Image by Freepik
Konwersacyjna sztuczna inteligencja odnosi się do wirtualnych agentów i chatbotów, które naśladują interakcje międzyludzkie i mogą angażować ludzi w rozmowę. Korzystanie z konwersacyjnej sztucznej inteligencji szybko staje się sposobem na życie – od proszenia Alexy o „znajdź najbliższą restaurację” do poproszenia Siri o „utwórz przypomnienie”, wirtualni asystenci i chatboty są często wykorzystywane do odpowiadania na pytania konsumentów, rozpatrywania reklamacji, dokonywania rezerwacji i wielu innych.
Opracowanie tych wirtualnych asystentów wymaga znacznego wysiłku. Jednakże zrozumienie i stawienie czoła kluczowym wyzwaniom może usprawnić proces rozwoju. Wykorzystałem swoje doświadczenie z pierwszej ręki w tworzeniu dojrzałego chatbota dla platformy rekrutacyjnej jako punkt odniesienia do wyjaśnienia kluczowych wyzwań i odpowiadających im rozwiązań.
Aby zbudować konwersacyjnego chatbota AI, programiści mogą używać platform takich jak RASA, Lex firmy Amazon lub Dialogflow firmy Google do tworzenia chatbotów. Większość woli RASA, gdy planują niestandardowe zmiany lub bot jest w fazie dojrzałej, ponieważ jest to framework typu open source. Inne frameworki są również odpowiednie jako punkt wyjścia.
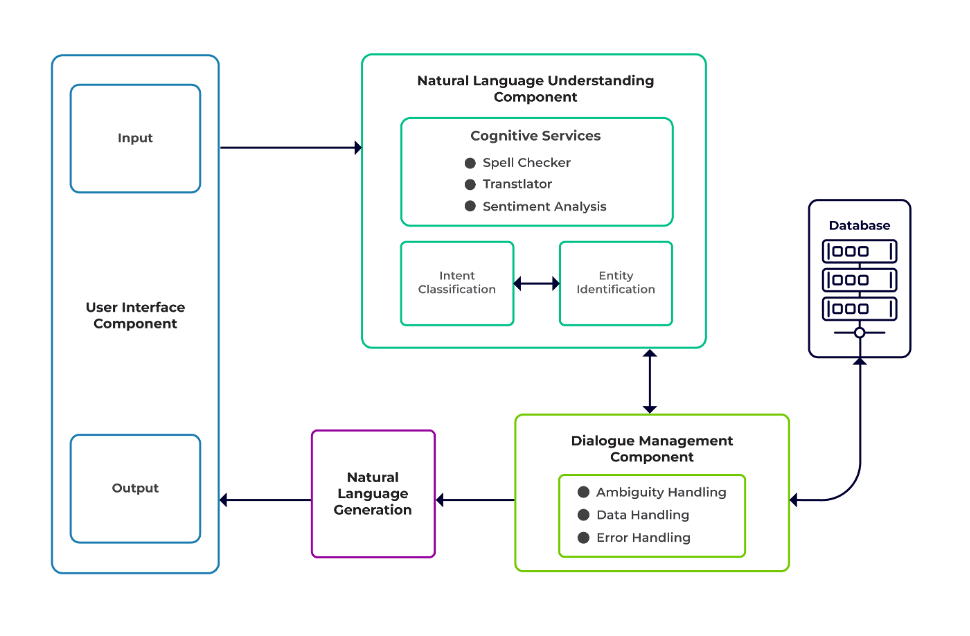
Wyzwania można podzielić na trzy główne elementy chatbota.
Rozumienie języka naturalnego (NLU) to zdolność bota do rozumienia ludzkiego dialogu. Wykonuje klasyfikację intencji, wyodrębnianie jednostek i pobieranie odpowiedzi.
Menedżer Dialogu odpowiada za zestaw działań, które mają zostać wykonane w oparciu o bieżący i poprzedni zestaw danych wejściowych użytkownika. Otrzymuje intencje i byty jako dane wejściowe (jako część poprzedniej rozmowy) i identyfikuje następną odpowiedź.
Generowanie języka naturalnego (NLG) to proces generowania zdań pisanych lub mówionych na podstawie podanych danych. Ramuje odpowiedź, która jest następnie prezentowana użytkownikowi.
