Jeziora danych obsługiwane przez AWS, wspierane przez niezrównaną dostępność Usługa Amazon Simple Storage (Amazon S3), może obsłużyć skalę, zwinność i elastyczność wymaganą do łączenia różnych podejść do danych i analiz. W miarę jak jeziora danych powiększają się i dojrzewają w użyciu, można włożyć wiele wysiłku w zapewnienie spójności danych z wydarzeniami biznesowymi. Aby zapewnić aktualizację plików w sposób spójny transakcyjnie, coraz większa liczba klientów korzysta z formatów tabel transakcyjnych typu open source, takich jak Góra lodowa Apache, Apache Hudi, Jezioro Delta Fundacji Linuksa które pomagają przechowywać dane z wysokim stopniem kompresji, natywnie łączą się z aplikacjami i frameworkami oraz upraszczają przyrostowe przetwarzanie danych w jeziorach danych zbudowanych na Amazon S3. Te formaty umożliwiają transakcje ACID (atomowość, spójność, izolacja, trwałość), wstawianie i usuwanie, a także zaawansowane funkcje, takie jak podróże w czasie i migawki, które wcześniej były dostępne tylko w hurtowniach danych. Każdy format przechowywania implementuje tę funkcjonalność w nieco inny sposób; dla porównania patrz Wybór formatu otwartej tabeli dla jeziora danych transakcyjnych w AWS.
W 2023, AWS ogłosił powszechną dostępność dla Apache Iceberg, Apache Hudi i Linux Foundation Delta Lake w Amazon Athena dla Apache Spark, co eliminuje potrzebę instalowania osobnego łącznika lub powiązanych zależności i zarządzania wersjami, a także upraszcza kroki konfiguracyjne wymagane do korzystania z tych struktur.
W tym poście pokażemy, jak używać Spark SQL w Amazonka Atena notatniki i pracować z tabelami w formatach Iceberg, Hudi i Delta Lake. Demonstrujemy typowe operacje, takie jak tworzenie baz danych i tabel, wstawianie danych do tabel, wykonywanie zapytań o dane i przeglądanie migawek tabel w Amazon S3 przy użyciu Spark SQL w Athenie.
Wymagania wstępne
Spełnij następujące wymagania wstępne:
Pobierz i importuj przykładowe notatniki z Amazon S3
Aby śledzić dalej, pobierz notesy omówione w tym poście z następujących lokalizacji:
Po pobraniu notesów zaimportuj je do środowiska Athena Spark, postępując zgodnie z instrukcją Aby zaimportować notatnik sekcja w Zarządzanie plikami notatnika.
Przejdź do określonej sekcji Format otwartej tabeli
Jeśli interesuje Cię format tabeli Iceberg, przejdź do Praca z tabelami Apache Iceberg
Jeśli interesuje Cię format tabeli Hudi, przejdź do Praca z tabelami Apache Hudi
Jeśli interesuje Cię format tabeli Delta Lake, przejdź do Praca z tabelami Delta Lake podstawy systemu Linux
Praca z tabelami Apache Iceberg
Korzystając z notesów Spark w Athenie, możesz bezpośrednio uruchamiać zapytania SQL bez konieczności korzystania z PySpark. Robimy to za pomocą magii komórek, czyli specjalnych nagłówków w komórce notatnika, które zmieniają zachowanie komórki. W przypadku SQL możemy dodać %%sql magic, który zinterpretuje całą zawartość komórki jako instrukcję SQL do uruchomienia w Athenie.
W tej sekcji pokazujemy, jak używać SQL w Apache Spark for Athena do tworzenia i analizowania tabel Apache Iceberg oraz zarządzania nimi.
Skonfiguruj sesję notatnika
Aby używać Apache Iceberg w Athenie, podczas tworzenia lub edycji sesji wybierz opcję Góra lodowa Apache opcję, rozwijając Właściwości Apache Spark Sekcja. Wstępnie wypełni właściwości, jak pokazano na poniższym zrzucie ekranu.
