
Financial Services clients are increasingly looking to modernize their applications. This includes modernization of code development and maintenance (helping with scarce skills and allowing innovation and new technologies required by end users) as well as improvement of deployment and operations, using agile techniques and DevSecOps.
As part of their modernization journey, clients want to have flexibility to determine what is the best “fit for purpose” deployment location for their applications. This may be in any of the environments that Hybrid Cloud supports (on premises, on a private cloud, on a public cloud or on the edge). IBM Cloud Satellite® fulfills this requirement by allowing modern, cloud-native applications to run anywhere the client requires while maintaining a standard and consistent control plane for the administration of applications across the hybrid cloud.
Moreover, many of these financial services applications support regulated workloads, which require strict levels of security and compliance, including Zero Trust protection of the workloads. IBM Cloud for Financial Services fulfills that requirement by providing an end-to-end security and compliance framework that can be used to implement and/or modernize applications securely across the hybrid cloud.
In this paper, we showcase how to easily deploy a banking application on both IBM Cloud for Financial Services and Satellite, using automated CI/CD/CC pipelines in a common and consistent manner. This requires a deep level of security and compliance throughout the entire build and deployment process.
Introduction to concepts and products
The purpose of IBM Cloud for Financial Services is to provide security and compliance for financial services companies. It does so by leveraging industry standards like NIST 800-53 and the expertise of more than a hundred financial services clients who are part of the Financial Services Cloud Council. It provides a control framework that can be easily implemented by using Reference Architectures, Validated Cloud Services and ISVs, as well as the highest levels of encryption and continuous compliance (CC) across the hybrid cloud.
IBM Cloud Satellite provides a true hybrid cloud experience. Satellite allows workloads to be run anywhere without compromising security. A single pane of glass grants the ease of seeing all resources in one dashboard. To deploy applications onto these varying environments, we have developed a set of robust DevSecOps toolchains to build applications, deploy them to a Satellite location in a secure and consistent manner and monitor the environment using the best DevOps practices.
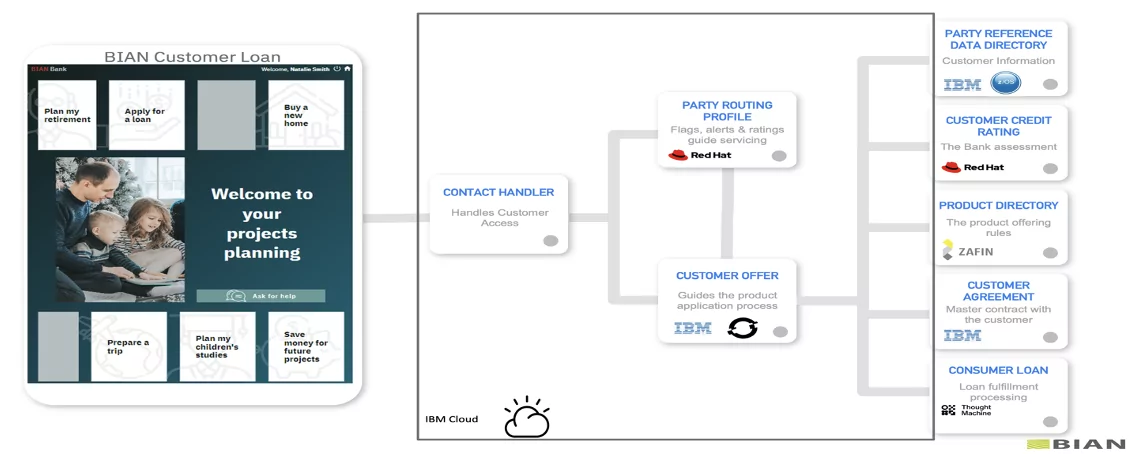
In this project, we used a loan origination application that was modernized to use Kubernetes and microservices. To deliver this service, the bank application employs an ecosystem of partner applications interoperating using the BIAN framework.
