Niedawno zdaliśmy sobie sprawę, że od jakiegoś czasu nie dostarczaliśmy wam żadnych ściągawek do analizy danych. I to nie z powodu ich braku dostępności; Ściągawki do nauki o danych są wszędzie, od wprowadzających po zaawansowane, obejmujące tematy od algorytmów, przez statystyki, po wskazówki dotyczące wywiadów i nie tylko.
Ale co czyni dobrą ściągawkę? Co sprawia, że ściągawka zasługuje na wyróżnienie jako szczególnie dobra? Trudno jest włożyć palec precyzyjnie co sprawia, że ściągawka jest dobra, ale oczywiście taka, która w zwięzły sposób przekazuje najważniejsze informacje — czy są to informacje szczegółowe, czy ogólne — to zdecydowanie dobry początek. I to właśnie czyni naszych dzisiejszych kandydatów godnymi uwagi. Czytaj dalej, aby zapoznać się z czterema wyselekcjonowanymi, uzupełniającymi ściągawkami, które pomogą Ci w nauce lub powtórce nauki o danych.
Najpierw jest Ściągawka do analizy danych Aarona Wanga 2.0, czterostronicową kompilację abstrakcji statystycznych, podstawowych algorytmów uczenia maszynowego oraz tematów i koncepcji związanych z uczeniem głębokim. Nie ma to być wyczerpujące, ale zamiast tego szybkie odniesienie do sytuacji, takich jak przygotowanie do rozmowy kwalifikacyjnej i recenzje egzaminów oraz wszystko inne wymagające podobnego poziomu szczegółowości recenzji. Autor zauważa, że chociaż ci, którzy mają podstawową wiedzę na temat statystyki i algebry liniowej, uznają ten zasób za najbardziej przydatny, początkujący również powinni być w stanie zebrać przydatne informacje z jego zawartości.

Zrzut ekranu od Aarona Wanga Ściągawka do nauki o danych 2.0
Naszą kolejną ofertą ściągawek dzisiaj jest ta, na której opiera się zasób Aarona Wanga, Ściągawka do analizy danych Mavericka Lina (Odniesienie Wanga do jego własnego jako 2.0 jest bezpośrednim ukłonem w stronę „oryginału” Lin). Ściągawka Lina może być postrzegana jako bardziej szczegółowa niż Wanga (chociaż decyzja Wanga, by uczynić jego mniej dogłębną, wydaje się celową i użyteczną alternatywą), obejmuje bardziej fundamentalne koncepcje nauki o danych, takie jak czyszczenie danych, idea modelowania, robienie „ big data” z Hadoopem, SQL, a nawet podstawami Pythona.
Najwyraźniej spodoba się to tym, którzy są bardziej w obozie „początkujących”, i dobrze radzi sobie z zaostrzaniem apetytu i uświadamianiem czytelnikom szerokiej dziedziny nauki o danych oraz wielu różnych koncepcji, które obejmuje. Jest to zdecydowanie kolejny solidny zasób, zwłaszcza jeśli czytelnik jest nowicjuszem w dziedzinie nauki o danych.

Zrzut ekranu z Maverick Lin Ściągawka do nauki o danych
Gdy cofamy się w czasie – szukając inspiracji dla ściągawki Lin – napotykamy Ściągawka prawdopodobieństwa Williama Chena 2.0. Ściągawka Chena przez lata cieszyła się dużym zainteresowaniem i uznaniem, więc mogłeś się z nią kiedyś spotkać. Najwyraźniej skupiając się na innym celu (zważywszy na swoją nazwę), ściągawka Chena to szybki kurs lub dogłębny przegląd koncepcji prawdopodobieństwa, w tym różnych rozkładów, kowariancji i transformacji, warunkowej wartości oczekiwanej, łańcuchów Markowa, różnych ważnych formuł i wiele więcej.
Na 10 stronach powinieneś być w stanie wyobrazić sobie zakres omawianych tutaj zagadnień związanych z prawdopodobieństwem. Ale niech cię to nie zniechęca; Godna uwagi jest zdolność Chena do sprowadzenia koncepcji do ich najważniejszych punktów i wyjaśnienia prostym angielskim, bez poświęcania podstawowych rzeczy. Jest również bogaty w objaśniające wizualizacje, co jest całkiem przydatne, gdy przestrzeń jest ograniczona, a chęć bycia zwięzłym jest silna.
Kompilacja Chena jest nie tylko wysokiej jakości i warta twojego czasu, jako początkujący lub ktoś zainteresowany pełną recenzją, pracowałbym w odwrotnej kolejności niż prezentowano te zasoby — od ściągawki Chena, przez Lina, a na końcu do Wanga, opierając się na koncepcjach na bieżąco.
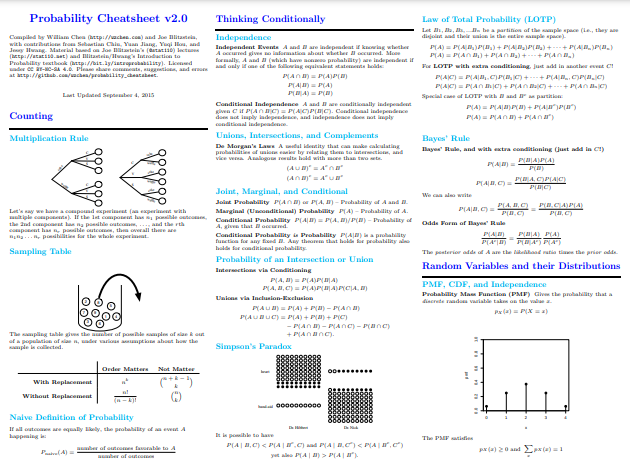
Zrzut ekranu od Williama Chena Ściągawka z prawdopodobieństwem 2.0
Ostatnim zasobem, który tu załączam, choć technicznie nie jest ściągawką, jest Ukąszenia uczenia maszynowego Rishabha Ananda. Reklamując się jako „przewodnik po rozmowach kwalifikacyjnych na temat typowych koncepcji uczenia maszynowego, najlepszych praktyk, definicji i teorii”, Anand skompilował szeroki zbiór „ukąszeń” wiedzy, których użyteczność zdecydowanie wykracza poza pierwotnie zamierzone przygotowanie do rozmowy kwalifikacyjnej. Poruszane w nim tematy to m.in.:
- Metryki punktacji modelu
- Udostępnianie parametrów
- Walidacja krzyżowa k-krotnie
- Typy danych Pythona
- Poprawa wydajności modelu
- Modele widzenia komputerowego
- Uwaga i jej warianty
- Radzenie sobie z nierównowagą klas
- Glosariusz wizji komputerowej
- Propagacja wsteczna wanilii
- Regularyzacja
- Referencje

