Amazonka Przesunięcie ku czerwieni to szybki, w pełni zarządzany magazyn danych w chmurze o skali petabajtów, który ułatwia i opłaca analizę wszystkich danych przy użyciu standardowego języka SQL i istniejących narzędzi Business Intelligence (BI). Dziesiątki tysięcy klientów korzysta dziś z usługi Amazon Redshift do analizowania eksabajtów danych i wykonywania zapytań analitycznych, co czyni ją najpowszechniej używaną hurtownią danych w chmurze. Usługa Amazon Redshift jest dostępna zarówno w konfiguracji bezserwerowej, jak i z obsługą administracyjną.
Amazon Redshift umożliwia bezpośredni dostęp do danych przechowywanych w Usługa Amazon Simple Storage (Amazon S3) za pomocą zapytań SQL i łączenia danych w hurtowni danych i jeziorze danych. Dzięki Amazon Redshift możesz wysyłać zapytania do danych w jeziorze danych S3 za pomocą centrum centralnego Klej AWS metastore z hurtowni danych Redshift.
Amazon Redshift obsługuje zapytania w wielu różnych formatach danych, takich jak CSV, JSON, Parquet i ORC, a także w formatach tabel, takich jak Apache Hudi i Delta. Amazon Redshift obsługuje również zapytania dotyczące danych zagnieżdżonych ze złożonymi typami danych, takimi jak struktura, tablica i mapa.
Dzięki tej możliwości Amazon Redshift w opłacalny sposób rozszerza hurtownię danych o skali petabajtów do jeziora danych o skali eksabajtów na platformie Amazon S3.
Apache Iceberg to najnowszy format tabeli obsługiwany teraz w wersji zapoznawczej przez Amazon Redshift. W tym poście pokażemy, jak wysyłać zapytania do tabel Iceberg za pomocą usługi Amazon Redshift oraz poznać obsługę i opcje Iceberg.
