W tym artykule dowiemy się jak wdrożyć i używać modelu GPT4All na komputerze z samym procesorem (używam ok Macbook Pro bez GPU!)

Użyj GPT4All na swoim komputerze — Zdjęcie autorstwa autora
W tym artykule zainstalujemy na naszym lokalnym komputerze GPT4All (potężny LLM) i odkryjemy, jak wchodzić w interakcje z naszymi dokumentami za pomocą Pythona. Zbiór plików PDF lub artykułów online będzie bazą wiedzy dla naszych pytań/odpowiedzi.
Z oficjalna strona GPT4All jest opisany jako darmowy, działający lokalnie, świadomy prywatności chatbot. Nie wymaga GPU ani Internetu.
GTP4All to ekosystem do trenowania i wdrażania mocny i dostosowane uruchamiane duże modele językowe lokalnie na procesorach klasy konsumenckiej.
Nasz model GPT4All to plik o wielkości 4 GB, który można pobrać i podłączyć do oprogramowania ekosystemu GPT4All typu open source. Nomiczna sztuczna inteligencja ułatwia tworzenie wysokiej jakości i bezpiecznych ekosystemów oprogramowania, stymulując wysiłki na rzecz umożliwienia jednostkom i organizacjom bezproblemowego szkolenia i wdrażania własnych, dużych modeli językowych lokalnie.
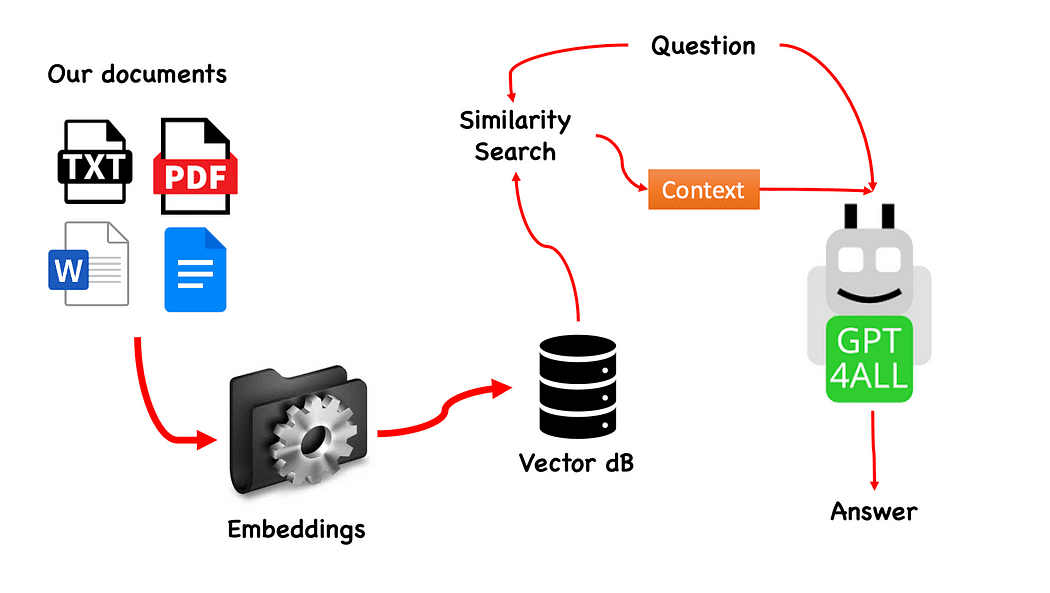
Workflow QnA z GPT4All — stworzony przez autora
Proces jest naprawdę prosty (jeśli go znasz) i można go powtórzyć również z innymi modelami. Kroki są następujące:
- załaduj model GPT4All
- posługiwać się Langchaina aby pobrać nasze dokumenty i załadować je
- podziel dokumenty na małe fragmenty, które będą przyswajalne przez Embeddings
- Skorzystaj z FAISS, aby utworzyć naszą bazę danych wektorów z osadzonymi elementami
- Wykonaj wyszukiwanie podobieństw (wyszukiwanie semantyczne) w naszej bazie danych wektorów na podstawie pytania, które chcemy przekazać do GPT4All: zostanie ono użyte jako kontekst na nasze pytanie
- Przekaż pytanie i kontekst GPT4All za pomocą Langchaina i czekać na odpowiedź.
Potrzebujemy więc Embeddings. Osadzanie to liczbowa reprezentacja fragmentu informacji, na przykład tekstu, dokumentów, obrazów, dźwięku itp. Reprezentacja oddaje semantyczne znaczenie tego, co jest osadzane, i właśnie tego potrzebujemy. W przypadku tego projektu nie możemy polegać na ciężkich modelach GPU: pobierzemy więc natywny model Alpaki i użyjemy go Langchaina dotychczasowy LamaCppEmbeddings. Nie martw się! Wszystko jest wyjaśnione krok po kroku
Stwórz środowisko wirtualne
Utwórz nowy folder dla swojego nowego projektu w Pythonie, na przykład GPT4ALL_Fabio (wpisz swoje imię…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioNastępnie utwórz nowe środowisko wirtualne języka Python. Jeśli masz zainstalowaną więcej niż jedną wersję Pythona, określ żądaną wersję: w tym przypadku użyję mojej głównej instalacji, powiązanej z Pythonem 3.10.
python3 -m venv .venvKomenda python3 -m venv .venv tworzy nowe środowisko wirtualne o nazwie .venv (kropka utworzy ukryty katalog o nazwie venv).
