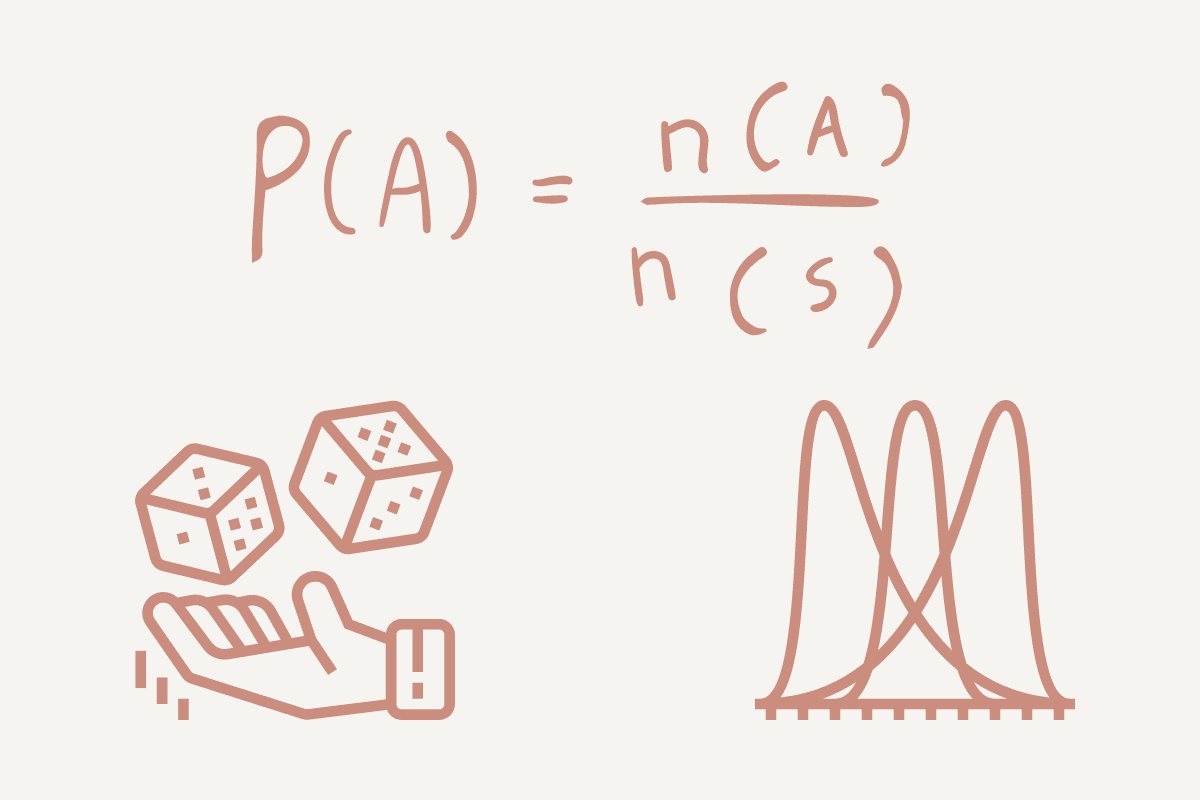
Imagem do autor
Como Cientista de Dados, você desejará saber a precisão de seus resultados para garantir a validade. O fluxo de trabalho da ciência de dados é um projeto planejado, com condições controladas. Permitindo que você avalie cada estágio e como ele contribuiu para sua produção.
Probabilidade é a medida da probabilidade de um evento/algo acontecer. É um elemento importante na análise preditiva, permitindo que você explore a matemática computacional por trás do seu resultado.
Usando um exemplo simples, vejamos o lançamento de uma moeda: cara (H) ou coroa (T). Sua probabilidade será o número de maneiras que um evento pode ocorrer dividido pelo número total de resultados possíveis.
- Se quisermos encontrar a probabilidade de cara, seria 1 (Cara) / 2 (Cara e Coroa) = 0.5.
- Se quisermos encontrar a probabilidade de coroa, seria 1 (Coroa) / 2 (Cara e Coroa) = 0.5.
Mas não queremos confundir verossimilhança e probabilidade – há uma diferença. Probabilidade é a medida da ocorrência de um evento ou resultado específico. A probabilidade é aplicada quando você deseja aumentar as chances de um evento ou resultado específico ocorrer.
Para decompô-lo – probabilidade é sobre resultados possíveis, enquanto probabilidade é sobre hipóteses.
Outro termo a ser conhecido é ''eventos mutuamente exclusivos''. São eventos que não ocorrem ao mesmo tempo. Por exemplo, você não pode ir para a direita e para a esquerda ao mesmo tempo. Ou, se estivermos jogando uma moeda, podemos obter cara ou coroa, não ambos.
