Naukowcy nadal opracowują nowe architektury modeli dla typowych zadań uczenia maszynowego (ML). Jednym z takich zadań jest klasyfikacja obrazu, gdzie obrazy są akceptowane jako dane wejściowe, a model próbuje sklasyfikować obraz jako całość z wynikami etykiet obiektów. Przy wielu dostępnych obecnie modelach, które wykonują to zadanie klasyfikacji obrazów, praktyk ML może zadawać pytania typu: „Jaki model powinienem dostroić, a następnie wdrożyć, aby osiągnąć najlepszą wydajność na moim zbiorze danych?” A badacz ML może zadawać pytania typu: „Jak mogę wygenerować własne, rzetelne porównanie wielu architektur modeli z określonym zestawem danych, kontrolując hiperparametry szkoleniowe i specyfikacje komputera, takie jak procesory graficzne, procesory i pamięć RAM?” Pierwsze pytanie dotyczy wyboru modeli w różnych architekturach modeli, podczas gdy drugie pytanie dotyczy porównywania wyszkolonych modeli z zestawem danych testowych.
W tym poście zobaczysz, jak Klasyfikacja obrazu TensorFlow algorytm Amazon SageMaker JumpStart może uprościć implementacje wymagane do rozwiązania tych problemów. Wraz ze szczegółami realizacji w odpowiednim przykładowy notatnik Jupyter, dostępne będą narzędzia do wybierania modeli poprzez eksplorację granic Pareto, gdzie poprawa jednej metryki wydajności, takiej jak dokładność, nie jest możliwa bez pogorszenia innej metryki, takiej jak przepustowość.
Omówienie rozwiązania
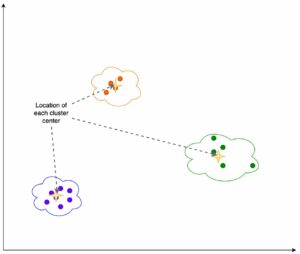
Poniższy rysunek ilustruje kompromis w zakresie wyboru modelu dla dużej liczby modeli klasyfikacji obrazów dostrojonych w programie Caltech-256 zestaw danych, który jest trudnym zestawem 30,607 256 rzeczywistych obrazów obejmujących XNUMX kategorii obiektów. Każdy punkt reprezentuje pojedynczy model, rozmiary punktów są skalowane w odniesieniu do liczby parametrów składających się na model, a punkty są kodowane kolorami na podstawie ich architektury modelu. Na przykład jasnozielone punkty reprezentują architekturę EfficientNet; każdy jasnozielony punkt to inna konfiguracja tej architektury z unikalnymi, precyzyjnie dostrojonymi pomiarami wydajności modelu. Rysunek pokazuje istnienie granicy Pareto dla wyboru modelu, gdzie większa dokładność jest wymieniana na niższą przepustowość. Ostatecznie wybór modelu wzdłuż granicy pareto lub zestawu rozwiązań efektywnych w sensie pareto zależy od wymagań wydajnościowych wdrożenia modelu.
