Autor: Vitalik Buterin za pośrednictwem Blog Vitalika Buterina
Specjalne podziękowania dla zespołów Worldcoin i Modulus Labs, Xinyuan Sun, Martina Koeppelmanna i Illii Polosukhin za opinie i dyskusję.
Wiele osób przez lata zadawało mi podobne pytanie: jakie są przecięcia pomiędzy kryptowalutami a sztuczną inteligencją, które uważam za najbardziej owocne? To rozsądne pytanie: krypto i sztuczna inteligencja to dwa główne trendy w zakresie głębokich technologii (oprogramowania) ostatniej dekady i po prostu wydaje się, że tak właśnie jest musi być jakimś połączeniem pomiędzy nimi. Łatwo jest znaleźć synergię na powierzchownym poziomie wibracji: decentralizacja kryptowalut może zrównoważyć centralizację sztucznej inteligencjisztuczna inteligencja jest nieprzejrzysta, a kryptowaluty zapewniają przejrzystość, sztuczna inteligencja potrzebuje danych, a łańcuchy bloków dobrze nadają się do przechowywania i śledzenia danych. Jednak przez lata, gdy ludzie prosili mnie, żebym zgłębił temat i opowiedział o konkretnych zastosowaniach, moja odpowiedź była rozczarowująca: „tak, jest kilka rzeczy, ale nie aż tak dużo”.
W ciągu ostatnich trzech lat wraz z pojawieniem się znacznie potężniejszej sztucznej inteligencji w postaci nowoczesnych LLMoraz pojawienie się znacznie potężniejszych kryptowalut w postaci nie tylko rozwiązań skalujących blockchain, ale także ZKP, FHE, (dwupartyjny i N-partyjny) MPC, zaczynam widzieć tę zmianę. Rzeczywiście istnieją pewne obiecujące zastosowania sztucznej inteligencji w ekosystemach blockchain Sztuczna inteligencja wraz z kryptografią, choć należy zachować ostrożność przy stosowaniu sztucznej inteligencji. Szczególnym wyzwaniem jest: w kryptografii otwarte oprogramowanie jest jedynym sposobem na zapewnienie naprawdę bezpieczeństwa, ale w przypadku sztucznej inteligencji model (lub nawet jego dane szkoleniowe) jest otwarty znacznie wzrasta jego podatność na kontradyktoryjne uczenie maszynowe ataki. W tym poście omówiona zostanie klasyfikacja różnych sposobów, w jakie kryptowaluty i sztuczna inteligencja mogą się ze sobą krzyżować, a także perspektywy i wyzwania związane z każdą kategorią.
Ogólne podsumowanie skrzyżowań kryptowalut i sztucznej inteligencji z a wpis na blogu uETH. Ale czego potrzeba, aby faktycznie zrealizować którąkolwiek z tych synergii w konkretnym zastosowaniu?
Cztery główne kategorie
Sztuczna inteligencja to bardzo szerokie pojęcie: można myśleć o „AI” jako o zestawie algorytmów, które tworzy się nie poprzez ich wyraźne określenie, ale raczej poprzez mieszanie dużej zupy obliczeniowej i wywieranie pewnego rodzaju presji optymalizacyjnej, która popycha zupę w kierunku tworzenie algorytmów o pożądanych właściwościach. Tego opisu zdecydowanie nie należy traktować lekceważąco: to obejmuje dotychczasowy wygląda tak że stworzony przede wszystkim my, ludzie! Oznacza to jednak, że algorytmy sztucznej inteligencji mają pewne wspólne właściwości: zdolność do wykonywania niezwykle potężnych zadań, a także ograniczenia w naszej zdolności poznania i zrozumienia tego, co dzieje się pod maską.
Istnieje wiele sposobów kategoryzowania sztucznej inteligencji; na potrzeby tego wpisu, który mówi o interakcjach pomiędzy AI a blockchainami (które zostały opisane jako platforma dla tworzenie „gier”), sklasyfikowam to w następujący sposób:
- AI jako gracz w grze [najwyższa żywotność]: Sztuczne inteligencje uczestniczące w mechanizmach, w których ostatecznym źródłem zachęt jest protokół z udziałem człowieka.
- AI jako interfejs do gry [duży potencjał, ale z ryzykiem]: Sztuczna inteligencja pomaga użytkownikom zrozumieć otaczający ich świat kryptowalut i zapewnia, że ich zachowanie (tj. podpisane wiadomości i transakcje) jest zgodne z ich intencjami i nie daje się oszukać ani oszukać.
