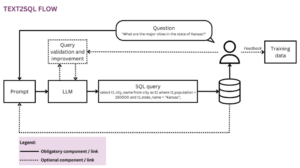
Ensemble learning is a technique used in machine learning to combine multiple models into a group model, in other words into an ensemble model. The ensemble model aims to perform better than each model alone or if not, to perform at least as well as the best individual model in the group.
In this article, you will learn popular ensemble methods: voting, bagging, boosting, and stacking along with their Python implementations. We will use libraries such as scikit-learn for voting, bagging and boosting, and mlxtend for stacking.
While following the article, I encourage you to check out the Jupyter Notebook on my GitHub for the full analysis and code. 🌻
Introduction
The intuition behind ensemble learning is often described with a phenomenon called the Wisdom of the Crowdwhich means aggregated decisions made by a group of individuals are often better than the individual decisions. There are multiple methods for creating aggregated models (or ensembles) which we can categorize as heterogenous and homogenous ensembles.
In heterogeneous ensembles, we combine multiple different fine-tuned models trained on the same dataset to generate an ensemble model. This method usually involves voting, averaging, or stacking techniques. On the other hand in homogenous ensembles, we use the same model which we call the “weak model” and with techniques such as bagging and boosting we convert this weak model to a stronger one.
Let’s start with the basic ensemble learning methods from heterogeneous ensembles: Voting and Averaging.
1. Voting (Hard Voting)
Hard voting ensemble is used for classification tasks and it combines predictions from multiple fine-tuned models that are trained on the same data based on the majority voting principle. For example, if we are ensembling 3 classifiers that have predictions as “Class A”, “Class A”, “Class B”, then the ensemble model will predict the output as “Class A” based on the majority votes, or in other words, based on the mode of the distribution of individual model predictions. As you can see, we will prefer having an odd number of individual models (e.g. 3, 5, 7 models) to be sure we will not have equal votes.
Hard Voting: New instance is predicted with multiple models and ensemble votes the final result by majority voting — Image by author
# Instantiate individual models clf_1 = KNeighborsClassifier()
clf_2 = LogisticRegression()
clf_3 = DecisionTreeClassifier() # Create voting classifier voting_ens = VotingClassifier(
estimators=[('knn', clf_1), ('lr', clf_2), ('dt', clf_3)], voting='hard') # Fit and predict with the models and ensemble
for clf in (clf_1, clf_2, clf_3, voting_ens): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
As we can see voting classifier has the highest accuracy score! Since ensemble will combine individual models predictions, each model should have been fine-tuned and already performing well. In the code above, I only initialized it for demonstrative purposes.
2. Averaging (Soft Voting)
Soft Voting is used for both classification and regression tasks and it combines predictions of multiple fine-tuned models trained on the same data by averaging them. For classification, it uses predicted probabilities and for regression, it uses predicted values. We do not need an odd number of individual models like in hard voting, but we need to have at least 2 models to build an ensemble.
Soft Voting: New instance is predicted with equally weighted models (w) and ensemble selects the final result by averaging — Image by author
One advantage of soft voting is you can decide whether if you want to average each model weighted equally (mean) or weighted by the classifier’s importance, which is an input parameter. If you prefer using a weighted average, then output predictions of the ensemble model will be the greatest sum of weighted probabilities/values.
# Instantiate individual models
reg1 = DecisionTreeRegressor()
reg2 = LinearRegression() # Create voting regressor
voting_ens = VotingRegressor(
estimators=[('dt', reg1), ('lr', reg2)], weights=[2,1]) # Fit and predict with the models and ensemble
for reg in (reg1, reg2, voting_ens): reg.fit(X_train, y_train) y_pred = reg.predict(X_test) print(reg.__class__.__name__, mean_absolute_error(y_test, y_pred))
It is important to understand that the performance of a voting ensemble (hard and soft voting)heavily depends on individual models’ performance. If we are ensembling one good and two average-performing models, then the ensemble model will show results close to the average models. In this case, we either need to improve average performing models or we shouldn’t make an ensemble and use the good-performing model instead. 📌
After understanding voting and averaging, we can continue with the last heterogeneous ensemble technique: Stacking.
3. Stacking
Stacking stands for “Stacked Generalization” and it combines multiple individual models (or base models) with a final model (or meta-model) that is trained with the predictions of base models. It can be used for both classification and regression tasks with an option to use values or probabilities for classification tasks.
The difference from voting ensembles is that in stacking meta-model is also a trainable model and in fact, it is trained using base models’ predictions. Since these predictions are input features for meta-model, they are also called meta-features. We have the option to choose between including the initial dataset to meta-features or only using the predictions.
Stacking: Base-model predictions used in training of meta-model to predict final outputs — Image by author
Stacking can be implemented with more than two layers: multi-layer stacking, where we define base models, aggregated with another layer of models, and then the final meta-model. Even though this can produce better results, we should consider the cost of time due to complexity.