Omówienie rozwiązania
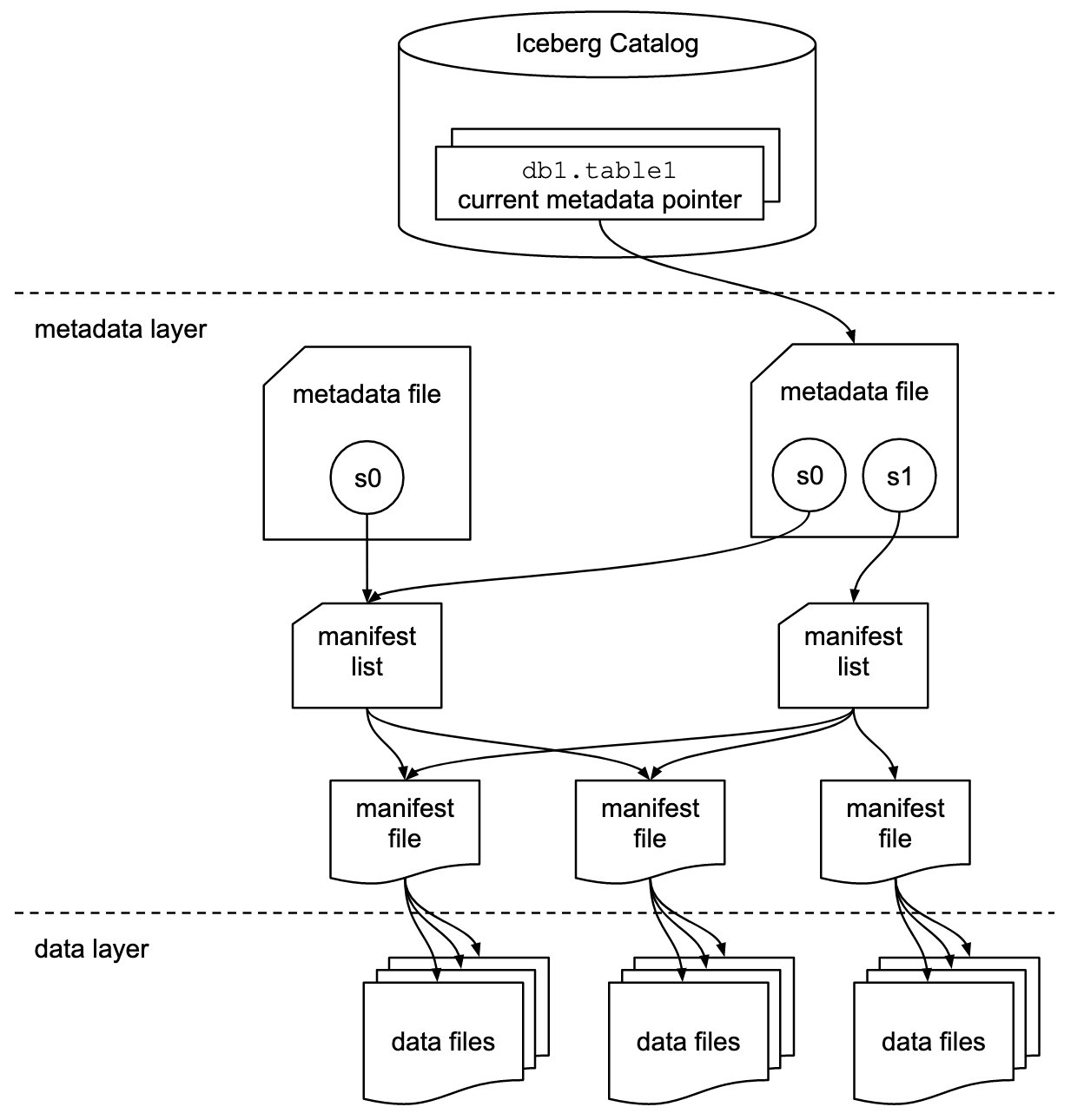
Góra lodowa Apache to format otwartej tabeli dla bardzo dużych analitycznych zbiorów danych w skali petabajtów. Iceberg zarządza dużymi zbiorami plików w postaci tabel i obsługuje nowoczesne analityczne operacje na jeziorach danych, takie jak wstawianie, aktualizacja, usuwanie i zapytania dotyczące podróży w czasie na poziomie rekordu. Specyfikacja Iceberg umożliwia płynną ewolucję tabeli, taką jak ewolucja schematu i partycji, a jej projekt jest zoptymalizowany do użytku na Amazon S3.
Iceberg przechowuje wskaźnik metadanych dla wszystkich plików metadanych. Kiedy zapytanie SELECT odczytuje tabelę Iceberg, silnik zapytań najpierw przechodzi do katalogu Iceberg, a następnie pobiera wpis lokalizacji najnowszego pliku metadanych, jak pokazano na poniższym diagramie.
Amazon Redshift zapewnia teraz obsługę tabel Apache Iceberg, co umożliwia klientom Data Lake uruchamianie zapytań analitycznych tylko do odczytu w sposób spójny transakcyjnie. Umożliwia to łatwe zarządzanie tabelami w jeziorach danych transakcyjnych i utrzymywanie ich.
Amazon Redshift obsługuje natywne możliwości schematu i ewolucji partycji Apache Iceberg za pomocą Katalog danych kleju AWSeliminując potrzebę zmiany definicji tabel w celu dodania nowych partycji lub przenoszenia i przetwarzania dużych ilości danych w celu zmiany schematu istniejącej tabeli Data Lake. Amazon Redshift wykorzystuje statystyki kolumn przechowywane w metadanych tabeli Apache Iceberg w celu optymalizacji planów zapytań i ograniczenia skanowania plików wymaganych do uruchamiania zapytań.