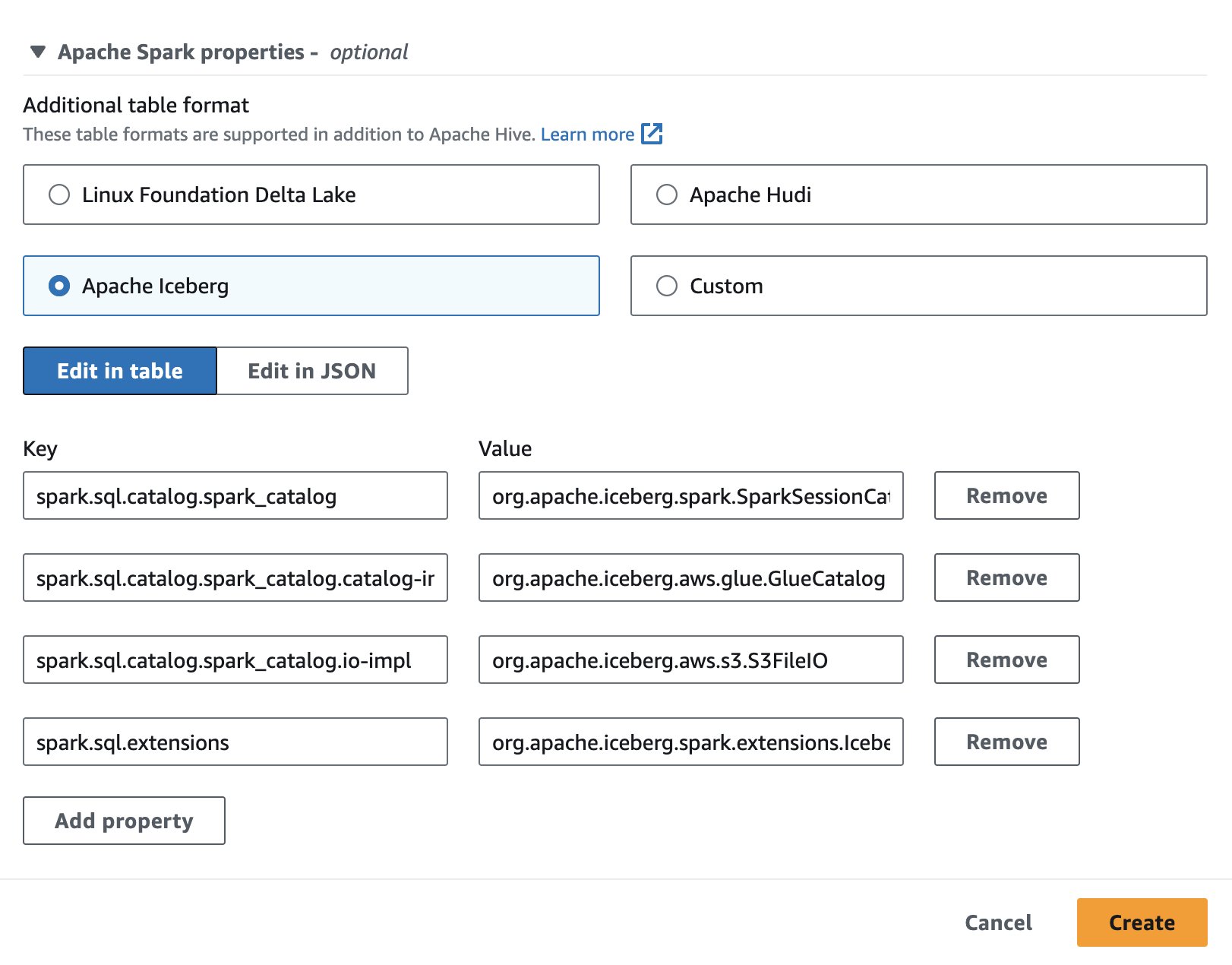
Aby zapoznać się z krokami, zobacz Edycja szczegółów sesji or Tworzenie własnego notesu.
Kod użyty w tej sekcji jest dostępny w pliku SparkSQL_iceberg.ipynb plik do naśladowania.
Utwórz bazę danych i tabelę góry lodowej
Najpierw tworzymy bazę danych w AWS Glue Data Catalog. Za pomocą następującego kodu SQL możemy utworzyć bazę danych o nazwie icebergdb:
Następnie w bazie danych icebergdb, tworzymy tabelę Iceberg o nazwie noaa_iceberg wskazując lokalizację w Amazon S3, gdzie załadujemy dane. Uruchom następującą instrukcję i zastąp lokalizację s3://<your-S3-bucket>/<prefix>/ z wiadrem S3 i prefiksem:
Wstaw dane do tabeli
Aby wypełnić noaa_iceberg Do tabeli Iceberg wstawiamy dane z tabeli Parquet sparkblogdb.noaa_pq który został utworzony jako część wymagań wstępnych. Można to zrobić za pomocą WŁÓŻ W instrukcja w Sparku:
Alternatywnie można użyć UTWÓRZ TABELĘ JAKO WYBIERZ z klauzulą USING iceberg, aby utworzyć tabelę Iceberg i wstawić dane z tabeli źródłowej w jednym kroku:
Zapytanie dotyczące tabeli góry lodowej
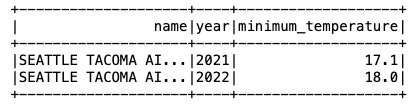
Teraz, gdy dane zostały wstawione do tabeli Iceberg, możemy zacząć je analizować. Uruchommy Spark SQL, aby znaleźć minimalną zarejestrowaną temperaturę w ciągu roku dla 'SEATTLE TACOMA AIRPORT, WA US' lokalizacja:
Otrzymujemy następujące dane wyjściowe.
