
Zdjęcie od autora | Kreator obrazów Bing
Wózek 2.0 to oparty na instrukcjach open-source model dużego języka (LLM), który został dopracowany na zbiorze danych wygenerowanym przez człowieka. Może być używany zarówno do celów badawczych, jak i komercyjnych.
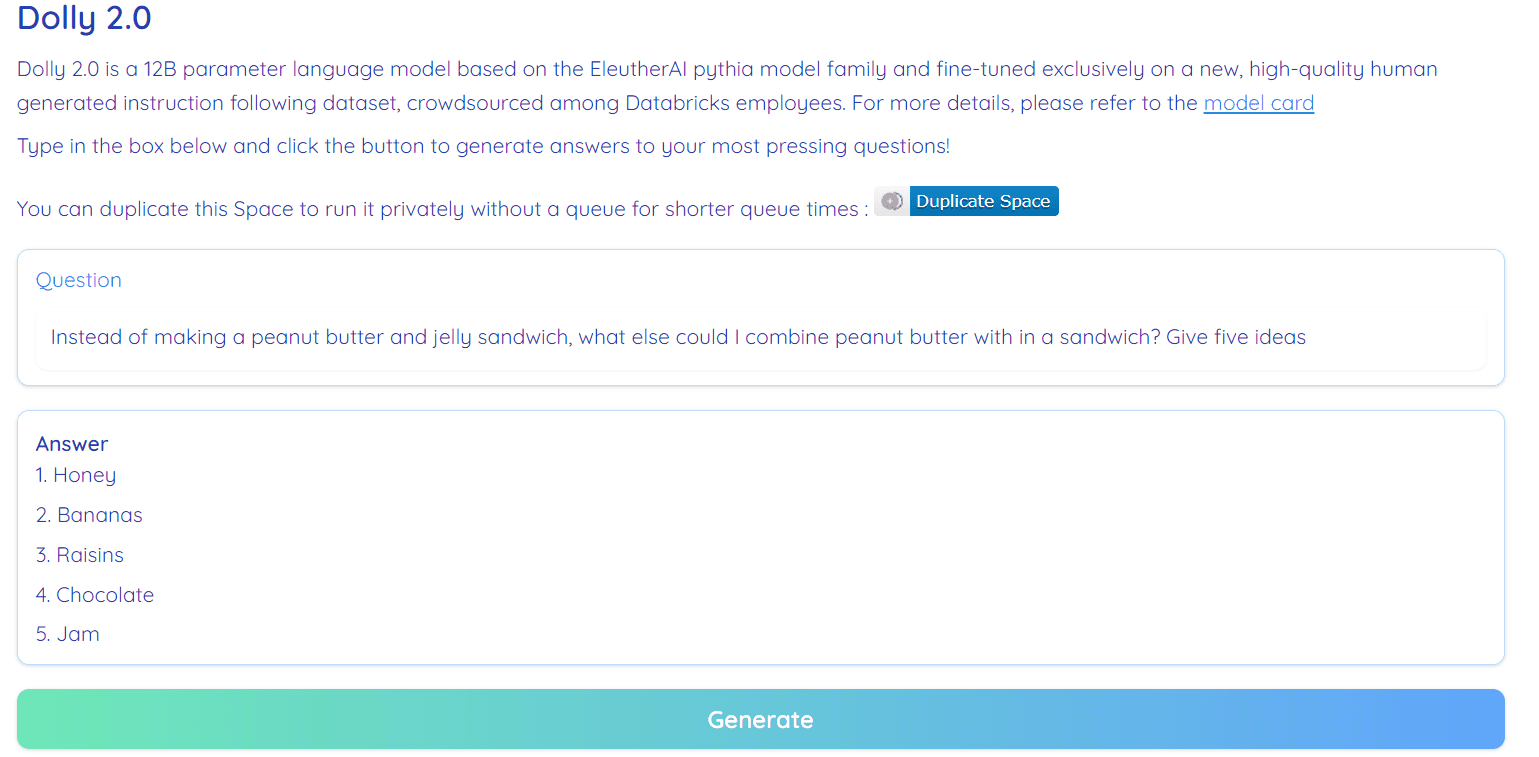
Obraz z Przytulanie twarzy przez RamAnanth1
Wcześniej zespół datakostek wydał Wózek 1.0, LLM, który wykazuje umiejętność podążania za instrukcjami podobnymi do ChatGPT i kosztuje mniej niż 30 USD za szkolenie. Korzystał z zestawu danych zespołu Stanford Alpaca, który był objęty ograniczoną licencją (tylko badania).