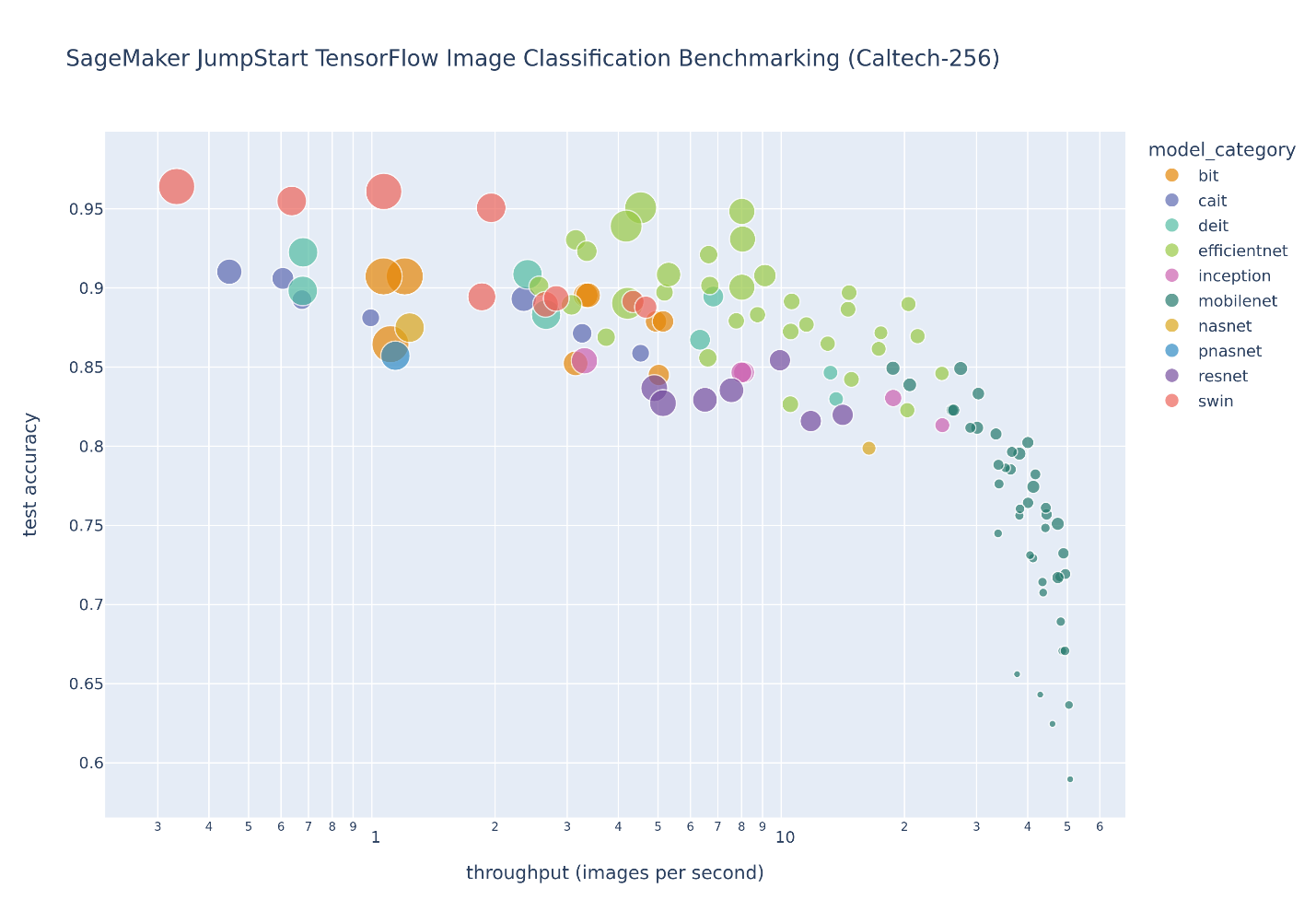
Jeśli zaobserwujesz dokładność testu i granice przepustowości testu, zestaw efektywnych rozwiązań Pareto na poprzednim rysunku zostanie wyodrębniony w poniższej tabeli. Wiersze są sortowane w taki sposób, że zwiększa się przepustowość testu, a dokładność testu maleje.
| Nazwa modelu | Liczba parametrów | Dokładność testu | Sprawdź najwyższą dokładność 5 | Przepustowość (obrazów/s) | Czas trwania na epokę (e) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| wydajny net-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| wydajnynet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| wydajny net-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| wydajna sieć-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| wydajny net-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| wydajny net-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| wydajny net-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Ten post zawiera szczegółowe informacje na temat wdrażania na dużą skalę Amazon Sage Maker zadania związane z analizą porównawczą i wyborem modeli. Najpierw przedstawiamy JumpStart i wbudowane algorytmy klasyfikacji obrazów TensorFlow. Następnie omawiamy kwestie implementacji wysokiego poziomu, takie jak konfiguracje hiperparametrów JumpStart, ekstrakcja metryk z Dzienniki Amazon CloudWatchi uruchamianie asynchronicznych zadań strojenia hiperparametrów. Na koniec omówimy środowisko implementacji i parametryzację prowadzącą do rozwiązań efektywnych w sensie Pareto w powyższej tabeli i na rysunku.