Zaktualizuj dane w tabeli Iceberg
Przyjrzyjmy się, jak zaktualizować dane w naszej tabeli. Chcemy zaktualizować nazwę stacji 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea-Tac'. Używając Spark SQL, możemy uruchomić plik Aktualizacja oświadczenie przeciwko tabeli góry lodowej:
Następnie możemy uruchomić poprzednie zapytanie SELECT, aby znaleźć minimalną zarejestrowaną temperaturę dla 'Sea-Tac' lokalizacja:
Otrzymujemy następujące dane wyjściowe.

Kompaktowe pliki danych
Otwarte formaty tabel, takie jak Iceberg, działają poprzez tworzenie zmian delta w przechowywaniu plików i śledzenie wersji wierszy za pomocą plików manifestu. Większa liczba plików danych prowadzi do większej liczby metadanych przechowywanych w plikach manifestu, a małe pliki danych często powodują niepotrzebną ilość metadanych, co skutkuje mniej wydajnymi zapytaniami i wyższymi kosztami dostępu do Amazon S3. Prowadzenie góry lodowej rewrite_data_files procedura w Spark for Athena skompaktuje pliki danych, łącząc wiele małych plików zmian delta w mniejszy zestaw zoptymalizowanych do odczytu plików Parquet. Kompaktowanie plików przyspiesza operację odczytu w przypadku zapytania. Aby uruchomić zagęszczanie na naszej tabeli, uruchom następujący Spark SQL:
rewrite_data_files oferuje opcje aby określić strategię sortowania, która może pomóc w reorganizacji i kompaktowaniu danych.
Lista migawek tabeli
Każda operacja zapisu, aktualizacji, usuwania, wstawiania i zagęszczania na tabeli Iceberg tworzy nową migawkę tabeli, zachowując jednocześnie stare dane i metadane w celu izolacji migawki i podróży w czasie. Aby wyświetlić migawki tabeli Iceberg, uruchom następującą instrukcję Spark SQL:
Wygasanie starych migawek
Zaleca się regularnie wygasające migawki, aby usunąć pliki danych, które nie są już potrzebne, i aby rozmiar metadanych tabeli był niewielki. Nigdy nie usunie plików, które są nadal wymagane przez nie wygasłą migawkę. W Spark for Athena uruchom następujący kod SQL, aby wygasnąć migawki dla tabeli icebergdb.noaa_iceberg które są starsze niż określony znacznik czasu:
Należy pamiętać, że wartość znacznika czasu jest określona jako ciąg znaków w formacie yyyy-MM-dd HH:mm:ss.fff. Dane wyjściowe podają liczbę usuniętych plików danych i metadanych.
Usuń tabelę i bazę danych
Możesz uruchomić następujący Spark SQL, aby wyczyścić tabele Iceberg i powiązane dane w Amazon S3 z tego ćwiczenia:
Uruchom następujący Spark SQL, aby usunąć bazę danych icebergdb:
Aby dowiedzieć się więcej o wszystkich operacjach, które możesz wykonać na stołach Iceberg za pomocą Spark for Athena, zobacz Zapytania dotyczące Sparka i Procedury iskrowe w dokumentacji Iceberg.
Praca z tabelami Apache Hudi
Następnie pokazujemy, jak używać języka SQL w platformie Spark for Athena do tworzenia i analizowania tabel Apache Hudi oraz zarządzania nimi.
