Ten post został napisany wspólnie z Preshenem Goobiahem i Johanem Olivierem z Capitec.
Apache Spark to szeroko stosowany system przetwarzania rozproszonego typu open source, znany z obsługi obciążeń danymi na dużą skalę. Znajduje częste zastosowanie wśród programistów Spark pracujących z Amazon EMR, Amazon Sage Maker, Klej AWS i niestandardowe aplikacje Spark.
Amazonka Przesunięcie ku czerwieni oferuje bezproblemową integrację z Apache Spark, umożliwiając łatwy dostęp do danych Redshift zarówno w klastrach udostępnianych przez Amazon Redshift, jak i Bezserwerowe Amazon Redshift. Integracja ta rozszerza możliwości rozwiązań analitycznych AWS i uczenia maszynowego (ML), dzięki czemu hurtownia danych jest dostępna dla szerszego zakresu aplikacji.
Z Integracja Amazon Redshift dla Apache Sparkmożesz szybko rozpocząć pracę i bez wysiłku tworzyć aplikacje Spark przy użyciu popularnych języków, takich jak Java, Scala, Python, SQL i R. Twoje aplikacje mogą bezproblemowo odczytywać i zapisywać w hurtowni danych Amazon Redshift, zachowując jednocześnie optymalną wydajność i spójność transakcyjną. Dodatkowo odniesiesz korzyści z poprawy wydajności dzięki optymalizacji przesuwania, co jeszcze bardziej zwiększy efektywność Twoich operacji.
Capitec, największy bank detaliczny w Republice Południowej Afryki, mający ponad 21 milionów klientów bankowości detalicznej, ma na celu świadczenie prostych, niedrogich i dostępnych usług finansowych, aby pomóc mieszkańcom Republiki Południowej Afryki w lepszym korzystaniu z bankowości i lepszym życiu. W tym poście omawiamy udaną integrację złącza Amazon Redshift o otwartym kodzie źródłowym przez zespół ds. platform usług wspólnych firmy Capitec. W wyniku wykorzystania integracji Amazon Redshift z Apache Spark produktywność programistów wzrosła 10-krotnie, usprawniono procesy generowania funkcji, a duplikację danych ograniczono do zera.
Okazja biznesowa
Dostępnych jest 19 modeli predykcyjnych wykorzystujących 93 funkcje zbudowane przy użyciu kleju AWS w oddziałach kredytów detalicznych firmy Capitec. Rekordy funkcji są wzbogacane o fakty i wymiary przechowywane w Amazon Redshift. Do tworzenia funkcji wybrano Apache PySpark, ponieważ oferuje szybki, zdecentralizowany i skalowalny mechanizm przetwarzania danych z różnych źródeł.
Te funkcje produkcyjne odgrywają kluczową rolę w umożliwianiu składania wniosków o pożyczki na czas określony i karty kredytowe w czasie rzeczywistym, miesięcznym monitorowaniu zachowań kredytowych w trybie zbiorczym oraz identyfikacji dziennego wynagrodzenia w ramach firmy.
Problem źródła danych
Aby zapewnić niezawodność potoków danych PySpark, konieczne jest posiadanie spójnych danych na poziomie rekordu z tabel wymiarowych i faktów przechowywanych w hurtowni danych przedsiębiorstwa (EDW). Tabele te są następnie łączone z tabelami z Enterprise Data Lake (EDL) w czasie wykonywania.
Podczas opracowywania funkcji inżynierowie danych potrzebują płynnego interfejsu do EDW. Interfejs ten umożliwia dostęp do niezbędnych danych z EDW i ich integrację z potokami danych, umożliwiając efektywny rozwój i testowanie funkcji.
Poprzedni proces rozwiązania
W poprzednim rozwiązaniu inżynierowie danych zespołu produktu poświęcali 30 minut na ręczne udostępnienie danych Redshift platformie Spark. Kroki obejmowały następujące czynności:
- Utwórz zapytanie predykowane w Pythonie.
- Prześlij ROZŁADOWAĆ zapytanie poprzez API danych Amazon Redshift.
- Dane katalogowe w katalogu danych kleju AWS za pośrednictwem pakietu AWS SDK dla Pand przy użyciu próbkowania.
Takie podejście stwarzało problemy w przypadku dużych zbiorów danych, wymagało okresowej konserwacji ze strony zespołu platformy i było skomplikowane w automatyzacji.
