Introduction
Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation. Azure data factory helps organizations across the globe in making critical business decisions by collecting data from various sources such as e-commerce websites, supply chains, logistics, healthcare, etc., transforming that data into a usable and trusted resource using multiple operations like filtering, concatenation, sorting, etc., and loads that data into a destination store.
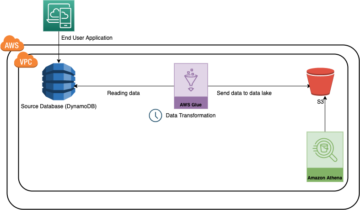
Source: https://github.com/mspnp/azure-data-factory-sqldw-elt-pipeline
Learning Objectives:
In this article, we will
1. Understand what Azure Data Factory is.
2. Gain knowledge about different types of activities supported by Azure Data Factory.
3. Look into some scenario-based questions on ADF.
4. Learn data store credentials can be secured in ADF.
5. Acknowledge the various data stores and file formats supported by Azure Data Factory.
This article was published as a part of the Data Science Blogathon.
Table of Contents
Q1. What is Azure Data Factory?
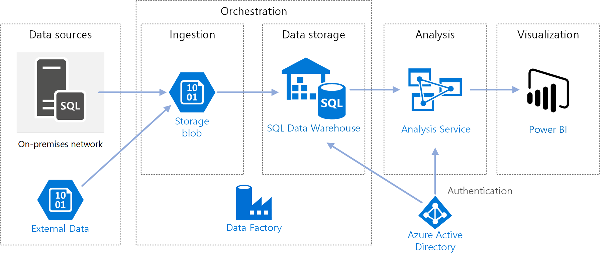
ADF is a cloud-based data ingestion and ETL (Extract, Transform, Load) Azure service.ADF helps organizations across the globe in making critical business decisions by building complex ETL processes and scheduled event-driven workflows to process data which later can be used by various reporting tools for storytelling purposes.
Source: docs.microsoft.com
Q2. How Azure Data Factory Makes the Process of Creating a Data Pipeline Easy?
ADF makes the process of creating a data pipeline easy by providing built-in connectors for data ingestion and orchestration, giving various activity options to perform operations such as copying data, for-each loop, look-up, etc., validating, publishing and monitoring pipelines, continuous integration, and continuous deployment support to the pipelines.
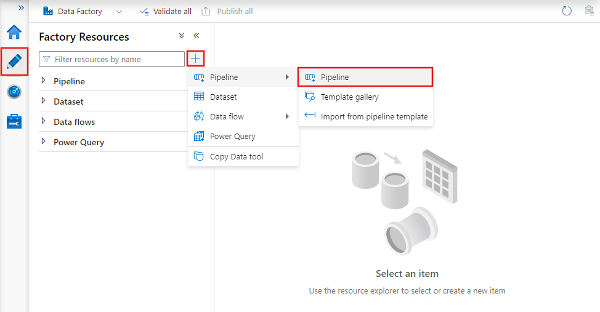
Q3. What are the Different Types of Activities Supported by Azure Data Factory?
Below are the different types of activities supported by ADF:
1. Data Movement Activities: Activities used to move data from one data source to another in a data pipeline are known as Data movement activities. For example, copy activity can be used to copy data from ADLS to Azure SQL.
2. Data Transformation Activities: Activities used to perform data transformation in a data pipeline are known as Data transformation activities. Data Flow Activity, Azure Functions Activity, Databricks Notebook Activity, etc., are examples of data transformation activities.
3. Control Activities: Activities used to build conditional, sequential, or iterative conditional logic in a data pipeline are known as control activities. Lookup Activity, Until Activity, For-Each Activity, etc., are examples of control activities.
Source: docs.microsoft.com
Q4. Solve the Project Scenario based on Question 1.
Your data team is building an ETL pipeline for a client. You want to generate output files from Azure Data Factory which are optimized for read-heavy analytical workloads and support the columnar format. What should be the file format of output files?
