Organizacje we wszystkich branżach mają złożone wymagania dotyczące przetwarzania danych w swoich analitycznych przypadkach użycia w różnych systemach analitycznych, takich jak jeziora danych w AWS, magazyn danych (Amazonka Przesunięcie ku czerwieni), szukaj (Usługa Amazon OpenSearch), NoSQL (Amazon DynamoDB), nauczanie maszynowe (Amazon Sage Maker), i więcej. Specjaliści ds. analityki mają za zadanie czerpać wartość z danych przechowywanych w tych rozproszonych systemach, aby tworzyć lepsze, bezpieczniejsze i zoptymalizowane pod względem kosztów doświadczenia dla swoich klientów. Na przykład firmy zajmujące się mediami cyfrowymi starają się łączyć i przetwarzać zbiory danych w wewnętrznych i zewnętrznych bazach danych, aby tworzyć ujednolicone widoki profili swoich klientów, pobudzać pomysły na innowacyjne funkcje i zwiększać zaangażowanie platformy.
W tych scenariuszach korzystają klienci poszukujący oferty integracji danych bez serwera Klej AWS jako główny komponent do przetwarzania i katalogowania danych. AWS Glue jest dobrze zintegrowany z usługami AWS i produktami partnerów oraz zapewnia opcje wyodrębniania, przekształcania i ładowania (ETL) z małą ilością kodu lub bez kodu, aby umożliwić przepływy pracy związane z analizą, uczeniem maszynowym (ML) lub tworzeniem aplikacji. Zadania AWS Glue ETL mogą być jednym z elementów bardziej złożonego potoku. Orkiestrowanie przebiegu i zarządzanie zależnościami między tymi komponentami to kluczowa umiejętność w strategii danych. Przepływy pracy zarządzane przez Amazon dla Apache Airflows (Amazon MWAA) organizuje potoki danych przy użyciu rozproszonych technologii, w tym zasobów lokalnych, usług AWS i komponentów innych firm.
W tym poście pokazujemy, jak uprościć monitorowanie zadania AWS Glue zorganizowanego przez Airflow przy użyciu najnowszych funkcji Amazon MWAA.
Przegląd rozwiązania
W tym poście omówiono następujące kwestie:
- Jak zaktualizować środowisko Amazon MWAA do wersji 2.4.3.
- Jak zorganizować zadanie AWS Glue z Airflow Skierowany graf acykliczny (DAG).
- Ulepszenia obserwowalności pakietu dostawcy Airflow Amazon w Amazon MWAA. Możesz teraz skonsolidować dzienniki uruchomień zadań AWS Glue w konsoli Airflow, aby uprościć rozwiązywanie problemów z potokami danych. Konsola Amazon MWAA staje się pojedynczym punktem odniesienia do monitorowania i analizowania uruchomień zadań AWS Glue. Wcześniej zespoły pomocy technicznej potrzebowały dostępu do plików Konsola zarządzania AWS i podejmij ręczne kroki w celu uzyskania tej widoczności. Ta funkcja jest domyślnie dostępna w Amazon MWAA w wersji 2.4.3.
