As the holiday season is upon us and a Hackaday scribe sits protected from the incoming Atlantic storms in her snug eyrie, it’s time for her to consider the basics of her craft. Writing, spelling, and the English language; such matters as why Americans have different English spellings from Brits, but perhaps most important of them all for Hackaday readers; is it “gif”, or is is “jif”? This or the jokey sentence about spellings might be considered obvious clickbait, but instead they’re a handle to descend into the study of language. Just how do we decide the conventions of our language, and should we even care too much about them?
Don’t Believe Everything You Read in School

We are sent to school to Learn Stuff. During that time we are deprived of our liberty as a succession of adults attempt year after year to cram our heads with facts. Some of it we find interesting and other parts not so much, but for the majority of it, we are discouraged from thinking for ourselves and are instead expected to learn by rote a set of fixed curricula.
Thus while writers have to discover for themselves that English is a constantly evolving language through which they can break free of these artificial bounds that school has imposed upon them, far too many people remain afraid to put their head above the linguistic parapet.
The result is that perceived deviations from the rules are jumped upon by those afraid to move with the language, and we even find our own linguistic Holy Wars to fight. The one mentioned above about “gif” versus “jif” is a great example, does it really matter that much whether you pronounce it with a hard “G” because that’s how most people say it, or as though it were a “J” because the creator of the file format said it that way? Not really, because English is an evolving language in the hands of those who speak it, not those of the people who write school books.
Sadly it’s not quite time to rejoice though, because even if some of those rules can move with the times, it’s not a free for all. Language has to be mutually intelligible, we can’t simply make it up as we go along. The professionals take what they call a descriptive approach, where they tell you how you use the language, in contrast to proscribing how you should be using it. They do this through statistical analysis of large corpora, bodies of text, to see which forms are gaining the most traction. And here’s where this becomes interesting, because a large scale language analysis can tell you things you didn’t know about a subject you thought you knew a lot about.
How I Wasn’t The Inventor Of Computational Linguistics

I got my introduction to language analysis about fifteen years ago, when I was working on improving the search engine visibility of a very large website. This wasn’t the dodgy smoke-and-mirrors world of shady search engine manipulation back then, instead I was there to improve hugely upon the site’s content and in short, make it a lot more interesting for both human and search engine alike. In this endeavour a bit of text analysis is incredibly useful, and before I knew it a few simple PHP scripts for wrangling text had become a fully-fledged suite.
I had without knowing that it was already a field, invented the whole subject of computational linguistics for myself, and even though I now know that work to be laughably inefficient, it did deliver the goods and help tell me and the site owner just where they’d gone wrong.
Having got a taste for language analysis, it’s become one of those projects which has stayed with me over many years as I’ve returned to it from time to time as my interest has waxed and waned, and my original suite has grown into something much more useful. And that’s the point of writing about it here, because there’s nothing too difficult about it. If I can do it so can you, so it’s worth making a stab at describing it.
To build a corpus of text for analysis, it’s first necessary to start with some text. I was particularly interested in time-series data as much as language, so I took as my source as many RSS feeds as I could find. This provided me with a never-ending supply of new text to add to my analysis, and my workhorse has been a Raspberry Pi with a large USB hard drive which quietly spends a part of the day fetching stories and crunching them.
So faced with a newly retrieved piece of text, what’s my first step? Before anything else, to strip away extraneous HTML and website cruft, something which used to be a huge annoyance of rules until I discovered Lynx has a -dump command line option which does all the heavy lifting. Then it’s time to split it by sentence delimiters such as full stops and question marks, and split the sentences by words into an array. I can then step through it word by word, and process what I find into my data store.
How Do You Quickly Fetch One Word In A Billion?
When you have a few thousand data points, there are plenty of options when it comes to data storage. An SQL database for example is a great idea. But a corpus grows to a huge size, and quickly leaves behind normal approaches to storage. There may be some amazing piece of software capable of handling billions of word instances but I never found it, so I opted for something built into my filesystem. I would use filesystem paths as queries, creating a directory tree of words which I could query simply by typing in a path.
