Poprawa sposobu, w jaki użytkownicy odkrywają nowe treści, ma kluczowe znaczenie dla zwiększenia zaangażowania i zadowolenia użytkowników na platformach medialnych. Samo wyszukiwanie słów kluczowych wiąże się z trudnościami w uchwyceniu semantyki i intencji użytkownika, co prowadzi do wyników pozbawionych odpowiedniego kontekstu. na przykład znalezienie wieczoru randkowego lub filmów o tematyce bożonarodzeniowej. Może to skutkować niższymi wskaźnikami retencji, jeśli użytkownicy nie będą mogli niezawodnie znaleźć potrzebnych treści. Jednak z duże modele językowe (LLM), istnieje możliwość rozwiązania tych wyzwań związanych z semantyką i intencjami użytkownika. Poprzez połączenie osadzenia które przechwytują semantykę za pomocą techniki zwanej Generowanie rozszerzone odzyskiwania (RAG)możesz generować trafniejsze odpowiedzi na podstawie kontekstu pobranego z własnych źródeł danych.
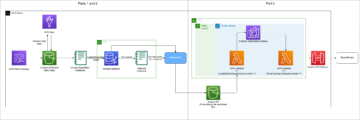
W tym poście pokazujemy, jak bezpiecznie stworzyć chatbota filmowego, wdrażając RAG z wykorzystaniem własnych danych Bazy wiedzy dla Amazońska skała macierzysta. Używamy zestawu danych IMDb i Box Office Mojo do symulacji katalogu dla klientów z branży mediów i rozrywki oraz pokazania, jak w kilku krokach można zbudować własne rozwiązanie RAG.
Omówienie rozwiązania
Połączenia IMDb i Box Office Mojo Movies/TV/OTT licencjonowany pakiet danych zapewnia szeroki zakres metadanych związanych z rozrywką, w tym ponad miliard ocen użytkowników; napisy dla ponad 1.6 milionów członków obsady i ekipy; 13 milionów tytułów filmowych, telewizyjnych i rozrywkowych; oraz globalne raporty kasowe z ponad 10 krajów. Wielu klientów mediów i rozrywki AWS licencjonuje dane IMDb za pośrednictwem Wymiana danych AWS aby usprawnić odkrywanie treści oraz zwiększyć zaangażowanie i utrzymanie klientów.
Wprowadzenie do baz wiedzy dla Amazon Bedrock
Aby wyposażyć LLM w aktualne, zastrzeżone informacje, organizacje korzystają z RAG – techniki polegającej na pobieraniu danych ze źródeł danych firmy i wzbogacaniu podpowiedzi tymi danymi, aby zapewnić bardziej trafne i dokładne odpowiedzi. Bazy wiedzy dla Amazon Bedrock umożliwiają w pełni zarządzaną funkcję RAG, która pozwala dostosowywać odpowiedzi LLM za pomocą kontekstowych i odpowiednich danych firmy. Bazy wiedzy automatyzują kompleksowy przepływ pracy RAG, w tym pozyskiwanie, pobieranie, szybkie rozszerzanie i cytowanie, eliminując potrzebę pisania niestandardowego kodu w celu integracji źródeł danych i zarządzania zapytaniami. Bazy wiedzy dla Amazon Bedrock umożliwiają również wieloetapowe rozmowy, dzięki czemu LLM może odpowiadać na złożone zapytania użytkowników z poprawną odpowiedzią.
W ramach tego rozwiązania korzystamy z następujących usług:
Przechodzimy przez następujące etapy wysokiego poziomu:
- Przetwarzaj wstępnie dane IMDb, aby tworzyć dokumenty z każdego nagrania filmowego i przesyłaj dane do pliku Usługa Amazon Simple Storage Łyżka (Amazon S3).
- Stwórz bazę wiedzy.
- Zsynchronizuj swoją bazę wiedzy ze źródłem danych.
- Skorzystaj z bazy wiedzy, aby odpowiedzieć na pytania semantyczne dotyczące katalogu filmów.
