Duże modele językowe (LLM) stają się coraz bardziej popularne, a nowe przypadki ich użycia są stale badane. Ogólnie rzecz biorąc, można tworzyć aplikacje oparte na LLM, włączając szybką inżynierię do swojego kodu. Są jednak przypadki, w których monitowanie istniejącego LLM jest niewystarczające. Tutaj pomocne może być dostrojenie modelu. Szybka inżynieria polega na kierowaniu wynikami modelu poprzez tworzenie podpowiedzi wejściowych, natomiast dostrajanie polega na trenowaniu modelu na niestandardowych zbiorach danych, aby lepiej pasował do określonych zadań lub domen.
Zanim będziesz mógł dostroić model, musisz znaleźć zbiór danych specyficzny dla zadania. Jednym z powszechnie używanych zbiorów danych jest Wspólny zbiór danych indeksowania. Korpus Common Crawl zawiera petabajty danych, gromadzonych regularnie od 2008 roku, i zawiera nieprzetworzone dane stron internetowych, ekstrakty metadanych i ekstrakty tekstu. Oprócz określenia, który zbiór danych powinien zostać użyty, wymagane jest oczyszczenie i przetworzenie danych zgodnie z konkretnymi potrzebami dostrajania.
Niedawno współpracowaliśmy z klientem, który chciał wstępnie przetworzyć podzbiór najnowszego zbioru danych Common Crawl, a następnie dostroić swoje LLM za pomocą wyczyszczonych danych. Klient szukał sposobu, w jaki mógłby to osiągnąć w najbardziej opłacalny sposób w AWS. Po omówieniu wymagań zarekomendowaliśmy użycie Bezserwerowe Amazon EMR jako platforma do wstępnego przetwarzania danych. EMR Serverless doskonale nadaje się do przetwarzania danych na dużą skalę i eliminuje potrzebę konserwacji infrastruktury. Jeśli chodzi o koszty, opłaty są naliczane wyłącznie w oparciu o zasoby i czas trwania każdego zadania. Klientowi udało się wstępnie przetworzyć setki TB danych w ciągu tygodnia, korzystając z rozwiązania EMR Serverless. Po wstępnym przetworzeniu danych wykorzystali je Amazon Sage Maker aby dostroić LLM.
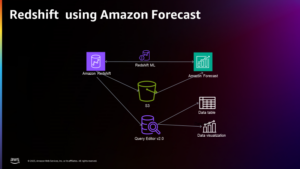
W tym poście przedstawiamy przypadek użycia klienta i zastosowaną architekturę.
W poniższych sekcjach najpierw przedstawiamy zbiór danych Common Crawl oraz opisujemy, jak eksplorować i filtrować potrzebne dane. Amazonka Atena pobiera opłaty tylko za rozmiar skanowanych danych i służy do szybkiego eksplorowania i filtrowania danych, a jednocześnie jest opłacalny. EMR Serverless zapewnia opłacalną i niewymagającą konserwacji opcję przetwarzania danych Spark i służy do przetwarzania filtrowanych danych. Dalej używamy Amazon SageMaker JumpStart aby dostroić Model Lamy 2 z wstępnie przetworzonym zbiorem danych. SageMaker JumpStart zapewnia zestaw rozwiązań dla najczęstszych przypadków użycia, które można wdrożyć za pomocą zaledwie kilku kliknięć. Nie musisz pisać żadnego kodu, aby dostroić LLM, taki jak Lama 2. Na koniec wdrażamy dopracowany model za pomocą Amazon Sage Maker i porównaj różnice w wynikach tekstowych tego samego pytania pomiędzy oryginalnym i dopracowanym modelem Llama 2.
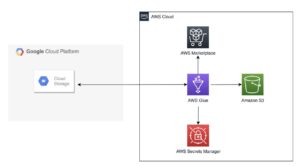
Poniższy diagram ilustruje architekturę tego rozwiązania.
Zanim zagłębisz się w szczegóły rozwiązania, wykonaj następujące wymagane kroki:
Common Crawl to otwarty zbiór danych uzyskany w wyniku przeszukania ponad 50 miliardów stron internetowych. Zawiera ogromne ilości nieustrukturyzowanych danych w wielu językach, począwszy od 2008 roku i osiągając poziom petabajtów. Jest stale aktualizowana.
Podczas uczenia GPT-3 zbiór danych Common Crawl stanowi 60% danych szkoleniowych, jak pokazano na poniższym diagramie (źródło: Modele językowe są mało uczącymi się).
Kolejnym ważnym zbiorem danych, o którym warto wspomnieć, jest Zbiór danych C4. C4, skrót od Colossal Clean Crawled Corpus, to zbiór danych uzyskany w wyniku przetwarzania końcowego zbioru danych Common Crawl. W artykule Meta LLaMA omówiono wykorzystywane zbiory danych, przy czym Common Crawl stanowił 67% (wykorzystując 3.3 TB danych), a C4 – 15% (wykorzystując 783 GB danych). W artykule podkreślono znaczenie włączania różnie wstępnie przetworzonych danych dla poprawy wydajności modelu. Mimo że oryginalne dane C4 były częścią Common Crawl, Meta zdecydowała się na ponownie przetworzoną wersję tych danych.
