Estúdio Amazon SageMaker fornece uma solução totalmente gerenciada para que cientistas de dados construam, treinem e implantem modelos de aprendizado de máquina (ML) de forma interativa. Trabalhos de notebook do Amazon SageMaker permita que os cientistas de dados executem seus notebooks sob demanda ou de acordo com uma programação com apenas alguns cliques no SageMaker Studio. Com este lançamento, você pode executar notebooks programaticamente como trabalhos usando APIs fornecidas por Pipelines Amazon SageMaker, o recurso de orquestração de fluxo de trabalho de ML de Amazon Sage Maker. Além disso, você pode criar um fluxo de trabalho de ML de várias etapas com vários notebooks dependentes usando essas APIs.
SageMaker Pipelines é uma ferramenta nativa de orquestração de fluxo de trabalho para construir pipelines de ML que aproveitam a integração direta do SageMaker. Cada pipeline do SageMaker é composto por passos, que correspondem a tarefas individuais, como processamento, treinamento ou processamento de dados usando Amazon EMR. Os trabalhos de notebook do SageMaker agora estão disponíveis como um tipo de etapa integrada nos pipelines do SageMaker. Você pode usar esta etapa de trabalho de notebook para executar facilmente notebooks como trabalhos com apenas algumas linhas de código usando o comando SDK do Amazon SageMaker Python. Além disso, você pode unir vários notebooks dependentes para criar um fluxo de trabalho na forma de gráficos acíclicos direcionados (DAGs). Você pode então executar esses trabalhos de notebooks ou DAGs e gerenciá-los e visualizá-los usando o SageMaker Studio.
Atualmente, os cientistas de dados usam o SageMaker Studio para desenvolver interativamente seus notebooks Jupyter e, em seguida, usam trabalhos de notebook do SageMaker para executar esses notebooks como trabalhos agendados. Esses trabalhos podem ser executados imediatamente ou em um cronograma recorrente, sem a necessidade de trabalhadores de dados refatorarem o código como módulos Python. Alguns casos de uso comuns para fazer isso incluem:
- Executando notebooks de longa duração em segundo plano
- Inferência de modelo em execução regular para gerar relatórios
- Ampliando desde a preparação de pequenos conjuntos de dados de amostra até o trabalho com big data em escala de petabytes
- Retreinar e implantar modelos em alguma cadência
- Agendamento de jobs para monitoramento de qualidade de modelo ou desvio de dados
- Explorando o espaço de parâmetros para melhores modelos
Embora essa funcionalidade facilite aos trabalhadores de dados a automatização de notebooks independentes, os fluxos de trabalho de ML geralmente são compostos por vários notebooks, cada um executando uma tarefa específica com dependências complexas. Por exemplo, um notebook que monitora desvios de dados do modelo deve ter uma pré-etapa que permita extrair, transformar e carregar (ETL) e processar novos dados e uma pós-etapa de atualização e treinamento do modelo caso um desvio significativo seja percebido. . Além disso, os cientistas de dados podem querer acionar todo esse fluxo de trabalho em uma programação recorrente para atualizar o modelo com base em novos dados. Para permitir que você automatize facilmente seus notebooks e crie fluxos de trabalho complexos, os trabalhos de notebook do SageMaker agora estão disponíveis como uma etapa no SageMaker Pipelines. Neste post, mostramos como você pode resolver os seguintes casos de uso com algumas linhas de código:
- Execute programaticamente um notebook autônomo imediatamente ou em uma programação recorrente
- Crie fluxos de trabalho de várias etapas de notebooks como DAGs para fins de integração contínua e entrega contínua (CI/CD) que podem ser gerenciados por meio da interface do usuário do SageMaker Studio
Visão geral da solução
O diagrama a seguir ilustra nossa arquitetura de solução. Você pode usar o SageMaker Python SDK para executar um único trabalho de notebook ou um fluxo de trabalho. Este recurso cria um trabalho de treinamento do SageMaker para executar o notebook.
