By Dawid Wendt i Grzegorz Kimball
Wydajne przetwarzanie danych ciągów ma kluczowe znaczenie dla wielu aplikacji do nauki o danych. Aby wydobyć cenne informacje z danych łańcuchowych, RAPIDY libcudf zapewnia potężne narzędzia do przyspieszania transformacji danych łańcuchowych. libcudf to biblioteka C++ GPU DataFrame używana do ładowania, łączenia, agregowania i filtrowania danych.
W nauce o danych łańcuch danych reprezentuje mowę, tekst, sekwencje genetyczne, rejestrowanie i wiele innych rodzajów informacji. Podczas pracy z danymi łańcuchowymi na potrzeby uczenia maszynowego i inżynierii funkcji dane muszą być często normalizowane i przekształcane, zanim będzie można je zastosować w określonych przypadkach użycia. libcudf zapewnia zarówno interfejsy API ogólnego przeznaczenia, jak i narzędzia po stronie urządzenia, umożliwiające szeroki zakres niestandardowych operacji na łańcuchach.
Ten post pokazuje, jak umiejętnie przekształcać kolumny ciągów za pomocą interfejsu API ogólnego przeznaczenia libcudf. Zdobędziesz nową wiedzę o tym, jak odblokować szczytową wydajność przy użyciu niestandardowych jąder i narzędzi libcudf po stronie urządzenia. Ten post zawiera również przykłady najlepszego zarządzania pamięcią GPU i efektywnego konstruowania kolumn libcudf w celu przyspieszenia transformacji łańcuchów.
libcudf przechowuje dane łańcuchowe w pamięci urządzenia za pomocą Forma strzałki, która reprezentuje kolumny ciągów jako dwie kolumny podrzędne: chars and offsets (Rysunek 1).
Połączenia chars kolumna przechowuje dane ciągu jako bajty znaków zakodowane w UTF-8, które są przechowywane w pamięci w sposób ciągły.
Połączenia offsets kolumna zawiera rosnącą sekwencję liczb całkowitych, które są pozycjami bajtów identyfikującymi początek każdego pojedynczego ciągu znaków w tablicy danych znaków. Ostatnim elementem przesunięcia jest całkowita liczba bajtów w kolumnie znaków. Oznacza to rozmiar pojedynczego ciągu w rzędzie i jest zdefiniowany jako (offsets[i+1]-offsets[i]).
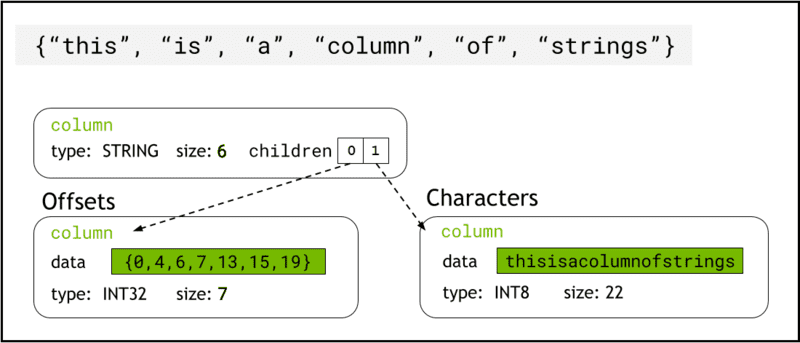 Rysunek 1. Schemat przedstawiający sposób, w jaki format Arrow reprezentuje ciągi kolumn z
Rysunek 1. Schemat przedstawiający sposób, w jaki format Arrow reprezentuje ciągi kolumn z chars i offsets kolumny podrzędne
Aby zilustrować przykładową transformację łańcucha, rozważmy funkcję, która otrzymuje dwie kolumny ciągów wejściowych i tworzy jedną zredagowaną kolumnę ciągów wyjściowych.
Dane wejściowe mają postać: kolumny „imiona” zawierającej imiona i nazwiska oddzielone spacją oraz kolumny „widoczności” zawierającej status „publiczny” lub „prywatny”.
Proponujemy funkcję „redagowania”, która działa na danych wejściowych w celu wytworzenia danych wyjściowych składających się z pierwszej litery nazwiska, po której następuje spacja i całego imienia. Jeśli jednak odpowiednia kolumna widoczności jest „prywatna”, wówczas ciąg wyjściowy powinien zostać całkowicie zredagowany jako „X X”.
