As Roblox has grown over the past 16+ years, so has the scale and complexity of the technical infrastructure that supports millions of immersive 3D co-experiences. The number of machines we support has more than tripled over the past two years, from approximately 36,000 as of June 30, 2021 to nearly 145,000 today. Supporting these always-on experiences for people all over the world requires more than 1,000 internal services. To help us control costs and network latency, we deploy and manage these machines as part of a custom-built and hybrid private cloud infrastructure that runs primarily on premises.
Our infrastructure currently supports more than 70 million daily active users around the world, including the creators who rely on Roblox’s economy for their businesses. All of these millions of people expect a very high level of reliability. Given the immersive nature of our experiences, there is an extremely low tolerance for lags or latency, let alone outages. Roblox is a platform for communication and connection, where people come together in immersive 3D experiences. When people are communicating as their avatars in an immersive space, even minor delays or glitches are more noticeable than they are on a text thread or a conference call.
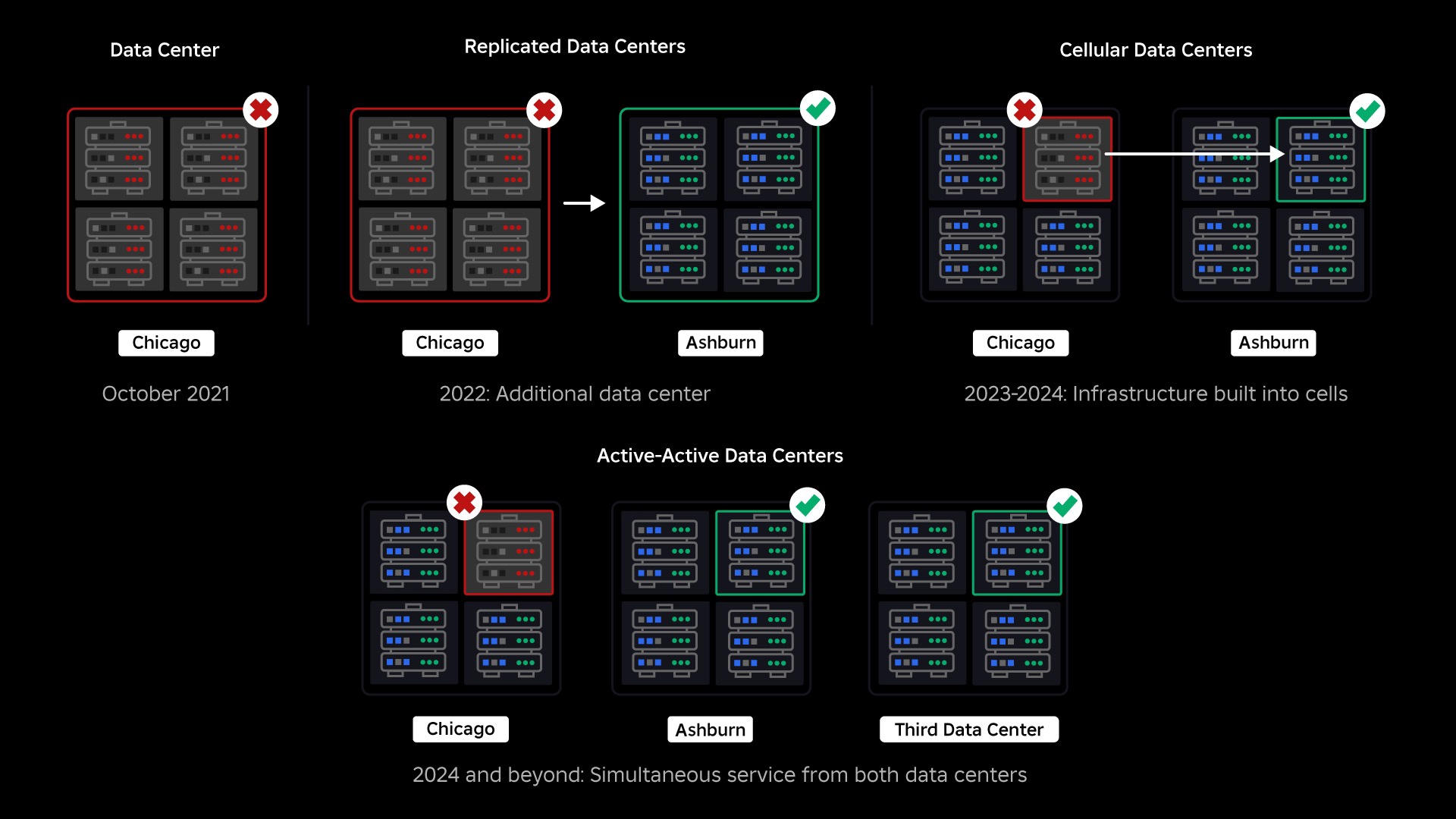
In October, 2021, we experienced a system-wide outage. It started small, with an issue in one component in one data center. But it spread quickly as we were investigating and ultimately resulted in a 73-hour outage. At the time, we shared both details about what happened and some of our early learnings from the issue. Since then, we’ve been studying those learnings and working to increase the resilience of our infrastructure