Amazonka Przesunięcie ku czerwieni to w pełni zarządzana hurtownia danych w chmurze o wielkości petabajtów, która jest używana przez dziesiątki tysięcy klientów do codziennego przetwarzania eksabajtów danych w celu obsługi obciążeń analitycznych. Możesz ustrukturyzować swoje dane, mierzyć procesy biznesowe i szybko uzyskiwać cenne spostrzeżenia, używając modelu wymiarowego. Amazon Redshift zapewnia wbudowane funkcje przyspieszające proces modelowania, orkiestracji i raportowania z modelu wielowymiarowego.
W tym poście omawiamy, jak zaimplementować model wymiarowy, a konkretnie model Metodologia Kimballa. Omawiamy wymiary i fakty dotyczące wdrażania w Amazon Redshift. Pokazujemy, jak przeprowadzić ekstrakcję, transformację i ładowanie (ELT), proces integracji skoncentrowany na pobieraniu nieprzetworzonych danych z jeziora danych do warstwy pomostowej w celu wykonania modelowania. Ogólnie rzecz biorąc, post da ci jasne zrozumienie, jak korzystać z modelowania wymiarowego w Amazon Redshift.
Omówienie rozwiązania
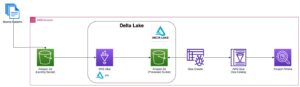
Poniższy schemat ilustruje architekturę rozwiązania.

W poniższych sekcjach najpierw omówimy i zademonstrujemy kluczowe aspekty modelu wymiarowego. Następnie tworzymy hurtownię danych za pomocą Amazon Redshift z wymiarowym modelem danych, w tym tabelami wymiarów i faktów. Dane są ładowane i umieszczane przy użyciu KOPIA polecenie, dane w wymiarach są ładowane za pomocą MERGE stwierdzenie, a fakty zostaną połączone z wymiarami, z których pochodzą spostrzeżenia. Planujemy ładowanie wymiarów i faktów za pomocą Edytor zapytań Amazon Redshift V2. Na koniec używamy Amazon QuickSight aby uzyskać wgląd w modelowane dane w postaci pulpitu nawigacyjnego QuickSight.
W przypadku tego rozwiązania używamy przykładowego zestawu danych (znormalizowanego) dostarczonego przez Amazon Redshift do sprzedaży biletów na wydarzenia. W tym poście zawęziliśmy zestaw danych dla uproszczenia i celów demonstracyjnych. Poniższe tabele przedstawiają przykładowe dane dotyczące sprzedaży biletów i miejsc.


Według Metodologia modelowania wymiarowego Kimballa, istnieją cztery kluczowe etapy projektowania modelu wymiarowego:
- Zidentyfikuj proces biznesowy.
- Zadeklaruj ziarno swoich danych.
- Zidentyfikuj i zaimplementuj wymiary.
- Zidentyfikuj i zastosuj fakty.
Dodatkowo do celów demonstracyjnych dodajemy piąty krok, czyli raportowanie i analizowanie zdarzeń biznesowych.
Wymagania wstępne
W tej instrukcji należy spełnić następujące wymagania wstępne:
Zidentyfikuj proces biznesowy
Mówiąc prościej, identyfikacja procesu biznesowego to identyfikacja mierzalnego zdarzenia, które generuje dane w organizacji. Zwykle firmy mają jakiś operacyjny system źródłowy, który generuje ich dane w surowym formacie. Jest to dobry punkt wyjścia do zidentyfikowania różnych źródeł dla procesu biznesowego.
Proces biznesowy jest następnie utrwalany jako plik Data Mart w postaci wymiarów i faktów. Patrząc na nasz przykładowy zestaw danych wspomniany wcześniej, możemy wyraźnie zobaczyć, że proces biznesowy to sprzedaż dokonywana dla danego wydarzenia.
Częstym błędem jest wykorzystywanie działów firmy jako procesu biznesowego. Dane (proces biznesowy) muszą być zintegrowane w różnych działach, w takim przypadku dział marketingu może uzyskać dostęp do danych sprzedaży. Identyfikacja prawidłowego procesu biznesowego ma kluczowe znaczenie — błędne wykonanie tego kroku może mieć wpływ na całą hurtownię danych (może to spowodować zduplikowanie ziarna i nieprawidłowe metryki w raportach końcowych).
