Organizacje na całym świecie – zarówno nastawione na zysk, jak i non-profit – szukają możliwości wykorzystania analizy danych w celu poprawy wyników biznesowych. Ustalenia z A Ankieta McKinsey wskazują, że organizacje działające w oparciu o dane mają 23 razy większe szanse na pozyskanie klientów, 19 razy większe prawdopodobieństwo ich zatrzymania i 1 razy większe zyski [XNUMX]. Badania przeprowadzone przez MIT odkryli, że firmy dojrzałe cyfrowo są o 26% bardziej rentowne niż ich odpowiedniki [2]. Jednak wiele firm, mimo że jest bogatych w dane, ma trudności z wdrożeniem analityki danych ze względu na sprzeczne priorytety między potrzebami biznesowymi, dostępnymi możliwościami i zasobami. Badania przeprowadzone przez firmę Gartner odkryli, że ponad 85% projektów dotyczących danych i analiz kończy się niepowodzeniem [3] oraz a wspólne sprawozdanie z IBM i Carnegie Melon pokazuje, że 90% danych w organizacji nigdy nie jest z powodzeniem wykorzystywane do żadnego celu strategicznego [4].
W tym kontekście przedstawiamy koncepcję „struktury analizy danych (DAF)” jako ekosystemu lub struktury umożliwiającej skuteczne działanie analityki danych w oparciu o (a) potrzeby lub cele biznesowe, (b) dostępne możliwości, takie jak ludzie/umiejętności , procesy, kultura, technologie, spostrzeżenia, kompetencje w zakresie podejmowania decyzji i nie tylko oraz (c) zasoby (tj. komponenty potrzebne firmie do prowadzenia działalności).
Naszym głównym celem wprowadzenia struktury analizy danych jest odpowiedź na to podstawowe pytanie: „Co jest wymagane, aby skutecznie zbudować system umożliwiający podejmowanie decyzji na podstawie Nauka danych algorytmy do pomiaru i poprawy wyników biznesowych?” Poniżej przedstawiono i omówiono strukturę analizy danych i jej pięć kluczowych przejawów.
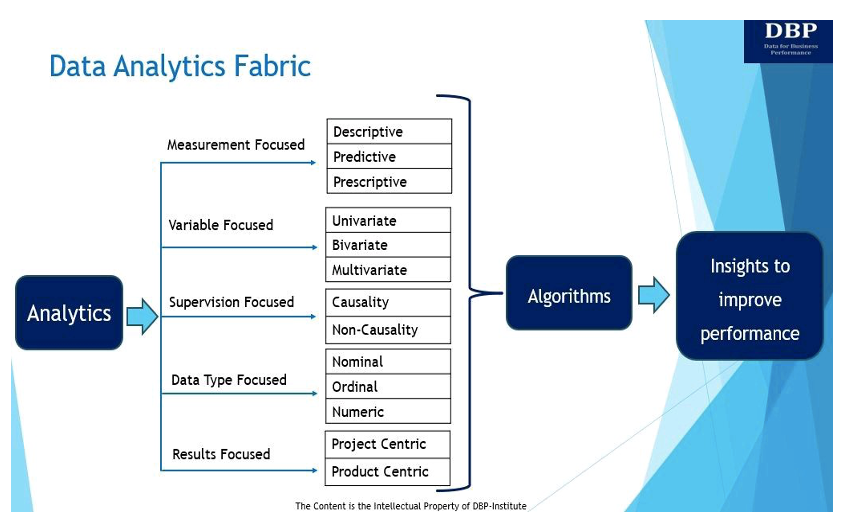
1. Skoncentrowany na pomiarach
W swojej istocie analityka polega na wykorzystaniu danych w celu uzyskania spostrzeżeń, które pozwalają zmierzyć i poprawić wyniki biznesowe [5]. Istnieją trzy główne typy analiz służących do pomiaru i poprawy wyników biznesowych:
- Analizy opisowe zadaje pytanie: „Co się stało?” Analityka opisowa służy do analizowania danych historycznych w celu identyfikacji wzorców, trendów i relacji przy użyciu technik analizy danych eksploracyjnych, asocjacyjnych i wnioskowania. Techniki eksploracyjnej analizy danych analizują i podsumowują zbiory danych. Asocjacyjna analiza opisowa wyjaśnia związek między zmiennymi. Inferencyjna opisowa analiza danych służy do wnioskowania lub wnioskowania o trendach dotyczących większej populacji na podstawie przykładowego zbioru danych.