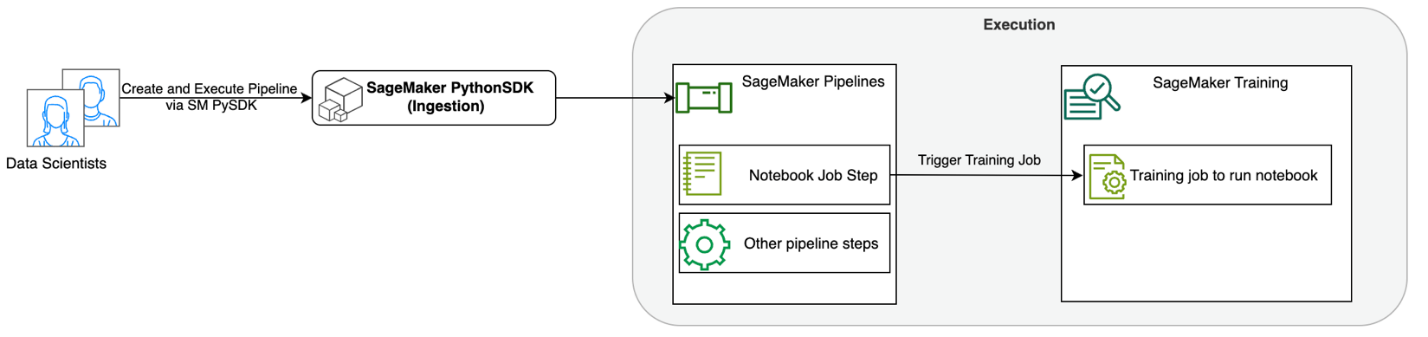
Nas seções a seguir, percorremos um exemplo de caso de uso de ML e mostramos as etapas para criar um fluxo de trabalho de trabalhos de notebook, passando parâmetros entre diferentes etapas do notebook, agendando seu fluxo de trabalho e monitorando-o por meio do SageMaker Studio.
Para nosso problema de ML neste exemplo, estamos construindo um modelo de análise de sentimento, que é um tipo de tarefa de classificação de texto. As aplicações mais comuns de análise de sentimento incluem monitoramento de mídia social, gerenciamento de suporte ao cliente e análise de feedback do cliente. O conjunto de dados usado neste exemplo é o conjunto de dados Stanford Sentiment Treebank (SST2), que consiste em resenhas de filmes junto com um número inteiro (0 ou 1) que indica o sentimento positivo ou negativo da crítica.
A seguir está um exemplo de um data.csv arquivo correspondente ao conjunto de dados SST2 e mostra valores em suas duas primeiras colunas. Observe que o arquivo não deve ter nenhum cabeçalho.
| Coluna 1 | Coluna 2 |
| 0 | esconder novas secreções das unidades parentais |
| 0 | não contém inteligência, apenas piadas elaboradas |
| 1 | que ama seus personagens e comunica algo bastante bonito sobre a natureza humana |
| 0 | permanece totalmente satisfeito em permanecer o mesmo durante todo |
| 0 | sobre os piores clichês da vingança dos nerds que os cineastas poderiam desenterrar |
| 0 | isso é trágico demais para merecer um tratamento tão superficial |
| 1 | demonstra que o diretor de sucessos de bilheteria de Hollywood, como Patriot Games, ainda pode produzir um pequeno filme pessoal com um impacto emocional. |
Neste exemplo de ML, devemos realizar diversas tarefas:
- Execute a engenharia de recursos para preparar esse conjunto de dados em um formato que nosso modelo possa entender.
- Pós-engenharia de recursos, execute uma etapa de treinamento que usa Transformers.
- Configure a inferência em lote com o modelo ajustado para ajudar a prever o sentimento das novas avaliações recebidas.
- Configure uma etapa de monitoramento de dados para que possamos monitorar regularmente nossos novos dados em busca de qualquer desvio na qualidade que possa exigir um novo treinamento dos pesos do modelo.
Com o lançamento de um notebook job como uma etapa nos pipelines do SageMaker, podemos orquestrar esse fluxo de trabalho, que consiste em três etapas distintas. Cada etapa do fluxo de trabalho é desenvolvida em um notebook diferente, que são então convertidos em etapas independentes de jobs de notebook e conectados como um pipeline:
- Pré-processando – Baixe o conjunto de dados público SST2 em Serviço de armazenamento simples da Amazon (Amazon S3) e crie um arquivo CSV para o notebook na Etapa 2 ser executado. O conjunto de dados SST2 é um conjunto de dados de classificação de texto com dois rótulos (0 e 1) e uma coluna de texto para categorizar.