Zadeklaruj ziarno swoich danych
Deklarowanie ziarna to czynność polegająca na unikatowym identyfikowaniu rekordu w źródle danych. Ziarno jest używane w tabeli faktów do dokładnego pomiaru danych i umożliwia dalsze zestawienie. W naszym przykładzie może to być pozycja w procesie biznesowym sprzedaży.
W naszym przypadku sprzedaż można jednoznacznie zidentyfikować, patrząc na czas transakcji, w której miała miejsce sprzedaż; będzie to poziom najbardziej atomowy.

Zidentyfikuj i zaimplementuj wymiary
Tabela wymiarów opisuje tabelę faktów i jej atrybuty. Podczas identyfikowania opisowego kontekstu procesu biznesowego zapisujesz tekst w osobnej tabeli, pamiętając o ziarnistości tabeli faktów. Podczas łączenia tabeli wymiarów z tabelą faktów z tabelą faktów powinien być powiązany tylko jeden wiersz. W naszym przykładzie używamy następującej tabeli, aby podzielić ją na tabelę wymiarów; pola te opisują fakty, które będziemy mierzyć.
Podczas projektowania struktury modelu wymiarowego (schematu) można albo utworzyć plik gwiazda or płatek śniegu schemat. Struktura powinna być ściśle powiązana z procesem biznesowym; dlatego schemat gwiazdy najlepiej pasuje do naszego przykładu. Poniższy rysunek przedstawia nasz Diagram relacji encji (ERD).

W poniższych sekcjach szczegółowo opisujemy kroki wdrażania wymiarów.
Przygotuj dane źródłowe
Zanim będziemy mogli utworzyć i załadować tabelę wymiarów, potrzebujemy danych źródłowych. Dlatego umieszczamy dane źródłowe w tabeli przejściowej lub tymczasowej. Jest to często określane jako warstwa inscenizacyjna, która jest nieprzetworzoną kopią danych źródłowych. Aby to zrobić w Amazon Redshift, używamy polecenie KOPIUJ aby załadować dane z publicznego zasobnika S3 modelowania wymiarowego w amazonce z przesunięciem ku czerwieni znajdującego się na us-east-1 Region. Zauważ, że polecenie COPY używa pliku AWS Zarządzanie tożsamością i dostępem (IAM) rola z dostęp do Amazona S3. Rola musi być związany z klastrem. Wykonaj następujące kroki, aby przygotować dane źródłowe:
- utworzyć
venuetabela źródłowa:
- Załaduj dane miejsca:
- utworzyć
salestabela źródłowa:
- Załaduj dane źródła sprzedaży:
- utworzyć
calendarstół:
- Załaduj dane kalendarza:
Utwórz tabelę wymiarów
Projektowanie tabeli wymiarów może zależeć od wymagań biznesowych — na przykład czy chcesz śledzić zmiany danych w czasie? Tam są siedem różnych typów wymiarów. Dla naszego przykładu używamy wpisz 1 ponieważ nie musimy śledzić historycznych zmian. Aby uzyskać więcej informacji na temat typu 2, patrz Uprość ładowanie danych do powoli zmieniających się wymiarów typu 2 w Amazon Redshift. Tabela wymiarów zostanie zdenormalizowana za pomocą klucza podstawowego, klucza zastępczego i kilku dodanych pól wskazujących zmiany w tabeli. Zobacz następujący kod:
Kilka uwag na temat tworzenia tabeli wymiarów:
- Nazwy pól są przekształcane w nazwy przyjazne dla biznesu
- Naszym podstawowym kluczem jest
VenueID, którego używamy do jednoznacznej identyfikacji miejsca, w którym miała miejsce sprzedaż - Zostaną dodane dwa dodatkowe wiersze wskazujące, kiedy rekord został wstawiony i zaktualizowany (w celu śledzenia zmian)
- Używamy Styl dystrybucji AUTO powierzyć Amazonowi Redshift odpowiedzialność za wybór i dostosowanie stylu dystrybucji
Innym ważnym czynnikiem, który należy wziąć pod uwagę w modelowaniu wymiarowym, jest użycie klucze zastępcze. Klucze zastępcze to sztuczne klucze używane w modelowaniu wymiarowym do jednoznacznej identyfikacji każdego rekordu w tabeli wymiarów. Zazwyczaj są one generowane jako sekwencyjne liczby całkowite i nie mają żadnego znaczenia w domenie biznesowej. Oferują one kilka korzyści, takich jak zapewnienie wyjątkowości i poprawa wydajności połączeń, ponieważ są zazwyczaj mniejsze niż klucze naturalne i jako klucze zastępcze nie zmieniają się w czasie. To pozwala nam być konsekwentnym i łatwiej łączyć fakty i wymiary.
