W dzisiejszym świecie opartym na danych umiejętność łatwego przenoszenia i analizowania danych na różnych platformach jest niezbędna. Przepływ aplikacji Amazon, w pełni zarządzana usługa integracji danych, przoduje w usprawnianiu przesyłania danych między usługami AWS, aplikacjami typu Software as a Service (SaaS), a obecnie Google BigQuery. W tym poście na blogu odkrywasz nowe Łącznik Google BigQuery w Amazon AppFlow i odkryj, jak upraszcza to proces przesyłania danych z hurtowni danych Google do Usługa Amazon Simple Storage (Amazon S3), zapewniając znaczące korzyści specjalistom i organizacjom zajmującym się danymi, w tym demokratyzację dostępu do danych w wielu chmurach.
Przegląd Amazon AppFlow
Przepływ aplikacji Amazon to w pełni zarządzana usługa integracji, za pomocą której można bezpiecznie przesyłać dane pomiędzy aplikacjami SaaS, takimi jak Google BigQuery, Salesforce, SAP, Hubspot i ServiceNow, a usługami AWS, takimi jak Amazon S3 i Amazonka Przesunięcie ku czerwieni, za pomocą kilku kliknięć. Dzięki Amazon AppFlow możesz uruchamiać przepływy danych w niemal dowolnej skali i z wybraną częstotliwością – zgodnie z harmonogramem, w odpowiedzi na wydarzenie biznesowe lub na żądanie. Możesz skonfigurować możliwości transformacji danych, takie jak filtrowanie i sprawdzanie poprawności, aby generować bogate, gotowe do użycia dane w ramach samego przepływu, bez dodatkowych kroków. Amazon AppFlow automatycznie szyfruje dane w ruchu i pozwala ograniczyć przepływ danych przez publiczny Internet w przypadku aplikacji SaaS zintegrowanych z Prywatny link AWS, ograniczając narażenie na zagrożenia bezpieczeństwa.
Przedstawiamy łącznik Google BigQuery
Nowa Łącznik Google BigQuery w Amazon AppFlow odkrywa możliwości dla organizacji, które chcą wykorzystać możliwości analityczne hurtowni danych Google i bez wysiłku integrować, analizować, przechowywać lub dalej przetwarzać dane z BigQuery, przekształcając je w przydatne spostrzeżenia.
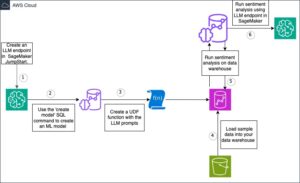
Architektura
Przyjrzyjmy się architekturze przesyłania danych z Google BigQuery do Amazon S3 za pomocą Amazon AppFlow.

- Wybierz źródło danych: In Przepływ aplikacji Amazon, wybierz Google BigQuery jako źródło danych. Określ tabele lub zestawy danych, z których chcesz wyodrębnić dane.
- Mapowanie i transformacja pól: Skonfiguruj transfer danych za pomocą intuicyjnego interfejsu wizualnego Amazon AppFlow. Możesz mapować pola danych i stosować przekształcenia zgodnie z potrzebami, aby dopasować dane do swoich wymagań.
- Częstotliwość przesyłania: Zdecyduj, jak często chcesz przesyłać dane — na przykład codziennie, co tydzień lub co miesiąc — zapewniając elastyczność i automatyzację.
- Miejsce docelowe: określ wiadro S3 jako miejsce docelowe danych. Amazon AppFlow skutecznie przeniesie dane, udostępniając je w pamięci Amazon S3.
- Zużycie: Użyj Amazonka Atena do analizy danych w Amazon S3.
Wymagania wstępne
Zestaw danych używany w tym rozwiązaniu jest generowany przez Syntea, syntetyczny symulator populacji pacjentów i projekt open source w ramach Licencja Apache 2.0. Załaduj te dane do Google BigQuery lub użyj istniejącego zbioru danych.
