Podczas gdy OpenAI ChatGPT wysysa cały tlen z 24-godzinnego cyklu wiadomości, Google po cichu zaprezentowało nowy model sztucznej inteligencji, który może generować filmy po otrzymaniu wideo, obrazu i tekstu. Nowy edytor wideo Google Dreamix AI przybliża teraz wygenerowane wideo do rzeczywistości.
Według badań opublikowanych na GitHub Dreamix edytuje wideo na podstawie wideo i monitu tekstowego. Wynikowy film zachowuje wierność kolorowi, postawie, rozmiarowi obiektu i pozie kamery, co daje czasowo spójny film. W tej chwili Dreamix nie może generować filmów na podstawie samego monitu, jednak może wykorzystać istniejący materiał i zmodyfikować wideo za pomocą monitów tekstowych.
Google używa modeli dyfuzji wideo dla Dreamix, podejścia, które zostało z powodzeniem zastosowane w większości edycji obrazu wideo, które widzimy w obrazowych AI, takich jak DALL-E2 lub Open Source Stable Diffusion.
Podejście to polega na znacznym zmniejszeniu wejściowego wideo, dodaniu sztucznego szumu, a następnie przetworzeniu go w modelu dyfuzji wideo, który następnie wykorzystuje monit tekstowy do wygenerowania z niego nowego wideo, które zachowuje niektóre właściwości oryginalnego wideo i ponownie renderuje inne zgodnie z do wprowadzania tekstu.
Model rozpowszechniania wideo oferuje obiecującą przyszłość, która może zapoczątkować nową erę pracy z wideo.

Na przykład w poniższym filmie Dreamix zamienia jedzącą małpę (po lewej) w tańczącego niedźwiedzia (po prawej), biorąc pod uwagę podpowiedź „Niedźwiedź tańczy i skacze do wesołej muzyki, poruszając całym ciałem”.
W innym przykładzie poniżej, Dreamix używa pojedynczego zdjęcia jako szablonu (jak w obrazie na wideo), a obiekt jest następnie animowany w filmie za pomocą monitu. Ruchy kamery są również możliwe w nowej scenie lub kolejnym nagraniu poklatkowym.
W innym przykładzie Dreamix zamienia orangutana w kałuży wody (po lewej) w orangutana z pomarańczowymi włosami kąpiącego się w pięknej łazience.
„Podczas gdy modele dyfuzji zostały z powodzeniem zastosowane do edycji obrazu, bardzo niewiele prac zrobiło to w przypadku edycji wideo. Przedstawiamy pierwszą metodę opartą na dyfuzji, która jest w stanie wykonać tekstową edycję ruchu i wyglądu ogólnych filmów”.
Zgodnie z artykułem badawczym Google, Dreamix używa modelu dyfuzji wideo, aby połączyć w czasie wnioskowania informacje czasoprzestrzenne o niskiej rozdzielczości z oryginalnego wideo z nowymi informacjami o wysokiej rozdzielczości, które zostały zsyntetyzowane w celu dopasowania do przewodniego monitu tekstowego.
Google powiedział, że zastosował takie podejście, ponieważ „uzyskanie wysokiej wierności oryginalnego wideo wymaga zachowania niektórych informacji o wysokiej rozdzielczości, dodajemy wstępny etap dostrajania modelu do oryginalnego wideo, znacznie zwiększając wierność”.
Poniżej znajduje się przegląd wideo pokazujący, jak działa Dreamix.