Wprowadzenie do klasyfikacji obrazów JumpStart TensorFlow
JumpStart zapewnia jednym kliknięciem dostrajanie i wdrażanie szerokiej gamy wstępnie wyszkolonych modeli w popularnych zadaniach uczenia maszynowego, a także wybór kompleksowych rozwiązań, które rozwiązują typowe problemy biznesowe. Te funkcje eliminują ciężkie prace na każdym etapie procesu uczenia maszynowego, ułatwiając opracowywanie modeli wysokiej jakości i skracając czas wdrażania. The Interfejsy API JumpStart umożliwiają programowe wdrażanie i dostrajanie szerokiej gamy wstępnie wyszkolonych modeli na własnych zestawach danych.
Hub modelu JumpStart zapewnia dostęp do dużej liczby Modele klasyfikacji obrazów TensorFlow które umożliwiają transfer uczenia się i dostrajanie na niestandardowych zestawach danych. W chwili pisania tego tekstu centrum modeli JumpStart zawiera 135 modeli klasyfikacji obrazów TensorFlow w różnych popularnych architekturach modeli, od Centrum TensorFlow, aby uwzględnić sieci rezydualne (ResNet), Sieć komórkowa, Wydajna sieć, Początek, Sieci wyszukiwania architektury neuronowej (NASNet), duży przelew (Fragment), przesunięte okno (Świnka) transformatory, uwaga klasowa w transformatorach obrazu (Cait) i Transformatory obrazu wydajne pod względem danych (Deit).
Każda architektura modelu składa się z bardzo różnych struktur wewnętrznych. Na przykład modele ResNet wykorzystują połączenia pomijane, aby umożliwić znacznie głębsze sieci, podczas gdy modele oparte na transformatorach wykorzystują mechanizmy samouwagi, które eliminują wewnętrzną lokalizację operacji splotu na rzecz bardziej globalnych pól receptywnych. Oprócz różnorodnych zestawów funkcji, które zapewniają te różne struktury, każda architektura modelu ma kilka konfiguracji, które dostosowują rozmiar, kształt i złożoność modelu w ramach tej architektury. Dzięki temu w centrum modeli JumpStart dostępne są setki unikalnych modeli klasyfikacji obrazów. W połączeniu z wbudowanymi skryptami do nauki transferu i wnioskowania, które obejmują wiele funkcji SageMaker, JumpStart API jest doskonałym punktem startowym dla praktyków ML, aby szybko rozpocząć szkolenie i wdrażanie modeli.
Odnosić się do Transfer uczenia się dla modeli klasyfikacji obrazów TensorFlow w Amazon SageMaker i następujące przykładowy notatnik aby dowiedzieć się więcej o klasyfikacji obrazów SageMaker TensorFlow, w tym o tym, jak uruchamiać wnioskowanie na wstępnie wytrenowanym modelu, a także dostrajać wstępnie wytrenowany model na niestandardowym zbiorze danych.
Rozważania dotyczące wyboru modelu na dużą skalę
Wybór modelu to proces wyboru najlepszego modelu ze zbioru modeli kandydujących. Proces ten można zastosować w modelach tego samego typu z różnymi wagami parametrów oraz w modelach różnych typów. Przykłady wyboru modelu w modelach tego samego typu obejmują dopasowanie tego samego modelu z różnymi hiperparametrami (na przykład szybkość uczenia się) i wczesne zatrzymanie, aby zapobiec nadmiernemu dopasowaniu wag modelu do zestawu danych pociągu. Wybór modelu wśród modeli różnych typów obejmuje wybór najlepszej architektury modelu (na przykład Swin vs. MobileNet) oraz wybór najlepszych konfiguracji modelu w ramach pojedynczej architektury modelu (na przykład mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
Zagadnienia przedstawione w tej sekcji umożliwiają wszystkie te procesy wyboru modelu w zbiorze danych walidacji.