Skonfiguruj sesję notatnika
Aby używać Apache Hudi w Athenie, podczas tworzenia lub edycji sesji wybierz opcję Apache Hudi opcję, rozwijając Właściwości Apache Spark
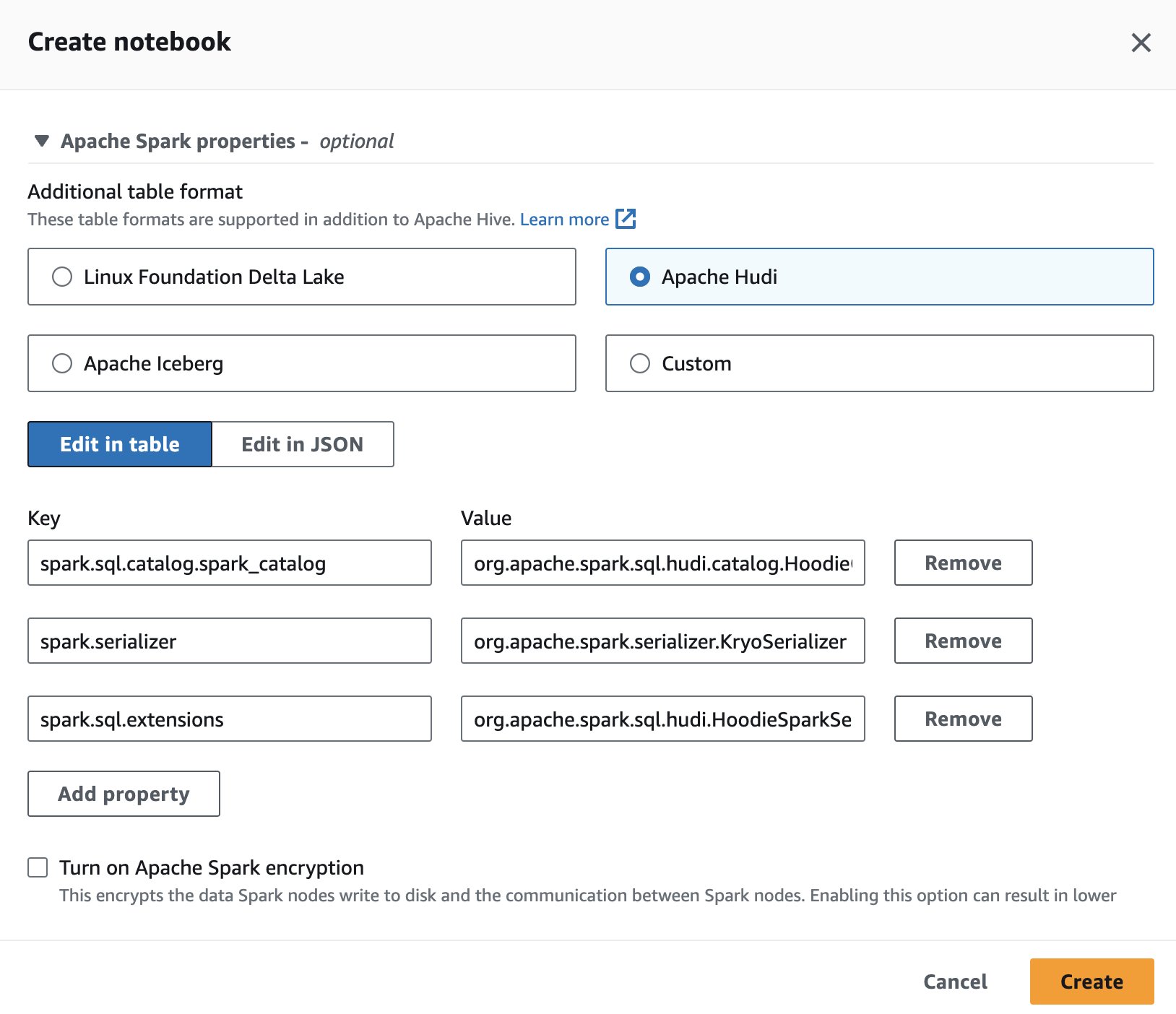
Aby zapoznać się z krokami, zobacz Edycja szczegółów sesji or Tworzenie własnego notesu.
Kod użyty w tej sekcji powinien być dostępny w pliku SparkSQL_hudi.ipynb plik do naśladowania.
Utwórz bazę danych i tabelę Hudi
Najpierw tworzymy bazę danych o nazwie hudidb które zostaną zapisane w katalogu danych kleju AWS, a następnie zostanie utworzona tabela Hudi:
Tworzymy tabelę Hudi wskazującą lokalizację w Amazon S3, gdzie będziemy ładować dane. Zwróć uwagę, że tabela jest z kopiowanie przy zapisie typ. Jest zdefiniowany przez type= 'cow' w tabeli DDL. Zdefiniowaliśmy stację i datę jako wiele kluczy podstawowych, a pole preCombinedField jako rok. Ponadto tabela jest podzielona według lat. Uruchom następującą instrukcję i zastąp lokalizację s3://<your-S3-bucket>/<prefix>/ z wiadrem S3 i prefiksem:
Wstaw dane do tabeli
Podobnie jak w przypadku Iceberg, używamy WŁÓŻ W instrukcja wypełniająca tabelę poprzez odczytanie danych z pliku sparkblogdb.noaa_pq tabela utworzona w poprzednim poście:
Zapytanie o tabelę Hudi
Po utworzeniu tabeli uruchommy zapytanie, aby znaleźć maksymalną zarejestrowaną temperaturę dla 'SEATTLE TACOMA AIRPORT, WA US' lokalizacja:
Zaktualizuj dane w tabeli Hudi
Zmieńmy nazwę stacji 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea–Tac'. Możemy uruchomić instrukcję UPDATE na platformie Spark dla Atheny aktualizacja zapisy noaa_hudi stół:
Uruchamiamy poprzednie zapytanie SELECT, aby znaleźć maksymalną zarejestrowaną temperaturę dla 'Sea-Tac' lokalizacja:
Uruchamiaj zapytania dotyczące podróży w czasie
Możemy używać zapytań dotyczących podróży w czasie w SQL na platformie Athena do analizowania przeszłych migawek danych. Na przykład:
To zapytanie sprawdza dane dotyczące temperatury na lotnisku w Seattle w określonym momencie w przeszłości. Klauzula znacznika czasu pozwala nam cofnąć się bez zmiany bieżących danych. Należy pamiętać, że wartość znacznika czasu jest określona jako ciąg znaków w formacie yyyy-MM-dd HH:mm:ss.fff.