Application overview
The application used in this project is a loan origination application developed as part of the BIAN Coreless 2.0 initiative. A customer obtains a personalized loan through a safe and secure online channel offered by a bank. The application employs an ecosystem of partner applications interoperating on the BIAN architecture, which is deployed on the IBM Cloud for Financial Services. BIAN Coreless Initiative empowers financial institutions to select the best partners to help bring new services to market quickly and efficiently through BIAN architectures. Each component or BIAN Service Domain is implemented through a microservice, which is deployed on an OCP cluster on IBM Cloud.
Application Components based on BIAN Service Domains
- Product Directory: Maintains a comprehensive directory of the bank’s products and services.
- Consumer Loan: Handles the fulfillment of a consumer loan product. This includes the initial set-up of the loan facility and the completion of scheduled and ad-hoc product processing tasks.
- Customer Offer Process/API: Orchestrates the processing of a product offer for a new or established customer.
- Party Routing Profile: Maintains a small profile of key indicators for a customer that is referenced during customer interactions to facilitate routing, servicing and product/service fulfillment decisions.
Deployment process overview
An agile DevSecOps workflow was used to complete the deployments across the hybrid cloud. DevSecOps workflows focus on a frequent and reliable software delivery process. The methodology is iterative rather than linear, which allows DevOps teams to write code, integrate it, run tests, deliver releases and deploy changes collaboratively and in real-time while keeping security and compliance in check.
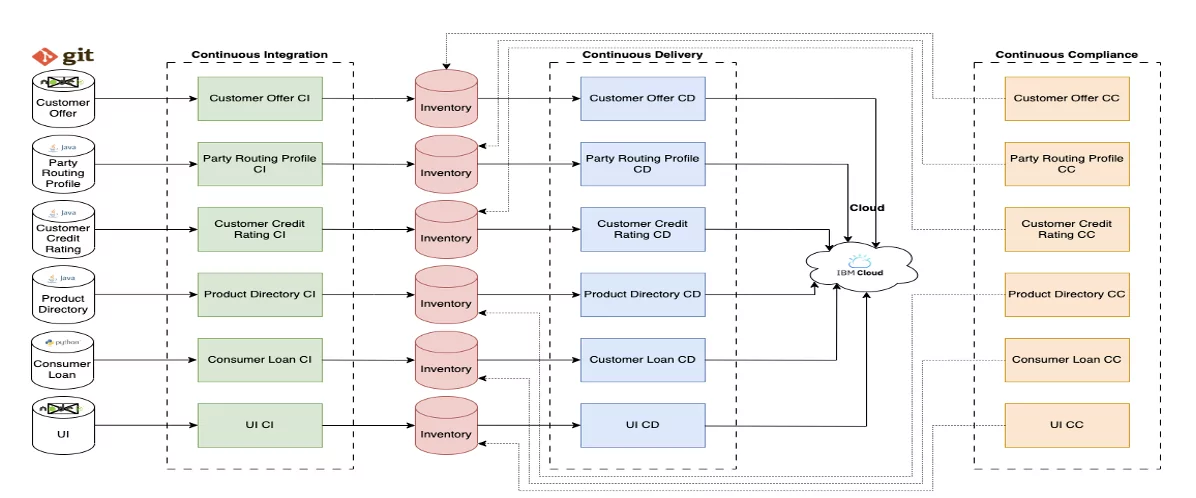
The IBM Cloud for Financial Services deployment was achieved in a secure landing zone cluster, and infrastructure deployment is also automated using policy as code (terraform). The application is comprised of various components. Each component was deployed using its own Continuous integration (CI), Continuous Delivery (CD) and Continuous Compliance (CC) pipeline on a RedHat OpenShift Cluster. To achieve the deployment on Satellite the CI/CC pipelines were reused, and a new CD pipeline was created.