Wymagania wstępne
Dane IMDb użyte w tym poście wymagają licencji na treści komercyjne i płatnej subskrypcji pakietu licencyjnego IMDb i Box Office Mojo Movies/TV/OTT w AWS Data Exchange. Aby zapytać o licencję i uzyskać dostęp do przykładowych danych, odwiedź stronę programista.imdb.com. Aby uzyskać dostęp do zbioru danych, zobacz Rekomendacja mocy i wyszukiwanie za pomocą wykresu wiedzy IMDb – Część 1 i wykonaj Uzyskaj dostęp do danych IMDb
Przetwórz wstępnie dane IMDb
Zanim utworzymy bazę wiedzy, musimy wstępnie przetworzyć zbiór danych IMDb na pliki tekstowe i przesłać je do segmentu S3. W tym poście symulujemy katalog klientów przy użyciu zestawu danych IMDb. Do katalogu bierzemy 10,000 XNUMX popularnych filmów ze zbioru danych IMDb i tworzymy zbiór danych.
Użyj poniższego notatnik aby utworzyć zbiór danych z dodatkowymi informacjami, takimi jak nazwiska aktorów, reżyserów i producentów. Używamy poniższego kodu, aby utworzyć pojedynczy plik filmu ze wszystkimi informacjami przechowywanymi w pliku w postaci nieustrukturyzowanego tekstu, który może być zrozumiały dla LLM:
Po uzyskaniu danych w formacie .txt możesz przesłać je do Amazon S3 za pomocą następującego polecenia:
Utwórz bazę wiedzy IMDb
Wykonaj następujące kroki, aby utworzyć bazę wiedzy:
- Na konsoli Amazon Bedrock wybierz Blog w okienku nawigacji.
- Dodaj Utwórz bazę wiedzy.
- W razie zamówieenia projektu Nazwa bazy wiedzy, wchodzić
imdb. - W razie zamówieenia projektu Opis bazy wiedzy, wprowadź opcjonalny opis, np. Baza wiedzy dotycząca pozyskiwania i przechowywania danych imdb.
- W razie zamówieenia projektu Uprawnienia, Wybierz Utwórz i użyj nowej roli usługi, a następnie wprowadź nazwę nowej roli usługi.
- Dodaj Następna.
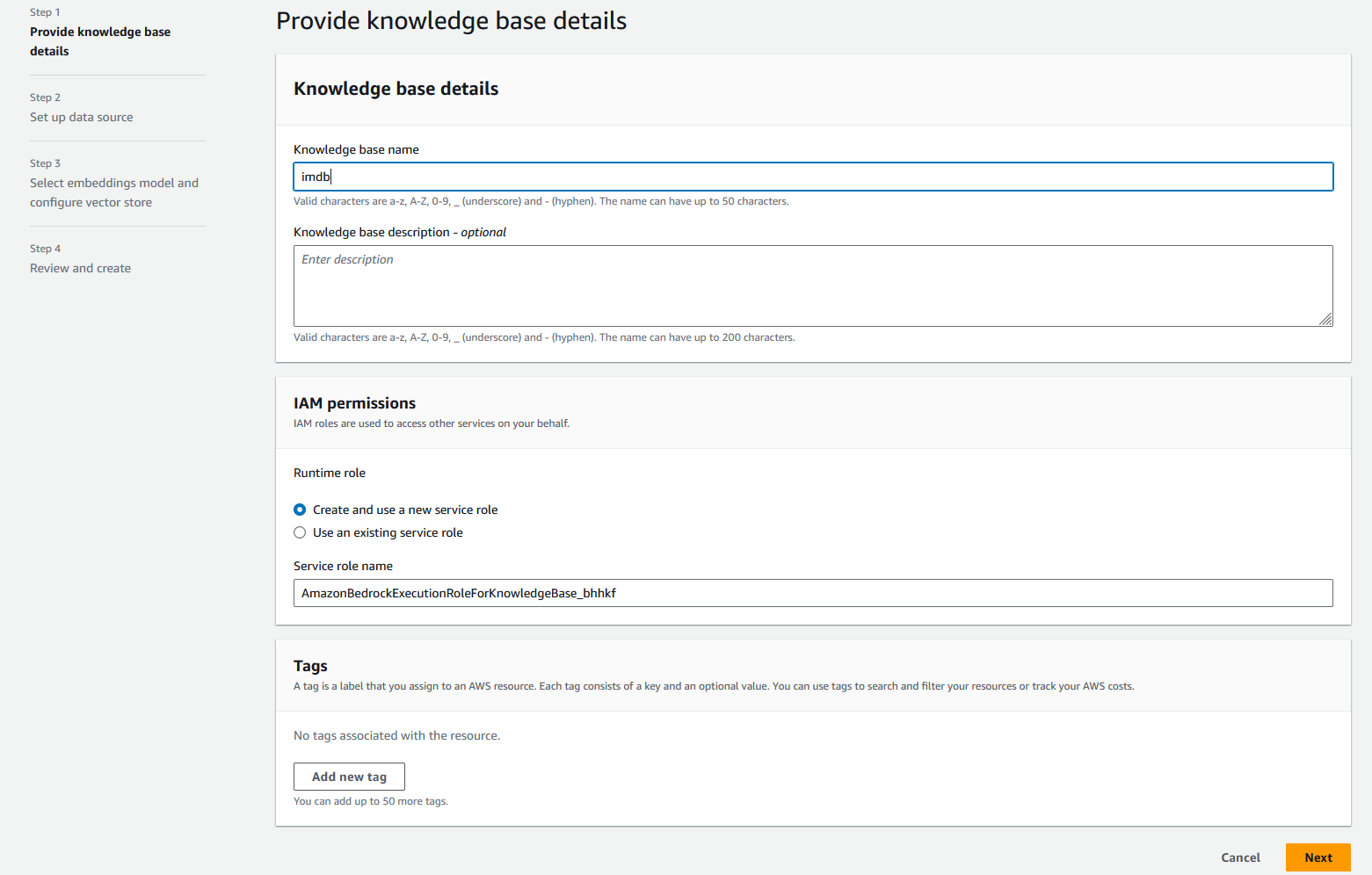
