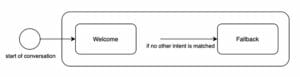
Rysunek 1: Reprezentacja przepływu Text2SQL
Ponieważ nasz świat staje się coraz bardziej globalny i dynamiczny, firmy w coraz większym stopniu polegają na danych przy podejmowaniu świadomych, obiektywnych i terminowych decyzji. Jednak obecnie uwolnienie pełnego potencjału danych organizacyjnych jest często przywilejem garstki naukowców i analityków danych. Większość pracowników nie opanowuje konwencjonalnego zestawu narzędzi do nauki o danych (SQL, Python, R itp.). Aby uzyskać dostęp do pożądanych danych, przechodzą przez dodatkową warstwę, w której analitycy lub zespoły BI „tłumaczą” prozę pytań biznesowych na język danych. Potencjał tarć i nieefektywności na tej drodze jest wysoki — na przykład dane mogą być dostarczane z opóźnieniami lub nawet wtedy, gdy pytanie stało się już nieaktualne. Informacje mogą zostać utracone po drodze, gdy wymagania nie zostaną dokładnie przełożone na zapytania analityczne. Poza tym generowanie wysokiej jakości spostrzeżeń wymaga podejścia iteracyjnego, które jest odradzane przy każdym kolejnym kroku w pętli. Z drugiej strony te doraźne interakcje powodują zakłócenia dla kosztownych talentów zajmujących się danymi i odwracają ich uwagę od bardziej strategicznej pracy z danymi, jak opisano w tych „wyznaniach” analityka danych:
Kiedy pracowałem w Square, a zespół był mniejszy, mieliśmy przerażającą rotację „analityków na wezwanie”. Była to ścisła rotacja co tydzień, a gdyby to była Twoja wizyta, wiedziałeś, że w tym tygodniu wykonasz bardzo mało „prawdziwej” pracy i spędzisz większość czasu na odpowiadaniu na doraźne pytania od różnych zespołów produktowych i operacyjnych w firma (nazywaliśmy to małpowaniem SQL). W zespole analitycznym panowała zacięta rywalizacja o stanowiska kierownicze w zespole analitycznym i myślę, że było to w całości wynikiem zwolnienia menedżerów z tej rotacji — żadna nagroda za status nie mogła się równać z marchewką niewykonywania pracy na wezwanie[1].
Rzeczywiście, czy nie byłoby fajnie rozmawiać bezpośrednio ze swoimi danymi, zamiast przechodzić przez wiele rund interakcji z personelem zajmującym się danymi? Wizję tę obejmują interfejsy konwersacyjne, które umożliwiają ludziom interakcję z danymi za pomocą języka, naszego najbardziej intuicyjnego i uniwersalnego kanału komunikacji. Po przeanalizowaniu pytania algorytm koduje je w ustrukturyzowanej postaci logicznej w wybranym języku zapytań, takim jak SQL. W ten sposób użytkownicy nietechniczni mogą czatować ze swoimi danymi i szybko uzyskiwać konkretne, istotne i aktualne informacje, bez konieczności korzystania z usług zespołu BI. W tym artykule rozważymy różne aspekty implementacji Text2SQL i skupimy się na nowoczesnych podejściach z wykorzystaniem modeli dużych języków (LLM), które obecnie osiągają najlepszą wydajność (por. [2]; przegląd alternatywnych podejść poza LLM, czytelnicy są odsyłani do [3]). Artykuł ma strukturę zgodną z następującym „modelem mentalnym” głównych elementów, które należy wziąć pod uwagę podczas planowania i tworzenia funkcji AI:

Zacznijmy od końca i podsumujmy wartość — dlaczego warto wbudować funkcję Text2SQL w swoje dane lub produkt analityczny. Trzy główne korzyści to:
- Użytkownicy biznesowi może uzyskiwać bezpośredni i terminowy dostęp do danych organizacji.
- To przynosi ulgę naukowców i analityków danych od ciężaru doraźnych żądań od użytkowników biznesowych i pozwala im skupić się na zaawansowanych wyzwaniach związanych z danymi.
- To pozwala biznes wykorzystać swoje dane w bardziej płynny i strategiczny sposób, ostatecznie przekształcając je w solidną podstawę do podejmowania decyzji.
Jakie są scenariusze produktów, w których możesz rozważyć Text2SQL? Trzy główne ustawienia to:
- Oferujesz A skalowalne dane/produkt BI i chcą umożliwić większej liczbie użytkowników dostęp do ich danych w sposób nietechniczny, zwiększając w ten sposób zarówno wykorzystanie, jak i bazę użytkowników. Jako przykład, ServiceNow ma zintegrowane zapytania dotyczące danych w ramach większej oferty konwersacyjnej, Atlan ostatnio ogłosił eksplorację danych w języku naturalnym.
- Chcesz zbudować coś w przestrzeni danych/AI, aby zdemokratyzować dostęp do danych w firmach, w takim przypadku możesz potencjalnie rozważyć MVP z Text2SQL w rdzeniu. Dostawcy lubią AI2SQL i Text2sql.ai już robią wejście w tę przestrzeń.
- Pracujesz nad niestandardowy system BI i chcą zmaksymalizować i zdemokratyzować jego wykorzystanie w poszczególnych firmach.
Jak zobaczymy w kolejnych sekcjach, Text2SQL wymaga nietrywialnej konfiguracji z góry. Aby oszacować ROI, weź pod uwagę charakter decyzji, które mają być wspierane, a także dostępne dane. Text2SQL może być absolutną wygraną w dynamicznych środowiskach, w których dane szybko się zmieniają i są aktywnie i często wykorzystywane przy podejmowaniu decyzji, takich jak inwestycje, marketing, produkcja i przemysł energetyczny. W tych środowiskach tradycyjne narzędzia do zarządzania wiedzą są zbyt statyczne, a bardziej płynne sposoby dostępu do danych i informacji pomagają firmom generować przewagę konkurencyjną. Jeśli chodzi o dane, Text2SQL zapewnia największą wartość dzięki bazie danych, która jest:
- Duży i rosnący, dzięki czemu Text2SQL może rozwijać swoją wartość w czasie, gdy coraz więcej danych jest wykorzystywanych.
- Wysokiej jakości, dzięki czemu algorytm Text2SQL nie musi radzić sobie z nadmiernym szumem (niespójnościami, pustymi wartościami itp.) w danych. Ogólnie rzecz biorąc, dane generowane automatycznie przez aplikacje mają wyższą jakość i spójność niż dane tworzone i utrzymywane przez ludzi.