- AI jako zasady gry [przestrzegaj bardzo ostrożnie]: blockchainy, DAO i podobne mechanizmy bezpośrednio odwołujące się do sztucznej inteligencji. Pomyśl np. „Sędziowie AI”
- AI jako cel gry [długoterminowy, ale intrygujący]: projektowanie łańcuchów bloków, DAO i podobnych mechanizmów w celu zbudowania i utrzymania sztucznej inteligencji, którą można wykorzystać do innych celów, wykorzystując bity kryptograficzne albo do lepszego zachęcania do szkoleń, albo do zapobiegania wyciekom prywatnych danych lub niewłaściwemu wykorzystaniu sztucznej inteligencji.
Przejrzyjmy je jeden po drugim.
AI jako gracz w grze
Właściwie jest to kategoria istniejąca od niemal dekady, a przynajmniej od tego czasu zdecentralizowane giełdy w łańcuchu (DEX) zaczął widzieć znaczące zastosowanie. Za każdym razem, gdy ma miejsce wymiana, istnieje możliwość zarobienia pieniędzy poprzez arbitraż, a boty mogą przeprowadzać arbitraż znacznie lepiej niż ludzie. Ten przypadek użycia istnieje od dawna, nawet w przypadku znacznie prostszych AI niż to, co mamy dzisiaj, ale ostatecznie jest to bardzo realne skrzyżowanie AI + krypto. Niedawno widzieliśmy boty arbitrażowe MEV często się nawzajem wyzyskując. Za każdym razem, gdy masz aplikację typu blockchain, która obejmuje aukcje lub handel, będziesz mieć boty arbitrażowe.
Ale boty arbitrażowe AI to tylko pierwszy przykład znacznie większej kategorii, która, jak się spodziewam, wkrótce zacznie obejmować wiele innych aplikacji. Poznaj AIOmen, a demonstracja rynku prognostycznego, w którym graczami są sztuczna inteligencja:
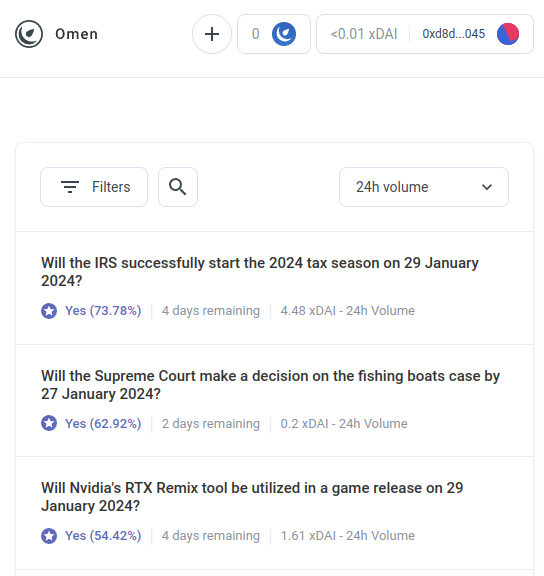
Jedną z odpowiedzi na to jest wskazanie ciągłych ulepszeń UX w Polimarket lub inne nowe rynki prognostyczne i mają nadzieję, że odniosą sukces tam, gdzie poprzednie iteracje zawiodły. W końcu, jak głosi historia, ludzie są skłonni obstawiać dziesiątki miliardów na sport, więc dlaczego ludzie nie mieliby dorzucić wystarczającej ilości pieniędzy, obstawiając wybory w USA lub… LK99 że zaczyna mieć sens, aby zaczęli dołączać poważni gracze? Ale ten argument musi uwzględniać fakt, że, cóż, poprzednie iteracje mieć nie udało się osiągnąć tego poziomu skali (przynajmniej w porównaniu z marzeniami ich zwolenników), więc wydaje się, że potrzebujesz coś nowego aby rynki prognostyczne odniosły sukces. Zatem inną odpowiedzią jest wskazanie jednej specyficznej cechy ekosystemów rynku prognostycznego, której możemy się spodziewać w latach 2020., a której nie widzieliśmy w latach 2010.: możliwość wszechobecnego udziału AI.
Sztuczne inteligencje są skłonne pracować za mniej niż 1 dolara za godzinę i dysponują wiedzą encyklopedyczną, a jeśli to nie wystarczy, można je nawet zintegrować z funkcją wyszukiwania w Internecie w czasie rzeczywistym. Jeśli stworzysz rynek i zapewnisz dotację na płynność w wysokości 50 dolarów, ludziom nie będzie na tyle zależało na składaniu ofert, ale tysiące sztucznej inteligencji z łatwością zaroją się od wszystkich pytań i dokonają najlepszego odgadnięcia. Zachęta do wykonania dobrej roboty w dowolnej kwestii może być niewielka, ale zachęta do stworzenia sztucznej inteligencji, która potrafi dobrze przewidywać ogólnie może iść w miliony. Należy pamiętać, że potencjalnie nie potrzebujesz nawet ludzi, aby rozstrzygnąć większość pytań: możesz użyć wielorundowego systemu sporów podobnego do Augur lub Kleros, gdzie AI byłyby również tymi, które brały udział we wcześniejszych rundach. Ludzie musieliby zareagować jedynie w tych nielicznych przypadkach, gdy miała miejsce seria eskalacji i obie strony zaangażowały duże kwoty pieniędzy.