Aktualny przegląd rozwiązań
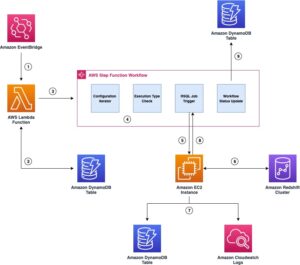
Capitec był w stanie rozwiązać te problemy dzięki integracji Amazon Redshift dla Apache Spark w ramach potoków generowania funkcji. Architekturę zdefiniowano na poniższym schemacie.

Przepływ pracy obejmuje następujące kroki:
- Biblioteki wewnętrzne są instalowane w zadaniu AWS Glue PySpark za pośrednictwem Artefakt Kodeksu AWS.
- Zadanie AWS Glue pobiera poświadczenia klastra Redshift z Menedżer tajemnic AWS i konfiguruje połączenie Amazon Redshift (wstrzykuje dane uwierzytelniające klastra, zwalnia lokalizacje, formaty plików) za pośrednictwem współdzielonej biblioteki wewnętrznej. Integracja Amazon Redshift dla Apache Spark obsługuje również używanie AWS Zarządzanie tożsamością i dostępem (IAM) do odzyskaj dane uwierzytelniające i połącz się z Amazon Redshift.
- Zapytanie Spark jest tłumaczone na zapytanie zoptymalizowane przez Amazon Redshift i przesyłane do EDW. Osiąga się to poprzez integrację Amazon Redshift dla Apache Spark.
- Zbiór danych EDW jest ładowany do tymczasowego przedrostka w pliku Usługa Amazon Simple Storage Łyżka (Amazon S3).
- Zbiór danych EDW z segmentu S3 jest ładowany do modułów wykonawczych Spark poprzez integrację Amazon Redshift dla Apache Spark.
- Zbiór danych EDL jest ładowany do modułów wykonawczych Spark za pośrednictwem katalogu danych kleju AWS.
Komponenty te współpracują ze sobą, aby zapewnić inżynierom danych i potokom danych produkcyjnych narzędzia niezbędne do wdrożenia integracji Amazon Redshift z Apache Spark, uruchamiania zapytań i ułatwienia przesyłania danych z Amazon Redshift do EDL.
Korzystanie z integracji Amazon Redshift dla Apache Spark w AWS Glue 4.0
W tej sekcji demonstrujemy użyteczność integracji Amazon Redshift dla Apache Spark poprzez wzbogacenie tabeli wniosków kredytowych znajdującej się w jeziorze danych S3 o informacje o kliencie z hurtowni danych Redshift w PySpark.
Połączenia dimclient tabela w Amazon Redshift zawiera następujące kolumny:
- Klucz klienta – INT8
- KlientAltKey – VARCHAR50
- Numer identyfikacyjny partii – VARCHAR20
- Data utworzenia klienta - DATA
- Jest odwołany – INT2
- WierszIsCurrent – INT2
Połączenia loanapplication tabela w katalogu danych kleju AWS zawiera następujące kolumny:
- Identyfikator rekordu – DUŻY
- Data dziennika - ZNAK CZASU
- Numer identyfikacyjny partii - STRUNOWY
Tabela Redshift jest odczytywana poprzez integrację Amazon Redshift dla Apache Spark i buforowana. Zobacz następujący kod:
Rekordy wniosków kredytowych są wczytywane z jeziora danych S3 i wzbogacane o dimclient tabela na temat informacji o Amazon Redshift:
Dzięki temu rekord wniosku kredytowego (z jeziora danych S3) zostaje wzbogacony o ClientCreateDate kolumna (z Amazon Redshift).

Jak integracja Amazon Redshift dla Apache Spark rozwiązuje problem pozyskiwania danych
Integracja Amazon Redshift dla Apache Spark skutecznie rozwiązuje problem pozyskiwania danych poprzez następujące mechanizmy:
- Lektura w sam raz – Integracja Amazon Redshift dla konektora Apache Spark odczytuje tabele Redshift w sposób just-in-time, zapewniając spójność danych i schematu. Jest to szczególnie cenne dla Typ 2 wolno zmieniający się wymiar (SCD) i przedział czasowy gromadzący fakty dotyczące migawek. Łącząc te tabele Redshift z tabelami systemu źródłowego AWS Glue Data Catalog z EDL w ramach produkcyjnych potoków PySpark, łącznik umożliwia bezproblemową integrację danych z wielu źródeł przy jednoczesnym zachowaniu integralności danych.