Środowisko wirtualne zapewnia izolowaną instalację Pythona, która umożliwia instalowanie pakietów i zależności tylko dla określonego projektu bez wpływu na ogólnosystemową instalację Pythona lub inne projekty. Ta izolacja pomaga zachować spójność i zapobiegać potencjalnym konfliktom między różnymi wymaganiami projektowymi.
Po utworzeniu środowiska wirtualnego możesz je aktywować za pomocą następującego polecenia:
source .venv/bin/activate 
Aktywowane środowisko wirtualne
Biblioteki do zainstalowania
Do projektu, który budujemy, nie potrzebujemy zbyt wielu pakietów. Potrzebujemy tylko:
- powiązania Pythona dla GPT4All
- Langchain do interakcji z naszymi dokumentami
LangChain to framework do tworzenia aplikacji opartych na modelach językowych. Pozwala nie tylko wywoływać model językowy za pośrednictwem interfejsu API, ale także łączyć model językowy z innymi źródłami danych i pozwalać modelowi językowemu na interakcję z jego środowiskiem.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4W przypadku LangChain widać, że podaliśmy również wersję. Ta biblioteka otrzymuje ostatnio wiele aktualizacji, więc aby mieć pewność, że nasza konfiguracja będzie działać również jutro, lepiej jest określić wersję, o której wiemy, że działa dobrze. Unstructured jest wymaganą zależnością dla modułu ładującego pdf i piteserakt i pdf2obraz , jak również.
UWAGA: na repozytorium GitHub znajduje się plik requirements.txt (sugerowany przez jl przym) ze wszystkimi wersjami powiązanymi z tym projektem. Możesz przeprowadzić instalację za jednym zamachem, po pobraniu jej do głównego katalogu plików projektu za pomocą następującego polecenia:
pip install -r requirements.txtNa końcu artykułu stworzyłem a sekcja dotycząca rozwiązywania problemów. Repozytorium GitHub ma również zaktualizowany READ.ME ze wszystkimi tymi informacjami.
Pamiętaj, że niektórzy biblioteki mają dostępne wersje w zależności od wersji Pythona pracujesz w swoim środowisku wirtualnym.
Pobierz na swój komputer modele
To naprawdę ważny krok.
Do projektu z pewnością potrzebujemy GPT4All. Proces opisany na Nomic AI jest naprawdę skomplikowany i wymaga sprzętu, który nie każdy z nas posiada (tak jak ja). Więc oto link do modelu już przekształcony i gotowy do użycia. Po prostu kliknij pobierz.
Pobierz model GPT4All
Jak opisano pokrótce we wstępie, potrzebujemy również modelu osadzania, modelu, który możemy uruchomić na naszym procesorze bez miażdżenia. Kliknij link tutaj, aby pobrać alpaca-native-7B-ggml już przekonwertowany na 4-bitowy i gotowy do użycia jako nasz model osadzania.

Kliknij strzałkę pobierania obok ggml-model-q4_0.bin
Dlaczego potrzebujemy osadzania? Jeśli pamiętasz ze schematu blokowego, pierwszym wymaganym krokiem po zebraniu dokumentów do naszej bazy wiedzy jest osadzać ich. Osadzenia LLamaCPP z tego modelu Alpaca idealnie pasują do tego zadania, a ten model jest również dość mały (4 Gb). Nawiasem mówiąc, możesz również użyć modelu Alpaca dla swojego QnA!
Aktualizacja 2023.05.25: Użytkownicy systemu Mani Windows mają problemy z korzystaniem z osadzania llamaCPP. Dzieje się tak głównie dlatego, że podczas instalacji pakietu python llama-cpp-python z:
pip install llama-cpp-pythonpakiet pip skompiluje ze źródła bibliotekę. Windows zwykle nie ma domyślnie zainstalowanego kompilatora CMake ani C na komputerze. Ale nie bój się, istnieje rozwiązanie
Uruchamianie instalacji llama-cpp-python, wymaganej przez LangChain z llamaEmbeddings, w systemie Windows Kompilator CMake C nie jest instalowany domyślnie, więc nie można budować ze źródła.
Na komputerach Mac z Xtools i na Linuksie zwykle kompilator C jest już dostępny w systemie operacyjnym.
Aby uniknąć problemu MUSISZ użyć wstępnie zgodnego koła.
Kliknij tutaj, https://github.com/abetlen/llama-cpp-python/releases
i poszukaj zgodnego koła dla swojej architektury i wersji Pythona — MUSISZ wziąć Weels w wersji 0.1.49 ponieważ wyższe wersje nie są kompatybilne.