- Training – Pegue o arquivo CSV modelado e execute o ajuste fino com BERT para classificação de texto utilizando bibliotecas Transformers. Usamos um notebook de preparação de dados de teste como parte desta etapa, que é uma dependência para a etapa de ajuste fino e inferência em lote. Quando o ajuste fino é concluído, este notebook é executado usando run magic e prepara um conjunto de dados de teste para inferência de amostra com o modelo ajustado.
- Transformar e monitorar – Execute inferência em lote e configure a qualidade dos dados com monitoramento de modelo para ter uma sugestão de conjunto de dados de linha de base.
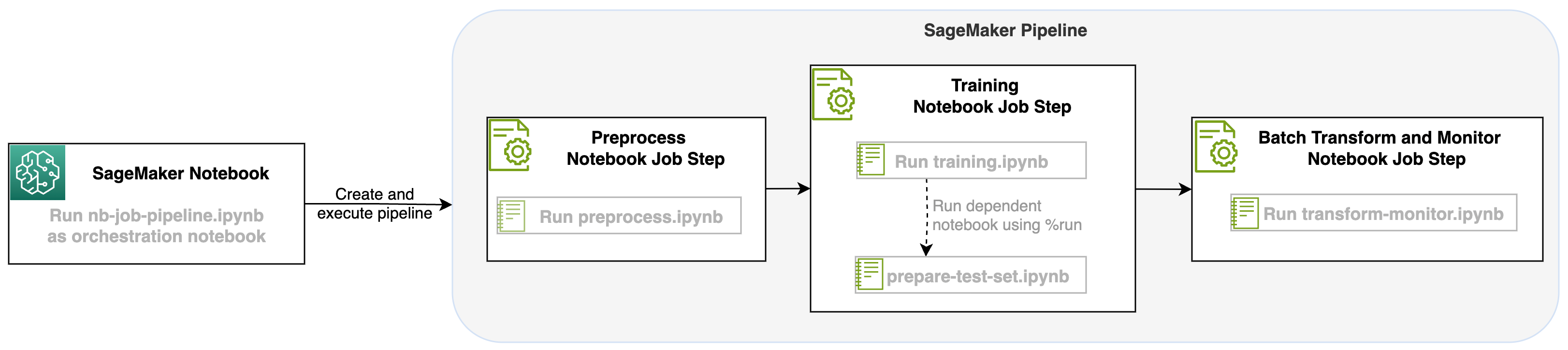
Execute os cadernos
O código de exemplo para esta solução está disponível em GitHub.
Criar uma etapa de trabalho do notebook SageMaker é semelhante à criação de outras etapas do SageMaker Pipeline. Neste exemplo de notebook, usamos o SageMaker Python SDK para orquestrar o fluxo de trabalho. Para criar uma etapa de notebook no SageMaker Pipelines, você pode definir os seguintes parâmetros:
- Caderno de entrada – O nome do notebook que esta etapa do notebook orquestrará. Aqui você pode passar o caminho local para o notebook de entrada. Opcionalmente, se este notebook tiver outros notebooks em execução, você poderá passá-los no
AdditionalDependenciesparâmetro para a etapa de trabalho do notebook. - URI da imagem – A imagem do Docker por trás da etapa de trabalho do notebook. Podem ser as imagens predefinidas que o SageMaker já fornece ou uma imagem personalizada que você definiu e enviou para Registro do Amazon Elastic Container (Amazon ECR). Consulte a seção de considerações no final desta postagem para ver as imagens suportadas.
- Nome do kernel – O nome do kernel que você está usando no SageMaker Studio. Esta especificação do kernel está registrada na imagem que você forneceu.
- Tipo de instância (opcional) - A Amazon Elastic Compute Nuvem (Amazon EC2) tipo de instância por trás do trabalho de notebook que você definiu e que estará em execução.
- Parâmetros (opcional) – Parâmetros que você pode passar e que ficarão acessíveis para o seu notebook. Eles podem ser definidos em pares de valores-chave. Além disso, esses parâmetros podem ser modificados entre várias execuções de trabalho de notebook ou de pipeline.
Nosso exemplo tem um total de cinco notebooks:
- nb-job-pipeline.ipynb – Este é o nosso caderno principal onde definimos nosso pipeline e fluxo de trabalho.
- pré-processo.ipynb – Este notebook é a primeira etapa em nosso fluxo de trabalho e contém o código que extrairá o conjunto de dados público da AWS e criará um arquivo CSV a partir dele.