W Amazon Redshift klucze zastępcze są zwykle tworzone przy użyciu słowa kluczowego IDENTITY. Na przykład poprzednia instrukcja CREATE tworzy tabelę wymiarów z a VenueSkey Klucz zastępczy. The VenueSkey kolumna jest automatycznie wypełniana unikatowymi wartościami w miarę dodawania nowych wierszy do tabeli. Tej kolumny można następnie użyć do przyłączenia tabeli miejsc do FactSaleTransactions tabela.
Kilka wskazówek dotyczących projektowania kluczy zastępczych:
- Użyj małego typu danych o stałej szerokości dla klucza zastępczego. Poprawi to wydajność i zmniejszy przestrzeń dyskową.
- Użyj słowa kluczowego IDENTITY lub wygeneruj klucz zastępczy, używając wartości sekwencyjnej lub identyfikatora GUID. Dzięki temu klucz zastępczy będzie unikalny i nie będzie można go zmienić.
Załaduj tabelę dim za pomocą MERGE
Istnieje wiele sposobów ładowania tabeli dim. Należy wziąć pod uwagę pewne czynniki — na przykład wydajność, ilość danych i być może czasy ładowania umów SLA. z MERGE wykonujemy upsert bez konieczności określania wielu poleceń wstawiania i aktualizowania. Możesz ustawić MERGE oświadczenie w A procedura składowana aby wypełnić dane. Następnie zaplanujesz programowe uruchamianie procedury składowanej za pośrednictwem edytora zapytań, co zademonstrujemy w dalszej części wpisu. Poniższy kod tworzy procedurę składowaną o nazwie SalesMart.DimVenueLoad:
Kilka uwag na temat ładowania wymiarów:
- Gdy rekord jest wstawiany po raz pierwszy, wstawiona data i zaktualizowana data zostaną wypełnione. W przypadku zmiany jakichkolwiek wartości dane są aktualizowane, a zaktualizowana data odzwierciedla datę zmiany. Wstawiona data pozostaje.
- Ponieważ dane będą używane przez użytkowników biznesowych, musimy zastąpić wartości NULL, jeśli takie istnieją, bardziej odpowiednimi wartościami biznesowymi.
Zidentyfikuj i zastosuj fakty
Teraz, gdy zadeklarowaliśmy, że nasze zboże jest wydarzeniem sprzedaży, która miała miejsce w określonym czasie, nasza tabela faktów będzie przechowywać fakty numeryczne dla naszego procesu biznesowego.
Zidentyfikowaliśmy następujące fakty liczbowe do zmierzenia:
- Liczba sprzedanych biletów na sprzedaż
- Prowizja od sprzedaży
Wdrażanie Faktu
Tam są trzy rodzaje tabel faktów (tabela faktów transakcji, tabela faktów migawek okresowych i tabela faktów kumulujących się migawek). Każdy z nich przedstawia inny pogląd na proces biznesowy. W naszym przykładzie używamy tabeli faktów transakcji. Wykonaj następujące kroki:
- Utwórz tabelę faktów
Dodawana jest wstawiona data z wartością domyślną, wskazująca, czy i kiedy rekord został załadowany. Możesz użyć tego podczas ponownego ładowania tabeli faktów, aby usunąć już załadowane dane, aby uniknąć duplikatów.
Ładowanie tabeli faktów składa się z prostej instrukcji wstawiania łączącej powiązane wymiary. Dołączamy od godz DimVenue tabela, która została utworzona, która opisuje nasze fakty. To najlepsza praktyka, ale opcjonalna data kalendarzowa wymiary, które umożliwiają użytkownikowi końcowemu poruszanie się po tabeli faktów. Dane mogą być ładowane, gdy pojawia się nowa sprzedaż lub codziennie; w tym miejscu przydaje się wstawiona data lub data załadunku.
Ładujemy tabelę faktów za pomocą procedury składowanej i używamy parametru daty.