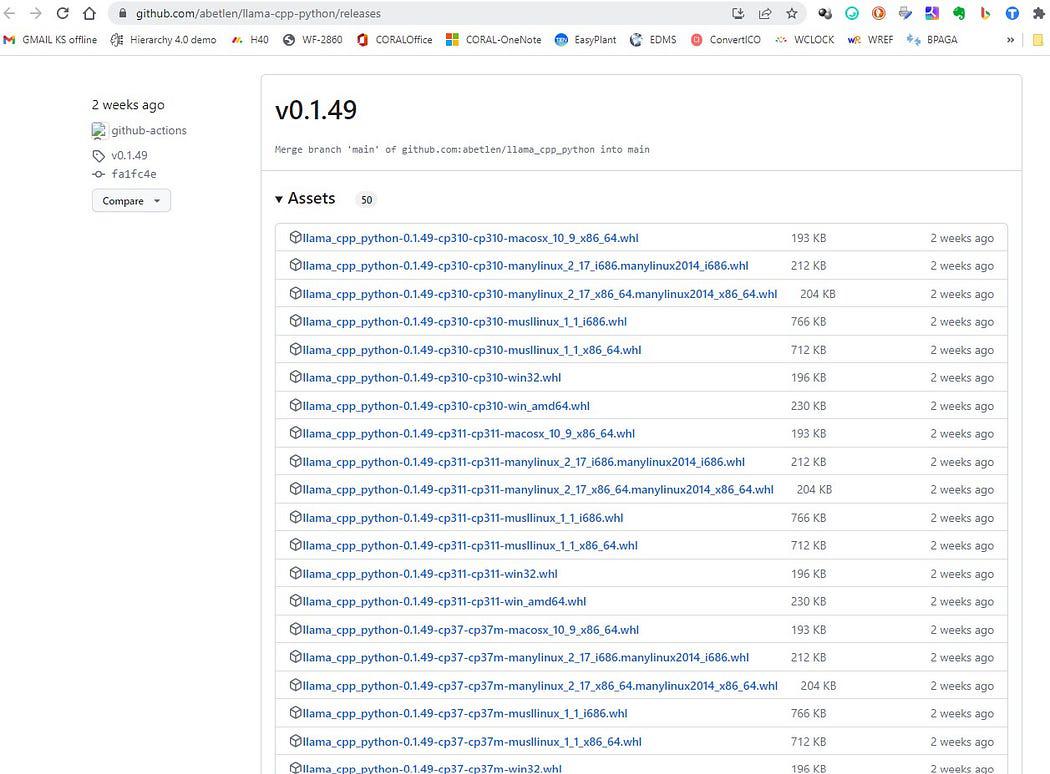
Zrzut ekranu z https://github.com/abetlen/llama-cpp-python/releases
W moim przypadku mam Windows 10, 64-bitowy, python 3.10
więc mój plik to llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
To zdjęcie problem jest śledzony w repozytorium GitHub
Po pobraniu musisz umieścić dwa modele w katalogu modeli, jak pokazano poniżej.

Struktura katalogów i gdzie umieścić pliki modelu
Ponieważ chcemy mieć kontrolę nad naszą interakcją w modelu GPT, musimy utworzyć plik Pythona (nazwijmy go pygpt4all_test.py), zaimportuj zależności i podaj instrukcję modelowi. Zobaczysz, że to całkiem łatwe.
from pygpt4all.models.gpt4all import GPT4AllTo jest powiązanie Pythona dla naszego modelu. Teraz możemy to nazwać i zacząć pytać. Spróbujmy kreatywnego.
Tworzymy funkcję, która odczytuje wywołanie zwrotne z modelu i prosimy GPT4All o dokończenie naszego zdania.
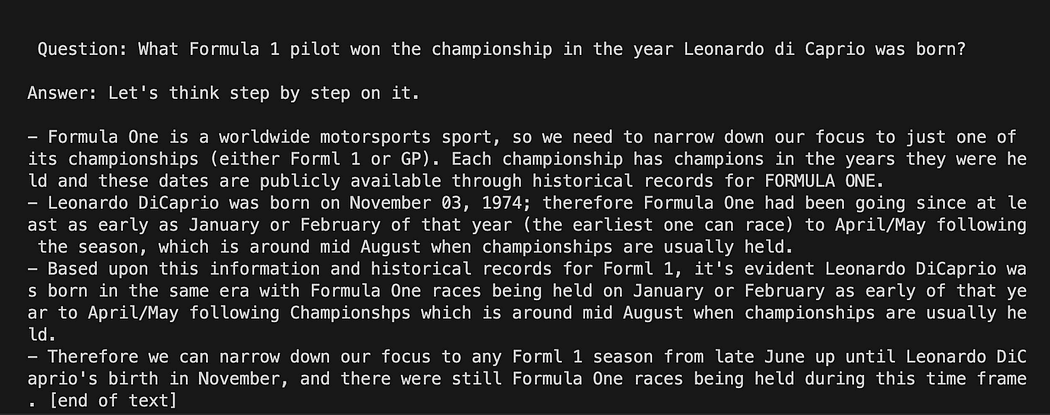
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Pierwsza instrukcja mówi naszemu programowi, gdzie znaleźć model (pamiętaj, co zrobiliśmy w sekcji powyżej)
Drugie stwierdzenie polega na poproszeniu modelu o wygenerowanie odpowiedzi i uzupełnienie naszego monitu „Dawno, dawno temu”.
