Apache Hudi to format otwartej tabeli, który zapewnia możliwości baz danych i hurtowni danych w jeziorach danych. Apache Hudi pomaga inżynierom danych zarządzać złożonymi wyzwaniami, takimi jak zarządzanie stale rozwijającymi się zbiorami danych z transakcjami przy jednoczesnym zachowaniu wydajności zapytań. Inżynierowie danych używają Apache Hudi do przesyłania strumieniowego obciążeń, a także do tworzenia wydajnych przyrostowych potoków danych. Hudi zapewnia stoły, transakcje, efektywne dodawanie i usuwanie, zaawansowane indeksy, usługi przetwarzania strumieniowego, dane klastrowanie i zagęszczanie optymalizacje i nadzór konkurencji, a wszystko to przy jednoczesnym przechowywaniu danych w formatach plików typu open source. Zaawansowane optymalizacje wydajności Hudi przyspieszają obciążenia analityczne w przypadku dowolnego z popularnych silników zapytań, w tym Apache Spark, Presto, Trino, Hive i tak dalej.
Wielu klientów AWS przyjęło Apache Hudi w swoich jeziorach danych zbudowanych na bazie Amazon S3 Klej AWS, bezserwerowa usługa integracji danych, która ułatwia odkrywanie, przygotowywanie, przenoszenie i integrowanie danych z wielu źródeł na potrzeby analiz, uczenia maszynowego (ML) i tworzenia aplikacji. Przeszukiwacz kleju AWS to komponent AWS Glue, który umożliwia automatyczne tworzenie metadanych tabeli z zawartości danych, bez konieczności ręcznego definiowania metadanych.
Roboty AWS Glue obsługują teraz tabele Apache Hudi, upraszczając przyjęcie Katalog danych kleju AWS jako katalog stołów Hudi. Jednym z typowych przypadków użycia jest rejestracja tabel Hudi, które nie mają definicji tabeli katalogu. Innym typowym przypadkiem użycia jest migracja z innych katalogów Hudi, takich jak metastore Hive. Podczas migracji z innych katalogów Hudi możesz utworzyć i zaplanować robota AWS Glue oraz udostępnić jedną lub więcej ścieżek Amazon S3, w których znajdują się pliki tabel Hudi. Masz możliwość podania maksymalnej głębokości ścieżek Amazon S3, które może pokonać robot AWS Glue. Przy każdym uruchomieniu roboty AWS Glue wyodrębnią informacje o schemacie i partycji oraz zaktualizują katalog danych AWS Glue Data Catalog o zmiany schematu i partycji. Roboty AWS Glue aktualizują najnowszą lokalizację pliku metadanych w katalogu danych AWS Glue Data Catalog, z którego mogą bezpośrednio korzystać silniki analityczne AWS.
Dzięki temu uruchomieniu możesz utworzyć i zaplanować robota AWS Glue, który będzie rejestrował tabele Hudi w katalogu danych AWS Glue Data Catalog. Następnie możesz podać jedną lub wiele ścieżek Amazon S3, w których znajdują się tabele Hudi. Masz możliwość zapewnienia maksymalnej głębokości ścieżek Amazon S3, które mogą przemierzać roboty. Przy każdym uruchomieniu przeszukiwacza sprawdza on każdą ze ścieżek S3 i kataloguje informacje o schemacie, takie jak nowe tabele, usunięcia i aktualizacje schematów w katalogu danych kleju AWS. Roboty indeksujące sprawdzają informacje o partycjach i dodają nowo dodane partycje do katalogu danych kleju AWS. Roboty indeksujące aktualizują także lokalizację najnowszego pliku metadanych w katalogu danych kleju AWS, z którego mogą bezpośrednio korzystać silniki analityczne AWS.
W tym poście pokazano, jak działa ta nowa możliwość indeksowania tabel Hudi.
Jak robot AWS Glue współpracuje z tabelami Hudi
Tabele Hudi dzielą się na dwie kategorie, z określonymi konsekwencjami dla każdej z nich:
- Kopiuj przy zapisie (CoW) – Dane zapisywane są w formacie kolumnowym (Parkiet), a każda aktualizacja podczas zapisu tworzy nową wersję plików.
- Scal po przeczytaniu (MoR) – Dane są przechowywane w formacie kolumnowym (Parquet) i wierszowym (Avro). Aktualizacje są rejestrowane w oparciu o wiersze
deltai są w razie potrzeby kompresowane w celu utworzenia nowych wersji plików kolumnowych.
W przypadku zestawów danych CoW za każdym razem, gdy następuje aktualizacja rekordu, plik zawierający rekord jest przepisywany ze zaktualizowanymi wartościami. W przypadku zbioru danych MoR przy każdej aktualizacji Hudi zapisuje tylko wiersz dotyczący zmienionego rekordu. MoR lepiej nadaje się do obciążeń wymagających dużej liczby zapisów lub zmian przy mniejszej liczbie odczytów. CoW lepiej sprawdza się w przypadku obciążeń wymagających dużego odczytu danych, które zmieniają się rzadziej.
Hudi udostępnia trzy typy zapytań umożliwiających dostęp do danych:
- Zapytania dotyczące migawek – Zapytania, które wyświetlają najnowszą migawkę tabeli z danego zatwierdzenia lub akcji zagęszczania. W przypadku tabel MoR zapytania migawkowe ujawniają najnowszy stan tabeli poprzez scalanie plików podstawowych i delta najnowszego wycinka pliku w momencie zapytania.
- Zapytania przyrostowe – Zapytania widzą tylko nowe dane wpisane do tabeli od czasu danego zatwierdzenia lub zagęszczenia. To skutecznie zapewnia strumienie zmian umożliwiające przyrostowe potoki danych.
- Przeczytaj zoptymalizowane zapytania – W przypadku tabel MoR zapytania uwzględniają skompresowane najnowsze dane. W przypadku tabel CoW zapytania wyświetlają najnowsze zatwierdzone dane.
W przypadku tabel z funkcją kopiowania przy zapisie roboty indeksujące tworzą pojedynczą tabelę w katalogu danych kleju AWS za pomocą narzędzia ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
W przypadku tabel scalanych po odczycie roboty indeksujące tworzą dwie tabele w AWS Glue Data Catalog dla tej samej lokalizacji tabeli:
- Tabela z przyrostkiem
_ro, który używa ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Tabela z przyrostkiem
_rt, który wykorzystuje RealTime Serde pozwalający na zapytania typu Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Podczas każdego przeszukiwania, dla każdej podanej ścieżki Hudi, roboty wykonują wywołanie API listy Amazon S3 i filtrują na podstawie .hoodie foldery i znajdź najnowszy plik metadanych w folderze metadanych tabeli Hudi.
Przeszukaj tabelę Hudi CoW za pomocą robota AWS Glue
W tej sekcji omówimy, jak przeszukać Hudi CoW za pomocą przeszukiwaczy AWS Glue.
Wymagania wstępne
Oto wymagania wstępne tego samouczka:
- Zainstaluj i skonfiguruj Interfejs wiersza poleceń AWS (AWS CLI).
- Utwórz wiadro S3, jeśli go nie masz.
- Utwórz swoją rolę IAM dla kleju AWS jeśli go nie masz. Potrzebujesz
s3:GetObjectdlas3://your_s3_bucket/data/sample_hudi_cow_table/. - Uruchom następujące polecenie, aby skopiować przykładową tabelę Hudi do segmentu S3. (Zastępować
your_s3_bucketz nazwą zasobnika S3.)
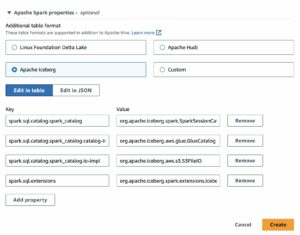
Ta instrukcja poprowadzi Cię do skopiowania przykładowych danych, ale możesz łatwo utworzyć dowolne tabele Hudi za pomocą kleju AWS. Dowiedz się więcej w Przedstawiamy natywną obsługę Apache Hudi, Delta Lake i Apache Iceberg w AWS Glue for Apache Spark, część 2: Edytor wizualny AWS Glue Studio.