W tej sekcji omówimy typowe sposoby interakcji, filtrowania i przetwarzania zbioru danych Common Crawl.
Nieprzetworzony zestaw danych Common Crawl obejmuje trzy typy plików danych: surowe dane strony internetowej (WARC), metadane (WAT) i ekstrakcję tekstu (WET).
Dane zebrane po 2013 r. są przechowywane w formacie WARC i obejmują odpowiednie metadane (WAT) i dane ekstrakcji tekstu (WET). Zbiór danych znajduje się w Amazon S3 i jest aktualizowany co miesiąc, a dostęp do niego można uzyskać bezpośrednio Rynek AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzZbiór danych Common Crawl udostępnia również tabelę indeksów do filtrowania danych, zwaną tabelą cc-index.
Tabela cc-index jest indeksem istniejących danych, zapewniającym oparty na tabeli indeks plików WARC. Pozwala na łatwe wyszukiwanie informacji, np. który plik WARC odpowiada konkretnemu adresowi URL.
Można na przykład utworzyć tabelę Athena w celu mapowania danych indeksu CC za pomocą następującego kodu:
Powyższe instrukcje SQL pokazują, jak utworzyć tabelę Athena, dodać partycje i uruchomić zapytanie.
Filtruj dane ze zbioru danych Common Crawl
Jak widać z instrukcji SQL tworzenia tabeli, istnieje kilka pól, które mogą pomóc w filtrowaniu danych. Na przykład, jeśli chcesz uzyskać liczbę chińskich dokumentów w określonym okresie, instrukcja SQL może wyglądać następująco:
Jeśli chcesz przeprowadzić dalsze przetwarzanie, możesz zapisać wyniki w innym segmencie S3.
Analizuj przefiltrowane dane
Połączenia Wspólne repozytorium indeksowania GitHub udostępnia kilka przykładów PySpark do przetwarzania surowych danych.
Spójrzmy na przykład biegania server_count.py (przykładowy skrypt dostarczony przez repozytorium Common Crawl GitHub) na danych znajdujących się w s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Po pierwsze potrzebujesz środowiska Spark, takiego jak EMR Spark. Na przykład możesz uruchomić Amazon EMR w klastrze EC2 w us-east-1 (ponieważ zbiór danych jest w us-east-1). Korzystanie z EMR w klastrze EC2 może pomóc w przeprowadzeniu testów przed przesłaniem zadań do środowiska produkcyjnego.
Po uruchomieniu EMR na klastrze EC2 należy zalogować się SSH do głównego węzła klastra. Następnie spakuj środowisko Python i prześlij skrypt (patrz plik Dokumentacja Condy aby zainstalować Minicondę):
Przetworzenie wszystkich odniesień w warc.path może zająć trochę czasu. Do celów demonstracyjnych możesz skrócić czas przetwarzania, stosując następujące strategie:
- Pobierz plik
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzna komputer lokalny, rozpakuj go, a następnie prześlij do systemu HDFS lub Amazon S3. Dzieje się tak, ponieważ pliku .gzip nie można podzielić. Musisz go rozpakować, aby przetwarzać ten plik równolegle. - Zmodyfikuj
warc.pathplik, usuń większość jego linii i zachowaj tylko dwie linie, aby zadanie działało znacznie szybciej.
Po zakończeniu zadania możesz zobaczyć wynik w s3://xxxx-common-crawl/output/, w formacie parkietu.
Zaimplementuj dostosowaną logikę posiadania
Repozytorium Common Crawl GitHub zapewnia wspólne podejście do przetwarzania plików WARC. Ogólnie rzecz biorąc, możesz przedłużyć CCSparkJob zastąpić pojedynczą metodę (process_record), co w wielu przypadkach jest wystarczające.
Spójrzmy na przykład, aby uzyskać recenzje najnowszych filmów w serwisie IMDB. Najpierw musisz odfiltrować pliki w witrynie IMDB:
Następnie możesz uzyskać listy plików WARC zawierające dane przeglądu IMDB i zapisać nazwy plików WARC jako listę w pliku tekstowym.