Aby go uruchomić, upewnij się, że środowisko wirtualne jest nadal aktywne i po prostu uruchom:
python3 pygpt4all_test.pyPowinieneś zobaczyć ładujący się tekst modelu i zakończenie zdania. W zależności od zasobów sprzętowych może to zająć trochę czasu.
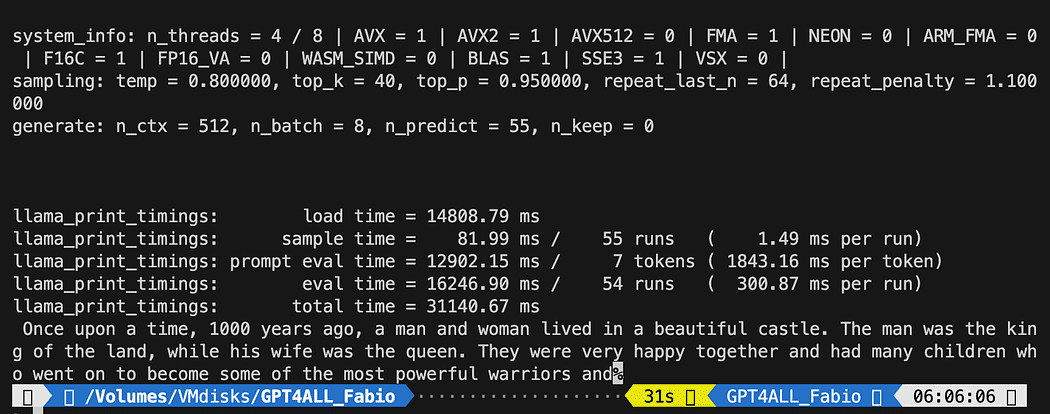
Wynik może być inny niż twój… Ale dla nas ważne jest to, że działa i możemy przystąpić do LangChain, aby stworzyć zaawansowane rzeczy.
UWAGA (aktualizacja 2023.05.23): jeśli napotkasz błąd związany z pygpt4all, sprawdź sekcję rozwiązywania problemów na ten temat z rozwiązaniem podanym przez Rajneesha Aggarwala or autorstwa Oscara Jeonga.
Framework LangChain to naprawdę niesamowita biblioteka. To zapewnia Podzespoly Komputerowe do pracy z modelami językowymi w łatwy w użyciu sposób, a także zapewnia Więzy. Łańcuchy można traktować jako łączenie tych komponentów w określony sposób, aby jak najlepiej zrealizować określony przypadek użycia. Mają one stanowić interfejs wyższego poziomu, dzięki któremu ludzie mogą łatwo rozpocząć pracę z określonym przypadkiem użycia. Te łańcuchy są również zaprojektowane tak, aby można je było dostosować.
W naszym następnym teście Pythona użyjemy pliku a Szablon zachęty. Modele językowe przyjmują tekst jako dane wejściowe — ten tekst jest powszechnie określany jako monit. Zwykle nie jest to po prostu zakodowany ciąg znaków, ale raczej połączenie szablonu, kilku przykładów i danych wprowadzonych przez użytkownika. LangChain udostępnia kilka klas i funkcji ułatwiających konstruowanie podpowiedzi i pracę z nimi. Zobaczmy, jak my też możemy to zrobić.
Utwórz nowy plik Pythona i nazwij go my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Zaimportowaliśmy z LangChain klasę Prompt Template and Chain oraz GPT4All llm, aby móc bezpośrednio wchodzić w interakcje z naszym modelem GPT.
Następnie, po ustawieniu naszej ścieżki llm (jak to zrobiliśmy wcześniej), tworzymy instancję menedżerów wywołań zwrotnych, abyśmy mogli przechwycić odpowiedzi na nasze zapytanie.
Tworzenie szablonu jest naprawdę proste: postępuj zgodnie z samouczek dokumentacji możemy użyć czegoś takiego…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Połączenia szablon zmienna to wielowierszowy łańcuch zawierający naszą strukturę interakcji z modelem: w nawiasach klamrowych wstawiamy zmienne zewnętrzne do szablonu, w naszym scenariuszu jest to nasza pytanie.
Ponieważ jest to zmienna, możesz zdecydować, czy jest to pytanie zakodowane na stałe, czy pytanie wprowadzone przez użytkownika: tutaj dwa przykłady.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")W przypadku naszego uruchomienia testowego skomentujemy dane wprowadzone przez użytkownika. Teraz musimy tylko połączyć nasz szablon, pytanie i model języka.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Pamiętaj, aby sprawdzić, czy środowisko wirtualne jest nadal aktywne i uruchom polecenie:
python3 my_langchain.pyMożesz uzyskać inne wyniki niż moje. Niesamowite jest to, że możesz zobaczyć całe rozumowanie, po którym GPT4All próbuje uzyskać dla ciebie odpowiedź. Dostosowanie pytania również może dać lepsze wyniki.