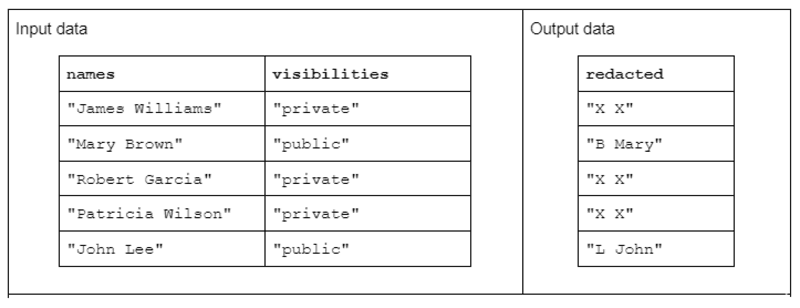 Tabela 1. Przykład „zredagowanej” transformacji łańcuchów, która otrzymuje kolumny ciągów nazw i widoczności jako dane wejściowe oraz częściowo lub całkowicie zredagowane dane jako dane wyjściowe
Tabela 1. Przykład „zredagowanej” transformacji łańcuchów, która otrzymuje kolumny ciągów nazw i widoczności jako dane wejściowe oraz częściowo lub całkowicie zredagowane dane jako dane wyjściowe
Po pierwsze, transformację łańcucha można przeprowadzić za pomocą metody Interfejs API łańcuchów libcudf. Interfejs API ogólnego przeznaczenia jest doskonałym punktem wyjścia i dobrą bazą do porównywania wydajności.
Funkcje API operują na całej kolumnie łańcuchów, uruchamiając co najmniej jedno jądro na funkcję i przypisując jeden wątek do łańcucha. Każdy wątek obsługuje pojedynczy wiersz danych równolegle w GPU i wyprowadza pojedynczy wiersz jako część nowej kolumny danych wyjściowych.
Aby wykonać przykładową funkcję redagowania przy użyciu interfejsu API ogólnego przeznaczenia, wykonaj następujące kroki:
- Przekonwertuj kolumnę łańcuchów „widoczności” na kolumnę logiczną, używając
contains - Utwórz nową kolumnę łańcuchów z kolumny nazw, kopiując „XX”, ilekroć odpowiedni wpis wiersza w kolumnie logicznej ma wartość „fałsz”
- Podziel „zredagowaną” kolumnę na kolumny imienia i nazwiska
- Pokrój pierwszy znak nazwisk jako inicjały nazwiska
- Zbuduj kolumnę wyjściową, łącząc kolumnę ostatnich inicjałów i kolumnę imion z separatorem spacji („”).
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Takie podejście zajmuje około 3.5 ms na A6000 z 600 XNUMX wierszy danych. Ten przykład używa contains, copy_if_else, split, slice_strings i concatenate aby wykonać niestandardową transformację ciągu. Analiza profilowania z Systemy Nsight wskazuje, że split funkcja zajmuje najwięcej czasu, a następnie slice_strings i concatenate.
Rysunek 2 przedstawia dane profilowania z Nsight Systems przykładu redact, pokazujące kompleksowe przetwarzanie łańcuchów z prędkością do ~600 milionów elementów na sekundę. Regiony odpowiadają zakresom NVTX związanym z każdą funkcją. Jasnoniebieskie zakresy odpowiadają okresom, w których działają jądra CUDA.
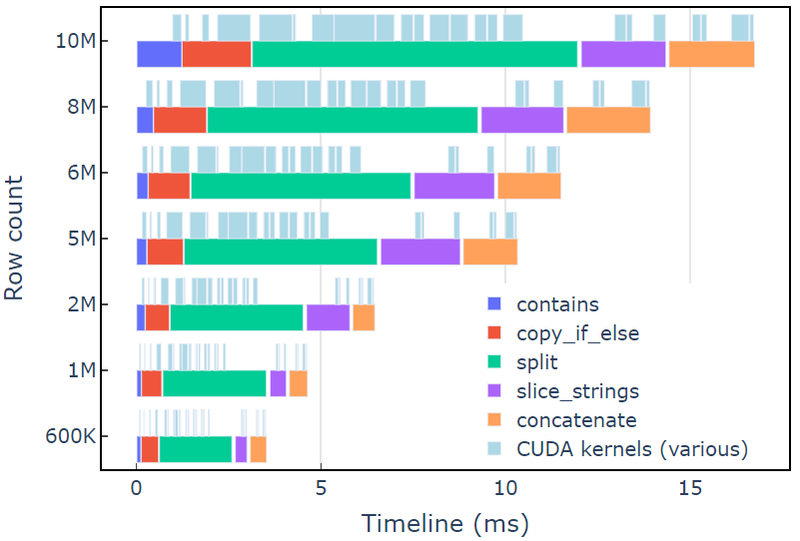 Rysunek 2. Profilowanie danych z Nsight Systems przykładu redact
Rysunek 2. Profilowanie danych z Nsight Systems przykładu redact
Interfejs API ciągów libcudf to szybki i wydajny zestaw narzędzi do przekształcania ciągów znaków, ale czasami funkcje o krytycznym znaczeniu dla wydajności muszą działać jeszcze szybciej. Kluczowym źródłem dodatkowej pracy w interfejsie API libcudf strings jest utworzenie co najmniej jednej nowej kolumny strings w globalnej pamięci urządzenia dla każdego wywołania API, otwierając możliwość łączenia wielu wywołań API w niestandardowe jądro.
