Image by jcomp on Freepik
Szeregi czasowe to unikalny zestaw danych w dziedzinie nauki o danych. Dane są rejestrowane z częstotliwością czasową (np. codziennie, co tydzień, co miesiąc itp.), a każda obserwacja jest powiązana z drugą. Dane szeregów czasowych są cenne, gdy chcesz analizować, co dzieje się z danymi w czasie i tworzyć prognozy na przyszłość.
Prognozowanie szeregów czasowych to metoda tworzenia przyszłych prognoz na podstawie historycznych danych szeregów czasowych. Istnieje wiele metod statystycznych służących do prognozowania szeregów czasowych, np ARIMA or Wygładzanie wykładnicze.
Prognozowanie szeregów czasowych jest często spotykane w biznesie, dlatego analityk danych powinien wiedzieć, jak opracować model szeregów czasowych. W tym artykule dowiemy się, jak prognozować szeregi czasowe przy użyciu dwóch popularnych pakietów Pythona do prognozowania; statsmodels i Prorok. Wejdźmy w to.
Połączenia modele statystyk Pakiet Pythona to pakiet typu open source oferujący różne modele statystyczne, w tym model prognozowania szeregów czasowych. Wypróbujmy pakiet z przykładowym zestawem danych. W tym artykule będzie używany Cyfrowe szeregi czasowe waluty dane z Kaggle (CC0: domena publiczna).
Wyczyśćmy dane i przyjrzyjmy się zestawowi danych, który mamy.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
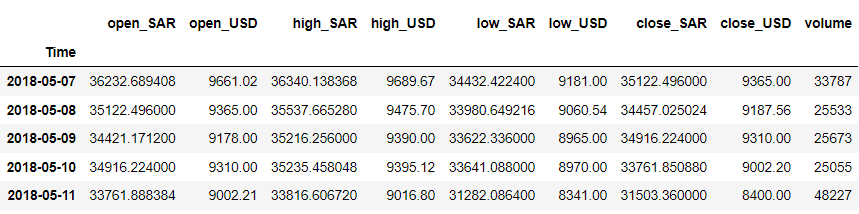
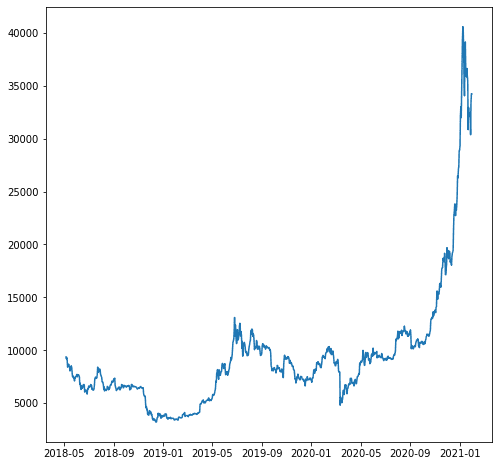
W naszym przykładzie załóżmy, że chcemy prognozować zmienną „close_USD”. Zobaczmy, jak wzór danych w czasie.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
Zbudujmy model prognostyczny na podstawie naszych powyższych danych. Przed przystąpieniem do modelowania podzielmy dane na dane pociągowe i testowe.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
Nie dzielimy danych losowo, ponieważ są to dane szeregów czasowych i musimy zachować kolejność. Zamiast tego staramy się mieć dane pociągu z wcześniejszych czasów, a dane testowe z najnowszych danych.
Użyjmy statsmodels do stworzenia modelu prognostycznego. The model statystyczny udostępnia wiele interfejsów API modeli szeregów czasowych, ale jako przykładu użylibyśmy modelu ARIMA.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
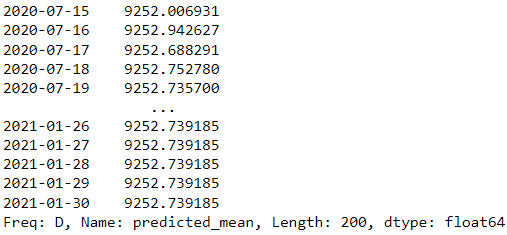
W powyższym przykładzie używamy modelu ARIMA z statsmodels jako modelu prognostycznego i próbujemy przewidzieć następne 200 dni.