- Analityka predykcyjna szuka odpowiedzi na pytanie: „Co się stanie?” Zasadniczo analiza predykcyjna to proces wykorzystywania danych do prognozowania przyszłych trendów i wydarzeń. Analizę predykcyjną można przeprowadzić ręcznie (powszechnie znaną jako analityka predykcyjna oparta na analitykach) lub przy użyciu algorytmy uczenia maszynowego (znana również jako analityka predykcyjna oparta na danych). Tak czy inaczej, dane historyczne służą do tworzenia prognoz na przyszłość.
- Analizy nakazowe pomaga odpowiedzieć na pytanie: „Jak możemy to osiągnąć?” Zasadniczo analityka preskryptywna zaleca najlepszy sposób działania, aby posunąć się do przodu, korzystając z technik optymalizacji i symulacji. Zazwyczaj analiza predykcyjna i analityka preskryptywna idą w parze, ponieważ analityka predykcyjna pomaga znaleźć potencjalne wyniki, podczas gdy analityka preskryptywna analizuje te wyniki i znajduje więcej opcji.
2. Skoncentrowany na zmiennych
Dane można również analizować na podstawie liczby dostępnych zmiennych. W związku z tym, w zależności od liczby zmiennych, techniki analizy danych mogą być jednowymiarowe, dwuwymiarowe lub wielowymiarowe.
- W analizie jednoczynnikowej: Analiza jednowymiarowa obejmuje analizę wzorca występującego w pojedynczej zmiennej przy użyciu miar centralności (średnia, mediana, moda itd.) i zmienności (odchylenie standardowe, błąd standardowy, wariancja itd.).
- Analiza dwuwymiarowa: Istnieją dwie zmienne, których analiza dotyczy przyczyny i związku między tymi dwiema zmiennymi. Te dwie zmienne mogą być od siebie zależne lub niezależne. Technika korelacji jest najczęściej stosowaną techniką analizy dwuwymiarowej.
- Analiza wielowymiarowa: Technikę tę stosuje się do analizy więcej niż dwóch zmiennych. W środowisku wielowymiarowym zazwyczaj działamy na arenie analityki predykcyjnej, a większość dobrze znanych algorytmów uczenia maszynowego (ML), takich jak regresja liniowa, regresja logistyczna, drzewa regresji, maszyny wektorów nośnych i sieci neuronowe, są zwykle stosowane do wielowymiarowych ustawienie.
3. Skoncentrowany na nadzorze
Trzeci typ struktury analizy danych zajmuje się uczeniem danych wejściowych lub danych zmiennych niezależnych, które zostały oznaczone etykietą dla określonego wyniku (tj. zmiennej zależnej). Zasadniczo zmienną niezależną jest ta, którą kontroluje eksperymentator. Zmienna zależna to zmienna, która zmienia się w odpowiedzi na zmienną niezależną. DAF zorientowany na nadzór może należeć do jednego z dwóch typów.
- Przyczynowość: Oznaczone dane, generowane automatycznie lub ręcznie, są niezbędne w uczeniu się pod nadzorem. Oznakowane dane pozwalają jednoznacznie zdefiniować zmienną zależną, a następnie kwestią algorytmu analityki predykcyjnej jest zbudowanie narzędzia AI/ML, które zbuduje relację pomiędzy etykietą (zmienną zależną) a zbiorem zmiennych niezależnych. Fakt, że mamy wyraźną demarkację pomiędzy pojęciem zmiennej zależnej a zbiorem zmiennych niezależnych, pozwalamy sobie na wprowadzenie terminu „przyczynowość”, aby najlepiej wyjaśnić tę zależność.
- Nieprzyczynowość: Kiedy jako nasz wymiar wskazujemy „skoncentrowany na superwizji”, mamy na myśli także „brak superwizji”, co wprowadza do dyskusji modele nieprzyczynowe. Na uwagę zasługują modele nieprzyczynowe, ponieważ nie wymagają oznakowanych danych. Podstawową techniką jest tu grupowanie, a najpopularniejszymi metodami są k-średnie i grupowanie hierarchiczne.
4. Koncentracja na typach danych
Ten wymiar lub przejaw struktury analizy danych skupia się na trzech różnych typach zmiennych danych, powiązanych zarówno ze zmiennymi niezależnymi, jak i zależnymi, które są wykorzystywane w technikach analizy danych w celu wyciągania wniosków.
- Dane nominalne służy do etykietowania lub kategoryzowania danych. Nie wiąże się to z wartością liczbową, w związku z czym nie są możliwe żadne obliczenia statystyczne na danych nominalnych. Przykładami danych nominalnych są płeć, opis produktu, adres klienta i tym podobne.
- Dane porządkowe lub rankingowe jest kolejnością wartości, ale różnice między każdą z nich nie są tak naprawdę znane. Typowymi przykładami są rankingi firm na podstawie kapitalizacji rynkowej, warunków płatności dostawców, wyników zadowolenia klientów, priorytetu dostaw i tak dalej.