To prevent overfitting, we can use stacking with cross-validation instead of standard stacking and mlxtend library has implementations for both versions. Below, I will implement:
1.Standard stacking for a classification task
from mlxtend.classifier import StackingClassifier # Initialize individual models
clf_1 = KNeighborsClassifier()
clf_2 = GaussianNB()
clf_3 = DecisionTreeClassifier() # Initialize meta-model
clf_meta = LogisticRegression() # Create stacking classifier
clf_stack = StackingClassifier(
classifiers=[clf_1, clf_2, clf_3], meta_classifier=clf_meta,
use_probas=False, use_features_in_secondary=False) # Fit and predict with the models and ensemble
for clf in (clf_1, clf_2, clf_3, clf_meta, clf_stack): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred))
Bootstrap Aggregating or in short “Bagging” aggregates multiple estimators that use the same algorithm trained with different subsets of the training data. It can be used for both classification and regression tasks, using bootstrapping to create training data for each estimator with random sampling.
Bootstrapping is a method to create samples with replacement from the original data. It is done with replacement to give equal probability to each data point for being picked. Due to selection with replacement, some data points may be picked multiple times and some may never been picked. We can calculate probability of not being picked for a data point in bootstrap sample with size n with the following formula. (preferible n is a large number).
This means that each bagging estimator is trained using around 63% of the training dataset and we call the remaining 37% out-of-bag (OOB) sample.
To sum up, bagging draws n training datasets with replacement from the original training data for n estimators. Each estimator is trained on their sampled training dataset in parallel to make predictions. Then, bagging aggregates these predictions using techniques such as hard voting or soft voting.
Bagging: Bootstrapped training samples used by estimators and predictions are combined with voting techniques — Image by author
In scikit-learn, we can define parameter n_estimators equal to n — number of estimators/models we would like to produce and oob_score can be set “True” if we would like to evaluate each estimator’s performance on their out-of-bag samples. By doing that, we can easily learn estimators’ performance on unseen data without using cross-validation or a separate test set. oob_score_ function calculates the mean of all n oob_scores using metrics accuracyscore for classification and R^2 for regression by default.
# Compare with test set
pred = clf_bagging.predict(X_test)
print(accuracy_score(y_test, pred))
accuracy_score: 0.916
Randomly sampled training datasets make the training less prone to deviations on the original data, therefore bagging reduces the variance of individual estimators.
A very popular bagging technique is random forest where the estimators are chosen as a decision tree. Random forest uses bootstrapping to create training datasets with replacement and it also selects a set of features (without replacement) to maximize the randomization on each training dataset. Usually, the number of features selected is equal to the square root of the total number of features.
5. Boosting
Boosting uses gradual learning which is an iterative process focusing on minimizing errors of the previous estimator. It is a sequential method where each estimator is dependent on the previous estimator to improve predictions. The most popular boosting methods are adaptive boosting (AdaBoost) and gradient boosting.
AdaBoost uses the entire training dataset for each n estimator with some important modifications. The first estimator (weak model) is trained on the original dataset with equally weighted data points. After the first predictions are made and error is calculated, the mispredicted data points are assigned with higher weights compared to the correctly predicted data points. By doing that next estimator will focus on these difficult-to-predict instances. This process will continue until all n estimators (say 1000) are sequentially trained. Finally, the ensemble’s prediction will be obtained with weighted majority voting or weighted averaging.
AdaBoost: Sequential model training with weight updates in the training data — Image by author
from sklearn.ensemble import AdaBoostRegressor # Initialize weak model
base_model = LinearRegression(normalize=True) # Create AdaBoost regressor
reg_adaboost = AdaBoostRegressor(base_estimator=base_model, n_estimators=1000) reg_adaboost.fit(X_train, y_train) # Predict and compare with y_test
pred = reg_adaboost.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, pred))
print('RMSE:', rmse)
RMSE: 4.18
Since every next estimator aims at correcting misclassified/miss-predicted data points, boosting reduces the bias of each estimator.
Gradient Boosting, very similar to AdaBoost, improves previous estimators with sequential iterations, but instead of updating weights of training data it fits new estimators to the residual errors from the previous estimator. XGBoost, LightGBM and CatBoost are popular gradient boosting algorithms, especially XGBoost is the winner of many competitions and popular for being very fast and scalable.
Conclusion
In this article, we have learned main ensemble learning techniques to improve model performance. We covered the theoretical background of each technique as well as relevant Python libraries to demonstrate these mechanisms.
Ensemble learning has a big portion in machine learning and it is important for every data scientist and machine learning practitioner. You may find a ton to learn, but I am sure you will never regret it!! 💯
If you need a refresher on bootstrapping or if you want to learn more about sampling techniques you can have a look at my article Resampling Methods for Inference Analysis.
I hope you enjoyed reading about ensemble learning methods and find the article useful for your analyses!