Zoptymalizuj szybkość zapytań dzięki klastrowaniu
Aby poprawić wydajność zapytań, możesz wykonać klastrowanie w tabelach Hudi przy użyciu SQL w Spark dla Atheny:
Kompaktowe stoły
Kompaktowanie to usługa tabel stosowana przez firmę Hudi szczególnie w tabelach Merge On Read (MOR), służąca do okresowego łączenia aktualizacji z plików dziennika wierszowych z odpowiednim plikiem podstawowym opartym na kolumnach w celu utworzenia nowej wersji pliku podstawowego. Kompaktowanie nie ma zastosowania do tabel z kopiowaniem przy zapisie (COW) i ma zastosowanie tylko do tabel MOR. Możesz uruchomić następujące zapytanie w Spark for Athena, aby wykonać zagęszczenie tabel MOR:
Usuń tabelę i bazę danych
Uruchom następujący Spark SQL, aby usunąć utworzoną tabelę Hudi i powiązane z nią dane z lokalizacji Amazon S3:
Uruchom następujący Spark SQL, aby usunąć bazę danych hudidb:
Aby dowiedzieć się o wszystkich operacjach, które możesz wykonać na tabelach Hudi za pomocą Spark for Athena, zobacz SQL-DDL i Procedury w dokumentacji Hudiego.
Praca z tabelami Delta Lake podstawy systemu Linux
Następnie pokazujemy, jak używać języka SQL w platformie Spark for Athena do tworzenia i analizowania tabel Delta Lake oraz zarządzania nimi.
Skonfiguruj sesję notatnika
Aby używać Delta Lake w Spark for Athena, podczas tworzenia lub edytowania sesji wybierz Jezioro Delta Fundacji Linuksa poprzez rozszerzenie Właściwości Apache Spark
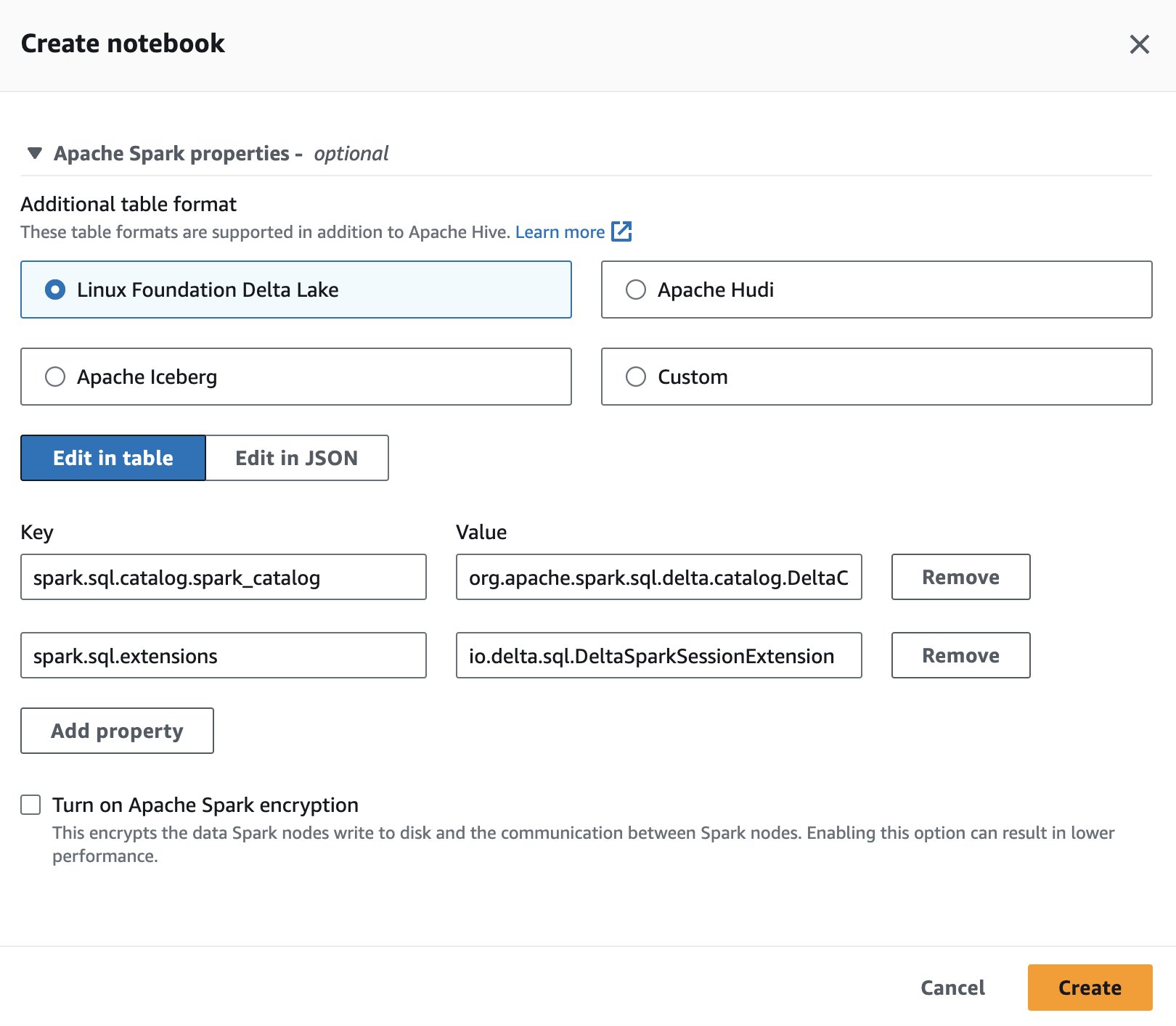
Aby zapoznać się z krokami, zobacz Edycja szczegółów sesji or Tworzenie własnego notesu.
Kod użyty w tej sekcji powinien być dostępny w pliku SparkSQL_delta.ipynb plik do naśladowania.
Utwórz bazę danych i tabelę Delta Lake
W tej sekcji tworzymy bazę danych w AWS Glue Data Catalog. Korzystając z poniższego SQL, możemy stworzyć bazę danych o nazwie deltalakedb:
Następnie w bazie danych deltalakedb, tworzymy tabelę Delta Lake o nazwie noaa_delta wskazując lokalizację w Amazon S3, gdzie załadujemy dane. Uruchom następującą instrukcję i zastąp lokalizację s3://<your-S3-bucket>/<prefix>/ z wiadrem S3 i prefiksem:
Wstaw dane do tabeli
Używamy WŁÓŻ W instrukcja wypełniająca tabelę poprzez odczytanie danych z pliku sparkblogdb.noaa_pq tabela utworzona w poprzednim poście:
Możesz także użyć narzędzia CREATE TABLE AS SELECT, aby utworzyć tabelę Delta Lake i wstawić dane z tabeli źródłowej w jednym zapytaniu.
Zapytanie dotyczące tabeli Delta Lake
Teraz, gdy dane zostały wstawione do tabeli Delta Lake, możemy rozpocząć ich analizę. Uruchommy Spark SQL, aby znaleźć minimalną zarejestrowaną temperaturę dla 'SEATTLE TACOMA AIRPORT, WA US' lokalizacja:
Zaktualizuj dane w tabeli jeziora Delta
Zmieńmy nazwę stacji 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea–Tac'. Możemy uruchomić Aktualizacja oświadczenie w sprawie Spark dotyczące Atheny w celu aktualizacji zapisów noaa_delta stół:
Możemy uruchomić poprzednie zapytanie SELECT, aby znaleźć minimalną zarejestrowaną temperaturę dla 'Sea-Tac' lokalizacja, a wynik powinien być taki sam jak wcześniej:
Kompaktowe pliki danych
W Spark for Athena możesz uruchomić OPTIMIZE w tabeli Delta Lake, co spowoduje kompaktowanie małych plików w większe pliki, dzięki czemu zapytania nie będą obciążone obciążeniem małych plików. Aby wykonać operację zagęszczania, uruchom następujące zapytanie:
Odnosić się do Optymalizacja w dokumentacji Delta Lake dla różnych opcji dostępnych podczas uruchamiania OPTIMIZE.
Usuń pliki, do których nie odwołuje się już tabela Delta Lake
Możesz usunąć pliki przechowywane w Amazon S3, do których nie odwołuje się już tabela Delta Lake i które są starsze niż próg przechowywania, uruchamiając polecenie VACCUM na tabeli za pomocą platformy Spark for Athena:
Odnosić się do Usuń pliki, do których nie odwołuje się już tabela Delta w dokumentacji Delta Lake dla opcji dostępnych z VACUUM.