Połącz Amazon AppFlow ze swoim kontem Google BigQuery
W tym poście używasz konta Google, klienta OAuth z odpowiednimi uprawnieniami i danych Google BigQuery. Aby umożliwić dostęp do Google BigQuery z Amazon AppFlow, musisz wcześniej skonfigurować nowego klienta OAuth. Aby uzyskać instrukcje, zobacz Łącznik Google BigQuery dla Amazon AppFlow.
Skonfiguruj Amazon S3
Każdy obiekt w Amazon S3 jest przechowywany w wiadrze. Zanim będziesz mógł przechowywać dane w Amazon S3, musisz to zrobić utwórz wiadro S3 do przechowywania wyników.
Utwórz nowy segment S3 dla wyników Amazon AppFlow
Aby utworzyć zasobnik S3, wykonaj następujące czynności:
- W konsoli zarządzania AWS dla Amazon S3wybierz Utwórz wiadro.
- Wprowadź unikalny globalnie nazwa dla Twojego wiadra; na przykład,
appflow-bq-sample. - Dodaj Utwórz zasobnik.
Utwórz nowy segment S3 dla wyników Amazon Athena
Aby utworzyć zasobnik S3, wykonaj następujące czynności:
- W konsoli zarządzania AWS dla Amazon S3wybierz Utwórz wiadro.
- Wprowadź unikalny globalnie nazwa dla Twojego wiadra; na przykład,
athena-results. - Dodaj Utwórz zasobnik.
Rola użytkownika (rola IAM) w katalogu danych kleju AWS
Aby móc katalogować dane przesyłane w ramach przepływu, musisz mieć odpowiednią rolę użytkownika Zarządzanie tożsamością i dostępem AWS (IAM). Podajesz tę rolę usłudze Amazon AppFlow, aby przyznać uprawnienia potrzebne do utworzenia pliku Katalog danych kleju AWS, tabele, bazy danych i partycje.
Aby zapoznać się z przykładową polityką uprawnień, która ma wymagane uprawnienia, zobacz Przykłady zasad opartych na tożsamości dla Amazon AppFlow.
Opis projektu
Przeanalizujmy teraz praktyczny przypadek użycia, aby zobaczyć, jak działa złącze Amazon AppFlow Google BigQuery do Amazon S3. W tym przypadku użyjesz Amazon AppFlow do archiwizacji danych historycznych z Google BigQuery do Amazon S3 w celu długoterminowego przechowywania i analizy.
Skonfiguruj Amazon AppFlow
Utwórz nowy przepływ Amazon AppFlow, aby przesyłać dane z Google Analytics do Amazon S3.
- Na Konsola Amazon AppFlowwybierz Utwórz przepływ.
- Wprowadź nazwę przepływu; Na przykład,
my-bq-flow. - Dodaj niezbędne Tagi; na przykład dla Klawisz wchodzić
envi dla wartość wchodzićdev.

- Dodaj Następna.
- W razie zamówieenia projektu Nazwa źródławybierz Google BigQuery.
- Dodaj Utwórz nowe połączenie.
- Wpisz swój OAuth identyfikator klienta i Sekret klienta, a następnie nazwij swoje połączenie; Na przykład,
bq-connection.

- W wyskakującym oknie zezwól witrynie amazon.com na dostęp do interfejsu API Google BigQuery.

- W razie zamówieenia projektu Wybierz obiekt Google BigQuerywybierz Stół.
- W razie zamówieenia projektu Wybierz podobiekt Google BigQuerywybierz NazwaProjektu BigQuery.
- W razie zamówieenia projektu Wybierz podobiekt Google BigQuerywybierz Nazwa bazy danych.
- W razie zamówieenia projektu Wybierz podobiekt Google BigQuerywybierz Nazwa tabeli.
- W razie zamówieenia projektu Nazwa celuwybierz Amazon S3.
- W razie zamówieenia projektu Szczegóły wiadra, wybierz segment Amazon S3, który utworzyłeś do przechowywania wyników Amazon AppFlow w wymaganiach wstępnych.