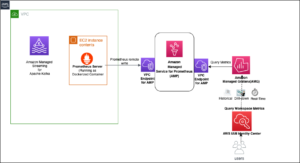
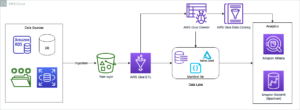
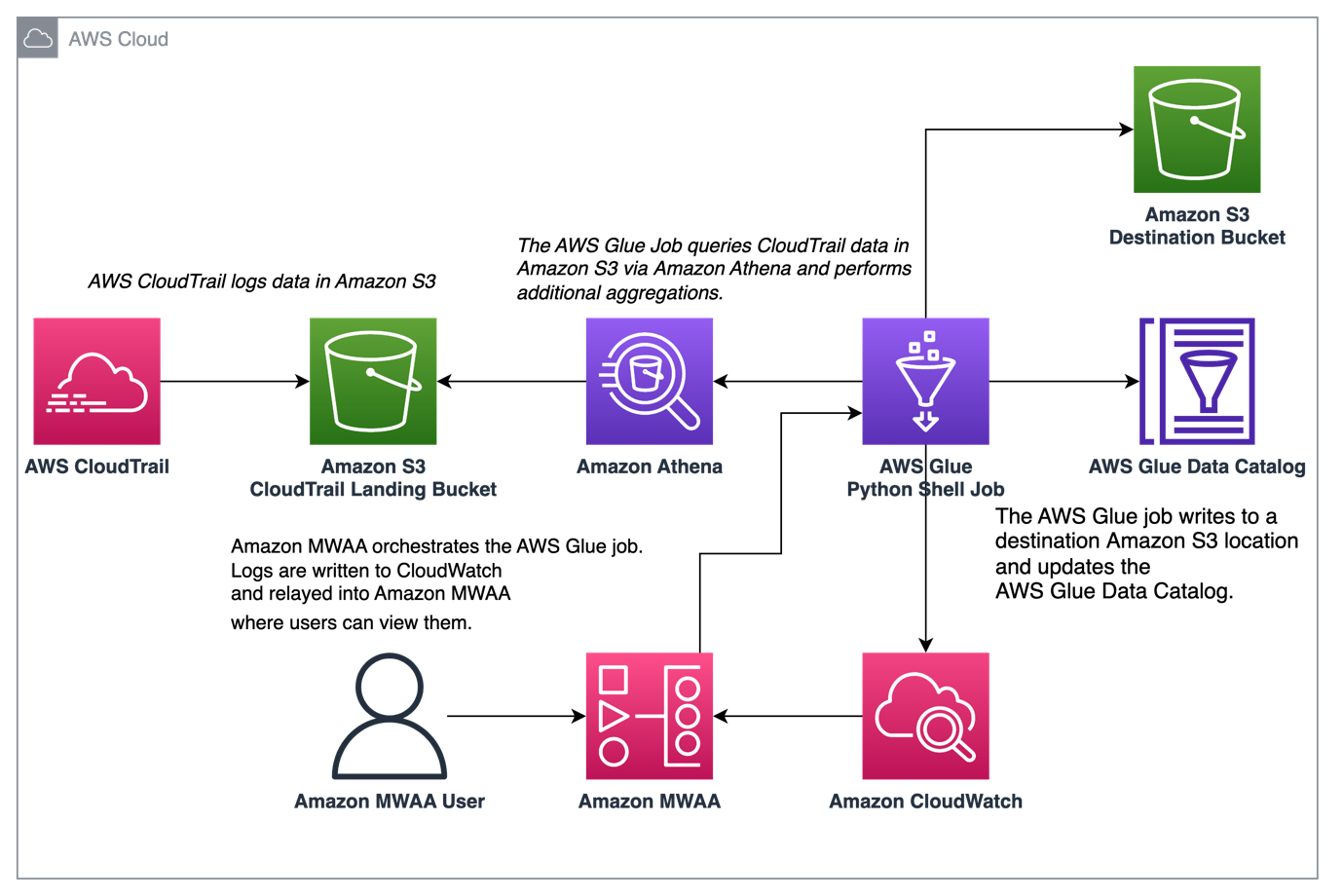
Poniższy diagram ilustruje naszą architekturę rozwiązania.
Wymagania wstępne
Potrzebujesz następujących wymagań wstępnych:
Skonfiguruj środowisko Amazon MWAA
Aby uzyskać instrukcje dotyczące tworzenia środowiska, zobacz Stwórz środowisko Amazon MWAA. Obecnym użytkownikom zalecamy aktualizację do wersji 2.4.3, aby skorzystać z ulepszeń obserwowalności opisanych w tym poście.
Kroki aktualizacji Amazon MWAA do wersji 2.4.3 różnią się w zależności od tego, czy aktualna wersja to 1.10.12 czy 2.2.2. Omówimy obie opcje w tym poście.
Wymagania wstępne dotyczące konfigurowania środowiska Amazon MWAA
Musisz spełnić następujące wymagania wstępne:
Aktualizacja z wersji 1.10.12 do 2.4.3
Jeśli używasz wersji Amazon MWAA 1.10.12, odnosić się do Migracja do nowego środowiska Amazon MWAA uaktualnić do wersji 2.4.3.