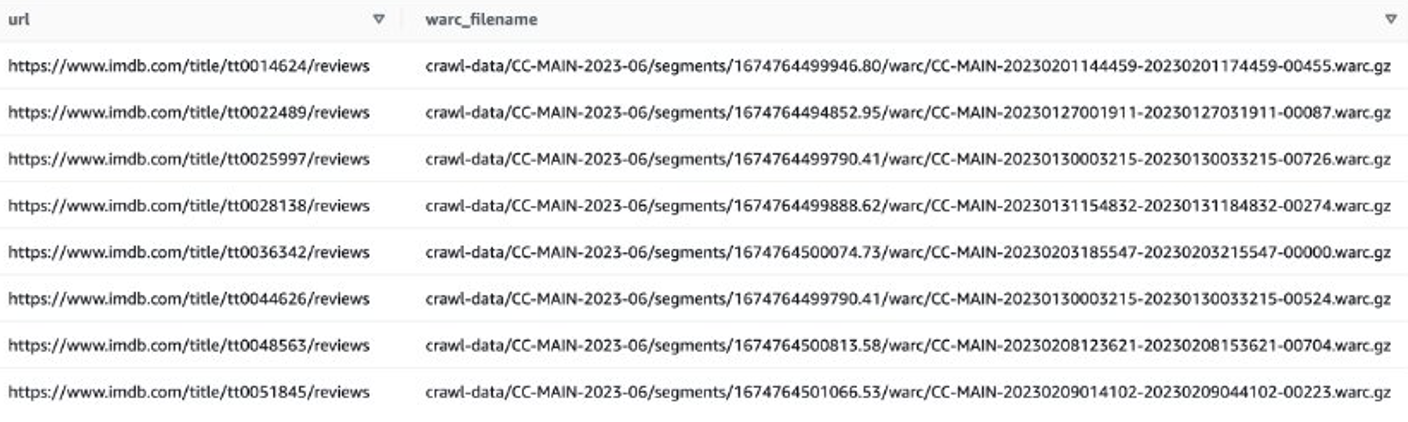
Alternatywnie możesz użyć EMR Spark, aby uzyskać listę plików WARC i zapisać ją w Amazon S3. Na przykład:
Plik wyjściowy powinien wyglądać podobnie do s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Następnym krokiem jest wyodrębnienie recenzji użytkowników z plików WARC. Możesz przedłużyć CCSparkJob zastąpić process_record() metoda:
Możesz zapisać powyższy skrypt jako imdb_extractor.py, którego użyjesz w poniższych krokach. Po przygotowaniu danych i skryptów możesz użyć EMR Serverless do przetworzenia przefiltrowanych danych.
EMR bez serwera
EMR Serverless to opcja wdrażania bezserwerowego umożliwiająca uruchamianie aplikacji do analizy dużych zbiorów danych przy użyciu platform open source, takich jak Apache Spark i Hive, bez konfigurowania, zarządzania i skalowania klastrów lub serwerów.
Dzięki EMR Serverless możesz uruchamiać obciążenia analityczne w dowolnej skali dzięki automatycznemu skalowaniu, które zmienia rozmiar zasobów w ciągu kilku sekund, aby sprostać zmieniającym się ilościom danych i wymaganiom przetwarzania. EMR Serverless automatycznie skaluje zasoby w górę i w dół, aby zapewnić odpowiednią pojemność dla Twojej aplikacji, a Ty płacisz tylko za to, z czego korzystasz.
Przetwarzanie zbioru danych Common Crawl jest zazwyczaj jednorazowym zadaniem przetwarzania, dzięki czemu nadaje się do obciążeń bezserwerowych EMR.
Utwórz aplikację bezserwerową EMR
Możesz utworzyć aplikację EMR Serverless na konsoli EMR Studio. Wykonaj następujące kroki:
- W konsoli EMR Studio wybierz Konsultacje dla Bezserwerowe w okienku nawigacji.
- Dodaj Utwórz aplikację.

- Podaj nazwę aplikacji i wybierz wersję Amazon EMR.

- Jeśli wymagany jest dostęp do zasobów VPC, dodaj niestandardowe ustawienie sieci.

- Dodaj Utwórz aplikację.
Twoje bezserwerowe środowisko Spark będzie wtedy gotowe.
Zanim będziesz mógł przesłać zadanie do EMR Spark Serverless, musisz jeszcze utworzyć rolę wykonawczą. Odnosić się do Rozpoczęcie pracy z Amazon EMR Serverless by uzyskać więcej szczegółów.
Przetwarzaj dane wspólnego indeksowania za pomocą rozwiązania EMR Serverless
Gdy aplikacja EMR Spark Serverless będzie gotowa, wykonaj następujące kroki, aby przetworzyć dane:
- Przygotuj środowisko Conda i prześlij je do Amazon S3, które będzie używane jako środowisko w EMR Spark Serverless.
- Prześlij skrypty, które mają zostać uruchomione, do segmentu S3. W poniższym przykładzie istnieją dwa skrypty:
- imbd_extractor.py – Dostosowana logika do wyodrębniania zawartości ze zbioru danych. Treść można znaleźć wcześniej w tym poście.
- cc-pyspark/sparkcc.py – Przykładowy framework PySpark z Wspólne repozytorium indeksowania GitHub, które należy uwzględnić.
