
Obraz z Adobe Firefly
„Było nas za dużo. Mieliśmy dostęp do za dużo pieniędzy, za dużo sprzętu i stopniowo popadaliśmy w szaleństwo”.
Francis Ford Coppola nie robił metafory firm zajmujących się sztuczną inteligencją, które wydają za dużo i tracą orientację, ale mógł to zrobić. Apocalypse Now był epicki, ale także długi, trudny i kosztowny projekt, podobnie jak GPT-4. Sugerowałbym, że rozwój LLM wiąże się ze zbyt dużą ilością pieniędzy i zbyt dużą ilością sprzętu. A część szumu w stylu „właśnie wynaleźliśmy inteligencję ogólną” jest trochę szalona. Ale teraz przyszła kolej na społeczności open source, aby zrobiły to, co potrafią najlepiej: dostarczanie darmowego, konkurencyjnego oprogramowania przy użyciu znacznie mniejszych środków i sprzętu.
OpenAI pozyskało ponad 11 miliardów dolarów finansowania i szacuje się, że GPT-3.5 kosztuje 5–6 milionów dolarów na przebieg szkolenia. Niewiele wiemy o GPT-4, ponieważ OpenAI nic nam nie mówi, ale myślę, że można bezpiecznie założyć, że nie jest on mniejszy niż GPT-3.5. Obecnie na całym świecie brakuje procesorów graficznych i – dla odmiany – nie jest to spowodowane najnowszą kryptowalutą. Start-upy generujące sztuczną inteligencję otrzymują rundy serii A o wartości ponad 100 milionów dolarów przy ogromnych wycenach, gdy nie posiadają żadnej własności intelektualnej do LLM, którego używają do zasilania swojego produktu. Moda na LLM jest na wysokich obrotach, a pieniądze płyną.
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
Na szczęście grupa mądrych ludzi i projekty open source potraktowały to raczej jako wyzwanie, a nie ograniczenie. Naukowcy ze Stanford opublikowali Alpaca, model o 7 miliardach parametrów, którego wydajność jest zbliżona do modelu GPT-3.5 o 175 miliardach parametrów. Nie mając zasobów do zbudowania zestawu szkoleniowego o rozmiarze używanym przez OpenAI, sprytnie zdecydowali się zamiast tego skorzystać z wytrenowanego open source LLM, LLaMA i dostroić go w oparciu o serię podpowiedzi i wyników GPT-3.5. Zasadniczo model nauczył się, co robi GPT-3.5, co okazuje się być bardzo skuteczną strategią replikowania jego zachowania.
Alpaca jest licencjonowana do użytku niekomercyjnego wyłącznie w zakresie kodu i danych, ponieważ korzysta z niekomercyjnego modelu LLaMA o otwartym kodzie źródłowym, a OpenAI wyraźnie zabrania jakiegokolwiek wykorzystywania swoich interfejsów API do tworzenia konkurencyjnych produktów. Stwarza to kuszącą perspektywę dostrojenia innego open source LLM na podstawie podpowiedzi i wyników Alpaca… tworząc trzeci model podobny do GPT-3.5 z różnymi możliwościami licencjonowania.
Jest w tym jeszcze jedna ironia polegająca na tym, że wszystkie główne LLM zostały przeszkolone w zakresie tekstów i obrazów chronionych prawem autorskim dostępnych w Internecie i nie zapłaciły ani grosza posiadaczom praw. Firmy domagają się zwolnienia z „dozwolonego użytku” na mocy amerykańskiego prawa autorskiego, argumentując, że wykorzystanie ma charakter „przekształcający”. Jeśli jednak chodzi o wyniki modeli, które budują z bezpłatnych danych, naprawdę nie chcą, aby ktokolwiek zrobił im to samo. Spodziewam się, że to się zmieni, gdy posiadacze praw zmądrzeją, i może w pewnym momencie skończyć się sprawą w sądzie.