Jest to potężny prymityw, ponieważ gdy „rynek prognoz” uda się uruchomić w tak mikroskopijnej skali, można go ponownie wykorzystać do wielu innych rodzajów pytań:
- Czy ten post w mediach społecznościowych jest akceptowalny zgodnie z [warunkami użytkowania]?
- Co stanie się z ceną akcji X (np. patrz Numerai)
- Czy konto, z którego obecnie do mnie wysyłasz wiadomości, to rzeczywiście Elon Musk?
- Czy przesłanie tej pracy na internetową giełdę zadań jest akceptowalne?
- Czy dapp na https://examplefinance.network jest oszustwem?
- Is
0x1b54....98c3właściwie adres tokena „Casinu Inu” ERC20?
Możesz zauważyć, że wiele z tych pomysłów zmierza w kierunku tego, co nazwałem „obrona informacyjna" W . Ogólnie rzecz biorąc, pytanie brzmi: w jaki sposób pomóc użytkownikom odróżniać informacje prawdziwe od fałszywych i wykrywać oszustwa, nie upoważniając scentralizowanego organu do decydowania, co jest dobre, a co złe, kto mógłby następnie nadużyć tej pozycji? Na poziomie mikro odpowiedzią może być „AI”. Ale na poziomie makro pytanie brzmi: kto buduje sztuczną inteligencję? Sztuczna inteligencja jest odzwierciedleniem procesu, który ją stworzył, dlatego nie można uniknąć uprzedzeń. Dlatego istnieje potrzeba gry na wyższym poziomie, która oceniałaby, jak dobrze radzą sobie różne AI, i w której AI mogłyby uczestniczyć w grze jako gracze.
To wykorzystanie sztucznej inteligencji, w ramach którego sztuczna inteligencja uczestniczy w mechanizmie, w wyniku którego zostaje ostatecznie nagrodzona lub ukarana (prawdopodobnie) przez mechanizm łańcuchowy, który zbiera dane wejściowe od ludzi (nazwijmy to zdecentralizowanym systemem rynkowym RLHF?), czy moim zdaniem naprawdę warto się tym zainteresować. Teraz jest właściwy czas, aby bliżej przyjrzeć się takim przypadkom użycia, ponieważ skalowanie blockchaina w końcu się udaje, dzięki czemu „mikro” wszystko staje się w końcu wykonalne w łańcuchu, gdy często nie było wcześniej.
Powiązana kategoria zastosowań zmierza w kierunku wysoce autonomicznych agentów wykorzystanie blockchainów do lepszej współpracy, czy to poprzez płatności, czy poprzez wykorzystanie inteligentnych umów do podejmowania wiarygodnych zobowiązań.
AI jako interfejs do gry
Jeden pomysł, który przedstawiłem w swoim pisma na to pomysł, że istnieje szansa rynkowa na napisanie oprogramowania skierowanego do użytkownika, które chroniłoby interesy użytkowników poprzez interpretację i identyfikację zagrożeń w świecie online, po którym porusza się użytkownik. Jednym z już istniejących przykładów jest funkcja wykrywania oszustw Metamask:
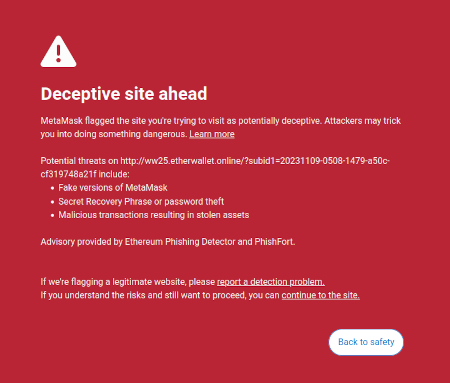
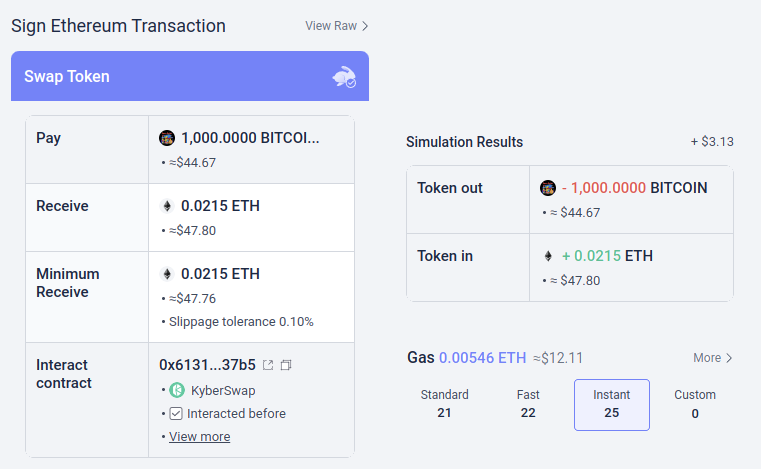
Potencjalnie tego rodzaju narzędzia mogłyby zostać wyposażone w sztuczną inteligencję. Sztuczna inteligencja może zapewnić znacznie bogatsze, przyjazne dla człowieka wyjaśnienie, w jakim rodzaju dapp bierzesz udział, konsekwencje bardziej skomplikowanych operacji, które podpisujesz, czy dany token jest autentyczny (np. BITCOIN to nie tylko ciąg znaków, to nazwa rzeczywistej kryptowaluty, która nie jest tokenem ERC20 i której cena jest znacznie wyższa niż 0.045 USD i nowoczesny LLM by o tym wiedział) i tak dalej. Istnieją projekty, które zaczynają zmierzać w tym kierunku (np Portfel LangChain, który wykorzystuje sztuczną inteligencję jako pierwotny interfejs). Moim zdaniem interfejsy wykorzystujące wyłącznie sztuczną inteligencję są obecnie prawdopodobnie zbyt ryzykowne, ponieważ zwiększają ryzyko inny rodzaje błędów, ale sztuczna inteligencja uzupełniająca bardziej konwencjonalny interfejs staje się bardzo opłacalna.