Usuń tabelę i bazę danych
Uruchom następujący Spark SQL, aby usunąć utworzoną tabelę Delta Lake:
Uruchom następujący Spark SQL, aby usunąć bazę danych deltalakedb:
Uruchomienie DDL DROP TABLE w tabeli i bazie danych Delta Lake powoduje usunięcie metadanych tych obiektów, ale nie powoduje automatycznego usunięcia plików danych w Amazon S3. Możesz uruchomić następujący kod Pythona w komórce notatnika, aby usunąć dane z lokalizacji S3:
Aby dowiedzieć się więcej na temat instrukcji SQL, które można uruchomić w tabeli Delta Lake przy użyciu platformy Spark for Athena, zapoznaj się z sekcją quickstart w dokumentacji Delta Lake.
Wnioski
W tym poście pokazano, jak używać platformy Spark SQL w notesach Athena do tworzenia baz danych i tabel, wstawiania danych i wykonywania zapytań o dane oraz wykonywania typowych operacji, takich jak aktualizacje, kompaktowanie i podróże w czasie na tabelach Hudi, Delta Lake i Iceberg. Otwarte formaty tabel dodają transakcje ACID, wstawki i usunięcia do jezior danych, pokonując ograniczenia przechowywania surowych obiektów. Eliminując potrzebę instalowania oddzielnych złączy, wbudowana integracja Spark on Athena ogranicza etapy konfiguracji i koszty zarządzania podczas korzystania z tych popularnych platform do tworzenia niezawodnych jezior danych na Amazon S3. Aby dowiedzieć się więcej na temat wybierania formatu otwartej tabeli dla obciążeń Data Lake, zobacz Wybór formatu otwartej tabeli dla jeziora danych transakcyjnych w AWS.
O autorach
![]() Pathik Shah jest starszym architektem analitycznym w Amazon Athena. Dołączył do AWS w 2015 roku i od tego czasu koncentruje się na przestrzeni analizy dużych zbiorów danych, pomagając klientom budować skalowalne i niezawodne rozwiązania z wykorzystaniem usług analitycznych AWS.
Pathik Shah jest starszym architektem analitycznym w Amazon Athena. Dołączył do AWS w 2015 roku i od tego czasu koncentruje się na przestrzeni analizy dużych zbiorów danych, pomagając klientom budować skalowalne i niezawodne rozwiązania z wykorzystaniem usług analitycznych AWS.
![]() Raja Devnatha jest menedżerem produktu w AWS na Amazon Athena. Jego pasją jest tworzenie produktów, które klienci uwielbiają, i pomaganie im w wydobywaniu wartości z ich danych. Jego doświadczenie obejmuje dostarczanie rozwiązań dla wielu rynków końcowych, takich jak finanse, handel detaliczny, inteligentne budynki, automatyka domowa i systemy transmisji danych.
Raja Devnatha jest menedżerem produktu w AWS na Amazon Athena. Jego pasją jest tworzenie produktów, które klienci uwielbiają, i pomaganie im w wydobywaniu wartości z ich danych. Jego doświadczenie obejmuje dostarczanie rozwiązań dla wielu rynków końcowych, takich jak finanse, handel detaliczny, inteligentne budynki, automatyka domowa i systemy transmisji danych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- O nas
- dostęp
- Dodaj
- zaawansowany
- przed
- lotnisko
- Wszystkie kategorie
- wzdłuż
- również
- Amazonka
- Amazonka Atena
- Amazon Web Services
- ilość
- an
- analityka
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- ogłosił
- Apache
- Apache Spark
- odpowiedni
- aplikacje
- dotyczy
- awanse
- SĄ
- na około
- AS
- powiązany
- At
- automatycznie
- Automatyzacja
- dostępność
- dostępny
- AWS
- Klej AWS
- z powrotem
- tło
- baza
- BE
- być
- zachowanie
- Duży
- Big Data
- budować
- Budowanie
- wybudowany
- wbudowany
- biznes
- ale
- by
- wezwanie
- nazywa
- CAN
- katalog
- Spowodować
- komórka
- zmiana
- Zmiany
- Wykrywanie urządzeń szpiegujących
- kleń
- kod
- połączyć
- łączenie
- wspólny
- Komunikacja
- systemy porozumiewania się
- kompaktowy
- porównanie
- systemu
- zgodny
- treść
- Odpowiedni
- Koszty:
- liczyć