- Dane liczbowe nie wymaga wprowadzenia i ma wartość liczbową. Zmienne te są najbardziej podstawowymi typami danych, które można wykorzystać do modelowania wszystkich typów algorytmów.
5. Koncentracja na wynikach
Ten typ struktury analizy danych analizuje sposoby dostarczania wartości biznesowej na podstawie wniosków uzyskanych z analiz. Analityka może napędzać wartość biznesową na dwa sposoby: poprzez produkty lub projekty. Chociaż w produktach może zaistnieć potrzeba uwzględnienia dodatkowych konsekwencji związanych z doświadczeniem użytkownika i inżynierią oprogramowania, ćwiczenie modelowania wykonane w celu wygenerowania modelu będzie podobne zarówno w projekcie, jak i produkcie.
- A produkt do analizy danych to zasób danych wielokrotnego użytku, który ma służyć długoterminowym potrzebom biznesowym. Pobiera dane z odpowiednich źródeł danych, dba o ich jakość, przetwarza je i udostępnia każdemu, kto ich potrzebuje. Produkty są zazwyczaj projektowane dla osób i mają wiele etapów cyklu życia lub iteracji, podczas których realizowana jest wartość produktu.
- A projekt analizy danych ma na celu zaspokojenie konkretnej lub unikalnej potrzeby biznesowej i ma zdefiniowaną lub wąską bazę użytkowników lub cel. Zasadniczo projekt to tymczasowe przedsięwzięcie, którego celem jest dostarczenie rozwiązania w określonym zakresie, w ramach budżetu i na czas.
W nadchodzących latach gospodarka światowa ulegnie radykalnej przemianie, ponieważ organizacje będą w coraz większym stopniu wykorzystywać dane i analizy do wyciągania wniosków i podejmowania decyzji w celu pomiaru i poprawy wyników biznesowych. McKinsey odkryli, że firmy, które kierują się wglądem, zgłaszają wzrost EBITDA (zysku przed odsetkami, podatkami, amortyzacją i amortyzacją) aż do 25% [5]. Jednak wielu organizacjom nie udaje się wykorzystać danych i analiz do poprawy wyników biznesowych. Nie ma jednak jednego standardowego sposobu ani podejścia do dostarczania analizy danych. Wdrożenie lub wdrożenie rozwiązań do analizy danych zależy od celów biznesowych, możliwości i zasobów. DAF i jego pięć omawianych tutaj przejawów może umożliwić skuteczne wdrożenie analiz w oparciu o potrzeby biznesowe, dostępne możliwości i zasoby.
Referencje
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate- Performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-bardziej zyskowne-niż-ich-rówieśnicy/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-mówi-prawie-połowa-ciosów-planuje-wdrożenie-sztucznej-inteligencji
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, Prashanth, „Najlepsze praktyki w zakresie analityki”, Technics, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- ChartPrime. Podnieś poziom swojej gry handlowej dzięki ChartPrime. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 1
- 19
- 23
- a
- O nas
- dostępny
- nabyć
- Działania
- Dodatkowy
- adres
- AI / ML
- algorytm
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- pozwala
- również
- amortyzacja
- an
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- analizowane
- Analizując
- i
- odpowiedź
- każdy
- ktoś
- stosowany
- podejście
- SĄ
- Arena
- na około
- AS
- kapitał
- At
- automatycznie
- dostępny
- b
- zasłona
- baza
- na podstawie
- podstawowy
- Gruntownie
- BE
- bo
- być
- zanim
- jest
- poniżej
- BEST
- pomiędzy
- obie
- Przynosi
- budżet
- budować
- biznes
- wyniki biznesowe
- ale
- by
- CAN
- możliwości
- kapitalizacja
- kategoryzowanie
- Spowodować
- Centralność
- Zmiany
- wyraźnie
- klastrowanie
- zbiera
- COM
- przyjście
- wspólny
- powszechnie
- Firmy
- składniki
- pojęcie
- stwierdza,
- przeprowadzone
- Sprzeczny
- kontroli
- rdzeń
- Korelacja
- mógłby
- kurs
- kultura
- klient
- Zadowolenie klienta
- Klientów
- dane
- analiza danych
