Materiały sponsorowane
ChatGPT i podobne narzędzia oparte na dużych modelach językowych (LLM) są niesamowite. Ale nie są to narzędzia uniwersalne.
To tak, jakby wybrać inne narzędzia do budowania i tworzenia. Musisz wybrać tego odpowiedniego do pracy. Nie próbowałbyś dokręcać śruby młotkiem ani przewracać kotleta hamburgerowego trzepaczką. Proces ten byłby niewygodny i powodowałby niechlujną awarię.
Modele językowe, takie jak LLM, stanowią jedynie część szerszego zestawu narzędzi do uczenia maszynowego, obejmującego zarówno generatywną, jak i predykcyjną sztuczną inteligencję. Wybór odpowiedniego typu modelu uczenia maszynowego ma kluczowe znaczenie, aby dostosować go do wymagań zadania.
Przyjrzyjmy się bliżej, dlaczego LLM lepiej nadają się do pomocy w sporządzaniu tekstów lub pomysłów na prezenty w ramach burzy mózgów, niż do rozwiązywania najważniejszych zadań związanych z modelowaniem predykcyjnym w Twojej firmie. „Tradycyjne” modele uczenia maszynowego, które poprzedzały programy LLM i wielokrotnie udowodniły swoją wartość w biznesie, nadal odgrywają kluczową rolę. Przeanalizujemy także pionierskie podejście do wspólnego korzystania z tych narzędzi — ekscytujący rozwój, który w Pecan nazywamy Przewidywalne GenAI.
LLM są przeznaczone dla słów, a nie liczb
W uczeniu maszynowym stosuje się różne metody matematyczne do analizy tak zwanych „danych szkoleniowych” — początkowego zbioru danych reprezentującego problem, który analityk danych lub naukowiec zajmujący się danymi ma nadzieję rozwiązać.
Nie można przecenić znaczenia danych szkoleniowych. Zawiera wzorce i relacje, których model uczenia maszynowego „nauczy się” przewidywać wyniki, gdy otrzyma później nowe, niewidoczne dane.
Czym konkretnie jest LLM? Modele dużych języków, czyli LLM, wchodzą w zakres uczenia maszynowego. Wywodzą się z głębokiego uczenia się, a ich struktura została opracowana specjalnie do przetwarzania języka naturalnego.
Można powiedzieć, że są zbudowane na fundamencie słów. Ich celem jest po prostu przewidzenie, które słowo będzie następne w sekwencji słów. Na przykład funkcja autokorekty w iPhone'ach w iOS 17 wykorzystuje teraz LLM, aby lepiej przewidzieć, które słowo najprawdopodobniej zamierzasz wpisać jako następne.

Teraz wyobraź sobie, że jesteś modelem uczenia maszynowego. (Wytrzymaj, wiemy, że to trudne.) Zostałeś przeszkolony w przewidywaniu słów. Przeczytałeś i przestudiowałeś miliony słów z szerokiej gamy źródeł na różne tematy. Twoi mentorzy (czyli programiści) pomogli Ci poznać najlepsze sposoby przewidywania słów i tworzenia nowego tekstu spełniającego wymagania użytkownika.
Ale oto zwrot akcji. Użytkownik udostępnia teraz ogromny arkusz kalkulacyjny zawierający dane klientów i transakcji, zawierający miliony wierszy liczb, i prosi o przewidzenie liczb powiązanych z istniejącymi danymi.
Jak myślisz, jak potoczą się twoje przewidywania? Po pierwsze, prawdopodobnie byłbyś zirytowany, że to zadanie nie odpowiada temu, czego tak ciężko pracowałeś, aby się nauczyć. (Na szczęście, o ile nam wiadomo, LLM nie mają jeszcze uczuć). Co ważniejsze, zostajesz poproszony o wykonanie zadania, które nie odpowiada temu, czego się nauczyłeś. I prawdopodobnie nie będziesz prezentował się tak dobrze.
Luka między szkoleniem a zadaniem pomaga wyjaśnić, dlaczego LLM nie nadają się dobrze do zadań predykcyjnych obejmujących dane liczbowe i tabelaryczne – podstawowy format danych gromadzonych przez większość firm. Zamiast tego bardziej efektywny jest model uczenia maszynowego specjalnie spreparowany i dostrojony do obsługi tego typu danych. Dosłownie został do tego przeszkolony.