Obraz z oprogramowania Talentica
Niedostateczna ilość danych
Kiedy programiści zastępują często zadawane pytania lub inne systemy wsparcia chatbotem, otrzymują przyzwoitą ilość danych szkoleniowych. Ale to samo nie dzieje się, gdy tworzą bota od zera. W takich przypadkach programiści generują dane szkoleniowe w sposób syntetyczny.
Co robić?
Generator danych oparty na szablonach może wygenerować przyzwoitą liczbę zapytań użytkowników na potrzeby szkolenia. Gdy chatbot będzie gotowy, właściciele projektów mogą udostępnić go ograniczonej liczbie użytkowników w celu ulepszenia danych szkoleniowych i uaktualnienia ich w pewnym okresie.
Nieodpowiedni dobór modelu
Odpowiedni wybór modelu i dane szkoleniowe mają kluczowe znaczenie dla uzyskania najlepszych intencji i wyników ekstrakcji jednostek. Deweloperzy zazwyczaj szkolą chatboty w określonym języku i domenie, a większość dostępnych wstępnie wytrenowanych modeli jest często specyficzna dla domeny i przeszkolona w jednym języku.
Mogą wystąpić również przypadki języków mieszanych, w których ludzie są poliglotami. Mogą wprowadzać zapytania w języku mieszanym. Na przykład w regionie zdominowanym przez Francję ludzie mogą używać języka angielskiego będącego mieszanką francuskiego i angielskiego.
Co robić?
Korzystanie z modeli przeszkolonych w wielu językach może zmniejszyć problem. W takich przypadkach pomocny może być wstępnie wyszkolony model, taki jak LaBSE (osadzanie zdań Berta niezależnie od języka). LaBSE jest szkolony w ponad 109 językach w ramach zadania dotyczącego podobieństwa zdań. Modelka zna już podobne słowa w innym języku. W naszym projekcie sprawdziło się to naprawdę dobrze.
Niewłaściwe wyodrębnienie jednostek
Chatboty wymagają od podmiotów określenia, jakiego rodzaju danych szuka użytkownik. Podmioty te obejmują czas, miejsce, osobę, przedmiot, datę itp. Jednak botom może nie udało się zidentyfikować podmiotu z języka naturalnego:
Ten sam kontekst, ale różne podmioty. Na przykład boty mogą pomylić miejsce z całością, gdy użytkownik wpisze „Nazwisko studentów z IIT Delhi”, a następnie „Nazwisko studentów z Bengaluru”.
Scenariusze, w których elementy są błędnie przewidywane z niskim poziomem pewności. Na przykład bot może zidentyfikować IIT Delhi jako miasto o niskim poziomie pewności.
Częściowa ekstrakcja jednostek za pomocą modelu uczenia maszynowego. Jeśli użytkownik wpisze „studenci z IIT Delhi”, model może zidentyfikować „IIT” tylko jako jednostkę, a nie „IIT Delhi”.
Wprowadzanie pojedynczych słów bez kontekstu może zmylić modele uczenia maszynowego. Na przykład słowo „Rishikesh” może oznaczać zarówno imię osoby, jak i miasto.
Co robić?
Rozwiązaniem może być dodanie większej liczby przykładów szkoleniowych. Istnieje jednak granica, powyżej której dodanie kolejnych nie pomoże. Co więcej, jest to proces niekończący się. Innym rozwiązaniem mogłoby być zdefiniowanie wzorców wyrażeń regularnych przy użyciu wstępnie zdefiniowanych słów, co pomoże wyodrębnić elementy o znanym zestawie możliwych wartości, takich jak miasto, kraj itp.
Modele charakteryzują się mniejszą pewnością, gdy nie są pewne przewidywania jednostek. Programiści mogą użyć tego jako wyzwalacza do wywołania komponentu niestandardowego, który może naprawić element o niskim stopniu pewności. Rozważmy powyższy przykład. Jeśli IIT Delhi jest przewidywane jako miasto o niskim poziomie pewności, wówczas użytkownik zawsze może je wyszukać w bazie danych. Po nieudanym znalezieniu przewidywanej jednostki w pliku Miasto tabeli, model przejdzie do innych tabel i ostatecznie znajdzie go w tabeli Instytut tabeli, co skutkuje korektą jednostki.
Zła klasyfikacja intencji
Z każdą wiadomością użytkownika wiąże się jakiś cel. Ponieważ intencje wyznaczają dalszy przebieg działań bota, kluczowa jest poprawna klasyfikacja zapytań użytkowników na podstawie intencji. Jednak programiści muszą identyfikować intencje przy minimalnym zamieszaniu między intencjami. W przeciwnym razie mogą wystąpić przypadki obarczone zamieszaniem. Na przykład, "Pokaż mi wolne stanowiska” vs. "Pokaż mi kandydatów na wolne stanowiska”.