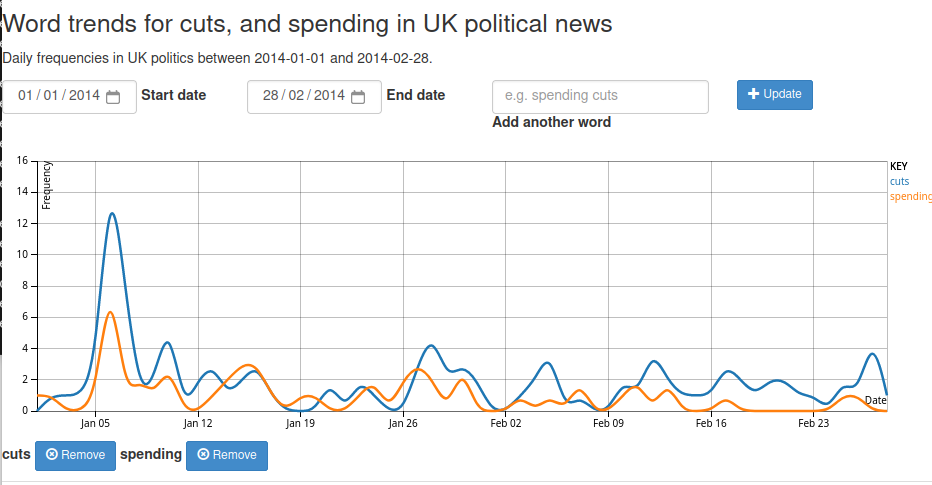
So as I step through the words in a sentence, I’m interested in their frequencies, and their collocates, i.e. the words the appear alongside. So for every word I would create a directory with a JSON file inside to record its occurrence, and within that directory I would create a subdirectory for the following word with a corresponding JSON file. Thus for example I could find the popularity of the word “Neil” by opening the JSON in the /neil/ directory, and find the prevalence of the phrase “Neil Armstrong” in /neil/armstrong/. I could also compare the relative occurrence of the Neils Armstrong and Young, by looking in both /neil/armstrong/ and /neil/young/. The nice thing about this filesystem approach is that the server-side processing script, still in PHP, was very simple, and my client could be some Javascript in the browser that would retrieve all those JSONs in real time from the filesystem.
The beauty of having billions of words of English analysis only a mouse click away is that I can very easily check which is the more appropriate version of a phrase, how popular an ephemeral phrase really is, and even the relative popularity of public figures such as politicians. It’s like having my own linguistic truth verifier without having to rely on what others tell me, which in my line of work can be very useful. It does of course come with drawbacks, for example doing any work with a tree of many millions of subdirectories and small JSON files becomes very tedious. Making a tarball of even a medium size data structure takes a couple of days, meaning moving it to a new disk requires some planning.
This may not have been the usual fare for describing a personal project on Hackaday, but it’s one which includes no less development time and technological evolution than any of my hardware work. If you’d like to follow in my footsteps then I’m afraid I’m shy of releasing my ill-formed mess of old PHP and Javascript, but given that its function is pretty well described above I think most of you could write one yourself if you turned your mind to it. Even if you don’t, I hope this has given you an insight into how a corpus analyser works and can tell you things you didn’t know, and you’ll follow my advice not to listen to everything your schoolteacher told you.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://hackaday.com/2024/01/02/its-pronounced-gif/
- :has
- :is
- :not
- :where
- $UP
- 1
- 130
- 2014
- 300
- 400
- 600
- a
- About
- about IT
- above
- add
- adults
- advice
- afraid
- After
- ago
- alike
- All
- along
- alongside
- already
- also
- amazing
- American
- Americans
- an
- analysis
- and
- any
- anything
- appear
- approach
- approaches
- appropriate
- ARE
- Armstrong
- around
- Array
- artificial
- AS
- At
- attempt
- away
- b
- back
- Basics
- BE
- Beauty
- because
- become
- becomes
- been
- before
- behind
- believe
- Billion
- billions
- Bit
- bodies
- Books
- both
- bounds
- Break
- browser
- build
- built
- but
- by
- call
- CAN
- capable
- care
- check
- classroom
- click
- clickbait
- client
- come
- comes
- compare
- computational
- Consider
- considered
- constantly
- content
- contrast
- Conventions
- Corresponding
- could
- Couple
- course
- craft
- create
- Creating
- creator
- data
- data points
- data storage
- Database
- day
- Days
- decade
- decide