Jest to odrębna i odrębna kwestia w stosunku do tej podnoszonej przez autorów otwartego oprogramowania objętego restrykcyjną licencją, którzy w przypadku generatywnej sztucznej inteligencji dla produktów Code, takich jak CoPilot, sprzeciwiają się wykorzystywaniu ich kodu do celów szkoleniowych na tej podstawie, że licencja nie jest przestrzegana. Problemem poszczególnych autorów open source jest to, że muszą wykazać się solidnością – merytorycznym kopiowaniem – i tym, że ponieśli szkody. A ponieważ modele utrudniają powiązanie kodu wyjściowego z danymi wejściowymi (linie kodu źródłowego autorstwa autora) i nie ma strat ekonomicznych (powinno być bezpłatne), znacznie trudniej jest przedstawić argument. Inaczej jest w przypadku twórców nastawionych na zysk (np. fotografów), których cały model biznesowy opiera się na licencjonowaniu/sprzedaży swoich dzieł i którzy są reprezentowani przez agregatory takie jak Getty Images, które mogą wykazać istotne kopiowanie.
Kolejną interesującą rzeczą w LLaMA jest to, że wyszła z Meta. Pierwotnie został udostępniony wyłącznie badaczom, a następnie wyciekł do świata za pośrednictwem BitTorrenta. Meta prowadzi zasadniczo inną działalność niż OpenAI, Microsoft, Google i Amazon, ponieważ nie próbuje sprzedawać usług ani oprogramowania w chmurze, a zatem ma zupełnie inne zachęty. W przeszłości korzystała z oprogramowania open source w swoich projektach obliczeniowych (OpenCompute) i widziała, jak społeczność udoskonalała je – rozumie wartość otwartego oprogramowania.
Meta może okazać się jednym z najważniejszych twórców sztucznej inteligencji typu open source. Nie tylko dysponuje ogromnymi zasobami, ale także odnosi korzyści z rozprzestrzeniania się wspaniałej technologii generatywnej sztucznej inteligencji: będzie więcej treści, na których będzie mogła zarabiać w mediach społecznościowych. Meta udostępniła trzy inne modele sztucznej inteligencji typu open source: ImageBind (wielowymiarowe indeksowanie danych), DINOv2 (wizja komputerowa) i Segment Everything. Ten ostatni identyfikuje unikalne obiekty na obrazach i jest udostępniany na podstawie wysoce liberalnej licencji Apache.
Wreszcie mieliśmy także rzekomy wyciek wewnętrznego dokumentu Google „Nie mamy fosy i OpenAI też nie”, w którym nieprzychylnie ocenia się modele zamknięte w porównaniu z innowacjami społeczności tworzących znacznie mniejsze, tańsze modele, które działają blisko lub lepiej niż ich odpowiedniki o zamkniętym źródle. Mówię rzekomo, ponieważ nie ma możliwości sprawdzenia źródła artykułu jako wewnętrznego pochodzenia Google. Zawiera jednak ten przekonujący wykres:
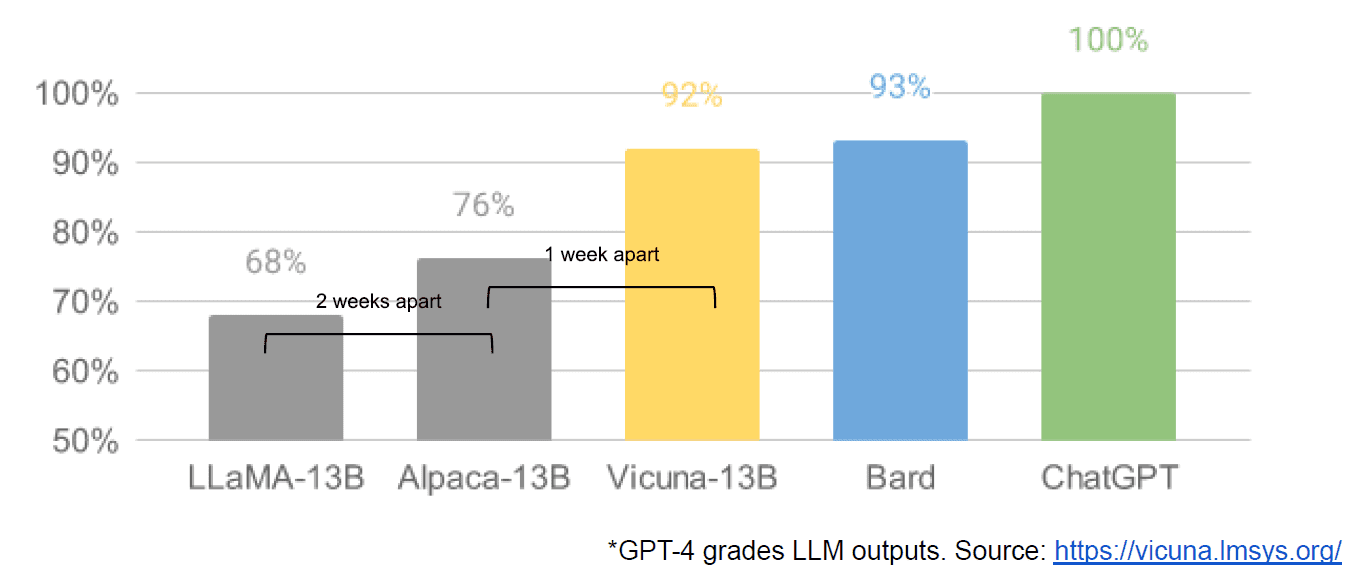
Dla jasności, oś pionowa to ocena wyników LLM według GPT-4.