The generated output files should have Parquet format as Parquet stores data in columns and are optimized for read-heavy analytical workloads.
Q5. What are Annotations in Azure Data Factory?
Annotations are additional informative tags that help in filtering and searching data factory resources such as datasets, pipelines, linked services, etc. For example, if you are working as a team lead for a large data processing project for a client ABC that uses ADF containing 10 pipelines. To avoid confusion in the data processing sequence, we can label each pipeline with its primary purpose: ingest, transform, or load using annotations. When we are monitoring pipelines, these annotations must be available to perform searching, grouping, and filtering.
Q6. Solve the Project Scenario based on Question 2.
A data science company handles data processing for different clients. Your team is building an ADF pipeline to move user logs generated based on users’ activities on an e-commerce platform from an ADLS container to a database inside Azure Synapse dedicated SQL pool. The user logs are stored in container users in the following folder structure./user/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /user/2021/01/02/00/00. The latest folder is /user/2021/01/17/01/45.
How would you configure the pipeline to trigger so that existing data must be loaded every 30 minutes, and up to two minutes delay in data arrival must be included in the time at which the data should have arrived?We can configure the pipeline to trigger using a tumbling window trigger with Recurrence: 30 minutes, Start time: 2021-01-01T00:00, and Delay: 2 minutes to achieve the above scenario.
Q7. How Can Users Secure Their Data Store Credentials in ADF?
Users can secure their data store credentials in ADF by storing them in Azure Key Vault or encrypting them with certificates. Azure Key Vault is an Azure service used to securely store API keys, data store credentials, passwords, etc., to prevent unauthorized access. Developers can easily import or create keys, authorize users to access the key vault, and configure and manage the keys using Azure Key Vault.
Q8. State the Difference Between Pipeline Parameters and Variables in ADF.
Pipeline parameters are created using the “Parameters” tab in the pipeline and cannot be modified while a pipeline is running.
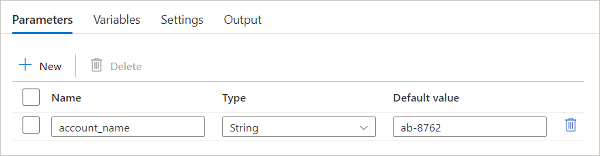
Source: learn.microsoft.com
Pipeline variables can be modified and set using Set variable activity during a pipeline run.
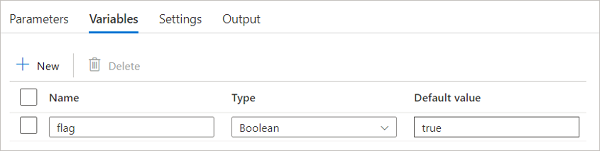
Source: learn.microsoft.com
Q9. Name Some Data Stores and File Formats Supported by Azure Data Factory.
Azure Data Factory supports various data stores such as Azure SQL, Azure Storage, Azure Databricks, HBase, Hive, Impala, MariaDB, Oracle, Cassandra, Amazon S3, MongoDB Atlas, etc. ADF supports various file formats such as Parquet, Avro, JSON, Delta, Excel, XML, Delimited text format, etc.
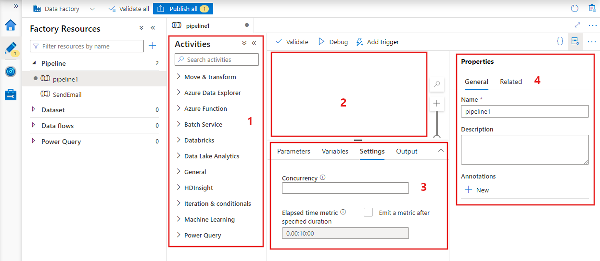
Q10. Which Activity of Azure Data Factory can be Used to Copy Data From Azure Blob Storage to Azure SQL?