Uaktualnij z wersji 2.0.2 lub 2.2.2 do 2.4.3
Jeśli używasz środowiska Amazon MWAA w wersji 2.2.2 lub starszej, wykonaj następujące czynności:
- Stwórz wymagania.txt dla wszelkich niestandardowych zależności z określonymi wersjami wymaganymi dla twoich DAG.
- Prześlij plik do Amazon S3 w odpowiedniej lokalizacji, w której środowisko Amazon MWAA wskazuje na wymagania.txt do instalacji zależności.
- Postępuj zgodnie z instrukcjami w Migracja do nowego środowiska Amazon MWAA i wybierz wersję 2.4.3.
Zaktualizuj swoje DAG
Klienci, którzy dokonali aktualizacji ze starszego środowiska Amazon MWAA, mogą potrzebować aktualizacji istniejących DAG. W Airflow w wersji 2.4.3 środowisko Airflow domyślnie korzysta z pakietu dostawcy Amazon w wersji 6.0.0. Ten pakiet może zawierać pewne potencjalnie szkodliwe zmiany, takie jak zmiany w nazwach operatorów. Na przykład Operator AWSGlueJob został wycofany i zastąpiony przez Operator aplikacji GlueJob. Aby zachować kompatybilność, zaktualizuj DAG Airflow, zastępując przestarzałe lub nieobsługiwane operatory z poprzednich wersji nowymi. Wykonaj następujące kroki:
- Nawigować do Operatorzy Amazon AWS.
- Wybierz odpowiednią wersję zainstalowaną w Twojej instancji Amazon MWAA (domyślnie 6.0.0.), aby znaleźć listę obsługiwanych operatorów Airflow.
- Wprowadź niezbędne zmiany w istniejącym kodzie DAG i prześlij zmodyfikowane pliki do lokalizacji DAG w Amazon S3.
Zorganizuj zadanie AWS Glue z Airflow
Ta sekcja zawiera szczegółowe informacje na temat orkiestracji zadania AWS Glue w ramach DAG Airflow. Airflow ułatwia tworzenie potoków danych z zależnościami między systemami heterogenicznymi, takimi jak procesy lokalne, zależności zewnętrzne, inne usługi AWS i nie tylko.
Zorganizuj agregację dzienników CloudTrail za pomocą AWS Glue i Amazon MWAA
W tym przykładzie omawiamy przypadek użycia Amazon MWAA do zorganizowania zadania AWS Glue Python Shell, które utrzymuje zagregowane metryki na podstawie dzienników CloudTrail.
CloudTrail umożliwia wgląd w wywołania API AWS, które są wykonywane na Twoim koncie AWS. Typowym przypadkiem użycia tych danych byłoby zebranie metryk użycia dotyczących zleceniodawców działających na zasobach Twojego konta na potrzeby audytu i przepisów.
Gdy zdarzenia CloudTrail są rejestrowane, są one dostarczane jako pliki JSON w Amazon S3, które nie są idealne do zapytań analitycznych. Chcemy agregować te dane i utrwalać je jako pliki Parquet, aby umożliwić optymalną wydajność zapytań. Jako pierwszy krok możemy użyć Atheny do wykonania wstępnego zapytania o dane przed wykonaniem dodatkowych agregacji w naszym zadaniu AWS Glue. Aby uzyskać więcej informacji na temat tworzenia tabeli AWS Glue Data Catalog, zobacz Tworzenie tabeli dla logów CloudTrail w Athenie przy użyciu projekcji partycji dane. Po zbadaniu danych za pośrednictwem Atheny i podjęciu decyzji, jakie metryki chcemy zachować w tabelach zbiorczych, możemy utworzyć zadanie AWS Glue.
Utwórz tabelę CloudTrail w Athenie
Najpierw musimy utworzyć tabelę w naszym Data Catalog, która umożliwi przeszukiwanie danych CloudTrail za pośrednictwem Atheny. Poniższe przykładowe zapytanie tworzy tabelę z dwiema partycjami w regionie i dacie (o nazwie snapshot_date). Pamiętaj o zastąpieniu symboli zastępczych zasobnika CloudTrail, identyfikatora konta AWS i nazwy tabeli CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Uruchom poprzednie zapytanie w konsoli Athena i zanotuj nazwę tabeli oraz bazę danych AWS Glue Data Catalog, w której została utworzona. Używamy tych wartości później w kodzie DAG przepływu powietrza.