- Wchodzę
rawjak prefiks.
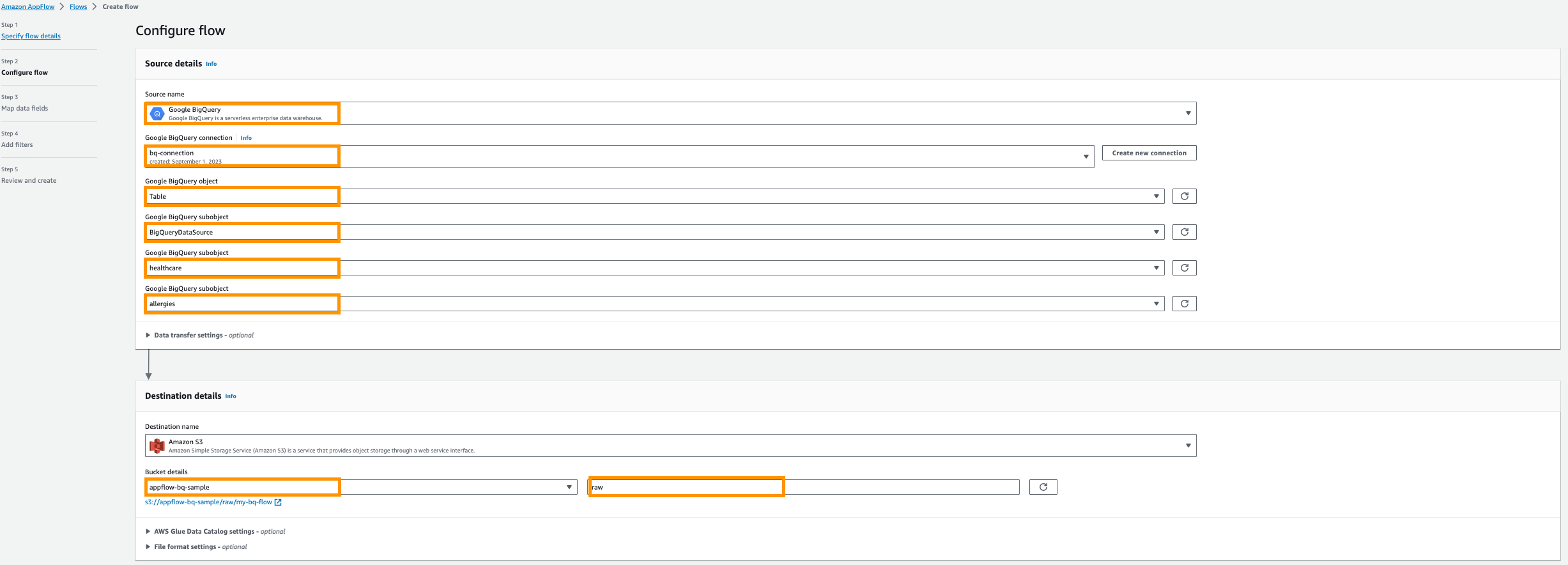
- Następnie podaj Katalog danych kleju AWS ustawienia, aby utworzyć tabelę do dalszej analizy.
- Wybierz Rola użytkownika (rola IAM) utworzona w wymaganiach wstępnych.
- Utwórz nowy baza danych Na przykład,
healthcare. - Zapewnij przedrostek tabeli ustawienie np.
bq.
- Wybierz Uruchom na żądanie.
