Zdjęcie autora
W tym poście przyjrzymy się nowemu, najnowocześniejszemu modelowi open source o nazwie Mixtral 8x7b. Dowiemy się również, jak uzyskać do niego dostęp za pomocą biblioteki LLaMA C++ i jak uruchamiać duże modele językowe przy zmniejszonej mocy obliczeniowej i pamięci.
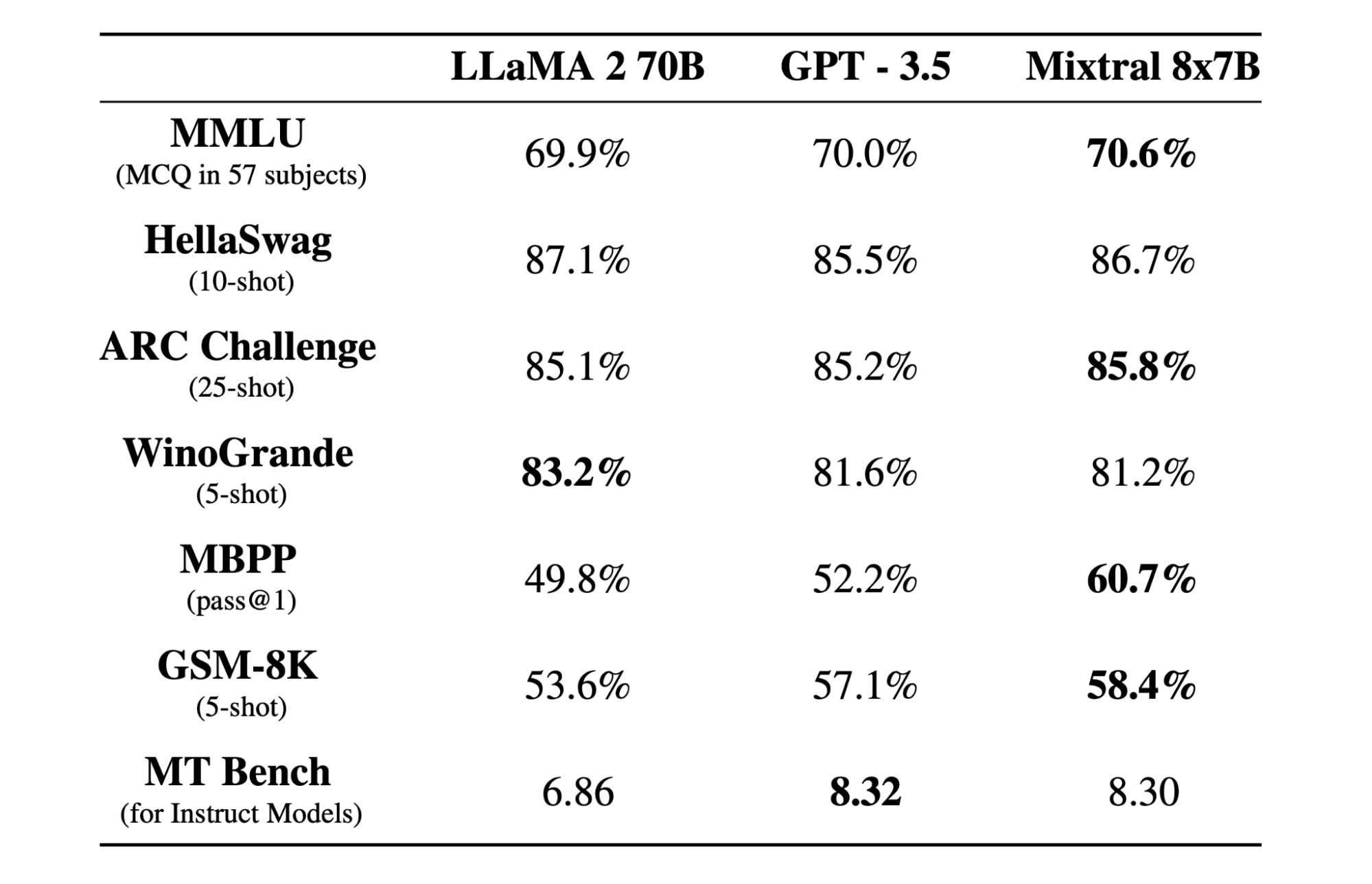
Mieszany 8x7b to wysokiej jakości model rzadkiej mieszanki ekspertów (SMoE) z otwartymi ciężarkami, stworzony przez Mistral AI. Jest licencjonowany w ramach Apache 2.0 i przewyższa Llamę 2 70B w większości testów porównawczych, zapewniając jednocześnie 6 razy szybsze wnioskowanie. Mixtral dorównuje lub przewyższa GPT3.5 w większości standardowych testów porównawczych i jest najlepszym modelem o otwartej wadze pod względem stosunku ceny do wydajności.