- treinamento.ipynb – Este notebook é a segunda etapa do nosso fluxo de trabalho e contém código para pegar o CSV da etapa anterior e realizar treinamento e ajustes locais. Esta etapa também depende do
prepare-test-set.ipynbnotebook para obter um conjunto de dados de teste para inferência de amostra com o modelo ajustado. - prepare-test-set.ipynb – Este notebook cria um conjunto de dados de teste que nosso notebook de treinamento usará na segunda etapa do pipeline e para inferência de amostra com o modelo ajustado.
- transform-monitor.ipynb – Este notebook é a terceira etapa em nosso fluxo de trabalho e pega o modelo BERT básico e executa um trabalho de transformação em lote do SageMaker, ao mesmo tempo que configura a qualidade dos dados com monitoramento do modelo.
A seguir, percorremos o caderno principal nb-job-pipeline.ipynb, que combina todos os subnotebooks em um pipeline e executa o fluxo de trabalho de ponta a ponta. Observe que, embora o exemplo a seguir execute o notebook apenas uma vez, você também pode agendar o pipeline para executar o notebook repetidamente. Referir-se Documentação do SageMaker para instruções detalhadas.
Para nossa primeira etapa do trabalho do notebook, passamos um parâmetro com um bucket S3 padrão. Podemos usar esse bucket para despejar quaisquer artefatos que desejarmos disponíveis para nossas outras etapas do pipeline. Para o primeiro caderno (preprocess.ipynb), extraímos o conjunto de dados de treinamento SST2 público da AWS e criamos um arquivo CSV de treinamento a partir dele, que enviamos para este bucket S3. Veja o seguinte código:
Podemos então converter este notebook em um NotebookJobStep com o seguinte código em nosso notebook principal:
Agora que temos um arquivo CSV de amostra, podemos começar a treinar nosso modelo em nosso caderno de treinamento. Nosso notebook de treinamento pega o mesmo parâmetro do bucket S3 e extrai o conjunto de dados de treinamento desse local. Em seguida, realizamos o ajuste fino usando o objeto de treinamento Transformers com o seguinte trecho de código:
Após o ajuste fino, queremos executar algumas inferências em lote para ver o desempenho do modelo. Isso é feito usando um caderno separado (prepare-test-set.ipynb) no mesmo caminho local que cria um conjunto de dados de teste para realizar inferência sobre o uso de nosso modelo treinado. Podemos executar o caderno adicional em nosso caderno de treinamento com a seguinte célula mágica:
Definimos essa dependência extra do notebook no arquivo AdditionalDependencies parâmetro em nossa segunda etapa do trabalho do notebook:
Também devemos especificar que a etapa de trabalho do notebook de treinamento (Etapa 2) depende da etapa de trabalho do notebook Pré-processar (Etapa 1) usando o método add_depends_on Chamada de API da seguinte forma:
Nossa última etapa fará com que o modelo BERT execute um SageMaker Batch Transform, ao mesmo tempo em que configurará a captura e qualidade de dados por meio do SageMaker Model Monitor. Observe que isso é diferente de usar o recurso integrado Transformar or captura etapas por meio de Pipelines. Nosso notebook para esta etapa executará essas mesmas APIs, mas será rastreado como uma etapa de trabalho do Notebook. Esta etapa depende da etapa do trabalho de treinamento que definimos anteriormente, portanto também capturamos isso com o sinalizador depende_on.
Após a definição das várias etapas do nosso fluxo de trabalho, podemos criar e executar o pipeline ponta a ponta:
Monitore as execuções do pipeline
Você pode rastrear e monitorar as execuções das etapas do notebook por meio do SageMaker Pipelines DAG, conforme visto na captura de tela a seguir.