Przykładowy kod zadania AWS Glue
Poniższy kod jest przykładem Zadanie AWS Glue Python Shell który wykonuje następujące czynności:
- Przyjmuje argumenty (które przekazujemy z naszego Amazon MWAA DAG) na temat tego, którego dnia dane mają być przetwarzane
- Wykorzystuje AWS SDK dla Pand aby uruchomić zapytanie Athena, aby wykonać wstępne filtrowanie danych CloudTrail JSON poza AWS Glue
- Używa Pand do wykonywania prostych agregacji filtrowanych danych
- Wysyła zagregowane dane do AWS Glue Data Catalog w formie tabeli
- Używa logowania podczas przetwarzania, które będzie widoczne w Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Oto kilka kluczowych zalet tego zadania AWS Glue:
- Używamy zapytania Athena, aby upewnić się, że wstępne filtrowanie odbywa się poza naszym zadaniem AWS Glue. W związku z tym zadanie Python Shell z minimalnymi mocami obliczeniowymi jest nadal wystarczające do agregowania dużego zestawu danych CloudTrail.
- zapewniamy opcja zestawu bibliotek analitycznych jest włączony podczas tworzenia naszego zadania AWS Glue, aby korzystać z biblioteki AWS SDK for Pandas.
Utwórz zadanie AWS Glue
Wykonaj następujące kroki, aby utworzyć zadanie AWS Glue:
- Skopiuj skrypt z poprzedniej sekcji i zapisz go w pliku lokalnym. W tym poście plik nazywa się
script.py. - Na konsoli AWS Glue wybierz zadania ETL w okienku nawigacji.
- Utwórz nową pracę i wybierz Edytor skryptów Python Shell.
- Wybierz Prześlij i edytuj istniejący skrypt i prześlij plik zapisany lokalnie.
- Dodaj Stwórz.

- Na Szczegóły pracy wprowadź nazwę zadania AWS Glue.
- W razie zamówieenia projektu Rola IAM, wybierz istniejącą rolę lub utwórz nową rolę, która ma wymagane uprawnienia dla Amazon S3, AWS Glue i Athena. Rola musi wysłać zapytanie do utworzonej wcześniej tabeli CloudTrail i zapisać ją w lokalizacji wyjściowej.
Możesz użyć następującego przykładowego kodu zasad. Zastąp symbole zastępcze zasobnikiem dzienników CloudTrail, nazwą tabeli wyjściowej, wyjściową bazą danych AWS Glue, wyjściowym zasobnikiem S3, nazwą tabeli CloudTrail, bazą danych AWS Glue zawierającą tabelę CloudTrail oraz identyfikatorem konta AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
W razie zamówieenia projektu Wersja Pythonawybierz Python 3.9.
- Wybierz Załaduj wspólne biblioteki analityczne.
- W razie zamówieenia projektu Jednostki przetwarzania danychwybierz 1 DPU.
- Pozostałe opcje pozostaw jako domyślne lub dostosuj według potrzeb.

- Dodaj Zapisz aby zapisać konfigurację zadania.
Skonfiguruj Amazon MWAA DAG do orkiestracji zadania AWS Glue
Poniższy kod dotyczy DAG, który może zorganizować utworzone przez nas zadanie AWS Glue. Korzystamy z następujących kluczowych funkcji tego DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Zwiększ obserwowalność zadań AWS Glue w Amazon MWAA
Zadania AWS Glue zapisują dzienniki Amazon Cloud Watch. Dzięki ostatnim ulepszeniom obserwowalności w pakiecie dostawcy Amazon firmy Airflow te dzienniki są teraz zintegrowane z dziennikami zadań Airflow. Ta konsolidacja zapewnia użytkownikom Airflow kompleksową widoczność bezpośrednio w interfejsie użytkownika Airflow, eliminując potrzebę wyszukiwania w CloudWatch lub konsoli AWS Glue.