- Prześlij zadanie PySpark do EMR Serverless Spark. Zdefiniuj następujące parametry, aby uruchomić ten przykład w swoim środowisku:
- identyfikator aplikacji – Identyfikator aplikacji bezserwerowej EMR.
- wykonanie-rola-arn – Twoja rola egzekucyjna EMR Serverless. Aby go utworzyć, patrz Utwórz rolę środowiska wykonawczego zadania.
- Lokalizacja pliku WARC – Lokalizacja plików WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtzawiera przefiltrowaną listę plików WARC, którą uzyskałeś wcześniej w tym poście. - spark.sql.warehouse.dir – Domyślna lokalizacja magazynu (użyj katalogu S3).
- iskra.archiwa – Lokalizacja S3 przygotowanego środowiska Conda.
- spark.submit.pyFiles – Przygotowany skrypt PySpark sparkcc.py.
Zobacz następujący kod:
Po zakończeniu zadania wyodrębnione recenzje są przechowywane w Amazon S3. Aby sprawdzić zawartość, możesz użyć Amazon S3 Select, jak pokazano na poniższym zrzucie ekranu.
rozważania
Poniżej znajdują się kwestie, które należy wziąć pod uwagę, gdy mamy do czynienia z ogromnymi ilościami danych za pomocą niestandardowego kodu:
- Niektóre biblioteki Pythona innych firm mogą nie być dostępne w Condzie. W takich przypadkach możesz przełączyć się na środowisko wirtualne Python, aby zbudować środowisko wykonawcze PySpark.
- Jeśli do przetworzenia jest ogromna ilość danych, spróbuj utworzyć i używać wielu aplikacji EMR Serverless Spark w celu ich zrównoleglenia. Każda aplikacja obsługuje podzbiór list plików.
- Możesz napotkać problem spowolnienia Amazon S3 podczas filtrowania lub przetwarzania danych Common Crawl. Dzieje się tak dlatego, że zasobnik S3 przechowujący dane jest publicznie dostępny i inni użytkownicy mogą uzyskać dostęp do danych w tym samym czasie. Aby złagodzić ten problem, możesz dodać mechanizm ponawiania prób lub synchronizować określone dane z zasobnika Common Crawl S3 z własnym zasobnikiem.
Dostosuj Llamę 2 za pomocą SageMaker
Po przygotowaniu danych można za ich pomocą dostroić model Lamy 2. Możesz to zrobić za pomocą SageMaker JumpStart, bez pisania żadnego kodu. Aby uzyskać więcej informacji, zobacz Dostosuj Llamę 2 do generowania tekstu w Amazon SageMaker JumpStart.
W tym scenariuszu przeprowadzane jest dostrajanie adaptacji domeny. W przypadku tego zestawu danych dane wejściowe składają się z pliku CSV, JSON lub TXT. Wszystkie dane recenzji należy umieścić w pliku TXT. Aby to zrobić, możesz przesłać proste zadanie Spark do EMR Spark Serverless. Zobacz następujący przykładowy fragment kodu:
Po przygotowaniu danych szkoleniowych wprowadź lokalizację danych Zestaw danych treningowych, A następnie wybierz Pociąg.
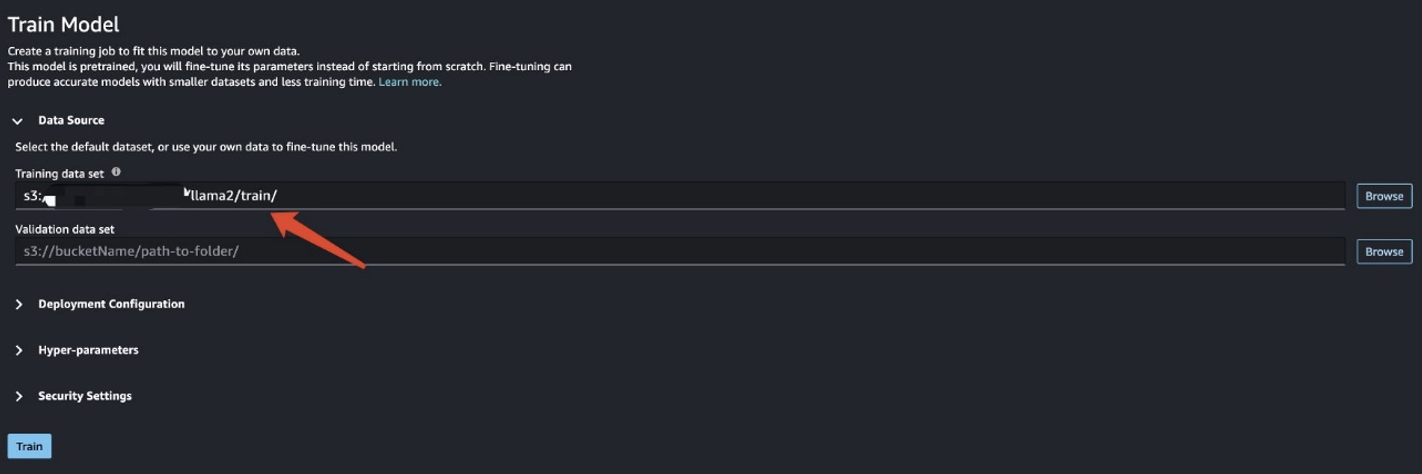
Możesz śledzić status zadania szkoleniowego.
