Table of Contents

Introduction
In this section, we will introduce KG by asking some simple but intuitive questions about KG. In fact, we will cover the what, why, and how of the knowledge graph. We will also go through some real-world examples.
What is a Knowledge Graph?
- To better under Knowledge graphs, let’s start by understanding its basic unit i.e. a “fact”. A fact is the most basic piece of information that can be stored in a KG. Facts can be represented in form of triplets in either of the ways,
– HRT: <head, relation, tail>
– SPO: <subject, predicate, object> - Remember, the above representations are just for nomenclature sake, hence you may come across people referring to the fact either way. Let’s follow the HRT representation for this article. So either way, facts contain 3 elements (hence facts are also called triplets) that can help with the intuitive representation of KG as a graph,
— Head or tail: these are entities that are real-world objects or abstract concepts which are represented as nodes
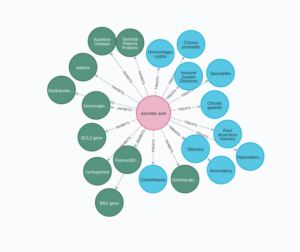
— Relation: these are the connection between entities which represented as edges - A simple KG example is shown below. One example of fact could be
<BoB, is_interested_in, The_Mona_Lisa>. You can see the KG is nothing but a collection of multiple such facts.

- Note, there are no limitations on the data type of the fact stored in KG. As shown in the above example, we have persons (Bob, Alice, ..), paintings (Mona Lisa), dates, etc, represented as nodes in the KG.
If this in-depth educational content is useful for you, subscribe to our AI research mailing list to be alerted when we release new material.
Why Knowledge Graph?
This is the very first and a valid question anyone will ask when introduced to KG. We will try to go through some points wherein we compare KG with normal graphs and even other ways of storing information. The aim is to highlight the major advantages of using KG.
Compared to Normal Graphs
- Heterogenous data: supports different types of entities (person, date, painting, etc) and relations (likes, born on, etc).
- Model real-world information: closer to our brain’s mental model of the world (represents information as a normal human does)
- Perform logical reasoning: traverse the graphs in a path to make logical connections (A’s father is B and B’s father is C, hence C is the grandfather of A)
Compared to other storage types
- Structured representation: far cry from unstructured representations like text data
- Removes redundancy: compared to tabular data, there is no need to add mostly empty columns or rows to add new data (a few facts)
- Query complex information: better than SQL for data where relationship matters more than individual data points (for example, in case you have to do lots of
JOINstatements in a SQL query, which is inherently slow)
How to use KG?
Knowledge graphs can be used for a large number of tasks — be it for logical reasoning, explainable recommendations, complex analysis or just being a better way to store information. There are two very interesting examples which we will discuss briefly.
Google Knowledge Panel
- On querying Google about a famous person, location, or concept, it returns a knowledge panel on the right. The panel contains a wide variety of information (description, education, born, died, quotes, etc) and interestingly in different formats — (text, image, dates, numbers, etc).
- All this information can be stored in a KG and one such example is shown below. This showcases how easy it is to store information and also note how intuitive it is to just read and understand the fact from a KG. In fact, Google uses KG as the base to store such information.

Recommendation system
- Classical algorithms considered user-item interactions to generate recommendations. Over time, newly created algorithms started considering additional information about the user as well as items to improve the recommendations.
- Below, we can see one KG (movie KG) that not only contains user-item connections (here person-movies) but also user-user interactions and item attributes. The idea is that, provided all this additional information, we can make much more accurate and informed suggestions. Without going into the exact algorithm, let’s rationalize what recommendations could be generated.
- “Avatar” could be recommended to,
— Bob: as it belongs to the Sci-fi genre same as Interstellar and Inception (which is already watched by Bob)
— Alice: as it is directed by James Cameron (Titanic) - “Blood Diamond” could be recommended to,
— Bob: as DiCaprio acted in Inception as well - This simple thought exercise should showcase how a lot of real-world interactions can be easily represented in form of facts using KG. And then we can leverage KG-based algorithms for a downstream use case like generating recommendations.