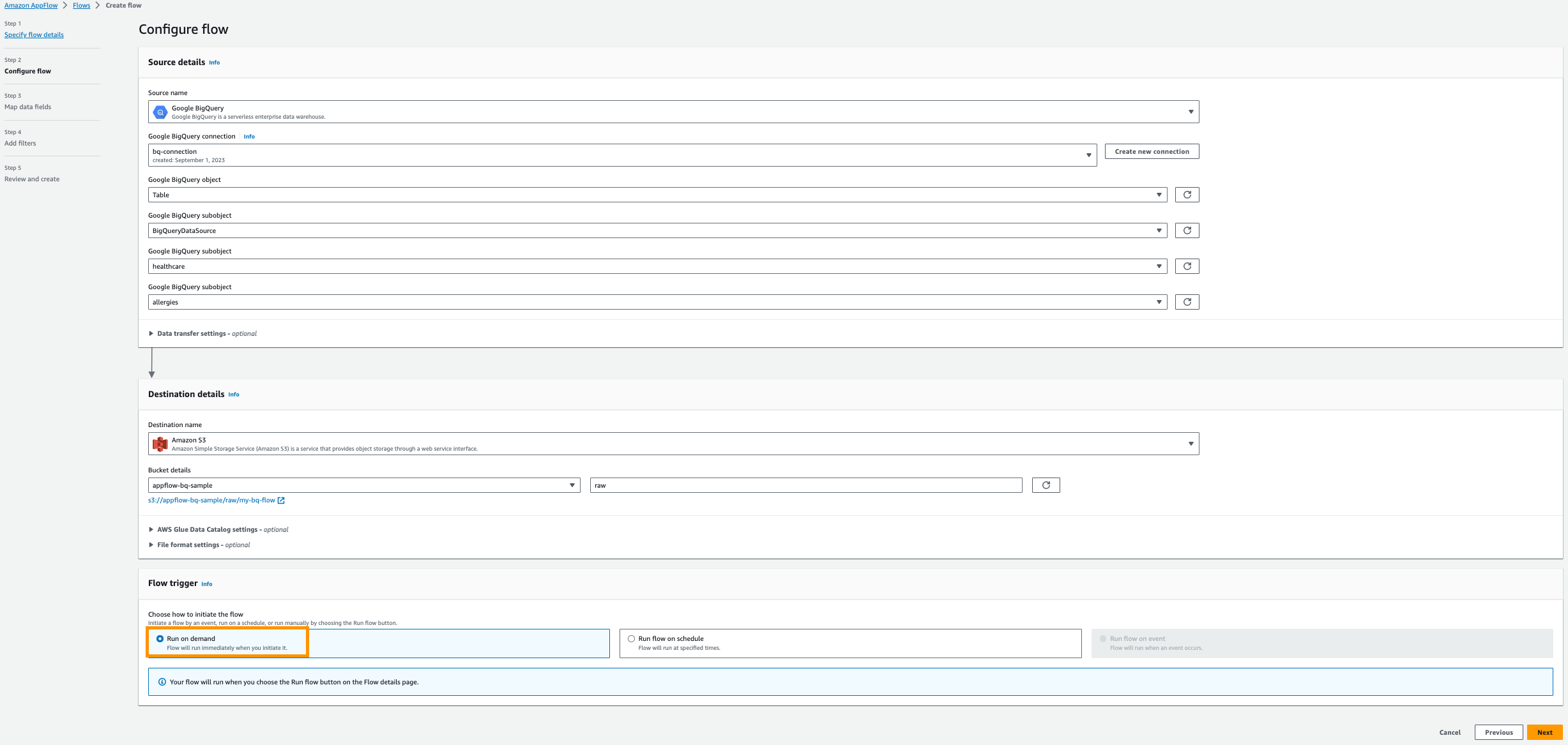
- Dodaj Dalej.
- Wybierz Ręcznie mapuj pola.
- Wybierz następujące sześć pól dla Nazwa pola źródłowego od stołu Alergie:
- Start
- Pacjent
- Code
- Opis
- Rodzaj Nieruchomości
- Kategoria
- Dodaj Bezpośrednio mapuj pola.

- Dodaj Następna.
- In opcję Dodaj filtry Sekcja, wybierz Następna.
- Dodaj Utwórz przepływ.
Uruchom przepływ
Po utworzeniu nowego przepływu możesz go uruchomić na żądanie.
- Na Konsola Amazon AppFlowwybierz
my-bq-flow. - Dodaj Uruchom przepływ.