- Semantycznie dojrzały w przeciwieństwie do surowych, aby ludzie mogli wyszukiwać dane w oparciu o główne koncepcje, relacje i metryki, które istnieją w ich modelu mentalnym. Należy zauważyć, że dojrzałość semantyczną można osiągnąć poprzez dodatkowy krok transformacji, który dopasowuje surowe dane do struktury pojęciowej (por. rozdział „Wzbogacanie podpowiedzi o informacje z bazy danych”).
Poniżej zagłębimy się w dane, algorytmy, wrażenia użytkownika, a także odpowiednie niefunkcjonalne wymagania funkcji Text2SQL. Artykuł jest napisany dla menedżerów produktu, projektantów UX oraz tych analityków danych i inżynierów, którzy są na początku swojej przygody z Text2SQL. Dla tych osób jest to nie tylko przewodnik na początek, ale także wspólna podstawa wiedzy do dyskusji na temat interfejsów między produktem, technologią i biznesem, w tym związanych z nimi kompromisów. Jeśli jesteś już bardziej zaawansowany we wdrażaniu, odniesienia na końcu zawierają szereg głębokich nurkowań do zbadania.
Jeśli te dogłębne treści edukacyjne są dla Ciebie przydatne, możesz zapisz się na naszą listę dyskusyjną AI zostać powiadomionym, gdy wydamy nowy materiał.
1. Dane
Każde przedsięwzięcie związane z uczeniem maszynowym zaczyna się od danych, więc zaczniemy od wyjaśnienia struktury danych wejściowych i docelowych, które są używane podczas uczenia i przewidywania. W całym artykule będziemy używać przepływu Text2SQL z rysunku 1 jako naszej działającej reprezentacji i podświetlać aktualnie rozważane komponenty i relacje na żółto.

1.1 Format i struktura danych
Zazwyczaj surowa para wejścia-wyjścia Text2SQL składa się z pytania w języku naturalnym i odpowiedniego zapytania SQL, na przykład:
Question"Podaj imię i nazwisko oraz liczbę obserwujących każdego użytkownika.
Zapytanie SQL:
wybierz nazwę, obserwujących z user_profiles
W przestrzeni danych szkoleniowych odwzorowanie między pytaniami a zapytaniami SQL jest typu wiele do wielu:
- Zapytanie SQL można odwzorować na wiele różnych pytań w języku naturalnym; na przykład powyższa semantyka zapytania może być wyrażona przez: „pokaż mi nazwiska i liczbę obserwujących na użytkownika","ilu obserwujących jest dla każdego użytkownika?”Itp.
- Składnia SQL jest bardzo wszechstronna i prawie każde pytanie można przedstawić w SQL na wiele sposobów. Najprostszym przykładem są różne uporządkowania klauzul WHERE. Z bardziej zaawansowanego punktu widzenia każdy, kto zajmował się optymalizacją zapytań SQL, będzie wiedział, że wiele dróg prowadzi do tego samego wyniku, a semantycznie równoważne zapytania mogą mieć zupełnie inną składnię.
Ręczne zbieranie danych treningowych dla Text2SQL jest szczególnie uciążliwe. Wymaga to nie tylko biegłości w SQL ze strony adnotatora, ale także więcej czasu na przykład niż bardziej ogólne zadania językowe, takie jak analiza tonacji i klasyfikacja tekstu. Aby zapewnić wystarczającą liczbę przykładów szkoleniowych, można zastosować rozszerzenie danych — na przykład LLM można wykorzystać do wygenerowania parafraz dla tego samego pytania. [3] zawiera pełniejszy przegląd technik rozszerzania danych Text2SQL.
1.2 Wzbogacenie podpowiedzi o informacje z bazy danych
Text2SQL to algorytm na styku danych nieustrukturyzowanych i ustrukturyzowanych. Aby uzyskać optymalną wydajność, oba typy danych muszą być obecne podczas uczenia i przewidywania. W szczególności algorytm musi wiedzieć o zapytanej bazie danych i być w stanie sformułować zapytanie w taki sposób, aby można je było wykonać w bazie danych. Ta wiedza może obejmować:
- Kolumny i tabele bazy danych
- Relacje między tabelami (klucze obce)
- Zawartość bazy danych
Istnieją dwie możliwości włączenia wiedzy o bazach danych: z jednej strony dane szkoleniowe można ograniczyć do przykładów napisanych dla konkretnej bazy danych, w którym to przypadku schemat jest uczony bezpośrednio z zapytania SQL i jego odwzorowania na pytanie. To ustawienie pojedynczej bazy danych pozwala zoptymalizować algorytm dla pojedynczej bazy danych i/lub firmy. Jednak zabija to wszelkie ambicje skalowalności, ponieważ model musi być dopracowany dla każdego klienta lub bazy danych. Alternatywnie, w ustawieniach z wieloma bazami danych, schemat bazy danych może być dostarczony jako część danych wejściowych, umożliwiając algorytmowi „uogólnienie” do nowych, niewidocznych schematów baz danych. Chociaż zdecydowanie będziesz musiał zastosować to podejście, jeśli chcesz używać Text2SQL w wielu różnych bazach danych, pamiętaj, że wymaga to znacznego szybkiego wysiłku inżynierskiego. Dla każdej rozsądnej biznesowej bazy danych uwzględnienie pełnej informacji w monicie będzie skrajnie nieefektywne i najprawdopodobniej niemożliwe ze względu na ograniczenia długości monitu. Zatem funkcja odpowiedzialna za szybkie sformułowanie powinna być na tyle inteligentna, aby wybrać podzbiór informacji z bazy danych, który jest najbardziej „użyteczny” dla danego pytania i zrobić to dla potencjalnie niewidocznych baz danych.
Wreszcie struktura bazy danych odgrywa kluczową rolę. W sytuacjach, w których masz wystarczającą kontrolę nad bazą danych, możesz ułatwić życie modelowi, pozwalając mu uczyć się z intuicyjnej struktury. Ogólna zasada jest taka, że im bardziej baza danych odzwierciedla sposób, w jaki użytkownicy biznesowi mówią o firmie, tym lepiej i szybciej model może się z niej uczyć. W związku z tym należy rozważyć zastosowanie dodatkowych przekształceń danych, takich jak złożenie znormalizowanych lub w inny sposób rozproszonych danych w szerokie tabele lub przechowalnię danych, nazewnictwo tabel i kolumn w wyraźny i jednoznaczny sposób itp. Cała wiedza biznesowa, którą można zakodować z góry, zmniejszy ciężar probabilistycznego uczenia się na modelu i pomóc osiągnąć lepsze wyniki.