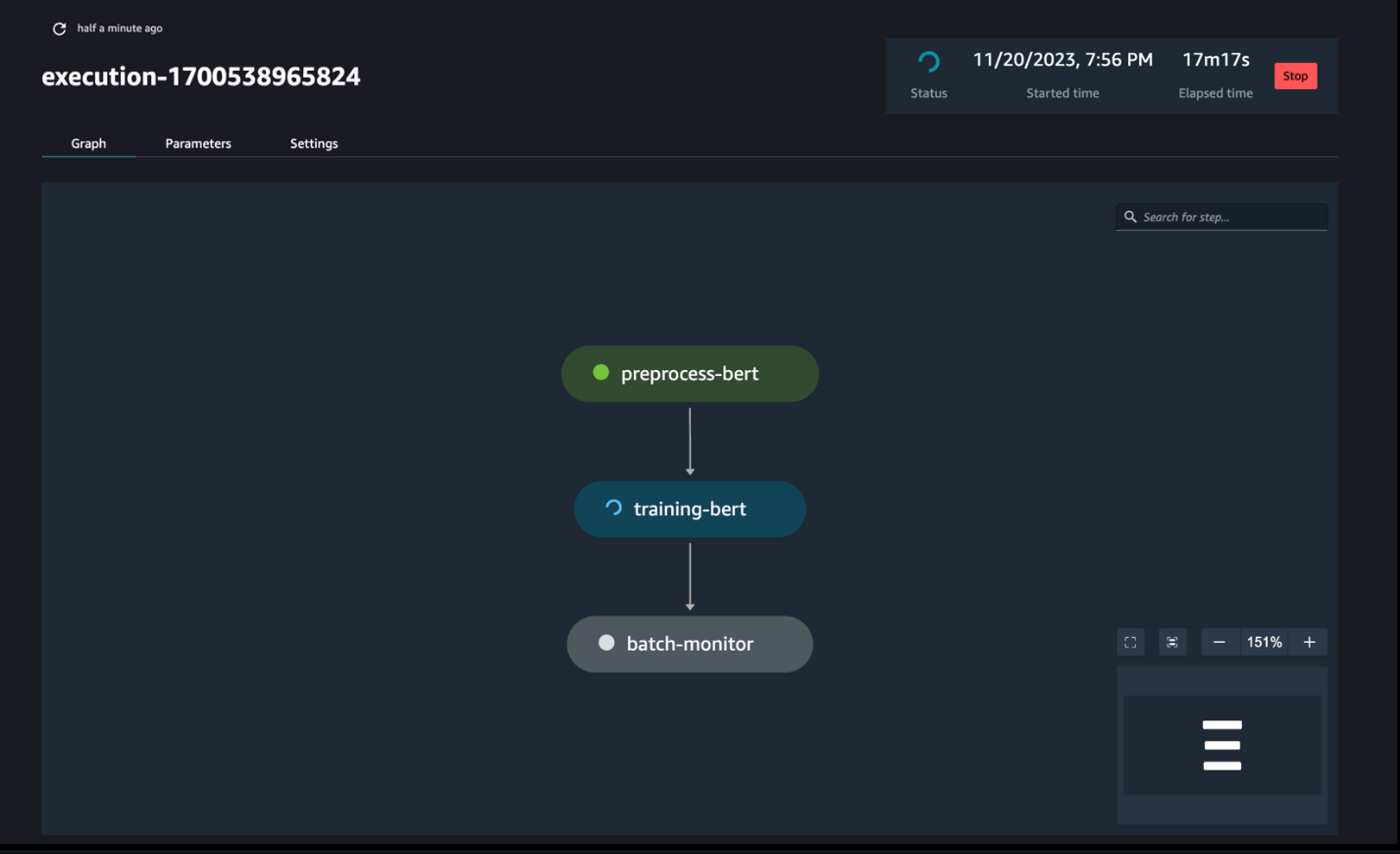
Opcionalmente, você também pode monitorar as execuções individuais do notebook no painel de trabalho do notebook e alternar os arquivos de saída que foram criados por meio da interface do usuário do SageMaker Studio. Ao usar essa funcionalidade fora do SageMaker Studio, você pode definir os usuários que podem rastrear o status da execução no painel do trabalho do notebook usando tags. Para obter mais detalhes sobre tags a serem incluídas, consulte Visualize seus trabalhos de notebook e baixe resultados no painel da UI do Studio.