to the types of failures that occur in all large-scale systems due to factors like extreme traffic spikes, weather, hardware failure, software bugs, or just humans making mistakes. When these failures occur, how do we ensure that an issue in a single component, or group of components, does not spread to the full system? This question has been our focus for the past two years and while the work is ongoing, what we’ve done so far is already paying off. For example, in the first half of 2023, we saved 125 million engagement hours per month compared to the first half of 2022. Today, we’re sharing the work we’ve already done, as well as our longer-term vision for building a more resilient infrastructure system.
Building a Backstop
Within large-scale infrastructure systems, small scale failures happen many times a day. If one machine has an issue and has to be taken out of service, that’s manageable because most companies maintain multiple instances of their back-end services. So when a single instance fails, others pick up the workload. To address these frequent failures, requests are generally set to automatically retry if they get an error.
This becomes challenging when a system or person retries too aggressively, which can become a way for those small-scale failures to propagate throughout the infrastructure to other services and systems. If the network or a user retries persistently enough, it will eventually overload every instance of that service, and potentially other systems, globally. Our 2021 outage was the result of something that’s fairly common in large scale systems: A failure starts small then propagates through the system, getting big so quickly it’s hard to resolve before everything goes down.
At the time of our outage, we had one active data center (with components within it acting as backup). We needed the ability to fail over manually to a new data center when an issue brought the existing one down. Our first priority was to ensure we had a backup deployment of Roblox, so we built that backup in a new data center, located in a different geographic region. That added protection for the worst-case scenario: an outage spreading to enough components within a data center that it becomes entirely inoperable. We now have one data center handling workloads (active) and one on standby, serving as backup (passive). Our long-term goal is to move from this active-passive configuration to an active-active configuration, in which both data centers handle workloads, with a load balancer distributing requests between them based on latency, capacity, and health. Once this is in place, we expect to have even higher reliability for all of Roblox and be able to fail over nearly instantaneously rather than over several hours. 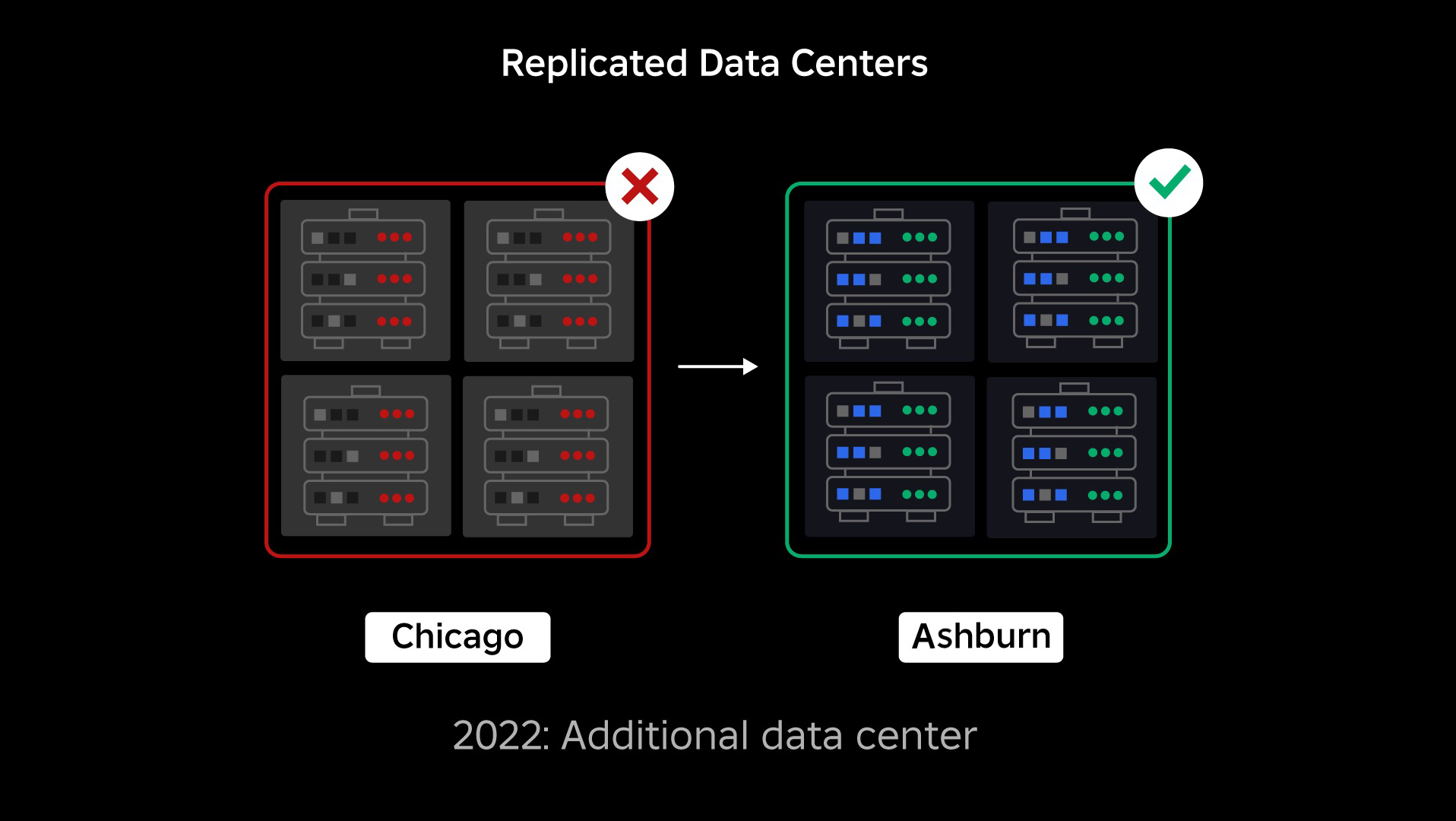
Moving to a Cellular Infrastructure
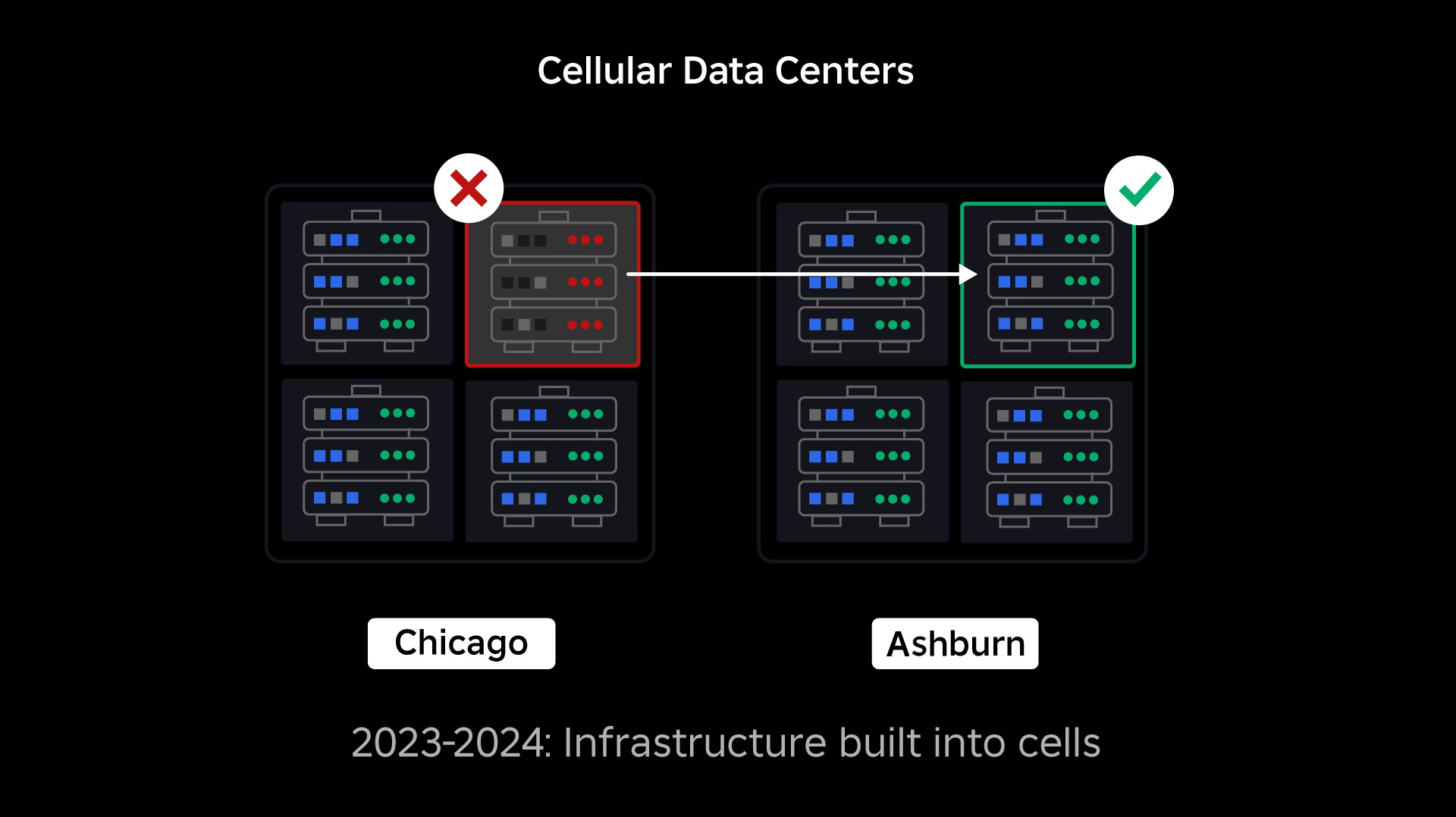
Our next priority was to create strong blast walls inside each data center to reduce the possibility of an entire data center failing. Cells (some companies call them clusters) are essentially a set of machines and are how we’re creating these walls. We replicate services both within and across cells for added redundancy. Ultimately, we want all services at Roblox to run in cells so they can benefit from both strong blast walls and redundancy. If a cell is no longer functional, it can safely be deactivated. Replication across cells enables the service to keep running while the cell is repaired. In some cases, cell repair might mean a complete reprovisioning of the cell. Across the industry, wiping and reprovisioning an individual machine, or a small set of machines, is fairly common, but doing this for an entire cell, which contains ~1,400 machines, is not.
For this to work, these cells need to be largely uniform, so we can quickly and efficiently move workloads from one cell to another. We have set certain requirements that services need to meet before they run in a cell. For example, services must be containerized, which makes them much more portable and prevents anyone from making configuration changes at the OS level. We’ve adopted an infrastructure-as-code philosophy for cells: In our source code repository, we include the definition of everything that’s in a cell so we can rebuild it quickly from scratch using automated tools.
Not all services currently meet these requirements, so we’ve worked to help service owners meet them where possible, and we’ve built new tools to make it easy to migrate services into cells when ready. For example, our new deployment tool automatically “stripes” a service deployment across cells, so service owners don’t have to think about the replication strategy. This level of rigor makes the migration process much more challenging and time consuming, but the long-term payoff will be a system where:
- It’s far easier to contain a failure and prevent it from spreading to other cells;
- Our infrastructure engineers can be more efficient and move more quickly; and
- The engineers who build the product-level services that are ultimately deployed in cells don’t need to know or worry about which cells their services are running in.