Warto wspomnieć o jednym szczególnym ryzyku. Zajmę się tym szerzej w sekcji „Sztuczna inteligencja jako zasady gry” poniżej, ale ogólnym problemem jest kontradyktoryjne uczenie maszynowe: jeśli użytkownik ma dostęp do asystenta AI w portfelu typu open source, przestępcy również będą mieli dostęp do tego asystenta AI, dzięki czemu będą mieli nieograniczone możliwości optymalizacji swoich oszustw tak, aby nie uruchamiały się obrona tego portfela. Wszystkie nowoczesne sztuczna inteligencja mają gdzieś błędy i nie jest to zbyt trudne dla procesu szkolenia, nawet takiego, w którym występuje tylko jedna sztuczna inteligencja ograniczony dostęp do modelu, aby je znaleźć.
Tutaj lepiej sprawdzają się „AI uczestniczące w mikrorynkach w łańcuchu”: każda pojedyncza sztuczna inteligencja jest narażona na te same ryzyko, ale celowo tworzysz otwarty ekosystem składający się z dziesiątek osób, które stale je iterują i na bieżąco ulepszają. Co więcej, każda indywidualna sztuczna inteligencja jest zamknięta: bezpieczeństwo systemu wynika z otwartości zasad gra, a nie wewnętrzne funkcjonowanie każdego z nich gracz.
Podsumowanie: Sztuczna inteligencja może pomóc użytkownikom zrozumieć, co się dzieje prostym językiem, może służyć jako nauczyciel w czasie rzeczywistym, może chronić użytkowników przed błędami, ale ostrzega, gdy próbuje się jej użyć bezpośrednio przeciwko złośliwym dezinformatorom i oszustom.
AI jako zasady gry
Teraz dochodzimy do aplikacji, która ekscytuje wiele osób, ale moim zdaniem jest najbardziej ryzykowna i w przypadku której musimy postępować ostrożnie: to, co nazywam sztuczną inteligencją, jest częścią zasad gry. Wiąże się to z podekscytowaniem elit politycznych głównego nurtu w związku z „sędziami AI” (np. zob ten artykuł na stronie internetowej „Światowego Szczytu Rządu”), a analogie tych pragnień można znaleźć w zastosowaniach blockchain. Jeśli inteligentny kontrakt oparty na blockchain lub DAO musi podjąć subiektywną decyzję (np. czy konkretny produkt pracy jest akceptowalny w umowie o pracę do wynajęcia? Jaka jest właściwa interpretacja konstytucji języka naturalnego, takiej jak Optymizm? Prawo łańcuchów?), czy mógłbyś sprawić, że sztuczna inteligencja będzie po prostu częścią umowy lub DAO, która pomoże w egzekwowaniu tych zasad?
To tutaj kontradyktoryjne uczenie maszynowe będzie niezwykle trudnym wyzwaniem. Podstawowy dwuzdaniowy argument „dlaczego” jest następujący:
Jeśli model sztucznej inteligencji, który odgrywa kluczową rolę w mechanizmie, jest zamknięty, nie można zweryfikować jego wewnętrznego działania, dlatego nie jest on lepszy od scentralizowanej aplikacji. Jeśli model sztucznej inteligencji jest otwarty, osoba atakująca może go pobrać i symulować lokalnie, a następnie zaprojektować wysoce zoptymalizowane ataki w celu oszukania modelu, które następnie można odtworzyć w działającej sieci.