- Utwórz procedurę składowaną za pomocą następującego kodu. Aby zachować taką samą integralność danych, jaką zastosowaliśmy przy ładowaniu wymiarów, zastępujemy wartości NULL, jeśli takie istnieją, bardziej odpowiednimi wartościami biznesowymi:
- Załaduj dane, wywołując procedurę za pomocą następującego polecenia:
Zaplanuj ładowanie danych
Możemy teraz zautomatyzować proces modelowania, planując procedury składowane w Amazon Redshift Query Editor V2. Wykonaj następujące kroki:
- Najpierw wywołujemy ładowanie wymiarów, a po pomyślnym uruchomieniu ładowania wymiarów rozpoczyna się ładowanie faktów:
Jeśli ładowanie wymiarów nie powiedzie się, ładowanie faktów nie zostanie uruchomione. Zapewnia to spójność danych, ponieważ nie chcemy ładować tabeli faktów z nieaktualnymi wymiarami.
- Aby zaplanować ładowanie, wybierz Plan w edytorze zapytań V2.

- Zaplanowaliśmy uruchamianie zapytania codziennie o 5:00.
- Opcjonalnie możesz dodać powiadomienia o błędach, włączając Usługa prostego powiadomienia Amazon (Amazon SNS) powiadomienia.

Raportuj i analizuj dane w Amazon Quicksight
QuickSight to usługa analizy biznesowej, która ułatwia dostarczanie szczegółowych informacji. Jako w pełni zarządzana usługa, QuickSight umożliwia łatwe tworzenie i publikowanie interaktywnych pulpitów nawigacyjnych, do których można uzyskać dostęp z dowolnego urządzenia i osadzać je w aplikacjach, portalach i witrynach internetowych.
Wykorzystujemy naszą hurtownię danych do wizualnej prezentacji faktów w postaci dashboardu. Aby rozpocząć i skonfigurować QuickSight, patrz Tworzenie zestawu danych przy użyciu bazy danych, która nie jest wykrywana automatycznie.
Po utworzeniu źródła danych w QuickSight łączymy modelowane dane (data mart) w oparciu o nasz klucz zastępczy skey. Używamy tego zestawu danych do wizualizacji składnicy danych.

Nasz końcowy pulpit nawigacyjny będzie zawierał spostrzeżenia z hurtowni danych i odpowiadał na krytyczne pytania biznesowe, takie jak łączna prowizja na miejsce i daty z najwyższą sprzedażą. Poniższy zrzut ekranu przedstawia produkt końcowy składnicy danych.

Sprzątać
Aby uniknąć naliczania przyszłych opłat, usuń wszystkie zasoby utworzone w ramach tego wpisu.
Wnioski
Z powodzeniem wdrożyliśmy hurtownię danych za pomocą naszego DimVenue, DimCalendar, FactSaleTransactions stoły. Nasz magazyn nie jest kompletny; ponieważ możemy rozszerzyć hurtownię danych o więcej faktów i wdrożyć więcej hurtowni danych, a wraz z upływem czasu rosną procesy biznesowe i wymagania, tak samo będzie rosła hurtownia danych. W tym poście przedstawiliśmy kompleksowe spojrzenie na zrozumienie i wdrożenie modelowania wymiarowego w Amazon Redshift.
Zacznij od swojego Amazonka Przesunięcie ku czerwieni model wymiarowy dzisiaj.
O autorach
 Bernarda Verstera jest doświadczonym inżynierem chmury z wieloletnim doświadczeniem w tworzeniu skalowalnych i wydajnych modeli danych, definiowaniu strategii integracji danych oraz zapewnianiu nadzoru i bezpieczeństwa danych. Pasjonuje go wykorzystywanie danych do uzyskiwania wglądu, przy jednoczesnym dostosowaniu do wymagań i celów biznesowych.
Bernarda Verstera jest doświadczonym inżynierem chmury z wieloletnim doświadczeniem w tworzeniu skalowalnych i wydajnych modeli danych, definiowaniu strategii integracji danych oraz zapewnianiu nadzoru i bezpieczeństwa danych. Pasjonuje go wykorzystywanie danych do uzyskiwania wglądu, przy jednoczesnym dostosowaniu do wymagań i celów biznesowych.