Stable Diffusion, która syntetyzuje obrazy z tekstu, to kolejny przykład tego, gdzie generatywna sztuczna inteligencja typu open source mogła rozwijać się szybciej niż modele zastrzeżone. Niedawna wersja tego projektu (ControlNet) ulepszyła go do tego stopnia, że przekroczył możliwości Dall-E2. Było to wynikiem mnóstwa majsterkowania na całym świecie, co doprowadziło do tempa postępu, które jest trudne do dorównania jakiejkolwiek pojedynczej instytucji. Niektórzy z tych majsterkowiczów wymyślili, jak przyspieszyć uczenie i uruchamianie Stable Diffusion na tańszym sprzęcie, umożliwiając krótsze cykle iteracji większej liczbie osób.
I tak zatoczyliśmy koło. Brak zbyt dużej ilości pieniędzy i zbyt dużej ilości sprzętu zainspirował całą społeczność zwykłych ludzi do sprytnego poziomu innowacji. Co za czas na bycie programistą AI.
Mateusz Loża jest dyrektorem generalnym Diffblue, startupu AI For Code. Ma ponad 25-letnie różnorodne doświadczenie w kierowaniu produktami w takich firmach jak Anaconda i VMware. Lodge jest obecnie członkiem zarządu Good Law Project i zastępcą przewodniczącego Rady Nadzorczej Królewskiego Towarzystwa Fotograficznego.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 9
- a
- Zdolny
- O nas
- Akademia
- dostęp
- Adobe
- awansować
- Agregatory
- AI
- Wszystkie kategorie
- rzekomy
- rzekomo
- również
- Amazonka
- an
- i
- Inne
- każdy
- ktoś
- wszystko
- Apache
- Pszczoła
- SĄ
- argument
- artykuł
- AS
- przypuszczalny
- At
- autor
- Autorzy
- dostępny
- Oś
- BE
- bo
- być
- jest
- Korzyści
- BEST
- Ulepsz Swój
- większe
- BitTorrent
- deska
- obie
- Budżety
- budować
- Budowanie
- Pęczek
- biznes
- Model biznesowy
- ale
- by
- oprawa ołowiana witrażu
- CAN
- możliwości
- kapitał
- walizka
- ceo
- Krzesło
- wyzwanie
- zmiana
- ChatGPT
- tańsze
- wybrał
- Okrągłe
- roszczenie
- jasny
- Zamknij
- zamknięte
- Chmura
- usługi w chmurze
- kod
- jak
- byliśmy spójni, od początku
- towar
- społeczności
- społeczność
- Firmy
- zniewalający
- rywalizować
- konkurowania
- obliczać
- komputer
- Wizja komputerowa
- zawartość
- Dostawcy
- biurowy
- prawo autorskie
- Koszty:
- mógłby
- Boisko
- Stwórz
- Tworzenie
- twórcy
- kryptowaluta
- Obecnie
- Cykle
- dane
- dostarczanie
- zastępca
- projekty
- Deweloper
- oprogramowania
- Umierać
- różne
- trudny
- Transmitowanie
- odrębny
- inny
- do
- dokument
- robi
- nie
- e
- Gospodarczy
- Efektywne
- umożliwiając
- zakończenia
- Cały
- EPICKI
- sprzęt
- istotnie
- szacunkowa
- Parzyste
- przykład
- oczekiwać
- drogi
- doświadczenie
- daleko
- szybciej
- wzorzysty
- Płynący
- następnie
- W razie zamówieenia projektu
- Ford
- Darmowy
- od
- pełny
- zasadniczo