Solving Bigger Challenges
Similar to the way fire doors are used to contain flames, cells act as strong blast walls within our infrastructure to help contain whatever issue is triggering a failure within a single cell. Eventually, all of the services that make up Roblox will be redundantly deployed inside of and across cells. Once this work is complete, issues could still propagate wide enough to make an entire cell inoperable, but it would be extremely difficult for an issue to propagate beyond that cell. And if we succeed in making cells interchangeable, recovery will be significantly faster because we’ll be able to fail over to a different cell and keep the issue from impacting end users.
Where this gets tricky is separating these cells enough to reduce the opportunity to propagate errors, while keeping things performant and functional. In a complex infrastructure system, services need to communicate with each other to share queries, information, workloads, etc. As we replicate these services into cells, we need to be thoughtful about how we manage cross-communication. In an ideal world, we redirect traffic from one unhealthy cell to other healthy cells. But how do we manage a “query of death”—one that’s causing a cell to be unhealthy? If we redirect that query to another cell, it can cause that cell to become unhealthy in just the way we’re trying to avoid. We need to find mechanisms to shift “good” traffic from unhealthy cells while detecting and squelching the traffic that’s causing cells to become unhealthy.
In the short term, we have deployed copies of computing services to each compute cell so that most requests to the data center can be served by a single cell. We are also load balancing traffic across cells. Looking further out, we’ve begun building a next-generation service discovery process that will be leveraged by a service mesh, which we hope to complete in 2024. This will allow us to implement sophisticated policies that will allow cross-cell communication only when it won’t negatively impact the failover cells. Also coming in 2024 will be a method for directing dependent requests to a service version in the same cell, which will minimize cross-cell traffic and thereby reduce the risk of cross-cell propagation of failures.
At peak, more than 70 percent of our back-end service traffic is being served out of cells and we’ve learned a lot about how to create cells, but we anticipate more research and testing as we continue to migrate our services through 2024 and beyond. As we progress, these blast walls will become increasingly stronger.
Migrating an always-on infrastructure
Roblox is a global platform supporting users all over the world, so we can’t move services during off-peak or “down time,” which further complicates the process of migrating all of our machines into cells and our services to run in those cells. We have millions of always-on experiences that need to continue to be supported, even as we move the machines they run on and the services that support them. When we started this process, we didn’t have tens of thousands of machines just sitting around unused and available to migrate these workloads onto.
We did, however, have a small number of additional machines that were purchased in anticipation of future growth. To start, we built new cells using those machines, then migrated workloads to them. We value efficiency as well as reliability, so rather than going out and buying more machines once we ran out of “spare” machines we built more cells by wiping and reprovisioning the machines we’d migrated off of. We then migrated workloads onto those reprovisioned machines, and started the process all over again. This process is complex—as machines are replaced and free up to be built into cells, they are not freeing up in an ideal, orderly fashion. They are physically fragmented across data halls, leaving us to provision them in a piecemeal fashion, which requires a hardware-level defragmentation process to keep the hardware locations aligned with large-scale physical failure domains.
A portion of our infrastructure engineering team is focused on migrating existing workloads from our legacy, or “pre-cell,” environment into cells. This work will continue until we’ve migrated thousands of different infrastructure services and thousands of back-end services into newly built cells. We expect this will take all of next year and possibly into 2025, due to some complicating factors. First, this work requires robust tooling to be built. For example, we need tooling to automatically rebalance large numbers of services when we deploy a new cell—without impacting our users. We’ve also seen services that were built with assumptions about our infrastructure. We need to revise these services so they do not depend upon things that could change in the future as we move into cells. We’ve also implemented both a way to search for known design patterns that won’t work well with cellular architecture, as well as a methodical testing process for each service that’s migrated. These processes help us head off any user-facing issues caused by a service being incompatible with cells.
Today, close to 30,000 machines are being managed by cells. It’s only a fraction of our total fleet, but it’s been a very smooth transition so far with no negative player impact. Our ultimate goal is for our systems to achieve 99.99 percent user uptime every month, meaning we would disrupt no more than 0.01 percent of engagement hours. Industry-wide, downtime cannot be completely eliminated, but our goal is to reduce any Roblox downtime to a degree that it’s nearly unnoticeable.