- W razie zamówieenia projektu Nazwa źródła danych, wchodzić
imdb-s3. - W razie zamówieenia projektu Identyfikator URI S3, wprowadź identyfikator URI S3, do którego przesłano dane.
- W Ustawienia zaawansowane – opcjonalne sekcja dla Strategia fragmentowaniawybierz Żadnego fragmentowania.
- Dodaj Następna.
Bazy wiedzy umożliwiają dzielenie dokumentów na mniejsze segmenty, co ułatwia przetwarzanie dużych dokumentów. W naszym przypadku podzieliliśmy już dane na dokument o mniejszym rozmiarze (jeden na film).
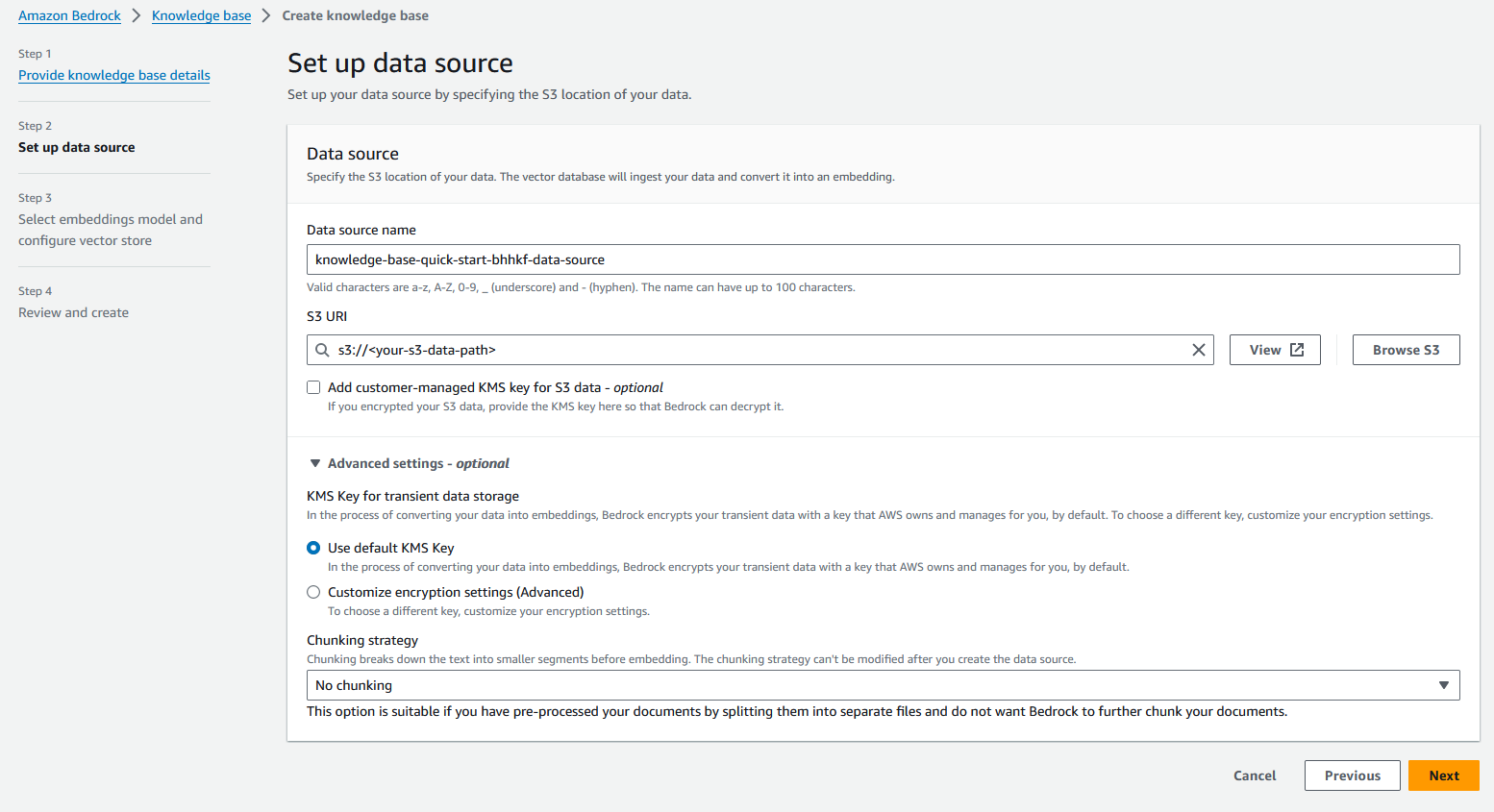
- W Baza danych wektorowych sekcja, wybierz Szybko utwórz nowy sklep wektorowy.
Amazon Bedrock automatycznie utworzy w pełni zarządzaną kolekcję wyszukiwania wektorowego OpenSearch Serverless i skonfiguruje ustawienia osadzania źródeł danych przy użyciu wybranego modelu osadzania tekstu Titan Embedding G1.
- Dodaj Następna.