Continuous integration
Each component of the IBM Cloud deployment had its own CI pipeline. A set of recommended procedures and approaches are included in the CI toolchain. A static code scanner is used to inspect the application repository for any secrets stored in the application source code, as well as any vulnerable packages used as dependencies within the application’s code. For each Git commit, a container image is created, and a tag is assigned to the image based on the build number, timestamp and commit ID. This tagging system ensures the image’s traceability. Prior to creating the image, the Dockerfile is tested. The created image is saved in a private image registry. The access privileges for the target cluster deployment are automatically configured using API tokens, which can be revoked. A security vulnerability scan is performed on the container image. A Docker signature is applied upon successful completion. The addition of the created image tag instantly updates the deployment record. The use of an explicit namespace within a cluster serves the purpose of isolating each deployment. Any code that is merged into the specified branch of the Git repository, expressly for deployment on the Kubernetes cluster, is automatically constructed, verified and implemented.
Details of each docker image is stored in an inventory repository, which is explained in detail in the Continuous Deployment section of this blog. In addition, evidence is gathered throughout every pipeline run. This evidence describes what tasks were carried out in the toolchain, such as vulnerability scans and unit tests. This evidence is stored in a git repository and a cloud object storage bucket, so that it can be audited if necessary.
We reused the current CI toolchains used for the IBM Cloud deployment stated above for the Satellite deployment. Because the application remained unchanged, it was unnecessary to rebuild the CI pipelines for the new deployment.
Continuous Deployment
The inventory serves as the source of truth regarding what artifacts are deployed in what environment/region; this is achieved using git branches to represent environments, with a promotion pipeline updating environments in a GitOps-based approach. In previous deployments, the inventory also hosted deployment files; these are the YAML Kubernetes resource files that describe each component. These deployment files would be updated with the correct namespace descriptors, along with the newest version of the Docker image for each component.
However, we found this approach difficult for a few reasons. From the applications’ perspective, having to change so many image tag values and namespaces using YAML replacement tools (such as YQ) was crude and complicated. For Satellite itself, we are using the direct upload strategy, with each YAML file provided counting as a “version”. We would prefer to have a version correspond to the entire application, not just one component or microservice.
A different approach was desired, so we rearchitected the deployment process to use a Helm chart instead. This allowed us to parametrize the important values, such as namespaces and image tags, and inject them in at deployment time. Using these variables takes out a lot of the difficulty associated with parsing YAML files for a given value. The helm chart was created separately and stored in the same container registry as the built BIAN images. We are currently working to develop a specific CI pipeline for validating helm charts; this will lint the chart, package it, sign it for veracity (this would be verified at deployment time) and store the chart. For now, these steps are done manually to develop the chart. There is one issue with using helm charts and Satellite configurations together: helm functionality requires a direct connection with a Kubernetes or OpenShift cluster to operate most effectively, and Satellite, of course, will not allow that. So, to solve this problem, we use the “helm template” to output the correctly formatted chart and then pass the resulting YAML file to the Satellite upload function. This function then leverages the IBM Cloud Satellite CLI to create a configuration version containing the application YAML. There are some drawbacks here: we cannot use some useful functionality Helm provides, such as the ability to rollback to a previous chart version and the tests that can be done to ensure the application is functioning correctly. However, we can use the Satellite rollback mechanism as a replacement and use its versioning as a basis for this.