Wyzwania związane z efektywnością i optymalizacją LLM
Oprócz tego, że lepiej dopasowują się do danych numerycznych, tradycyjne metody uczenia maszynowego są znacznie wydajniejsze i łatwiejsze do optymalizacji pod kątem lepszej wydajności niż LLM.
Wróćmy do Twoich doświadczeń z podszywaniem się pod LLM. Czytanie tych wszystkich słów i studiowanie ich stylu i sekwencji brzmi jak mnóstwo pracy, prawda? Przyswojenie wszystkich tych informacji wymagałoby wiele wysiłku.
Podobnie złożone szkolenie LLM może skutkować powstaniem modeli z miliardami parametrów. Ta złożoność pozwala tym modelom zrozumieć zawiłe niuanse ludzkiego języka i reagować na nie. Jednak intensywne szkolenie wiąże się z dużymi wymaganiami obliczeniowymi, gdy LLM generują odpowiedzi. Numerycznie zorientowane „tradycyjne” algorytmy uczenia maszynowego, takie jak drzewa decyzyjne lub sieci neuronowe, będą prawdopodobnie potrzebować znacznie mniej zasobów obliczeniowych. I nie jest to przypadek, że „większe jest lepsze”. Nawet gdyby szkoły LLM mogły obsługiwać dane liczbowe, ta różnica oznaczałaby, że tradycyjne metody uczenia maszynowego byłyby nadal szybsze, wydajniejsze, bardziej zrównoważone pod względem środowiskowym i bardziej opłacalne.
Ponadto, czy kiedykolwiek pytałeś ChatGPT, skąd wiedział, jak udzielić konkretnej odpowiedzi? Odpowiedź będzie prawdopodobnie nieco niejasna:
Generuję odpowiedzi w oparciu o mieszankę danych licencjonowanych, danych tworzonych przez trenerów i danych publicznie dostępnych. Moje szkolenie obejmowało także wielkoskalowe zbiory danych uzyskane z różnych źródeł, w tym książek, stron internetowych i innych tekstów, aby rozwinąć wszechstronne rozumienie ludzkiego języka. Proces szkolenia obejmuje wykonywanie obliczeń na tysiącach procesorów graficznych przez tygodnie lub miesiące, ale dokładne szczegóły i ramy czasowe są zastrzeżone dla OpenAI.
Jaka część „wiedzy” odzwierciedlonej w tej odpowiedzi pochodziła od trenerów ludzi, z danych publicznych czy z książek? Nawet sam ChatGPT nie jest pewien: „Względne proporcje tych źródeł są nieznane i nie mam szczegółowego wglądu w to, które konkretne dokumenty były częścią mojego zestawu treningowego”.
To trochę denerwujące, że ChatGPT udziela tak pewnych odpowiedzi na Twoje pytania, ale nie jest w stanie prześledzić swoich odpowiedzi do konkretnych źródeł. Ograniczona interpretowalność i wyjaśnialność LLM również stwarza wyzwania w optymalizacji ich pod kątem konkretnych potrzeb biznesowych. Zrozumienie przesłanek stojących za ich informacjami lub przewidywaniami może być trudne. Aby jeszcze bardziej skomplikować sprawę, niektóre firmy borykają się z wymogami regulacyjnymi, które oznaczają, że muszą być w stanie wyjaśnić czynniki wpływające na przewidywania modelu. Podsumowując, wyzwania te pokazują, że tradycyjne modele uczenia maszynowego – ogólnie rzecz biorąc łatwiejsze do interpretacji i wyjaśnienia – prawdopodobnie lepiej nadają się do zastosowań biznesowych.
Właściwe miejsce dla LLM w zestawie narzędzi predykcyjnych przedsiębiorstw
Czy zatem powinniśmy po prostu pozostawić LLM ich zadaniom związanym ze słowami i zapomnieć o nich w przypadku predykcyjnych przypadków użycia? Może się teraz wydawać, że mimo wszystko nie są w stanie pomóc w przewidywaniu odejścia klientów ani wartości życiowej klienta.