Utwórz robota Hudi
W tej instrukcji utwórz przeszukiwacza za pomocą konsoli. Wykonaj następujące kroki, aby utworzyć przeszukiwacza Hudi:
- Na konsoli AWS Glue wybierz Roboty.
- Dodaj Utwórz robota.
- W razie zamówieenia projektu Imię, wchodzić
hudi_cow_crawler, Wybierać Następna. - Pod Konfiguracja źródła danych, wybierać Dodaj źródło danych.
- W razie zamówieenia projektu Źródło danychwybierz Zły.
- W razie zamówieenia projektu Dołącz ścieżki tabeli hudi, wchodzić
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Zastępowaćyour_s3_bucketz nazwą zasobnika S3.) - Dodaj Dodaj źródło danych Hudi.
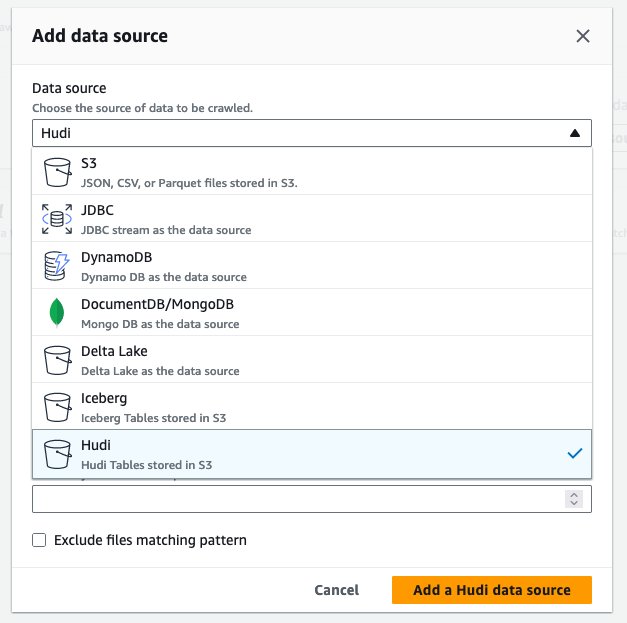
- Dodaj Następna.
- W razie zamówieenia projektu Istniejąca rola uprawnień, wybierz swoją rolę uprawnień, a następnie wybierz Następna.
- W razie zamówieenia projektu Docelowa baza danychwybierz Dodaj bazę danych, a później Dodaj bazę danych pojawi się okno dialogowe. Do Nazwa bazy danych, wchodzić
hudi_crawler_blog, A następnie wybierz Stwórz, Wybierać Następna. - Dodaj Utwórz robota.
Teraz pomyślnie utworzono nowy przeszukiwacz Hudi. Przeszukiwacz można uruchomić za pomocą konsoli lub pakietu SDK lub interfejsu wiersza polecenia AWS za pomocą polecenia StartCrawl API. Można to również zaplanować za pomocą konsoli, aby uruchomić roboty indeksujące o określonych porach. W tej instrukcji uruchom przeszukiwacz przez konsolę.
- Dodaj Uruchom robota.
- Poczekaj, aż robot się zakończy.
Po uruchomieniu robota możesz zobaczyć definicję tabeli Hudi w konsoli AWS Glue:
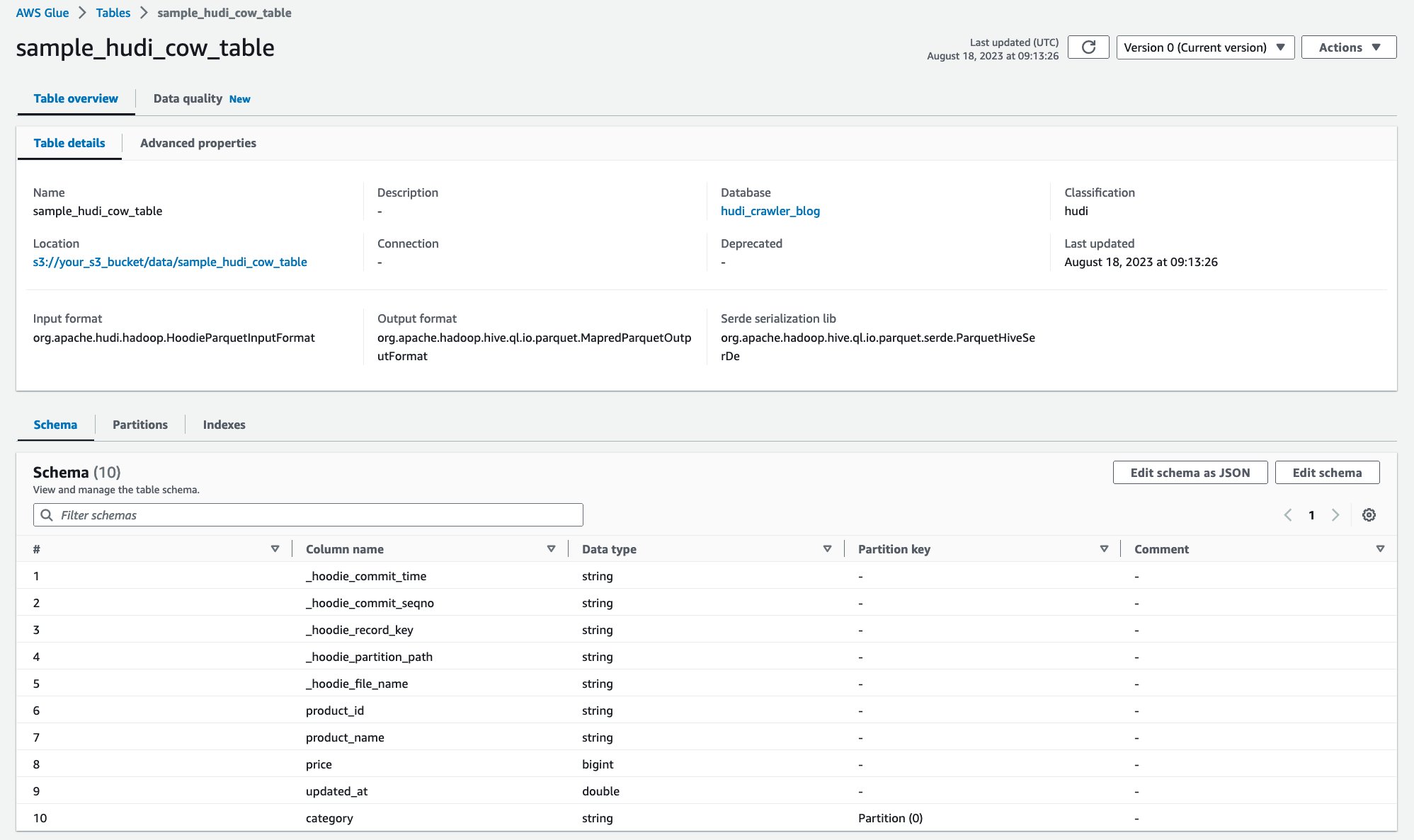
Pomyślnie przeszukałeś tabelę Hudi CoR z danymi na Amazon S3 i utworzyłeś tabelę AWS Glue Data Catalog z wypełnionym schematem. Po utworzeniu definicji tabeli w katalogu danych kleju AWS usługi analityczne AWS, takie jak Amazon Athena, mogą wysyłać zapytania do tabeli Hudi.
Wykonaj następujące kroki, aby rozpocząć zapytania w usłudze Athena:
- Otwórz konsolę Amazon Athena.
