Image by Editor
In the ever-evolving landscape of technology, the role of data scientists and analysts has become crucial for every organization to find data-driven insights for decision-making. Kaggle, a platform that brings together data scientists and machine learning engineers enthusiasts, becomes a central platform for improving data science and machine learning skills. As we are going into 2024, the demand for proficient data scientists continues to rise significantly, making it an opportune time to accelerate your journey in this dynamic field.
So, in this article, you will get to know the top 10 Kaggle machine-learning projects to tackle in 2024, which can help you gain practical experience in solving data science problems. By implementing these projects, you will get a comprehensive learning experience covering various aspects of data science, from data preprocessing and exploratory data analysis to advanced machine learning model development.
Let's explore the exciting world of data science together and elevate your skills to new heights in 2024.
Idea: In this project, you must implement a deep learning model that helps recognize and classify a dog's breed based on input images provided by the user in the testing environment. By exploring this classic image classification task, you will learn about one of the famous architectures of deep learning, i.e., convolutional neural networks (CNNs), and their application to real-world problems.
Dataset: Since it's a supervised problem, the dataset would consist of labeled images of various dog breeds. One of the most popular choices to implement this task is the "Stanford Dogs Dataset," freely available on Kaggle.

Image from Medium
Technologies: Based on your expertise, Python libraries and frameworks like TensorFlow or PyTorch can be used to implement this image classification task.
Implementation: Firstly, you have to preprocess the images, design a CNN architecture with different layers involved, train the model, and evaluate its performance using evaluation metrics such as accuracy and confusion matrix.
Idea: In this project, you will learn the practical aspects of deploying a machine-learning model using Gradio. This user-friendly library facilitates model deployment with almost no code requirements. This project emphasizes making machine learning models accessible through a simple interface and used in a real-time production environment.
Dataset: Based on the problem statement ranging from image classification to natural language processing tasks, you can choose the respective dataset, and accordingly, algorithm selection can be done by keeping different factors such as latency for prediction and accuracy, etc., and then deploying it.
Technologies: Gradio for deployment, along with the necessary libraries for model development (e.g., TensorFlow, PyTorch).
Implementation: Firstly, train a model, then save the weights, which are the learnable parameters that help to make the prediction, and finally integrate those with Gradio to create a simple user interface and deploy the model for interactive predictions.
Idea: In this project, you have to develop a machine learning model that helps to find the difference between real and fake news articles collected from different social media applications using natural language processing techniques. This project involves text preprocessing, feature extraction, and classification.
Dataset: Use datasets containing labeled news articles, such as the "Fake News Dataset" on Kaggle.

Image from Kaggle
Technologies: Natural Language Processing libraries like NLTK or spaCy and machine learning algorithms like Naive Bayes or deep learning models.
Implementation: You'll tokenize and clean text data, extract relevant features, train a classification model, and assess its performance using metrics like precision, recall, and F1 score.
Idea: In this project, you must build a recommendation system that automatically suggests movies or web series to users based on their past watches through the correlated platforms. Recommendation systems like Netflix and Amazon Prime are widely used in streaming media to enhance user experience.
Dataset: Commonly used datasets include MovieLens or IMDb, which contain user ratings and movie information.
Technologies: Collaborative filtering algorithms, matrix factorization, and recommendation system frameworks like Surprise or LightFM.
Implementation: You'll explore user-item interactions, build a recommendation algorithm, evaluate its performance using metrics like Mean Absolute Error, and fine-tune the model for better predictions.
Idea: In this project, you have to create a machine learning model to segment customers based on their past purchasing behavior so that when the same customer comes again, that system can recommend past things to increase sales. In this way, by utilizing segmentation, organizations can target marketing and personalized services to all customers.
Dataset: Since this is a kind of unsupervised learning problem, labels will not be required for such tasks, and you can use datasets containing customer transaction data, online retail datasets, or any e-commerce-related datasets such as from Amazon, Flipkart, etc.,
Technologies: Different clustering algorithms from the class of unsupervised machine learning algorithms, such as K-means or hierarchical clustering(either divisive or agglomerative), for segmenting customers based on their behavior.
Implementation: Firstly, you have to process the transaction data, including visualizing the data and then apply different clustering algorithms, visualize customer segments based on other clusters formed by the model, analyze the characteristics of each segment for marketing insights, and then evaluate it using different metrics such as Silhouette score, etc.
Idea: The behavior of stocks is a bit random, but by using machine learning, you can predict the approximated stock prices using historical financial data by capturing the variance in the data. This project involves time series analysis and forecasting to model the dynamics of different stock prices among multiple sectors such as Banking, Automobile, etc.
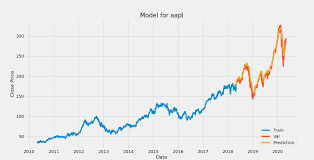
Image from Devpost
Dataset: You need the historical prices of stocks, which include Open, High, Low, Close, Volume, etc, in different time frames, including daily or minute-by-minute prices and traded quantities.
Technologies: You can use different techniques to analyze the time series models, such as Autocorrelation function and forecasting models, including Autoregressive Integrated Moving Average (ARIMA), Long Short-Term Memory (LSTM) networks, etc.