Tipos de probabilidade
- Probabilidade Teórica: isso se concentra na probabilidade de um evento ocorrer e é baseado no fundamento do raciocínio. Usando a teoria, o resultado é o valor esperado. Usando o exemplo de cara e coroa, a probabilidade teórica de dar cara é 0.5 ou 50%.
- Probabilidade Experimental: concentra-se na frequência com que um evento ocorre durante a duração de um experimento. Usando o exemplo de cara e coroa – se lançarmos uma moeda 10 vezes e ela cair em cara 6 vezes, a probabilidade experimental de a moeda cair em cara seria 6/10 ou 60%.
A probabilidade condicional é a possibilidade de um evento/resultado ocorrer com base em um evento/resultado existente. Por exemplo, se você trabalha para uma companhia de seguros, pode querer descobrir a probabilidade de uma pessoa poder pagar seu seguro com base na condição de que ela tenha contraído um empréstimo imobiliário.
A Probabilidade Condicional ajuda os Cientistas de Dados a produzir modelos e saídas mais precisos usando outras variáveis no conjunto de dados.
Uma distribuição de probabilidade é uma função estatística que ajuda a descrever os possíveis valores e probabilidades para uma variável aleatória dentro de um determinado intervalo. O intervalo terá valores mínimos e máximos possíveis, e onde eles são plotados em um gráfico de distribuição dependem de testes estatísticos.
Dependendo do tipo de dados usados no projeto, você pode descobrir que tipo de distribuição está usando. Vou dividi-los em duas categorias: distribuição discreta e distribuição contínua.
Distribuição Discreta
A distribuição discreta é quando os dados só podem assumir determinados valores ou têm um número limitado de resultados. Por exemplo, se você rolar um dado, seus valores limitados são 1, 2, 3, 4, 5 e 6.
Existem diferentes tipos de distribuição discreta. Por exemplo:
- Distribuição uniforme discreta é quando todos os resultados são igualmente prováveis. Se usarmos o exemplo de rolar um dado de seis lados, há uma probabilidade igual de cair em 1, 2, 3, 4, 5 ou 6 – ⅙. No entanto, o problema com a distribuição uniforme discreta é que ela não nos fornece informações relevantes, que os cientistas de dados possam usar e aplicar.
- Distribuição Bernoulli é outro tipo de distribuição discreta, onde o experimento tem apenas dois resultados possíveis, sim ou não, 1 ou 2, verdadeiro ou falso. Isso pode ser usado ao jogar uma moeda, seja cara ou coroa. Ao usar a distribuição de Bernoulli, temos a probabilidade de um dos resultados (p) e podemos deduzi-la da probabilidade total (1), representada como (1-p).
- Distribuição binomial é uma sequência de eventos de Bernoulli e é a distribuição de probabilidade discreta que só pode produzir dois resultados possíveis em um experimento, sucesso ou fracasso. Ao lançar uma moeda, a probabilidade de lançar uma moeda será sempre 1.5 ou ½ em cada experimento realizado.
- Distribuição de veneno é a distribuição de quantas vezes um evento provavelmente ocorrerá em um período ou distância especificados. Em vez de se concentrar na ocorrência de um evento, ele se concentra na frequência de um evento que ocorre em um intervalo específico. Por exemplo, se 12 carros trafegam por uma determinada estrada às 11h todos os dias, podemos usar a distribuição de Poisson para descobrir quantos carros trafegam por essa estrada às 11h em um mês.
Distribuição Contínua
Ao contrário das distribuições discretas que têm resultados finitos, as distribuições contínuas têm resultados contínuos. Essas distribuições geralmente aparecem como uma curva ou uma linha em um gráfico, pois os dados são contínuos.
- Distribuição normal é aquele que você pode ter ouvido falar, pois é o mais usado. É uma distribuição simétrica dos valores em torno da média, sem inclinação. Os dados seguem uma forma de sino quando plotados, onde o intervalo médio é a média. Por exemplo, características como altura e pontuações de QI seguem uma distribuição normal.
- T-Distribuição é um tipo de distribuição contínua usada quando o desvio padrão da população (σ) é desconhecido e o tamanho da amostra é pequeno (n<30). Segue a mesma forma de uma distribuição normal, a curva de sino. Por exemplo, se estivermos olhando quantas barras de chocolate foram vendidas em um dia, usaríamos a distribuição normal. No entanto, se quisermos saber quantos foram vendidos em uma hora específica, usaremos a distribuição t.
- Distribuição exponencial é um tipo de distribuição de probabilidade contínua que se concentra na quantidade de tempo até que um evento ocorra. Por exemplo, podemos querer examinar terremotos e usar a distribuição exponencial. A quantidade de tempo, a partir deste ponto, até que ocorra um terremoto. A distribuição exponencial é plotada como uma linha curva e representa as probabilidades exponencialmente.