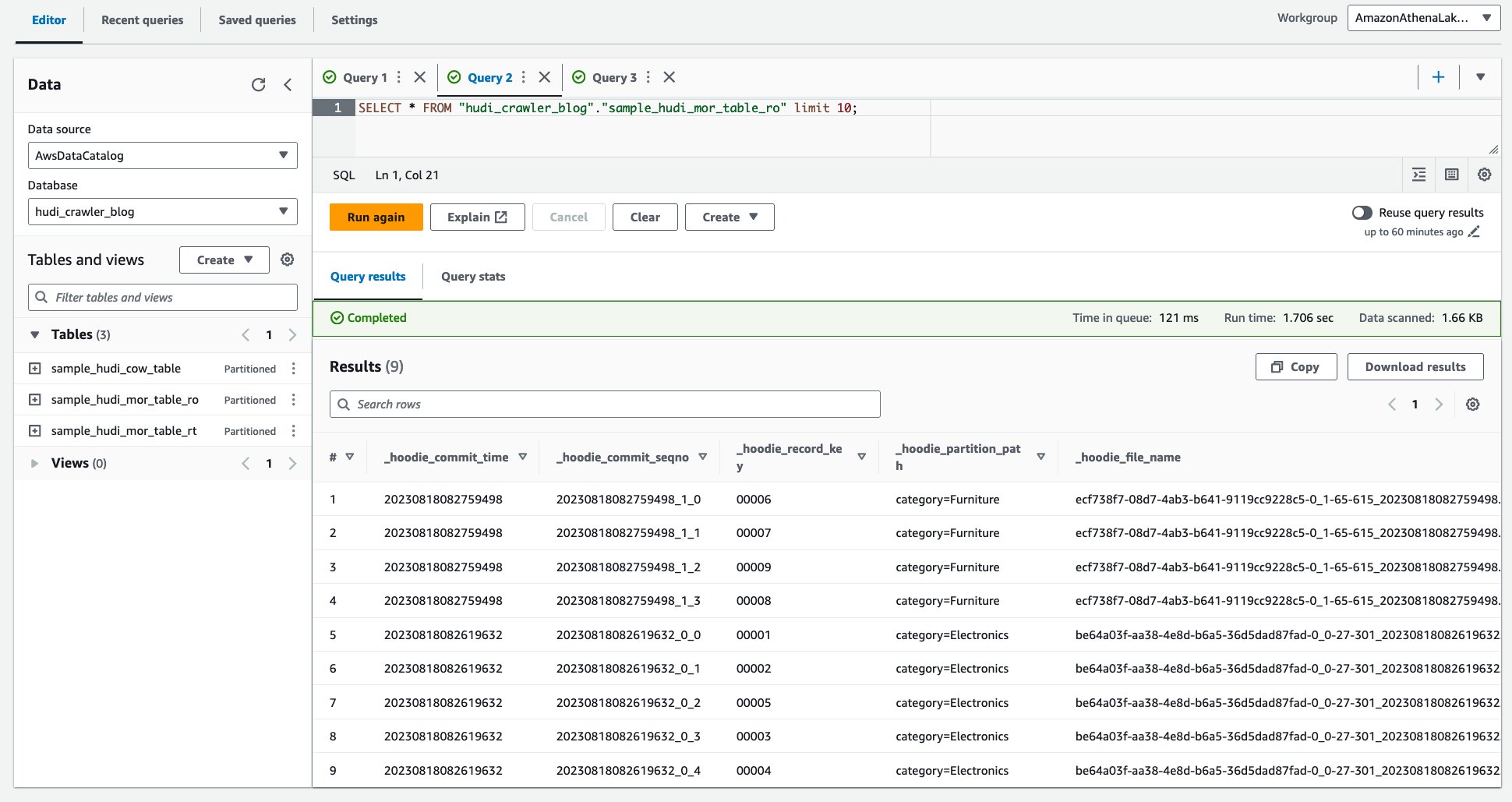
- Uruchom następujące zapytanie.
Poniższy zrzut ekranu przedstawia nasze dane wyjściowe:
Przeszukaj tabelę Hudi MoR za pomocą przeszukiwacza AWS Glue z uprawnieniami do danych AWS Lake Formation
W tej sekcji omówimy, jak przeszukać tabelę Hudi MoR przy użyciu kleju AWS. Tym razem używasz uprawnień do danych AWS Lake Formation do przeszukiwania źródeł danych Amazon S3 zamiast uprawnień IAM i Amazon S3. Jest to opcjonalne, ale upraszcza konfiguracje uprawnień, gdy jezioro danych jest zarządzane za pomocą uprawnień AWS Lake Formation.
Wymagania wstępne
Oto wymagania wstępne tego samouczka:
- Zainstaluj i skonfiguruj Interfejs wiersza poleceń AWS (AWS CLI).
- Utwórz wiadro S3, jeśli go nie masz.
- Utwórz swoją rolę IAM dla kleju AWS jeśli go nie masz. Potrzebujesz
lakeformation:GetDataAccess. Ale nie musiszs3:GetObjectdlas3://your_s3_bucket/data/sample_hudi_mor_table/ponieważ korzystamy z uprawnień do danych Lake Formation, aby uzyskać dostęp do plików. - Uruchom następujące polecenie, aby skopiować przykładową tabelę Hudi do segmentu S3. (Zastępować
your_s3_bucketz nazwą zasobnika S3.)
Oprócz etapów przetwarzania wykonaj następujące kroki, aby zaktualizować ustawienia katalogu danych kleju AWS, aby używać uprawnień Lake Formation do kontrolowania zasobów katalogu zamiast kontroli dostępu opartej na IAM:
- Zaloguj się do konsoli Lake Formation jako administrator Data Lake.
- Jeśli po raz pierwszy uzyskujesz dostęp do konsoli Lake Formation, dodaj siebie jako administratora data lake.
- Pod Administracjawybierz Ustawienia katalogu danych.
- W razie zamówieenia projektu Domyślne uprawnienia dla nowo utworzonych baz danych i tabel, odznacz Używaj tylko kontroli dostępu IAM dla nowych baz danych i Używaj tylko kontroli dostępu IAM dla nowych tabel w nowych bazach danych.
- W razie zamówieenia projektu Ustawienie wersji konta krzyżowegowybierz Wersja 3.
- Dodaj Zapisz.
Następnym krokiem jest zarejestrowanie segmentu S3 w lokalizacjach jezior danych Lake Formation:
- W konsoli Lake Formation wybierz Lokalizacje jeziora danychi wybierz Zarejestruj lokalizację.
- W razie zamówieenia projektu Ścieżka Amazon S3, wchodzić
s3://your_s3_bucket/. (Zastępowaćyour_s3_bucketz nazwą zasobnika S3.) - Dodaj Zarejestruj lokalizację.
Następnie przyznaj roli przeszukiwacza Glue dostęp do lokalizacji danych, aby przeszukiwacz mógł korzystać z uprawnień Lake Formation w celu uzyskania dostępu do danych i tworzenia tabel w tej lokalizacji:
- W konsoli Lake Formation wybierz Lokalizacje danych i wybierz Dotacja.
- W razie zamówieenia projektu Użytkownicy i role uprawnieńwybierz rolę uprawnień użytą dla robota.
- W razie zamówieenia projektu Miejsce przechowywania, wchodzić
s3://your_s3_bucket/data/. (Zastępowaćyour_s3_bucketz nazwą zasobnika S3.) - Dodaj Dotacja.
Następnie nadaj rolę przeszukiwacza, aby tworzyć tabele w bazie danych hudi_crawler_blog:
- W konsoli Lake Formation wybierz Uprawnienia do jeziora danych.
- Dodaj Dotacja.
- W razie zamówieenia projektu Dyrektorzywybierz Użytkownicy i role uprawnieńi wybierz rolę robota.
- W razie zamówieenia projektu Tagi LF lub zasoby kataloguwybierz Nazwane zasoby katalogu danych.
- W razie zamówieenia projektu Baza danych, wybierz bazę danych
hudi_crawler_blog. - Pod Uprawnienia do bazy danych, Wybierz Utwórz tabelę.
- Dodaj Dotacja.
Utwórz robota Hudi z uprawnieniami do danych Lake Formation
Wykonaj następujące kroki, aby utworzyć przeszukiwacza Hudi:
- Na konsoli AWS Glue wybierz Roboty.