- Zoptymalizowane zapytania Redshift – Integracja Amazon Redshift z Apache Spark odgrywa kluczową rolę w przekształcaniu planu zapytań Spark w zoptymalizowane zapytanie Redshift. Ten proces konwersji upraszcza pracę zespołu ds. produktu, przestrzegając zasady lokalizacji danych. Zoptymalizowane zapytania korzystają z możliwości i optymalizacji wydajności Amazon Redshift, zapewniając wydajne pobieranie i przetwarzanie danych z Amazon Redshift dla potoków PySpark. Pomaga to usprawnić proces programowania, jednocześnie zwiększając ogólną wydajność operacji pozyskiwania danych.
Uzyskanie najlepszej wydajności
Integracja Amazon Redshift dla Apache Spark automatycznie stosuje przekazywanie predykatów i zapytań w celu optymalizacji wydajności. Możesz uzyskać poprawę wydajności, używając domyślnego formatu Parquet używanego do rozładunku w ramach tej integracji.
Dodatkowe szczegóły i próbki kodu można znaleźć w artykule Nowość – integracja Amazon Redshift z Apache Spark.
Korzyści rozwiązania
Przyjęcie integracji przyniosło zespołowi kilka znaczących korzyści:
- Większa produktywność programistów – Interfejs PySpark dostarczony w ramach integracji zwiększył produktywność programistów 10-krotnie, umożliwiając płynniejszą interakcję z Amazon Redshift.
- Eliminacja duplikacji danych – Wyeliminowano duplikaty i skatalogowane tabele przesunięcia ku czerwieni AWS Glue w jeziorze danych, co spowodowało usprawnienie środowiska danych.
- Zmniejszone obciążenie EDW – Integracja ułatwiła selektywny rozładunek danych, minimalizując obciążenie EDW poprzez wyodrębnienie tylko niezbędnych danych.
Korzystając z integracji Amazon Redshift z Apache Spark, firma Capitec utorowała drogę ulepszonemu przetwarzaniu danych, zwiększonej produktywności i wydajniejszemu ekosystemowi inżynierii funkcji.
Wnioski
W tym poście omówiliśmy, jak zespół Capitec pomyślnie wdrożył integrację Apache Spark Amazon Redshift dla Apache Spark, aby uprościć przepływy pracy związane z obliczaniem funkcji. Podkreślili znaczenie wykorzystania zdecentralizowanych i modułowych potoków danych PySpark do tworzenia funkcji modelu predykcyjnego.
Obecnie integracja Amazon Redshift dla Apache Spark jest wykorzystywana w 7 potokach danych produkcyjnych i 20 potokach programistycznych, co potwierdza jej skuteczność w środowisku Capitec.
W przyszłości zespół ds. platformy funkcji wspólnych w firmie Capitec planuje rozszerzyć zastosowanie integracji Amazon Redshift dla Apache Spark w różnych obszarach biznesowych, mając na celu dalsze zwiększanie możliwości przetwarzania danych i promowanie wydajnych praktyk inżynierii funkcji.
Dodatkowe informacje na temat korzystania z integracji Amazon Redshift dla Apache Spark można znaleźć w następujących zasobach:
O autorach
 Preshena Goobiaha jest głównym inżynierem uczenia maszynowego platformy funkcji w firmie Capitec. Koncentruje się na projektowaniu i budowaniu komponentów Feature Store do użytku korporacyjnego. W wolnym czasie czyta i podróżuje.
Preshena Goobiaha jest głównym inżynierem uczenia maszynowego platformy funkcji w firmie Capitec. Koncentruje się na projektowaniu i budowaniu komponentów Feature Store do użytku korporacyjnego. W wolnym czasie czyta i podróżuje.
 Johana Oliviera jest starszym inżynierem ds. uczenia maszynowego w platformie modelowej firmy Capitec. Jest przedsiębiorcą i entuzjastą rozwiązywania problemów. W wolnym czasie lubi muzykę i spotkania towarzyskie.
Johana Oliviera jest starszym inżynierem ds. uczenia maszynowego w platformie modelowej firmy Capitec. Jest przedsiębiorcą i entuzjastą rozwiązywania problemów. W wolnym czasie lubi muzykę i spotkania towarzyskie.