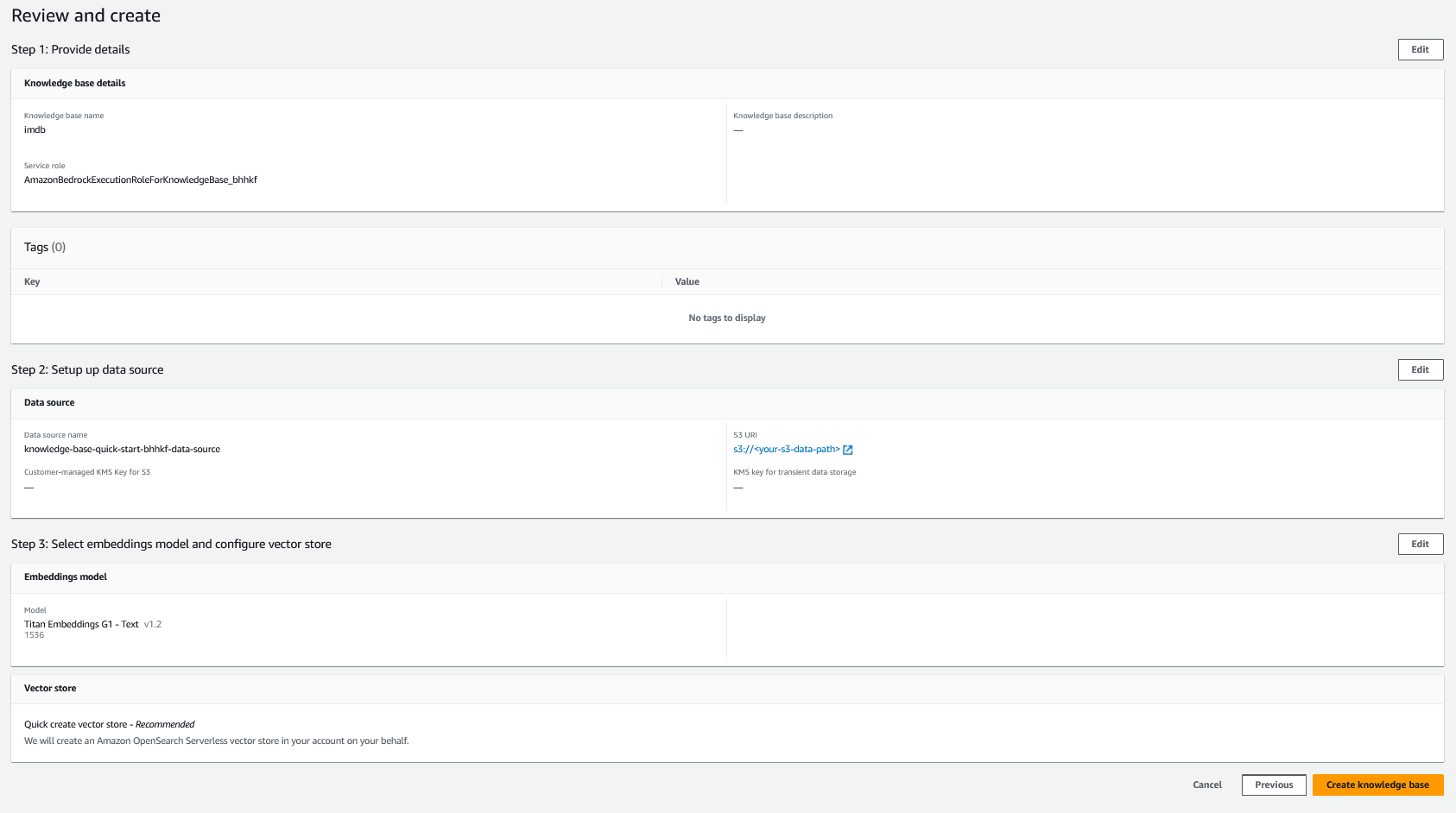
- Przejrzyj swoje ustawienia i wybierz Utwórz bazę wiedzy.
Synchronizuj swoje dane z bazą wiedzy
Po utworzeniu bazy wiedzy możesz zsynchronizować ją ze swoimi danymi.
- Na konsoli Amazon Bedrock przejdź do swojej bazy wiedzy.
- W Źródło danych Sekcja, wybierz Sync.

Po zsynchronizowaniu źródła danych można przystąpić do wysyłania zapytań do danych.
Usprawnij wyszukiwanie, korzystając z wyników semantycznych
Wykonaj następujące kroki, aby przetestować rozwiązanie i usprawnić wyszukiwanie, korzystając z wyników semantycznych:
- Na konsoli Amazon Bedrock przejdź do swojej bazy wiedzy.
- Wybierz swoją bazę wiedzy i wybierz Testowa baza wiedzy.
- Dodaj Wybierz modeli wybierz Antropiczny Claude v2.1.
- Dodaj Aplikuj.