Future-proofing as we scale
While our early efforts are proving successful, our work on cells is far from done. As Roblox continues to scale, we will keep working to improve the efficiency and resiliency of our systems through this and other technologies. As we go, the platform will become increasingly resilient to issues, and any issues that occur should become progressively less visible and disruptive to the people on our platform.
In summary, to date, we have:
- Built a second data center and successfully achieved active/passive status.
- Created cells in our active and passive data centers and successfully migrated more than 70 percent of our back-end service traffic to these cells.
- Set in place the requirements and best practices we’ll need to follow to keep all cells uniform as we continue to migrate the rest of our infrastructure.
- Kicked off a continuous process of building stronger “blast walls” between cells.
As these cells become more interchangeable, there will be less crosstalk between cells. This unlocks some very interesting opportunities for us in terms of increasing automation around monitoring, troubleshooting, and even shifting workloads automatically.
In September we also started running active/active experiments across our data centers. This is another mechanism we’re testing to improve reliability and minimize failover times. These experiments helped identify a number of system design patterns, largely around data access, that we need to rework as we push toward becoming fully active-active. Overall, the experiment was successful enough to leave it running for the traffic from a limited number of our users.
We’re excited to keep driving this work forward to bring greater efficiency and resiliency to the platform. This work on cells and active-active infrastructure, along with our other efforts, will make it possible for us to grow into a reliable, high performing utility for millions of people and to continue to scale as we work to connect a billion people in real time.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :has
- :is
- :not
- :where
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- ability
- Able
- About
- access
- Achieve
- achieved
- across
- Act
- acting
- active
- added
- Additional
- address
- adopted
- again
- aggressively
- aligned
- All
- allow
- alone
- along
- already
- also
- an
- and
- Another
- anticipate
- anticipation
- any
- anyone
- approximately
- architecture
- ARE
- around
- AS
- assumptions
- At
- Automated
- automatically
- Automation
- available
- Avatars
- avoid
- Back-end
- Backup
- balancer
- balancing
- based
- BE
- because
- become
- becomes
- becoming
- been
- before
- begun
- being
- benefit
- BEST
- best practices
- between
- Beyond
- Big
- bigger
- Billion
- Blog
- both
- bring
- brought
- bugs
- build
- Building
- built
- businesses
- but
- Buying
- by
- call
- CAN
- cannot
- Capacity
- cases
- Cause
- caused
- causing
- cell
- Cells
- cellular
- Center
- Centers
- certain
- challenging
- change
- Changes
- Close
- Cloud
- cloud infrastructure
- code
- come
- coming
- Common
- communicate
- communicating
- Communication
- Companies
- compared
- complete
- completely
- complex
- complexity
- component
- components
- Compute
- computing
- Conference
- Configuration
- Connect
- connection
- contain
- contains
- continue
- continues
- continuous
- control
- copies
- Costs
- could
- create
- Creating
- creators
- Currently
- Custom-built
- daily
- data
- data access
- Data Center
- data centers
- Date
- day
- definition
- Degree
- delays
- depend
- dependent
- deploy
- deployed
- deployment
- Design
- design patterns
- DID
- different
- difficult
- directing
- discovery
- Disrupt
- disruptive
- distributing
- do
- does
- doing
- domains
- done
- Dont
- doors
- down
- downtime
- driving
- due
- during
- each
- Early
- easier
- easy
- efficiency
- efficient
- efficiently
- efforts
- eliminated
- enables
- end
- engagement
- Engineering
- Engineers
- enough
- ensure
- Entire
- entirely
- Environment
- error
- Errors
- essentially
- etc
- Even
- eventually
- Every
- everything
- example
- excited
- existing
- expect
- experienced