Zrzut ekranu z Ukąszenia uczenia maszynowego
Chociaż poruszane są „koncepcje, najlepsze praktyki, definicje i teoria” uczenia maszynowego, jak obiecano w opisie samego zasobu, te „ukąszenia” są zdecydowanie ukierunkowane na praktykę, co sprawia, że witryna jest komplementarna w stosunku do większości materiałów omawianych w trzy wspomniane wcześniej ściągawki. Gdybym chciał omówić cały materiał we wszystkich czterech zasobach w tym poście, z pewnością spojrzałbym na to po pozostałych trzech.
Masz więc cztery ściągawki (lub trzy ściągawki i jeden zasób z ściągami) do wykorzystania podczas nauki lub powtórki. Mam nadzieję, że coś tutaj jest dla Ciebie przydatne i zapraszam wszystkich do podzielenia się ściągawkami, które uznali za przydatne w komentarzach poniżej.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html?utm_source=rss&utm_medium=rss&utm_campaign=more-data-science-cheatsheets
- 10
- a
- Aaron
- zdolność
- Zdolny
- w poprzek
- zaawansowany
- Po
- Algorytmy
- Wszystkie kategorie
- alternatywny
- i
- Inne
- ktoś
- odwołać się
- Uwaga
- autor
- dostępność
- z powrotem
- na podstawie
- podstawowy
- Podstawy
- początkujących
- jest
- poniżej
- korzyści
- BEST
- Najlepsze praktyki
- Poza
- Duży
- Big Data
- billing
- szerokość
- szeroki
- przyniósł
- Budowanie
- Obóz
- kandydatów
- na pewno
- więzy
- chen
- klasa
- Sprzątanie
- wyraźnie
- kolekcja
- jak
- komentarze
- wspólny
- uzupełniający
- Koncepcje
- zawartość
- kurs
- pokrywa
- pokryty
- pokrycie
- Crash
- Krzyż
- kurator
- dane
- nauka danych
- decyzja
- głęboko
- głębokie nurkowanie
- głęboka nauka
- Zdecydowanie
- głębokość
- opis
- różne
- trudny
- kierować
- Dystrybucje
- robi
- na dół
- obejmuje
- Angielski
- szczególnie
- niezbędny
- Essentials
- Eter (ETH)
- Parzyste
- egzamin
- oczekiwanie
- Wyjaśniać
- pole
- Postać
- finał
- W końcu
- Znajdź
- mocno
- Skupiać
- znaleziono
- od
- pełny
- fundamentalny
- dalej
- nastawiony
- Ogólne
- dany
- Go
- dobry
- dobra praca
- poprowadzi
- tutaj
- Ufnie
- W jaki sposób
- HTTPS
- pomysł
- brak równowagi
- znaczenie
- in
- informacje
- zawierać
- Włącznie z
- Informacja
- Inspiracja
- zamiast
- Zamierzony
- zainteresowany
- Wywiad
- wprowadzający
- zapraszać
- IT
- samo
- Praca
- wiedza
- Brak
- nauka
- poziom
- Ograniczony
- Popatrz
- poszukuje
- maszyna
- uczenie maszynowe
- robić
- WYKONUJE
- Dokonywanie
- wiele
- materiał
- politycznie niezależny
- wzmiankowany
- Metryka
- model
- modele
- jeszcze
- większość
- ruch
- Nazwa
- Natura
- Następny
- Uwagi
- godny uwagi
- Pojęcie
- oferuje
- ONE
- zamówienie
- oryginalny
- pierwotnie
- Inne
- własny
- szczególnie
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- Równina
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- Post
- Praktyczny
- praktyki
- przedstawione
- poprzednio
- obiecał
- położyć
- Python
- jakość
- Szybki
- nośny
- Czytaj
- Czytelnik
- czytelnicy
- realizowany
- niedawno
- Zasób
- Zasoby
- rewers
- przeglądu
- Recenzje
- Bogaty
- poświęcanie
- nauka
- punktacji
- poszukuje
- wydaje
- Share
- dzielenie
- powinien
- podobny
- witryna internetowa
- sytuacje
- So
- solidny
- kilka
- Ktoś
- coś
- Typ przestrzeni
- specyficzny
- początek
- statystyczny
- statystyka
- silny
- taki
- Połączenia
- Podstawy
- ich
- trzy
- czas
- wskazówki
- do
- już dziś
- Top
- tematy
- w kierunku
- przemiany
- typy
- zrozumienie
- posługiwać się
- uprawomocnienie
- różnorodność
- różnorodny
- wizja
- Co
- czy
- który
- Podczas
- KIM
- szeroki
- będzie
- w ciągu
- Praca
- by
- lat
- Twój
- zefirnet