Aby korzystać z tej funkcji, upewnij się, że rola IAM połączona ze środowiskiem Amazon MWAA ma następujące uprawnienia do pobierania i zapisywania niezbędnych dzienników:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Jeśli verbose=true, dzienniki uruchomień zadania AWS Glue są wyświetlane w dziennikach zadań Airflow. Wartość domyślna to fałsz. Aby uzyskać więcej informacji, patrz parametry.
Po włączeniu DAG odczytują strumień dziennika CloudWatch zadania AWS Glue i przekazują je do dzienników kroków zadania Airflow DAG AWS Glue. Zapewnia to szczegółowy wgląd w przebieg zadania AWS Glue w czasie rzeczywistym za pośrednictwem dzienników DAG. Pamiętaj, że zadania AWS Glue generują dane wyjściowe i grupę dzienników błędów CloudWatch na podstawie odpowiednio STDOUT i STDERR zadania. Wszystkie dzienniki w grupie dzienników wyjściowych oraz dzienniki wyjątków lub błędów z grupy dzienników błędów są przekazywane do Amazon MWAA.
Administratorzy AWS mogą teraz ograniczyć dostęp zespołu wsparcia tylko do Airflow, dzięki czemu Amazon MWAA jest pojedynczą szybą w zakresie orkiestracji zadań i zarządzania stanem pracy. Wcześniej użytkownicy musieli sprawdzać stan uruchomienia zadania AWS Glue w krokach Airflow DAG i pobierać identyfikator uruchomienia zadania. Następnie musieli uzyskać dostęp do konsoli AWS Glue, aby znaleźć historię uruchamiania zadania, wyszukać interesujące go zadanie za pomocą identyfikatora, a na koniec przejść do dzienników zadania CloudWatch w celu rozwiązania problemu.
Utwórz DAG
Aby utworzyć DAG, wykonaj następujące kroki:
- Zapisz poprzedni kod DAG w lokalnym pliku .py, zastępując wskazane symbole zastępcze.
Wartości identyfikatora konta AWS, nazwy zadania AWS Glue, bazy danych AWS Glue z tabelą CloudTrail i nazwy tabeli CloudTrail powinny być już znane. W razie potrzeby możesz dostosować wyjściowy zasobnik S3, wyjściową bazę danych AWS Glue i nazwę tabeli wyjściowej, ale upewnij się, że rola IAM zadania AWS Glue, której używałeś wcześniej, jest odpowiednio skonfigurowana.
- W konsoli Amazon MWAA przejdź do swojego środowiska, aby zobaczyć, gdzie jest przechowywany kod DAG.
Folder DAGs to prefiks w zasobniku S3, w którym należy umieścić plik DAG.
- Prześlij tam edytowany plik.

- Otwórz konsolę Amazon MWAA, aby potwierdzić, że DAG pojawia się w tabeli.

Uruchom DAG
Aby uruchomić DAG, wykonaj następujące kroki:
- Wybierz jedną z następujących opcji:
- Wyzwalaj DAG – Powoduje to, że jako dane do przetworzenia zostaną użyte wczorajsze dane
- Wyzwalacz DAG z konfiguracją – Dzięki tej opcji możesz podać inną datę, potencjalnie dla zasypek, która jest pobierana za pomocą
dag_run.confw kodzie DAG, a następnie przekazany do zadania AWS Glue jako parametr

Poniższy zrzut ekranu pokazuje dodatkowe opcje konfiguracji, jeśli wybierzesz Wyzwalacz DAG z konfiguracją.

- Monitoruj DAG podczas jego działania.
- Po zakończeniu DAG otwórz szczegóły przebiegu.
W prawym okienku możesz wyświetlić dzienniki lub wybrać Szczegóły instancji zadania dla pełnego widoku.

- Przeglądaj dzienniki wyjściowe zadania AWS Glue w Amazon MWAA bez korzystania z konsoli AWS Glue dzięki
GlueJobOperatorgadatliwa flaga.