Wybierz konfiguracje hiperparametrów
Klasyfikacja obrazu TensorFlow w JumpStart ma dużą liczbę dostępnych hiperparametry które mogą jednakowo dostosować zachowanie skryptu uczenia transferu dla wszystkich architektur modeli. Te hiperparametry odnoszą się do rozszerzania i wstępnego przetwarzania danych, specyfikacji optymalizatora, kontrolek nadmiernego dopasowania i wskaźników warstw, które można trenować. Zachęcamy do dostosowania domyślnych wartości tych hiperparametrów, jeśli jest to konieczne dla Twojej aplikacji:
W przypadku tej analizy i powiązanego notatnika wszystkie hiperparametry są ustawione na wartości domyślne, z wyjątkiem szybkości uczenia, liczby epok i specyfikacji wczesnego zatrzymania. Szybkość uczenia się jest dostosowywana jako a parametr kategoryczny przez Automatyczne dostrajanie modelu SageMaker stanowisko. Ponieważ każdy model ma unikalne domyślne wartości hiperparametrów, dyskretna lista możliwych szybkości uczenia się obejmuje domyślną szybkość uczenia się oraz jedną piątą domyślnej szybkości uczenia się. Spowoduje to uruchomienie dwóch zadań szkoleniowych dla pojedynczego zadania dostrajania hiperparametrów i wybranie zadania szkoleniowego z najlepszą zgłoszoną wydajnością w zestawie danych sprawdzania poprawności. Ponieważ liczba epok jest ustawiona na 10, czyli jest większa niż domyślne ustawienie hiperparametru, wybrane najlepsze zadanie szkoleniowe nie zawsze odpowiada domyślnej szybkości uczenia się. Wreszcie kryterium wczesnego zatrzymania jest stosowane z cierpliwością lub liczbą epok do kontynuowania treningu bez poprawy wynoszącą trzy epoki.
Jednym z domyślnych ustawień hiperparametru o szczególnym znaczeniu jest train_only_on_top_layer, gdzie, jeśli ustawione na True, warstwy ekstrakcji cech modelu nie są precyzyjnie dostrojone do dostarczonego zestawu danych szkoleniowych. Optymalizator będzie trenował parametry tylko w najwyższej, w pełni połączonej warstwie klasyfikacji z wymiarowością wyjściową równą liczbie etykiet klas w zbiorze danych. Domyślnie ten hiperparametr jest ustawiony na True, które jest ustawieniem przeznaczonym do przenoszenia nauki na małych zestawach danych. Możesz mieć niestandardowy zestaw danych, w którym ekstrakcja funkcji z wstępnego szkolenia w zestawie danych ImageNet nie jest wystarczająca. W takich przypadkach należy ustawić train_only_on_top_layer do False. Chociaż to ustawienie wydłuży czas uczenia, wyodrębnisz bardziej znaczące funkcje dla interesującego Cię problemu, zwiększając w ten sposób dokładność.
Wyodrębnij metryki z dzienników CloudWatch
Algorytm klasyfikacji obrazu JumpStart TensorFlow niezawodnie rejestruje różne dane podczas treningu, które są dostępne dla SageMaker Estimator i obiekty HyperparameterTuner. Konstruktor SageMaker Estimator ma metric_definitions argument słowa kluczowego, który można wykorzystać do oceny pracy szkoleniowej, udostępniając listę słowników z dwoma kluczami: Nazwa dla nazwy metryki oraz Regex dla wyrażenia regularnego używanego do wyodrębnienia metryki z dzienników. Towarzyszący notatnik pokazuje szczegóły implementacji. W poniższej tabeli wymieniono dostępne metryki i powiązane wyrażenia regularne dla wszystkich modeli klasyfikacji obrazów JumpStart TensorFlow.