Knowledge Graph in practice
In this section, we will look at KG from a practitioner’s perspective. We will go through some open-source and readily available KG. For some cases, we may even want to create our own KG, so we will discuss some pointers w.r.t. it as well. Then we will quickly understand some rules and ways a KG can be structured by discussing KG ontology. Finally, we will discuss KG hosting databases and learn how we can query (fetch facts from) a KG.
Open source Knowledge Graphs
While there are several small-sized and domain-specific KGs, on the other hand, we also have many huge-sized and domain-agnostic KG that contains facts of all types and forms. Some of the famous open-source knowledge graphs are,
- DBpedia: is a crowd-sourced community-based effort to extract structured content from the information present in various Wikimedia projects.
- Freebase: a massive, collaboratively edited database of cross-linked data. Touted as “an openly shared database of the world’s knowledge”. It was bought by Google and used to power its own KG. In 2015, it was finally discontinued.
- OpenCyc: is a gateway to the full power of Cyc, one of the world’s most complete general knowledge base and commonsense reasoning engines.
- Wikidata: is a free, collaborative, multilingual database, collecting structured data to provide support for Wikimedia projects.
- YAGO: huge semantic knowledge base, derived from Wikipedia, WordNet, and GeoNames.

Creating custom Knowledge Graph
In spite of having several open-source KGs, we may have a requirement to create domain-specific KG for our use case. There, our base data (from which we want to create the KG), could be of multiple types — tabular, graphical, or text blob. We will cover some steps on how to create KG from unstructured data like text, as it’s relatively easier to convert structured data into KG using minimal domain knowledge and scripting. The complete process can be divided into two steps,
- Facts creation: this is the first step where we parse the text (sentence by sentence) and extract facts in triplet format like
<H, R, T>. As we are processing text, we can leverage pre-processing steps like tokenization, stemming, or lemmatization, etc to clean the text. Next, we want to extract the entities and relations (facts) from the text. For entities, we can use Named entity recognition (NER) algorithms. For relation, we can use sentence dependency parsing techniques to find the relationship between any pair of entities. Example article with code. - Facts selection: Once we have extracted several facts, the next obvious steps could be to remove duplicates and identify relevant facts that could be added to a KG. To identify duplicates, we can use entity and relation disambiguation techniques. The idea is to consolidate the same facts or elements of a fact, in case of repetitions. For example, “Albert Einstein” can also be written as “Albert E.” or “A. Einstein” in the text, but in reality, they all refer to the same entity. Finally, we can have a comprehensive rule-based system that decides which triplet should be added to the KG or which one could be skipped based on factors like redundant information (
A → sibling of → Bis present, henceB → sibling of → Ais redundant) or irrelevant information.

Knowledge Graph ontology
- An ontology is a model of the world (practically only a subset), listing the types of entities, the relationships that connect them, and constraints on the ways that entities and relationships can be combined. In a way, an ontology defines the rules on how the entities are connected within the world.
- Resource Description Framework (RDF) and Web Ontology Language (OWL) are some of the vocabulary frameworks used to model ontology. They provide a common framework for expressing this information so it can be exchanged between applications without loss of meaning.

- RDF provides languages for creating ontology, which we will use to create a sample KG. Below you can see the KG creating script [on left] in Turtle language for the KG [on right]. Notice, at the top of the script, we are creating references to a lot of predefined ontologies, as there is no need to reinvent the wheel. Next, to create the facts (or triplets) of our KG we can follow the lines below the
PREFIXcommands. - Notice, each entity and relation has a unique identifier (their unique key or UID). Throughout the code, the same entity or relation should be referenced by the same UID. Next, using the predefined schemas, we can add facts for an entity (in graphical terms, add a connecting edge and tail node to the head node). These facts could include another entity (refer by their UID), some text, date (in DateTime format), links, etc.