Co robić?
Istnieją dwa sposoby rozróżniania mylących zapytań. Po pierwsze, programista może wprowadzić podintencję. Po drugie, modele mogą obsługiwać zapytania w oparciu o zidentyfikowane podmioty.
Chatbot domeny powinien być systemem zamkniętym, w którym powinien jasno określić, do czego jest zdolny, a czego nie. Programiści muszą wykonywać prace programistyczne etapami, planując chatboty specyficzne dla domeny. Na każdym etapie mogą zidentyfikować nieobsługiwane funkcje chatbota (poprzez nieobsługiwane intencje).
Mogą także zidentyfikować, czego chatbot nie może obsłużyć w zamiarze „poza zakresem”. Mogą się jednak zdarzyć przypadki, gdy bot będzie zdezorientowany z powodu nieobsługiwanego i wykraczającego poza zakres celu. W przypadku takich scenariuszy powinien istnieć mechanizm awaryjny, w przypadku którego, jeśli pewność zamierzenia jest poniżej progu, model może sprawnie działać z zamiarem awaryjnym, aby poradzić sobie z przypadkami zamieszania.
Gdy bot zidentyfikuje intencję wiadomości użytkownika, musi odesłać odpowiedź. Bot decyduje o odpowiedzi w oparciu o pewien zestaw zdefiniowanych zasad i historii. Na przykład reguła może być tak prosta, jak całkowita "dzień dobry" kiedy użytkownik się wita "Cześć". Najczęściej jednak rozmowy z chatbotami mają charakter uzupełniający, a ich reakcje zależą od ogólnego kontekstu rozmowy.
Co robić?
Aby sobie z tym poradzić, chatboty są karmione prawdziwymi przykładami rozmów zwanymi Stories. Jednak użytkownicy nie zawsze wchodzą w interakcję zgodnie z zamierzeniami. Dojrzały chatbot powinien z wdziękiem radzić sobie z takimi odchyleniami. Projektanci i programiści mogą to zagwarantować, jeśli podczas pisania historii nie skupiają się tylko na szczęśliwej ścieżce, ale także pracują na nieszczęśliwych ścieżkach.
Zaangażowanie użytkowników w chatboty w dużej mierze opiera się na odpowiedziach chatbotów. Użytkownicy mogą stracić zainteresowanie, jeśli odpowiedzi będą zbyt automatyczne lub zbyt znajome. Na przykład użytkownikowi może nie spodobać się odpowiedź w stylu „Wpisałeś nieprawidłowe zapytanie” w przypadku nieprawidłowego wprowadzenia danych, mimo że odpowiedź jest poprawna. Odpowiedź tutaj nie pasuje do osobowości asystenta.
Co robić?
Chatbot pełni funkcję asystenta i powinien posiadać określoną osobowość oraz ton głosu. Powinni być gościnni i pokorni, a programiści powinni odpowiednio projektować rozmowy i wypowiedzi. Odpowiedzi nie powinny sprawiać wrażenia robota ani mechanicznego. Bot może na przykład powiedzieć: „Przepraszam, wygląda na to, że nie mam żadnych szczegółów. Czy mógłbyś ponownie wpisać zapytanie?” aby zaadresować błędne dane wejściowe.
Chatboty oparte na LLM (Large Language Model), takie jak ChatGPT i Bard, to innowacje zmieniające zasady gry i poprawiające możliwości konwersacyjnych AI. Nie tylko dobrze radzą sobie z prowadzeniem otwartych rozmów przypominających ludzkie, ale potrafią wykonywać różne zadania, takie jak podsumowywanie tekstu, pisanie akapitów itp., Które wcześniej można było osiągnąć jedynie za pomocą określonych modeli.
Jednym z wyzwań związanych z tradycyjnymi systemami chatbotów jest kategoryzowanie każdego zdania według intencji i odpowiednie podejmowanie decyzji o odpowiedzi. To podejście nie jest praktyczne. Odpowiedzi takie jak „Przepraszam, nie mogłem cię złapać” często są irytujące. Rozwiązaniem są bezintencjonalne systemy chatbotów, a firmy LLM mogą sprawić, że stanie się to rzeczywistością.