Czy wynik modelu jest dobry? Spróbujmy je ocenić. Ocena modelu szeregów czasowych zwykle wykorzystuje wykres wizualizacji do porównania rzeczywistego i przewidywanego z metrykami regresji, takimi jak średni błąd bezwzględny (MAE), główny błąd średniokwadratowy (RMSE) i MAPE (średni bezwzględny błąd procentowy).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
Powyższy wynik wygląda dobrze, ale zobaczmy, jak to jest, gdy je zwizualizujemy.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
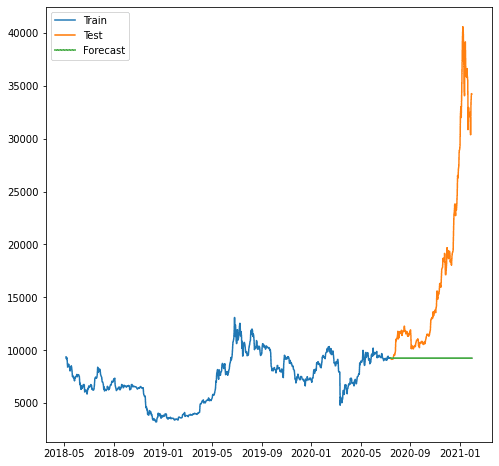
Jak widać prognoza była gorsza, ponieważ nasz model nie jest w stanie przewidzieć trendu wzrostowego. Model ARIMA, którego używamy, wydaje się zbyt prosty do prognozowania.
Może lepiej będzie, jeśli spróbujemy użyć innego modelu poza statsmodels. Wypróbujmy słynny pakiet proroka z Facebooka.
prorok to pakiet modelu prognozowania szeregów czasowych, który najlepiej sprawdza się w przypadku danych z efektami sezonowymi. Prophet uznano również za solidny model prognostyczny, ponieważ radził sobie z brakującymi danymi i wartościami odstającymi.
Wypróbujmy pakiet Prorok. Najpierw musimy zainstalować pakiet.
pip install prophet
Następnie musimy przygotować nasz zestaw danych do szkolenia modelu prognostycznego. Prorok ma określone wymagania: kolumna czasu musi mieć nazwę „ds”, a wartość „y”.
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
Gdy nasze dane są gotowe, spróbujmy utworzyć prognozę na podstawie tych danych.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
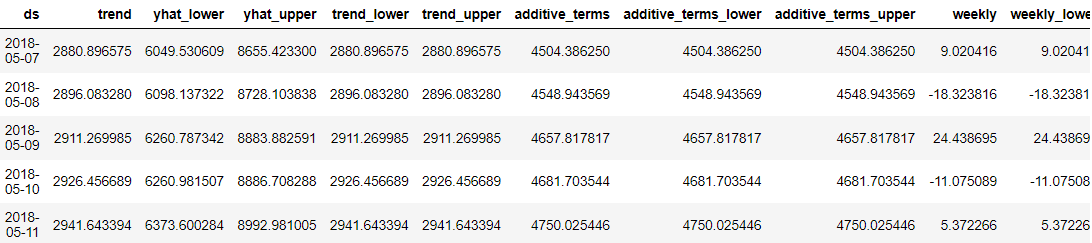
Wspaniałe w Proroku było to, że każdy punkt danych prognozy był szczegółowy, abyśmy my, użytkownicy, mogli go zrozumieć. Jednak trudno jest zrozumieć wynik tylko na podstawie danych. Możemy więc spróbować zwizualizować je za pomocą Proroka.
model.plot(predictions)
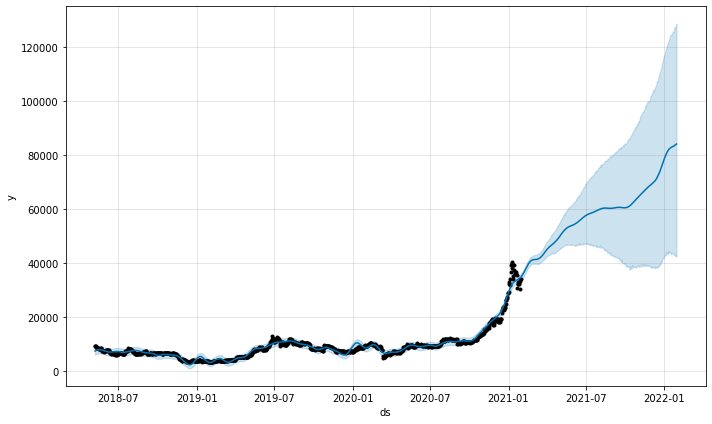
Funkcja wykresu prognoz z modelu dostarczyłaby nam informacji o tym, jak pewne były prognozy. Z powyższego wykresu widać, że prognoza ma tendencję wzrostową, ale wraz ze wzrostem niepewności im dłuższe są prognozy.