 Sudipta Bagchi jest starszym specjalistą ds. rozwiązań architektonicznych w Amazon Web Services. Ma ponad 12-letnie doświadczenie w zakresie danych i analityki. Pomaga klientom projektować i budować skalowalne i wydajne rozwiązania analityczne. Poza pracą uwielbia biegać, podróżować i grać w krykieta. Połącz się z nim LinkedIn.
Sudipta Bagchi jest starszym specjalistą ds. rozwiązań architektonicznych w Amazon Web Services. Ma ponad 12-letnie doświadczenie w zakresie danych i analityki. Pomaga klientom projektować i budować skalowalne i wydajne rozwiązania analityczne. Poza pracą uwielbia biegać, podróżować i grać w krykieta. Połącz się z nim LinkedIn.
 Syeda Humaira jest starszym specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services (AWS). Ma ponad 17-letnie doświadczenie w architekturze korporacyjnej, koncentrując się na danych i sztucznej inteligencji/ML, pomagając klientom AWS na całym świecie w spełnianiu ich wymagań biznesowych i technicznych. Możesz się z nim połączyć LinkedIn.
Syeda Humaira jest starszym specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services (AWS). Ma ponad 17-letnie doświadczenie w architekturze korporacyjnej, koncentrując się na danych i sztucznej inteligencji/ML, pomagając klientom AWS na całym świecie w spełnianiu ich wymagań biznesowych i technicznych. Możesz się z nim połączyć LinkedIn.
 Vuyisa Maswana jest starszym architektem rozwiązań w AWS z siedzibą w Cape Town. Vuyisa kładzie duży nacisk na pomaganie klientom w tworzeniu rozwiązań technicznych w celu rozwiązywania problemów biznesowych. Wspiera Capitec w ich podróży do AWS od 2019 roku.
Vuyisa Maswana jest starszym architektem rozwiązań w AWS z siedzibą w Cape Town. Vuyisa kładzie duży nacisk na pomaganie klientom w tworzeniu rozwiązań technicznych w celu rozwiązywania problemów biznesowych. Wspiera Capitec w ich podróży do AWS od 2019 roku.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- :ma
- :Jest
- $W GÓRĘ
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- Zdolny
- dostęp
- dostępny
- realizowane
- w poprzek
- Dodatkowy
- Dodatkowe informacje
- do tego
- adres
- Adresy
- przylegający
- Przyjęcie
- przystępne
- AI / ML
- Cel
- Cele
- Pozwalać
- pozwala
- również
- Amazonka
- Amazon Web Services
- Amazon Web Services (AWS)
- wśród
- an
- analityka
- i
- Apache
- Apache Spark
- Zastosowanie
- aplikacje
- dotyczy
- podejście
- architektura
- SĄ
- obszary
- AS
- At
- zautomatyzować
- automatycznie
- AWS
- Klej AWS
- Bank
- Bankowość
- na podstawie
- bo
- zachowanie
- korzyści
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Najwyższa
- Wzmocnione
- obie
- szerszy
- budować
- Budowanie
- wybudowany
- biznes
- by
- CAN
- możliwości
- peleryna
- karta
- katalog
- wymiana pieniędzy
- klient
- klientów
- Grupa
- CO
- kod
- Kolumna
- kolumny
- łączenie
- kompleks
- składniki
- obliczenia
- Skontaktuj się
- połączenie
- zgodny
- zawiera
- kontekst
- Konwersja
- 轉換
- Stwórz
- Tworzenie
- Listy uwierzytelniające
- kredyt
- Karta kredytowa
- krykiet
- istotny
- zwyczaj
- Klientów
- codziennie
- dane
- Jezioro danych
- analiza danych
- hurtownia danych
- zbiory danych
- Zdecentralizowane
- Domyślnie
- zdefiniowane
- wykazać
- Wnętrze
- projektowanie
- detale
- rozwijać
- Deweloper
- deweloperzy
- oprogramowania
- różne
- Wymiary
- Wymiary
- dyskutować
- omówione
- dystrybuowane
- inny
- z łatwością
- Ekosystem
- faktycznie
- skuteczność
- efektywność
- wydajny
- bez wysiłku
- wyłączony
- podkreślił
- Umożliwia
- umożliwiając