Ograniczenia wydajności w wywołaniach malloc jądra
Najpierw zbudujemy niestandardowe jądro, aby zaimplementować transformację przykładu redakcji. Projektując to jądro, musimy pamiętać, że kolumny łańcuchów libcudf są niezmienne.
Kolumny łańcuchów nie mogą być zmieniane w miejscu, ponieważ bajty znaków są przechowywane w sposób ciągły, a wszelkie zmiany długości łańcucha unieważniłyby dane przesunięć. Dlatego też redact_kernel niestandardowe jądro generuje nową kolumnę ciągów przy użyciu fabryki kolumn libcudf do zbudowania obu offsets i chars kolumny podrzędne.
W tym pierwszym podejściu ciąg wyjściowy dla każdego wiersza jest tworzony w dynamiczna pamięć urządzenia używając wywołania malloc wewnątrz jądra. Niestandardowe dane wyjściowe jądra to wektor wskaźników urządzeń do każdego wyjścia wiersza, a ten wektor służy jako dane wejściowe do fabryki kolumn ciągów.
Niestandardowe jądro akceptuje plik cudf::column_device_view aby uzyskać dostęp do danych kolumny ciągów i używa element metoda zwrotu a cudf::string_view reprezentujący dane ciągu w określonym indeksie wiersza. Wyjście jądra jest wektorem typu cudf::string_view który przechowuje wskaźniki do pamięci urządzenia zawierające ciąg wyjściowy i rozmiar tego ciągu w bajtach.
Połączenia cudf::string_view class jest podobna do klasy std::string_view, ale jest zaimplementowana specjalnie dla libcudf i zawija dane znakowe o stałej długości w pamięci urządzenia zakodowane jako UTF-8. Ma wiele takich samych funkcji (find i substr funkcje, na przykład) i ograniczenia (brak terminatora zerowego) jako std odpowiednik. A cudf::string_view reprezentuje sekwencję znaków przechowywaną w pamięci urządzenia, więc możemy jej użyć tutaj do zarejestrowania pamięci malloc dla wektora wyjściowego.
Jądro Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Może się to wydawać rozsądnym podejściem, dopóki nie zostanie zmierzona wydajność jądra. Takie podejście zajmuje około 108 ms na A6000 z 600 30 wierszy danych — ponad XNUMX razy wolniej niż rozwiązanie przedstawione powyżej z wykorzystaniem interfejsu API libcudf strings.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Głównym wąskim gardłem jest tzw malloc/free wywołania wewnątrz dwóch jąder tutaj. Wymagana jest dynamiczna pamięć urządzenia CUDA malloc/free wywołuje synchronizację jądra, powodując degenerację wykonywania równoległego do wykonywania sekwencyjnego.
Wstępna alokacja pamięci roboczej w celu wyeliminowania wąskich gardeł
Wyeliminuj malloc/free wąskie gardło poprzez wymianę malloc/free wywołuje jądro ze wstępnie przydzieloną pamięcią roboczą przed uruchomieniem jądra.
W przypadku redagowania rozmiar wyjściowy każdego ciągu w tym przykładzie nie powinien być większy niż sam ciąg wejściowy, ponieważ logika usuwa tylko znaki. Dlatego pojedynczy bufor pamięci urządzenia może być używany z takim samym rozmiarem jak bufor wejściowy. Użyj przesunięć wejściowych, aby zlokalizować każdą pozycję w rzędzie.
