
Summarization agents imagined by the AI image generation tool Dall-E.
Are you part of the population that leaves reviews on Google maps every time you visit to a new restaurant?
Or perhaps you are the type to share your opinion on Amazon purchases, especially when you get triggered by a low-quality product?
Don’t worry, I won’t blame you — we all have our moments!
In today’s data world, we all contribute to the data deluge in multiple ways. One data type that I find particularly interesting due to its diversity and difficulty of interpretation is textual data, such as the countless reviews that are posted over the Internet every day. Have you ever stopped to consider the importance of standardizing and condensing textual data?
Welcome to the world of summarization agents!
Summarization agents have seamlessly integrated into our daily lives condensing information and providing quick access to relevant content across a multitude of applications and platforms.
In this article, we will explore the utilization of ChatGPT as a powerful summarization agent for our custom applications. Thanks to the ability of Large Language Models (LLM) to process and understand texts, they can assist in reading texts and generating accurate summaries or standardizing information. However, it is important to know how to extract their potential in doing such a task, as well as to acknowledge their limitations.
The biggest limitation for summarization?
LLMs often fall short when it comes to adhering to specific character or word limitations in their summaries.
Let’s explore the best practices for generating summaries with ChatGPT for our custom application, as well as the reasons behind its limitations and how to overcome them!
If this in-depth educational content is useful for you, you can subscribe to our AI research mailing list to be alerted when we release new material.
Effective Summarization with ChatGPT
Summarization agents are used all over the Internet. For instance, websites use summarization agents to offer concise summaries of articles, enabling users to gain a quick overview of the news without diving into the entire content. Social media platforms and search engines do this too.
From news aggregators and social media platforms to e-commerce websites, summarization agents have become an integral part of our digital landscape. And with the raise of LLMs, some of these agents are now using AI for more effective summarization results.
ChatGPT can be a good ally when building an application using summarization agents for speeding up reading tasks and classifying texts. For example, imagine we have an e-commerce business and we are interested in processing all our customer reviews. ChatGPT could help us in summarizing any given review in a few sentences, standardizing it to a generic format, determining the sentiment of the review, and classifying it accordingly.
While it is true that we could simply feed the review to ChatGPT, there is a list of best practices — and things to avoid — to leverage the power of ChatGPT in this concrete task.
Let’s explore the options by bringing this example to life!
Example: E-commerce Reviews

Consider the example above in which we are interested in processing all the reviews for a given product on our e-commerce website. We would be interested in processing reviews such as the following one about our star product: the first computer for children!
prod_review = """ I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier than expected, so I got to play with it myself before I gave it to him. """
In this case, we would like that ChatGPT to:
- Classify the review into positive or negative.
- Provide a summary of the review of 20 words.
- Output the response with a concrete structure to standardize all the reviews into one single format.
Implementation Notes
Here is the basic code structure we could use to prompt ChatGPT from our custom application. I also provide a link to a Jupyter Notebook with all the examples used in this article.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)The function get_completion() calls the ChatGPT API with a given prompt. If the prompt contains additional user text, such as the review itself in our case, it is separated from the rest of the code by triple quotes.
Let’s use the get_completion() function to prompt ChatGPT!
Here is a prompt fulfilling the requirements described above:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)⚠️ The prompting guidelines used in this example such as using delimiters to separate the input text from the rest of the prompt and asking for a structured output are fully explained at What I Learned from OpenAI’s Course on Prompt Engineering — Prompting Guidelines.
Here is ChatGPT’s answer:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
As we can observe from the output, the review is accurate and well structured, although it misses some information we could be interested in as the owners of the e-commerce, such as information about the delivery of the product.
Summarize with a Focus on <Shipping and Delivery>
We can iteratively improve our prompt asking ChatGPT to focus on certain things in the summary. In this case, we are interested in any details given about the shipping and delivery:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)This time, ChatGPT’s answer is the following:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Now the review is much more complete. Giving details on the important focus of the original review is crucial to avoid ChatGPT skipping some information that might be valuable for our use case.
Have you noticed that although this second trial includes information on the delivery, it skipped the only negative aspect of the original review?