- Finansowanie
- Sprzęt
- Ogólne
- generatywny
- generatywna sztuczna inteligencja
- dobry
- GPU
- wykres
- wspaniały
- miał
- Ciężko
- sprzęt komputerowy
- Have
- mający
- he
- tutaj
- Wysoki
- wysoko
- posiadacze
- W jaki sposób
- How To
- Jednak
- HTTPS
- olbrzymi
- Szum
- i
- identyfikuje
- if
- zdjęcia
- ważny
- podnieść
- ulepszony
- in
- zachęty
- indywidualny
- Innowacja
- wkład
- SZALONY
- inspirowane
- zamiast
- Instytucja
- integracje
- ciekawy
- wewnętrzny
- Internet
- Zmyślony
- IP
- ironia
- IT
- iteracja
- JEGO
- właśnie
- Knuggety
- Wiedzieć
- lądowanie
- firmy
- Prawo
- warstwa
- Przywództwo
- dowiedziałem
- lewo
- mniej
- poziom
- Licencja
- Upoważniony
- Koncesjonowanie
- lubić
- linie
- LINK
- mało
- Lama
- długo
- wyglądał
- poszukuje
- stracić
- od
- Partia
- poważny
- robić
- Dokonywanie
- wiele
- rynek
- masywny
- Mecz
- Może..
- Media
- Meta
- Microsoft
- model
- modele
- zarabiać
- pieniądze
- jeszcze
- większość
- dużo
- Potrzebować
- Ani
- Nie
- niekomercyjny
- już dziś
- przedmiot
- obiekty
- of
- on
- ONE
- tylko
- koncepcja
- open source
- projekty open source
- OpenAI
- or
- zwykły
- pierwotnie
- Inne
- na zewnątrz
- wydajność
- koniec
- własny
- Pokój
- parametr
- Przeszłość
- Zapłacić
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- możliwości
- power
- Problem
- Produkt
- Produkty
- projekt
- projektowanie
- własność
- Perspektywa
- podnieść
- raczej
- naprawdę
- niedawny
- wydany
- reprezentowane
- Badania naukowe
- Badacze
- Zasoby
- ograniczenie
- wynikły
- prawa
- rundy
- królewski
- run
- s
- "bezpiecznym"
- taki sam
- powiedzieć
- widziany
- segment
- sprzedać
- oddzielny
- Serie
- Seria A
- służy
- Usługi
- zestaw
- niedobór
- pokazać
- ponieważ
- pojedynczy
- Rozmiar
- mniejszy
- mądry
- So
- Obserwuj Nas
- Media społecznościowe
- Społeczeństwo
- Tworzenie
- kilka
- coś
- Źródło
- Kod źródłowy
- wydać
- stabilny
- Stanford
- start-up
- startup
- Strategia
- taki
- sugerować
- domniemany
- przewyższał
- Brać
- Zadania
- trwa
- Technologia
- niż
- że
- Połączenia
- Źródło
- świat
- ich
- Im
- następnie
- Tam.
- one
- rzecz
- myśleć
- Trzeci
- to
- tych
- trzy
- czas
- do
- także
- wziął
- Pociąg
- przeszkolony
- Trening
- SKRĘCAĆ
- włącza
- dla
- rozumie
- wyjątkowy
- w odróżnieniu
- aż do
- us
- posługiwać się
- używany
- zastosowania
- za pomocą
- wyceny
- wartość
- zweryfikować
- wersja
- pionowy
- początku.
- przez
- Zobacz i wysłuchaj
- wizja
- vmware
- vs
- czekać
- chcieć
- była
- Droga..
- we
- poszedł
- były
- Co
- jeśli chodzi o komunikację i motywację
- który
- KIM
- cały
- którego
- będzie
- MĄDRY
- w
- Praca
- świat
- Źle
- ty
- zefirnet