Dostęp do przesunięć kolumny ciągów wymaga zawijania cudf::column_view z cudf::strings_column_view i dzwoniąc do niego offsets_begin metoda. Rozmiar chars Dostęp do kolumny podrzędnej można również uzyskać za pomocą chars_size metoda. Następnie rmm::device_uvector jest wstępnie przydzielany przed wywołaniem jądra w celu zapisania wyjściowych danych znakowych.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Wstępnie przydzielone jądro
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Jądro generuje wektor cudf::string_view obiekty, które są przekazywane do cudf::make_strings_column funkcja fabryczna. Drugi parametr tej funkcji służy do identyfikowania pustych wpisów w kolumnie danych wyjściowych. Przykłady w tym poście nie mają pustych wpisów, więc symbol zastępczy nullptr cudf::string_view{nullptr,0} Jest używane.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Takie podejście zajmuje około 1.1 ms na A6000 z 600 2 wierszy danych i dlatego przewyższa linię bazową o ponad XNUMXx. Przybliżony podział przedstawiono poniżej:
redact_kernel 66us make_strings_column 400us
Pozostały czas spędza się w cudaMalloc, cudaFree, cudaMemcpy, co jest typowe dla narzutu związanego z zarządzaniem tymczasowymi instancjami rmm::device_uvector. Ta metoda działa dobrze, jeśli wszystkie ciągi wyjściowe mają ten sam lub mniejszy rozmiar niż ciągi wejściowe.
Ogólnie rzecz biorąc, przejście na masową alokację pamięci roboczej za pomocą RAPIDS RMM jest znaczącym ulepszeniem i dobrym rozwiązaniem dla niestandardowej funkcji łańcuchów.
Optymalizacja tworzenia kolumn w celu skrócenia czasu obliczeń
Czy istnieje sposób, aby jeszcze bardziej to poprawić? Wąskim gardłem jest teraz tzw cudf::make_strings_column funkcja fabryczna, która buduje dwa komponenty kolumny ciągów znaków, offsets i chars, z wektora cudf::string_view obiekty.
W libcudf zawiera się wiele funkcji fabrycznych służących do budowania kolumn ciągów znaków. Funkcja fabryczna użyta w poprzednich przykładach przyjmuje a cudf::device_span of cudf::string_view obiektów, a następnie konstruuje kolumnę, wykonując a gather na bazowych danych znakowych, aby zbudować przesunięcia i kolumny podrzędne znaków. A rmm::device_uvector jest automatycznie konwertowany na a cudf::device_span bez kopiowania danych.
Jeśli jednak wektor znaków i wektor przesunięć są budowane bezpośrednio, można użyć innej funkcji fabrycznej, która po prostu tworzy kolumnę łańcuchów bez konieczności zbierania w celu skopiowania danych.
Połączenia sizes_kernel wykonuje pierwsze przejście przez dane wejściowe, aby obliczyć dokładny rozmiar wyjściowy każdego wiersza wyjściowego:
Zoptymalizowane jądro: część 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Rozmiary wyjściowe są następnie konwertowane na przesunięcia, wykonując operacje w miejscu exclusive_scan. Zauważ, że offsets wektor został utworzony za pomocą names.size()+1 elementy. Ostatnim wpisem będzie całkowita liczba bajtów (wszystkie rozmiary dodane razem), a pierwszym wpisem będzie 0. Oba są obsługiwane przez exclusive_scan dzwonić. Rozmiar chars kolumna jest pobierana z ostatniego wpisu offsets kolumna do zbudowania wektora znaków.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
Połączenia redact_kernel logika jest nadal bardzo podobna, z wyjątkiem tego, że akceptuje dane wyjściowe d_offsets vector, aby rozwiązać lokalizację wyjściową każdego wiersza:
Zoptymalizowane jądro: część 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Rozmiar danych wyjściowych d_chars kolumna jest pobierana z ostatniego wpisu d_offsets kolumna, aby przydzielić wektor znaków. Jądro uruchamia się ze wstępnie obliczonym wektorem przesunięć i zwraca wypełniony wektor znaków. Na koniec fabryka kolumn libcudf tworzy wyjściowe kolumny ciągów.
To zdjęcie cudf::make_strings_column funkcja fabryczna buduje kolumnę łańcuchów bez tworzenia kopii danych. The offsets dane i chars dane są już we właściwym, oczekiwanym formacie, a ta fabryka po prostu przenosi dane z każdego wektora i tworzy wokół niego strukturę kolumn. Po zakończeniu, rmm::device_uvectors dla offsets i chars są puste, ich dane zostały przeniesione do kolumny wyjściowej.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
To podejście zajmuje około 300 us (0.3 ms) na A6000 z 600 2 wierszy danych i jest lepsze niż poprzednie podejście o ponad XNUMXx. Możesz to zauważyć sizes_kernel i redact_kernel mają w dużej mierze tę samą logikę: raz, aby zmierzyć rozmiar danych wyjściowych, a następnie ponownie, aby wypełnić dane wyjściowe.