Implementation: Firstly, you have to process the time series data, including its decomposition such as cyclical, seasonal, random, etc., then choose a suitable forecasting model to train the model, and finally evaluate its performance using metrics like Mean Squared Error, Mean Absolute Error or Root Mean Squared Error.
Idea: In this project, you have to develop a model that can recognize different types of emotions in spoken languages, such as angry, happy, crazy, etc., which involves the processing of the audio data captured from various persons and applying machine learning techniques for emotion classification.
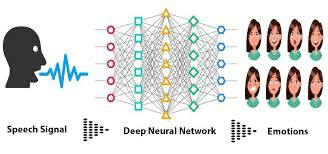
Image from Kaggle
Dataset: Utilize datasets with labeled audio clips, such as the "RAVDESS" dataset containing emotional speech recordings.
Technologies: Signal processing techniques for feature extraction deep learning models for audio analysis.
Implementation: You'll extract features from audio data, design a neural network for emotion recognition, train the model, and assess its performance using metrics like accuracy and confusion matrix.
Idea: In this project, you must build a system to predict future sales based on historical sales data. This project is essential for businesses to optimize inventory and plan for future demand.
Dataset: Historical sales data for products or services, including information on sales volume, time, and relevant factors.
Technologies: Time series forecasting methods, regression models, and machine learning frameworks.
Implementation: Firstly, you'll preprocess sales data, choose an appropriate forecasting or regression model, train the model, and evaluate its performance using metrics like Mean Squared Error or R-squared.
Idea: In this project, you must create a model to classify hand-written digits using the MNIST dataset. This project is a fundamental introduction to image classification and is often considered a starting point for those new to deep learning.
Dataset: The MNIST dataset consists of grayscale images of hand-written digits (0-9).

Image from ResearchGate
Technologies: Convolutional Neural Networks (CNNs) using frameworks such as TensorFlow or PyTorch.
Implementation: Firstly, you must preprocess the image data, design a CNN architecture, train the model, and evaluate its performance using metrics like accuracy and confusion matrix.
Idea: In this project, you have to develop a machine learning model to detect fraudulent credit card transactions, which is crucial for financial institutions to enhance security, protect users from fraudulent activities, and make the environment for different transactions very easy.
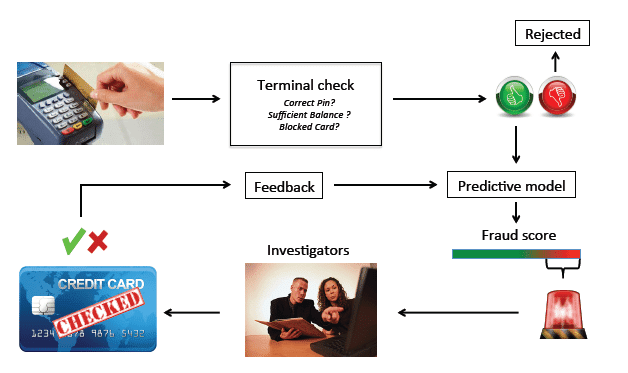
Image from ResearchGate
Dataset: Since it's a supervised learning problem, you have to collect the dataset, which contains Credit card transaction datasets with labeled cases of fraud and non-fraud transactions.
Technologies: Anomaly detection algorithms, classification models like Random Forest or Support Vector Machines, and machine learning frameworks for implementation.
Implementation: Firstly, you have to preprocess the transaction data, train a fraud detection model, tune parameters for optimal performance, and evaluate the model using classification evaluation metrics like precision, recall, and ROC-AUC.
In conclusion, exploring the Top 10 Kaggle Machine Learning Projects has been fantastic. From unraveling the mysteries of canine breeds and deploying machine learning models with Gradio to combating fake news and predicting stock prices, each project has offered a unique feature in the diversified field of data science. These projects help gain invaluable insights into solving real-world challenges.
Remember, becoming a data scientist in 2024 is not just about mastering algorithms or frameworks—it's about crafting solutions to intricate problems, understanding diverse datasets, and constantly adapting to the evolving landscape of technology. Keep exploring, stay curious, and let the insights from these projects guide you in making impactful contributions to the world of data science. Cheers to your ongoing journey in the dynamic and ever-expanding field of data science!