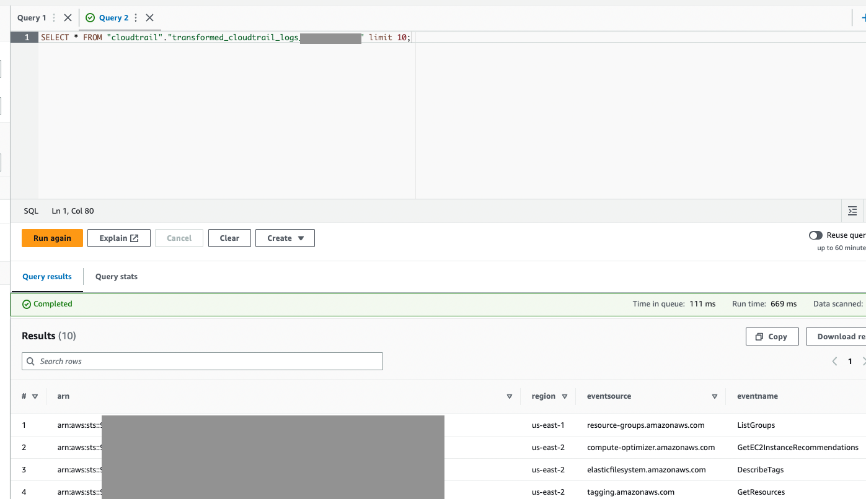
Zadanie AWS Glue będzie miało zapisane wyniki w określonej tabeli wyjściowej.
- Zapytanie o tę tabelę za pośrednictwem Ateny, aby potwierdzić, że się powiodło.
Podsumowanie
Amazon MWAA zapewnia teraz jedno miejsce do śledzenia statusu zadań AWS Glue i umożliwia korzystanie z konsoli Airflow jako pojedynczej szyby do orkiestracji zadań i zarządzania stanem. W tym poście omówiliśmy kroki orkiestracji zadań AWS Glue za pomocą Airflow GlueJobOperator. Dzięki nowym ulepszeniom obserwowalności możesz bezproblemowo rozwiązywać problemy z zadaniami AWS Glue w ujednoliconym środowisku. Pokazaliśmy również, jak zaktualizować środowisko Amazon MWAA do kompatybilnej wersji, zaktualizować zależności i odpowiednio zmienić zasady ról IAM.
Aby uzyskać więcej informacji na temat typowych kroków rozwiązywania problemów, zobacz Rozwiązywanie problemów: tworzenie i aktualizowanie środowiska Amazon MWAA. Aby uzyskać szczegółowe informacje na temat migracji do środowiska Amazon MWAA, zobacz Aktualizacja z 1.10 do 2. Aby dowiedzieć się o zmianach kodu open source w celu zwiększenia obserwowalności zadań AWS Glue w pakiecie dostawcy Airflow Amazon, zapoznaj się z przekazywać logi z zadań AWS Glue.
Na koniec polecamy odwiedzić tzw Blog AWS Big Data inne materiały dotyczące analityki, uczenia maszynowego i zarządzania danymi w AWS.
O autorach
 Rushabh Lokhande jest inżynierem danych i uczenia maszynowego z praktyką analizy usług profesjonalnych AWS. Pomaga klientom wdrażać rozwiązania big data, machine learning i analityczne. Poza pracą lubi spędzać czas z rodziną, czytać, biegać i grać w golfa.
Rushabh Lokhande jest inżynierem danych i uczenia maszynowego z praktyką analizy usług profesjonalnych AWS. Pomaga klientom wdrażać rozwiązania big data, machine learning i analityczne. Poza pracą lubi spędzać czas z rodziną, czytać, biegać i grać w golfa.
 Ryana Gomesa jest inżynierem danych i uczenia maszynowego z praktyką analizy usług profesjonalnych AWS. Pasjonuje się pomaganiem klientom w osiąganiu lepszych wyników dzięki rozwiązaniom analitycznym i uczeniu maszynowym w chmurze. Poza pracą lubi fitness, gotowanie i spędzanie czasu z przyjaciółmi i rodziną.
Ryana Gomesa jest inżynierem danych i uczenia maszynowego z praktyką analizy usług profesjonalnych AWS. Pasjonuje się pomaganiem klientom w osiąganiu lepszych wyników dzięki rozwiązaniom analitycznym i uczeniu maszynowym w chmurze. Poza pracą lubi fitness, gotowanie i spędzanie czasu z przyjaciółmi i rodziną.