Z punktu widzenia jakości kodu korzystne jest refaktoryzacja transformacji jako funkcji urządzenia wywoływanej zarówno przez rozmiary, jak i jądra redakcji. Z punktu widzenia wydajności możesz być zaskoczony, widząc, że koszt obliczeniowy transformacji jest płacony dwukrotnie.
Korzyści związane z zarządzaniem pamięcią i wydajniejszym tworzeniem kolumn często przewyższają koszt obliczeniowy związany z dwukrotnym wykonaniem transformacji.
Tabela 2 pokazuje czas obliczeń, liczbę jąder i przetworzone bajty dla czterech rozwiązań omówionych w tym poście. „Całkowita liczba uruchomionych jąder” odzwierciedla całkowitą liczbę uruchomionych jąder, w tym jąder obliczeniowych i pomocniczych. „Całkowita liczba przetworzonych bajtów” to łączna przepustowość odczytu i zapisu pamięci DRAM, a „minimalna liczba przetworzonych bajtów” to średnio 37.9 bajtów na wiersz dla naszych testowych wejść i wyjść. Idealny przypadek „ograniczonej przepustowości pamięci” zakłada przepustowość 768 GB/s, teoretyczną szczytową przepustowość A6000.
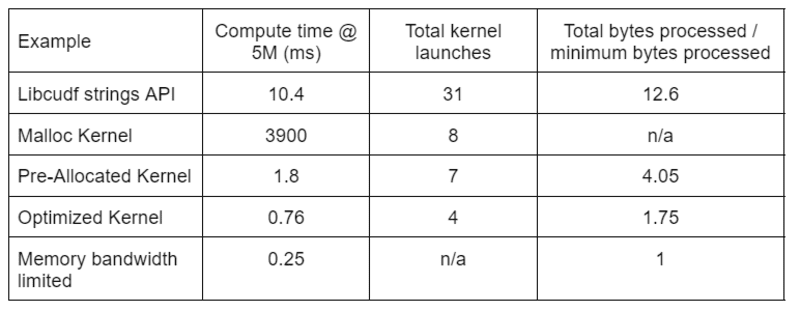 Tabela 2. Czas obliczeń, liczba jąder i przetworzone bajty dla czterech rozwiązań omówionych w tym poście
Tabela 2. Czas obliczeń, liczba jąder i przetworzone bajty dla czterech rozwiązań omówionych w tym poście
„Zoptymalizowane jądro” zapewnia najwyższą przepustowość dzięki zmniejszonej liczbie uruchomień jądra i mniejszej łącznej liczbie przetworzonych bajtów. W przypadku wydajnych, niestandardowych jąder całkowita liczba uruchomień jądra spada z 31 do 4, a łączna liczba przetwarzanych bajtów z 12.6x do 1.75x rozmiaru danych wejściowych i wyjściowych.
W rezultacie niestandardowe jądro osiąga ponad 10-krotnie wyższą przepustowość niż interfejs API łańcuchów ogólnego przeznaczenia do transformacji redakcyjnej.
Zasób pamięci puli w Menedżer pamięci RAPIDS (RMM) to kolejne narzędzie, którego możesz użyć do zwiększenia wydajności. Powyższe przykłady wykorzystują domyślny „zasób pamięci CUDA” do przydzielania i zwalniania globalnej pamięci urządzenia. Jednak czas potrzebny do przydzielenia pamięci roboczej powoduje znaczne opóźnienie między krokami transformacji łańcuchów. „Zasoby pamięci puli” w RMM zmniejszają opóźnienia, przydzielając z góry dużą pulę pamięci i przypisując podprzydziały w razie potrzeby podczas przetwarzania.
W przypadku zasobu pamięci CUDA „Zoptymalizowane jądro” wykazuje przyspieszenie 10x-15x, które zaczyna spadać przy większej liczbie wierszy ze względu na rosnący rozmiar alokacji (Rysunek 3). Korzystanie z zasobu pamięci w puli łagodzi ten efekt i utrzymuje 15-25-krotne przyspieszenie w porównaniu z podejściem API łańcuchów libcudf.