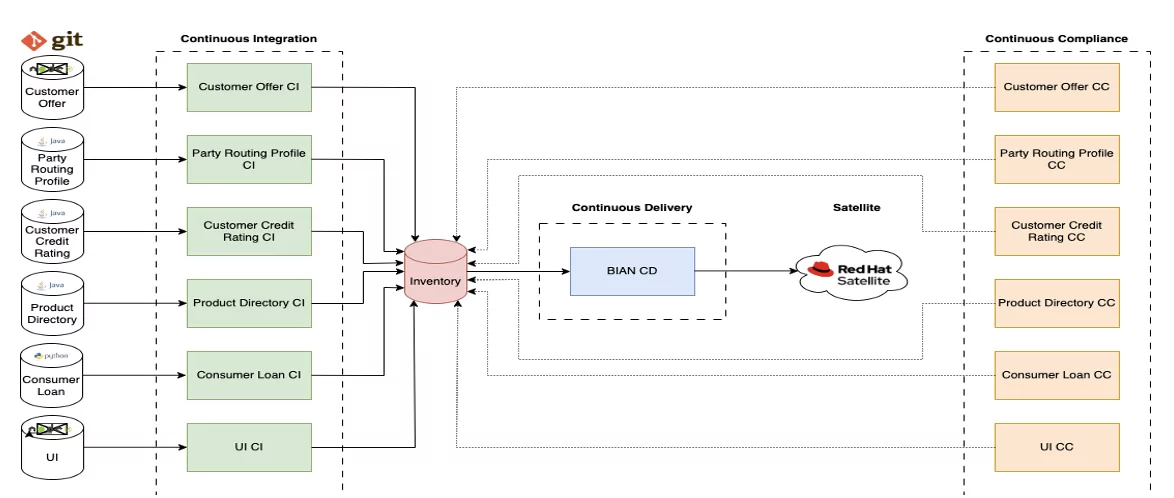
Continuous Compliance
The CC pipeline is important for continuous scanning of deployed artifacts and repositories. The value here is in finding newly reported vulnerabilities that may have been discovered after the application has been deployed. The latest definitions of vulnerabilities from organizations such as Snyk and the CVE Program are used to track these new issues. The CC toolchain runs a static code scanner at user-defined intervals on the application repositories that are provided to detect secrets in the application source code and vulnerabilities in application dependencies.
The pipeline also scans container images for security vulnerabilities. Any incident issue that is found during the scan or updated is marked with a due date. Evidence is created and stored in IBM Cloud Object Storage at the end of every run that summarizes the details of the scan.
DevOps Insights is valuable to keep track of issues and the overall security posture of your application. This tool contains all the metrics from previous toolchain runs across all three systems: continuous integration, deployment and compliance. Any scan or test result is uploaded to that system, and over time, you can observe how your security posture is evolving.
Getting CC in a cloud environment is significant for highly regulated industries like financial services that want to protect customer and application data. In the past, this process was hard and had to be done by hand, which puts organizations at risk. But with IBM Cloud Security and Compliance Center, you can add daily, automatic compliance checks to your development lifecycle to help reduce this risk. These checks include various assessments of DevSecOps toolchains to ensure security and compliance.

Based on our experience with this project and other similar projects, we created a set of best practices to help teams implement hybrid cloud solutions for IBM Cloud for Financial Services and IBM Cloud Satellite:
- Continuous Integration
- Maintain a common script library for similar applications in different toolchains. This is the set of instructions determining what your CI toolchain should do. For example, the build process for NodeJS applications will generally follow the same structure, so it makes sense to keep a scripting library in a separate repository, which the toolchains will refer to when building applications. This allows for a consistent approach to CI, promotes reuse and increases maintainability.
- Alternatively, CI toolchains can be reused for similar applications with the use of triggers; these separate triggers can be used to specify what application is to be built, where the code for the application is and other customizations.
- Continuous Deployment
- For multi-component applications, maintain a single inventory and, thus, a single deployment toolchain to deploy all components listed in the inventory. This prevents a lot of repetition. Kubernetes YAML deployment files all have the same deployment mechanism, so a singular toolchain iterating over each in turn is more logical than maintaining multiple CD toolchains, all of which are essentially doing the same thing. Maintainability has increased, and there is less work to do to deploy the application. Triggers can still be used to deploy individual microservices, if desired.
- Use Helm charts for complex multi-component applications. The use of Helm in the BIAN project made deployment much easier. Kubernetes files are written in YAML, and using bash-based text parsers is cumbersome if multiple values need to be customized at deployment time. Helm simplifies this by using variables, which makes substitution of values much more effective. In addition, Helm offers other features, such as whole-application versioning, chart versioning, registry storage of deployment configuration and rollback capabilities in the event of failure. While rollback won’t work on Satellite-specific deployments, this is catered to by Satellite configuration versioning.