Teraz częsti czytelnicy tego bloga (lub mieszkańcy kryptoświata) być może już mnie wyprzedzają i myślą: ale poczekaj! Mamy wymyślne dowody wiedzy zerowej i inne naprawdę fajne formy kryptografii. Z pewnością możemy zastosować trochę magii kryptograficznej i ukryć wewnętrzne działanie modelu, aby napastnicy nie mogli zoptymalizować ataków, ale jednocześnie dowód że model jest wykonywany poprawnie i został skonstruowany przy użyciu rozsądnego procesu uczenia na rozsądnym zestawie danych bazowych!
Zwykle tak jest dokładnie jest to sposób myślenia, który propaguję zarówno na tym blogu, jak i w innych moich tekstach. Jednak w przypadku obliczeń związanych ze sztuczną inteligencją istnieją dwa główne zastrzeżenia:
- Narzut kryptograficzny: znacznie mniej efektywne jest zrobienie czegoś wewnątrz SNARK-a (lub MPC lub...) niż zrobienie tego „w przejrzysty sposób”. Biorąc pod uwagę, że sztuczna inteligencja wymaga już bardzo dużej mocy obliczeniowej, czy tworzenie sztucznej inteligencji wewnątrz czarnych skrzynek kryptograficznych jest w ogóle wykonalne obliczeniowo?
- Ataki kontradyktoryjne z wykorzystaniem uczenia maszynowego typu „czarna skrzynka”.: istnieją sposoby optymalizacji ataków na modele AI nawet nie wiedząc zbyt wiele o wewnętrznym funkcjonowaniu modelu. A jeśli się ukryjesz zbyt wiele, ryzykujesz, że osoba wybierająca dane szkoleniowe będzie zbyt łatwa do uszkodzenia modelu zatrucie Ataki.
Obie są skomplikowanymi króliczymi norami, więc przejdźmy do każdego z nich po kolei.
Narzut kryptograficzny
Gadżety kryptograficzne, szczególnie te ogólnego przeznaczenia, takie jak ZK-SNARK i MPC, wiążą się z dużym obciążeniem. Bezpośrednia weryfikacja bloku Ethereum zajmuje klientowi kilkaset milisekund, ale wygenerowanie ZK-SNARK w celu sprawdzenia poprawności takiego bloku może zająć wiele godzin. Typowy narzut innych gadżetów kryptograficznych, takich jak MPC, może być jeszcze większy. Obliczenia AI są już drogie: najpotężniejsze LLM mogą generować pojedyncze słowa tylko trochę szybciej, niż ludzie są w stanie je odczytać, nie wspominając o często wielomilionowych kosztach obliczeniowych trening modele. Różnica w jakości pomiędzy modelami z najwyższej półki a modelami, które starają się zaoszczędzić znacznie więcej koszt szkolenia or liczba parametrów jest wielki. Na pierwszy rzut oka jest to bardzo dobry powód, aby zachować podejrzliwość wobec całego projektu polegającego na próbie dodania gwarancji do sztucznej inteligencji poprzez otulenie jej kryptografią.
Jednak na szczęście Sztuczna inteligencja to: bardzo specyficzny typ obliczeń, co czyni go podatnym na wszelkiego rodzaju optymalizacje z których nie mogą skorzystać bardziej „nieustrukturyzowane” typy obliczeń, takie jak ZK-EVM. Przyjrzyjmy się podstawowej strukturze modelu AI:

y = max(x, 0)). Asymptotycznie, większość pracy zajmują mnożenia macierzy: mnożenie przez dwa N*N matryce zajmuje �(�2.8) czasu, natomiast liczba operacji nieliniowych jest znacznie mniejsza. Jest to naprawdę wygodne w kryptografii, ponieważ wiele form kryptografii może wykonywać operacje liniowe (czym są mnożenia macierzy, przynajmniej jeśli szyfrujesz model, ale nie dane wejściowe do niego) prawie „za darmo”.
Jeśli jesteś kryptografem, prawdopodobnie słyszałeś już o podobnym zjawisku w kontekście szyfrowanie homomorficzne: występ wzbogacenie na zaszyfrowanych tekstach zaszyfrowanych jest naprawdę łatwe, ale mnożenia są niewiarygodnie trudne i aż do 2009 roku nie wymyśliliśmy żadnego sposobu, aby to zrobić z nieograniczoną głębokością.
W przypadku ZK-SNARK odpowiednikiem jest protokoły takie jak ten z 2013 roku, które przedstawiają a mniej niż 4x koszty ogólne udowadniania mnożenia macierzy. Niestety, narzut na warstwy nieliniowe nadal jest znaczny, a najlepsze implementacje w praktyce wykazują narzut około 200x. Istnieje jednak nadzieja, że dzięki dalszym badaniom można to znacznie zmniejszyć; Widzieć ta prezentacja Ryana Cao za najnowsze podejście oparte na GKR i moje własne uproszczone wyjaśnienie działania głównego składnika GKR.