2. algorytm

Text2SQL jest typem parsowanie semantyczne — odwzorowanie tekstów na reprezentacje logiczne. Algorytm musi więc nie tylko „nauczyć się” języka naturalnego, ale także docelowej reprezentacji — w naszym przypadku języka SQL. W szczególności musi zdobyć następujące elementy wiedzy:
- Składnia i semantyka języka SQL
- Struktura bazy danych
- Rozumienie języka naturalnego (NLU)
- Mapowanie między zapytaniami języka naturalnego i SQL (składniowe, leksykalne i semantyczne)
2.1 Rozwiązywanie zmienności językowej na wejściu
Na wejściu głównym wyzwaniem Text2SQL jest elastyczność języka: jak opisano w sekcji Format i struktura danych, to samo pytanie można sparafrazować na wiele różnych sposobów. Dodatkowo, w realnym kontekście konwersacji, mamy do czynienia z szeregiem problemów, takich jak błędy ortograficzne i gramatyczne, niekompletne i niejednoznaczne dane wejściowe, dane wielojęzyczne itp.

LLM, takie jak modele GPT, T5 i CodeX, są coraz bliżej rozwiązania tego problemu. Ucząc się z ogromnej ilości różnorodnego tekstu, uczą się radzić sobie z dużą liczbą wzorców i nieprawidłowości językowych. W końcu stają się zdolni do uogólniania pytań, które są semantycznie podobne, mimo że mają różne formy powierzchniowe. LLM można zastosować od razu po wyjęciu z pudełka (zero-shot) lub po dopracowaniu. Ta pierwsza, choć wygodna, prowadzi do mniejszej dokładności. Ta ostatnia wymaga więcej umiejętności i pracy, ale może znacznie zwiększyć celność.
Pod względem dokładności, zgodnie z oczekiwaniami, najlepiej działające modele to najnowsze modele z rodziny GPT, w tym modele CodeX. W kwietniu 2023 r. GPT-4 doprowadził do dramatycznego wzrostu dokładności o ponad 5% w stosunku do poprzedniego najnowocześniejszego stanu techniki i osiągnął dokładność 85.3% (w mierniku „wykonanie z wartościami”).[4] W obozie open source pierwsze próby rozwiązania zagadki Text2SQL koncentrowały się na modelach automatycznego kodowania, takich jak BERT, które doskonale radzą sobie z zadaniami NLU.[5, 6, 7] Jednak wśród szumu wokół generatywnej sztucznej inteligencji, ostatnie podejścia koncentrują się na modelach autoregresyjnych, takich jak model T5. T5 jest wstępnie przeszkolony w zakresie uczenia się wielozadaniowego, dzięki czemu łatwo dostosowuje się do nowych zadań językowych, m.in. różne warianty analizy semantycznej. Jednak modele autoregresyjne mają wrodzoną wadę, jeśli chodzi o semantyczne zadania analizy składniowej: mają nieograniczoną przestrzeń wyjściową i nie mają żadnych barier semantycznych, które ograniczałyby ich wyniki, co oznacza, że mogą być niezwykle kreatywne w swoim zachowaniu. Chociaż jest to niesamowite narzędzie do generowania treści o dowolnej formie, jest uciążliwe w przypadku zadań takich jak Text2SQL, w przypadku których oczekujemy ograniczonego, dobrze ustrukturyzowanego docelowego wyniku.
2.2 Walidacja i doskonalenie zapytań
Aby ograniczyć dane wyjściowe LLM, możemy wprowadzić dodatkowe mechanizmy sprawdzania poprawności i ulepszania zapytania. Można to wdrożyć jako dodatkowy etap walidacji, zgodnie z propozycją w systemie PICARD.[8] PICARD używa parsera SQL, który może zweryfikować, czy częściowe zapytanie SQL może po zakończeniu prowadzić do poprawnego zapytania SQL. Na każdym etapie generowania przez LLM tokeny, które unieważniłyby zapytanie, są odrzucane i zachowywane są prawidłowe tokeny o najwyższym prawdopodobieństwie. Będąc deterministycznym, podejście to zapewnia 100% poprawności SQL, o ile parser przestrzega poprawnych reguł SQL. Oddziela również sprawdzanie poprawności zapytania od generowania, umożliwiając w ten sposób utrzymanie obu komponentów niezależnie od siebie oraz aktualizację i modyfikację LLM.
Innym podejściem jest włączenie wiedzy strukturalnej i SQL bezpośrednio do LLM. Na przykład Graphix [9] używa warstw rozpoznających grafy do wstrzyknięcia ustrukturyzowanej wiedzy SQL do modelu T5. Ze względu na probabilistyczny charakter tego podejścia, skłania ono system do poprawnych zapytań, ale nie daje gwarancji sukcesu.
Wreszcie LLM może być używany jako wieloetapowy agent, który może samodzielnie sprawdzać i ulepszać zapytanie.[10] Korzystając z wielu kroków w łańcuchu myśli, agent może otrzymać zadanie zastanowienia się nad poprawnością własnych zapytań i poprawienia wszelkich błędów. Jeśli zweryfikowane zapytanie nadal nie może zostać wykonane, śledzenie wsteczne wyjątku SQL może zostać przekazane agentowi jako dodatkowa informacja zwrotna w celu ulepszenia.
Oprócz tych zautomatyzowanych metod, które mają miejsce w backendzie, możliwe jest również zaangażowanie użytkownika w proces sprawdzania zapytań. Opiszemy to bardziej szczegółowo w części dotyczącej doświadczenia użytkownika.
Ocena 2.3
Aby ocenić nasz algorytm Text2SQL, musimy wygenerować zestaw danych testowych (walidacyjnych), uruchomić na nim nasz algorytm i zastosować odpowiednie metryki oceny wyniku. Naiwny zbiór danych podzielony na dane szkoleniowe, rozwojowe i walidacyjne byłby oparty na parach pytanie-zapytanie i prowadziłby do nieoptymalnych wyników. Zapytania weryfikacyjne mogą zostać ujawnione modelowi podczas szkolenia i prowadzić do zbyt optymistycznego spojrzenia na jego umiejętności uogólniania. A podział oparty na zapytaniach, gdzie zbiór danych jest podzielony w taki sposób, że żadne zapytanie nie pojawia się zarówno podczas uczenia, jak i podczas walidacji, zapewnia bardziej zgodne z prawdą wyniki.