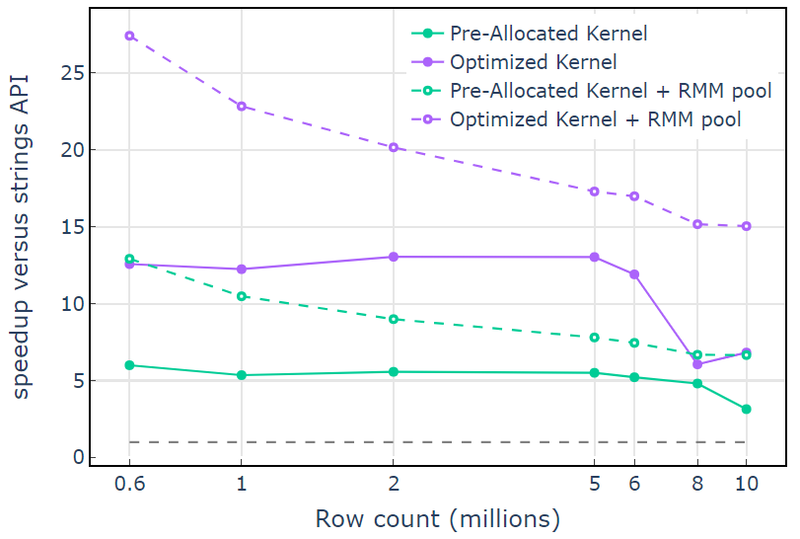 Rysunek 3. Przyspieszenie z niestandardowych jąder „Wstępnie przydzielone jądro” i „Zoptymalizowane jądro” z domyślnym zasobem pamięci CUDA (pełne) i zasobem pamięci puli (przerywana) w porównaniu z interfejsem API ciągów znaków libcudf przy użyciu domyślnego zasobu pamięci CUDA
Rysunek 3. Przyspieszenie z niestandardowych jąder „Wstępnie przydzielone jądro” i „Zoptymalizowane jądro” z domyślnym zasobem pamięci CUDA (pełne) i zasobem pamięci puli (przerywana) w porównaniu z interfejsem API ciągów znaków libcudf przy użyciu domyślnego zasobu pamięci CUDA
W przypadku zasobu puli pamięci zademonstrowano całkowitą przepustowość pamięci zbliżającą się do teoretycznego limitu dla algorytmu dwuprzebiegowego. „Zoptymalizowane jądro” osiąga przepustowość 320-340 GB/s, mierzoną na podstawie rozmiaru wejść, rozmiaru wyjść i czasu obliczeniowego (Rysunek 4).
Podejście dwuprzebiegowe najpierw mierzy rozmiary elementów wyjściowych, przydziela pamięć, a następnie ustawia pamięć z wyjściami. Biorąc pod uwagę algorytm przetwarzania dwuprzebiegowego, implementacja w „Zoptymalizowanym jądrze” działa blisko limitu przepustowości pamięci. „Kompleksowa przepustowość pamięci” jest zdefiniowana jako wielkość danych wejściowych i wyjściowych w GB podzielona przez czas obliczeń. *Przepustowość pamięci RTX A6000 (768 GB/s).
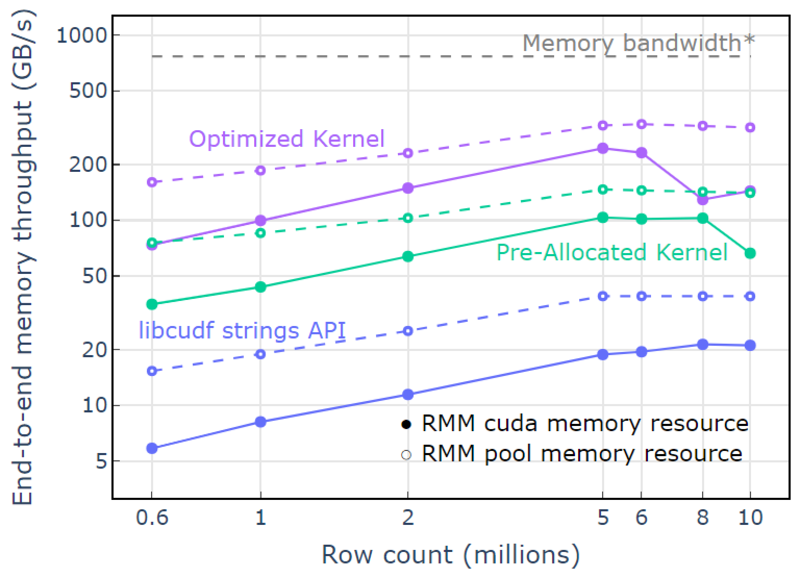 Rysunek 4. Przepustowość pamięci dla „zoptymalizowanego jądra”, „wstępnie przydzielonego jądra” i „interfejsu API łańcuchów libcudf” jako funkcja liczby wierszy wejścia/wyjścia
Rysunek 4. Przepustowość pamięci dla „zoptymalizowanego jądra”, „wstępnie przydzielonego jądra” i „interfejsu API łańcuchów libcudf” jako funkcja liczby wierszy wejścia/wyjścia
Ten post pokazuje dwa podejścia do pisania wydajnych transformacji danych łańcuchowych w libcudf. Interfejs API ogólnego przeznaczenia libcudf jest szybki i prosty dla programistów oraz zapewnia dobrą wydajność. libcudf zapewnia również narzędzia po stronie urządzenia zaprojektowane do użytku z niestandardowymi jądrami, w tym przykładzie odblokowując >10x wyższą wydajność.