Możliwe jest również zbadanie składowych prognozy za pomocą następującej funkcji.
model.plot_components(predictions)
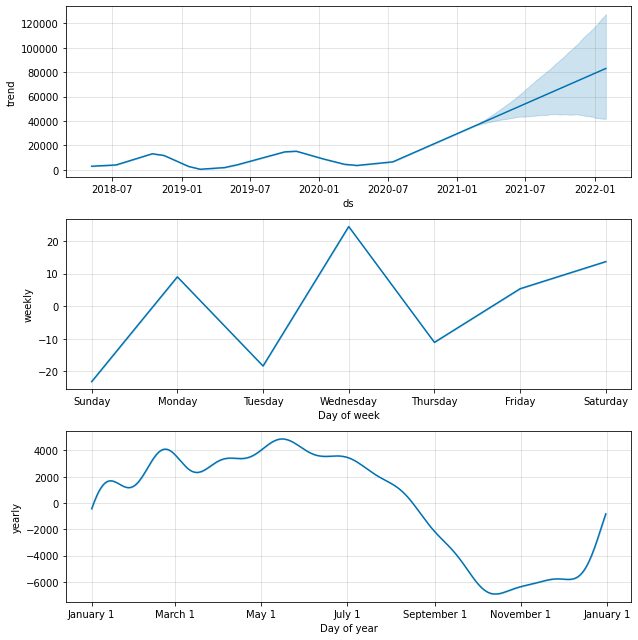
Domyślnie uzyskalibyśmy trend danych z roczną i tygodniową sezonowością. To dobry sposób na wyjaśnienie, co dzieje się z naszymi danymi.
Czy można by również ocenić model Proroka? Absolutnie. Prophet zawiera pomiar diagnostyczny, z którego możemy skorzystać: walidacja krzyżowa szeregów czasowych. Metoda wykorzystuje część danych historycznych i za każdym razem dopasowuje model do punktu odcięcia. Następnie Prorok porównywał przepowiednie z rzeczywistymi. Spróbujmy użyć kodu.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
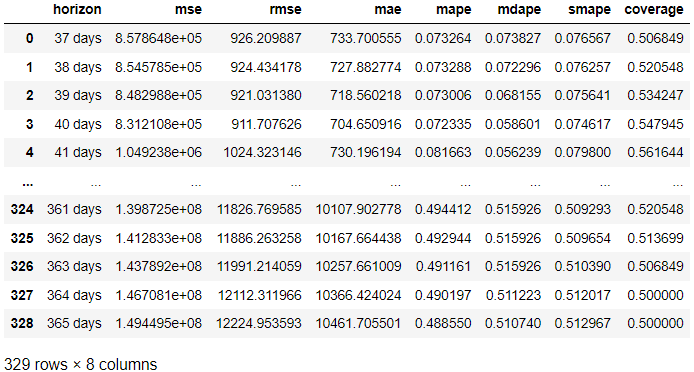
W powyższym wyniku uzyskaliśmy wynik oceny z rzeczywistego wyniku w porównaniu z prognozą w każdym dniu prognozy. Możliwe jest również zwizualizowanie wyniku za pomocą następującego kodu.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
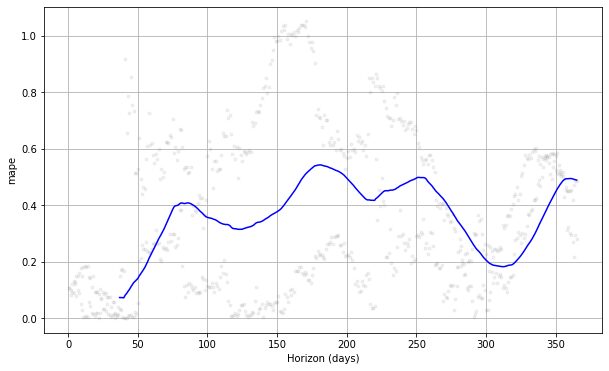
Jeśli spojrzymy na powyższy wykres, zobaczymy, że błąd przewidywania zmieniał się w kolejnych dniach i w niektórych punktach mógł osiągnąć błąd 50%. W ten sposób możemy chcieć jeszcze bardziej ulepszyć model, aby naprawić błąd. Możesz sprawdzić dokumentacja do dalszej eksploracji.