| Nazwa metryki | Wyrażenie regularne |
| liczba parametrów | „- Liczba parametrów: ([0-9\.]+)” |
| liczba możliwych do wytrenowania parametrów | „- Liczba możliwych do nauczenia parametrów: ([0-9\.]+)” |
| liczba parametrów, których nie można trenować | „- Liczba parametrów, których nie można trenować: ([0-9\.]+)” |
| metryka zbioru danych pociągu | f”- {metryka}: ([0-9\.]+)” |
| metryka zbioru danych walidacji | f”- val_{metryka}: ([0-9\.]+)” |
| metryka zbioru danych testowych | f”- Test {metryka}: ([0-9\.]+)” |
| czas trwania pociągu | „- Całkowity czas szkolenia: ([0-9\.]+)” |
| czas trwania pociągu na epokę | „- Średni czas trwania treningu na epokę: ([0-9\.]+)” |
| opóźnienie oceny testu | „- Opóźnienie oceny testu: ([0-9\.]+)” |
| opóźnienie testu na próbkę | „- Średnie opóźnienie testu na próbkę: ([0-9\.]+)” |
| przepustowość testowa | „- Średnia przepustowość testu: ([0-9\.]+)” |
Wbudowany skrypt uczenia transferu zapewnia różnorodne metryki zestawu danych pociągu, sprawdzania poprawności i testowania w ramach tych definicji, reprezentowane przez wartości zastępcze ciągów f. Dokładne dostępne metryki różnią się w zależności od typu przeprowadzanej klasyfikacji. Wszystkie skompilowane modele mają loss metryka, która jest reprezentowana przez utratę entropii krzyżowej dla problemu klasyfikacji binarnej lub kategorycznej. Pierwsza jest używana, gdy istnieje jedna etykieta klasy; ta ostatnia jest używana, jeśli istnieją dwie lub więcej etykiet klas. Jeśli istnieje tylko jedna etykieta klasy, następujące metryki są obliczane, rejestrowane i możliwe do wyodrębnienia za pomocą wyrażeń regularnych f-string w poprzedniej tabeli: liczba prawdziwych trafień (true_pos), liczba fałszywych alarmów (false_pos), liczba prawdziwych negatywów (true_neg), liczba wyników fałszywie ujemnych (false_neg), precision, recall, pole pod krzywą charakterystyki działania odbiornika (ROC) (auc) i obszar pod krzywą precyzji-przywołania (PR) (prc). Podobnie, jeśli istnieje sześć lub więcej etykiet klasy, metryka dokładności 5 najlepszych (top_5_accuracy) można również obliczyć, zarejestrować i wyodrębnić za pomocą powyższych wyrażeń regularnych.
Podczas szkolenia metryki określone dla SageMaker Estimator są wysyłane do dzienników CloudWatch. Po zakończeniu szkolenia możesz wywołać SageMaker opisuje API TrainingJob i sprawdź FinalMetricDataList klucz w odpowiedzi JSON:
Ten interfejs API wymaga podania tylko nazwy zadania w zapytaniu, więc po zakończeniu można uzyskać metryki w przyszłych analizach, o ile nazwa zadania szkoleniowego jest odpowiednio rejestrowana i możliwa do odzyskania. W przypadku tego zadania wyboru modelu zapisywane są nazwy zadań dostrajania hiperparametrów, a kolejne analizy są ponownie dołączane HyperparameterTuner podając nazwę zadania dostrajania, wyodrębnij najlepszą nazwę zadania szkoleniowego z dołączonego tunera hiperparametrów, a następnie wywołaj DescribeTrainingJob API, jak opisano wcześniej, aby uzyskać metryki związane z najlepszą pracą szkoleniową.
