemente
- bem sucedido
- suscetibilidade
- .
- sistemas
- Tire
- tomado
- toma
- tarefas
- que
- A
- deles
- Eles
- então
- Lá.
- Este
- isto
- aqueles
- três
- Através da
- tempo
- vezes
- para
- tolerância
- tráfego
- transição
- VIRAR
- dois
- tipicamente
- para
- subjacente
- imprevisto
- Atualizações
- usava
- Utilizador
- usos
- utilização
- utiliza
- vário
- voluntariamente
- Votação
- we
- web
- serviços web
- peso
- BEM
- bem definido
- foram
- quando
- qual
- enquanto
- precisarão
- de
- dentro
- trabalhar
- trabalho
- escrever
- zefirnet
- zero
- zonas