W tym poście używamy Publiczny zbiór danych dotyczących żółtych taksówek z Komisji ds. taksówek i limuzyn Nowego Jorku jako nasze dane źródłowe. Zbiór danych zawiera pliki danych w Parkiet Apache sformatować na Amazon S3. Używamy Amazonka Atena aby przekonwertować ten zestaw danych Parquet, a następnie użyć Widmo przesunięcia ku czerwieni Amazonki do wykonywania zapytań i przyłączania się do lokalnej tabeli Redshift, wykonywania usuwania i aktualizacji na poziomie wierszy oraz ewolucji partycji, wszystko koordynowane przez katalog danych kleju AWS w jeziorze danych S3.
Wymagania wstępne
Powinieneś mieć następujące wymagania wstępne:
Konwertuj dane Parquet na tabelę Iceberg
Do tego postu potrzebujesz Publiczny zbiór danych dotyczących żółtych taksówek uzyskany od Komisji ds. taksówek i limuzyn Nowego Jorku dostępny w formacie góry lodowej. Możesz pobrać pliki, a następnie użyć narzędzia Athena do przekonwertowania zestawu danych Parquet na tabelę Iceberg lub zapoznać się z Zbuduj jezioro danych Apache Iceberg za pomocą Amazon Athena, Amazon EMR i AWS Glue post na blogu dotyczący tworzenia stołu lodowego.
W tym poście używamy Atheny do konwersji danych. Wykonaj następujące kroki:
- Pobierz pliki korzystając z poprzedniego linku lub skorzystaj z Interfejs wiersza poleceń AWS (AWS CLI), aby skopiować pliki z publicznego zasobnika S3 na lata 2020 i 2021 do zasobnika S3 za pomocą następującego polecenia:
Aby uzyskać więcej informacji, zobacz Konfigurowanie interfejsu CLI Amazon Redshift.
- Utwórz bazę danych
Icebergdbi utwórz tabelę, używając Ateny, wskazując pliki w formacie Parquet, używając następującej instrukcji: - Sprawdź poprawność danych w tabeli Parquet, używając następującego kodu SQL:

- Utwórz tabelę Iceberg w Athenie za pomocą następującego kodu. Poniżej możesz zobaczyć właściwości typu tabeli w postaci tabeli Iceberg w formacie Parquet i szybkiej kompresji
create tableoświadczenie. Przed uruchomieniem SQL należy zaktualizować lokalizację S3. Należy również pamiętać, że tabela Iceberg jest podzielona na partycjeYearklawisz. - Po utworzeniu tabeli załaduj dane do tabeli Iceberg, korzystając z wcześniej załadowanej tabeli Parquet
nyc_taxi_yellow_parquetz następującym kodem SQL: - Po zakończeniu instrukcji SQL sprawdź poprawność danych w tabeli Iceberg
nyc_taxi_yellow_iceberg. Ten krok jest wymagany przed przejściem do następnego kroku. - Możesz sprawdzić, czy tabela nyc_taxi_yellow_iceberg jest w formacie tabeli Iceberg i jest podzielona na partycje w kolumnie Rok, używając następującego polecenia:



Utwórz zewnętrzny schemat w Amazon Redshift
W tej sekcji pokazujemy, jak utworzyć zewnętrzny schemat w Amazon Redshift wskazujący na bazę danych AWS Glue icebergdb aby wysłać zapytanie do tabeli Iceberg nyc_taxi_yellow_iceberg które widzieliśmy w poprzedniej sekcji przy użyciu Ateny.
Zaloguj się do Redshift poprzez Edytor zapytań v2 lub klienta SQL i uruchom następujące polecenie (zwróć uwagę, że plik bazy danych AWS Glue icebergdb i informacje o regionie są używane):

Aby dowiedzieć się więcej o tworzeniu schematów zewnętrznych w Amazon Redshift, zob utwórz schemat zewnętrzny
Po utworzeniu schematu zewnętrznego spectrum_iceberg_schema, możesz wysłać zapytanie do tabeli Iceberg w Amazon Redshift.