Ale w przypadku wielu zastosowań nie tylko tego chcemy dowód że wynik AI został obliczony poprawnie, my również tego chcemy ukryj model. Istnieją naiwne podejścia do tego: możesz podzielić model tak, aby inny zestaw serwerów nadmiarowo przechowywał każdą warstwę i mieć nadzieję, że niektóre serwery, w przypadku których niektóre warstwy wyciekają, nie wyciekną zbyt dużo danych. Ale są też zaskakująco skuteczne formy specjalistyczne obliczenia wielostronne.
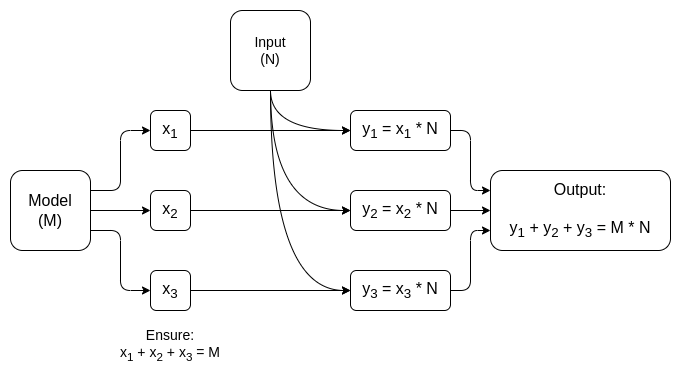
W obu przypadkach morał z tej historii jest taki sam: Największą częścią obliczeń AI są mnożenia macierzy, które można wykonać bardzo wydajny ZK-SNARK lub MPC (lub nawet FHE), więc całkowity narzut związany z umieszczaniem sztucznej inteligencji w skrzynkach kryptograficznych jest zaskakująco niski. Ogólnie rzecz biorąc, to warstwy nieliniowe stanowią największe wąskie gardło pomimo ich mniejszych rozmiarów; być może nowsze techniki, takie jak wyszukaj argumenty może pomóc.
Kontrowersyjne uczenie maszynowe typu „czarna skrzynka”.
Przejdźmy teraz do innego dużego problemu: rodzajów ataków, które możesz przeprowadzić choćby zawartość modelu jest prywatna i masz jedynie „dostęp API” do modelu. Cytując A papier z 2016:
Wiele modeli uczenia maszynowego jest podatnych na przykłady kontradyktoryjne: dane wejściowe są specjalnie spreparowane, aby spowodować, że model uczenia maszynowego wygeneruje nieprawidłowe dane wyjściowe. Przykłady kontradywersyjne, które wpływają na jeden model, często wpływają na inny model, nawet jeśli oba modele mają różną architekturę lub zostały przeszkolone na różnych zestawach szkoleniowych, o ile oba modele zostały przeszkolone do wykonywania tego samego zadania. Osoba atakująca może zatem wyszkolić swój własny model zastępczy, stworzyć kontradyktoryjne przykłady przeciwko substytutowi i przenieść je do modelu ofiary, mając bardzo mało informacji o ofierze.
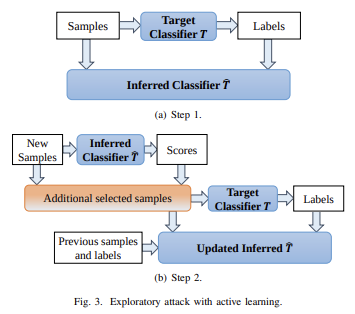
Potencjalnie możesz nawet świadomie tworzyć ataki tylko dane treningowe, nawet jeśli masz bardzo ograniczony dostęp lub nie masz żadnego dostępu do modelu, który próbujesz zaatakować. Od 2023 r. tego rodzaju ataki nadal będą dużym problemem.
Aby skutecznie ograniczyć tego rodzaju ataki czarnej skrzynki, musimy zrobić dwie rzeczy:
- Naprawdę ogranicz, kto lub co może wysyłać zapytania do modelu i jak dużo. Czarne skrzynki z nieograniczonym dostępem do API nie są bezpieczne; mogą być czarne skrzynki z bardzo ograniczonym dostępem do API.
- Ukryj dane treningowe, zachowując pewność czy proces używany do tworzenia danych szkoleniowych nie jest uszkodzony.