Na potrzeby tego przewodnika wybierz opcję Uruchom zadanie na żądanie, aby ułatwić zrozumienie. W praktyce można wybrać zaplanowane zadanie i okresowo wyodrębniać tylko nowo dodane dane.
Zapytanie za pośrednictwem Amazon Athena
Po wybraniu opcjonalnych ustawień katalogu danych kleju AWS, katalog danych tworzy katalog danych, umożliwiając usłudze Amazon Athena wykonywanie zapytań.
Jeśli zostanie wyświetlony monit o skonfigurowanie lokalizacji wyników zapytania, przejdź do Ustawienia kartę i wybierz zarządzanie. Pod Zarządzaj ustawieniami, wybierz segment wyników Athena utworzony w wymaganiach wstępnych i wybierz Zapisz.
- Na Konsola Amazon Athenawybierz źródło danych jako
AWSDataCatalog. - Następnie wybierz Baza danych as
healthcare. - Teraz możesz wybrać tabelę utworzoną przez robota AWS Glue i wyświetlić jej podgląd.

- Możesz także uruchomić zapytanie niestandardowe, aby znaleźć 10 najczęstszych alergii, jak pokazano w poniższym zapytaniu.
Note: W poniższym zapytaniu zastąp w tym przypadku nazwę tabeli bq_appflow_mybqflow_1693588670_latest, z nazwą tabeli wygenerowanej na Twoim koncie AWS.
- Dodaj Uruchom zapytanie.

Ten wynik pokazuje 10 najczęstszych alergii według liczby przypadków.
Sprzątać
Aby uniknąć opłat, wyczyść zasoby na swoim koncie AWS, wykonując następujące kroki:
- W konsoli Amazon AppFlow wybierz Przepływy w okienku nawigacji.
- Z listy przepływów wybierz przepływ
my-bq-flowi usuń go. - Wprowadź usuń, aby usunąć przepływ.
- Dodaj połączenia w okienku nawigacji.
- Dodaj Google BigQuery z listy łączników wybierz
bq-connectori usuń go. - Wprowadź usuń, aby usunąć łącznik.
- W konsoli IAM wybierz role na stronie nawigacji, a następnie wybierz rolę utworzoną dla robota AWS Glue i usuń ją.
- Na konsoli Amazon Athena:
- Usuń tabele utworzone w bazie danych
healthcareza pomocą robota AWS Glue. - Usuń bazę danych
healthcare
- Usuń tabele utworzone w bazie danych
- Na konsoli Amazon S3 wyszukaj utworzony zbiór wyników Amazon AppFlow i wybierz pusty , aby usunąć obiekty, a następnie usuń zasobnik.
- Na konsoli Amazon S3 wyszukaj utworzony zbiór wyników Amazon Athena i wybierz pusty , aby usunąć obiekty, a następnie usuń zasobnik.
- Wyczyść zasoby na swoim koncie Google, usuwając projekt zawierający zasoby Google BigQuery. Postępuj zgodnie z dokumentacją do oczyścić zasoby Google.
Wnioski
Łącznik Google BigQuery w Amazon AppFlow usprawnia proces przesyłania danych z hurtowni danych Google do Amazon S3. Integracja ta upraszcza analitykę i uczenie maszynowe, archiwizację i długoterminowe przechowywanie, zapewniając znaczące korzyści specjalistom zajmującym się danymi i organizacjom pragnącym wykorzystać możliwości analityczne obu platform.
Dzięki Amazon AppFlow złożoność integracji danych zostaje wyeliminowana, dzięki czemu możesz skupić się na wyciąganiu praktycznych wniosków z danych. Niezależnie od tego, czy archiwizujesz dane historyczne, przeprowadzasz złożone analizy, czy przygotowujesz dane do uczenia maszynowego, ten łącznik upraszcza ten proces, udostępniając go szerszemu gronu specjalistów ds. danych.