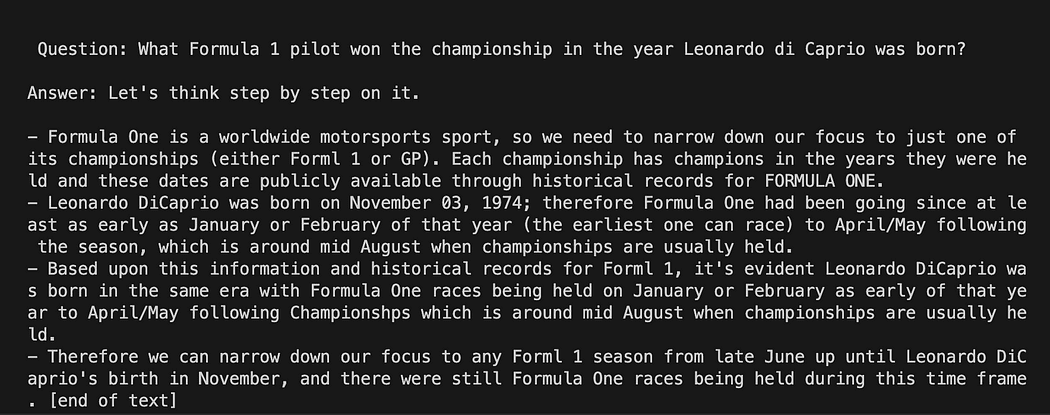
Langchain z szablonem zachęty na GPT4All
Tutaj zaczynamy niesamowitą część, ponieważ będziemy rozmawiać z naszymi dokumentami za pomocą GPT4All jako chatbota, który odpowiada na nasze pytania.
Sekwencja kroków, odnosząc się do Przepływ pracy QnA z GPT4All, polega na załadowaniu naszych plików pdf, podzieleniu ich na porcje. Następnie będziemy potrzebować Vector Store dla naszych osadzeń. Musimy zasilić nasze podzielone dokumenty w sklepie wektorowym w celu wyszukania informacji, a następnie osadzimy je razem z wyszukiwaniem podobieństwa w tej bazie danych jako kontekst dla naszego zapytania LLM.
W tym celu użyjemy FAISS bezpośrednio z Langchaina biblioteka. FAISS to biblioteka typu open source firmy Facebook AI Research, zaprojektowana w celu szybkiego znajdowania podobnych elementów w dużych zbiorach wielowymiarowych danych. Oferuje metody indeksowania i wyszukiwania, które ułatwiają i przyspieszają znajdowanie najbardziej podobnych elementów w zbiorze danych. Jest to dla nas szczególnie wygodne, ponieważ upraszcza wyszukiwanie informacji i pozwalają nam zapisać lokalnie utworzoną bazę danych: oznacza to, że po pierwszym utworzeniu zostanie ona bardzo szybko załadowana do dalszego wykorzystania.
Tworzenie indeksu wektorów db
Utwórz nowy plik i nazwij go moja_wiedza_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimePierwsze biblioteki to te same, których używaliśmy wcześniej: dodatkowo używamy Langchaina do tworzenia indeksu sklepu wektorowego, LamaCppEmbeddings do interakcji z naszym modelem Alpaca (kwantyzowanym do 4-bitów i skompilowanym z biblioteką cpp) oraz modułem ładującym PDF.
Załadujmy również nasze LLM z ich własnymi ścieżkami: jedną dla osadzania i jedną dla generowania tekstu.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Dla testu sprawdźmy, czy udało nam się odczytać wszystkie pliki pfd: pierwszym krokiem jest zadeklarowanie 3 funkcji, które mają być używane na każdym pojedynczym dokumencie. Pierwszym jest podzielenie wyodrębnionego tekstu na części, drugim utworzenie indeksu wektorów z metadanymi (takimi jak numery stron itp.), a ostatnim testowanie wyszukiwania podobieństw (wyjaśnię to lepiej później).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesTeraz możemy przetestować generowanie indeksu dla dokumentów w docs katalog: musimy umieścić tam wszystkie nasze pliki pdf. Langchaina posiada również metodę ładowania całego folderu, niezależnie od typu pliku: ponieważ jest to skomplikowany proces postowania, omówię go w następnym artykule o modelach LaMini.

mój katalog dokumentów zawiera 4 pliki pdf
Zastosujemy nasze funkcje do pierwszego dokumentu na liście
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)W pierwszych liniach używamy biblioteki os, aby pobrać plik lista plików pdf w katalogu docs. Następnie ładujemy pierwszy dokument (lista_dokumentów[0]) z folderu dokumentów za pomocą Langchaina, dzielimy na porcje, a następnie tworzymy wektorową bazę danych z rozszerzeniem Lama osadzania.
Jak widzieliście, używamy Metoda pyPDF. Ten jest nieco dłuższy w użyciu, ponieważ musisz ładować pliki jeden po drugim, ale ładowanie PDF za pomocą pypdf w tablicę dokumentów pozwala mieć tablicę, w której każdy dokument zawiera zawartość strony i metadane page numer. Jest to bardzo wygodne, gdy chcesz poznać źródła kontekstu, które przekażemy GPT4All z naszym zapytaniem. Oto przykład z readthedocs:
Zrzut ekranu z Dokumentacja Langchaina
Możemy uruchomić plik Pythona za pomocą polecenia z terminala:
python3 my_knowledge_qna.pyPo załadowaniu modelu do osadzania zobaczysz tokeny w pracy do indeksowania: nie panikuj, ponieważ zajmie to trochę czasu, szczególnie jeśli działasz tylko na procesorze, tak jak ja (zajęło to 8 minut).