Zapytanie o tabelę Iceberg w Amazon Redshift
Uruchom następujące zapytanie w Edytorze zapytań w wersji 2. Zauważ to spectrum_iceberg_schema to nazwa schematu zewnętrznego utworzonego w Amazon Redshift i nyc_taxi_yellow_iceberg to tabela w bazie danych AWS Glue użyta w zapytaniu:
Dane wyjściowe zapytania na poniższym zrzucie ekranu pokazują, że do tabeli AWS Glue w formacie Iceberg można wysyłać zapytania przy użyciu Redshift Spectrum.

Sprawdź plan wyjaśnienia zapytania do tabeli Iceberg
Możesz użyć poniższego zapytania, aby uzyskać wynik planu wyjaśniania, który pokazuje, że format to ICEBERG:

Sprawdź aktualizacje pod kątem spójności danych
Po zakończeniu aktualizacji tabeli Iceberg możesz wysłać zapytanie do Amazon Redshift, aby zobaczyć spójny transakcyjnie widok danych. Uruchommy zapytanie, wybierając a vendorid oraz dla określonego odbioru i transportu:

Następnie zaktualizuj wartość passenger_count do 4 i trip_distance do 9.4 za ok vendorid oraz niektóre daty odbioru i zwrotu w Atenie:

Na koniec uruchom następujące zapytanie w Edytorze zapytań w wersji 2, aby zobaczyć zaktualizowaną wartość passenger_count i trip_distance:
Jak pokazano na poniższym zrzucie ekranu, operacje aktualizacji na stole Iceberg są dostępne w Amazon Redshift.

Utwórz ujednolicony widok tabeli lokalnej i danych historycznych w Amazon Redshift
W ramach nowoczesnej strategii architektury danych można organizować dane historyczne lub rzadziej używane dane w jeziorze danych i przechowywać często używane dane w hurtowni danych Redshift. Zapewnia to elastyczność zarządzania analityką na dużą skalę i znajdowania najbardziej opłacalnego rozwiązania architektonicznego.
W tym przykładzie ładujemy dane z 2 lat do tabeli przesunięcia ku czerwieni; reszta danych pozostaje w jeziorze danych S3, ponieważ zapytania dotyczące tego zestawu danych są rzadsze.
- Użyj poniższego kodu, aby załadować dane z 2 lat do pliku
nyc_taxi_yellow_recenttabela w Amazon Redshift, pochodząc z tabeli Iceberg:
- Następnie możesz usunąć dane z tabeli Iceberg z ostatnich 2 lat, używając następującego polecenia w Athenie, ponieważ dane zostały załadowane do tabeli przesunięcia ku czerwieni w poprzednim kroku:

Po wykonaniu tych kroków tabela Redshift zawiera dane z 2 lat, a reszta danych znajduje się w tabeli Iceberg w Amazon S3.
- Utwórz widok za pomocą
nyc_taxi_yellow_icebergStół lodowy inyc_taxi_yellow_recenttabela w Amazon Redshift: - Teraz wykonaj zapytanie do widoku, w zależności od warunków filtra, Redshift Spectrum przeskanuje dane Iceberg, tabelę Redshift lub oba. Poniższe przykładowe zapytanie zwraca liczbę rekordów z każdej tabeli źródłowej poprzez skanowanie obu tabel:

Ewolucja partycji
Góra lodowa wykorzystuje ukryte partycjonowanie, co oznacza, że nie musisz ręcznie dodawać partycji do tabel Apache Iceberg. Nowe wartości partycji lub nowe specyfikacje partycji (dodaj lub usuń kolumny partycji) w tabelach Apache Iceberg są automatycznie wykrywane przez Amazon Redshift i nie jest wymagana żadna ręczna operacja, aby zaktualizować partycje w definicji tabeli. Poniższy przykład to demonstruje.
W naszym przykładzie, jeśli stół Iceberg nyc_taxi_yellow_iceberg pierwotnie był podzielony według roku, a później według kolumny vendorid została dodana jako dodatkowa kolumna partycji, wówczas Amazon Redshift może bezproblemowo wysyłać zapytania do tabeli Iceberg nyc_taxi_yellow_iceberg z dwoma różnymi schematami partycji w pewnym okresie czasu.