- Dodaj Utwórz robota.
- W razie zamówieenia projektu Imię, wchodzić
hudi_mor_crawler, Wybierać Następna. - Pod Konfiguracja źródła danych, wybierać Dodaj źródło danych.
- W razie zamówieenia projektu Źródło danychwybierz Zły.
- W razie zamówieenia projektu Dołącz ścieżki tabeli hudi, wchodzić
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Zastępowaćyour_s3_bucketz nazwą zasobnika S3.) - Dodaj Dodaj źródło danych Hudi.
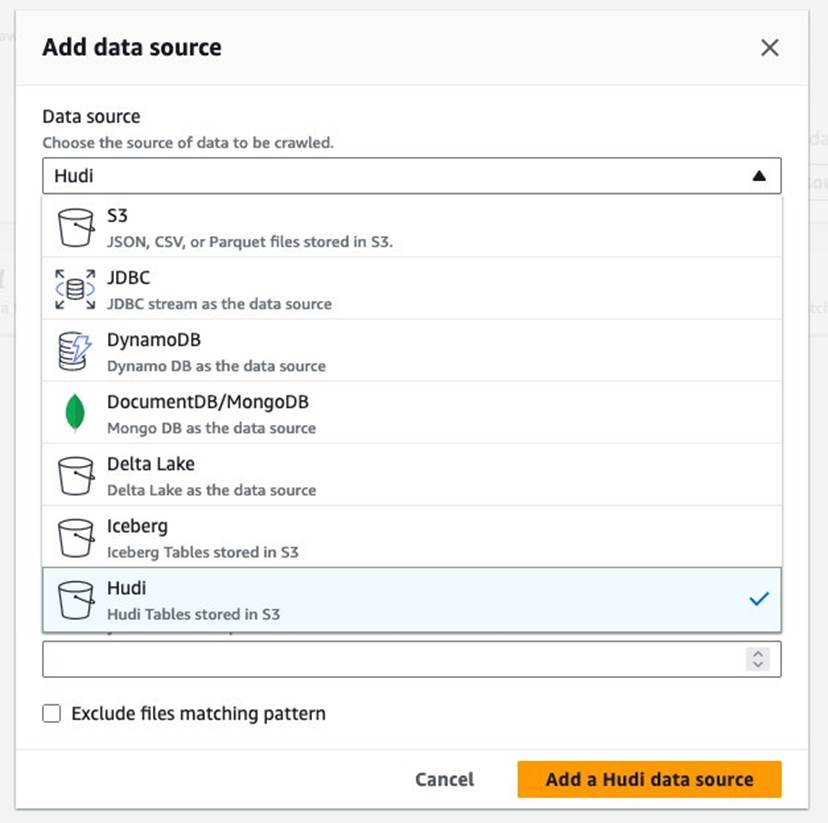
- Dodaj Następna.
- W razie zamówieenia projektu Istniejąca rola uprawnień, wybierz swoją rolę uprawnień.
- Pod Konfiguracja Lake Formation – opcjonalna, Wybierz Użyj poświadczeń Lake Formation do przeszukiwania źródła danych S3.
- Dodaj Następna.
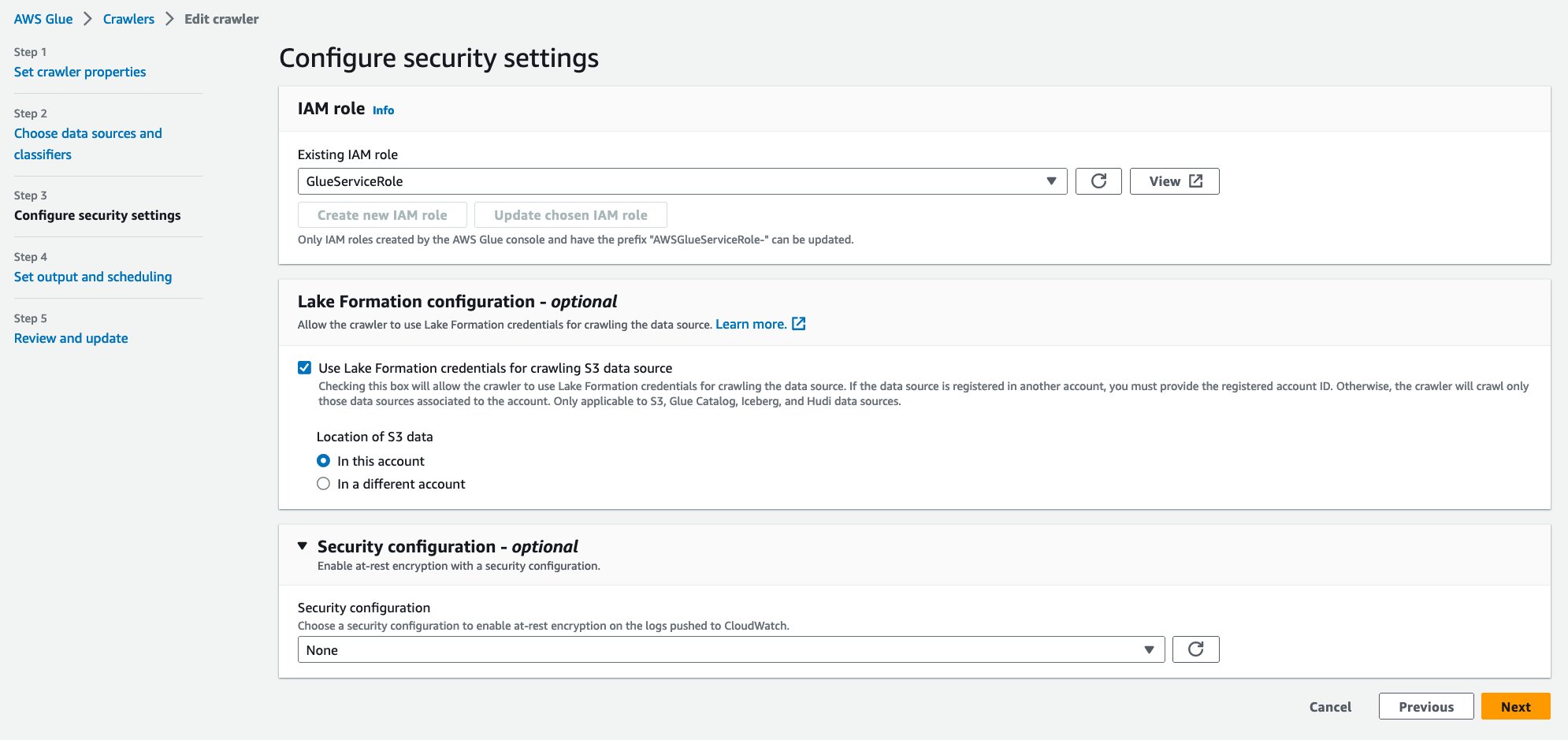
- W razie zamówieenia projektu Docelowa baza danychwybierz
hudi_crawler_blog, Wybierać Następna. - Dodaj Utwórz robota.
Teraz pomyślnie utworzono nowy przeszukiwacz Hudi. Przeszukiwacz używa poświadczeń Lake Formation do przeszukiwania plików Amazon S3. Uruchommy nowego robota:
- Dodaj Uruchom robota.
- Poczekaj, aż robot się zakończy.