Jeśli chodzi o metryki oceny, w Text2SQL zależy nam nie na generowaniu zapytań, które są całkowicie identyczne ze złotym standardem. Ten „dokładne dopasowanie ciągu” Metoda jest zbyt restrykcyjna i wygeneruje wiele fałszywych negatywów, ponieważ różne zapytania SQL mogą prowadzić do tego samego zwróconego zestawu danych. Zamiast tego, chcemy osiągnąć wysokie dokładność semantyczna i oceń, czy zapytania przewidywane i zapytania o „złotym standardzie” zawsze zwracają te same zestawy danych. Istnieją trzy wskaźniki oceny, które przybliżają ten cel:
- Dokładnie ustawiona dokładność dopasowania: wygenerowane i docelowe zapytania SQL są dzielone na ich składniki, a powstałe zestawy są porównywane pod kątem tożsamości. Wadą jest to, że uwzględnia tylko zmiany kolejności w zapytaniu SQL, ale nie bardziej wyraźne różnice składniowe między zapytaniami semantycznie równoważnymi.
- Dokładność wykonania: zestawy danych wynikające z wygenerowanych i docelowych zapytań SQL są porównywane pod kątem tożsamości. Przy odrobinie szczęścia zapytania o innej semantyce mogą przejść ten test na określonej instancji bazy danych. Zakładając na przykład bazę danych, w której wszyscy użytkownicy mają więcej niż 30 lat, następujące dwa zapytania zwrócą identyczne wyniki, mimo że mają różną semantykę:
wybierz * od użytkownika
wybierz * od użytkownika, którego wiek > 30 - Dokładność zestawu testów: dokładność zestawu testów jest bardziej zaawansowaną i mniej liberalną wersją dokładności wykonania. Dla każdego zapytania generowany jest zestaw („zestaw testów”) baz danych, które są bardzo zróżnicowane pod względem zmiennych, warunków i wartości w zapytaniu. Następnie dokładność wykonania jest testowana na każdej z tych baz danych. Chociaż wymaga to dodatkowego wysiłku w celu opracowania zestawu testów, ta metryka znacznie zmniejsza również ryzyko fałszywych alarmów w ocenie.[12]
3. Doświadczenie użytkownika

Obecny stan Text2SQL nie pozwala na całkowicie bezproblemową integrację z systemami produkcyjnymi — zamiast tego konieczne jest aktywne zarządzanie oczekiwaniami i zachowaniem użytkownika, który zawsze powinien mieć świadomość, że wchodzi w interakcję z system sztucznej inteligencji.
3.1 Zarządzanie awariami
Text2SQL może zawieść w dwóch trybach, które należy złapać na różne sposoby:
- Błędy SQL: wygenerowane zapytanie jest nieprawidłowe — albo kod SQL jest nieprawidłowy, albo nie można go wykonać w określonej bazie danych z powodu błędów leksykalnych lub semantycznych. W takim przypadku żaden wynik nie może zostać zwrócony użytkownikowi.
- Błędy semantyczne: wygenerowane zapytanie jest poprawne, ale nie odzwierciedla semantyki pytania, co prowadzi do błędnego zwróconego zestawu danych.
Drugi tryb jest szczególnie trudny, ponieważ ryzyko „cichych awarii” — błędów niewykrytych przez użytkownika — jest wysokie. Prototypowy użytkownik nie będzie miał ani czasu, ani umiejętności technicznych, aby zweryfikować poprawność zapytania i/lub uzyskanych danych. Kiedy dane są wykorzystywane do podejmowania decyzji w świecie rzeczywistym, tego rodzaju awarie mogą mieć druzgocące konsekwencje. Aby tego uniknąć, niezwykle ważne jest edukowanie użytkowników i ustanowienie poręcze na poziomie biznesowym które ograniczają potencjalny wpływ, takie jak dodatkowe kontrole danych w przypadku decyzji o większym wpływie. Z drugiej strony możemy również użyć interfejsu użytkownika do zarządzania interakcją człowiek-maszyna i pomóc użytkownikowi wykryć i poprawić problematyczne żądania.
3.2 Interakcja człowiek-maszyna
Użytkownicy mogą angażować się w Twój system AI z różnym stopniem intensywności. Większa interakcja na żądanie może prowadzić do lepszych wyników, ale spowalnia również płynność doświadczenia użytkownika. Oprócz potencjalnego negatywnego wpływu błędnych zapytań i wyników, zastanów się również, jak zmotywowani będą Twoi użytkownicy do przekazywania informacji zwrotnych, aby uzyskać dokładniejsze wyniki, a także pomóc ulepszyć produkt w dłuższej perspektywie.
Najłatwiejszym i najmniej angażującym sposobem jest praca z wynikami zaufania. Podczas gdy naiwne obliczanie pewności jako średniej prawdopodobieństw wygenerowanych tokenów jest zbyt uproszczone, można zastosować bardziej zaawansowane metody, takie jak zwerbalizowana informacja zwrotna. [13] Zaufanie może być wyświetlane w interfejsie i wyróżnione wyraźnym ostrzeżeniem w przypadku, gdy jest niebezpiecznie niskie. W ten sposób odpowiedzialność za odpowiednią kontynuację w „realnym świecie” — odrzucenie, akceptację lub dodatkowe sprawdzenie danych — spoczywa na barkach użytkownika. Chociaż jest to bezpieczny zakład dla Ciebie jako dostawcy, przekazanie tej pracy użytkownikowi może również obniżyć wartość Twojego produktu.
Drugą możliwością jest zaangażowanie użytkownika w dialog wyjaśniający w przypadku niepewnych, niejednoznacznych lub w inny sposób podejrzanych zapytań. Na przykład twój system może zasugerować poprawki ortograficzne lub gramatyczne do danych wejściowych i poprosić o ujednoznacznienie określonych słów lub struktur gramatycznych. Może to również pozwolić użytkownikowi proaktywnie prosić o poprawki w zapytaniu:[14]
UŻYTKOWNIK: Pokaż mi zadania Jana w tym sprincie.
ASYSTENT: Czy chcesz zobaczyć zadania utworzone przez Jana lub te, nad którymi pracuje?
UŻYTKOWNIK: zadania utworzone przez Johna
ASYSTENT: Ok, oto identyfikatory zadań:

UŻYTKOWNIK: Dzięki, chciałbym również zobaczyć więcej informacji o zadaniach. Proszę również posortować według pilności.
ASYSTENT: Jasne, oto zadania wraz z krótkimi opisami, przydzielonymi osobami i terminami, posortowane według terminu.