Obraz z Mixtral ekspertów
Mixtral 8x7B korzysta z rzadkiej sieci składającej się wyłącznie z dekoderów. Obejmuje to wybór bloku wyprzedzającego spośród 8 grup parametrów, przy czym sieć routerów wybiera dwie z tych grup dla każdego tokena i addytywnie łączy ich dane wyjściowe. Ta metoda zwiększa liczbę parametrów modelu, jednocześnie zarządzając kosztami i opóźnieniami, dzięki czemu jest on równie wydajny jak model 12.9B, mimo że ma całkowite parametry 46.7B.
Model Mixtral 8x7B doskonale radzi sobie z obsługą szerokiego kontekstu tokenów 32 tys. i obsługuje wiele języków, w tym angielski, francuski, włoski, niemiecki i hiszpański. Wykazuje wysoką wydajność w generowaniu kodu i można go dostroić do modelu zgodnego z instrukcjami, osiągając wysokie wyniki w testach porównawczych, takich jak MT-Bench.
LLaMA.cpp to biblioteka C/C++ zapewniająca wydajny interfejs dla dużych modeli językowych (LLM) w oparciu o architekturę LLM Facebooka. Jest to lekka i wydajna biblioteka, której można używać do różnych zadań, w tym do generowania tekstu, tłumaczenia i odpowiadania na pytania. LLaMA.cpp obsługuje szeroką gamę LLM, w tym LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B i GPT4ALL. Jest kompatybilny ze wszystkimi systemami operacyjnymi i może działać zarówno na procesorach, jak i procesorach graficznych.
W tej sekcji będziemy uruchamiać aplikację internetową llama.cpp w Colab. Pisząc kilka linijek kodu, będziesz mógł doświadczyć działania nowego, najnowocześniejszego modelu na swoim komputerze lub w Google Colab.
Pierwsze kroki
Najpierw pobierzemy repozytorium llama.cpp GitHub za pomocą poniższego wiersza poleceń:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitNastępnie zmienimy katalog na repozytorium i zainstalujemy plik llama.cpp za pomocą polecenia `make`. Instalujemy plik llama.cpp dla procesora graficznego NVidia z zainstalowaną CUDA.
%cd llama.cpp
!make LLAMA_CUBLAS=1Pobierz model
Model możemy pobrać z Hugging Face Hub wybierając odpowiednią wersję pliku modelu `.gguf`. Więcej informacji na temat różnych wersji można znaleźć w TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Obraz z TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Aby pobrać model z bieżącego katalogu, możesz użyć polecenia `wget`.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufAdres zewnętrzny serwera LLaMA
Kiedy uruchomimy serwer LLaMA, otrzymamy adres IP hosta lokalnego, który jest dla nas bezużyteczny w Colab. Potrzebujemy połączenia z serwerem proxy localhost przy użyciu portu proxy jądra Colab.