Projektem, który zrobił najwięcej w tym pierwszym przypadku, jest prawdopodobnie Worldcoin, którego wcześniejszą wersję (wśród innych protokołów) szczegółowo analizuję tutaj. Worldcoin szeroko wykorzystuje modele sztucznej inteligencji na poziomie protokołu, aby (i) konwertować skany tęczówki na krótkie „kody tęczówki”, które można łatwo porównać pod kątem podobieństwa oraz (ii) weryfikować, czy skanowana przez niego rzecz to w rzeczywistości człowiek. Główną obroną, na której opiera się Worldcoin, jest fakt, że nie pozwala nikomu po prostu wywołać modelu AI: używa raczej zaufanego sprzętu, aby mieć pewność, że model akceptuje tylko dane wejściowe podpisane cyfrowo przez kamerę kuli.
Nie ma gwarancji, że to podejście zadziała: okazuje się, że można przeprowadzać kontradyktoryjne ataki na biometryczną sztuczną inteligencję, które przybierają formę fizyczne plastry lub biżuteria, które można założyć na twarz:

Ale jest nadzieja, że jeśli połącz wszystkie mechanizmy obronne razem, ukrywając sam model sztucznej inteligencji, znacznie ograniczając liczbę zapytań i wymagając, aby każde zapytanie było w jakiś sposób uwierzytelnione, można przeprowadzić ataki kontradyktoryjne na tyle trudne, że system może być bezpieczny.
I to prowadzi nas do drugiej części: jak ukryć dane treningowe? To jest gdzie „DAO w celu demokratycznego zarządzania sztuczną inteligencją” może faktycznie mieć sens: możemy stworzyć on-chain DAO, który reguluje proces tego, kto może przesyłać dane szkoleniowe (i jakie atesty są wymagane dla samych danych), kto może tworzyć zapytania i ile, a także używać technik kryptograficznych, takich jak MPC do szyfrowania całego procesu tworzenia i uruchamiania sztucznej inteligencji, począwszy od danych wejściowych szkoleniowych każdego użytkownika, aż do końcowego wyniku każdego zapytania. Ten DAO mógłby jednocześnie spełniać bardzo popularny cel, jakim jest wynagradzanie osób za przesyłanie danych.
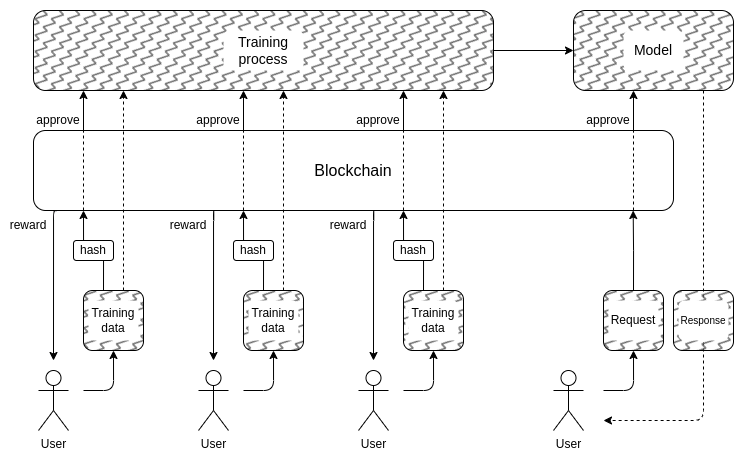
- Narzut kryptograficzny może w dalszym ciągu okazać się zbyt wysoki aby tego rodzaju architektura w pełni czarnej skrzynki była konkurencyjna w stosunku do tradycyjnego, zamkniętego podejścia „zaufaj mi”.
- Może się to okazać nie ma dobrego sposobu na zdecentralizowanie procesu przesyłania danych szkoleniowych i chroniony przed atakami zatruć.
- Wielostronne gadżety obliczeniowe mogą się zepsuć gwarancje bezpieczeństwa lub prywatności z powodu uczestnicy zmowy: w końcu stało się to w przypadku mostów kryptowalutowych typu cross-chain ponownie i ponownie.
Jednym z powodów, dla których nie zacząłem tej sekcji od większej liczby dużych czerwonych etykiet ostrzegawczych z napisem „NIE RÓB SĘDZIÓW AI, TO DYSTOPIA”, jest to, że nasze społeczeństwo jest już w dużym stopniu uzależnione od nieodpowiedzialnych, scentralizowanych sędziów AI: algorytmów, które określają, jakie rodzaje posty i opinie polityczne są w mediach społecznościowych wzmacniane i dementowane, a nawet cenzurowane. Myślę, że warto rozszerzyć ten trend dalej na tym etapie to dość zły pomysł, ale nie sądzę, żeby istniała na to duża szansa społeczność blockchain częściej eksperymentuje ze sztuczną inteligencją będzie tym, co przyczyni się do pogorszenia sytuacji.