Ukończenie pierwszej db wektora
Jak już wyjaśniałem, metoda pyPDF jest wolniejsza, ale daje nam dodatkowe dane do wyszukiwania podobieństw. Aby przeglądać wszystkie nasze pliki, użyjemy wygodnej metody firmy FAISS, która pozwala nam łączyć ze sobą różne bazy danych. Teraz używamy powyższego kodu do wygenerowania pierwszej bazy danych (nazwiemy ją db0) i za pomocą pętli for tworzymy indeks następnego pliku na liście i natychmiast go łączymy db0.
Oto kod: zauważ, że dodałem kilka dzienników, aby uzyskać status postępu w użyciu datagodzina.datagodzina.teraz() i drukowanie delty czasu zakończenia i czasu rozpoczęcia, aby obliczyć, jak długo trwała operacja (możesz to usunąć, jeśli ci się nie podoba).
Instrukcje scalania są takie
# merge dbi with the existing db0
db0.merge_from(dbi)Jedna z ostatnich instrukcji dotyczy zapisania naszej bazy lokalnie: całe generowanie może zająć nawet godziny (w zależności od ilości posiadanych dokumentów), więc naprawdę dobrze, że musimy to zrobić tylko raz!
# Save the databasae locally
db0.save_local("my_faiss_index")Tutaj cały kod. Skomentujemy wiele jego części, gdy wejdziemy w interakcję z GPT4All, ładując indeks bezpośrednio z naszego folderu.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Uruchomienie pliku Pythona zajęło 22 minuty
Uruchomienie pliku Pythona zajęło 22 minuty
Zadawaj GPT4All pytania dotyczące swoich dokumentów
Teraz jesteśmy tutaj. Mamy nasz indeks, możemy go załadować, a dzięki szablonowi podpowiedzi możemy poprosić GPT4All o odpowiedź na nasze pytania. Zaczynamy od zakodowanego na stałe pytania, a następnie przechodzimy przez nasze pytania wejściowe.
Umieść następujący kod w pliku Pythona db_loading.py i uruchom go za pomocą polecenia z terminala python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Wydrukowany tekst to lista 3 źródeł najlepiej pasujących do zapytania, podająca nam również nazwę dokumentu i numer strony.
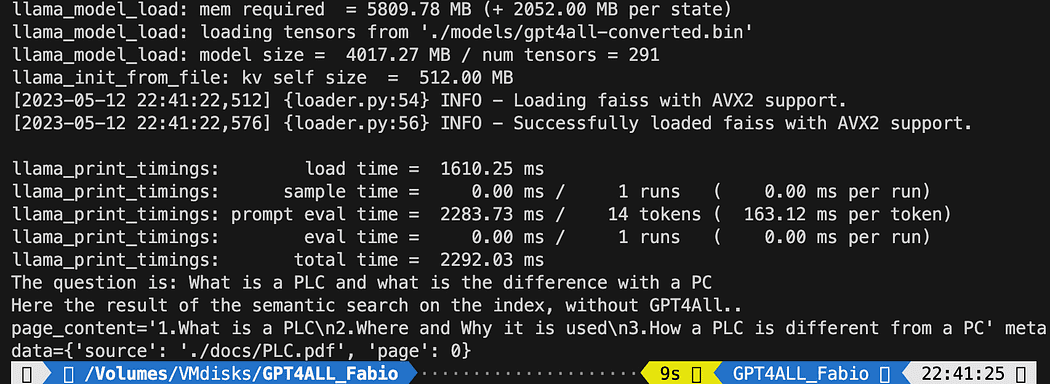
Wyniki wyszukiwania semantycznego uruchamiającego plik db_loading.py
Teraz możemy użyć wyszukiwania podobieństwa jako kontekstu dla naszego zapytania, używając szablonu zachęty. Po 3 funkcjach po prostu zastąp cały kod następującym:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Po uruchomieniu otrzymasz taki wynik (ale może się różnić). Niesamowite nie!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Jeśli chcesz, aby pytanie wprowadzane przez użytkownika zastąpiło wiersz
question = "What is a PLC and what is the difference with a PC"z czymś takim:
question = input("Your question: ")Nadszedł czas, abyś poeksperymentował. Zadawaj różne pytania na wszystkie tematy związane z Twoimi dokumentami i przeglądaj wyniki. Istnieje duże pole do ulepszeń, na pewno w monicie i szablonie: możesz rzucić okiem tutaj po inspiracje, Ale Langchaina dokumentacja jest naprawdę niesamowita (mógłbym ją śledzić!!).
Możesz śledzić kod z artykułu lub sprawdzić go moje repozytorium na githubie.