Po uruchomieniu robota w konsoli AWS Glue możesz zobaczyć dwie tabele definicji tabeli Hudi:
sample_hudi_mor_table_ro(przeczytaj zoptymalizowaną tabelę)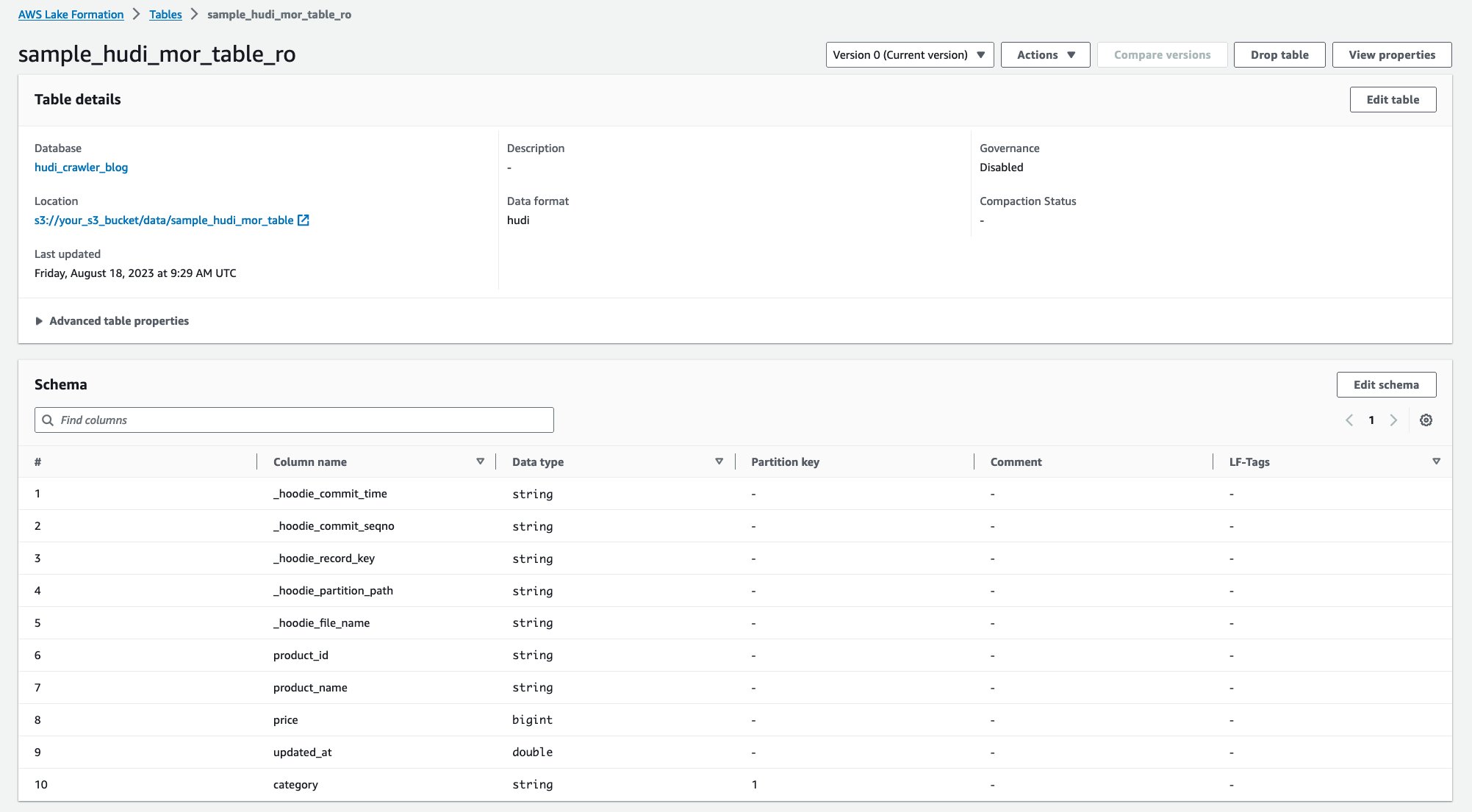
sample_hudi_mor_table_rt(tabela czasu rzeczywistego)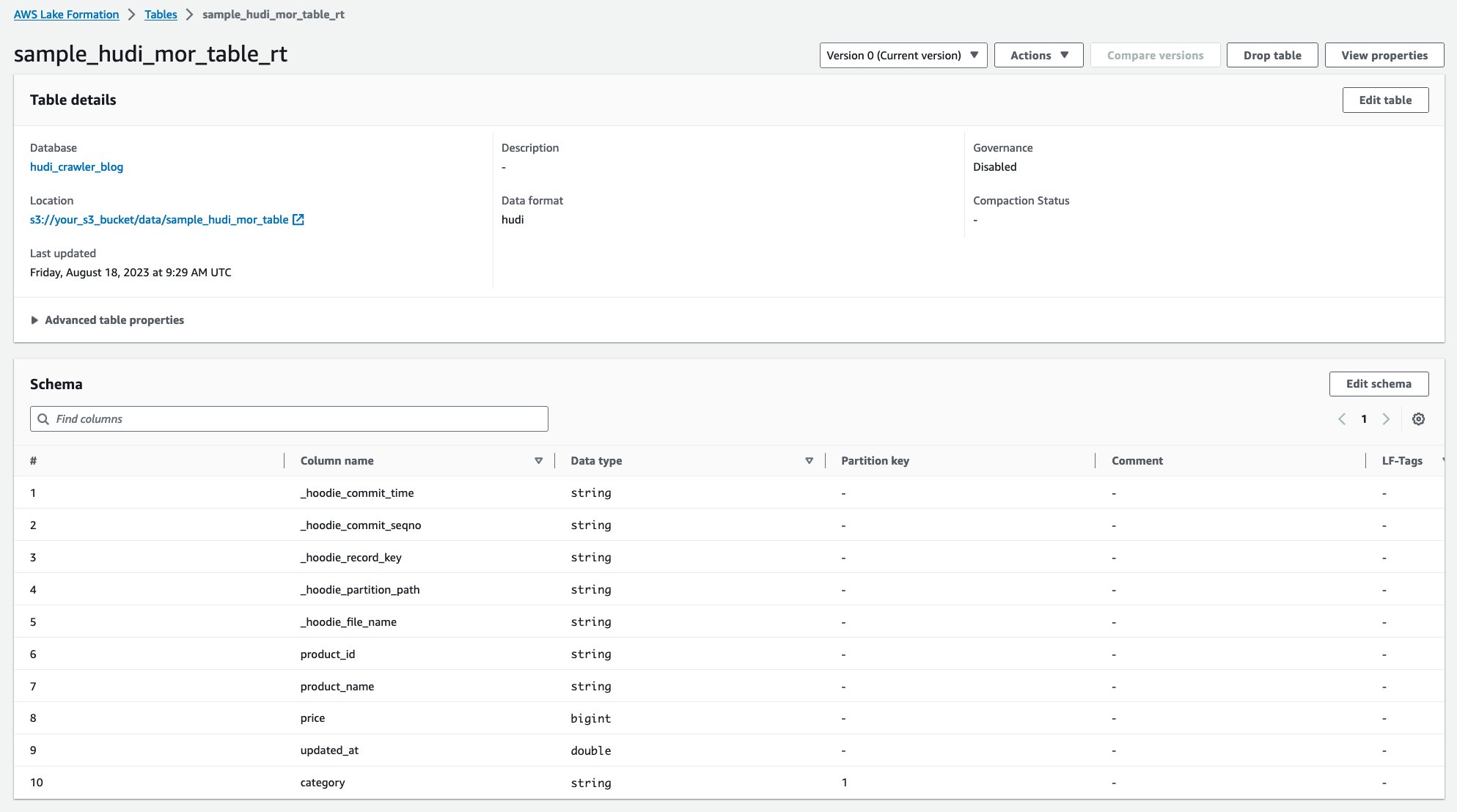
Zarejestrowałeś zasobnik Data Lake w Lake Formation i włączyłeś dostęp do indeksowania do Data Lake przy użyciu uprawnień Lake Formation. Pomyślnie przeszukałeś tabelę Hudi MoR z danymi na Amazon S3 i utworzyłeś tabelę AWS Glue Data Catalog z wypełnionym schematem. Po utworzeniu definicji tabel w katalogu danych kleju AWS usługi analityczne AWS, takie jak Amazon Athena, mogą wysyłać zapytania do tabeli Hudi.
Wykonaj następujące kroki, aby rozpocząć zapytania w usłudze Athena:
- Otwórz konsolę Amazon Athena.
- Uruchom następujące zapytanie.