 Wiśwa Gupta jest starszym architektem danych w AWS Professional Services Analytics Practice. Pomaga klientom wdrażać rozwiązania big data i analityczne. Poza pracą lubi spędzać czas z rodziną, podróżować i próbować nowych potraw.
Wiśwa Gupta jest starszym architektem danych w AWS Professional Services Analytics Practice. Pomaga klientom wdrażać rozwiązania big data i analityczne. Poza pracą lubi spędzać czas z rodziną, podróżować i próbować nowych potraw.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 12
- 8
- a
- O nas
- dostęp
- odpowiednio
- Konto
- Osiągać
- w poprzek
- Działania
- acykliczny
- Dodatkowy
- Korzyść
- Zalety
- Po
- zbiór
- Wszystkie kategorie
- dopuszczać
- pozwala
- już
- również
- Amazonka
- Amazon Web Services
- an
- Analityczny
- analityka
- w czasie rzeczywistym sprawiają,
- i
- każdy
- Apache
- api
- Zastosowanie
- Application Development
- właściwy
- architektura
- SĄ
- argument
- argumenty
- AS
- At
- atrybuty
- audytu
- dostępny
- AWS
- Klej AWS
- Usługi profesjonalne AWS
- na podstawie
- BE
- staje się
- być
- zanim
- jest
- Ulepsz Swój
- pomiędzy
- Duży
- Big Data
- obie
- Przełamując
- budować
- ale
- by
- nazywa
- Połączenia
- CAN
- walizka
- Etui
- katalog
- Przyczyny
- zmiana
- Zmiany
- ZOBACZ
- Dodaj
- Chmura
- kod
- COM
- połączyć
- komentarz
- wspólny
- Firmy
- zgodność
- zgodny
- kompletny
- kompleks
- składnik
- składniki
- obliczać
- systemu
- Potwierdzać
- Konsola
- konsolidować
- konsolidacja
- gotowanie
- rdzeń
- obejmuje
- Stwórz
- stworzony
- tworzy
- Tworzenie
- Aktualny
- zwyczaj
- klient
- Klientów
- DZIEŃ
- dane
- integracja danych
- analiza danych
- strategia danych
- magazyn danych
- Baza danych
- Bazy danych
- zbiory danych
- Data
- Daty
- data i godzina
- Dni
- postanowiła
- Domyślnie
- dostarczona
- wykazać
- W zależności
- przestarzałe
- szczegółowe
- detale
- oprogramowania
- różnić się
- różne
- cyfrowy
- Cyfrowe media
- bezpośrednio
- dyskutować
- dystrybuowane
- systemy rozproszone
- do
- robi
- robi
- zrobić
- podczas
- e
- Wcześniej
- Łatwość
- efekt
- eliminując
- więcej
- umożliwiać
- włączony
- Umożliwia
- koniec końców
- zaręczynowy
- inżynier
- ulepszenia
- zapewnić
- Wchodzę
- Środowisko
- błąd
- Eter (ETH)
- wydarzenia
- przykład
- Z wyjątkiem
- wyjątek
- istnieć
- Przede wszystkim system został opracowany
- istnieje
- doświadczenie
- Doświadczenia
- zbadane
- wyrażenie
- zewnętrzny
- wyciąg
- Failed
- fałszywy
- członków Twojej rodziny
- Cecha
- polecane
- Korzyści
- filet
- Akta
- filtracja
- W końcu
- Znajdź
- ZDROWIE I FITNESS
- następujący
- jedzenie
- W razie zamówieenia projektu
- format
- przyjaciele
- od
- pełny
- zbierać
- Generować
- szkło
- Go
- golf
- zarządzanie
- Zarządzanie
- Hadoop
- Have
- he
- Zdrowie
- pomoc
- pomaga
- historia
- Ul
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- idealny
- pomysły
- identyfikator
- if
- ilustruje
- wdrożenia
- importować
- in
- informacje
- zawierać
- Włącznie z
- Zwiększać
- wzrosła
- wskazany
- przemysłowa
- Informacje
- Informacja
- początkowy
- Innowacyjny
- spostrzeżenia
- Instalacja
- przykład
- instrukcje
- zintegrowany
- integracja
- odsetki
- wewnętrzny
- najnowszych
- IT
- Praca
- Oferty pracy
- jpg
- json
- Klawisz
- znany
- duży
- później
- firmy
- UCZYĆ SIĘ
- nauka
- Biblioteka
- LIMIT
- Lista
- załadować
- miejscowy
- lokalnie
- lokalizacja
- log
- zalogowany
- zalogowaniu
- poszukuje
- maszyna
- uczenie maszynowe
- zrobiony
- utrzymać
- robić
- Dokonywanie
- zarządzane
- i konserwacjami
- zarządzający
- podręcznik
- materiał
- Może..