Let’s fix that!
“Extract” instead of “Summarize”
By investigating summarization tasks, I found out that summarization can be a tricky task for LLMs if the user prompt is not accurate enough.
When asking ChatGPT to provide a summary of a given text, it can skip information that might be relevant for us — as we have recently experienced — or it will give the same importance to all the topics in the text, only providing an overview of the main points.
Experts in LLMs use the term extract and additional information on their focuses instead of summarize when doing such tasks assisted by these types of models.
While summarization aims to provide a concise overview of the text’s main points including topics non-related to the topic of focus, information extraction focuses on retrieving specific details and can give us what we are exactly looking for. Let’s try then with extraction!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)In this case, by using extraction, we only get information about our topic of focus: Shipping: Arrived a day earlier than expected.
Automatization
This system works for one single review. Nevertheless, when designing a prompt for a concrete application, it is important to test it in a batch of examples so that we can catch any outliers or misbehavior in the model.
In case of processing multiple reviews, here is a sample Python code structure that can help.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """Here are the summaries of our batch of reviews:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Note that although the word restriction of our summaries was clear enough in our prompts, we can easily see that this word limitation is not accomplished in any of the iterations.
This mismatch in word counting happens because LLMs do not have a precise understanding of word or character count. The reason behind this relies on one of the main important components of their architecture: the tokenizer.
Tokenizer
LLMs like ChatGPT are designed to generate text based on statistical patterns learned from vast amounts of language data. While they are highly effective at generating fluent and coherent text, they lack precise control over the word count.
In the examples above, when we have given instructions about a very precise word count, ChatGPT was struggling to meet those requirements. Instead, it has generated text that is actually shorter than the specified word count.
In other cases, it may generate longer texts or simply text that is overly verbose or lacking in detail. Additionally, ChatGPT may prioritize other factors such as coherence and relevance, over strict adherence to the word count. This can result in text that is high-quality in terms of its content and coherence, but which does not precisely match the word count requirement.
The tokenizer is the key element in the architecture of ChatGPT that clearly influences the number of words in the generated output.

Tokenizer Architecture
The tokenizer is the first step in the process of text generation. It is responsible for breaking down the piece of text that we input to ChatGPT into individual elements — tokens — , which are then processed by the language model to generate new text.
When the tokenizer breaks down a piece of text into tokens, it does so based on a set of rules that are designed to identify the meaningful units of the target language. However, these rules are not always perfect, and there can be cases where the tokenizer splits or merges tokens in a way that affects the overall word count of the text.
For example, consider the following sentence: “I want to eat a peanut butter sandwich”. If the tokenizer is configured to split tokens based on spaces and punctuation, it may break this sentence down into the following tokens with a total word count of 8, equal to the token count.
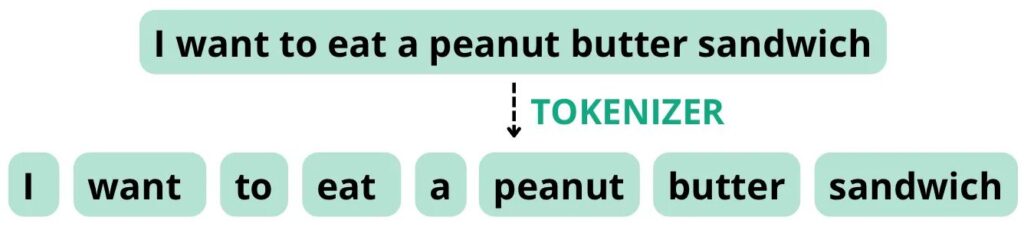
However, if the tokenizer is configured to treat “peanut butter” as a compound word, it may break the sentence down into the following tokens, with a total word count of 8, but a token count of 7.

Thus, the way the tokenizer is configured can affect the overall word count of the text, and this can impact the ability of the LLM to follow instructions about precise word counts. While some tokenizers offer options to customize how text is tokenized, this is not always sufficient to ensure precise adherence to word count requirements. For ChatGPT in this case, we cannot control this part of its architecture.