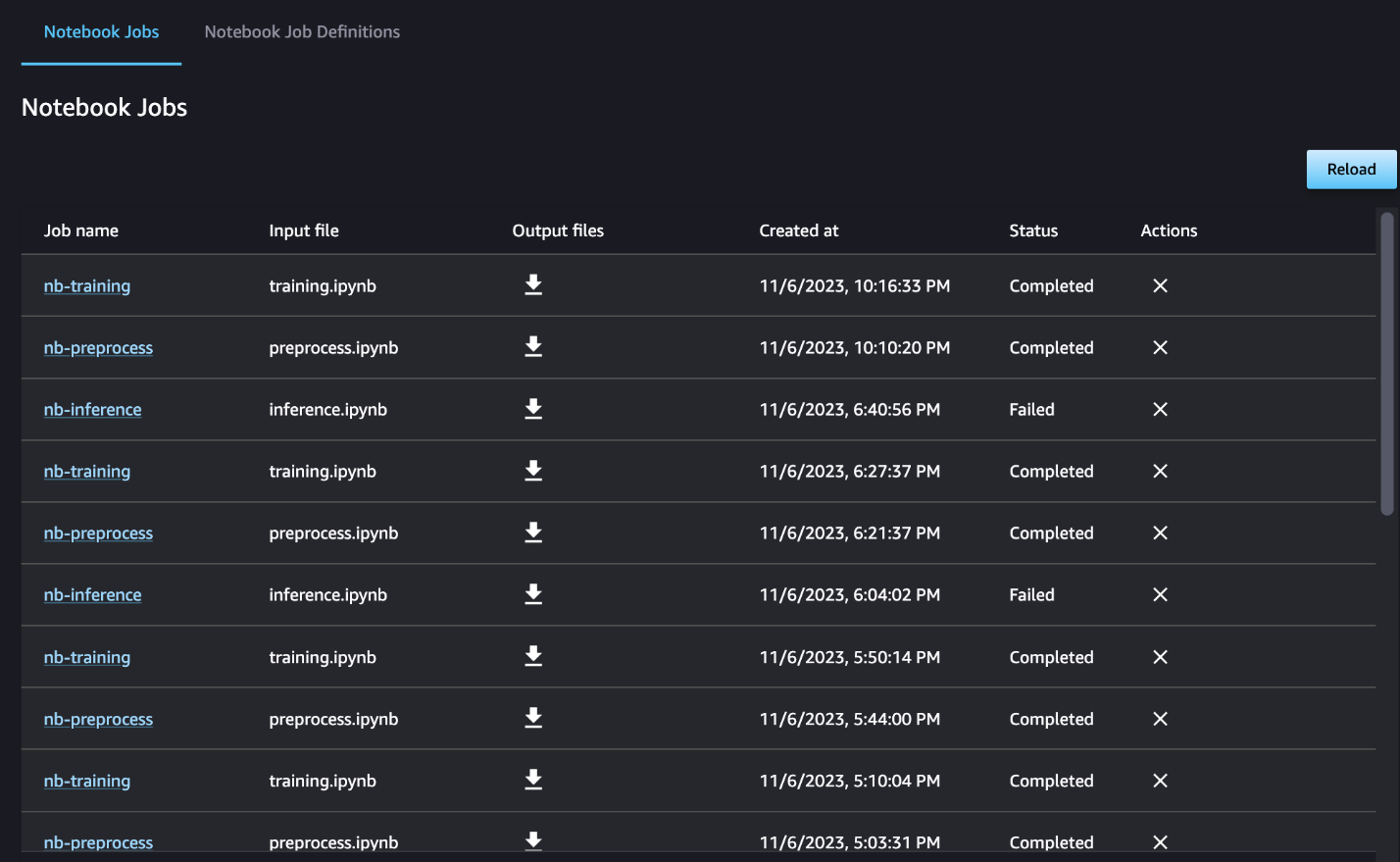
Para este exemplo, enviamos os trabalhos de notebook resultantes para um diretório chamado outputs no caminho local com o código de execução do pipeline. Conforme mostrado na captura de tela a seguir, aqui você pode ver a saída do seu notebook de entrada e também quaisquer parâmetros definidos para essa etapa.
limpar
Se você seguiu nosso exemplo, certifique-se de excluir o pipeline criado, os trabalhos de notebook e os dados s3 baixados pelos notebooks de amostra.
Considerações
A seguir estão algumas considerações importantes para esse recurso:
- Restrições do SDK – A etapa de trabalho do notebook só pode ser criada por meio do SageMaker Python SDK.
- Restrições de imagem –A etapa de trabalho do notebook suporta as seguintes imagens:
Conclusão
Com este lançamento, os profissionais de dados agora podem executar programaticamente seus notebooks com algumas linhas de código usando o SDK Python do SageMaker. Além disso, você pode criar fluxos de trabalho complexos de várias etapas usando seus notebooks, reduzindo significativamente o tempo necessário para passar de um notebook para um pipeline de CI/CD. Depois de criar o pipeline, você pode usar o SageMaker Studio para visualizar e executar DAGs para seus pipelines e gerenciar e comparar as execuções. Esteja você agendando fluxos de trabalho de ML de ponta a ponta ou parte deles, recomendamos que você experimente fluxos de trabalho baseados em notebook.