Prognozowanie jest jednym z typowych przypadków występujących w biznesie. Jednym z łatwych sposobów opracowania modelu prognostycznego jest użycie pakietów statsforecast i Prophet Python. W tym artykule dowiemy się, jak utworzyć model prognostyczny i ocenić go za pomocą statsforecast i Prophet.
Cornelius Yudha Wijaya jest kierownikiem i asystentem analityka danych oraz autorem danych. Pracując na pełny etat w Allianz Indonesia, uwielbia dzielić się wskazówkami dotyczącymi Pythona i danych za pośrednictwem mediów społecznościowych i mediów.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :Jest
- $W GÓRĘ
- 1
- 11
- 7
- 8
- 9
- a
- O nas
- powyżej
- bezwzględny
- absolutnie
- Osiągać
- nabyty
- Allianz
- w czasie rzeczywistym sprawiają,
- i
- Inne
- Pszczoła
- SĄ
- artykuł
- AS
- Asystent
- At
- na podstawie
- BE
- bo
- zanim
- korzystny
- BEST
- Ulepsz Swój
- pomiędzy
- budować
- biznes
- by
- obliczać
- CAN
- Etui
- Wózki CC0
- ZOBACZ
- kod
- Kolumna
- kolumny
- wspólny
- porównać
- w porównaniu
- składniki
- pewność
- za
- mógłby
- pokrycie
- Stwórz
- Waluta
- codziennie
- dane
- nauka danych
- naukowiec danych
- Data
- dzień
- Dni
- dc
- Domyślnie
- szczegółowe
- rozwijać
- domena
- nie
- e
- każdy
- Wcześniej
- ruchomości
- błąd
- itp
- oceniać
- ewaluację
- Każdy
- przykład
- Wyjaśniać
- eksploracja
- sławny
- pole
- w porządku
- i terminów, a
- dopasować
- Fix
- następujący
- W razie zamówieenia projektu
- Prognoza
- od
- funkcjonować
- dalej
- przyszłość
- otrzymać
- GitHub
- dobry
- wykres
- wspaniały
- uchwyt
- dzieje
- Ciężko
- Have
- historyczny
- horyzont
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- importować
- in
- obejmuje
- Włącznie z
- wzrosła
- wzrastający
- wskaźnik
- Indonezja
- początkowy
- zainstalować
- zamiast
- IT
- jpg
- Knuggety
- Wiedzieć
- firmy
- UCZYĆ SIĘ
- dłużej
- Popatrz
- WYGLĄD
- robić
- kierownik
- wiele
- matplotlib
- Media
- metoda
- metody
- Metryka
- może
- brakujący
- model
- modelowanie
- modele
- miesięcznie
- O imieniu
- Potrzebować
- wymagania
- Następny
- tępy
- uzyskać
- of
- oferuje
- on
- ONE
- open source
- zamówienie
- Inne
- zewnętrzne
- pakiet
- Pakiety
- pandy
- parametry
- część
- Wzór
- procent
- wykonać
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- Popularny
- możliwy
- przewidzieć
- przepowiednia
- Przewidywania
- Przygotować
- zapewniać
- zapewnia
- publiczny
- Python
- gotowy
- nagrany
- regresja
- związane z
- wymaganie
- dalsze
- Efekt
- krzepki
- korzeń
- nauka
- Naukowiec
- wydaje
- Serie
- zestaw
- Share
- Prosty
- So
- Obserwuj Nas
- Media społecznościowe
- kilka
- specyficzny
- dzielić
- Kwadratowa
- statystyczny
- taki
- Brać
- test
- że
- Połączenia
- Im
- czas
- Szereg czasowy
- wskazówki
- do
- także
- Pociąg
- Trening
- Trend
- Niepewność
- zrozumieć
- wyjątkowy
- ANONIMOWY
- w górę
- us
- posługiwać się
- Użytkownicy
- zazwyczaj
- Cenny
- wartość
- różnorodny
- przez
- wyobrażanie sobie
- Droga..
- tygodniowy
- DOBRZE
- Co
- Podczas
- Wikipedia
- będzie
- w
- w ciągu
- pracujący
- działa
- by
- pisarz
- pisanie
- Twój
- zefirnet