[Osadzone treści]
Jak działają modele rozpowszechniania wideo Dreamix
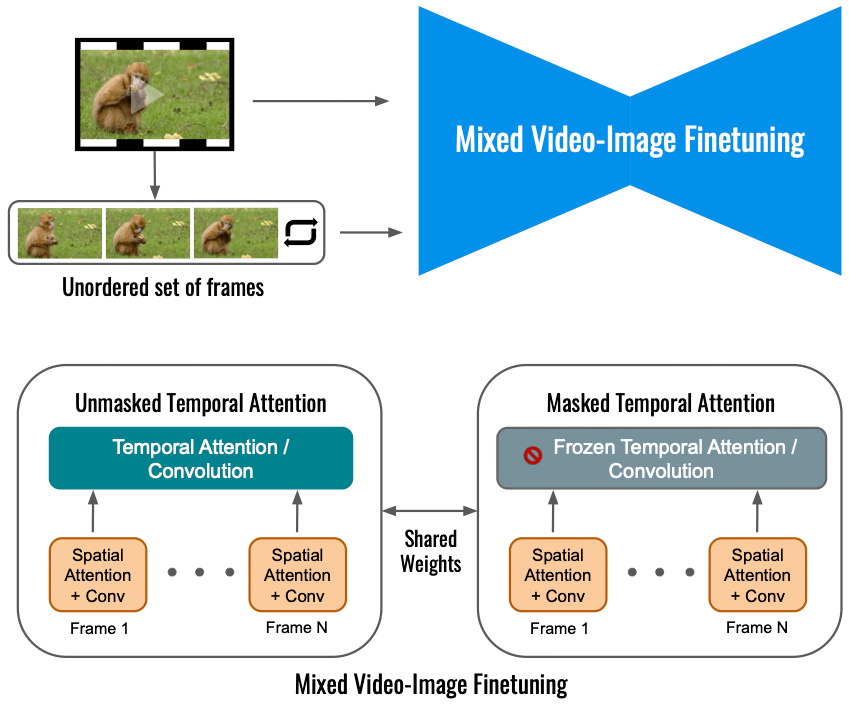
Według Google, precyzyjne dostrojenie modelu rozpowszechniania wideo dla Dreamix na samym wejściu wideo ogranicza zakres zmian ruchu. Zamiast tego używamy celu mieszanego, który oprócz pierwotnego celu (lewy dolny róg) dostraja również nieuporządkowany zestaw klatek. Odbywa się to za pomocą „zamaskowanej uwagi czasowej”, zapobiegając precyzyjnemu dostrojeniu uwagi czasowej i splotu (prawy dolny róg). Pozwala to na dodanie ruchu do statycznego wideo.
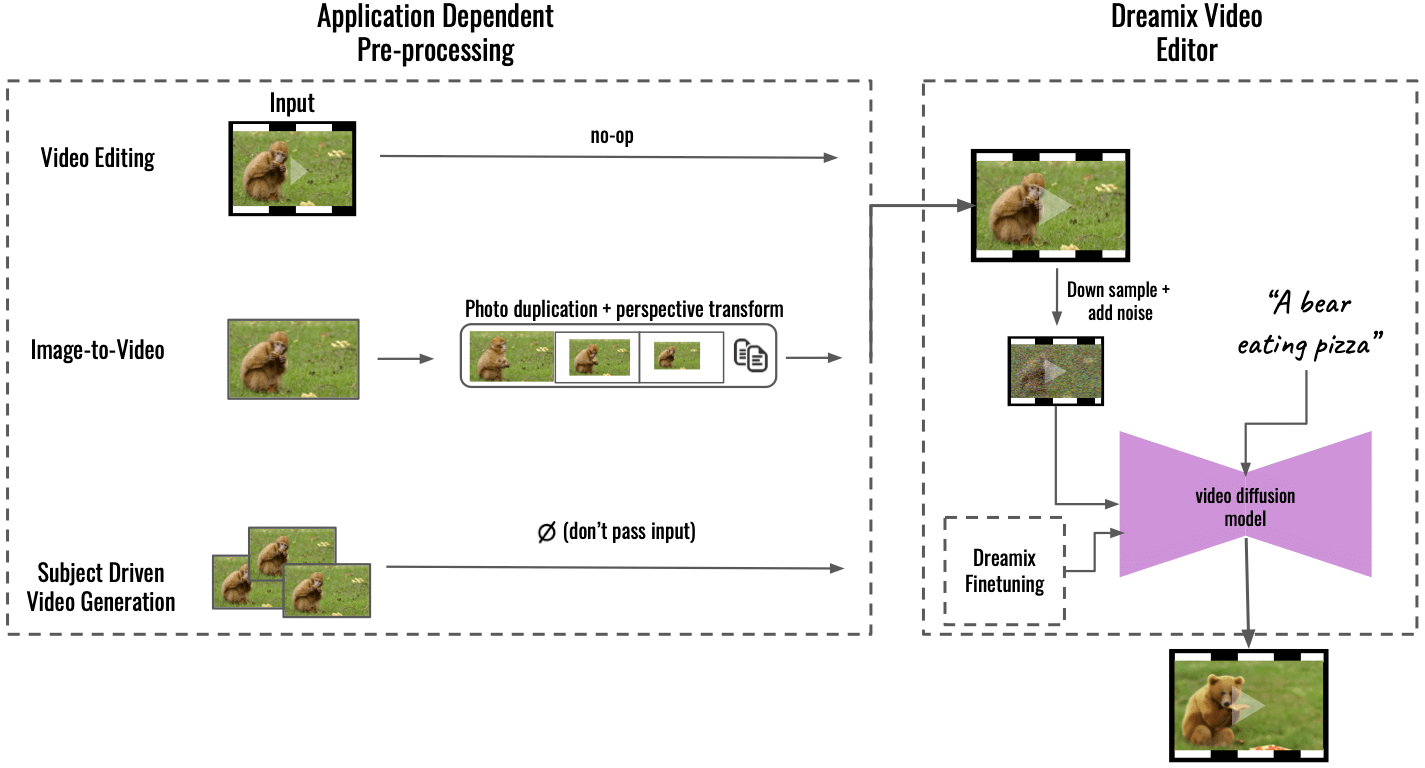
„Nasza metoda obsługuje wiele aplikacji dzięki wstępnemu przetwarzaniu zależnemu od aplikacji (po lewej), konwertując zawartość wejściową na jednolity format wideo. W przypadku przetwarzania obrazu na wideo obraz wejściowy jest powielany i przekształcany przy użyciu transformacji perspektywy, syntetyzując zgrubne wideo z pewnym ruchem kamery. W przypadku generowania wideo opartego na tematach dane wejściowe są pomijane — samo dostrajanie zapewnia wierność. To zgrubne wideo jest następnie edytowane za pomocą naszego ogólnego „Edytora wideo Dreamix” (po prawej): najpierw psujemy wideo, zmniejszając próbkowanie, a następnie dodając szum. Następnie stosujemy dopracowany model dyfuzji wideo kierowany tekstem, który przeskalowuje wideo do ostatecznej rozdzielczości czasoprzestrzennej” – napisał Dream na GitHub.
Artykuł badawczy można przeczytać poniżej.
Google Dreamix- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Zdolny
- Stosownie
- AI
- ai wideo
- Zasilany AI
- Wszystkie kategorie
- pozwala
- sam
- i
- Inne
- aplikacje