- Continuous Compliance
- We strongly recommend setting up CC toolchains as part of your infrastructure to continually scan code and artifacts for vulnerabilities that are newly exposed. Typically, these scans can be run nightly or on whatever schedule suits your application and security situation. To keep track of issues and the overall security posture of your application, we suggest you use DevOps Insights.
- We also recommend the use of the Security and Compliance Center (SCC) to automate your security posture. The evidence summary generated by the pipelines can be uploaded to the SCC, where each entry in the evidence summary is treated as a “fact” related to a task completed in a toolchain, be that a vulnerability scan, unit test or other things the like. The SCC will then run validation tests against the evidence to determine that best practices related to toolchains are being followed.
- Inventory
- As previously mentioned, with continuous deployment, it is preferable to maintain a single application inventory in which all your microservice details will be stored, along with (if not using Helm) Kubernetes deployment files. This allows for a single source of truth regarding the state of your deployments; as branches in your inventory represent environments, maintaining these environments across multiple inventory repositories can become cumbersome very quickly.
- Evidence
- The approach to evidence repositories should be treated differently from the inventory. In this case, one evidence repository per component is preferable; if you combine them, the stored evidence can become overwhelming and difficult to manage. Locating specific pieces of evidence is much more efficient if the evidence is stored in a repository specific to a component. For deployment, a single evidence locker is acceptable, as it is sourced from a single deployment toolchain.
- We strongly recommend storing evidence in a cloud object storage bucket as well as using the default git repository option. This is because a COS bucket can be configured to be immutable, which allows us to securely store the evidence without the possibility of tampering, which is very important in the case of audit trails.
Conclusion
In this blog, we showcased our experience implementing a banking application based on BIAN across the hybrid cloud, that is, using DevSecOps pipelines to deploy the workload both on IBM Cloud as well as in a Satellite environment. We discussed the pros and cons of different approaches and the best practices we derived after going through this project. We hope this can help other teams achieve their hybrid cloud journey with more consistency and speed. Let us know your thoughts.
Explore what IBM has to offer todayMore from Cloud




IBM Newsletters
Get our newsletters and topic updates that deliver the latest thought leadership and insights on emerging trends.Subscribe now More newsletters
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.ibm.com/blog/best-practices-for-hybrid-cloud-banking-applications-secure-and-compliant-deployment-across-ibm-cloud-and-satellite/
- :has
- :is
- :not
- :where
- $UP
- 1
- 13
- 14
- 20
- 2023
- 28
- 29
- 30
- 300
- 31
- 33
- 35%
- 39
- 400
- 41
- 46
- 87
- 9
- a
- ability
- above
- acceptable
- access
- Achieve
- achieved
- across
- actually
- add
- addition
- administration
- advancements
- Advertising
- African
- After
- against
- agile
- ahead
- AI
- All
- allow
- allowed
- Allowing
- allows
- along
- also
- American
- amp
- an
- analytics
- and
- and infrastructure
- any
- anywhere
- api
- Application
- applications
- applied
- approach
- approaches
- architecture
- ARE
- article
- AS
- assessments
- assigned
- associated
- At
- audit
- audited
- author
- automate
- Automated
- Automatic
- automatically
- available
- away
- back
- Bank
- Banking
- based
- basis
- BE
- because
- become
- been
- being
- benefits
- BEST
- best practices
- BIAN
- Blog
- Blue
- both
- Branch
- branches
- bring