- Finally, once we have prepared the script (with
ttlextension — for scripts in Turtle language), that script contains the complete schema and definition of our KG. In itself, this may not be interesting, hence the file can be imported into any KG database for beautiful visualization and efficient querying.
Hosting Knowledge Graphs
There are two types of databases that can be used to store graphical information. The first is “property graphs” like Neo4j and OrientDB that does not support RDF file (out of the box) and have their own custom query language. On the other hand, we have “RDF triplet stores”, that support RDF files and support query language like SPARQL that is universally used to query KG. Some of the most famous ones are (with open source version),
- GraphDB: a solution by Ontotext, that provides frontend (visualization) and backend (server) services to see and query hosted knowledge graphs.
- Virtuoso: a solution by OpenLinkSoftware, that provides backend services to query hosted KG. It also supports querying KG using a combination of SQL and SPARQL. On top of it, a lot of open-source KG like DBpedia are hosted on Virtuoso.
Querying Knowledge Graph
- Once facts are created as RDF and hosted on an RDF triplet store like Virtuoso, we can query them to extract relevant information. SPARQL is an RDF query language that is able to retrieve and manipulate data stored in RDF format. An interesting read for more detail is Walkthrough DBpedia And Triplestore.
- Most of the RDF triple stores provide a visual SPARQL query page to fetch the relevant info. For our case, let us use one such visual query helper exposed by Wikidata (shown below). A sample query is shown, where we want to extract all entities that are instances of a house cat (we just want some cats 🐱). As discussed before, each entity has a UID, hence relation
<instance of>is represented asP31, and the entity<house cat>is represented asQ146. The query is quite simple to understand, as from lines 2 to 5, we are just trying to convey that we want any entity that is an instance of a house cat. As Wikidata contains data in multiple languages, line 6 is needed to filter results specific to the English language. The results (entities with their UID and some basic details) are shown below the query.

- Open-source KG also exposes several ready-made APIs for frequently used queries. One such API is shown below (for Wikidata), which returns relevant information for a given entity. Below we can see the result of querying
wbgetentitiesAPI for entityQ9141which is the UID for the Taj Mahal.

Conclusion
Let us stop here. Till now we have discussed the basics of Knowledge graphs and dealt with some practical aspects of using KG. This article is a weak transcription of the first part of the guest lectures I gave at UoT. And the intention of the first lecture (and hence of this article) is to introduce the beginner audience to KG and guide the intermediate audience to some of the most important and useful sources and tools w.r.t. KG. As for the more advanced audience, who want to discuss KG embedding techniques or KG research and application tracks, you can refer to the second lecture. Or maybe be in touch for the second part of this article 🤗
Author’s note: This article is also present as a chapter in my book on data science (WIP) — A Lazy Guide to Data Science. It is a weak transcription of the first part of guest lectures I gave at the University of Tartu for the Computational Social Science Group.
Reference
- A Survey on Knowledge Graph-Based Recommender Systems, Qingyu Guo et.al. 2020
- Which Knowledge Graph Is Best for Me? Michael Färber et. al. 2018
- A Survey on Knowledge Graphs: Representation, Acquisition, and Applications, Shaoxiong Ji et.al 2021
- RDF Primer
- Wikidata SPARQL Query Helper
- Wikidata API services
This article was originally published on Towards Data Science and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI updates.
We’ll let you know when we release more technical education.
Related
- acquisition
- Additional
- AI
- ai research
- algorithm
- algorithms
- All
- analysis
- api
- APIs
- Application
- applications
- article
- audience
- Basics
- BEST
- Box
- cases
- Cats
- closer
- code
- collaborative
- Collecting
- Common
- connection
- Connections
- content
- Creating
- data
- data science
- Database
- databases
- Dates
- detail
- died
- Edge
- Education
- educational
- English
- etc
- Exercise
- Finally
- First
- follow
- form
- format
- Framework
- Free
- full
- General
- Guest
- guide
- head
- here
- Highlight
- hosting
- House
- How
- How To
- HTTPS
- huge
- idea
- identify
- image
- info
- information
- involved
- IT
- Key
- knowledge
- language
- Languages
- large
- LEARN
- lemmatization
- Leverage
- Line
- listing
- location
- major
- Matters
- model
- movie
- nodes
- numbers
- Ontology
- open
- open source
- Other
- painting
- People
- perspective
- power
- present
- projects
- Reality
- Relationships
- research
- Results
- returns
- rules
- Science
- Search
- Services
- shared
- Simple
- So
- Social
- SQL
- start
- started
- stats
- storage
- store
- stores
- support
- Supports
- Survey
- system
- Systems
- Technical
- techniques
- The Basics
- the world
- time
- Tokenization
- top
- touch
- university
- Updates
- us
- visualization
- W
- W3
- web
- Wheel
- WHO
- Wikipedia
- within
- world