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/top-10-kaggle-machine-learning-projects-to-become-data-scientist-in-2024?utm_source=rss&utm_medium=rss&utm_campaign=top-10-kaggle-machine-learning-projects-to-become-data-scientist-in-2024
- :has
- :is
- :not
- 10
- 2024
- a
- About
- Absolute
- accelerate
- accessible
- accordingly
- accuracy
- activities
- advanced
- again
- algorithm
- algorithms
- All
- almost
- along
- am
- Amazon
- among
- an
- analysis
- Analysts
- analyze
- and
- any
- Application
- applications
- Apply
- Applying
- appropriate
- architecture
- ARE
- article
- articles
- AS
- aspects
- assess
- audio
- automatically
- automobile
- available
- average
- b
- Banking
- based
- BE
- become
- becomes
- becoming
- been
- behavior
- Better
- between
- Bit
- BREED
- Brings
- build
- businesses
- but
- by
- CAN
- captured
- Capturing
- card
- cases
- central
- challenges
- characteristics
- cheers
- choices
- Choose
- class
- classic
- classification
- Classify
- clean
- clips
- Close
- clustering
- CNN
- code
- collect
- combating
- comes
- commonly
- comprehensive
- conclusion
- confusion
- considered
- consists
- constantly
- contain
- contains
- continues
- contributions
- correlated
- covering
- crazy
- create
- credit
- credit card
- crucial
- curious
- Currently
- customer
- Customers
- Cyclical
- daily
- data
- data analysis
- data science
- data scientist
- data-driven
- datasets
- Decision Making
- deep
- deep learning
- Demand
- deploy
- deploying
- deployment
- Design
- detect
- Detection
- develop
- Development
- difference
- different
- digits
- directions
- diverse
- diversified
- Dog
- Dogs
- done
- dynamic
- dynamics
- e
- each
- eager
- easy
- either
- electrical engineering
- ELEVATE
- emotion
- emotions
- emphasizes
- Engineering
- Engineers
- enhance
- enthusiasts
- Environment
- error
- essential
- etc
- Ether (ETH)
- evaluate
- evaluation
- Every
- evolving
- exciting
- experience
- expertise
- Exploratory Data Analysis
- explore
- Exploring
- extract
- extraction
- f1
- facilitates
- factors
- fake
- fake news
- famous
- fantastic
- Feature
- Features
- field
- filtering
- final
- Finally
- financial
- financial data
- Financial institutions
- Find
- FLIPKART
- For
- forest
- formed
- frameworks
- fraud
- fraud detection
- fraudulent
- freely
- from
- function
- fundamental
- future
- Gain
- get
- going
- Grayscale
- guide
- happy
- Have
- he
- heights
- help
- helps
- High
- his
- historical
- HTTPS
- i
- image
- Image classification
- images
- impactful
- implement
- implementation
- implementing
- improving
- in
- include
- Including
- Increase
- information
- input
- insights
- institutions
- integrate
- integrated
- interactions
- interactive
- interest
- Interface
- into
- intricate
- Introduction
- invaluable
- inventory
- involved
- involves
- IT
- ITS
- journey
- just
- KDnuggets
- Keep
- keeping
- Kind
- Know
- Labels
- landscape
- language
- Languages
- Latency
- layers
- LEARN
- learning
- learning engineers
- let
- libraries
- Library
- lies
- like
- ll
- Long
- Low
- machine
- machine learning
- Machine Learning Techniques
- Machines
- make
- Making
- Marketing
- Mastering
- Matrix
- mean
- Media
- Memory
- methods
- Metrics
- model
- models
- more
- most
- Most Popular
- movie
- Movies
- moving
- moving average
- multiple
- must
- Natural
- Natural Language
- Natural Language Processing
- necessary
- Need
- Netflix
- network
- networks
- Neural
- neural network
- neural networks
- New
- news
- no
- of
- offered
- often
- on
- ONE
- ongoing
- online
- online retail
- open
- opportune
- optimal
- Optimize
- or
- organization
- organizations
- Other
- parameters
- past
- performance
- Personalized
- persons
- plan
- platform
- Platforms
- plato
- Plato Data Intelligence
- PlatoData
- Point
- Popular
- Practical
- Precision
- predict
- predicting
- prediction
- Predictions
- Prices
- Prime
- Problem
- problems
- process
- processing
- Production
- Products
- project
- projects
- protect
- provided
- purchasing
- Python
- pytorch
- random
- ranging
- ratings
- real
- real world
- real-time
- recognition
- recognize
- recommend
- Recommendation
- Recommendation Algorithm
- regression
- relevant
- required
- Requirements
- respective
- retail
- Rise
- Role
- root
- s
- sales
- Sales Volume
- same
- Save
- Science
- Scientist
- scientists
- score
- seasonal
- Sectors
- security
- segment
- segmentation
- segments
- selection
- Series
- Services
- short-term
- significantly
- Simple
- since
- skills
- So
- Social
- social media
- Solutions
- Solving
- speech
- spoken
- Squared
- stanford
- Starting
- Statement
- stay
- stock
- Stocks
- streaming
- Student
- such
- Suggests
- suitable
- supervised learning
- support
- surprise
- system
- Systems
- tackle
- Target
- Task
- tasks
- tech
- techniques
- Technology
- tensorflow
- Testing
- text
- that
- The
- the world
- their
- then
- These
- things
- this
- those
- Through
- time
- Time Series
- to
- together
- tokenize
- top
- Top 10
- traded
- Train
- transaction
- Transactions
- types
- understanding
- unique
- unsupervised learning
- use
- used
- User
- User Experience
- User Interface
- user-friendly
- users
- using
- utilize
- Utilizing
- various
- very
- visualize
- volume
- watches
- Way..
- we
- web
- Web development
- when
- which
- widely
- will
- with
- Work
- world
- would
- year
- you
- Your
- zephyrnet