Jeśli ciekawi Cię jak wygląda transfer danych z Google BigQuery do Amazon S3 za pomocą Amazon AppFlow, obejrzyj krok po kroku Samouczek wideo. W tym samouczku omówimy cały proces, od skonfigurowania połączenia po uruchomienie przepływu danych. Aby uzyskać więcej informacji na temat Amazon AppFlow, odwiedź stronę Przepływ aplikacji Amazon.
O autorach
![]() Kartikay Khator jest architektem rozwiązań w globalnej branży Life Science w Amazon Web Services. Jego pasją jest pomaganie klientom w ich podróży do chmury, ze szczególnym uwzględnieniem usług analitycznych AWS. Jest zapalonym biegaczem i lubi wędrówki.
Kartikay Khator jest architektem rozwiązań w globalnej branży Life Science w Amazon Web Services. Jego pasją jest pomaganie klientom w ich podróży do chmury, ze szczególnym uwzględnieniem usług analitycznych AWS. Jest zapalonym biegaczem i lubi wędrówki.
 Kamen Sharlandjiev jest starszym architektem rozwiązań Big Data i ETL oraz ekspertem Amazon AppFlow. Jego misją jest ułatwianie życia klientom stojącym przed złożonymi wyzwaniami związanymi z integracją danych. Jego tajna broń? W pełni zarządzane usługi AWS o niskim poziomie kodu, które mogą wykonać zadanie przy minimalnym wysiłku i bez kodowania.
Kamen Sharlandjiev jest starszym architektem rozwiązań Big Data i ETL oraz ekspertem Amazon AppFlow. Jego misją jest ułatwianie życia klientom stojącym przed złożonymi wyzwaniami związanymi z integracją danych. Jego tajna broń? W pełni zarządzane usługi AWS o niskim poziomie kodu, które mogą wykonać zadanie przy minimalnym wysiłku i bez kodowania.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/
- :ma
- :Jest
- $W GÓRĘ
- 10
- 100
- 14
- 16
- 17
- 22
- 321
- 8
- 9
- a
- zdolność
- O nas
- dostęp
- zarządzanie dostępem
- dostępny
- Konto
- w poprzek
- Dodaj
- w dodatku
- Dodatkowy
- awansować
- wyrównać
- Alergie
- dopuszczać
- Pozwalać
- pozwala
- również
- Amazonka
- Amazonka Atena
- Amazon Web Services
- Amazon.com
- an
- analiza
- Analityczny
- analityka
- w czasie rzeczywistym sprawiają,
- i
- każdy
- api
- aplikacje
- Aplikuj
- właściwy
- architektura
- Archiwum
- SĄ
- AS
- At
- automatycznie
- Automatyzacja
- uniknąć
- AWS
- Klej AWS
- Konsola zarządzania AWS
- być
- zanim
- poniżej
- Korzyści
- pomiędzy
- Duży
- Big Data
- bigQuery
- Blog
- obie
- szerszy
- biznes
- by
- CAN
- Może uzyskać
- możliwości
- zdolność
- walizka
- Etui
- katalog
- Kategoria
- wyzwania
- Opłaty
- Dodaj
- klient
- Chmura
- Kodowanie
- COM
- kompletny
- wypełniając
- kompleks
- złożoności
- połączenie
- Konsola
- zawiera
- crawler
- Stwórz
- stworzony
- tworzy
- Tworzenie
- zwyczaj
- Klientów
- codziennie
- dane
- dostęp do danych
- integracja danych
- hurtownia danych
- sterowane danymi
- Baza danych
- Bazy danych
- zbiory danych
- zdecydować
- Kreowanie
- demokratyzacja
- opis
- miejsce przeznaczenia
- odkryj
- inny
- dokumentacja
- zrobić
- łatwość
- łatwiej
- skutecznie
- wysiłek
- bez wysiłku
- wyłączony