Teraz możesz już wysłać zapytanie do danych.
Możemy zadać pytania semantyczne, np. „Poleccie mi jakieś filmy o tematyce bożonarodzeniowej”.
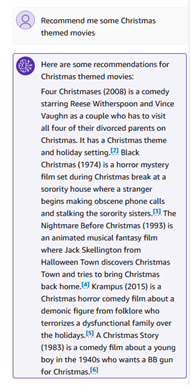
Odpowiedzi z bazy wiedzy zawierają cytaty, które można sprawdzić pod kątem poprawności odpowiedzi i rzeczowości.
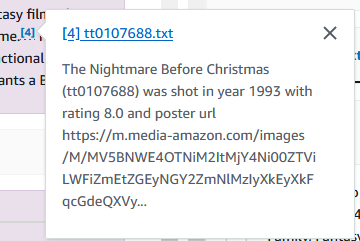
Możesz także drążyć wszelkie potrzebne informacje z tych filmów. W poniższym przykładzie pytamy: „Kto wyreżyserował koszmar przed świętami Bożego Narodzenia?”

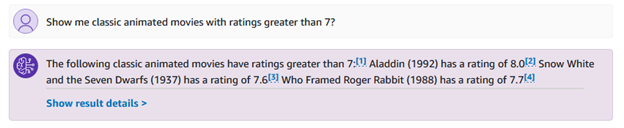
Możesz także zadać bardziej szczegółowe pytania związane z gatunkami i ocenami, np. „pokaż mi klasyczne filmy animowane z oceną wyższą niż 7?”
Poszerzaj swoją bazę wiedzy o agentów
Agenci Amazon Bedrock pomogą Ci zautomatyzować złożone zadania. Agenci mogą podzielić zapytanie użytkownika na mniejsze zadania i wywołać niestandardowe interfejsy API lub bazy wiedzy w celu uzupełnienia informacji na potrzeby bieżących działań. Dzięki Agents for Amazon Bedrock programiści mogą integrować inteligentne agenty ze swoimi aplikacjami, przyspieszając dostarczanie aplikacji opartych na sztucznej inteligencji i oszczędzając tygodnie czasu potrzebnego na programowanie. Dzięki agentom możesz poszerzyć swoją bazę wiedzy, dodając więcej funkcji, takich jak rekomendacje z Amazon Personalizuj w celu uzyskania rekomendacji specyficznych dla użytkownika lub wykonywania działań, takich jak filtrowanie filmów na podstawie potrzeb użytkownika.
Wnioski
W tym poście pokazaliśmy, jak w kilku krokach zbudować konwersacyjnego chatbota filmowego przy użyciu Amazon Bedrock, aby odpowiedzieć na potrzeby wyszukiwania semantycznego i konwersacji w oparciu o własne dane oraz licencjonowany zbiór danych IMDb i Box Office Mojo Movies/TV/OTT. W następnym poście przejdziemy przez proces dodawania większej funkcjonalności do Twojego rozwiązania za pomocą Agentów dla Amazon Bedrock. Aby rozpocząć korzystanie z baz wiedzy na temat Amazon Bedrock, zobacz Bazy wiedzy na temat Amazon Bedrock.
O autorach
 Gaurav Rele jest starszym analitykiem danych w Centrum Innowacji Generative AI, gdzie współpracuje z klientami AWS z różnych branż, aby przyspieszyć ich wykorzystanie generatywnej sztucznej inteligencji i usług AWS Cloud w celu rozwiązywania ich wyzwań biznesowych.
Gaurav Rele jest starszym analitykiem danych w Centrum Innowacji Generative AI, gdzie współpracuje z klientami AWS z różnych branż, aby przyspieszyć ich wykorzystanie generatywnej sztucznej inteligencji i usług AWS Cloud w celu rozwiązywania ich wyzwań biznesowych.