Po uruchomieniu poniższego kodu otrzymasz globalne hiperłącze. Użyjemy tego linku, aby uzyskać później dostęp do naszej aplikacji internetowej.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Uruchamianie serwera
Aby uruchomić serwer LLaMA C++ należy podać komendę serwera z lokalizacją pliku modelu i poprawnym numerem portu. Ważne jest, aby upewnić się, że numer portu jest zgodny z tym, który zainicjowaliśmy w poprzednim kroku dla portu proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
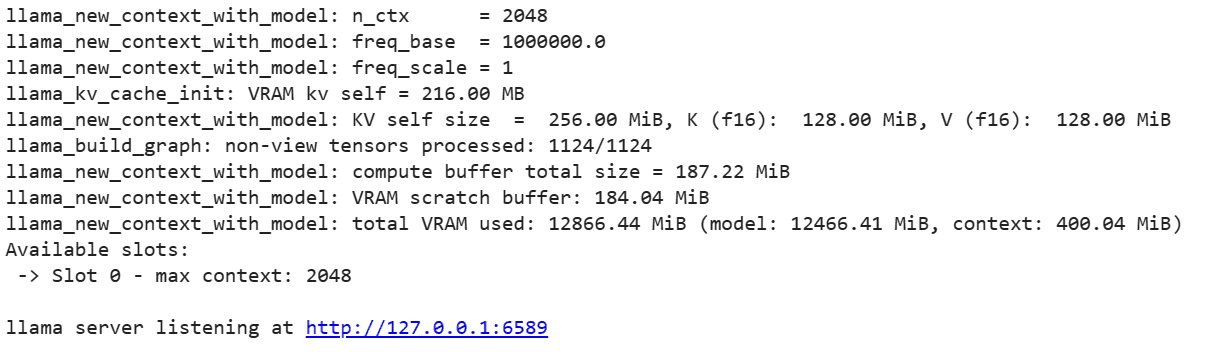
Dostęp do aplikacji internetowej czatu można uzyskać, klikając hiperłącze portu proxy w poprzednim kroku, ponieważ serwer nie działa lokalnie.
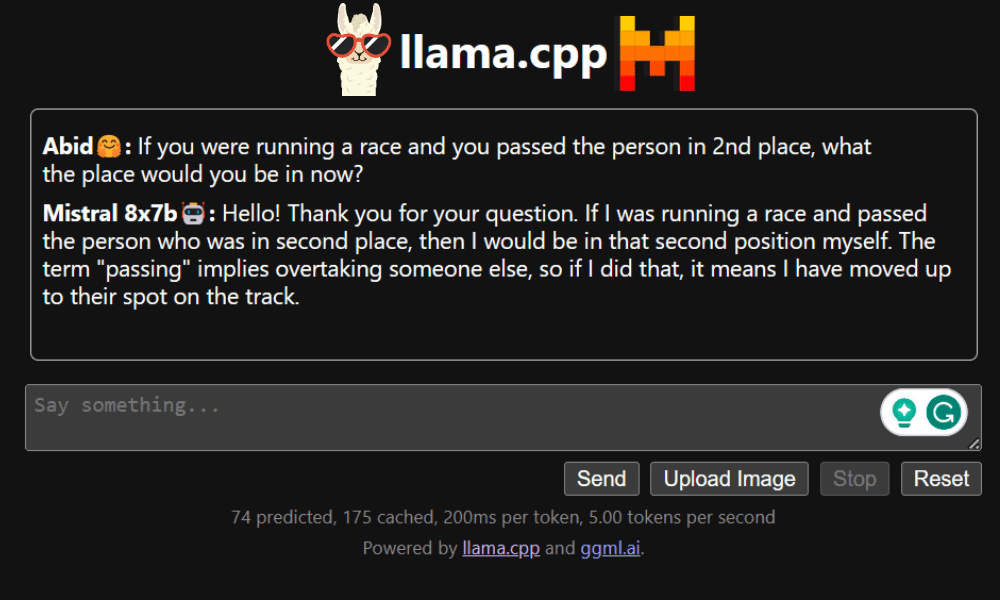
Aplikacja internetowa LLaMA C++
Zanim zaczniemy korzystać z chatbota, musimy go dostosować. Zastąp „LLaMA” nazwą swojego modelu w sekcji podpowiedzi. Dodatkowo zmodyfikuj nazwę użytkownika i nazwę bota, aby rozróżnić wygenerowane odpowiedzi.