- build
- Building
- built
- business
- Business Leaders
- Business Transformation
- businesses
- but
- button
- by
- camera
- CAN
- cannot
- capabilities
- carbon
- card
- Cards
- carried
- case
- CAT
- Category
- CD
- Center
- challenges
- change
- Changes
- Channel
- Chart
- Charts
- check
- Checks
- circles
- class
- clear
- client
- clients
- Cloud
- cloud banking
- Cloud Security
- cloud services
- Cluster
- code
- color
- combine
- comes
- commit
- Common
- Companies
- complete
- Completed
- completion
- complex
- compliance
- compliant
- complicated
- component
- components
- comprehensive
- Comprised
- compromising
- computer
- Concentrated
- concept
- concepts
- Configuration
- configured
- Connect
- connection
- Cons
- consistent
- consumer
- Consumers
- Container
- contains
- continually
- continue
- continuous
- control
- Core
- correct
- correctly
- cos
- Council
- counting
- course
- create
- created
- Creating
- crucial
- crude
- CSS
- cumbersome
- Current
- Currently
- curve
- custom
- customer
- customized
- daily
- dashboard
- data
- data storage
- Date
- decisions
- deep
- Default
- definitions
- deliver
- delivering
- delivery
- dependencies
- deploy
- deployed
- deployment
- deployments
- Derived
- describe
- description
- desired
- desk
- detail
- details
- detect
- Determine
- determining
- develop
- developed
- Developer
- developers
- Development
- DevOps
- difference
- different
- differently
- difficult
- Difficulty
- digital
- digital services
- digitally
- direct
- discovered
- discussed
- do
- Docker
- does
- doing
- domain
- done
- drawbacks
- drive
- drives
- due
- during
- each
- ease
- easier
- easily
- Economic
- ecosystem
- Edge
- Effective
- effectively
- efficient
- efficiently
- emerging
- employs
- empowers
- encryption
- end
- end-to-end
- engineer
- enjoy
- ensure
- ensures
- Enter
- Enterprise
- enterprises
- Entire
- entry
- Environment
- environments
- essential
- essentially
- established
- Ether (ETH)
- Event
- Every
- evidence
- evolving
- example
- Exit
- experience
- expertise
- explained
- exposed
- express
- expressly
- Face
- faced
- facilitate
- Facility
- Failure
- false
- faster
- fastest
- Features
- few
- File
- Files
- financial
- Financial institutions
- financial services
- finding
- Flexibility
- Focus
- follow
- followed
- fonts
- For
- found
- Foundation
- Framework
- frequent
- from
- Fuel
- fulfillment
- fully
- function
- functionality
- functioning
- gathered
- generally
- generated
- generative
- Generative AI
- generator
- get
- Git
- given
- glass
- glasses
- Global
- going
- grants
- Grid
- grown
- had
- hand
- Handles
- Hard
- Have
- having
- Heading
- height
- help
- helping
- here
- highest
- Highlight
- highly
- Home
- hope
- hosted
- How
- How To
- However
- HTTPS
- hundred
- Hybrid
- hybrid cloud
- IBM
- IBM Cloud
- ICO
- ICON
- ID
- if
- image
- images
- immutable
- implement
- implemented
- implementing
- important
- improvement
- in
- incident
- include
- included
- includes
- Including
- increased
- Increases
- increasingly
- index
- Indicators
- individual
- industries
- industry
- industry standards
- Infrastructure
- initial
- Initiative
- inject
- Innovation
- insight
- insights
- instantly
- instead
- Institute
- institutions
- instructions
- integrate
- Integrating
- integration
- interactions
- interoperating
- into
- intrinsic
- Introduction
- inventory
- issue
- issues
- IT
- IT Support
- ITS
- itself
- Java
- Jennifer
- journey
- jpg
- just
- just one
- kafka
- Keep
- keeping
- Key
- Know
- Kubernetes
- labor
- Lack
- landing
- landscape
- large
- latest
- leaders
- Leadership
- leading
- less
- let
- Level
- levels
- leverages
- leveraging
- Library
- lifecycle
- like
- Listed
- loan
- local
- locale
- locating
- location
- Locker
- logical
- Look
- looking
- Lot
- made
- maintain
- maintaining
- maintains
- maintenance
- MAKES
- manage
- managed
- management
- manner
- manually
- many
- marked
- Market
- max-width
- May..