 Abhiszek Pan jest specjalistą WWSO SA-Analytics pracującym z klientami AWS India z sektora publicznego. Współpracuje z klientami w celu zdefiniowania strategii opartej na danych, prowadzenia szczegółowych sesji dotyczących analitycznych przypadków użycia oraz projektowania skalowalnych i wydajnych aplikacji analitycznych. Ma 12 lat doświadczenia i jest pasjonatem baz danych, analityki i AI/ML. Jest zapalonym podróżnikiem i próbuje uchwycić świat przez obiektyw aparatu.
Abhiszek Pan jest specjalistą WWSO SA-Analytics pracującym z klientami AWS India z sektora publicznego. Współpracuje z klientami w celu zdefiniowania strategii opartej na danych, prowadzenia szczegółowych sesji dotyczących analitycznych przypadków użycia oraz projektowania skalowalnych i wydajnych aplikacji analitycznych. Ma 12 lat doświadczenia i jest pasjonatem baz danych, analityki i AI/ML. Jest zapalonym podróżnikiem i próbuje uchwycić świat przez obiektyw aparatu.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- O nas
- przyśpieszyć
- dostęp
- dostęp
- dokładnie
- w poprzek
- działać
- Dodaj
- w dodatku
- Dodatkowy
- Po
- AI / ML
- wyrównać
- justowanie
- dopuszczać
- pozwala
- już
- am
- Amazonka
- Amazon Web Services
- an
- analiza
- Analityczny
- analityka
- w czasie rzeczywistym sprawiają,
- i
- odpowiedź
- każdy
- aplikacje
- stosowany
- właściwy
- architektura
- SĄ
- sztuczny
- AS
- aspekty
- powiązany
- At
- atrybuty
- samochód
- zautomatyzować
- automatycznie
- uniknąć
- AWS
- b
- na podstawie
- BE
- bo
- rozpocząć
- Korzyści
- BEST
- wbudowany
- biznes
- business intelligence
- Proces biznesowy
- procesów biznesowych
- ale
- by
- Kalendarz
- wezwanie
- nazywa
- powołanie
- aparat fotograficzny
- CAN
- zdobyć
- walizka
- Etui
- Spowodować
- pewien
- zmiana
- zmieniony
- Zmiany
- wymiana pieniędzy
- charakter
- Opłaty
- Dodaj
- jasny
- wyraźnie
- dokładnie
- Chmura
- kod
- Kolumna
- byliśmy spójni, od początku
- prowizja
- wspólny
- Firmy
- sukcesy firma
- kompletny
- Rozważać
- zgodny
- składa się
- kontekst
- skorygowania
- mógłby
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- krytyczny
- Klientów
- codziennie
- tablica rozdzielcza
- Deski rozdzielcze
- dane
- integracja danych
- Jezioro danych
- hurtownia danych
- sterowane danymi
- Strategia oparta na danych
- Baza danych
- Bazy danych
- Data
- Daty
- data i godzina
- dzień
- głęboko
- głębokie nurkowanie
- Domyślnie
- definiowanie
- dostarczyć
- wykazać
- Działy
- Pochodny
- opisać
- Wnętrze
- projektowanie
- detal
- urządzenie
- różne
- Wymiary
- Wymiary
- dyskutować
- odrębny
- 分配
- do
- domena
- zrobić
- nie
- na dół
- napęd
- duplikaty
- każdy
- Wcześniej
- z łatwością
- łatwo
- redaktor
- wydajny
- bądź
- osadzone
- umożliwiać
- umożliwiając
- zakończenia
- koniec końców
- zaangażowany
- inżynier
- zapewnić
- zapewnia
- zapewnienie
- Cały
- jednostka
- Eter (ETH)
- wydarzenie
- wydarzenia
- Każdy
- codziennie
- przykład
- przykłady
- Rozszerzać
- doświadczenie
- doświadczony
- Ekspozycja
- wyciąg
- fakt
- czynnik
- Czynniki
- fakty
- nie
- Brak
- Korzyści
- kilka
- pole
- Łąka
- piąty
- Postać
- filtrować
- finał
- i terminów, a
- pierwszy raz
- dopasować
- koncentruje
- następujący
- W razie zamówieenia projektu
- Nasz formularz
- format
- cztery
- od
- w pełni
- dalej
- przyszłość
- Wzrost
- Generować
- wygenerowane
- generuje
- otrzymać
- miejsce
- Dać
- dany
- dobry
- zarządzanie
- Rosnąć
- poręczny
- Have