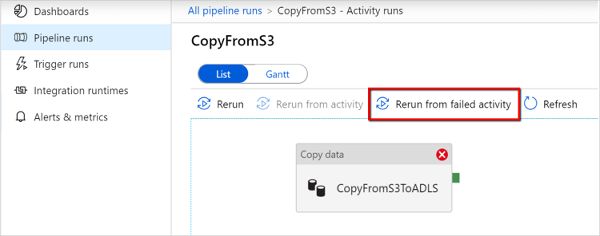
Source: learn.microsoft.com
Conclusion
Azure Data Factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) Azure service. The data-driven workflow in ADF orchestrates and automates data movement and data transformation. ADF helps developers to build complex ETL processes and scheduled event-driven workflows to process data which later can be used by various reporting tools for storytelling purposes. Below are some key points from the above article:
1. We have seen how ADF makes the process of creating a data pipeline easy.
2. We learned about approaches by which users can secure their data store credentials in ADF.
3. We have seen the differences between pipeline parameters and variables in ADF.
4. We got an understanding of how we can copy data from Azure Blob Storage to Azure SQL using ADF.
5. Apart from this, we also saw some scenario-based questions on ADF.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2023/02/most-frequently-asked-azure-data-factory-interview-questions/
- 1
- 10
- 7
- a
- ABC
- About
- above
- access
- Achieve
- across
- activities
- activity
- Additional
- Analytical
- analytics
- Analytics Vidhya
- and
- Another
- apart
- api
- approaches
- arrival
- article
- atlas
- authorize
- automates
- available
- Azure
- based
- below
- between
- build
- Building
- built-in
- business
- cannot
- certificates
- chains
- client
- clients
- Collecting
- Column
- Columns
- company
- complex
- conclusion
- confusion
- Container
- continuous
- control
- copying
- create
- created
- Creating
- Credentials
- critical
- data
- data processing
- data science
- data-driven
- Database
- Databricks
- datasets
- decisions
- dedicated
- delay
- Delta
- deployment
- destination
- developers
- difference
- differences
- different
- discretion
- during
- e-commerce
- each
- easily
- etc
- Every
- example
- examples
- Excel
- existing
- extract
- factory
- File
- Files
- filtering
- flow
- following
- format
- frequently
- from
- functions
- generate
- generated
- Giving
- globe
- Handles
- healthcare
- help
- helps
- Hive
- How
- HTTPS
- import
- in
- included
- informative
- input
- integration
- Interview
- interview questions
- Introduction
- json
- Key
- keys
- knowledge
- known
- Label
- large
- latest
- lead
- LEARN
- learned
- linked
- load
- loads
- logistics
- lookup
- MAKES
- Making
- manage
- mapping
- Media
- Microsoft
- minutes
- modified
- MongoDB
- monitoring
- most
- move
- movement
- multiple
- name
- nav
- notebook
- objectives
- ONE
- Operations
- optimized
- Options
- oracle
- orchestration
- organizations
- owned
- parameters
- part
- Passwords
- perform
- performs
- pipeline
- platform
- plato
- Plato Data Intelligence
- PlatoData
- points
- pool
- prevent
- primary
- process
- processes
- processing
- project
- providing
- published
- Publishing
- purpose
- purposes
- Q1
- Q2
- Q3
- question
- Questions
- Reporting
- resource
- Resources
- Run
- running
- scenario
- scheduled
- Science
- searching
- secure
- Secured
- securely
- Sequence
- service
- Services
- set
- should
- shown
- So
- SOLVE
- some
- Source
- Sources
- SQL
- start
- State
- storage
- store
- stored
- stores
- storytelling
- structure
- such
- supply
- Supply chains
- support
- Supported
- Supports
- Synapse
- team
- The
- The Source
- their
- time
- to
- tool
- tools
- Transform
- Transformation
- transforming
- trigger
- trusted
- types
- understanding
- User
- users
- various
- Vault
- websites
- What
- What is
- which
- while
- workflow
- workflows
- working
- would
- XML
- Your
- zephyrnet