LLM mogą z łatwością osiągnąć najnowocześniejsze wyniki w zakresie ogólnego rozpoznawania nazwanych jednostek, z wyjątkiem rozpoznawania niektórych jednostek specyficznych dla domeny. Mieszane podejście do korzystania z LLM z dowolnym frameworkiem chatbota może zainspirować bardziej dojrzały i solidny system chatbota.
Dzięki najnowszym osiągnięciom i ciągłym badaniom nad konwersacyjną sztuczną inteligencją chatboty są z każdym dniem coraz lepsze. Dużą uwagę poświęca się obszarom takim jak wykonywanie złożonych zadań o wielu celach, takich jak „Zarezerwuj lot do Bombaju i zorganizuj taksówkę do Dadar”.
Wkrótce będą prowadzone spersonalizowane rozmowy w oparciu o cechy użytkownika, aby utrzymać jego zaangażowanie. Na przykład, jeśli bot stwierdzi, że użytkownik jest niezadowolony, przekierowuje rozmowę do prawdziwego agenta. Dodatkowo, przy stale rosnącej liczbie danych chatbota, techniki głębokiego uczenia się, takie jak ChatGPT, mogą automatycznie generować odpowiedzi na zapytania przy użyciu bazy wiedzy.
Suman Sauraw jest analitykiem danych w Talentica Software, firmie zajmującej się rozwojem oprogramowania. Jest absolwentem NIT Agartala z ponad 8-letnim doświadczeniem w projektowaniu i wdrażaniu rewolucyjnych rozwiązań AI z wykorzystaniem NLP, Conversational AI i Generative AI.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :ma
- :Jest
- :nie
- :Gdzie
- 8
- a
- zdolność
- O nas
- powyżej
- odpowiednio
- Osiągać
- osiągnięty
- w poprzek
- działania
- dodanie
- do tego
- adres
- adresowanie
- postępy
- Po
- Agent
- agentów
- AI
- Chatbot AI
- Alexa
- Wszystkie kategorie
- już
- również
- absolwent
- zawsze
- ilość
- an
- i
- Inne
- odpowiedź
- każdy
- podejście
- SĄ
- obszary
- AS
- pytanie
- Asystent
- asystenci
- powiązany
- At
- Uwaga
- automatycznie
- dostępny
- uniknąć
- z powrotem
- baza
- na podstawie
- BE
- staje
- istoty
- poniżej
- BEST
- Ulepsz Swój
- Bot
- obie
- boty
- budować
- ale
- by
- wezwanie
- nazywa
- CAN
- nie może
- możliwości
- zdolny
- Etui
- kategoryzowanie
- pewien
- wyzwania
- Zmiany
- Charakterystyka
- chatbot
- nasze chatboty
- ChatGPT
- Miasto
- klasyfikacja
- sklasyfikowany
- wyraźnie
- zamknięte
- sukcesy firma
- skarg
- kompleks
- składnik
- składniki
- zrozumieć
- pewność siebie
- zmieszany
- mylące
- zamieszanie
- Rozważać
- kontekst
- ciągły
- Rozmowa
- konwersacyjny
- konwersacyjna sztuczna inteligencja
- rozmowy
- skorygowania
- prawidłowo
- Odpowiedni
- mógłby
- kraj
- kurs
- Stwórz
- Tworzenie
- istotny
- Aktualny
- zwyczaj
- dane
- naukowiec danych
- Baza danych
- Data
- dzień
- przyzwoity
- Decydowanie
- głęboko
- głęboka nauka
- określić
- zdefiniowane
- Delhi
- zależeć
- czerpać
- Wnętrze
- projektanci
- projektowanie
- detale
- Deweloper
- deweloperzy
- oprogramowania
- przepływ dialogów
- Dialog
- różne
- różnicować
- do
- Nie
- domena
- nie
- każdy
- Wcześniej
- z łatwością
- wysiłek
- osadzanie
- Nieskończony
- zobowiązany
- zaangażowany
- zaręczynowy
- Angielski
- wzmacniać
- Wchodzę
- podmioty
- jednostka
- itp
- Parzyste
- ostatecznie
- stale rosnący
- Każdy
- codziennie
- przykład
- przykłady
- doświadczenie
- Wyjaśniać
- wyciąg
- ekstrakcja
- FAIL
- nie
- znajomy
- FAST
- Korzyści
- nakarmiony
- Znajdź
- znajduje
- lot
- Skupiać
- W razie zamówieenia projektu
- Naprzód
- Framework
- Ramy
- francuski
- od
- Ogólne
- Generować
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- generator
- otrzymać
- miejsce
- dany
- dobry
- Google'a
- gwarancja
- uchwyt
- Prowadzenie
- zdarzyć
- Zaoszczędzić
- Have
- mający
- he
- ciężko
- pomoc
- pomocny
- tutaj
- W jaki sposób
- How To
- Jednak
- HTTPS
- człowiek
- pokorny
- i
- zidentyfikowane
- identyfikuje
- zidentyfikować
- if
- wykonawczych
- ulepszony
- in
- zawierać
- innowacje
- wkład
- Wejścia
- inspirować
- przykład
- zamiast
- zamierzony
- zamiar
- interakcji
- wzajemne oddziaływanie
- Interakcje
- odsetki
- najnowszych
- przedstawiać
- IT
- jpg
- właśnie
- Knuggety
- Trzymać
- Klawisz
- Uprzejmy
- wiedza
- znany
- wie
- język
- Języki
- duży
- firmy
- nauka
- życie
- lubić
- LIMIT
- Ograniczony
- stracić
- niski
- niższy
- maszyna
- uczenie maszynowe
- poważny
- robić
- Dokonywanie
- Mecz
- dojrzały
- Może..