Zastosuj swoją wiedzę
Aby rozpocząć korzystanie z RAPIDS cuDF, odwiedź stronę Rapidsai/cudf Repozytorium GitHub. Jeśli jeszcze nie wypróbowałeś cuDF i libcudf do obsługi obciążeń związanych z przetwarzaniem ciągów znaków, zachęcamy do przetestowania najnowszej wersji. Docker containers są dostępne zarówno dla wydań, jak i nocnych kompilacji. Pakiety Condy są również dostępne w celu ułatwienia testowania i wdrażania. Jeśli już używasz cuDF, zachęcamy do uruchomienia nowego przykładu transformacji łańcuchów, odwiedzając stronę rapidsai/cudf/drzewo/HEAD/cpp/przykłady/ciągi na GitHub.
Dawid Wendt jest starszym inżynierem oprogramowania systemowego w firmie NVIDIA, opracowującym kod C++/CUDA dla RAPIDS. David posiada tytuł magistra elektrotechniki uzyskany na Uniwersytecie Johnsa Hopkinsa.
Grzegorz Kimball jest menedżerem ds. inżynierii oprogramowania w firmie NVIDIA pracującym w zespole RAPIDS. Gregory kieruje rozwojem libcudf, biblioteki CUDA/C++ do kolumnowego przetwarzania danych, która napędza RAPIDS cuDF. Gregory posiada doktorat z fizyki stosowanej z California Institute of Technology.
Oryginalny. Przesłane za zgodą.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- O nas
- powyżej
- przyspieszenie
- Akceptuje
- dostęp
- dostęp
- realizowane
- w poprzek
- w dodatku
- Dodaje
- algorytm
- Wszystkie kategorie
- przydziela
- przydział
- już
- ilość
- analiza
- i
- Inne
- Apache
- api
- Pszczoła
- aplikacje
- stosowany
- podejście
- awanse
- zbliżający się
- na około
- Szyk
- powiązany
- samochód
- automatycznie
- dostępny
- średni
- przepustowość
- Baseline
- bo
- zanim
- jest
- poniżej
- korzystny
- Korzyści
- BEST
- pomiędzy
- Niebieski
- awaria
- bufor
- budować
- Budowanie
- Buduje
- wybudowany
- C + +
- California
- wezwanie
- nazywa
- powołanie
- Połączenia
- nie może
- walizka
- Etui
- spowodowanie
- Zmiany
- charakter
- znaków
- dziecko
- klasa
- Zamknij
- kod
- Kolumna
- kolumny
- połączyć
- porównanie
- kompletny
- Zakończony
- składniki
- obliczenia
- obliczać
- Rozważać
- Składający się
- skonstruować
- zawiera
- konwertować
- przeliczone
- biurowy
- Odpowiedni
- Koszty:
- Stwórz
- stworzony
- tworzy
- tworzenie
- zwyczaj
- dane
- analiza danych
- nauka danych
- David
- Domyślnie
- Stopień
- dostarcza
- wykazać
- Wdrożenie
- zaprojektowany
- projektowanie
- deweloperzy
- rozwijanie
- oprogramowania
- urządzenie
- różne
- bezpośrednio
- omówione
- podzielony
- Doker
- Spadek
- podczas
- dynamiczny
- każdy
- łatwiej
- efekt
- wydajny
- skutecznie
- Inżynieria elektryczna
- Elementy
- wyeliminować
- umożliwiać
- zachęcać
- koniec końców
- inżynier
- Inżynieria
- Cały
- wejście
- Eter (ETH)
- Parzyste
- wszystko
- przykład
- przykłady
- doskonała
- Z wyjątkiem
- egzekucja
- spodziewany
- zewnętrzny
- dodatkowy
- wyciąg
- fabryka
- FAST
- szybciej
- Cecha
- Korzyści
- Postać
- filtracja
- finał
- W końcu
- i terminów, a
- ustalony
- obserwuj
- następnie
- następujący
- Nasz formularz
- format
- Darmowy
- często
- od
- z przodu
- w pełni
- funkcjonować
- Funkcje
- dalej
- Wzrost
- Ogólne
- generuje
- otrzymać