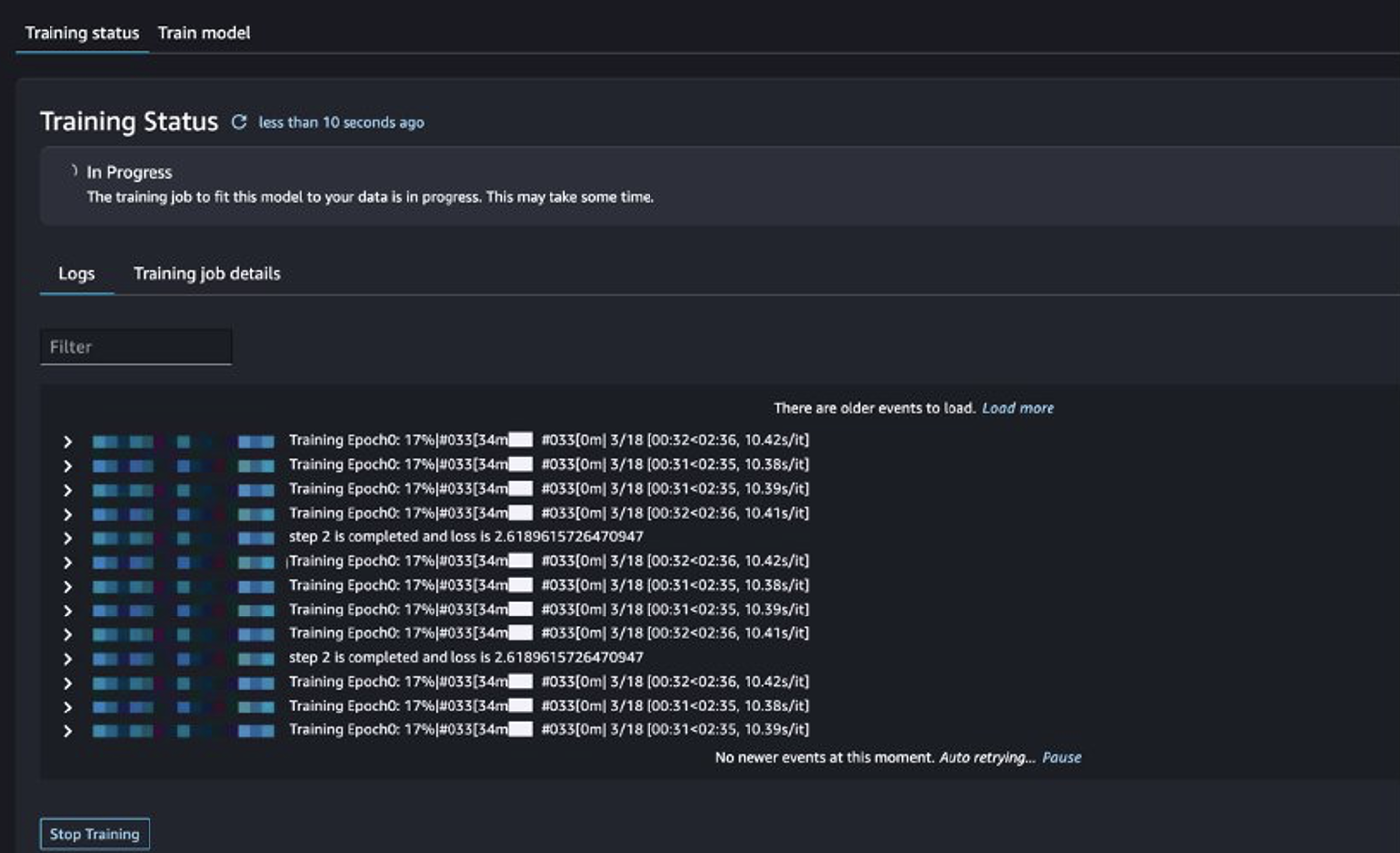
Oceń dopracowany model
Po zakończeniu szkolenia wybierz Rozmieścić w SageMaker JumpStart, aby wdrożyć swój dopracowany model.

Po pomyślnym wdrożeniu modelu wybierz Otwórz notatnik, który przekieruje Cię do przygotowanego notatnika Jupyter, w którym możesz uruchomić swój kod w Pythonie.

W przypadku notebooka można użyć obrazu Data Science 2.0 i jądra Python 3.