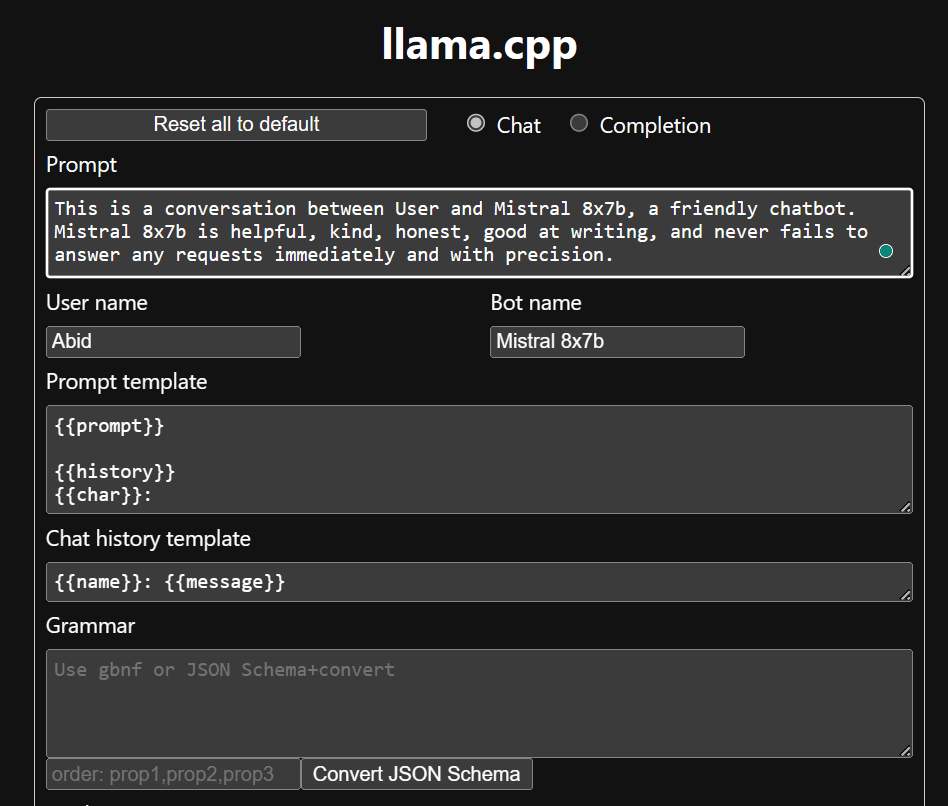
Rozpocznij czat, przewijając w dół i pisząc w sekcji czatu. Zachęcamy do zadawania pytań technicznych, na które inne modele open source nie odpowiedziały prawidłowo.
Jeśli napotkasz problemy z aplikacją, możesz spróbować uruchomić ją samodzielnie, korzystając z mojego Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Ten samouczek zawiera kompleksowy przewodnik na temat uruchamiania zaawansowanego modelu open source, Mixtral 8x7b, w Google Colab przy użyciu biblioteki LLaMA C++. W porównaniu do innych modeli Mixtral 8x7b zapewnia doskonałą wydajność i efektywność, co czyni go doskonałym rozwiązaniem dla tych, którzy chcą eksperymentować z dużymi modelami językowymi, ale nie dysponują rozbudowanymi zasobami obliczeniowymi. Możesz go łatwo uruchomić na swoim laptopie lub w bezpłatnej chmurze obliczeniowej. Jest przyjazny dla użytkownika i możesz nawet wdrożyć aplikację do czatu, aby inni mogli z niej korzystać i eksperymentować.
Mam nadzieję, że to proste rozwiązanie dotyczące obsługi dużego modelu okazało się pomocne. Zawsze szukam prostych i lepszych opcji. Jeśli masz jeszcze lepsze rozwiązanie, daj mi znać, a omówię je następnym razem.
Abid Ali Awan (@ 1abidaliawan) jest certyfikowanym specjalistą ds. analityków danych, który uwielbia tworzyć modele uczenia maszynowego. Obecnie koncentruje się na tworzeniu treści i pisaniu blogów technicznych na temat technologii uczenia maszynowego i data science. Abid posiada tytuł magistra zarządzania technologią oraz tytuł licencjata inżynierii telekomunikacyjnej. Jego wizją jest zbudowanie produktu AI z wykorzystaniem grafowej sieci neuronowej dla studentów zmagających się z chorobami psychicznymi.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :Jest
- :nie
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Zdolny
- dostęp
- dostęp
- osiągnięcia
- do tego
- adres
- zaawansowany
- AI
- Wszystkie kategorie
- również
- zawsze
- am
- an
- i
- odpowiedź
- Apache
- Aplikacja
- Zastosowanie
- właściwy
- architektura
- SĄ
- AS
- zapytać
- na podstawie
- BE
- rozpocząć
- poniżej
- Benchmarki
- BEST
- Ulepsz Swój
- pomiędzy
- Blokować
- blogi
- Bot
- obie
- budować
- Budowanie
- ale
- by
- C + +
- nazywa
- CAN
- Dyplomowani
- zmiana
- pogawędzić
- chatbot
- na czacie
- Wybierając
- Chmura
- kod
- łączenie
- w porównaniu
- zgodny
- wszechstronny
- obliczeniowy
- obliczać
- computing
- połączenie
- zawartość
- Tworzenie treści
- kontekst
- skorygowania
- Koszty:
- pokrywa
- stworzony
- tworzenie
- Aktualny
- Obecnie
- dostosować
- dane
- nauka danych
- naukowiec danych
- Stopień
- dostarcza
- demonstruje
- rozwijać
- Mimo
- rozróżniać
- do
- na dół
- pobieranie
- każdy
- z łatwością