Fabia Matricardiego pedagog, nauczyciel, inżynier i entuzjasta nauki. Od 15 lat uczy młodych studentów, a teraz szkoli nowych pracowników w Key Solution Srl. Rozpoczął moją karierę jako Inżynier Automatyki Przemysłowej w 2010 roku. Pasjonat programowania odkąd był nastolatkiem, odkrył piękno tworzenia oprogramowania i interfejsów człowiek-maszyna, aby ożywić coś. Nauczanie i coaching to część mojej codziennej rutyny, podobnie jak studiowanie i uczenie się, jak być pełnym pasji liderem z aktualnymi umiejętnościami zarządzania. Dołącz do mnie w podróży w kierunku lepszego projektu, predykcyjnej integracji systemu z wykorzystaniem uczenia maszynowego i sztucznej inteligencji w całym cyklu życia inżynierii.
Oryginalny. Przesłane za zgodą.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- EVM Finanse. Ujednolicony interfejs dla zdecentralizowanych finansów. Dostęp tutaj.
- Quantum Media Group. Wzmocnienie IR/PR. Dostęp tutaj.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 11
- 12
- 13
- 14
- 15 roku
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- zdolność
- Zdolny
- O nas
- powyżej
- wykonać
- działać
- aktywowany
- w dodatku
- dodatek
- Dodatkowy
- zaawansowany
- wpływający
- Po
- AI
- ai badania
- Wszystkie kategorie
- dopuszczać
- pozwala
- już
- również
- am
- zdumiewający
- an
- analiza
- i
- odpowiedź
- każdy
- api
- aplikacje
- Aplikuj
- architektura
- SĄ
- Szyk
- artykuł
- towary
- sztuczny
- sztuczna inteligencja
- AS
- powiązany
- At
- audio
- zautomatyzowane
- automatycznie
- Automatyzacja
- dostępny
- uniknąć
- baza
- na podstawie
- BE
- Uroda
- bo
- być
- zanim
- jest
- poniżej
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- Duży
- BIN
- wiążący
- Bit
- urodzony
- krótko
- przynieść
- budować
- Budowanie
- wbudowany
- autobusy
- ale
- by
- obliczać
- wezwanie
- nazywa
- Połączenia
- CAN
- nie może
- Pojemność
- przechwytuje
- Kariera
- nieść
- walizka
- zapasy
- CD
- pewien
- na pewno
- łańcuch
- więzy
- mistrzostwo
- chatbot
- ChatGPT
- ZOBACZ
- chemiczny
- klasa
- Klasy
- kliknij
- Coaching
- kod
- Kody
- zbierać
- kolekcja
- kolekcje
- połączenie
- komentarz
- powszechnie
- komunikować
- Komunikacja
- zgodny
- kompletny
- Zakończony
- ukończenia
- kompleks
- skomplikowane
- składniki
- komputer
- komputery
- Skontaktuj się
- połączony
- budowy
- konsument
- zawiera
- zawartość
- kontekst
- kontrola
- kontroler
- kontroli
- Wygodny
- przeliczone
- mógłby
- pokrywa
- CPU
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- Twórczy
- krytyczny
- konfigurowalny
- codziennie
- dane
- Baza danych
- Bazy danych
- Data
- data i godzina
- zdecydować
- Domyślnie
- zdefiniowane
- Delta
- Zależność
- W zależności
- zależy
- rozwijać
- opisane
- Wnętrze
- zaprojektowany
- życzenia
- rozwijanie
- urządzenie
- urządzenia
- ZROBIŁ
- różnica
- różne
- strawny
- cyfrowy
- bezpośrednio
- odkryj
- odkryty
- do
- dokument
- dokumentacja
- dokumenty
- robi
- robi
- zrobić
- nie
- DOT
- pobieranie
- jazdy
- podczas
- każdy
- łatwiej
- z łatwością
- łatwo
- Ekosystem
- Ekosystemy
- wysiłek
- osadzać
- osadzone
- osadzanie
- pracowników
- umożliwiać
- zakończenia
- inżynier
- Inżynieria
- Wchodzę
- entuzjasta
- Cały
- Środowisko
- błąd
- szczególnie
- itp
- Eter (ETH)
- Parzyste
- wszystko
- dokładnie
- przykład
- przykłady
- egzekucja
- Przede wszystkim system został opracowany
- eksperyment
- Wyjaśniać
- wyjaśnione
- wyjaśniając
- zewnętrzny
- Twarz
- ułatwia
- okładzina
- FAST
- szybciej
- filet
- Akta
- Znajdź
- w porządku
- i terminów, a
- dopasować
- pływ
- obserwuj
- następnie
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Nasz formularz
- format
- formuła
- Formuła 1
- Framework
- od
- funkcjonować
- Funkcje
- dalej
- Generować
- generujący
- generacja
- otrzymać
- GitHub
- Dać
- dany
- daje
- Dający
- będzie
- dobry
- GPU
- stopień
- Prowadzenie
- dzieje
- Ciężko
- sprzęt komputerowy
- Have
- he
- ciężki
- pomaga
- tutaj
- Ukryty
- Wysoki
- wyższy
- GODZINY
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- człowiek
- i
- ICS
- if
- zdjęcia
- natychmiast
- wdrożenia
- importować
- ważny
- poprawa
- in
- zawierać
- wskaźnik
- indeksy
- osób
- przemysłowy
- automatyka przemysłowa
- przemysłowa
- Informacja
- wkład
- wejście wyjście
- Wejścia
- zainstalować
- instalacja
- przykład
- instrukcje
- integracja
- Inteligencja
- zamierzony
- interakcji
- wzajemne oddziaływanie
- Interfejs
- interfejsy
- Internet
- najnowszych
- Wprowadzenie
- odosobniony
- izolacja
- IT
- szt
- iteracja
- JEGO
- Praca
- przystąpić
- podróż
- właśnie
- Knuggety
- Klawisz
- Wiedzieć
- wiedza
- język
- duży
- Nazwisko
- później
- lider
- nauka
- poziom
- biblioteki
- Biblioteka
- życie
- wifecycwe
- lubić
- linie
- LINK
- linux
- Lista
- mało
- załadować
- ładowarka
- załadunek
- miejscowy
- lokalnie
- logika
- długo
- dłużej
- Popatrz
- Partia
- mac
- maszyna
- uczenie maszynowe
- maszyny
- Główny
- głównie
- utrzymać
- robić
- zarządzane
- i konserwacjami
- kierownik
- Zarządzający
- produkcja
- wiele
- Może..