- umożliwiać
- umożliwiając
- Cały
- niezbędny
- Eter (ETH)
- wydarzenie
- przykład
- przykłady
- Przede wszystkim system został opracowany
- ekspert
- odkryj
- Ekspozycja
- wyciąg
- okładzina
- kilka
- pole
- Łąka
- filtracja
- Znajdź
- Elastyczność
- pływ
- Płynący
- Przepływy
- Skupiać
- obserwuj
- następujący
- W razie zamówieenia projektu
- czoło
- Częstotliwość
- często
- od
- w pełni
- dalej
- Generować
- wygenerowane
- otrzymać
- Globalne
- Globalnie
- Google Analytics
- Google'a
- przyznać
- Zarządzanie
- uprząż
- Have
- he
- opieki zdrowotnej
- pomoc
- turystyka
- jego
- historyczny
- W jaki sposób
- HTML
- http
- HTTPS
- HubSpot
- IAM
- tożsamość
- zarządzanie tożsamością i dostępem
- in
- Włącznie z
- Informacja
- spostrzeżenia
- instrukcje
- integrować
- zintegrowany
- integracja
- zainteresowany
- Interfejs
- Internet
- najnowszych
- intuicyjny
- IT
- samo
- Praca
- podróż
- właśnie
- nauka
- Licencja
- życie
- Life Science
- LIMIT
- Lista
- załadować
- lokalizacja
- długoterminowy
- Popatrz
- maszyna
- uczenie maszynowe
- robić
- Dokonywanie
- zarządzane
- i konserwacjami
- mapa
- mapowanie
- minimalny
- Misja
- jeszcze
- ruch
- ruch
- musi
- Nazwa
- Nawigacja
- Nawigacja
- prawie
- niezbędny
- potrzebne
- wymagania
- Nowości
- nowo
- Nie
- już dziś
- numer
- przysięgać
- przedmiot
- obiekty
- of
- on
- Na żądanie
- tylko
- opensource
- or
- zamówienie
- organizacji
- koniec
- strona
- chleb
- część
- namiętny
- pacjent
- wykonać
- wykonywania
- uprawnienia
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- pop-up
- populacja
- możliwości
- Post
- Praktyczny
- praktyka
- przygotowanie
- warunki wstępne
- Podgląd
- wygląda tak
- specjalistów
- projekt
- zapewniać
- że
- publiczny
- zapytania
- zasięg
- redukcja
- obsługi produkcji rolnej, która zastąpiła
- wymagany
- wymagania
- Zasoby
- odpowiedź
- ograniczać
- dalsze
- Efekt
- przeglądu
- Bogaty
- Rola
- run
- biegacz
- bieganie
- SaaS
- sprzedawca
- SAP
- Skala
- rozkład
- zaplanowane
- nauka
- Szukaj
- Tajemnica
- Sekcja
- bezpiecznie
- bezpieczeństwo
- Zagrożenia bezpieczeństwa
- widzieć
- poszukuje
- usługa
- ServiceNow
- Usługi
- zestaw
- ustawienie
- w panelu ustawień
- pokazane
- Targi
- znaczący
- Prosty
- upraszczać
- symulator
- SIX
- Tworzenie
- Oprogramowanie jako usługa
- rozwiązanie
- Rozwiązania
- Źródło
- Cel
- przechowywanie
- sklep
- przechowywany
- usprawnienie
- taki
- syntetyczny
- stół
- Brać
- że
- Połączenia
- ich
- następnie
- to
- zagrożenia
- Przez
- do
- dzisiaj
- Top
- Top 10
- przenieść
- Przesyłanie
- Transformacja
- przemiany
- transformatorowy
- Tutorial
- rodzaj
- dla
- zrozumienie
- wyjątkowy
- Odsłonięto
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- za pomocą
- uprawomocnienie
- wartość
- Odwiedzić
- spacer
- solucja
- chcieć
- Magazyn
- we
- sieć
- usługi internetowe
- tygodniowy
- czy
- KIM
- będzie
- okno
- w
- bez
- działa
- świat
- ty
- Twój
- youtube
- zefirnet