Wreszcie, aby ułatwić zrozumienie zapytania przez użytkownika, system może również zapewnić wyraźne tekstowe przeformułowanie zapytania i poprosić użytkownika o potwierdzenie lub poprawienie go.[15]
4. Wymagania niefunkcjonalne
W tej sekcji omówimy specyficzne wymagania niefunkcjonalne dla Text2SQL, a także kompromisy między nimi. Skoncentrujemy się na sześciu wymaganiach, które wydają się najważniejsze dla zadania: dokładność, skalowalność, szybkość, zrozumiałość, prywatność i zdolność adaptacji w czasie.
4.1 Dokładność
W przypadku Text2SQL wymagania dotyczące dokładności są wysokie. Po pierwsze, Text2SQL jest zwykle stosowany w ustawieniach konwersacji, w których prognozy są wykonywane jeden po drugim. Tak więc „prawo wielkich liczb”, które zwykle pomaga zrównoważyć błąd w prognozach wsadowych, nie pomaga. Po drugie, ważność składniowa i leksykalna jest warunkiem „twardym”: model musi wygenerować dobrze sformułowane zapytanie SQL, potencjalnie ze złożoną składnią i semantyką, w przeciwnym razie żądanie nie może zostać wykonane w bazie danych. A jeśli to pójdzie dobrze i zapytanie może zostać wykonane, może nadal zawierać błędy semantyczne i prowadzić do błędnego zwróconego zestawu danych (por. sekcja 3.1 Zarządzanie awariami).
4.2 Skalowalność
Główne kwestie dotyczące skalowalności dotyczą tego, czy chcesz zastosować Text2SQL w jednej, czy w wielu bazach danych — aw tym drugim przypadku, czy zestaw baz danych jest znany i zamknięty. Jeśli tak, będzie Ci łatwiej, ponieważ podczas szkolenia możesz uwzględnić informacje o tych bazach danych. Jednak w scenariuszu skalowalnego produktu — niezależnie od tego, czy jest to samodzielna aplikacja Text2SQL, czy też integracja z istniejącym produktem danych — algorytm musi radzić sobie z każdym nowym schematem bazy danych w locie. Ten scenariusz nie daje również możliwości przekształcenia struktury bazy danych, aby była bardziej intuicyjna do nauki (link!). Wszystko to prowadzi do ciężkiego kompromisu z dokładnością, co może również wyjaśniać, dlaczego obecni dostawcy Text2SQL, którzy oferują zapytania ad hoc dotyczące nowych baz danych, nie osiągnęli jeszcze znaczącej penetracji rynku.
Prędkość 4.3
Ponieważ żądania Text2SQL będą zazwyczaj przetwarzane online podczas konwersacji, aspekt szybkości jest ważny dla zadowolenia użytkownika. Pozytywną stroną jest to, że użytkownicy często są świadomi faktu, że żądania danych mogą zająć trochę czasu i wykazać się wymaganą cierpliwością. Jednak ta dobra wola może zostać podważona przez ustawienie czatu, w którym użytkownicy podświadomie oczekują szybkości rozmowy zbliżonej do ludzkiej. Brutalne metody optymalizacji, takie jak zmniejszenie rozmiaru modelu, mogą mieć niedopuszczalny wpływ na dokładność, więc rozważ optymalizację wnioskowania, aby spełnić te oczekiwania.
4.4 Wyjaśnialność i przejrzystość
W idealnym przypadku użytkownik może prześledzić, jak zapytanie zostało wygenerowane z tekstu, zobaczyć odwzorowanie między określonymi słowami lub wyrażeniami w pytaniu a zapytaniem SQL itp. Pozwala to na weryfikację zapytania i dokonanie ewentualnych korekt podczas interakcji z systemem . Poza tym system mógłby również zapewnić wyraźne tekstowe przeformułowanie zapytania i poprosić użytkownika o potwierdzenie lub poprawienie.
4.5 Privacy
Funkcję Text2SQL można odizolować od wykonywania zapytania, dzięki czemu zwrócone informacje z bazy danych mogą pozostać niewidoczne. Krytycznym pytaniem jest jednak, ile informacji o bazie danych zawiera monit. Trzy opcje (poprzez obniżenie poziomu prywatności) to:
- Brak informacji
- Schemat bazy danych
- Zawartość bazy danych
Prywatność idzie w parze z dokładnością — im mniej masz ograniczeń w umieszczaniu przydatnych informacji w monicie, tym lepsze wyniki.
4.6 Możliwość dostosowania w czasie
Aby trwale korzystać z Text2SQL, należy dostosować się do dryfu danych, czyli zmieniającego się rozkładu danych, do których model jest stosowany. Załóżmy na przykład, że dane użyte do wstępnego dostrajania odzwierciedlają proste zapytania użytkowników, gdy zaczynają korzystać z systemu BI. Z biegiem czasu potrzeby informacyjne użytkowników stają się coraz bardziej wyrafinowane i wymagają bardziej złożonych zapytań, co przytłacza Twój naiwny model. Poza tym cele lub strategia zmiany firmy mogą również dryfować i kierować potrzeby informacyjne w inne obszary bazy danych. Wreszcie wyzwaniem specyficznym dla Text2SQL jest dryf bazy danych. W miarę rozszerzania bazy danych firmy do monitu trafiają nowe, niewidoczne kolumny i tabele. Chociaż algorytmy Text2SQL, które są przeznaczone do aplikacji z wieloma bazami danych, dobrze radzą sobie z tym problemem, może to znacząco wpłynąć na dokładność modelu z jedną bazą danych. Wszystkie te problemy można najlepiej rozwiązać za pomocą dostrajającego zestawu danych, który odzwierciedla bieżące, rzeczywiste zachowanie użytkowników. Dlatego kluczowe znaczenie ma rejestrowanie pytań i wyników użytkowników, a także wszelkich powiązanych informacji zwrotnych, które można zebrać na podstawie użytkowania. Ponadto algorytmy klastrowania semantycznego, na przykład wykorzystujące osadzanie lub modelowanie tematyczne, mogą być stosowane do wykrywania długoterminowych zmian w zachowaniu użytkowników i wykorzystywać je jako dodatkowe źródło informacji do doskonalenia zbioru danych dostrajających
Wnioski
Podsumujmy kluczowe punkty artykułu:
- Text2SQL pozwala na wdrożenie intuicyjnego i demokratycznego dostępu do danych w biznesie, maksymalizując tym samym wartość dostępnych danych.
- Dane Text2SQL składają się z pytań na wejściu i zapytań SQL na wyjściu. Odwzorowanie między pytaniami a zapytaniami SQL to wiele do wielu.