 Divya Bhargawi jest starszym specjalistą ds. nauki stosowanej w Centrum Innowacji Generative AI, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS przy użyciu metod generatywnej AI. Pracuje nad zrozumieniem i wyszukiwaniem obrazów/wideo, grafami wiedzy rozszerzonymi o duże modele językowe i przypadkami użycia reklam spersonalizowanych.
Divya Bhargawi jest starszym specjalistą ds. nauki stosowanej w Centrum Innowacji Generative AI, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS przy użyciu metod generatywnej AI. Pracuje nad zrozumieniem i wyszukiwaniem obrazów/wideo, grafami wiedzy rozszerzonymi o duże modele językowe i przypadkami użycia reklam spersonalizowanych.
 Surena Gunturu jest Data Scientistem pracującym w Centrum Innowacji Generative AI, gdzie współpracuje z różnymi klientami AWS w celu rozwiązywania problemów biznesowych o dużej wartości. Specjalizuje się w budowaniu potoków ML z wykorzystaniem modeli wielkojęzykowych, głównie poprzez Amazon Bedrock i inne usługi AWS Cloud.
Surena Gunturu jest Data Scientistem pracującym w Centrum Innowacji Generative AI, gdzie współpracuje z różnymi klientami AWS w celu rozwiązywania problemów biznesowych o dużej wartości. Specjalizuje się w budowaniu potoków ML z wykorzystaniem modeli wielkojęzykowych, głównie poprzez Amazon Bedrock i inne usługi AWS Cloud.
 Widja Sagar Rawipati jest kierownikiem ds. nauki w Centrum Innowacji Generative AI, gdzie wykorzystuje swoje rozległe doświadczenie w zakresie wielkoskalowych systemów rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż w przyspieszeniu wdrażania sztucznej inteligencji i chmury.
Widja Sagar Rawipati jest kierownikiem ds. nauki w Centrum Innowacji Generative AI, gdzie wykorzystuje swoje rozległe doświadczenie w zakresie wielkoskalowych systemów rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż w przyspieszeniu wdrażania sztucznej inteligencji i chmury.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- :ma
- :Jest
- :Gdzie
- $ 10 mln
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- O nas
- przyśpieszyć
- przyspieszenie
- dostęp
- dokładny
- w poprzek
- działania
- aktorzy
- dodanie
- Dodatkowy
- Przyjęcie
- Reklama
- agentów
- AI
- Zasilany AI
- Wszystkie kategorie
- pozwala
- sam
- już
- również
- Amazonka
- Amazon Web Services
- an
- i
- odpowiedź
- odpowiedzi
- każdy
- Pszczoła
- aplikacje
- stosowany
- mobilne i webowe
- SĄ
- AS
- zapytać
- At
- zwiększać
- zwiększona
- zautomatyzować
- automatycznie
- AWS
- baza
- na podstawie
- BE
- zanim
- Miliard
- Pudełko
- box office
- przerwa
- budować
- Budowanie
- biznes
- by
- wezwanie
- nazywa
- CAN
- zdolność
- zdobyć
- Przechwytywanie
- walizka
- Etui
- katalog
- Centrum
- wyzwania
- chatbot
- Dodaj
- wybrany
- Boże Narodzenie
- klasyczny
- Chmura
- adopcja chmury
- usługi w chmurze
- kod
- kolekcja
- łączenie
- handlowy
- sukcesy firma
- kompleks
- Konsola
- zawierać
- zawartość
- kontekst
- kontekstowy
- konwersacyjny
- rozmowy
- skorygowania
- kraje
- Para
- Stwórz
- stworzony
- Kredyty
- załoga
- krytyczny
- zwyczaj
- klient
- Zaangażowanie klienta
- Klientów
- dostosować
- dane
- Wymiana danych
- naukowiec danych
- Data
- dostarczyć
- dostawa