- Media
- Poznaj nasz
- wiadomość
- Metryka
- migracja
- minimalny
- ML
- zmodyfikowano
- moduł
- monitor
- monitorowanie
- jeszcze
- musi
- Nazwa
- Nazwy
- Nawigacja
- Nawigacja
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- Nowości
- nic
- już dziś
- of
- oferuje
- on
- ONE
- te
- tylko
- koncepcja
- open source
- kod open source
- operator
- operatorzy
- Optymalny
- Option
- Opcje
- or
- orkiestrowany
- orkiestracja
- Inne
- ludzkiej,
- wyniki
- wydajność
- zewnętrzne
- pakiet
- pandy
- chleb
- parametry
- partnerem
- przechodzić
- minęło
- namiętny
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- utrzymuje się
- rurociąg
- Miejsce
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- zwrotnica
- polityka
- Post
- potencjalnie
- praktyka
- warunki wstępne
- poprzedni
- poprzednio
- wygląda tak
- procesów
- przetwarzanie
- Produkty
- profesjonalny
- specjalistów
- profile
- Projekcja
- dostawca
- dostawców
- zapewnia
- Python
- jakość
- zapytania
- podnieść
- zasięg
- Czytaj
- Czytający
- real
- w czasie rzeczywistym
- niedawny
- polecić
- region
- regulacyjne
- Przekaźnik
- obsługi produkcji rolnej, która zastąpiła
- otrzymuje
- wymagany
- wymagania
- Zasób
- Zasoby
- odpowiednio
- odpowiedź
- Efekt
- zachować
- prawo
- Rola
- RZĄD
- run
- bieganie
- s
- Zapisz
- scenariusze
- Sdk
- płynnie
- Szukaj
- Sekcja
- bezpieczne
- widzieć
- Szukajcie
- senior
- Bezserwerowe
- Usługi
- ustawienie
- ustawienie
- Powłoka
- powinien
- pokazać
- Targi
- Prosty
- upraszczać
- ponieważ
- pojedynczy
- Migawka
- rozwiązanie
- Rozwiązania
- kilka
- specyficzny
- określony
- Spędzanie
- Zestawienie sprzedaży
- Rynek
- Ewolucja krok po kroku
- Cel
- Nadal
- przechowywanie
- przechowywany
- Strategia
- strumień
- sznur
- udany
- taki
- wystarczający
- wsparcie
- Utrzymany
- systemy
- stół
- Brać
- biorąc
- Zadanie
- Zespoły
- Technologies
- szablon
- dzięki
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- Te
- one
- innych firm
- to
- Przez
- czas
- do
- śledzić
- Przekształcać
- Podróżowanie
- prawdziwy
- próbować
- Wtorek
- Obrócony
- drugiej
- rodzaj
- ui
- Ujednolicony
- jednostka
- Aktualizacja
- Nowości
- aktualizowanie
- uaktualnienie
- zmodernizowane
- Uploading
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- Użytkownicy
- za pomocą
- wartość
- Wartości
- wersja
- przez
- Zobacz i wysłuchaj
- widoki
- widoczność
- widoczny
- chodził
- chcieć
- była
- we
- sieć
- usługi internetowe
- DOBRZE
- Co
- jeśli chodzi o komunikację i motywację
- czy
- który
- KIM
- będzie
- w
- w ciągu
- bez
- Praca
- przepływów pracy
- by
- napisać
- napisany
- ty
- Twój
- zefirnet