Poniższy zrzut ekranu przedstawia nasze dane wyjściowe:
- Uruchom następujące zapytanie.
Poniższy zrzut ekranu przedstawia nasze dane wyjściowe:
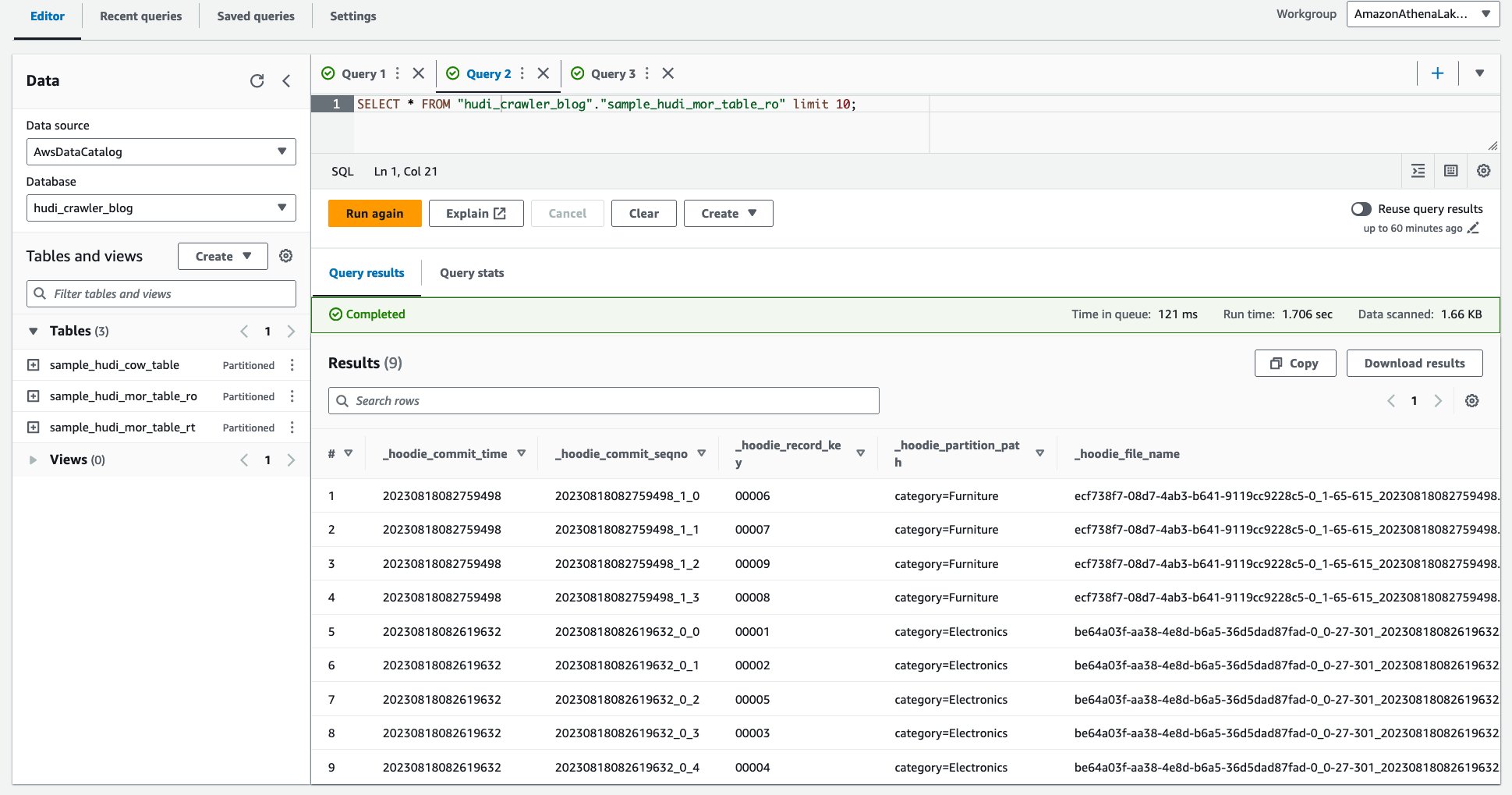
Szczegółowa kontrola dostępu przy użyciu uprawnień AWS Lake Formation
Aby zastosować precyzyjną kontrolę dostępu do tabeli Hudi, możesz skorzystać z uprawnień AWS Lake Formation. Uprawnienia Lake Formation pozwalają ograniczyć dostęp do określonych tabel, kolumn lub wierszy, a następnie wysyłać zapytania do tabel Hudi za pośrednictwem usługi Amazon Athena z precyzyjną kontrolą dostępu. Skonfigurujmy uprawnienia Lake Formation dla tabeli Hudi MoR.
Wymagania wstępne
Oto wymagania wstępne tego samouczka:
- Uzupełnij poprzednią sekcję Przeszukaj tabelę Hudi MoR za pomocą przeszukiwacza AWS Glue z uprawnieniami do danych AWS Lake Formation.
- Utwórz użytkownika DataAnalyst z uprawnieniami IAM, który ma zarządzane zasady AWS AmazonAthenaPełny dostęp.
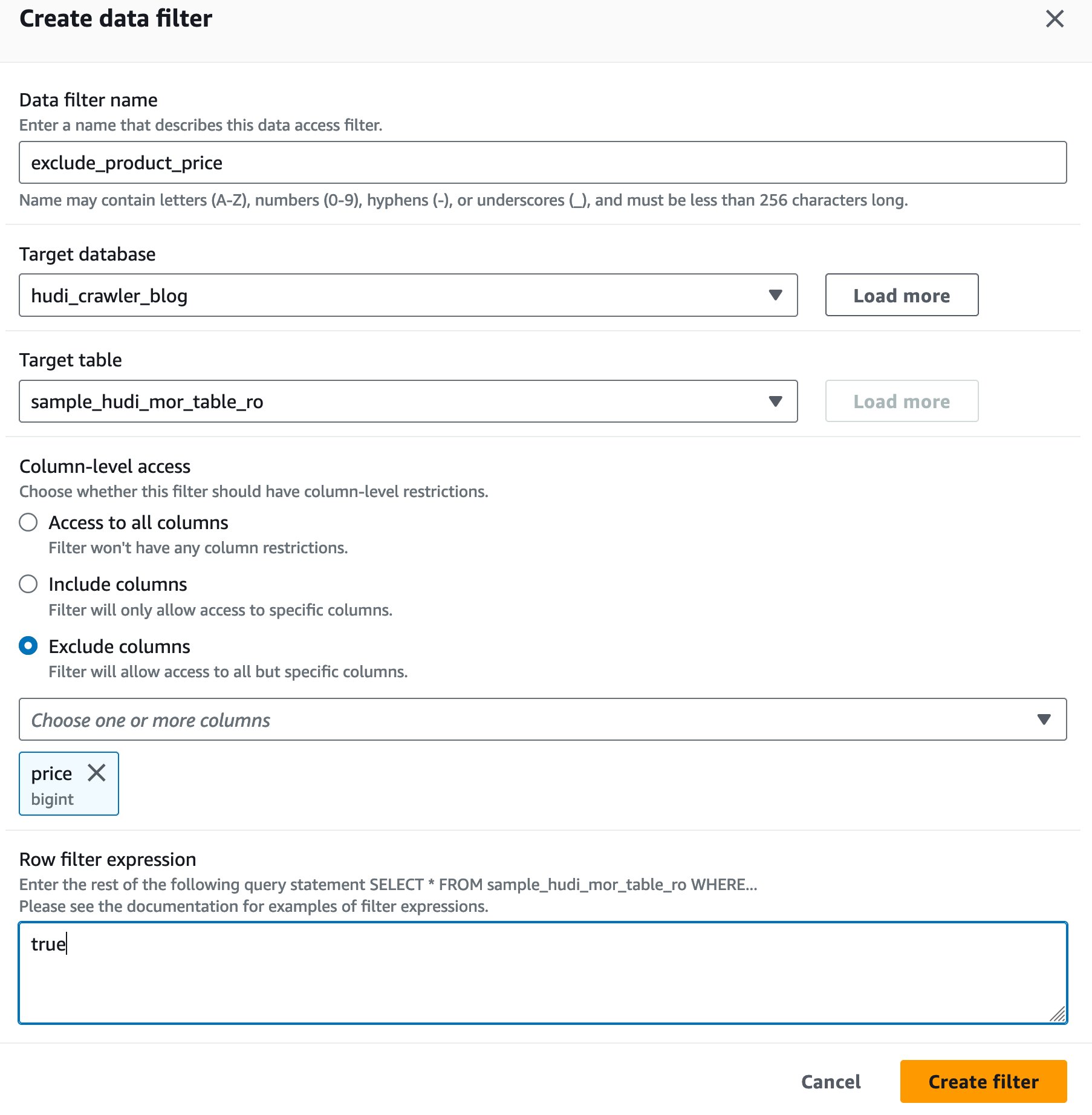
Utwórz filtr komórek danych Formacja jeziora
Najpierw skonfigurujmy filtr dla tabeli zoptymalizowanej pod kątem odczytu MoR.