Dolly 2.0 rozwiązało ten problem, dostrajając model języka parametrów 12B (pytia) na wysokiej jakości instrukcji wygenerowanej przez człowieka w następującym zbiorze danych, który został oznaczony przez pracownika Datbricks. Zarówno model, jak i zestaw danych są dostępne do użytku komercyjnego.
Dolly 1.0 został przeszkolony na zbiorze danych Stanford Alpaca, który został utworzony przy użyciu OpenAI API. Zestaw danych zawiera dane wyjściowe z ChatGPT i uniemożliwia komukolwiek używanie go do konkurowania z OpenAI. Krótko mówiąc, na podstawie tego zbioru danych nie można zbudować komercyjnego chatbota ani aplikacji językowej.
Większość najnowszych modeli wydanych w ciągu ostatnich kilku tygodni miała te same problemy, takie jak modele Alpaka, Koala, GPT4Wszystkie, Wigoń. Aby się obejść, musimy utworzyć nowe zestawy danych wysokiej jakości, które można wykorzystać do użytku komercyjnego, i to właśnie zrobił zespół Databricks z zestawem danych databricks-dolly-15k.
Nowy zestaw danych zawiera 15,000 XNUMX wysokiej jakości par podpowiedzi/odpowiedzi, które można wykorzystać do projektowania dostrajania instrukcji w dużych modelach językowych. The datakostki-dolly-15 tys zestaw danych pochodzi z Licencja Creative Commons Attribution-ShareAlike 3.0 Unported, dzięki czemu każdy może go używać, modyfikować i tworzyć na nim aplikacje komercyjne.
Jak stworzyli zestaw danych datakostki-dolly-15k?
Badania OpenAI papier stwierdza, że oryginalny model InstructGPT został przeszkolony na 13,000 13 monitów i odpowiedzi. Korzystając z tych informacji, zespół Databricks zaczął nad tym pracować i okazuje się, że wygenerowanie 5,000 tys. pytań i odpowiedzi było trudnym zadaniem. Nie mogą wykorzystywać danych syntetycznych ani danych generatywnych AI i muszą generować oryginalne odpowiedzi na każde pytanie. W tym miejscu postanowili wykorzystać XNUMX pracowników Databricks do tworzenia danych generowanych przez ludzi.
Firma Databricks zorganizowała konkurs, w którym 20 najlepszych etykieciarzy otrzyma duże nagrody. W tym konkursie wzięło udział 5,000 pracowników Databricks, którzy byli bardzo zainteresowani LLM
Dolly-v2-12b nie jest najnowocześniejszym modelem. W niektórych testach porównawczych osiąga gorsze wyniki niż dolly-v1-6b. Może to wynikać ze składu i rozmiaru bazowych zestawów danych dostrajających. Rodzina modeli Dolly jest w trakcie aktywnego rozwoju, więc w przyszłości możesz zobaczyć zaktualizowaną wersję z lepszą wydajnością.
Krótko mówiąc, model dolly-v2-12b działał lepiej niż EleutherAI/gpt-neox-20b i EleutherAI/pythia-6.9b.

Obraz z Uwolnij Dolly
Dolly 2.0 jest w 100% open source. Zawiera kod szkoleniowy, zestaw danych, wagi modeli i potok wnioskowania. Wszystkie komponenty nadają się do użytku komercyjnego. Możesz wypróbować model na Hugging Face Spaces Dolly V2 autorstwa RamAnanth1.