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- Aktualny
- Klientów
- dane
- Analityka danych
- Jezioro danych
- analiza danych
- magazyn danych
- Baza danych
- Bazy danych
- Data
- zdefiniowane
- dostarczanie
- Delta
- wykazać
- wykazać
- Zależności
- różne
- bezpośrednio
- omówione
- do
- dokumentacja
- Nie
- pobieranie
- Spadek
- trwałość
- każdy
- Wcześniej
- redagowanie
- wydajny
- wysiłek
- zatrudniony
- umożliwiać
- zakończenia
- zapewnić
- Cały
- Środowisko
- Eter (ETH)
- wydarzenia
- przykład
- Ćwiczenie
- rozszerzenie
- wyciąg
- Korzyści
- filet
- Akta
- finansować
- Znajdź
- i terminów, a
- Elastyczność
- skupienie
- obserwuj
- następnie
- następujący
- W razie zamówieenia projektu
- format
- Fundacja
- Ramy
- od
- Funkcjonalność
- Ogólne
- otrzymać
- Dać
- Zarządzanie
- Rozwój
- dorosły
- uchwyt
- Have
- mający
- he
- headers
- pomoc
- pomoc
- hh
- Wysoki
- wyższy
- jego
- Strona główna
- Automatyka domowa
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- obraz
- narzędzia
- importować
- podnieść
- in
- przyrostowe
- zainstalować
- integracja
- zainteresowany
- Interfejs
- najnowszych
- izolacja
- IT
- Dołączył
- jpg
- Trzymać
- konserwacja
- Klawisze
- jezioro
- jezior
- większe
- szerokość
- Wyprowadzenia
- UCZYĆ SIĘ
- mniej
- pozwala
- lubić
- Ograniczenia
- linux
- podstawa linuksa
- Lista
- załadować
- lokalizacja
- lokalizacji
- log
- dłużej
- Popatrz
- poszukuje
- miłość
- magia
- zarządzanie
- i konserwacjami
- kierownik
- sposób
- wiele
- rynki
- max
- maksymalny
- Łączyć
- Metadane
- min
- minimum
- jeszcze
- wielokrotność
- Nazwa
- natywnie
- Nawigacja
- Potrzebować
- potrzebne
- nigdy
- Nowości
- Nie
- noty
- notatnik
- laptopy
- numer
- przedmiot
- Przechowywanie obiektów
- obiekty
- of
- Oferty
- często
- Stary
- starszych
- on
- ONE
- tylko
- OP
- koncepcja
- open source
- działanie
- operacje
- Optymalizacja
- Option
- Opcje
- or
- zamówienie
- ludzkiej,
- wydajność
- przezwyciężaniu
- własny
- część
- namiętny
- Przeszłość
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- plato
- Analiza danych Platona
- PlatoDane
- Popularny
- Post
- warunki wstępne
- poprzedni
- poprzednio
- pierwotny
- procedura
- przetwarzanie
- produkować
- Produkt
- product manager
- Produkty
- niska zabudowa
- Python
- zapytania
- ceny
- Surowy
- Czytaj
- Czytający
- Zalecana
- nagrany
- dokumentacja
- zmniejsza
- odnosić się
- odwołanie
- rzetelny
- usunąć
- usuwa
- usuwanie
- obsługi produkcji rolnej, która zastąpiła
- wymagany
- dalsze
- wynikły
- detaliczny
- retencja
- krzepki
- run
- bieganie
- taki sam
- skalowalny
- Skala
- Seattle
- druga
- Sekcja
- widzieć
- wybierać
- wybierając
- oddzielny
- usługa
- Usługi
- Sesja
- zestaw
- powinien
- pokazać
- pokazane
- Targi
- znaczący
- Prosty
- upraszcza
- upraszczać
- ponieważ
- Rozmiar
- trochę inny
- SLP
- mały
- mniejszy
- mądry
- Migawka
- So
- Rozwiązania
- Źródło
- Typ przestrzeni
- Iskra
- specjalny
- specyficzny
- swoiście
- określony
- prędkość
- prędkości
- spędził
- SQL
- początek
- Zestawienie sprzedaży
- oświadczenia
- stacja
- Ewolucja krok po kroku
- Cel
- Nadal
- przechowywanie
- sklep
- przechowywany
- Strategia
- sznur
- taki
- Utrzymany
- system
- systemy
- stół
- Tacoma
- niż
- że
- Połączenia
- ich
- Im
- następnie
- Te
- to
- próg
- Przez
- czas
- podróż w czasie
- znak czasu
- do
- Śledzenie
- transakcyjny
- transakcje
- podróżować
- rodzaj
- niezrównany
- Aktualizacja
- zaktualizowane
- Nowości
- us
- Stosowanie
- posługiwać się
- używany
- za pomocą
- Odkurzać
- wartość
- wersja
- Wersje
- chcieć
- była
- sposoby
- we
- sieć
- usługi internetowe
- były
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- będzie
- w
- bez
- Praca
- napisać
- rok
- ty
- Twój
- zefirnet