- Zaloguj się do konsoli Lake Formation jako administrator Data Lake.
- Dodaj Filtry danych.
- Dodaj Utwórz nowy filtr.
- W razie zamówieenia projektu Nazwa filtra danych, wchodzić
exclude_product_price. - W razie zamówieenia projektu Docelowa baza danych, wybierz bazę danych
hudi_crawler_blog. - W razie zamówieenia projektu Tabela docelowa, wybierz stolik
sample_hudi_mor_table_ro. - W razie zamówieenia projektu Poziom kolumny dostęp, wybierz Wyklucz kolumnyi wybierz cenę w kolumnie.
- W razie zamówieenia projektu Wyrażenie filtra wierszy, wchodzić
true. - Dodaj Utwórz filtr.
Przyznaj uprawnienia Lake Formation użytkownikowi DataAnalyst
Wykonaj następujące kroki, aby udzielić uprawnienia do tworzenia jeziora DataAnalyst użytkownik
- W konsoli Lake Formation wybierz Uprawnienia do jeziora danych.
- Dodaj Dotacja.
- W razie zamówieenia projektu Dyrektorzywybierz Użytkownicy i role uprawnieńi wybierz użytkownika
DataAnalyst. - W razie zamówieenia projektu Tagi LF lub zasoby kataloguwybierz Nazwane zasoby katalogu danych.
- W razie zamówieenia projektu Baza danych, wybierz bazę danych
hudi_crawler_blog. - W razie zamówieenia projektu Stół – opcjonalnie, wybierz stolik
sample_hudi_mor_table_ro. - W razie zamówieenia projektu Filtry danych – opcjonalne, Wybierz
exclude_product_price. - W razie zamówieenia projektu Uprawnienia do filtrowania danych, Wybierz Wybierz.
- Dodaj Dotacja.
Przyznałeś uprawnienia do tworzenia jeziora w bazie danych hudi_crawler_blog i stół sample_hudi_mor_table_ro, z wyłączeniem kolumny price dla użytkownika DataAnalyst. Teraz zweryfikujmy dostęp użytkownika do danych za pomocą Atheny.
- Zaloguj się do konsoli Athena jako użytkownik DataAnalyst.
- W edytorze zapytań uruchom następujące zapytanie:
Poniższy zrzut ekranu przedstawia nasze dane wyjściowe:
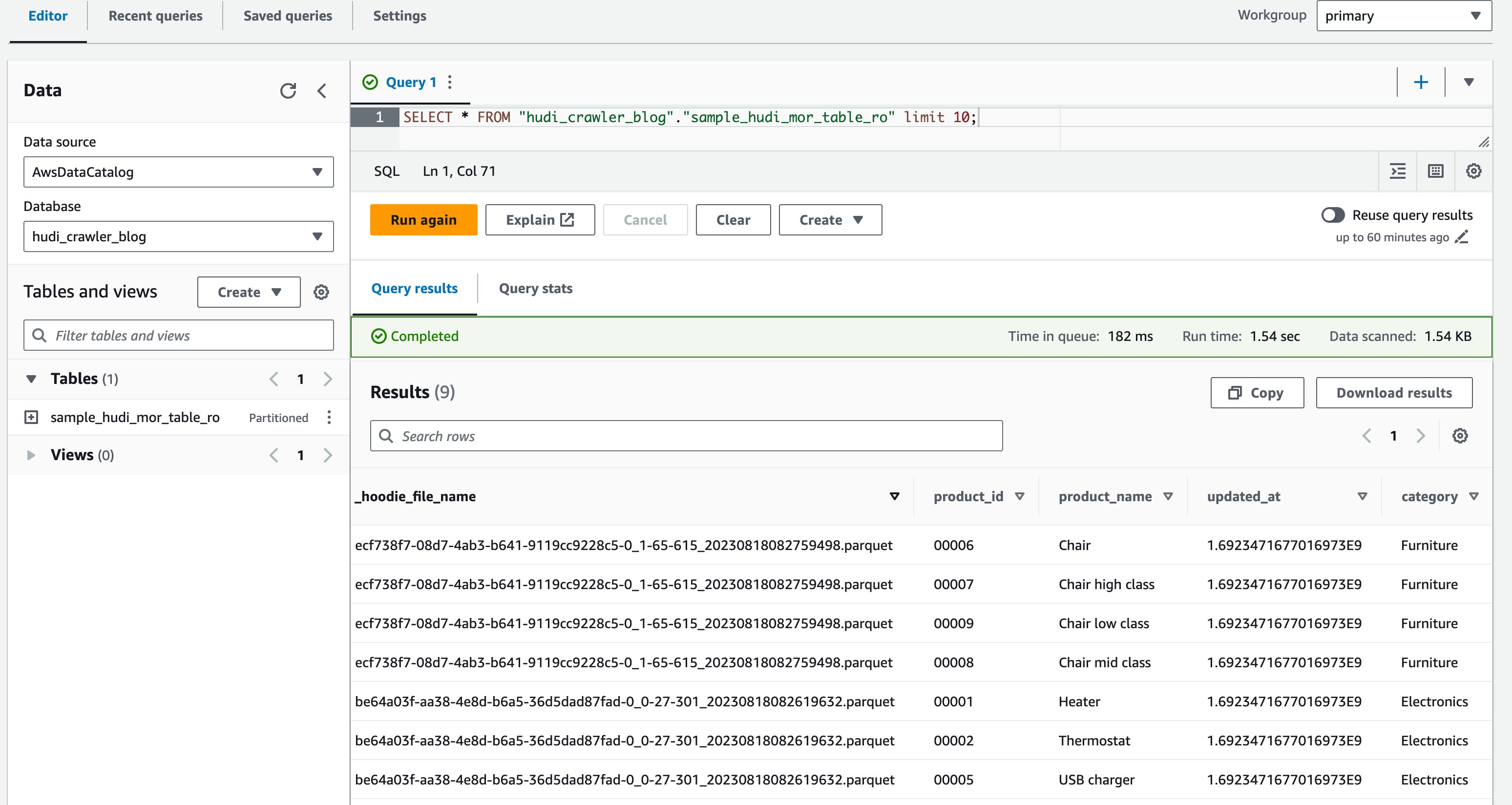
Teraz sprawdziłeś, czy kolumna price nie jest pokazana, ale pozostałe kolumny product_id, product_name, update_at, category są pokazane.
Sprzątać
Aby uniknąć niechcianych opłat na koncie AWS, usuń następujące zasoby AWS:
- Usuń bazę danych kleju AWS
hudi_crawler_blog. - Usuń roboty AWS Glue
hudi_cow_crawlerihudi_mor_crawler. - Usuń pliki Amazon S3 w obszarze
s3://your_s3_bucket/data/sample_hudi_cow_table/is3://your_s3_bucket/data/sample_hudi_mor_table/.