- opis
- detale
- deweloperzy
- oprogramowania
- różne
- skierowany
- Dyrektor
- Dyrektorzy
- odkryj
- odkrycie
- dystrybuowane
- systemy rozproszone
- dokument
- dokumenty
- na dół
- napęd
- eliminując
- osadzanie
- umożliwiać
- koniec końców
- zaręczynowy
- wzbogacanie
- Wchodzę
- rozrywka
- Eter (ETH)
- Każdy
- przykład
- wymiana
- doświadczenie
- Doświadczenia
- odkryj
- kilka
- filet
- Akta
- filtracja
- Znajdź
- znalezieniu
- obserwuj
- następujący
- W razie zamówieenia projektu
- format
- od
- w pełni
- Funkcjonalność
- g1
- Generować
- generacja
- generatywny
- generatywna sztuczna inteligencja
- gatunki
- otrzymać
- Globalne
- Go
- wykres
- większy
- Have
- he
- pomoc
- na wysokim szczeblu
- jego
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- if
- wykonawczych
- podnieść
- in
- Włącznie z
- Zwiększać
- przemysł
- Informacje
- Informacja
- Innowacja
- dowiadywać się
- integrować
- Inteligentny
- zamiar
- najnowszych
- dotyczy
- IT
- jpg
- właśnie
- wiedza
- Brak
- język
- duży
- na dużą skalę
- prowadzić
- prowadzący
- nauka
- wykorzystuje
- Licencja
- Upoważniony
- Koncesjonowanie
- lubić
- llm
- miejscowy
- lokalizacja
- niższy
- maszyna
- uczenie maszynowe
- robić
- zarządzanie
- zarządzane
- kierownik
- wiele
- me
- Media
- Użytkownicy
- Metadane
- metody
- milion
- ML
- model
- modele
- mojo
- jeszcze
- film
- Kino
- Nazwa
- Nazwy
- Nawigacja
- Nawigacja
- Potrzebować
- wymagania
- Nowości
- Następny
- noc
- of
- Biurowe
- on
- ONE
- Okazja
- or
- organizacji
- Inne
- ludzkiej,
- koniec
- własny
- pakiet
- strona
- płatny
- chleb
- część
- pasja
- ścieżka
- dla
- wykonywania
- Personalizowany
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- działka
- Popularny
- Post
- plakat
- głównie
- problemy
- wygląda tak
- producent
- Producenci
- własność
- zapewnia
- zapytania
- pytanie
- pytania
- szmata
- zasięg
- ceny
- ocena
- Oceny
- gotowy
- polecić
- Rekomendacja
- zalecenia
- rekord
- odnosić się
- związane z
- Raportowanie
- Wymaga
- odpowiedź
- Odpowiedzi
- Efekt
- retencja
- wyszukiwanie
- powrót
- Rola
- RZĄD
- bieganie
- klientów
- oszczędność
- nauka
- Naukowiec
- Szukaj
- Sekcja
- bezpiecznie
- Segmenty
- wybierać
- semantyczny
- semantyka
- senior
- Bezserwerowe
- usługa
- Usługi
- w panelu ustawień
- ona
- strzał
- pokazać
- prezentacja
- pokazał
- Prosty
- symulować
- pojedynczy
- Rozmiar
- mniejszy
- So
- rozwiązanie
- ROZWIĄZANIA
- Rozwiązuje
- kilka
- Źródło
- Źródła
- specjalizuje się
- specyficzny
- rozpoczęty
- Cel
- przechowywanie
- sklep
- przechowywany
- bezpośredni
- subskrypcja
- taki
- uzupełnienie
- synchronizacja
- systemy
- Brać
- zadania
- technika
- test
- XNUMX
- niż
- że
- Połączenia
- Informacje
- ich
- Im
- Tematyczne
- następnie
- Tam.
- Te
- one
- to
- Przez
- czas
- tytan
- tytuły
- do
- tv
- zrozumienie
- zrozumiany
- nieuporządkowany
- nowomodny
- przesłanych
- URI
- URL
- posługiwać się
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- różnorodny
- Naprawiono
- pionowe
- Odwiedzić
- W
- spacer
- chcieć
- była
- we
- sieć
- usługi internetowe
- tygodni
- szeroki
- Szeroki zasięg
- będzie
- w
- workflow
- pracujący
- działa
- napisać
- X
- rok
- ty
- Twój
- zefirnet