- Istotne jest podanie informacji o bazie danych w ramach monitu. Dodatkowo strukturę bazy danych można zoptymalizować, aby ułatwić algorytmowi jej poznanie i zrozumienie.
- Jeśli chodzi o dane wejściowe, głównym wyzwaniem jest zmienność językowa pytań w języku naturalnym, do których można podejść za pomocą LLM, które zostały wstępnie przeszkolone w zakresie szerokiej gamy różnych stylów tekstu
- Dane wyjściowe Text2SQL powinny być prawidłowym zapytaniem SQL. To ograniczenie można wprowadzić poprzez „wstrzyknięcie” wiedzy SQL do algorytmu; alternatywnie, stosując podejście iteracyjne, zapytanie można sprawdzić i poprawić w wielu krokach.
- Ze względu na potencjalnie duży wpływ „cichych awarii”, które zwracają błędne dane do podejmowania decyzji, zarządzanie awariami jest głównym problemem w interfejsie użytkownika.
- W „rozszerzony” sposób użytkownicy mogą być aktywnie zaangażowani w iteracyjne sprawdzanie poprawności i ulepszanie zapytań SQL. Chociaż sprawia to, że aplikacja jest mniej płynna, zmniejsza również wskaźniki awaryjności, pozwala użytkownikom eksplorować dane w bardziej elastyczny sposób i generuje cenne sygnały do dalszej nauki.
- Główne wymagania niefunkcjonalne, które należy wziąć pod uwagę, to dokładność, skalowalność, szybkość, zrozumiałość, prywatność i możliwość dostosowania w czasie. Główne kompromisy polegają z jednej strony na dokładności, a z drugiej na skalowalności, szybkości i prywatności.
Referencje
[1] Kena Van Harena. 2023. Zastąpienie analityka SQL 26 rekurencyjnymi monitami GPT
[2] Nitarshan Rajkumar i in. 2022. Ocena możliwości zamiany tekstu na SQL w dużych modelach językowych
[3] Naihao Deng i in. 2023. Najnowsze postępy w przetwarzaniu tekstu na SQL: przegląd tego, co mamy i czego oczekujemy
[4] Mohammadreza Pourreza i in. 2023. DIN-SQL: zdekomponowane uczenie kontekstowe przetwarzania tekstu na SQL z samokorektą
[5] Victor Zhong i in. 2021. Uziemiona adaptacja dla wykonywalnego parsowania semantycznego bez strzału
[6] Xi Victoria Lin i in. 2020. Łączenie danych tekstowych i tabelarycznych w celu semantycznego analizowania tekstu do SQL w wielu domenach
[7] Tong Guo i in. 2019. Udoskonalone generowanie tekstu do SQL w oparciu o BERT
[8] Torsten Scholak i in. 2021. PICARD: Parsowanie przyrostowe w celu ograniczonego dekodowania auto-regresyjnego z modeli językowych
[9] Jinyang Li i in. 2023. Graphix-T5: Mieszanie wstępnie wyszkolonych transformatorów z warstwami obsługującymi grafy w celu przetwarzania tekstu na SQL
[10] Łańcuch Lang. 2023. LLM i SQL
[11] Tao Yu i in. 2018. Pająk: wielkoskalowy zestaw danych oznaczony przez człowieka do złożonego i międzydomenowego analizowania semantycznego oraz zadania zamiany tekstu na SQL
[12] Ruiqi Zhong i in. 2020. Ocena semantyczna dla Text-to-SQL z destylowanymi zestawami testów
[13] Katherine Tian i in. 2023. Po prostu poproś o kalibrację: strategie uzyskiwania skalibrowanych wyników ufności z modeli językowych dostrojonych z ludzkimi opiniami
[14] Braden Hancock i in. 2019. Uczenie się z dialogu po wdrożeniu: Nakarm się, Chatbot!
[15] Ahmed Elgohary i in. 2020. Porozmawiaj ze swoim parserem: interaktywna zamiana tekstu na SQL z informacją zwrotną w języku naturalnym
[16] Janna Lipenkova. 2022. Mów do mnie! Rozmowy Text2SQL z danymi Twojej firmy, wykład na spotkaniu dotyczącym przetwarzania języka naturalnego w Nowym Jorku.
Wszystkie obrazy są autorstwa autora.
Ten artykuł został pierwotnie opublikowany w W kierunku nauki o danych i ponownie opublikowane w TOPBOTS za zgodą autora.
Podoba ci się ten artykuł? Zarejestruj się, aby otrzymywać więcej aktualizacji badań AI.
Damy Ci znać, gdy wydamy więcej artykułów podsumowujących takich jak ten.
Związane z
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://www.topbots.com/conversational-ai-for-data-analysis/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 11
- 12
- 13
- 14
- 15%
- 16
- 2018
- 2019
- 2020
- 2021
- 2022
- 2023
- 26
- 30
- 7
- 8
- 9
- a
- Zdolny
- O nas
- powyżej
- bezwzględny
- absolutnie
- akceptacja
- dostęp
- Dostęp do danych
- Stosownie
- Konta
- precyzja
- dokładny
- dokładnie
- Osiągać
- osiągnięty
- nabyć
- aktywnie
- przystosować
- adaptacja
- dostosowuje się
- Dodatkowy
- do tego
- Korekty
- zaawansowany
- zaliczki
- Korzyść
- Po
- przed
- wiek
- w wieku
- Agent
- AI
- ai badania
- AL
- Alarm
- algorytm
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- wzdłuż
- już
- również
- alternatywny
- zawsze
- zdumiewający
- Ambicje
- wśród
- an
- analiza
- analityk
- analitycy
- Analityczny
- analityka
- i
- Inne
- każdy
- Zastosowanie
- aplikacje
- stosowany
- Aplikuj
- Stosowanie
- podejście
- awanse
- właściwy
- przybliżony
- kwiecień
- SĄ
- obszary
- na około
- artykuł
- towary
- AS
- aspekt
- aspekty
- powiązany
- At
- Próby
- autor
- zautomatyzowane
- automatycznie
- autonomicznie
- dostępny
- średni
- uniknąć
- świadomy
- Backend