A partir do exposto, você pode ver como os cientistas de dados podem usar a probabilidade para entender mais sobre os dados e responder a perguntas. É muito útil para os cientistas de dados conhecer e entender as chances de um evento ocorrer e pode ser muito eficaz no processo de tomada de decisão.
Você trabalhará constantemente com dados e precisará aprender mais sobre eles antes de realizar qualquer forma de análise. Observar a distribuição de dados pode fornecer muitas informações e usar isso para ajustar sua tarefa, processo e modelo para atender à distribuição de dados.
Isso reduz o tempo gasto na compreensão dos dados, fornece um fluxo de trabalho mais eficaz e produz resultados mais precisos.
Muitos dos conceitos da ciência de dados são baseados nos fundamentos da probabilidade.
Nisha Arya é Cientista de Dados e Redator Técnico Freelance. Ela está particularmente interessada em fornecer conselhos de carreira em Ciência de Dados ou tutoriais e conhecimento baseado em teoria sobre Ciência de Dados. Ela também deseja explorar as diferentes maneiras pelas quais a Inteligência Artificial é/pode beneficiar a longevidade da vida humana. Um aprendiz interessado, buscando ampliar seus conhecimentos técnicos e habilidades de escrita, enquanto ajuda a orientar os outros.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/02/importance-probability-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-importance-of-probability-in-data-science
- 1
- 10
- 11
- a
- Capaz
- Sobre
- sobre isso
- acima
- precisão
- preciso
- conselho
- Todos os Produtos
- Permitindo
- sempre
- quantidade
- análise
- e
- Outro
- responder
- aparecer
- aplicado
- Aplicar
- por aí
- artificial
- inteligência artificial
- barras
- baseado
- antes
- atrás
- ser
- sino
- beneficiar
- Break
- ampliar
- não podes
- Oportunidades
- carros
- Categorias
- certo
- chances
- características
- chocolate
- Moeda
- Empresa
- conceitos
- condição
- condições
- confuso
- constantemente
- contínuo
- Continuum
- controlado
- curva
- dados,
- ciência de dados
- cientista de dados
- dia
- Tomada de Decisão
- descreve
- desvio
- morrem
- diferença
- diferente
- distância
- distribuição
- distribuições
- dividido
- não
- down
- durante
- cada
- terremoto
- Eficaz
- ou
- garantir
- igualmente
- Evento
- eventos
- Cada
- todo dia
- exemplo
- Exclusivo
- existente
- esperado
- experimentar
- explorar
- exponencial
- exponencialmente
- Falha
- Figura
- Encontre
- concentra-se
- focando
- seguir
- segue
- formulário
- Foundation
- freelance
- Frequência
- freqüentemente
- da
- função
- Fundamentos
- ter
- OFERTE
- dado
- Go
- gráfico
- guia
- Acontecimento
- cabeça
- cabeças
- ouviu
- altura
- ajuda
- ajuda
- House
- Como funciona o dobrador de carta de canal
- Contudo
- HTTPS
- humano
- importância
- importante
- in
- Crescimento
- INFORMAÇÕES
- com seguro
- Inteligência
- interessado
- IT
- KDnuggetsGenericName
- Afiado
- Saber
- Conhecimento
- Terreno
- aterrissagem
- APRENDER
- aprendiz
- vida
- Provável
- Limitado
- Line
- empréstimo
- longevidade
- olhar
- procurando
- lote
- muitos
- matemática
- máximo
- a medida
- Coração
- mínimo
- modelo
- modelos
- Mês
- mais
- a maioria
- você merece...
- normal
- número
- ONE
- Outros
- Outros
- Resultado
- particular
- particularmente
- Pagar
- realização
- significativo
- pessoa
- planejado
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- população
- possibilidade
- possível
- Análise Preditiva
- probabilidade
- Problema
- processo
- produzir
- projeto
- fornecer
- fornece
- fornecendo
- Frequentes
- acaso
- alcance
- reduz
- relevante
- representado
- representa
- Resultados
- estrada
- Rolo
- rolando
- mesmo
- Ciência
- Cientista
- cientistas
- busca
- Seqüência
- Shape
- simples
- Tamanho
- inclinar
- Habilidades
- pequeno
- vendido
- específico
- especificada
- gasto
- Etapa
- padrão
- Comece
- estatístico
- sucesso
- tal
- Tire
- Tarefa
- tecnologia
- Dados Técnicos:
- testes
- A
- teórico
- tempo
- vezes
- para
- lançar
- Total
- para
- verdadeiro
- tutoriais
- tipos
- tipicamente
- compreender
- compreensão
- us
- usar
- valor
- Valores
- maneiras
- O Quê
- qual
- Enquanto
- precisarão
- desejos
- dentro
- de gestão de documentos
- trabalhar
- seria
- escritor
- escrita
- investimentos
- zefirnet