Sobre os autores
 Anchit Gupta é gerente de produto sênior do Amazon SageMaker Studio. Ela se concentra em permitir fluxos de trabalho interativos de ciência de dados e engenharia de dados no SageMaker Studio IDE. Nas horas vagas, ela gosta de cozinhar, jogar jogos de tabuleiro/cartas e ler.
Anchit Gupta é gerente de produto sênior do Amazon SageMaker Studio. Ela se concentra em permitir fluxos de trabalho interativos de ciência de dados e engenharia de dados no SageMaker Studio IDE. Nas horas vagas, ela gosta de cozinhar, jogar jogos de tabuleiro/cartas e ler.
 Ram Vegiraju é um arquiteto de ML da equipe SageMaker Service. Ele se concentra em ajudar os clientes a criar e otimizar suas soluções de IA/ML no Amazon SageMaker. Nas horas vagas, adora viajar e escrever.
Ram Vegiraju é um arquiteto de ML da equipe SageMaker Service. Ele se concentra em ajudar os clientes a criar e otimizar suas soluções de IA/ML no Amazon SageMaker. Nas horas vagas, adora viajar e escrever.
 Eduardo Sol é um SDE sênior que trabalha para o SageMaker Studio na Amazon Web Services. Ele está focado na criação de soluções de ML interativas e na simplificação da experiência do cliente para integrar o SageMaker Studio com tecnologias populares em engenharia de dados e ecossistema de ML. Em seu tempo livre, Edward é um grande fã de camping, caminhadas e pesca e gosta de passar o tempo com sua família.
Eduardo Sol é um SDE sênior que trabalha para o SageMaker Studio na Amazon Web Services. Ele está focado na criação de soluções de ML interativas e na simplificação da experiência do cliente para integrar o SageMaker Studio com tecnologias populares em engenharia de dados e ecossistema de ML. Em seu tempo livre, Edward é um grande fã de camping, caminhadas e pesca e gosta de passar o tempo com sua família.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :tem
- :é
- :onde
- $UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Sobre
- acessível
- acíclico
- Adicional
- Adicionalmente
- Vantagem
- Depois de
- AI / ML
- Todos os Produtos
- permite
- juntamente
- já
- tb
- Apesar
- Amazon
- Amazon EC2
- Amazon Sage Maker
- Estúdio Amazon SageMaker
- Amazon Web Services
- an
- análise
- análise
- e
- qualquer
- api
- APIs
- aplicações
- arquitetura
- SOMOS
- AS
- At
- automatizar
- disponível
- AWS
- base
- baseado
- Linha de Base
- BE
- bonita
- sido
- atrás
- ser
- Melhor
- entre
- Grande
- construir
- Prédio
- construídas em
- mas a
- by
- chamada
- chamado
- camping
- CAN
- capturar
- casas
- casos
- célula
- caracteres
- classificação
- código
- Coluna
- colunas
- combina
- como
- comum
- comparar
- completar
- integrações
- composta
- Composto
- Computar
- Conduzir
- conectado
- Considerações
- consiste
- Recipiente
- contém
- contínuo
- converter
- convertido
- cozinha
- Correspondente
- poderia
- crio
- criado
- cria
- Criar
- Atualmente
- personalizadas
- cliente
- experiência do cliente
- Suporte ao cliente
- Clientes
- DAG
- painel de instrumentos
- dados,
- monitoramento de dados
- Preparação de dados
- informática
- qualidade de dados
- ciência de dados
- conjuntos de dados
- Padrão
- definir
- definido
- Entrega
- Demanda
- dependências
- Dependência
- dependente
- depende
- implantar
- Implantação
- detalhado
- detalhes
- desenvolver
- desenvolvido
- diferente
- diretamente
- dirigido
- Diretor
- distinto
- Estivador
- fazer
- feito
- down
- download
- despejar
- cada
- facilmente
- ecossistema
- Edward
- permitir
- permitindo
- encorajar
- final
- end-to-end
- Engenharia
- Todo
- época
- Éter (ETH)
- exemplo
- executar
- execução
- vasta experiência
- extra
- extrato
- família