Rzecz w tym, że choć stwierdzenie „tradycyjne modele uczenia maszynowego” sprawia, że techniki te wydają się szeroko rozumiane i łatwe w użyciu, z naszego doświadczenia w Pecan wiemy, że firmy w dalszym ciągu mają trudności z przyjęciem nawet tych bardziej znanych form sztucznej inteligencji.

Niedawne badanie przeprowadzone przez Workday pokazuje, że 42% firm w Ameryce Północnej albo nie rozpoczęło stosowania sztucznej inteligencji, albo jest dopiero na wczesnym etapie analizowania dostępnych możliwości. Minęło ponad dziesięć lat, odkąd narzędzia do uczenia maszynowego stały się bardziej dostępne dla firm. Mieli czas i dostępne są różne narzędzia.
Z jakiegoś powodu udane wdrożenia sztucznej inteligencji były zaskakująco rzadkie pomimo ogromnego szumu wokół analityki danych i sztucznej inteligencji oraz ich potwierdzonego potencjału w zakresie znaczącego wpływu na biznes. Brakuje jakiegoś ważnego mechanizmu, który pomógłby wypełnić lukę między obietnicami złożonymi przez sztuczną inteligencję a możliwością jej produktywnego wdrożenia.
Uważamy, że właśnie w tym punkcie LLM mogą teraz odegrać istotną rolę pomostową. LLM mogą pomóc użytkownikom biznesowym pokonać przepaść między identyfikacją problemu biznesowego do rozwiązania a opracowaniem modelu predykcyjnego.
Dzięki LLM na rynku zespoły biznesowe i zajmujące się danymi, które nie mają możliwości lub możliwości ręcznego kodowania modeli uczenia maszynowego, mogą teraz lepiej przekładać swoje potrzeby na modele. Mogą „używać swoich słów”, jak lubią mawiać rodzice, aby rozpocząć proces modelowania.
Łączenie LLM z technikami uczenia maszynowego stworzonymi z myślą o doskonaleniu danych biznesowych
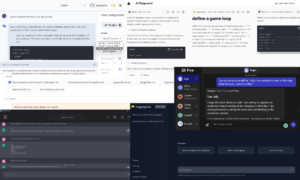
Ta funkcja pojawiła się teraz w rozwiązaniu Predictive GenAI firmy Pecan, które łączy mocne strony LLM z naszą już wysoce udoskonaloną i zautomatyzowaną platformą uczenia maszynowego. Nasz czat predykcyjny oparty na LLM zbiera informacje od użytkownika biznesowego, aby pomóc w zdefiniowaniu i opracowaniu pytania predykcyjnego — konkretnego problemu, który użytkownik chce rozwiązać za pomocą modelu.
Następnie, korzystając z GenAI, nasza platforma generuje notes predykcyjny, dzięki któremu kolejny krok w kierunku modelowania staje się jeszcze łatwiejszy. Ponownie, korzystając z możliwości LLM, notatnik zawiera wstępnie wypełnione zapytania SQL umożliwiające wybranie danych szkoleniowych dla modelu predykcyjnego. Zautomatyzowane przygotowywanie danych, inżynieria funkcji, budowanie modeli i możliwości wdrażania firmy Pecan pozwalają przeprowadzić resztę procesu w rekordowym czasie, szybciej niż jakiekolwiek inne rozwiązanie do modelowania predykcyjnego.
Krótko mówiąc, Predictive GenAI firmy Pecan wykorzystuje niezrównane umiejętności językowe LLM, aby nasza najlepsza w swojej klasie platforma modelowania predykcyjnego była znacznie bardziej dostępna i przyjazna dla użytkowników biznesowych. Nie możemy się doczekać, aby zobaczyć, jak to podejście pomoże znacznie większej liczbie firm odnieść sukces dzięki sztucznej inteligencji.