Uruchom asynchroniczne zadania dostrajania hiperparametrów
Patrz odpowiedni notatnik aby uzyskać szczegółowe informacje na temat implementacji asynchronicznego uruchamiania zadań dostrajania parametrów, które korzystają ze standardowej biblioteki języka Python równoczesne kontrakty futures module, interfejs wysokiego poziomu do asynchronicznie uruchamianych funkcji wywoływalnych. W tym rozwiązaniu zaimplementowano kilka kwestii związanych z SageMaker:
- Każde konto AWS jest powiązane Limity usługi SageMaker. Powinieneś zobaczyć swoje obecne limity, aby w pełni wykorzystać swoje zasoby i potencjalnie zażądać zwiększenia limitu zasobów w razie potrzeby.
- Częste wywołania API w celu utworzenia wielu jednoczesnych zadań strojenia hiperparametrów mogą przekraczać szybkość Python SDK i zgłaszać wyjątki ograniczania. Rozwiązaniem tego problemu jest utworzenie klienta SageMaker Boto3 z niestandardową konfiguracją ponawiania.
- Co się stanie, jeśli skrypt napotka błąd lub zostanie zatrzymany przed zakończeniem? W przypadku tak dużego wyboru modeli lub badania porównawczego można rejestrować nazwy zadań dostrajania i udostępniać wygodne funkcje ponownie dołącz zadania dostrajania hiperparametrów które już istnieją:
Szczegóły analizy i dyskusja
Analiza w tym poście dotyczy nauki transferu identyfikatory modeli w algorytmie klasyfikacji obrazu JumpStart TensorFlow na zbiorze danych Caltech-256. Wszystkie zadania szkoleniowe zostały wykonane na instancji szkoleniowej SageMaker ml.g4dn.xlarge, która zawiera pojedynczy procesor graficzny NVIDIA T4.
Zestaw danych testowych jest oceniany w wystąpieniu szkoleniowym na końcu szkolenia. Wybór modelu jest wykonywany przed oceną zestawu danych testowych, aby ustawić wagi modelu dla epoki z najlepszą wydajnością zestawu walidacyjnego. Przepustowość testu nie jest zoptymalizowana: rozmiar partii zestawu danych jest ustawiony na domyślny rozmiar partii hiperparametru szkoleniowego, który nie jest dostosowywany w celu maksymalizacji użycia pamięci GPU; zgłoszona przepustowość testowa obejmuje czas ładowania danych, ponieważ zestaw danych nie jest wstępnie buforowany; i rozproszone wnioskowanie na wiele procesorów graficznych nie jest wykorzystywane. Z tych powodów ta przepływność jest dobrą względną miarą, ale rzeczywista przepływność zależy w dużej mierze od konfiguracji wdrożenia punktu końcowego wnioskowania dla przeszkolonego modelu.
Chociaż centrum modelu JumpStart zawiera wiele typów architektury klasyfikacji obrazów, ta granica pareto jest zdominowana przez wybrane modele Swin, EfficientNet i MobileNet. Modele Swin są większe i stosunkowo dokładniejsze, podczas gdy modele MobileNet są mniejsze, stosunkowo mniej dokładne i odpowiednie dla ograniczeń zasobów urządzeń mobilnych. Należy zauważyć, że ta granica jest uwarunkowana różnymi czynnikami, w tym dokładnym używanym zestawem danych i wybranymi hiperparametrami dostrajania. Może się okazać, że Twój niestandardowy zestaw danych tworzy inny zestaw wydajnych rozwiązań Pareto i możesz chcieć dłuższych czasów uczenia z różnymi parametrami, takimi jak większe rozszerzanie danych lub dostrajanie więcej niż tylko górnej warstwy klasyfikacji modelu.
Wnioski
W tym poście pokazaliśmy, jak uruchamiać zadania wyboru modeli lub testów porównawczych na dużą skalę za pomocą centrum modeli JumpStart. To rozwiązanie pomoże Ci wybrać najlepszy model dla Twoich potrzeb. Zachęcamy do wypróbowania i zbadania tego rozwiązanie na własnym zbiorze danych.