- he
- Najwyższa
- jego
- historyczny
- Wakacje
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- IAM
- zidentyfikowane
- zidentyfikować
- identyfikacja
- tożsamość
- if
- ilustruje
- Rezultat
- wdrożenia
- realizowane
- wykonawczych
- ważny
- podnieść
- poprawy
- in
- Włącznie z
- Indie
- wskazać
- wskazując,
- Informacje
- spostrzeżenia
- zintegrowany
- integracja
- integralność
- Inteligencja
- interaktywne
- najnowszych
- IT
- JEGO
- przystąpić
- Dołączył
- łączący
- Łączy
- jpg
- Trzymać
- konserwacja
- Klawisz
- Klawisze
- jezioro
- język
- później
- firmy
- warstwa
- lewo
- Obiektyw
- pozwala
- poziom
- Linia
- załadować
- załadunek
- masa
- usytuowany
- poszukuje
- zrobiony
- WYKONUJE
- zarządzane
- Marketing
- dopasowane
- znaczenie
- zmierzyć
- wzmiankowany
- Łączyć
- Metryka
- nic
- błąd
- model
- modelowanie
- modelowanie
- modele
- Miesiąc
- jeszcze
- większość
- wielokrotność
- Nazwy
- Naturalny
- Nawigacja
- Potrzebować
- potrzeba
- wymagania
- Nowości
- Uwagi
- powiadomienie
- Powiadomienia
- już dziś
- liczny
- Cele
- of
- oferta
- często
- on
- tylko
- operacyjny
- or
- organizacja
- ludzkiej,
- koniec
- ogólny
- parametr
- część
- namiętny
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- może
- periodycznie
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zaludniony
- Post
- power
- praktyka
- warunki wstępne
- teraźniejszość
- pierwotny
- procedura
- procedury
- wygląda tak
- procesów
- Produkt
- zapewniać
- pod warunkiem,
- zapewnia
- publiczny
- publikować
- cele
- pytania
- szybko
- podnieść
- Surowy
- surowe dane
- rekord
- dokumentacja
- zmniejszyć
- , o którym mowa
- odzwierciedla
- region
- związek
- szczątki
- usunąć
- obsługi produkcji rolnej, która zastąpiła
- raport
- Raportowanie
- Raporty
- wymagania
- Zasoby
- odpowiedzialność
- Rola
- Rolka
- RZĄD
- run
- działa
- sprzedaż
- sole
- taki sam
- Przykładowy zbiór danych
- skalowalny
- rozkład
- szeregowanie
- działy
- sektor
- bezpieczeństwo
- widzieć
- oddzielny
- służy
- usługa
- Usługi
- Sesje
- zestaw
- kilka
- powinien
- pokazać
- Targi
- Prosty
- prostota
- pojedynczy
- Powoli
- mały
- mniejszy
- Migawka
- So
- sprzedany
- rozwiązanie
- kilka
- Źródło
- Źródła
- Typ przestrzeni
- specjalista
- specyficzny
- swoiście
- STAGE
- inscenizacja
- Gwiazda
- rozpoczęty
- Startowy
- Zestawienie sprzedaży
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- przechowywany
- strategie
- Strategia
- Struktura
- udany
- Z powodzeniem
- taki
- system
- stół
- tymczasowy
- kilkadziesiąt
- REGULAMIN
- niż
- że
- Połączenia
- Źródło
- świat
- ich
- następnie
- Tam.
- w związku z tym
- Te
- one
- to
- tysiące
- Przez
- bilet
- sprzedaż biletów
- bilety
- czas
- czasy
- znak czasu
- wskazówki
- do
- już dziś
- razem
- wziął
- Kwota produktów:
- śledzić
- transakcja
- Przekształcać
- przekształcony
- podróżnik
- rodzaj
- typy
- zazwyczaj
- zrozumienie
- wyjątkowy
- wyjątkowo
- wyjątkowość
- nieznany
- Aktualizacja
- zaktualizowane
- us
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- Użytkownicy
- zastosowania
- za pomocą
- zazwyczaj
- Cenny
- wartość
- Wartości
- różnorodny
- Miejsce
- miejsc
- przez
- Zobacz i wysłuchaj
- Tom
- solucja
- chcieć
- Magazyn
- była
- sposoby
- we
- sieć
- usługi internetowe
- strony internetowe
- tydzień
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- będzie
- w
- w ciągu
- bez
- pracujący
- świat
- Źle
- rok
- lat
- ty
- Twój
- zefirnet