- GitHub
- dany
- Globalne
- dobry
- GPU
- gwarantowane
- Uchwyty
- mający
- tutaj
- wyższy
- Najwyższa
- posiada
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- idealny
- identyfikacja
- niezmienny
- wdrożenia
- realizacja
- realizowane
- podnieść
- poprawa
- poprawia
- in
- włączony
- Włącznie z
- Zwiększać
- wzrastający
- wskaźnik
- indywidualny
- Informacja
- początkowy
- wkład
- Instytut
- wewnętrzny
- IT
- samo
- Johns Hopkins
- Johns Hopkins University
- łączący
- Knuggety
- Trzymać
- Klawisz
- wiedza
- Etykieta
- duży
- większe
- Nazwisko
- Utajenie
- firmy
- Najnowsze wydanie
- uruchomiona
- uruchamia
- wodowanie
- Wyprowadzenia
- nauka
- Długość
- Biblioteka
- lekki
- LIMIT
- Ograniczenia
- załadunek
- lokalizacja
- maszyna
- uczenie maszynowe
- Główny
- utrzymuje
- robić
- WYKONUJE
- Dokonywanie
- zarządzanie
- i konserwacjami
- kierownik
- zarządzający
- wiele
- mistrz
- Mastering
- Mecz
- znaczy
- zmierzyć
- środków
- Pamięć
- metoda
- może
- milion
- nic
- jeszcze
- bardziej wydajny
- porusza się
- MS
- wielokrotność
- Nazwa
- Nazwy
- Potrzebować
- potrzebne
- Nowości
- numer
- Nvidia
- obiekty
- offset
- ONE
- otwarcie
- działać
- działa
- operacje
- Okazja
- Inne
- płatny
- Parallel
- parametr
- część
- minęło
- Szczyt
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- wykonuje
- okresy
- pozwolenie
- perspektywa
- Fizyka
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- plus
- punkt
- basen
- zaludniony
- position
- Pozycje
- Post
- mocny
- uprawnienia
- poprzedni
- przetwarzanie
- produkować
- Profilowanie
- zaproponować
- pod warunkiem,
- zapewnia
- publiczny
- cel
- jakość
- zasięg
- Osiąga
- Czytaj
- rozsądny
- otrzymuje
- rekord
- Zredukowany
- zmniejsza
- Refaktoryzacja
- odzwierciedla
- regiony
- zwolnić
- prasowe
- pozostały
- reprezentowanie
- reprezentuje
- Zasób
- dalsze
- powrót
- powraca
- RZĄD
- run
- bieganie
- taki sam
- nauka
- druga
- senior
- Sekwencja
- służy
- Zestawy
- Share
- powinien
- pokazane
- Targi
- znaczący
- podobny
- po prostu
- ponieważ
- pojedynczy
- Rozmiar
- rozmiary
- mniejszy
- So
- Tworzenie
- Software Engineer
- Inżynieria oprogramowania
- solidny
- rozwiązanie
- Rozwiązania
- Źródło
- Typ przestrzeni
- specyficzny
- swoiście
- określony
- przemówienie
- prędkość
- spędził
- dzielić
- początek
- rozpoczęty
- Startowy
- Rynek
- Cel
- Nadal
- sklep
- przechowywany
- sklep
- bezpośredni
- strumień
- Struktura
- zdziwiony
- systemy
- trwa
- zespół
- Technologia
- tymczasowy
- test
- Testowanie
- Połączenia
- ich
- teoretyczny
- w związku z tym
- Przez
- wydajność
- czas
- do
- razem
- narzędzie
- Zestaw narzędzi
- narzędzia
- Kwota produktów:
- Przekształcać
- Transformacja
- przemiany
- przekształcony
- transformatorowy
- tv
- typy
- typowy
- zasadniczy
- uniwersytet
- odblokować
- odblokowywanie
- us
- posługiwać się
- Użytkowe
- Cenny
- Cenne informacje
- Przeciw
- widoczność
- widoczny
- istotny
- który
- Podczas
- szeroki
- Szeroki zasięg
- będzie
- w ciągu
- bez
- Praca
- pracujący
- działa
- by
- napisać
- pisanie
- X
- Twój
- zefirnet