- Bilans
- baza
- na podstawie
- podstawa
- BE
- stają się
- Początek
- jest
- Korzyści
- oprócz
- BEST
- Zakład
- Ulepsz Swój
- pomiędzy
- Poza
- uprzedzenia
- Najwyższa
- obie
- budować
- Budowanie
- ciężar
- biznes
- biznes
- ale
- by
- nazywa
- Obóz
- CAN
- Może uzyskać
- nie może
- możliwości
- który
- walizka
- złapany
- centralny
- pewien
- wyzwanie
- wyzwania
- zmiana
- Zmiany
- wymiana pieniędzy
- Kanał
- ZOBACZ
- w kratę
- kontrola
- Wykrywanie urządzeń szpiegujących
- wybór
- klasyfikacja
- zamknięte
- bliższy
- klastrowanie
- kolekcja
- kolumny
- byliśmy spójni, od początku
- przyjście
- wspólny
- Komunikacja
- Firmy
- sukcesy firma
- Firma
- w porównaniu
- konkurencja
- konkurencyjny
- kompletny
- całkowicie
- ukończenia
- kompleks
- składniki
- Koncepcje
- koncepcyjnego
- Troska
- warunek
- Warunki
- pewność siebie
- Potwierdzać
- Konsekwencje
- Rozważać
- znaczny
- Rozważania
- za
- składa się
- zawartość
- kontekst
- kontrola
- Wygodny
- Konwencjonalny
- Rozmowa
- konwersacyjny
- konwersacyjna sztuczna inteligencja
- Interfejsy konwersacyjne
- rozmowy
- Chłodny
- skorygowania
- Korekty
- Odpowiedni
- mógłby
- Stwórz
- stworzony
- tworzy
- Tworzenie
- Twórczy
- krytyczny
- istotny
- Aktualny
- Obecnie
- klient
- dane
- dostęp do danych
- analiza danych
- nauka danych
- naukowiec danych
- Baza danych
- Bazy danych
- zbiory danych
- sprawa
- decyzja
- Podejmowanie decyzji
- Decyzje
- Rozszyfrowanie
- głęboko
- głębokie nurkowanie
- opóźnienia
- dostarczona
- demokratyczny
- zależny
- Wdrożenie
- opisać
- opisane
- zaprojektowany
- projektanci
- życzenia
- Mimo
- detal
- niszczycielski
- oprogramowania
- Dialog
- Różnice
- różne
- zróżnicowany
- kierować
- bezpośrednio
- zniechęcony
- dyskutować
- dyskusje
- rozproszone
- wystawiany
- Zakłócenie
- 分配
- inny
- do
- robi
- Nie
- robi
- zrobić
- nie
- na dół
- dramatycznie
- z powodu
- podczas
- dynamiczny
- e
- E i T
- każdy
- łatwość
- łatwiej
- Najprostszym
- z łatwością
- krawędź
- kształcić
- edukacyjny
- wysiłek
- bądź
- Elementy
- objęty
- pracowników
- umożliwiać
- objąć
- zakończenia
- energia
- zobowiązany
- ujmujący
- inżynier
- Inżynieria
- Inżynierowie
- wzmocnione
- dość
- wzbogacanie
- zapewnić
- zapewnia
- całkowicie
- wejście
- środowiska
- Równoważny
- błąd
- Błędy
- oszacowanie
- itp
- Eter (ETH)
- oceniać
- ewaluację
- Parzyste
- Każdy
- wszyscy
- przykład
- przykłady
- przewyższać
- wyjątek
- wykonany
- egzekucja
- zwolniony
- istnieć
- Przede wszystkim system został opracowany
- oczekiwać
- oczekiwanie
- oczekiwania
- spodziewany
- drogi
- doświadczenie
- Wyjaśniać
- Wyjaśnialność
- odkryj
- wyrażone
- wyrażeń
- dodatkowy
- niezwykle
- fakt
- FAIL
- Brak
- fałszywy
- członków Twojej rodziny
- Moda
- szybciej
- Cecha
- informacja zwrotna
- Postać
- W końcu
- i terminów, a
- wada
- Skazy
- Elastyczność
- elastyczne
- pływ
- płyn
- płynność
- Skupiać
- skoncentrowany
- obserwuj
- ilość obserwujących
- następujący
- W razie zamówieenia projektu
- obcy
- Nasz formularz
- format
- Dawny
- formularze
- sformułowanie
- często
- tarcie
- od
- pełny
- funkcjonować
- dalej
- Ogólne
- Generować
- wygenerowane
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- otrzymać
- miejsce
- Dać
- dany
- Globalne
- Go
- cel
- Gole
- Goes
- Złoto
- gold standard
- dobry
- Życzliwość
- Gramatyka
- Ziemia
- Rozwój
- gwarancja
- poprowadzi
- miał
- ręka
- garstka
- uchwyt
- siła robocza
- zdarzyć
- Have
- mający
- he
- ciężki
- pomoc
- pomaga
- tutaj
- Wysoki
- wysokiej jakości
- wyższy
- Atrakcja
- Podświetlony
- wysoko
- W jaki sposób
- Jednak
- HTML
- HTTPS
- olbrzymi
- człowiek
- Ludzie
- Szum
- i
- idealny
- identiques
- tożsamość
- ids
- if
- zdjęcia
- Rezultat
- wdrożenia
- realizacja
- realizowane
- ważny
- niemożliwy
- podnieść
- ulepszony
- poprawa
- poprawy
- in
- informacje
- zawierać
- włączony
- Włącznie z
- włączać
- Rejestrowy
- włączenie
- Zwiększać
- niezależnie
- indywidualny
- przemysł
- niewydajny
- Informacja
- poinformowany
- początkowy
- wstrzykiwać
- wkład
- Wejścia
- spostrzeżenia
- przykład
- zamiast
- integracja
- interakcji
- interakcji
- wzajemne oddziaływanie
- Interakcje
- interaktywne
- Interfejs
- interfejsy
- najnowszych
- wewnętrzny
- przedstawiać
- intuicyjny
- inwestowanie
- angażować
- zaangażowany
- odosobniony
- problem
- problemy
- IT
- JEGO
- John
- podróż
- Trzymać
- trzymane
- Klawisz
- Klawisze
- Zabija
- Uprzejmy
- Wiedzieć
- wiedza
- Zarządzanie wiedzą
- znany
- Ziemie
- język
- duży
- na dużą skalę
- większe
- firmy
- warstwa
- nioski
- prowadzić
- prowadzący
- Wyprowadzenia
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- najmniej
- Doprowadziło
- Długość
- mniej
- najmu
- poziom
- Dźwignia
- li
- leży
- życie
- lubić
- LIMIT
- Ograniczenia
- lin
- mało
- log
- logiczny
- długo
- długoterminowy
- poszukuje
- stracił
- niski
- niższy
- szczęście
- maszyna
- uczenie maszynowe