- znaczenie
- znaczy
- Pamięć
- Łączyć
- połączenie
- Metadane
- metoda
- metody
- nic
- minuty
- model
- modele
- jeszcze
- większość
- wielokrotność
- musi
- my
- Nazwa
- rodzimy
- Potrzebować
- sieci
- Nowości
- Następny
- już dziś
- numer
- z naszej
- przedmiot
- of
- Oferty
- on
- pewnego razu
- ONE
- Online
- tylko
- open source
- działanie
- operacje
- or
- zamówienie
- organizacji
- OS
- Inne
- ludzkiej,
- na zewnątrz
- wydajność
- koniec
- własny
- pakiet
- Pakiety
- strona
- Parallel
- część
- szczególny
- szczególnie
- przechodzić
- namiętny
- ścieżka
- PC
- Ludzie
- wykonać
- pozwolenie
- osobisty
- obraz
- kawałek
- pilot
- Rośliny
- plato
- Analiza danych Platona
- PlatoDane
- PLC
- Proszę
- wtyczka
- porty
- position
- Post
- potencjał
- power
- elektrownie
- powered
- mocny
- dla
- zapobiec
- druk
- problemy
- wygląda tak
- obrobiony
- procesów
- Program
- zaprogramowany
- Programowanie
- Postęp
- projekt
- projektowanie
- protokoły
- zapewnia
- cele
- położyć
- Python
- jakość
- pytanie
- pytania
- szybko
- raczej
- Czytaj
- gotowy
- naprawdę
- odbieranie
- niedawno
- , o którym mowa
- odnosi
- Bez względu
- rejestry
- związane z
- niezawodność
- polegać
- pamiętać
- usunąć
- powtórzony
- obsługi produkcji rolnej, która zastąpiła
- raport
- składnica
- reprezentacja
- wymagany
- wymagania
- Wymaga
- Badania naukowe
- Zasoby
- odpowiedź
- Odpowiedzi
- dalsze
- Efekt
- powrót
- Pokój
- run
- bieganie
- s
- Bezpieczeństwo
- taki sam
- Zapisz
- oszczędność
- scenariusz
- Szukaj
- poszukiwania
- druga
- Sekcja
- bezpieczne
- widzieć
- czujniki
- wyrok
- Sekwencja
- seryjny
- ustawienie
- ustawienie
- kilka
- strzał
- powinien
- pokazane
- podobny
- Prosty
- po prostu
- ponieważ
- pojedynczy
- umiejętności
- mały
- So
- Tworzenie
- rozwiązanie
- kilka
- coś
- Źródło
- Źródła
- wyspecjalizowanym
- specjalnie
- specyficzny
- określony
- dzielić
- Spot
- początek
- rozpoczęty
- Startowy
- Zestawienie sprzedaży
- Rynek
- Ewolucja krok po kroku
- Cel
- Nadal
- sklep
- sznur
- Struktura
- Studenci
- Studiowanie
- taki
- system
- Brać
- Mówić
- zadania
- nauczyciel
- Nauczanie
- nastolatek
- szablon
- terminal
- test
- Testowe uruchomienie
- Testowanie
- generowanie tekstu
- niż
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- Te
- one
- myśleć
- to
- myśl
- Przez
- poprzez
- czas
- do
- razem
- Żetony
- jutro
- także
- wziął
- aktualny
- tematy
- w kierunku
- Pociąg
- próbować
- drugiej
- rodzaj
- typowy
- zazwyczaj
- zaktualizowane
- Nowości
- na
- us
- Stosowanie
- usb
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- zazwyczaj
- wykorzystany
- różnorodny
- zweryfikować
- wersja
- początku.
- przez
- Wirtualny
- W3
- czekać
- chcieć
- była
- Droga..
- sposoby
- we
- Strona internetowa
- DOBRZE
- Co
- Co to jest
- Koło
- jeśli chodzi o komunikację i motywację
- który
- KIM
- dlaczego
- szeroko
- będzie
- okna
- Użytkownicy systemu Windows
- w
- w ciągu
- bez
- Wygrał
- Praca
- pracujący
- rok
- lat
- ty
- młody
- Twój
- zefirnet