- Experiences
- experiment
- experiments
- extreme
- extremely
- factors
- FAIL
- failing
- fails
- Failure
- failures
- fairly
- far
- Fashion
- faster
- Find
- Fire
- First
- FLEET
- Focus
- focused
- follow
- For
- Forward
- fraction
- fragmented
- Free
- frequent
- from
- full
- fully
- functional
- further
- future
- future growth
- generally
- geographic
- get
- getting
- given
- Global
- Globally
- Go
- goal
- Goes
- going
- greater
- Group
- Grow
- grown
- Growth
- had
- Half
- handle
- Handling
- happen
- Hard
- Hardware
- Have
- head
- Health
- healthy
- help
- helped
- High
- higher
- hope
- HOURS
- How
- How To
- However
- HTTPS
- Humans
- Hybrid
- ideal
- identify
- if
- immersive
- Impact
- impacting
- implement
- implemented
- improve
- in
- include
- Including
- incompatible
- Increase
- increasing
- increasingly
- individual
- industry
- information
- Infrastructure
- inside
- instance
- instances
- instantaneously
- interesting
- internal
- into
- issue
- issues
- IT
- june
- just
- Keep
- keeping
- Know
- known
- large
- large-scale
- largely
- Latency
- learned
- Leave
- leaving
- Legacy
- less
- let
- Level
- leveraged
- like
- Limited
- load
- located
- locations
- long-term
- longer
- looking
- Lot
- Low
- machine
- Machines
- maintain
- make
- MAKES
- Making
- manage
- managed
- manually
- many
- max-width
- mean
- meaning
- mechanism
- mechanisms
- Meet
- mesh
- method
- methodical
- might
- migrate
- migrated
- migrating
- migration
- million
- millions
- minimize
- minor
- mistakes
- monitoring
- Month
- more
- more efficient
- most
- move
- much
- multiple
- must
- Nature
- nearly
- Need
- needed
- negative
- negatively
- network
- New
- newly
- next
- next-generation
- no
- now
- number
- numbers
- occur
- october
- of
- off
- on
- once
- ONE
- ongoing
- only
- opportunities
- Opportunity
- or
- OS
- Other
- Others
- our
- out
- outage
- Outages
- over
- overall
- owners
- part
- passive
- past
- patterns
- paying
- Peak
- People
- per
- percent
- performing
- persistently
- person
- philosophy
- physical
- Physically
- pick
- Place
- platform
- plato
- Plato Data Intelligence
- PlatoData
- player
- policies
- portable
- portion
- possibility
- possible
- possibly
- potentially
- practices
- prevent
- prevents
- primarily
- priority
- private
- process
- processes
- Progress
- progressively
- propagation
- protection
- proving
- provision
- purchased
- Push
- queries
- question
- quickly
- rather
- ready
- real
- real-time
- rebalance
- recovery
- redirect
- reduce
- region
- reliability
- reliable
- rely
- repair
- replaced
- replication
- repository
- requests
- Requirements
- requires
- research
- resilience
- resilient
- resolve
- REST
- result
- resulted
- revise
- Risk
- Roblox
- robust
- Run
- running
- runs
- safely
- same
- saved
- Scale
- scenario
- scratch
- Search
- Second
- seen
- separating
- September
- served
- service
- Services
- serving
- set
- several
- Share
- shared
- sharing
- shift
- SHIFTING
- Short
- should
- significantly
- since
- single
- Sitting
- small
- smooth
- So
- so Far
- Software
- some
- something
- sophisticated
- Source
- source code
- Space
- spikes
- spread
- Spreading
- start
- started
- starts
- Status
- Still
- Strategy
- strong
- stronger
- Studying
- succeed
- successful
- Successfully
- SUMMARY
- support
- Supported
- Supporting
- Supports
- system
- Systems
- Take
- taken
- team
- Technical
- Technologies
- tens
- term
- terms
- Testing
- text
- than
- that
- The
- The Future
- the world
- their
- Them
- then
- There.
- thereby
- These
- they
- things
- think
- this
- those
- thousands
- Through
- throughout
- time
- times
- to
- today
- together
- tolerance
- too
- tool
- tools
- Total
- toward
- traffic
- transition
- triggering
- trying
- two
- types
- ultimate
- Ultimately
- unlocks
- until
- unused
- upon
- uptime
- us
- used
- User
- users
- using
- utility
- value
- version
- very
- visible
- vision
- want
- was
- Way..
- we
- Weather
- WELL
- were
- What
- whatever
- when
- which
- while
- WHO
- wide
- will
- wiping
- with
- within
- Work
- worked
- working
- world
- worry
- would
- year
- years
- zephyrnet