This makes ChatGPT not so good at accomplishing character or word limitations, but one can try with sentences instead since the tokenizer does not affect the number of sentences, but their length.
Being aware of this restriction can help you to build the best suitable prompt for your application in mind. Having this knowledge about how word count works on ChatGPT, let’s do a final iteration with our prompt for the e-commerce application!
Wrapping up: E-commerce Reviews
Let’s combine our learnings from this article into a final prompt! In this case, we will be asking for the results in HTML format for a nicer output:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))And here is the final output from ChatGPT:

Summary
In this article, we have discussed the best practices for using ChatGPT as a summarization agent for our custom application.
We have seen that when building an application, it is extremely difficult to come up with the perfect prompt that matches your application requirements in the first trial. I think a nice take-home message is to think about prompting as an iterative process where you refine and model your prompt until you get exactly the desired output.
By iteratively refining your prompt and applying it to a batch of examples before deploying it into production, you can make sure the output is consistent across multiple examples and cover outlier responses. In our example, it could happen that someone provides a random text instead of a review. We can instruct ChatGPT to also have a standardized output to exclude these outlier responses.
In addition, when using ChatGPT for a specific task, it is also a good practice to learn about the pros and cons of using LLMs for our target task. That is how we came across the fact that extraction tasks are more effective than summarization when we want a common human-like summary of an input text. We have also learned that providing the focus of the summary can be a game-changer regarding the generated content.
Finally, while LLMs can be highly effective at generating text, they are not ideal for following precise instructions about word count or other specific formatting requirements. To achieve these goals, it may be necessary to stick to sentence counting or use other tools or methods, such as manual editing or more specialized software.
This article was originally published on Towards Data Science and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://www.topbots.com/mastering-chatgpt-effective-summarization-with-llms/
- :has
- :is
- :not
- :where
- $UP
- 1
- 100
- 11
- 12
- 16
- 17
- 20
- 8
- 9
- a
- ability
- About
- above
- absolutely
- access
- accomplished
- accomplishing
- accurate
- Achieve
- acknowledge
- across
- active
- actually
- added
- addition
- Additional
- Additional Information
- Additionally
- affect
- Agent
- agents
- Aggregators
- AI
- ai research
- aims
- All
- Ally
- also
- Although
- always
- am
- Amazon
- amounts
- amp
- an
- and
- answer
- any
- api
- Application
- applications
- Applying
- architecture
- ARE
- article
- articles
- AS
- aspect
- aspects
- assist
- At
- author
- avoid
- aware
- back
- based
- basic
- BE
- become
- before
- behind
- below
- BEST
- best practices
- Biggest
- Bit
- bought
- Break
- Breaking
- breaks
- Bringing
- build
- Building
- built
- business
- but
- by
- call
- Calls
- came
- CAN
- cannot
- case
- cases
- Catch
- certain
- character
- characters
- ChatGPT
- Children
- clear
- clearly
- code
- COHERENT
- colorful
- combine
- come
- comes
- Common
- complete
- components
- Compound
- computer
- concise
- configured
- Cons
- Consider
- consistent
- construct
- contains
- content
- contribute
- control
- could
- counting
- course
- cover
- crucial
- custom
- customer
- customize
- daily
- dall-e
- data
- day
- Delayed
- delivery
- Department
- deploying
- described
- Design
- designed
- designing
- desired
- detail
- details
- difficult
- Difficulty
- digital
- disappointing
- discussed
- Display
- Diversity
- do
- does
- doing
- down
- due
- e-commerce
- e-commerce business
- each
- Earlier
- easily
- easy
- eat
- ecommerce