- ventilador
- longe
- Característica
- retornos
- poucos
- Envie o
- Arquivos
- Filme
- cineastas
- Primeiro nome
- Pescaria
- cinco
- focado
- concentra-se
- seguido
- seguinte
- segue
- Escolha
- formulário
- formato
- da
- totalmente
- funcionalidade
- Além disso
- Games
- gerar
- gráficos
- Ter
- he
- ajudar
- ajuda
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- caminhadas
- sua
- Hollywood
- Como funciona o dobrador de carta de canal
- HTML
- http
- HTTPS
- humano
- if
- ilustra
- imagem
- imagens
- imediatamente
- importar
- importante
- in
- incluir
- de treinadores em Entrevista Motivacional
- indicam
- Individual
- entrada
- instância
- instruções
- integrar
- integração
- interativo
- para dentro
- IT
- ESTÁ
- Trabalho
- Empregos
- jpg
- apenas por
- O rótulo
- Rótulos
- Sobrenome
- lançamento
- aprendizagem
- bibliotecas
- Line
- linhas
- carregar
- local
- localização
- longo
- ama
- máquina
- aprendizado de máquina
- mágica
- a Principal
- FAZ
- gerencia
- gerenciados
- de grupos
- Gerente
- Mídia
- Mérito
- poder
- ML
- modelo
- modelos
- modificada
- Módulos
- Monitore
- monitoração
- monitores
- mais
- a maioria
- mover
- filme
- múltiplo
- devo
- nome
- nativo
- você merece...
- necessário
- negativo
- Novo
- não
- nota
- caderno
- laptops
- agora
- objeto
- of
- frequentemente
- on
- ONE
- só
- Otimize
- or
- orquestração
- Outros
- A Nossa
- Fora
- saída
- outputs
- lado de fora
- pares
- parâmetro
- parâmetros
- parte
- passar
- Passagem
- caminho
- realizar
- realização
- pessoal
- oleoduto
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- Popular
- positivo
- Publique
- predizer
- preparação
- Preparar
- Prepara
- preparação
- anterior
- anteriormente
- Problema
- em processamento
- Produto
- gerente de produto
- fornecer
- fornecido
- fornece
- público
- Pullover
- fins
- Empurrar
- empurrado
- Python
- qualidade
- mais rápido
- R
- em vez
- Leia
- Leitura
- recorrente
- redução
- Refatorar
- referir
- registrado
- regularmente
- permanecem
- REPETIDAMENTE
- requerer
- resultando
- rever
- Opinões
- Execute
- corrida
- é executado
- sábio
- Pipelines SageMaker
- mesmo
- satisfeito
- cronograma
- programado
- Trabalhos agendados
- agendamento
- Ciência
- cientistas
- Sdk
- Segundo
- Seção
- seções
- Vejo
- visto
- senior
- sentimento
- separado
- serviço
- Serviços
- Sessão
- conjunto
- contexto
- vários
- em forma de
- ela
- rede de apoio social
- mostrar
- mostrar
- mostrando
- Shows
- periodo
- de forma considerável
- semelhante
- simples
- simplificando
- solteiro
- pequeno
- menor
- fragmento
- So
- Redes Sociais
- meios de comunicação social
- solução
- Soluções
- RESOLVER
- alguns
- algo
- Espaço
- específico
- Passar
- autônoma
- Stanford
- começo
- Status
- Passo
- Passos
- Ainda
- armazenamento
- franco
- estudo
- tal
- Espreguiçadeiras
- ajuda
- Suportado
- suportes
- certo
- Tire
- toma
- Tarefa
- tarefas
- Profissionais
- Tecnologias
- teste
- texto
- Classificação de Texto
- que
- A
- deles
- Eles
- então
- Este
- Terceiro
- isto
- aqueles
- três
- Através da
- tempo
- para
- juntos
- também
- ferramenta
- Total
- pista
- Trem
- treinado
- Training
- Transformar
- transformadores
- Viagens
- desencadear
- VIRAR
- dois
- tipo
- ui
- compreender
- Atualizar
- us
- usar
- caso de uso
- usava
- usuários
- usos
- utilização
- Utilizando
- Valores
- vário
- via
- Ver
- visualizar
- andar
- queremos
- we
- web
- serviços web
- quando
- se
- qual
- enquanto
- QUEM
- precisarão
- de
- dentro
- sem
- trabalhadores
- de gestão de documentos
- fluxos de trabalho
- trabalhar
- o pior
- escrita
- Você
- investimentos
- zefirnet