Uwagi dotyczące wykonywania zapytań do tabel Iceberg za pomocą usługi Amazon Redshift
W okresie podglądu podczas korzystania z Amazon Redshift ze stołami Iceberg należy wziąć pod uwagę następujące kwestie:
- Obsługiwane są tylko tabele Iceberg zdefiniowane w katalogu danych kleju AWS.
- Polecenia tabeli zewnętrznej CREATE lub ALTER nie są obsługiwane, co oznacza, że tabela Iceberg powinna już istnieć w bazie danych AWS Glue.
- Zapytania dotyczące podróży w czasie nie są obsługiwane.
- Obsługiwane są wersje Iceberg 1 i 2. Aby uzyskać więcej informacji na temat wersji w formacie Iceberg, zobacz Wersjonowanie formatu.
- Aby zapoznać się z listą obsługiwanych typów danych w tabelach Iceberg, zobacz Obsługiwane typy danych w tabelach Apache Iceberg (wersja zapoznawcza).
- Ceny za wysyłanie zapytań do tabeli Iceberg są takie same, jak za dostęp do innych formatów danych za pomocą usługi Amazon Redshift.
Dodatkowe szczegóły dotyczące podglądu tabel w formacie Iceberg można znaleźć w artykule Korzystanie z tabel Apache Iceberg z usługą Amazon Redshift (wersja zapoznawcza).
Opinie klientów
„Tinuiti, największa niezależna firma zajmująca się marketingiem wydajnościowym, codziennie przetwarza duże ilości danych i musi mieć solidną strategię dotyczącą jeziora danych i hurtowni danych, aby nasze zespoły analityki rynkowej mogły przechowywać i analizować wszystkie dane naszych klientów w łatwy, niedrogi i bezpieczny sposób i solidny sposób” – mówi Justin Manus, dyrektor ds. technologii w Tinuiti. „Wsparcie Amazon Redshift dla tabel Apache Iceberg w naszym jeziorze danych, które jest jedynym źródłem prawdy, rozwiązuje kluczowe wyzwanie związane z optymalizacją wydajności i dostępności oraz jeszcze bardziej upraszcza nasze procesy integracji danych, aby uzyskać dostęp do wszystkich danych pozyskiwanych z różnych źródeł i zasilać nasze potencjał marki klientów.”
Wnioski
W tym poście pokazaliśmy przykład zapytania do tabeli Iceberg w Redshift przy użyciu plików przechowywanych w Amazon S3, skatalogowanych jako tabela w katalogu danych kleju AWS i zademonstrowaliśmy niektóre kluczowe funkcje, takie jak wydajna aktualizacja i usuwanie na poziomie wierszy, oraz możliwość ewolucji schematu dla użytkowników, aby uwolnić możliwości dużych zbiorów danych za pomocą technologii Athena.
Możesz używać Amazon Redshift do uruchamiania zapytań w tabelach Data Lake w różnych plikach i formatach tabel, takich jak Apache Hudi i Jezioro Delta, a teraz z Apache Iceberg (podgląd), który zapewnia dodatkowe opcje spełniające potrzeby nowoczesnych architektur danych.
Mamy nadzieję, że stanowi to doskonały punkt wyjścia do wysyłania zapytań do tabel Iceberg w serwisie Amazon Redshift.
O autorach
 Rohita Bansala jest Architektem Rozwiązań Specjalistycznych ds. Analityki w AWS. Specjalizuje się w Amazon Redshift i współpracuje z klientami przy tworzeniu rozwiązań analitycznych nowej generacji przy użyciu innych usług AWS Analytics.
Rohita Bansala jest Architektem Rozwiązań Specjalistycznych ds. Analityki w AWS. Specjalizuje się w Amazon Redshift i współpracuje z klientami przy tworzeniu rozwiązań analitycznych nowej generacji przy użyciu innych usług AWS Analytics.