Obraz z Przytulanie Twarzy
Zasobów:
Wersja demonstracyjna Dolly 2.0: Dolly V2 autorstwa RamAnanth1
Abid Ali Awan (@ 1abidaliawan) jest certyfikowanym specjalistą ds. analityków danych, który uwielbia tworzyć modele uczenia maszynowego. Obecnie koncentruje się na tworzeniu treści i pisaniu blogów technicznych na temat technologii uczenia maszynowego i data science. Abid posiada tytuł magistra zarządzania technologią oraz tytuł licencjata inżynierii telekomunikacyjnej. Jego wizją jest zbudowanie produktu AI z wykorzystaniem grafowej sieci neuronowej dla studentów zmagających się z chorobami psychicznymi.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 000
- 1
- 20
- a
- zdolność
- aktywny
- AI
- Wszystkie kategorie
- pozwala
- alternatywny
- an
- i
- odpowiedzi
- ktoś
- api
- Zastosowanie
- SĄ
- na około
- autor
- dostępny
- nagroda
- na podstawie
- BE
- Benchmarki
- Berkeley
- Ulepsz Swój
- Duży
- Bing
- blogi
- obie
- budować
- Budowanie
- by
- CAN
- nie może
- Dyplomowani
- chatbot
- ChatGPT
- kod
- handlowy
- Lud
- rywalizować
- składniki
- zawiera
- zawartość
- Tworzenie treści
- konkurs
- Koszty:
- Stwórz
- stworzony
- tworzenie
- Obecnie
- dane
- nauka danych
- naukowiec danych
- Pamięci danych
- zbiory danych
- postanowiła
- Stopień
- Demo
- Wnętrze
- oprogramowania
- ZROBIŁ
- trudny
- Laleczka
- Pracownik
- pracowników
- Inżynieria
- ewaluację
- Każdy
- eksponaty
- Twarz
- członków Twojej rodziny
- kilka
- skupienie
- następujący
- W razie zamówieenia projektu
- od
- przyszłość
- Generować
- generujący
- generatywny
- otrzymać
- wykres
- Wykres sieci neuronowej
- Have
- he
- wysokiej jakości
- posiada
- HTML
- HTTPS
- choroba
- obraz
- in
- Informacja
- zainteresowany
- problem
- problemy
- IT
- jpg
- Knuggety
- język
- duży
- Nazwisko
- firmy
- nauka
- Licencja
- lubić
- maszyna
- uczenie maszynowe
- i konserwacjami
- mistrz
- psychika
- Choroba umysłowa
- może
- model
- modele
- modyfikować
- Potrzebować
- sieć
- Nerwowy
- sieci neuronowe
- Nowości
- of
- on
- tylko
- koncepcja
- open source
- OpenAI
- or
- oryginalny
- wydajność
- par
- parametr
- udział
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- rurociąg
- plato
- Analiza danych Platona
- PlatoDane
- Produkt
- profesjonalny
- cele
- pytanie
- pytania
- wydany
- Badania naukowe
- zdecydowany
- ograniczony
- s
- taki sam
- nauka
- Naukowiec
- zestaw
- Short
- Rozmiar
- So
- kilka
- Źródło
- Typ przestrzeni
- obowiązuje
- Stanford
- rozpoczęty
- state-of-the-art
- Zjednoczone
- Walka
- Studenci
- odpowiedni
- syntetyczny
- dane syntetyczne
- Zadanie
- zespół
- Techniczny
- Technologies
- Technologia
- telekomunikacja
- niż
- że
- Połączenia
- Przyszłość
- one
- to
- do
- Top
- Pociąg
- przeszkolony
- Trening
- dla
- zasadniczy
- zaktualizowane
- posługiwać się
- używany
- za pomocą
- wersja
- wizja
- była
- we
- tygodni
- były
- Co
- który
- KIM
- w
- Praca
- by
- pisanie
- ty
- zefirnet