Tak więc, podczas gdy LLM sam nie są dobrze dostosowane do obsługi wszystkich Twoich potrzeb predykcyjnych, mogą odegrać potężną rolę w rozwoju Twoich projektów AI. Interpretując Twój przypadek użycia i zapewniając przewagę dzięki automatycznie wygenerowanemu kodowi SQL, Predictive GenAI firmy Pecan jest liderem w jednoczeniu tych technologii. Możesz sprawdź to teraz, korzystając z bezpłatnego okresu próbnego.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2024/01/pecan-llms-used-alone-cant-address-companys-predictive-needs?utm_source=rss&utm_medium=rss&utm_campaign=why-llms-used-alone-cant-address-your-companys-predictive-needs
- :ma
- :Jest
- :nie
- :Gdzie
- 15%
- 17
- a
- zdolność
- Zdolny
- O nas
- dostępny
- przyznał
- dodatek
- adres
- przyjąć
- Po
- ponownie
- AI
- aka
- Algorytmy
- wyrównać
- Wszystkie kategorie
- pozwala
- sam
- już
- również
- zdumiewający
- Ameryka
- an
- analityk
- w czasie rzeczywistym sprawiają,
- i
- odpowiedź
- odpowiedzi
- każdy
- podejście
- SĄ
- na około
- przybył
- AS
- pomagać
- At
- zautomatyzowane
- zautomatyzowane uczenie maszynowe
- automatycznie
- dostępny
- z powrotem
- na podstawie
- BE
- Niedźwiedź
- stał
- być
- Początek
- za
- jest
- uwierzyć
- BEST
- Ulepsz Swój
- pomiędzy
- miliardy
- Bit
- Bolt
- Książki
- obie
- burza mózgów
- BRIDGE
- mostkowanie
- szerszy
- Budowanie
- wybudowany
- biznes
- wpływ na biznes
- biznes
- ale
- by
- wezwanie
- oprawa ołowiana witrażu
- CAN
- możliwości
- zdolność
- Pojemność
- nieść
- walizka
- Etui
- pewien
- wyzwania
- przepaść
- pogawędzić
- ChatGPT
- Wybierając
- kod
- zbierać
- byliśmy spójni, od początku
- Firmy
- Firma
- kompleks
- kompleksowość
- obliczeniowy
- obliczenia
- computing
- pewność
- stanowić
- zawiera
- skorygowania
- opłacalne
- mógłby
- wykonane
- Stwórz
- stworzony
- Tworzenie
- krytyczny
- Krzyż
- istotny
- klient
- dane
- analityk danych
- Przygotowywanie danych
- nauka danych
- naukowiec danych
- zbiory danych
- dekada
- decyzja
- głęboko
- głęboka nauka
- głębiej
- definicja
- wymagania
- Wdrożenie
- zaprojektowany
- Mimo
- szczegółowe
- detale
- rozwijać
- rozwinięty
- deweloperzy
- rozwijanie
- oprogramowania
- różnica
- różne
- KOPAĆ
- do
- dokumenty
- Nie
- darowizna
- nie
- projekt
- rysunek
- Wcześnie
- łatwiej
- łatwo
- Efektywne
- efektywność
- wydajny
- wysiłek
- bądź
- obejmujący
- Inżynieria
- środowiska
- Eter (ETH)
- Parzyste
- EVER
- przykład
- przewyższać
- podniecony
- ekscytujący
- Przede wszystkim system został opracowany
- doświadczenie
- Wyjaśniać
- Wyjaśnialność
- odkryj
- Exploring
- Czynniki
- Brak
- Spadać
- znajomy
- daleko
- szybciej
- Cecha
- uczucia
- mniej
- i terminów, a
- dopasować
- pasuje
- Trzepnięcie
- W razie zamówieenia projektu
- format
- formularze
- na szczęście
- Naprzód
- Fundacja
- Darmowy
- przyjazny
- od
- dalej
- łączenie
- szczelina
- genialne
- ogólnie
- Generować
- wygenerowane
- generuje
- generatywny
- generatywna sztuczna inteligencja
- prezent
- dany
- daje
- Dający
- Go
- cel
- GPU
- poprowadzi
- miał
- młotek
- uchwyt
- Prowadzenie
- Ciężko
- Have
- przystań
- głowa
- ciężki
- pomoc
- pomógł
- pomoc
- pomaga
- wysoko
- posiada
- ma nadzieję,
- W jaki sposób
- Jednak
- HTTPS
- człowiek
- i
- pomysły
- identyfikacja
- if
- obraz
- Rezultat
- wdrożenia
- wdrożenia
- ważny
- co ważne
- in
- Włącznie z
- wpływanie
- Informacja