 Satish Sathiya jest starszym inżynierem produktu w Amazon Redshift. Jest zapalonym entuzjastą big data, który współpracuje z klientami na całym świecie, aby osiągnąć sukces i zaspokoić ich potrzeby w zakresie hurtowni danych i architektury jeziora danych.
Satish Sathiya jest starszym inżynierem produktu w Amazon Redshift. Jest zapalonym entuzjastą big data, który współpracuje z klientami na całym świecie, aby osiągnąć sukces i zaspokoić ich potrzeby w zakresie hurtowni danych i architektury jeziora danych.
 Ranjana Burmana jest Architektem Rozwiązań Specjalistycznych ds. Analityki w AWS. Specjalizuje się w Amazon Redshift i pomaga klientom budować skalowalne rozwiązania analityczne. Posiada ponad 16-letnie doświadczenie w różnych technologiach baz danych i hurtowni danych. Pasjonuje się automatyzacją i rozwiązywaniem problemów klientów za pomocą rozwiązań chmurowych.
Ranjana Burmana jest Architektem Rozwiązań Specjalistycznych ds. Analityki w AWS. Specjalizuje się w Amazon Redshift i pomaga klientom budować skalowalne rozwiązania analityczne. Posiada ponad 16-letnie doświadczenie w różnych technologiach baz danych i hurtowni danych. Pasjonuje się automatyzacją i rozwiązywaniem problemów klientów za pomocą rozwiązań chmurowych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- ChartPrime. Podnieś poziom swojej gry handlowej dzięki ChartPrime. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- O nas
- dostęp
- dostęp
- dostępność
- Dostęp
- Osiągać
- w poprzek
- Dodaj
- w dodatku
- Dodatkowy
- Adresy
- przystępne
- Wszystkie kategorie
- pozwala
- już
- również
- Amazonka
- Amazonka Atena
- Amazon EMR
- Amazon Web Services
- kwoty
- an
- Analityczny
- Analityczny
- analityka
- w czasie rzeczywistym sprawiają,
- i
- każdy
- Apache
- architektura
- SĄ
- na około
- Szyk
- AS
- At
- automatycznie
- automatyzacja
- dostępny
- AWS
- Klej AWS
- podstawa
- bo
- zanim
- jest
- Duży
- Big Data
- wiążący
- Blog
- obie
- marka
- budować
- biznes
- business intelligence
- by
- CAN
- możliwości
- zdolność
- katalog
- centralny
- pewien
- wyzwanie
- zmiana
- szef
- Chief Technology Officer
- klient
- Chmura
- kod
- kolekcje
- Kolumna
- kolumny
- kompletny
- kompleks
- Warunki
- Rozważać
- Rozważania
- zgodny
- zawiera
- konwertować
- skoordynowane
- opłacalne
- Stwórz
- stworzony
- Tworzenie
- krytyczny
- klient
- dane klienta
- Klientów
- codziennie
- dane
- integracja danych
- Jezioro danych
- hurtownia danych
- Baza danych
- zbiory danych
- Daty
- Domyślnie
- zdefiniowane
- definicja
- definicje
- Delta
- wykazać
- wykazać
- demonstruje
- W zależności
- Wnętrze
- detale
- wykryte
- dev
- różne
- bezpośrednio
- nie
- Podwójna
- pobieranie
- każdy
- z łatwością
- łatwo
- redaktor
- wydajny
- bądź
- eliminując
- Umożliwia
- silnik
- inżynier
- entuzjasta
- wejście
- Eter (ETH)
- ewolucja
- przykład
- istnieć
- Przede wszystkim system został opracowany
- doświadczenie
- Wyjaśniać
- odkryj
- rozciąga się
- zewnętrzny
- dodatkowy
- FAST
- Korzyści
- filet
- Akta