- Analityka danych
- jakość danych
- zbiór danych
- zestawy danych
- sterowane danymi
- WSZECHSTRONNOŚĆ DANYCH
- Promocje
- Podejmowanie decyzji
- Decyzje
- określić
- zdefiniowane
- dostarczyć
- dostarczona
- dostawa
- zależny
- zależy
- wdrażane
- Wdrożenie
- deprecjacja
- Pochodny
- opis
- zasłużyć
- zaprojektowany
- Mimo
- odchylenie
- Różnice
- różne
- cyfrowo
- Wymiary
- omówione
- dyskusja
- odrębny
- do
- robi
- zrobić
- dramatycznie
- napędzany
- z powodu
- e
- każdy
- Zarobki
- EBITDA
- gospodarka
- Ekosystem
- faktycznie
- bądź
- umożliwiać
- Umożliwia
- starać się
- Inżynieria
- zapewnia
- błąd
- niezbędny
- wydarzenia
- przykłady
- Ćwiczenie
- doświadczenie
- Wyjaśniać
- Objaśnia
- Analiza danych rozpoznawczych
- tkanina
- fakt
- FAIL
- Znajdź
- Ustalenia
- znajduje
- firmy
- pięć
- koncentruje
- W razie zamówieenia projektu
- Forbes
- Prognoza
- Naprzód
- znaleziono
- od
- funkcjonować
- fundamentalny
- przyszłość
- Gartner
- Płeć
- wygenerowane
- Go
- cel
- zdarzyć
- się
- Have
- pomaga
- stąd
- tutaj
- historyczny
- Jednak
- HTTPS
- i
- IBM
- zidentyfikować
- wdrożenia
- realizacja
- podnieść
- ulepszony
- poprawy
- in
- Zwiększenia
- coraz bardziej
- niezależny
- wskazać
- wkład
- spostrzeżenia
- zamierzony
- odsetki
- przedstawiać
- wprowadzenie
- Wprowadzenie
- angażować
- dotyczy
- IT
- iteracje
- JEGO
- Klawisz
- znany
- Etykieta
- etykietowanie
- większe
- nauka
- lewarowanie
- wifecycwe
- lubić
- Prawdopodobnie
- długoterminowy
- poszukuje
- WYGLĄD
- maszyna
- uczenie maszynowe
- maszyny
- Główny
- robić
- WYKONUJE
- ręcznie
- wiele
- rynek
- Kapitalizacja rynkowa
- Materia
- dojrzały
- Maksymalna szerokość
- Może..
- McKinsey
- oznaczać
- zmierzyć
- środków
- wspominać
- metody
- MIT
- ML
- Moda
- model
- modelowanie
- modele
- jeszcze
- większość
- Najbardziej popularne posty
- przeniesienie
- wielokrotność
- Potrzebować
- wymagania
- sieci
- Nerwowy
- sieci neuronowe
- nigdy
- Nie
- Niedochodowy
- Pojęcie
- numer
- Cele
- of
- on
- ONE
- działać
- optymalizacja
- Opcje
- or
- zamówienie
- organizacja
- organizacji
- Inne
- ludzkiej,
- sobie
- wyniki
- wydajność
- koniec
- szczególny
- Wzór
- wzory
- płatność
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- plato
- Analiza danych Platona
- PlatoDane
- Popularny
- populacja
- możliwy
- potencjał
- Przewidywania
- proroczy
- Analiza predykcyjna
- Analityka predykcyjna
- teraźniejszość
- pierwotny
- priorytet
- wygląda tak
- procesów
- Produkt
- Produkty
- Zysk
- rentowny
- projekt
- projektowanie
- cel
- jakość
- pytanie
- konsekwencje
- w rankingu
- Ranking
- realizowany
- naprawdę
- zaleca
- Uważać
- regresja
- związane z
- związek
- Relacje
- raport
- wymagać
- wymagany
- Zasoby
- odpowiedź
- zachować
- wielokrotnego użytku
- klientów
- zakres
- wyniki
- służyć
- zestaw
- Zestawy
- ustawienie
- pokazane
- Targi
- podobny
- symulacja
- pojedynczy
- SIX
- So
- Tworzenie
- Inżynieria oprogramowania
- rozwiązanie
- Rozwiązania
- Źródło
- Źródła
- etapy
- standard
- statystyczny
- Strategiczny
- Struktura
- Walka
- udany
- Z powodzeniem
- taki
- streszczać
- Nadzorowana nauka
- nadzór
- wsparcie
- system
- Podatki
- Techniki
- Technologies
- tymczasowy
- semestr
- REGULAMIN
- niż
- że
- Połączenia
- świat
- ich
- następnie
- Tam.
- Te
- one
- Trzeci
- to
- tych
- trzy
- Przez
- czas
- czasy
- do
- razem
- narzędzie
- Trening
- Przekształcać
- Drzewa
- Trendy
- drugiej
- rodzaj
- typy
- zazwyczaj
- wyjątkowy
- posługiwać się
- używany
- Użytkownik
- Doświadczenie użytkownika
- za pomocą
- wartość
- Wartości
- zmienna
- sprzedawca
- Droga..
- sposoby
- we
- znane
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- KIM
- będzie
- w
- w ciągu
- świat
- świat
- by
- lat
- zefirnet