Następnie możesz ocenić w tym notatniku model dopracowany i model oryginalny.
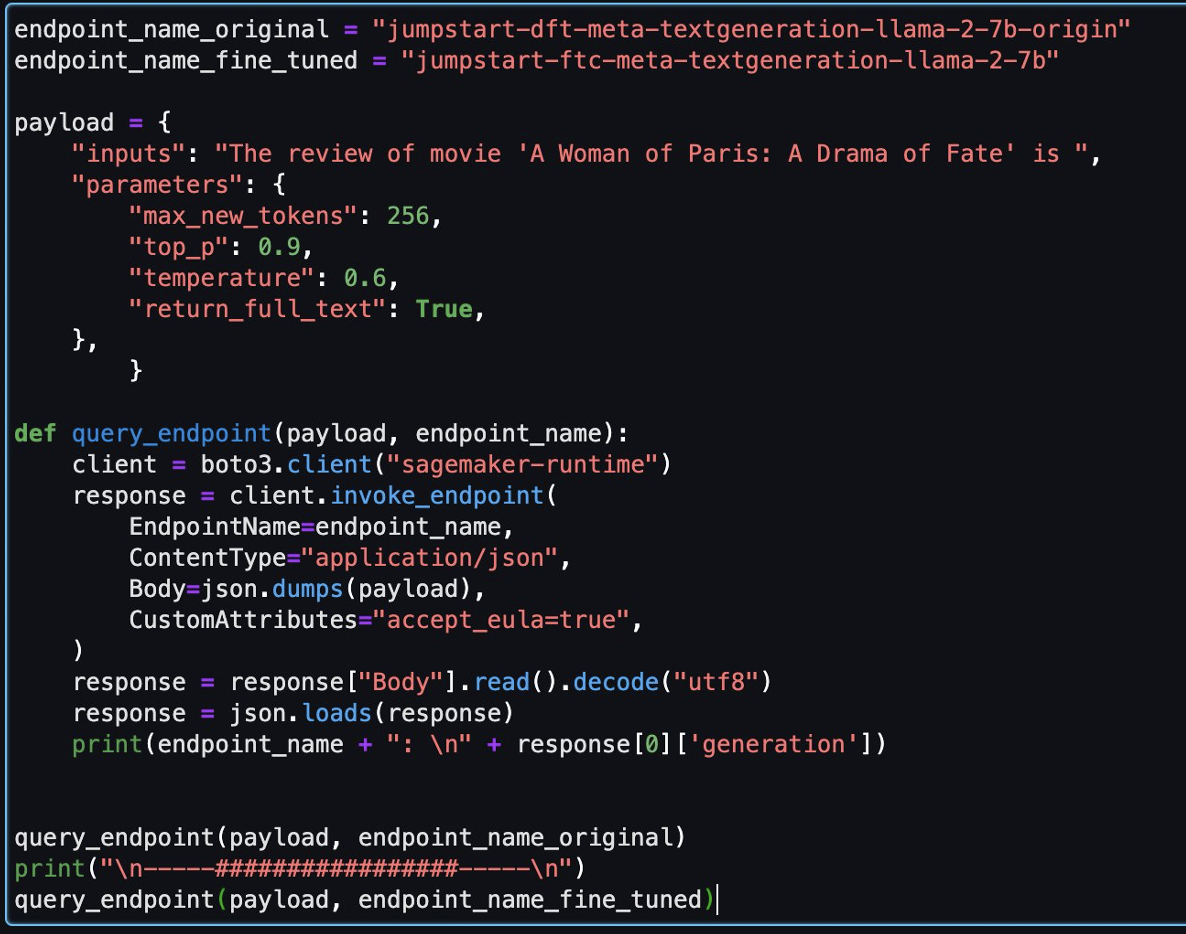
Poniżej znajdują się dwie odpowiedzi zwrócone przez model oryginalny i model dostrojony na to samo pytanie.

Obu modelom przekazaliśmy to samo zdanie: „Recenzja filmu „Kobieta z Paryża: Dramat losu” to” i pozwoliliśmy im dokończyć zdanie.
Oryginalny model generuje pozbawione znaczenia zdania:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Natomiast wyniki dopracowanego modelu przypominają raczej recenzję filmu:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Oczywiście model dostrojony działa lepiej w tym konkretnym scenariuszu.
Sprzątać
Po zakończeniu tego ćwiczenia wykonaj następujące kroki, aby oczyścić zasoby:
- Usuń wiadro S3 przechowujący oczyszczony zbiór danych.
- Zatrzymaj środowisko bezserwerowe EMR.
- Usuń punkt końcowy SageMaker obsługujący model LLM.
- Usuń domenę SageMaker który obsługuje Twoje notebooki.
Domyślnie utworzona aplikacja powinna zatrzymać się automatycznie po 15 minutach bezczynności.