- editing
- educational
- educational games
- Effective
- element
- enabling
- engaging
- Engineering
- Engines
- enough
- ensure
- Entire
- equal
- especially
- Ether (ETH)
- EVER
- Every
- every day
- exactly
- example
- examples
- excellent
- expectations
- expected
- experience
- experienced
- explained
- explore
- Exploring
- extract
- extraction
- extremely
- fact
- factors
- Fall
- fantastic
- FAST
- Features
- feedback
- few
- final
- Find
- First
- Fix
- Focus
- focuses
- focusing
- follow
- following
- For
- format
- found
- from
- frustration
- fulfilling
- fully
- fun
- function
- Gain
- Games
- General
- generate
- generated
- generating
- generation
- get
- gif
- Give
- given
- Goals
- good
- google maps
- great
- guidelines
- Handling
- happen
- happens
- happy
- Have
- he
- help
- here
- high-quality
- highly
- him
- HOURS
- How
- How To
- However
- HTML
- HTTPS
- huge
- i
- ideal
- identify
- if
- image
- image generation
- imagine
- imagined
- Impact
- import
- importance
- important
- improve
- in
- in-depth
- included
- includes
- Including
- individual
- information
- information extraction
- input
- instance
- instead
- instructions
- integral
- integrated
- interactive
- interested
- interesting
- Interface
- Internet
- interpretation
- into
- intuitive
- IT
- iteration
- iterations
- ITS
- itself
- jpg
- json
- Key
- keys
- kids
- Know
- knowledge
- Lack
- language
- large
- LEARN
- learned
- learning
- Leverage
- like
- limitation
- limitations
- LINK
- List
- live
- Lives
- longer
- looking
- loves
- Main
- make
- MAKES
- manual
- Maps
- Mastering
- Match
- material
- max-width
- May..
- meaningful
- Media
- Meet
- merges
- message
- messages
- methods
- might
- mind
- minor
- misses
- model
- models
- more
- most
- much
- multiple
- multitude
- my
- Navigate
- necessary
- negative
- Nevertheless
- New
- news
- nice
- now
- number
- observe
- of
- offer
- often
- on
- ONE
- only
- OpenAI
- Opinion
- Options
- or
- original
- originally
- OS
- Other
- our
- out
- output
- over
- overall
- Overcome
- overview
- owners
- part
- particularly
- patterns
- perfect
- perhaps
- permission
- piece
- Plain
- Platforms
- plato
- Plato Data Intelligence
- PlatoData
- Play
- playing
- points
- population
- positive
- posted
- potential
- power
- powerful
- practice
- practices
- precise
- precisely
- Prioritize
- process
- processed
- processing
- Product
- Production
- properly
- PROS
- provide
- provides
- providing
- published
- purchased
- purchases
- Python
- Quick
- quotes
- raise
- random
- Reading
- really
- reason
- reasons
- received
- recently
- recommend
- refine
- refining
- regarding
- release
- relevance
- relevant
- requirement
- Requirements
- research
- response
- responsible
- REST
- restaurant
- restriction
- result
- Results
- return
- returns
- review
- Reviews
- right
- Role
- rules
- s
- same
- seamlessly
- Search
- Search engines
- Second
- see
- seen
- sentence
- sentiment
- separate
- set
- Share
- she
- Shipping
- Short
- sign
- Simple
- simply
- since
- single
- site
- So
- Social
- social media
- social media platforms
- Software
- some
- Someone
- son
- spaces
- specialized
- specific
- specified
- split
- Splits
- standardizing
- Star
- statistical
- Step
- Stick
- stopped
- strict
- structure
- structured
- Struggling
- such
- sufficient
- suitable
- summarize
- SUMMARY
- SWIFT
- system
- table
- Target
- Task
- tasks
- terms
- test
- text generation
- than
- thanks
- that
- The
- the information
- the world
- their
- then
- There.
- These
- they
- things
- think
- this
- those
- time
- Title
- to
- today’s
- token
- tokenized
- Tokens
- too
- took
- tool
- tools
- TOPBOTS
- topic
- Topics
- Total
- toy
- trial
- triggered
- Triple
- true
- try
- two
- type
- types
- understand
- understanding
- units
- until
- Updates
- us
- use
- used
- User
- users
- using
- Valuable
- various
- Vast
- very
- Visit
- volume
- want
- was
- Way..
- ways
- we
- Website
- websites
- WELL
- were
- What
- when
- which
- while
- will
- with
- without
- Word
- words
- Work
- works
- world
- worry
- would
- you
- Your
- zephyrnet