W rzeczywistości istnieje kilka prostych, charakteryzujących się niskim ryzykiem sposobów, dzięki którym technologia kryptograficzna może ulepszyć nawet istniejące scentralizowane systemy, co do których jestem całkiem pewien. Jedna prosta technika polega na tym, że zweryfikowana sztuczna inteligencja z opóźnioną publikacją: gdy serwis społecznościowy tworzy ranking postów oparty na sztucznej inteligencji, może opublikować ZK-SNARK potwierdzający skrót modelu, który wygenerował ten ranking. Strona mogłaby zobowiązać się do ujawnienia swoich modeli sztucznej inteligencji po np. roczne opóźnienie. Po ujawnieniu modelu użytkownicy mogą sprawdzić skrót, aby sprawdzić, czy wydano właściwy model, a społeczność może przeprowadzić testy modelu, aby sprawdzić jego rzetelność. Opóźnienie publikacji sprawi, że model w momencie ujawnienia będzie już nieaktualny.
Zatem w porównaniu do scentralizowane świecie, pytanie nie brzmi if możemy zrobić lepiej, ale o ile. Dla zdecentralizowany światjednak należy zachować ostrożność: jeśli ktoś buduje np. rynek prognostyczny lub stablecoin korzystający z wyroczni AI i okazuje się, że wyrocznię można zaatakować, to ogromna ilość pieniędzy, która może zniknąć w jednej chwili.
AI jako cel gry
Jeśli powyższe techniki tworzenia skalowalnej, zdecentralizowanej prywatnej sztucznej inteligencji, której zawartość jest nikomu nie znaną czarną skrzynką, faktycznie mogą zadziałać, to można by je również wykorzystać do stworzenia sztucznej inteligencji o użyteczności wykraczającej poza łańcuchy bloków. Zespół protokołu NEAR sprawia, że jest to a zasadniczy cel ich bieżącej pracy.
Istnieją dwa powody, aby to zrobić:
- Jeśli ty mogą robić "godnych zaufania sztuczną inteligencję czarnej skrzynki”poprzez uruchomienie procesu uczenia i wnioskowania przy użyciu kombinacji łańcuchów bloków i MPC, wówczas wiele aplikacji, w których użytkownicy obawiają się, że system będzie stronniczy lub oszuka ich, może na tym skorzystać. Wiele osób wyraziło chęć demokratyczne rządy AI o znaczeniu systemowym na których będziemy polegać; Techniki kryptograficzne i oparte na blockchainie mogą być ścieżką do osiągnięcia tego celu.
- Z Bezpieczeństwo AI Z perspektywy czasu byłaby to technika tworzenia zdecentralizowanej sztucznej inteligencji, która ma również naturalny wyłącznik awaryjny i która mogłaby ograniczyć zapytania próbujące wykorzystać sztuczną inteligencję do złośliwych zachowań.
Warto również zauważyć, że „wykorzystywanie zachęt kryptograficznych w celu zachęcania do tworzenia lepszej sztucznej inteligencji” można osiągnąć bez wchodzenia w pełną króliczą norę związaną z wykorzystaniem kryptografii do całkowitego zaszyfrowania: podejścia takie jak BitTensor należą do tej kategorii.
wnioski
Teraz, gdy zarówno łańcuchy bloków, jak i sztuczna inteligencja stają się coraz potężniejsze, rośnie liczba przypadków użycia na styku tych dwóch obszarów. Jednak niektóre z tych przypadków użycia mają znacznie większy sens i są znacznie solidniejsze niż inne. Ogólnie rzecz biorąc, przypadki użycia, w których podstawowy mechanizm jest nadal projektowany z grubsza tak jak poprzednio, ale indywidualnie gracze stać się sztuczną inteligencją, umożliwiając mechanizmowi skuteczne działanie w znacznie bardziej mikroskali, są najbardziej obiecujące i najłatwiejsze do wdrożenia.
Najtrudniejsze w realizacji są aplikacje, które próbują wykorzystać łańcuchy bloków i techniki kryptograficzne do stworzenia „singletonu”: pojedynczej zdecentralizowanej, zaufanej sztucznej inteligencji, na której niektóre aplikacje będą w jakimś celu polegać. Aplikacje te są obiecujące zarówno pod względem funkcjonalności, jak i poprawy bezpieczeństwa sztucznej inteligencji w sposób pozwalający uniknąć ryzyka centralizacji związanego z bardziej głównymi podejściami do tego problemu. Istnieje jednak wiele sposobów, w jakie podstawowe założenia mogą zawieść; dlatego warto zachować ostrożność, szczególnie podczas wdrażania tych aplikacji w kontekstach o dużej wartości i wysokim ryzyku.
Nie mogę się doczekać kolejnych prób konstruktywnych przypadków użycia sztucznej inteligencji we wszystkich tych obszarach, abyśmy mogli zobaczyć, które z nich są naprawdę wykonalne na dużą skalę.
Autor: Vitalik Buterin
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: Inteligencja danych Platona.