- stosowany
- Aplikuj
- podejście
- sztuczny
- Uwaga
- na podstawie
- Niedźwiedź
- piękny
- bo
- jest
- poniżej
- ciało
- pobudzanie
- Dolny
- Przynosi
- aparat fotograficzny
- nie może
- który
- zmiana
- ChatGPT
- bliższy
- kolor
- połączyć
- zgodny
- zawartość
- Tworzenie
- cykl
- Taniec
- Transmitowanie
- marzenie
- redaktor
- osadzone
- Era
- przykład
- Przede wszystkim system został opracowany
- kilka
- wierność
- finał
- i terminów, a
- następnie
- format
- od
- przyszłość
- Ogólne
- Generować
- wygenerowane
- generacja
- gif
- GitHub
- dany
- Włosy
- ciężko
- wysoka rozdzielczość
- W jaki sposób
- Jednak
- HTTPS
- obraz
- zdjęcia
- in
- Informacja
- wkład
- zamiast
- IT
- uruchamia
- Limity
- utrzymuje
- materiał
- max
- metoda
- mieszany
- model
- modele
- modyfikować
- moment
- większość
- ruch
- Ruchy
- przeniesienie
- wielokrotność
- Muzyka
- Nowości
- aktualności
- Hałas
- przedmiot
- cel
- Oferty
- open source
- OpenAI
- Orange
- oryginalny
- Pozostałe
- przegląd
- Tlen
- Papier
- wykonać
- perspektywa
- plato
- Analiza danych Platona
- PlatoDane
- basen
- możliwy
- teraźniejszość
- zapobieganie
- przetwarzanie
- obiecujący
- niska zabudowa
- opublikowany
- spokojnie
- Czytaj
- Rzeczywistość
- nagranie
- redukcja
- Wymaga
- Badania naukowe
- Rozkład
- wynikły
- wspornikowy
- Powiedział
- scena
- zestaw
- znacznie
- pojedynczy
- Rozmiar
- So
- kilka
- stabilny
- STAGE
- kolejny
- Z powodzeniem
- taki
- podpory
- Brać
- szablon
- Połączenia
- czas
- do
- przemiany
- przekształcony
- odsłonięty
- posługiwać się
- przez
- Wideo
- Filmy
- Woda
- który
- pracujący
- działa
- youtube
- zefirnet