Referencje
Więcej informacji można znaleźć w następujących zasobach:
O autorach
 dr Kyle Ulrich jest naukowcem z Wbudowane algorytmy Amazon SageMaker zespół. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametryczne Bayesa i procesy Gaussa. Jego doktorat uzyskał na Uniwersytecie Duke'a i publikował artykuły w czasopismach NeurIPS, Cell i Neuron.
dr Kyle Ulrich jest naukowcem z Wbudowane algorytmy Amazon SageMaker zespół. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametryczne Bayesa i procesy Gaussa. Jego doktorat uzyskał na Uniwersytecie Duke'a i publikował artykuły w czasopismach NeurIPS, Cell i Neuron.
 Dr Ashish Khetan jest Starszym Naukowcem Stosowanym z Wbudowane algorytmy Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego. Opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest Starszym Naukowcem Stosowanym z Wbudowane algorytmy Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego. Opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- O nas
- dostęp
- dostępny
- Konto
- precyzja
- dokładny
- Osiągać
- w poprzek
- aktywny
- dodatek
- adres
- Adresy
- Skorygowana
- Powiązane
- przed
- algorytm
- Algorytmy
- Wszystkie kategorie
- już
- Chociaż
- zawsze
- Amazonka
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- analiza
- i
- Inne
- api
- Zastosowanie
- stosowany
- odpowiednio
- architektura
- POWIERZCHNIA
- argument
- powiązany
- dołączać
- Próby
- automatycznie
- dostępny
- średni
- AWS
- na podstawie
- Bayesian
- bo
- zanim
- jest
- BEST
- Duży
- wbudowany
- biznes
- Połączenia
- kandydat
- Etui
- kategorie
- wyzwanie
- charakterystyka
- Dodaj
- klasa
- klasyfikacja
- Klasyfikuj
- klient
- połączony
- wspólny
- porównanie
- kompletny
- Zakończony
- ukończenia
- kompleksowość
- komputer
- Wizja komputerowa
- Obawy
- konferencje
- systemu
- połączony
- połączenia
- Rozważania
- Ograniczenia
- zawiera
- kontynuować
- kontrolowania
- kontroli
- wygoda
- Odpowiedni
- pokrywa
- Stwórz
- Aktualny
- krzywa
- zwyczaj
- dane
- zbiory danych
- głębiej
- Domyślnie
- zależy
- rozwijać
- wdrażanie
- Wdrożenie
- głębokość
- opisane
- opis
- detale
- rozwijać
- urządzenia
- różne
- dyskutować
- dystrybuowane
- inny
- Nie
- Książę
- uniwersytet książęcy
- podczas
- każdy
- Wcześniej
- Wcześnie
- łatwiej
- wydajny
- bądź
- wyeliminować
- umożliwiać
- zachęcać
- zachęcać
- koniec końców
- Punkt końcowy
- Środowisko
- epoka
- epoki
- błąd
- Eter (ETH)
- oceniać
- oceniane
- ewaluację
- przykład
- przykłady
- Z wyjątkiem
- odkryj
- Exploring
- wyrażeń
- wyciąg
- ekstrakcja
- Czynniki
- sprawiedliwy
- faworyzować
- Cecha
- Korzyści
- Łąka
- Postać
- W końcu
- Znajdź
- i terminów, a
- dopasowywanie
- następujący
- Dawny
- od
- Granica
- Frontiers
- w pełni
- Funkcje
- przyszłość
- Futures
- Generować
- otrzymać
- dany
- Globalne
- dobry
- GPU
- GPU
- wspaniały
- większy
- Zielony
- dzieje
- ciężko
- pomoc
- pomaga
- na wysokim szczeblu
- wysokiej jakości
- wyższy
- W jaki sposób
- How To