- efektywność
- wydajny
- spotkanie
- Inżynieria
- Angielski
- Poprawia
- Parzyste
- doskonała
- doświadczenie
- eksperyment
- eksperci
- odkryj
- rozległy
- Twarz
- Failed
- sokół
- szybciej
- czuć
- kilka
- filet
- skupienie
- W razie zamówieenia projektu
- znaleziono
- Darmowy
- francuski
- od
- funkcjonować
- wygenerowane
- generacja
- niemiecki
- otrzymać
- GitHub
- Dać
- Globalne
- GPU
- GPU
- wykres
- Wykres sieci neuronowej
- Grupy
- poprowadzi
- Prowadzenie
- Have
- mający
- he
- pomocny
- Wysoki
- wysoka wydajność
- wysokiej jakości
- jego
- posiada
- nadzieję
- W jaki sposób
- How To
- HTTPS
- Piasta
- i
- if
- choroba
- importować
- ważny
- in
- Włącznie z
- Informacja
- zapoczątkowany
- zainstalować
- Instalacja
- Interfejs
- najnowszych
- dotyczy
- IP
- problemy
- IT
- włoski
- Knuggety
- Wiedzieć
- język
- Języki
- laptopa
- duży
- Utajenie
- później
- UCZYĆ SIĘ
- nauka
- niech
- Biblioteka
- Upoważniony
- lekki
- lubić
- Linia
- linie
- LINK
- Lama
- lokalnie
- lokalizacja
- poszukuje
- kocha
- maszyna
- uczenie maszynowe
- robić
- Dokonywanie
- i konserwacjami
- zarządzający
- mistrz
- zapałki
- me
- Pamięć
- psychika
- Choroba umysłowa
- metoda
- mieszanina
- model
- modele
- modyfikować
- jeszcze
- większość
- wielokrotność
- my
- Nazwa
- Potrzebować
- sieć
- Nerwowy
- sieci neuronowe
- Nowości
- Następny
- numer
- Nvidia
- of
- on
- ONE
- koncepcja
- open source
- operacyjny
- system operacyjny
- Opcje
- or
- Inne
- Pozostałe
- ludzkiej,
- Przewyższa
- wydajność
- Wyjścia
- własny
- parametr
- parametry
- PC
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- plato
- Analiza danych Platona
- PlatoDane
- Proszę
- Post
- poprzedni
- Produkt
- profesjonalny
- prawidłowo
- zapewniać
- zapewnia
- pełnomocnik
- pytanie
- pytania
- zasięg
- Zredukowany
- w sprawie
- obsługi produkcji rolnej, która zastąpiła
- składnica
- Badania naukowe
- Zasoby
- Odpowiedzi
- Router
- run
- bieganie
- s
- nauka
- Naukowiec
- wyniki
- przewijanie
- Sekcja
- wybierając
- serwer
- Prosty
- ponieważ
- rozwiązanie
- Źródło
- hiszpański
- standard
- state-of-the-art
- Ewolucja krok po kroku
- silny
- Walka
- Studenci
- przełożony
- podpory
- pewnie
- systemy
- zadania
- Techniczny
- Technologies
- Technologia
- telekomunikacja
- XNUMX
- generowanie tekstu
- że
- Połączenia
- ich
- Te
- to
- tych
- czas
- do
- żeton
- Żetony
- Kwota produktów:
- Tłumaczenie
- próbować
- Tutorial
- drugiej
- dla
- us
- posługiwać się
- używany
- Użytkownik
- łatwy w obsłudze
- zastosowania
- za pomocą
- różnorodność
- różnorodny
- wersja
- wizja
- chcieć
- we
- sieć
- Aplikacja internetowa
- który
- Podczas
- KIM
- szeroki
- Szeroki zasięg
- będzie
- w
- pisanie
- ty
- Twój
- zefirnet