- zrobiony
- Główny
- utrzymać
- poważny
- robić
- WYKONUJE
- Dokonywanie
- zarządzanie
- i konserwacjami
- kierownik
- Zarządzający
- podręcznik
- produkcja
- wiele
- mapowanie
- wyraźny
- rynek
- Marketing
- mistrz
- mistrzostwo
- Mecz
- materiał
- dojrzałość
- Maksymalna szerokość
- maksymalizacja
- me
- znaczy
- Mechanizmy
- Meetup
- psychika
- metoda
- metody
- metryczny
- Metryka
- może
- nic
- błędy
- Mieszanie
- Moda
- model
- modelowanie
- modele
- Nowoczesne technologie
- Tryby
- modyfikować
- jeszcze
- większość
- zmotywowani
- dużo
- wielokrotność
- Nazwa
- Nazwy
- nazywania
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Natura
- niezbędny
- Potrzebować
- wymagania
- ujemny
- negatywy
- Ani
- Nowości
- I Love New York
- nie
- Nie
- Hałas
- nietechniczne
- ani
- już dziś
- numer
- z naszej
- cel
- Obserwuje
- przestarzały
- of
- poza
- oferta
- oferuje
- często
- on
- ONE
- Online
- tylko
- open source
- operacje
- Okazja
- przeciwny
- Optymalny
- optymalizacji
- Zoptymalizowany
- Optymistyczny
- Opcje
- or
- zamówienie
- pierwotnie
- Inne
- Inaczej
- ludzkiej,
- wydajność
- koniec
- własny
- đôi
- par
- część
- szczególnie
- przechodzić
- minęło
- przebiegi
- Cierpliwość
- wzory
- penetracja
- doskonalenie
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- pozwolenie
- planowanie
- plato
- Analiza danych Platona
- PlatoDane
- odgrywa
- Proszę
- zwrotnica
- pozytywny
- możliwość
- możliwy
- potencjał
- potencjalnie
- Przewiduje
- przepowiednia
- Przewidywania
- teraźniejszość
- poprzedni
- pierwotny
- prywatność
- przywilej
- nagroda
- prawdopodobnie
- wygląda tak
- obrobiony
- przetwarzanie
- Produkt
- Produkcja
- wyraźny
- zaproponowane
- zapewniać
- pod warunkiem,
- dostawców
- zapewnia
- opublikowany
- puzzle
- Python
- jakość
- ilość
- zapytania
- pytanie
- pytania
- szybko
- zasięg
- ceny
- Surowy
- surowe dane
- czytelnicy
- real
- Prawdziwy świat
- rozsądny
- podsumować
- niedawny
- Rekurencyjne
- zmniejszyć
- zmniejsza
- redukcja
- referencje
- , o którym mowa
- odzwierciedlić
- odzwierciedla
- związane z
- relacje
- Relacje
- zwolnić
- reprezentacja
- reprezentowane
- zażądać
- wywołań
- wymagać
- wymagany
- wymagania
- Wymaga
- Badania naukowe
- poszanowanie
- odpowiedzialność
- odpowiedzialny
- ograniczony
- dalsze
- wynikły
- Efekt
- powrót
- Ujawnił
- Ryzyko
- Rywal
- drogi
- ROI
- Rola
- role
- rundy
- Zasada
- reguły
- run
- bieganie
- "bezpiecznym"
- taki sam
- klientów
- Skalowalność
- skalowalny
- scenariusz
- scenariusze
- nauka
- Naukowiec
- Naukowcy
- wyniki
- bezszwowy
- druga
- Sekcja
- działy
- widzieć
- wydać się
- semantyka
- sentyment
- ServiceNow
- zestaw
- Zestawy
- ustawienie
- w panelu ustawień
- ustawienie
- ona
- Short
- powinien
- pokazać
- bok
- znak
- Sygnały
- znaczący
- znacznie
- podobny
- Prosty
- ponieważ
- pojedynczy
- SIX
- Rozmiar
- umiejętność
- umiejętności
- zwalnia
- mniejszy
- mądry
- So
- solidny
- Rozwiązywanie
- coś
- wyrafinowany
- Źródło
- Typ przestrzeni
- specyficzny
- swoiście
- prędkość
- wydać
- dzielić
- sprint
- SQL
- Kwadratowa
- Personel
- standalone
- standard
- początek
- rozpoczęty
- rozpocznie
- state-of-the-art
- Rynek
- Ewolucja krok po kroku
- Cel
- Nadal
- Strategiczny
- strategie
- Strategia
- rygorystyczny
- sznur
- strukturalny
- Struktura
- zbudowany
- sukces
- taki
- wystarczający
- sugerować
- PODSUMOWANIE
- Utrzymany
- Powierzchnia
- Badanie
- podejrzliwy
- składnia
- system
- systemy
- Brać
- Talent
- Mówić
- cel
- Zadanie
- zadania
- zespół
- Zespoły
- Techniczny
- Techniki
- Technologia
- semestr
- REGULAMIN
- test
- przetestowany
- Klasyfikacja tekstu
- niż
- że
- Połączenia
- Codex
- Informacje
- ich
- Im
- następnie
- Tam.
- Te
- one
- myśleć
- to
- tych
- trzy
- Przez
- poprzez
- czas
- do
- Żetony
- także
- Zestaw narzędzi
- narzędzia
- TOPBOTY
- aktualny
- w kierunku
- Transakcje
- tradycyjny
- Trening
- Przesyłanie
- Przekształcać
- Transformacja
- przemiany
- Transformatory
- SKRĘCAĆ
- Obrócenie
- drugiej
- rodzaj
- typy
- zazwyczaj
- zasadniczy
- zrozumieć
- zrozumienie
- uniwersalny
- Nowości
- uaktualnienie
- pilna sprawa
- Stosowanie
- posługiwać się
- używany
- przydatna informacja
- Użytkownik
- Doświadczenie użytkownika
- Interfejs użytkownika
- Użytkownicy
- zastosowania
- za pomocą
- ux
- projektanci ux
- zatwierdzony
- sprawdzanie poprawności
- uprawomocnienie
- Cenny
- wartość
- Wartości
- różnorodność
- różnorodny
- Sklepienie
- sprzedawca
- zweryfikować
- wszechstronny
- wersja
- początku.
- przez
- Wiktoria
- Zobacz i wysłuchaj
- wizja
- chcieć
- była
- Droga..
- sposoby
- we
- tydzień
- tygodniowy
- DOBRZE
- były
- Co
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- KIM
- dlaczego
- szeroki
- będzie
- wygrać
- w
- bez
- słowa
- Praca
- pracujący
- świat
- by
- napisany
- Źle
- xi
- z żółtymi
- tak
- jeszcze
- york
- ty
- Twój
- siebie
- youtube
- zefirnet
- Zhong