Ogólnie rzecz biorąc, nie musisz sprzątać środowiska Athena, ponieważ nie są pobierane żadne opłaty, gdy z niego nie korzystasz.
Wnioski
W tym poście przedstawiliśmy zbiór danych Common Crawl i sposób wykorzystania EMR Serverless do przetwarzania danych w celu dostrojenia LLM. Następnie zademonstrowaliśmy, jak używać SageMaker JumpStart do dostrojenia LLM i wdrożenia go bez żadnego kodu. Więcej przypadków użycia EMR Serverless można znaleźć w artykule Bezserwerowy Amazon EMR. Aby uzyskać więcej informacji na temat hostingu i dostrajania modeli w Amazon SageMaker JumpStart, zobacz Dokumentacja Sagemaker JumpStart.
O autorach
 Shijian Tang jest specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services.
Shijian Tang jest specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services.
 Mateusz Liem jest starszym menedżerem ds. architektury rozwiązań w Amazon Web Services.
Mateusz Liem jest starszym menedżerem ds. architektury rozwiązań w Amazon Web Services.
 Dalei Xu jest specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services.
Dalei Xu jest specjalistą ds. analityki i architektem rozwiązań w Amazon Web Services.
 Yuanjun Xiao jest starszym architektem rozwiązań w Amazon Web Services.
Yuanjun Xiao jest starszym architektem rozwiązań w Amazon Web Services.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Zdolny
- O nas
- dostęp
- dostęp
- dostępny
- Księgowość
- Konta
- Osiągać
- aktywowany
- Dodaj
- dodatek
- Afryka
- Po
- Wszystkie kategorie
- pozwala
- również
- zdumiewający
- Amazonka
- Amazon EMR
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- ilość
- kwoty
- an
- analityka
- i
- Inne
- każdy
- Apache
- Apache Spark
- Zastosowanie
- aplikacje
- podejście
- architektura
- SĄ
- AS
- At
- australijski
- automatycznie
- automatycznie
- dostępny
- AWS
- tło
- na podstawie
- podstawa
- BE
- piękny
- bo
- staje
- zanim
- rozpocząć
- jest
- Ulepsz Swój
- pomiędzy
- Duży
- Big Data
- Miliard
- ciało
- obie
- budować
- by
- nazywa
- CAN
- Może uzyskać
- Pojemność
- nieść
- walizka
- Etui
- wymiana pieniędzy
- charakter
- Opłaty
- ZOBACZ
- chiński
- Dodaj
- klasa
- kleń
- klient
- Grupa
- kod
- COM
- wspólny
- powszechnie
- porównać
- kompletny
- konfigurowanie
- Rozważać
- składa się
- Konsola
- stale
- zawierać
- zawiera
- treść
- bez przerwy
- kontrast
- Odpowiedni
- odpowiada
- Koszty:
- opłacalne
- mógłby
- liczyć
- pokrywa
- Stwórz
- stworzony
- zwyczaj
- klient
- dostosowane
- dane
- Analityka danych
- analiza danych
- nauka danych
- zbiory danych
- Davis
- czynienia
- Promocje
- głęboko
- Domyślnie
- określić
- Demo
- wykazać
- wykazać
- rozwijać
- wdrażane
- Wdrożenie
- Pochodny
- Mimo
- detale
- określaniu
- schemat
- Różnice
- różnie
- skierowany
- bezpośrednio
- Omawiając
- nurkować
- do
- dokumenty
- domena
- domeny
- donald
- nie
- na dół
- Dramat
- kierowca
- czas trwania
- podczas
- każdy
- Wcześniej
- łatwo
- eliminuje
- podkreśla
- spotkanie
- Inżynieria
- wzmocnienie
- Wchodzę
- Środowisko
- Eter (ETH)
- oceniać
- przykład
- przykłady
- egzekucja
- Ćwiczenie
- Przede wszystkim system został opracowany
- istnieje
- odkryj
- zbadane
- rozciągać się
- zewnętrzny
- wyciąg
- ekstrakcja
- Wyciągi
- Spada
- fałszywy
- szybciej
- los
- polecane
- kilka
- Łąka
- filet
- Akta
- filtrować
- filtracja
- W końcu
- Znajdź
- koniec
- i terminów, a
- następujący
- następujący sposób
- W razie zamówieenia projektu
- format
- znaleziono
- Framework
- Ramy
- od
- dalej
- Ogólne
- ogólnie
- generujący
- generacja
- otrzymać
- git
- GitHub
- przewodnictwo
- Have
- pomoc
- Ul
- Hosting
- gospodarze
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- Setki
- i
- IAM
- ID
- if
- ilustruje
- obraz
- importować
- ważny
- podnieść
- in
- włączony
- obejmuje
- włączenie
- wzrastający
- wskaźnik
- Informacja
- Infrastruktura
- wkład
- Wejścia
- zainstalować
- interakcji
- najnowszych
- przedstawiać
- wprowadzono
- problem
- IT
- JEGO
- jack
- Praca
- Oferty pracy
- json
- Notebook Jupyter
- właśnie
- Trzymać
- Klawisz
- język
- Języki
- na dużą skalę
- firmy
- uruchomić
- wodowanie
- prowadzić
- niech
- poziom
- biblioteki
- lubić
- LIMIT
- linie
- Lista
- wykazy
- Lama
- llm
- miejscowy
- usytuowany
- lokalizacja
- logika
- Zaloguj Się
- Popatrz
- poszukuje
- wyszukiwania
- maszyna
- konserwacja
- robić
- Dokonywanie
- kierownik
- zarządzający
- wiele
- mapa
- masywny
- Może..