Wnioski
W tym poście pokazano, jak roboty AWS Glue działają w przypadku tabel Hudi. Dzięki obsłudze robota Hudi możesz szybko przejść do używania AWS Glue Data Catalog jako głównego katalogu tabel Hudi. Możesz rozpocząć budowanie bezserwerowego jeziora danych transakcyjnych za pomocą Hudi na AWS, korzystając z AWS Glue, AWS Glue Data Catalog i precyzyjnej kontroli dostępu Lake Formation dla tabel i formatów obsługiwanych przez silniki analityczne AWS.
O autorach
 Noritaka Sekiyama jest głównym architektem Big Data w zespole AWS Glue. Pracuje w Tokio w Japonii. Jest odpowiedzialny za budowanie artefaktów oprogramowania, aby pomóc klientom. W wolnym czasie lubi jeździć na rowerze szosowym.
Noritaka Sekiyama jest głównym architektem Big Data w zespole AWS Glue. Pracuje w Tokio w Japonii. Jest odpowiedzialny za budowanie artefaktów oprogramowania, aby pomóc klientom. W wolnym czasie lubi jeździć na rowerze szosowym.
 Kyle'a Duonga jest inżynierem ds. rozwoju oprogramowania w zespole AWS Glue and Lake Formation. Pasjonuje się budowaniem technologii big data i systemów rozproszonych.
Kyle'a Duonga jest inżynierem ds. rozwoju oprogramowania w zespole AWS Glue and Lake Formation. Pasjonuje się budowaniem technologii big data i systemów rozproszonych.
 Sandeepa Adwankara jest Senior Technical Product Managerem w AWS. Mieszka w California Bay Area i współpracuje z klientami na całym świecie, aby przełożyć wymagania biznesowe i techniczne na produkty, które umożliwiają klientom poprawę zarządzania danymi, ich zabezpieczania i uzyskiwania do nich dostępu.
Sandeepa Adwankara jest Senior Technical Product Managerem w AWS. Mieszka w California Bay Area i współpracuje z klientami na całym świecie, aby przełożyć wymagania biznesowe i techniczne na produkty, które umożliwiają klientom poprawę zarządzania danymi, ich zabezpieczania i uzyskiwania do nich dostępu.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Zdolny
- O nas
- dostęp
- Dostęp do danych
- Dostęp
- Konto
- Działania
- Dodaj
- w dodatku
- dodatek
- przyjęty
- Przyjęcie
- zaawansowany
- Po
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- również
- Amazonka
- Amazonka Atena
- Amazon Web Services
- an
- Analityczny
- analityka
- i
- Inne
- każdy
- Apache
- Apache Spark
- api
- pojawia się
- Zastosowanie
- Application Development
- Aplikuj
- SĄ
- POWIERZCHNIA
- na około
- AS
- At
- automatycznie
- uniknąć
- AWS
- Klej AWS
- Formacja AWS Lake
- baza
- na podstawie
- Zatoka
- BE
- bo
- być
- korzyści
- Ulepsz Swój
- Duży
- Big Data
- Przynosi
- Budowanie
- wybudowany
- biznes
- ale
- by
- California
- wezwanie
- CAN
- możliwości
- zdolność
- walizka
- katalog
- katalogi
- kategorie
- komórka
- wyzwania
- zmiana
- zmieniony
- Zmiany
- Opłaty
- Dodaj
- Kolumna
- kolumny
- połączenie
- popełnić
- zobowiązany
- kompletny
- kompleks
- składnik
- systemu
- Konsola
- zawiera
- zawartość
- bez przerwy
- kontrola
- kontroli
- mógłby
- crawler
- Stwórz
- stworzony
- tworzy
- Listy uwierzytelniające
- Klientów
- dane
- integracja danych
- Jezioro danych
- hurtownia danych
- Baza danych
- Bazy danych
- zbiory danych
- definicja
- definicje
- Delta
- wykazać
- demonstruje
- głębokość
- oprogramowania
- bezpośrednio
- odkryj
- dystrybuowane
- systemy rozproszone
- do
- robi
- podczas
- każdy
- łatwiej
- z łatwością
- redaktor
- faktycznie
- wydajny
- umożliwiać
- włączony
- inżynier
- Inżynierowie
- silniki
- Wchodzę
- Eter (ETH)
- ewoluuje
- z pominięciem
- wyciąg
- szybciej
- mniej
- filet
- Akta
- filtrować
- filtry
- Znajdź
- i terminów, a
- pierwszy raz
- następujący
- W razie zamówieenia projektu
- format
- formacja
- często
- od
- dany
- globus
- Go
- przyznać
- udzielony
- Przewodniki
- Hadoop
- Have
- he
- pomoc
- pomaga
- jego
- Ul
- W jaki sposób
- How To
- HTML
- HTTPS
- IAM
- if
- implikacje
- podnieść
- in
- Włącznie z
- przyrostowe
- Informacja
- zamiast
- integrować
- integracja
- Interfejs
- najnowszych
- wprowadzenie
- IT
- Japonia
- jpg
- konserwacja
- jezioro
- jezior
- firmy
- uruchomić
- UCZYĆ SIĘ
- nauka
- mniej
- LIMIT
- Linia
- Lista
- usytuowany
- lokalizacja
- lokalizacji
- zalogowany
- maszyna
- uczenie maszynowe
- utrzymanie
- robić
- WYKONUJE
- zarządzanie
- zarządzane
- kierownik
- zarządzający
- podręcznik
- maksymalny
- połączenie
- Metadane
- migracja
- migracja
- ML
- jeszcze
- większość
- ruch
- wielokrotność
- Nazwa
- rodzimy
- Potrzebować
- potrzebne
- Nowości
- nowo
- Następny
- już dziś
- of
- on
- ONE
- tylko
- koncepcja
- open source
- zoptymalizowane
- Option
- or
- Inne
- ludzkiej,
- wydajność
- część
- namiętny
- ścieżka
- ścieżki
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- pozwolenie
- uprawnienia
- plato
- Analiza danych Platona
- PlatoDane
- Popularny
- zaludniony
- Post
- Przygotować
- warunki wstępne
- poprzedni
- Cena
- pierwotny
- Główny
- przetwarzanie
- Produkt
- product manager
- Produkty
- zapewniać
- pod warunkiem,
- zapewnia
- zapytania
- szybko
- Czytaj
- real
- w czasie rzeczywistym
- realtime
- niedawny
- rekord
- zarejestrować
- zarejestrowany
- obsługi produkcji rolnej, która zastąpiła
- wymagania
- Zasoby
- odpowiedzialny
- ograniczać
- droga
- Rola
- RZĄD
- run
- taki sam
- rozkład
- zaplanowane
- Sdk
- Sekcja
- bezpieczne
- widzieć
- wybierać
- senior
- Bezserwerowe
- usługa
- Usługi
- zestaw
- w panelu ustawień
- pokazane
- Targi
- upraszcza
- ponieważ
- pojedynczy
- Plaster
- Migawka
- So
- Tworzenie
- rozwoju oprogramowania
- Źródło
- Źródła
- Iskra
- specyficzny
- początek
- Stan
- Ewolucja krok po kroku
- Cel
- przechowywany
- Streaming
- Strumienie
- studio
- Z powodzeniem
- taki
- wsparcie
- Utrzymany
- synchronizacja
- systemy
- stół
- zespół
- Techniczny
- Technologies
- że
- Połączenia
- ich
- następnie
- Tam.
- one
- to
- trzy
- Przez
- czas
- czasy
- do
- Tokio
- Top
- transakcyjny
- transakcje
- tłumaczyć
- poligon
- wyzwalać
- rozsierdzony
- Tutorial
- drugiej
- typy
- typowy
- dla
- niepożądany
- Aktualizacja
- zaktualizowane
- Nowości
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- UPRAWOMOCNIĆ
- zatwierdzony
- Wartości
- wersja
- wizualny
- Magazyn
- we
- sieć
- usługi internetowe
- DOBRZE
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- KIM
- będzie
- w
- bez
- Praca
- działa
- napisać
- napisany
- ty
- Twój
- siebie
- zefirnet