- me
- oznaczać
- mechaniczny
- mechanizm
- wiadomość
- może
- minimalny
- mieszać
- mieszany
- model
- modele
- jeszcze
- Ponadto
- większość
- dużo
- wielokrotność
- Bombaj
- musi
- my
- Nazwa
- O imieniu
- Naturalny
- Język naturalny
- Następny
- NLG
- nlp
- nie
- Nie
- numer
- of
- często
- on
- pewnego razu
- tylko
- koncepcja
- open source
- or
- Inne
- Inaczej
- ludzkiej,
- koniec
- ogólny
- właściciele
- część
- ścieżka
- ścieżki
- wzory
- Ludzie
- wykonać
- wykonywane
- wykonuje
- okres
- osoba
- Personalizowany
- faza
- fazy
- Miejsce
- krok po kroku
- planowanie
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Proszę
- punkt
- position
- posiadać
- możliwy
- Praktyczny
- Przewiduje
- przepowiednia
- woleć
- przedstawione
- poprzedni
- Problem
- kontynuować
- wygląda tak
- Produkt
- rozwój produktów
- projekt
- zapytania
- pytania
- R
- rasa
- gotowy
- real
- Rzeczywistość
- naprawdę
- uznanie
- rekrutacja
- zmniejszyć
- odniesienie
- odnosi
- region
- polegać
- przypomnienie
- obsługi produkcji rolnej, która zastąpiła
- wymagać
- Wymaga
- Badania naukowe
- rozwiązać
- odpowiedź
- Odpowiedzi
- odpowiedzialny
- wynikły
- Efekt
- rewolucyjny
- krzepki
- Zasada
- reguły
- taki sam
- powiedzieć
- scenariusze
- Naukowiec
- zadraśnięcie
- Szukaj
- poszukiwania
- wydaje
- wybór
- wysłać
- wyrok
- służy
- zestaw
- Share
- powinien
- podobny
- Prosty
- ponieważ
- pojedynczy
- Siri
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Dźwięk
- specyficzny
- mówiony
- STAGE
- Startowy
- state-of-the-art
- historie
- opływowy
- Studenci
- znaczny
- taki
- odpowiedni
- wsparcie
- Systemy wsparcia
- pewnie
- syntetycznie
- system
- systemy
- T
- stół
- Brać
- trwa
- Zadanie
- zadania
- Techniki
- XNUMX
- niż
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- Te
- one
- to
- chociaż?
- trzy
- próg
- czas
- do
- TON
- Ton głosu
- także
- tradycyjny
- Pociąg
- przeszkolony
- Trening
- wyzwalać
- drugiej
- rodzaj
- typy
- zrozumienie
- uaktualnienie
- posługiwać się
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- zazwyczaj
- Wartości
- przez
- Wirtualny
- Głos
- vs
- W
- Droga..
- sposoby
- powitanie
- DOBRZE
- Co
- jeśli chodzi o komunikację i motywację
- ilekroć
- który
- Podczas
- będzie
- w
- słowo
- słowa
- Praca
- pracował
- by
- pisanie
- napisany
- Źle
- lat
- ty
- Twój
- zefirnet