- HTML
- HTTPS
- Piasta
- Setki
- Dostrajanie hiperparametrów
- ICLR
- Illinois
- obraz
- Klasyfikacja obrazu
- ImageNet
- zdjęcia
- wdrożenia
- realizacja
- realizowane
- znaczenie
- ważny
- poprawa
- poprawy
- in
- zawierać
- obejmuje
- Włącznie z
- Zwiększać
- Zwiększenia
- wzrastający
- wskaźniki
- Informacja
- wkład
- przykład
- odsetki
- zainteresowania
- Interfejs
- wewnętrzny
- wewnętrzny
- przedstawiać
- IT
- Praca
- Oferty pracy
- json
- Klawisz
- Klawisze
- Etykieta
- Etykiety
- duży
- na dużą skalę
- większe
- Utajenie
- uruchamia
- wodowanie
- warstwa
- nioski
- prowadzący
- UCZYĆ SIĘ
- nauka
- Modernizacja
- lekki
- LIMIT
- Limity
- Lista
- wykazy
- załadunek
- długo
- dłużej
- od
- maszyna
- uczenie maszynowe
- Dokonywanie
- wiele
- Maksymalizuj
- wymowny
- Pomiary
- Pamięć
- metryczny
- Metryka
- ML
- Aplikacje mobilne
- urządzenia mobilne
- model
- modele
- moduł
- jeszcze
- wielokrotność
- Nazwa
- Nazwy
- niezbędny
- potrzebne
- wymagania
- sieci
- Nerwowy
- NeuroIPS
- Nowości
- notatnik
- numer
- Nvidia
- przedmiot
- obiekty
- obserwować
- uzyskać
- uzyskane
- ONE
- operacyjny
- operacje
- zoptymalizowane
- opisane
- własny
- Papiery
- parametr
- parametry
- szczególny
- Cierpliwość
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- Popularny
- możliwy
- Post
- potencjalnie
- pr
- zapobiec
- Wcześniejszy
- Problem
- problemy
- wygląda tak
- procesów
- zapewniać
- pod warunkiem,
- zapewnia
- że
- opublikowany
- Python
- pytanie
- pytania
- szybko
- RAM
- Kurs
- ceny
- Prawdziwy świat
- Przyczyny
- redukcja
- regularny
- stosunkowo
- usunąć
- Zgłoszone
- reprezentować
- reprezentowane
- reprezentuje
- zażądać
- wymagany
- wymagania
- Wymaga
- Badania naukowe
- badacz
- Rozkład
- Zasób
- Zasoby
- odpowiedź
- Efekt
- run
- bieganie
- sagemaker
- taki sam
- skalowalny
- Naukowiec
- skrypty
- Sdk
- Szukaj
- Sekcja
- wybrany
- wybierając
- wybór
- senior
- Serie
- usługa
- Sesja
- zestaw
- Zestawy
- ustawienie
- kilka
- Shape
- powinien
- Targi
- Podobnie
- upraszczać
- jednoczesny
- pojedynczy
- SIX
- Rozmiar
- rozmiary
- mały
- mniejszy
- So
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- specyfikacja
- Specyfikacje
- określony
- standard
- rozpoczęty
- statystyczny
- Ewolucja krok po kroku
- zatrzymany
- zatrzymanie
- przechowywany
- Badanie
- kolejny
- w zasadzie
- taki
- wystarczający
- odpowiedni
- stół
- ukierunkowane
- Zadanie
- zadania
- zespół
- tensorflow
- test
- Połączenia
- ich
- a tym samym
- trzy
- wydajność
- czas
- Szereg czasowy
- czasy
- do
- już dziś
- razem
- narzędzia
- Top
- top 5
- Kwota produktów:
- Pociąg
- przeszkolony
- Trening
- przenieść
- Transformatory
- prawdziwy
- typy
- Ostatecznie
- dla
- wyjątkowy
- uniwersytet
- Stosowanie
- posługiwać się
- wykorzystać
- wykorzystany
- uprawomocnienie
- Wartości
- różnorodność
- Naprawiono
- przez
- Zobacz i wysłuchaj
- wizja
- który
- Podczas
- szeroki
- będzie
- w ciągu
- bez
- by
- pisanie
- Twój
- zefirnet