- początkowy
- zapoczątkowany
- wkład
- zamiast
- Zamierzam
- najnowszych
- zaangażowany
- dotyczy
- z udziałem
- iOS
- IT
- JEGO
- samo
- Praca
- właśnie
- Knuggety
- Wiedzieć
- znany
- język
- duży
- na dużą skalę
- w dużej mierze
- później
- prowadzący
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- Pozostawiać
- Upoważniony
- dożywotni
- lubić
- Prawdopodobnie
- Ograniczony
- Partia
- maszyna
- uczenie maszynowe
- Techniki uczenia maszynowego
- zrobiony
- robić
- WYKONUJE
- wiele
- masywny
- Mecz
- matematyczny
- oznaczać
- mechanizm
- mentorzy
- metody
- może
- miliony
- brakujący
- mieszanina
- model
- modelowanie
- modele
- miesięcy
- jeszcze
- bardziej wydajny
- większość
- przeniesienie
- dużo
- musi
- my
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Potrzebować
- wymagania
- sieci
- Nerwowy
- sieci neuronowe
- Nowości
- Następny
- Północ
- Ameryka Północna
- notatnik
- już dziś
- zacienienie
- z naszej
- uzyskane
- of
- on
- ONE
- tylko
- OpenAI
- optymalizacja
- Optymalizacja
- optymalizacji
- Opcje
- or
- Inne
- ludzkiej,
- na zewnątrz
- wyniki
- koniec
- zawyżone
- parametry
- rodzice
- część
- szczególny
- wzory
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wybierać
- obraz
- Pionierskość
- Miejsce
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- potencjał
- mocny
- precyzyjnie
- przewidzieć
- przewidywanie
- Przewidywania
- proroczy
- przygotowanie
- pierwotny
- prawdopodobnie
- Problem
- wygląda tak
- przetwarzanie
- projektowanie
- obiecuje
- własność
- Sprawdzony
- zapewniać
- publiczny
- publicznie
- zapytania
- pytanie
- pytania
- zasięg
- RZADKO SPOTYKANY
- racjonalny
- Czytaj
- Czytający
- powód
- rekord
- rafinowany
- odzwierciedlenie
- regulacyjne
- związane z
- Relacje
- względny
- WIELOKROTNIE
- reprezentowanie
- zażądać
- wymagania
- Badania naukowe
- Zasoby
- Odpowiadać
- odpowiedź
- Odpowiedzi
- REST
- dalsze
- wynikły
- ujawnia
- prawo
- Rola
- bieganie
- s
- powiedzieć
- powiedzenie
- nauka
- Naukowiec
- widzieć
- wydać się
- wybierać
- wybierając
- Sekwencja
- zestaw
- Short
- powinien
- pokazać
- znaczenie
- znaczący
- podobny
- po prostu
- ponieważ
- umiejętności
- So
- rozwiązanie
- ROZWIĄZANIA
- kilka
- Dźwięk
- Dźwięki
- Źródła
- specyficzny
- swoiście
- Arkusz kalkulacyjny
- SQL
- etapy
- początek
- rozpoczęty
- Ewolucja krok po kroku
- Nadal
- silne strony
- Struktura
- Walka
- Studiował
- Studiowanie
- styl
- osiągnąć sukces
- udany
- taki
- pewnie
- zrównoważone
- T
- zwalczanie
- Brać
- Zadanie
- zadania
- Zespoły
- Techniki
- Technologies
- XNUMX
- niż
- że
- Połączenia
- ich
- Im
- Te
- one
- rzecz
- rzeczy
- myśleć
- to
- tych
- tysiące
- dokręcać
- czas
- do
- razem
- Tona
- Zestaw narzędzi
- narzędzia
- tematy
- w kierunku
- wyśledzić
- tradycyjny
- przeszkolony
- Trening
- transakcja
- tłumaczyć
- Drzewa
- próbować
- SKRĘCAĆ
- twist
- rodzaj
- parasol
- dla
- zrozumieć
- zrozumienie
- zrozumiany
- jednoczący
- nieznany
- niezrównany
- us
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- wartość
- różnorodność
- różnorodny
- Naprawiono
- widoczność
- istotny
- vs
- chce
- Droga..
- sposoby
- we
- strony internetowe
- tygodni
- DOBRZE
- były
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- dlaczego
- szeroko
- będzie
- w
- w ciągu
- słowo
- słowa
- Praca
- pracował
- wartość
- by
- jeszcze
- ty
- Twój
- zefirnet