- mechanizm
- Poznaj nasz
- Spełnia
- wspominając
- Meta
- Metadane
- metoda
- minuty
- Złagodzić
- model
- modele
- miesięcznie
- jeszcze
- większość
- film
- Kino
- dużo
- wielokrotność
- Nazwa
- Nazwy
- Nawigacja
- niezbędny
- Potrzebować
- sieć
- Nowości
- Następny
- Nie
- węzeł
- notatnik
- laptopy
- uzyskane
- październik
- of
- on
- ONE
- tylko
- koncepcja
- open source
- Option
- or
- oryginalny
- Inne
- na zewnątrz
- opisane
- wydajność
- Wyjścia
- koniec
- Zastąp
- własny
- Pakować
- pakiet
- chleb
- Papier
- Parallel
- parametry
- Paryż
- część
- ścieżka
- ścieżki
- Zapłacić
- Ludzie
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- spektakle
- wykonuje
- okres
- petabajt
- Piotr
- fotograf
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- działka
- zwrotnica
- Popularny
- Post
- powered
- dla
- poprzedzający
- Przygotować
- przygotowany
- pierwotny
- wygląda tak
- obrobiony
- przetwarzanie
- Produkcja
- monity
- zapewniać
- pod warunkiem,
- zapewnia
- że
- publicznie
- cele
- położyć
- Python
- pytanie
- pytanie
- szybko
- Surowy
- surowe dane
- osiągnięcie
- Czytaj
- gotowy
- niedawny
- niedawno
- Zalecana
- rekord
- odnosić się
- referencje
- regularnie
- związek
- wydany
- naprawa
- obsługi produkcji rolnej, która zastąpiła
- wywołań
- wymagany
- wymagania
- Zasoby
- odpowiedź
- Odpowiedzi
- dalsze
- Efekt
- przeglądu
- Recenzje
- prawo
- Rola
- Rory
- run
- bieganie
- działa
- sagemaker
- taki sam
- Zapisz
- Skala
- waga
- skalowaniem
- skany
- scenariusz
- nauka
- scenariusz
- skrypty
- sekund
- Sekcja
- działy
- widzieć
- segment
- wybierać
- SAMEGO SIEBIE
- senior
- wyrok
- Bezserwerowe
- serwery
- Usługi
- zestaw
- ustawienie
- kilka
- ona
- Short
- powinien
- pokazane
- znaczenie
- podobny
- ponieważ
- pojedynczy
- witryna internetowa
- Rozmiar
- Zwolnij
- skrawek
- So
- rozwiązanie
- Rozwiązania
- zupa
- Źródło
- Iskra
- specjalista
- specyficzny
- SQL
- ssh
- rozpoczęty
- Startowy
- Zestawienie sprzedaży
- oświadczenia
- Rynek
- Ewolucja krok po kroku
- Cel
- Nadal
- Stop
- sklep
- przechowywany
- sklep
- Historia
- bezpośredni
- strategie
- sznur
- studio
- Zatwierdź
- przedkładający
- Z powodzeniem
- taki
- wystarczający
- odpowiedni
- Przełącznik
- synchronizacja
- stół
- Brać
- cel
- Zadanie
- zadania
- tensorflow
- REGULAMIN
- Testy
- XNUMX
- generowanie tekstu
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- Te
- one
- innych firm
- to
- trzy
- Przez
- czas
- znak czasu
- do
- śledzić
- Trening
- podróże
- prawdziwy
- próbować
- drugiej
- typy
- dla
- nieuporządkowany
- zaktualizowane
- URL
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- opinie użytkowników
- Użytkownicy
- za pomocą
- Wykorzystując
- wersja
- Wirtualny
- kłęby
- spacer
- chcieć
- poszukiwany
- Magazyn
- była
- Droga..
- sposoby
- we
- sieć
- usługi internetowe
- tydzień
- DOBRZE
- Co
- jeśli chodzi o komunikację i motywację
- natomiast
- który
- Podczas
- KIM
- Wildlife
- będzie
- William
- w
- w ciągu
- bez
- kobieta
- pracował
- wartość
- napisać
- pisanie
- Wydajność
- ty
- Twój
- zefirnet