- inżynier
- Inżynieria
- Inżynierowie
- wzmacniać
- wzmocnienie
- Wzbogacony
- wzbogacanie
- zapewnić
- zapewnienie
- Enterprise
- entuzjasta
- Przedsiębiorca
- Środowisko
- niezbędny
- Eter (ETH)
- Przede wszystkim system został opracowany
- Rozszerzać
- rozszerza się
- doświadczenie
- ułatwiać
- ułatwione
- fakt
- czynnik
- fakty
- FAST
- Cecha
- Korzyści
- filet
- budżetowy
- usługi finansowe
- znajduje
- Skupiać
- koncentruje
- skupienie
- następujący
- W razie zamówieenia projektu
- format
- Naprzód
- częsty
- od
- Funkcje
- dalej
- Wzrost
- generacja
- otrzymać
- GitHub
- Globalnie
- Prowadzenie
- Have
- he
- pomoc
- pomoc
- pomaga
- go
- jego
- W jaki sposób
- HTML
- http
- HTTPS
- IAM
- Identyfikacja
- tożsamość
- wdrożenia
- realizowane
- importować
- znaczenie
- ulepszony
- ulepszenia
- in
- włączony
- obejmuje
- wzrosła
- Informacja
- integrować
- integracja
- integralność
- wzajemne oddziaływanie
- Interfejs
- wewnętrzny
- najnowszych
- problemy
- IT
- JEGO
- Java
- Praca
- przystąpić
- Dołączył
- podróż
- jezioro
- Języki
- duży
- na dużą skalę
- prowadzić
- nauka
- lewo
- biblioteki
- Biblioteka
- lubić
- relacja na żywo
- załadować
- pożyczka
- lokalizacji
- kocha
- maszyna
- uczenie maszynowe
- utrzymanie
- konserwacja
- Dokonywanie
- sposób
- ręcznie
- mechanizm
- Mechanizmy
- milion
- minimalizowanie
- minuty
- ML
- model
- modele
- Modułowa
- monitorowanie
- miesięcznie
- jeszcze
- bardziej wydajny
- wielokrotność
- Muzyka
- niezbędny
- of
- Oferty
- Oliwkowy
- on
- tylko
- koncepcja
- open source
- operacje
- Optymalny
- Optymalizacja
- zoptymalizowane
- zamówienie
- zewnętrzne
- koniec
- ogólny
- pandy
- szczególnie
- Hasło
- dla
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- krok po kroku
- plany
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- gra
- odgrywa
- Popularny
- stwarzane
- możliwości
- Post
- praktyki
- proroczy
- poprzedni
- zasada
- Problem
- rozwiązanie problemu
- problemy
- wygląda tak
- przetwarzanie
- Produkt
- Produkcja
- wydajność
- promować
- zapewniać
- pod warunkiem,
- Python
- zapytania
- szybko
- R
- zasięg
- Czytaj
- Czytający
- w czasie rzeczywistym
- rekord
- dokumentacja
- powtarzające się
- Zredukowany
- odnosić się
- niezawodność
- Słynny
- wymagać
- wymagany
- wymagania
- rozwiązać
- Zasoby
- dalsze
- wynikły
- detaliczny
- Bankowości detalicznej
- Rola
- run
- bieganie
- wynagrodzenie
- SC
- Scala
- skalowalny
- zakres
- Sdk
- bezszwowy
- płynnie
- tajniki
- Sekcja
- widzieć
- wybrany
- wybierając
- selektywny
- senior
- Usługi
- Zestawy
- kilka
- shared
- ściąganie
- znaczący
- Prosty
- upraszczać
- upraszczanie
- ponieważ
- Powoli
- gładsze
- Migawka
- So
- towarzyskie
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Rozwiązuje
- Źródło
- Źródła
- Sourcing
- Południe
- Iskra
- specjalista
- spędził
- SQL
- rozpoczęty
- Cel
- przechowywanie
- przechowywany
- opływowy
- usprawniony
- sznur
- silny
- składane
- udany
- Z powodzeniem
- Utrzymany
- podpory
- system
- stół
- zespół
- Techniczny
- tymczasowy
- Testowanie
- że
- Połączenia
- Źródło
- ich
- Im
- następnie
- Te
- one
- to
- Przez
- czas
- do
- razem
- narzędzia
- miasto
- transakcyjny
- Podróżowanie
- URL
- posługiwać się
- używany
- za pomocą
- użyteczność
- wykorzystany
- Wykorzystując
- Cenny
- przez
- Magazyn
- była
- Droga..
- we
- sieć
- usługi internetowe
- były
- Podczas
- w
- w ciągu
- Praca
- pracować razem
- workflow
- przepływów pracy
- pracujący
- napisać
- lat
- wydany
- ty
- Twój
- zefirnet
- zero