- deliver
- descend
- described
- describing
- Development
- DID
- different
- difficult
- discouraged
- discover
- discovered
- do
- does
- doing
- Dont
- drawbacks
- drive
- during
- e
- Early
- easily
- else
- Engine
- English
- Even
- Every
- everything
- evolution
- evolving
- example
- expected
- faced
- facts
- far
- few
- field
- fight
- Figures
- File
- Files
- Find
- First
- fixed
- follow
- following
- For
- format
- forms
- found
- Free
- from
- full
- function
- gaining
- gif
- given
- Go
- gone
- goods
- got
- graph
- great
- grown
- Grows
- had
- handle
- Handling
- Hands
- Hard
- hard drive
- Hardware
- Have
- having
- head
- heads
- heavy
- heavy lifting
- help
- her
- here
- holding
- Holiday
- hope
- How
- HTML
- HTTPS
- huge
- Hugely
- human
- i
- idea
- if
- important
- imposed
- improve
- improving
- in
- incidents
- includes
- Incoming
- incredibly
- inefficient
- inside
- insight
- instances
- instead
- interest
- interested
- interesting
- into
- Introduction
- Invented
- IT
- ITS
- JavaScript
- jpg
- json
- just
- Know
- Knowing
- language
- large
- LEARN
- less
- Liberty
- lifting
- like
- Line
- linguistics
- little
- looking
- Lot
- lynx
- Majority
- make
- Making
- Manipulation
- many
- many people
- Matter
- Matters
- max-width
- May..
- me
- meaning
- medium
- mentioned
- might
- millions
- mind
- model
- more
- most
- mouse
- move
- moving
- much
- mutually
- my
- myself
- necessary
- never
- New
- newly
- news
- nice
- no
- normal
- nothing
- now
- obvious
- occurrence
- of
- Old
- on
- ONE
- only
- opening
- Option
- Options
- or
- original
- Other
- Others
- our
- ourselves
- over
- own
- owner
- part
- particularly
- parts
- path
- paths
- People
- perceived
- perhaps
- personal
- PHP
- picture
- piece
- planning
- plato
- Plato Data Intelligence
- PlatoData
- Plenty
- Point
- points
- Politicians
- Popular
- popularity
- pretty
- prevalence
- process
- processing
- professionals
- project
- projects
- pronounced
- protected
- provided
- public
- put
- queries
- question
- quickly
- quietly
- quite
- Raspberry
- Raspberry Pi
- Read
- readers
- real
- real-time
- really
- record
- relative
- releasing
- rely
- remain
- requires
- result
- rss
- rules
- Said
- say
- Scale
- School
- script
- scripts
- Search
- search engine
- Season
- see
- sent
- sentence
- set
- Short
- should
- Simple
- simply
- site
- sits
- Sitting
- Size
- small
- So
- Software
- some
- something
- Source
- speak
- spelling
- split
- SQL
- start
- statistical
- stayed
- Step
- Still
- Stops
- storage
- store
- Stories
- storms
- Strip
- structure
- Study
- subject
- such
- suite
- supply
- Take
- takes
- taste
- technological
- tell
- text
- than
- that
- The
- The Basics
- their
- Them
- themselves
- then
- There.
- These
- they
- thing
- things
- think
- Thinking
- this
- those
- though?
- thought
- thousand
- Through
- Thus
- time
- times
- to
- told
- too
- took
- top
- traction
- tree
- truth
- Turned
- tv
- Uk
- UK news
- until
- upon
- us
- usb
- use
- used
- using
- usual
- version
- Versus
- very
- visibility
- waned
- was
- Way..
- we
- Website
- WELL
- were
- What
- when
- whether
- which
- while
- WHO
- whole
- why
- with
- within
- without
- Word
- words
- Work
- working
- works
- world
- worth
- would
- write
- writers
- writing
- Wrong
- year
- years
- you
- young
- Your
- yourself
- zephyrnet