- mechanism
- Memory
- mentioned
- Methodology
- Metrics
- Michael
- microservices
- min
- minutes
- Mobile
- Modern
- modern technologies
- modernization
- modernize
- modernizing
- Monitor
- more
- more efficient
- Moreover
- most
- Most Popular
- move
- much
- multiple
- Navigation
- necessary
- Need
- New
- New technologies
- Newest
- newly
- Newsletters
- night
- nist
- nothing
- November
- now
- number
- object
- Object Storage
- observe
- obtains
- of
- off
- offer
- offered
- Offers
- Office
- often
- on
- ONE
- online
- open source
- operate
- Operations
- optimized
- Option
- or
- organizations
- origination
- Other
- our
- out
- output
- over
- overall
- overwhelming
- own
- package
- packages
- page
- pane
- Paper
- part
- partner
- partners
- pass
- past
- People
- per
- performed
- person
- Personalized
- perspective
- PHP
- pieces
- pipeline
- plane
- platform
- Platforms
- plato
- Plato Data Intelligence
- PlatoData
- plugin
- policy
- Popular
- portrait
- position
- possibility
- Post
- power
- practices
- prefer
- preferable
- pressure
- prevents
- previous
- previously
- primary
- Prior
- private
- privileges
- Problem
- procedures
- process
- processing
- Product
- productivity
- Products
- Products and Services
- Profile
- Programmer
- project
- projects
- promotes
- promotion
- PROS
- protect
- protection
- protocol
- provide
- provided
- provides
- providing
- public
- Public cloud
- purpose
- Puts
- quickly
- rapid
- rather
- Reading
- real-time
- reasons
- recommend
- recommended
- record
- reduce
- refer
- reference
- regarding
- registry
- regulated
- regulated industries
- related
- Releases
- reliable
- remained
- replacement
- report
- Reported
- repository
- represent
- require
- required
- requirement
- requires
- resource
- Resources
- responsive
- result
- resulting
- reuse
- Rise
- Risk
- robots
- robust
- routing
- Run
- runs
- s
- safe
- same
- satellite
- saved
- scan
- scanning
- scans
- Scarce
- schedule
- scheduled
- Screen
- script
- scripts
- secrets
- Section
- secure
- securely
- security
- security vulnerability
- seeing
- select
- sense
- seo
- separate
- serves
- service
- Services
- servicing
- set
- setting
- several
- Share
- should
- showcase
- showcased
- sign
- signature
- significant
- similar
- Simple
- simplifies
- single
- singular
- site
- situation
- skills
- small
- So
- Software
- Software Engineer
- Solutions
- SOLVE
- some
- Source
- source code
- sourced
- specific
- specified
- speed
- Sponsored
- squares
- staggering
- standard
- standards
- start
- State
- stated
- staying
- Steps
- Still
- storage
- store
- stored
- Strategy
- stream
- streaming
- streams
- strict
- strongly
- structure
- Struggle
- subscribe
- successful
- such
- suggest
- SUMMARY
- support
- Supports
- Survey
- Sustainability
- SVG
- system
- Systems
- TAG
- takes
- Target
- Task
- tasks
- teams
- techniques
- technological
- Technologies
- Technology
- terms
- Terraform
- tertiary
- test
- tested
- tests
- text
- than
- that
- The
- The Source
- The State
- their
- Them
- theme
- then
- There.
- These
- they
- thing
- things
- this
- thought
- thought leadership
- three
- Through
- throughout
- Thus
- time
- timestamp
- Title
- to
- today
- together
- Tokens
- tool
- tools
- top
- topic
- towards
- Traceability
- track
- traditional
- Transform
- Transformation
- treated
- Trends
- true
- Trust
- truth
- TURN
- two
- type
- types
- typically
- unit
- unlock
- unprecedented
- updated
- Updates
- updating
- uploaded
- upon
- URL
- us
- use
- used
- users
- using
- validated
- validating
- validation
- Valuable
- value
- Values
- various
- varying
- verified
- version
- very
- vs
- Vulnerabilities
- vulnerability
- Vulnerable
- W
- want
- was
- Way..
- we
- WELL
- well-known
- were
- What
- What is
- whatever
- when
- which
- while
- WHO
- will
- with
- within
- without
- WordPress
- Work
- workflow
- workflows
- working
- would
- write
- write code
- written
- yaml
- you
- young
- Your
- zephyrnet
- zero
- zero trust