- filtrować
- Znajdź
- Firma
- i terminów, a
- Elastyczność
- następujący
- W razie zamówieenia projektu
- format
- często
- od
- w pełni
- dalej
- otrzymać
- daje
- globus
- Goes
- wspaniały
- Zarządzanie
- Uchwyty
- Have
- he
- pomaga
- historyczny
- nadzieję
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- if
- in
- niezależny
- Informacja
- integracja
- Inteligencja
- najnowszych
- IT
- JEGO
- przystąpić
- jpg
- json
- Justin
- Trzymać
- Klawisz
- jezioro
- duży
- największym
- Nazwisko
- później
- firmy
- UCZYĆ SIĘ
- mniej
- lubić
- LIMIT
- Linia
- LINK
- Lista
- załadować
- miejscowy
- lokalizacja
- utrzymać
- WYKONUJE
- Dokonywanie
- zarządzanie
- zarządzane
- zarządza
- sposób
- podręcznik
- ręcznie
- mapa
- rynek
- Marketing
- znaczy
- Poznaj nasz
- Metadane
- Nowoczesne technologie
- jeszcze
- większość
- ruch
- przeniesienie
- musi
- Nazwa
- rodzimy
- Potrzebować
- potrzebne
- wymagania
- Nowości
- Następny
- następna generacja
- Nie
- noty
- już dziś
- numer
- NYC
- of
- Oficer
- on
- koncepcja
- działanie
- operacje
- Optymalizacja
- zoptymalizowane
- optymalizacji
- Opcje
- or
- pierwotnie
- Inne
- ludzkiej,
- wydajność
- koniec
- strona
- namiętny
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- okres
- krok po kroku
- plany
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- Post
- potencjał
- power
- warunki wstępne
- Podgląd
- poprzedni
- poprzednio
- problemy
- wygląda tak
- Produkt
- niska zabudowa
- zapewnia
- publiczny
- zapytania
- Czytający
- dokumentacja
- zmniejszyć
- region
- usunąć
- obsługi produkcji rolnej, która zastąpiła
- wymagany
- REST
- powraca
- krzepki
- run
- bieganie
- taki sam
- zobaczył
- mówią
- skalowalny
- Skala
- skanować
- skanowanie
- skany
- systemy
- bezszwowy
- płynnie
- Sekcja
- bezpieczne
- widzieć
- senior
- Bezserwerowe
- Usługi
- zestaw
- powinien
- pokazać
- pokazał
- pokazane
- Targi
- Prosty
- pojedynczy
- rozwiązanie
- Rozwiązania
- Rozwiązywanie
- kilka
- Źródło
- Źródła
- Sourcing
- specjalista
- specjalizuje się
- specyfikacja
- okular
- Widmo
- SQL
- standard
- Startowy
- Zestawienie sprzedaży
- statystyka
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- przechowywany
- sklep
- Strategia
- sznur
- sukces
- taki
- wsparcie
- Utrzymany
- podpory
- stół
- Zespoły
- Technologies
- Technologia
- kilkadziesiąt
- niż
- że
- Połączenia
- Źródło
- ich
- następnie
- Te
- to
- tysiące
- Przez
- czas
- podróż w czasie
- znak czasu
- do
- już dziś
- narzędzia
- transakcyjny
- podróżować
- Prawda
- drugiej
- rodzaj
- typy
- Ujednolicony
- unia
- odblokować
- Aktualizacja
- zaktualizowane
- Nowości
- Stosowanie
- posługiwać się
- używany
- Użytkownicy
- zastosowania
- za pomocą
- UPRAWOMOCNIĆ
- wartość
- Wartości
- różnorodność
- różnorodny
- początku.
- przez
- Zobacz i wysłuchaj
- kłęby
- Magazyn
- Magazynowanie
- była
- Droga..
- we
- sieć
- usługi internetowe
- jeśli chodzi o komunikację i motywację
- który
- KIM
- szeroki
- szeroko
- będzie
- w
- działa
- rok
- lat
- ty
- Twój
- zefirnet