29 stycznia to Narodowy Dzień Łamigłówek i z tej okazji stworzyliśmy zabawny blog, w którym szczegółowo opisano, jak rozwiązać Sudoku przy użyciu sztucznej inteligencji (AI).
Wprowadzenie
Przed wordleThe Sudoku był wściekłość i nadal jest bardzo popularny. W ostatnich latach zastosowanie optymalizacja dominującym tematem były metody rozwiązywania zagadek. Widzieć „Rozwiązywanie sudoku za pomocą optymalizacji w Arkieva".
Obecnie wykorzystanie sztucznej inteligencji koncentruje się na uczeniu maszynowym, które obejmuje szeroki zakres metod, od regresji lasso po uczenie się przez wzmacnianie. Zastosowanie sztucznej inteligencji ma ponownie uporać się z kompleksami szeregowanie wyzwania. Jedna z metod, wyszukiwanie z cofaniem, jest powszechnie stosowana i doskonale sprawdza się w Sudoku.
Na tym blogu znajdziesz szczegółowy opis wykorzystania tej metody do rozwiązywania Sudoku. Jak się okazuje, „backtracking” można znaleźć w silnikach optymalizacji i uczenia maszynowego i stanowi on kamień węgielny zaawansowanej heurystyki wykorzystywanej przez Arkieva do planowania. Algorytm jest zaimplementowany w „języku programowania tablicowego”, języku programowania zorientowanym na funkcje, który obsługuje: bogaty zestaw struktur tablicowych.
Podstawy Sudoku
Z Wikipedii: Sudoku to oparta na logice kombinatoryczna łamigłówka polegająca na umieszczaniu liczb. Celem jest wypełnienie cyframi siatki 9×9 w taki sposób, aby każda kolumna, każdy wiersz i każda z dziewięciu podsiatek 3×3 tworzących siatkę (zwanych także „pudełkami”, „blokami”, „regionami”) lub „podkwadraty”) zawiera wszystkie cyfry od 1 do 9. Układacz puzzli zapewnia częściowo ukończoną siatkę, która zazwyczaj ma unikalne rozwiązanie. Ukończone puzzle są zawsze rodzajem kwadratu łacińskiego z dodatkowym ograniczeniem zawartości poszczególnych regionów. Na przykład ta sama pojedyncza liczba całkowita nie może pojawić się dwukrotnie w tym samym rzędzie lub kolumnie planszy 9×9 ani w żadnym z dziewięciu podobszarów 3×3 planszy 9×9.
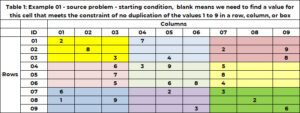
Tabela 1 zawiera przykładowy problem. Istnieje 9 wierszy i 9 kolumn, co daje w sumie 81 komórek. Każda może mieć jedną i tylko jedną z dziewięciu liczb całkowitych od 1 do 9. W rozwiązaniu początkowym komórka albo ma pojedynczą wartość – co ustala wartość w tej komórce na tę wartość, albo komórka jest pusta, co wskazuje, że potrzebujemy aby znaleźć wartość dla tej komórki. Komórka (1,1) ma wartość 2, a komórka (6,5) ma wartość 6. Komórka (1,2) i komórka (2,3) są puste, a algorytm znajdzie dla tych komórek wartość.
Komplikacja
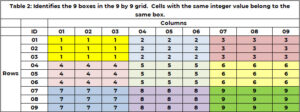
Oprócz przynależności do jednego i tylko jednego wiersza i kolumny, komórka należy do jednego i tylko 1 pola. Jest 9 pól i są one oznaczone kolorem w Tabeli 1. W Tabeli 2 do identyfikacji każdego pola lub siatki używana jest unikalna liczba całkowita z zakresu od 1 do 9. Komórki z wartością wiersza (1, 2 lub 3) i wartością kolumny (1, 2 lub 3) należą do pola 1. Pole 6 zawiera wartości wiersza (4, 5, 6) i wartości kolumny (7, 8) , 9). Identyfikator boxu określany jest wzorem BOX_ID = {3x(podłoga((ROW_ID-1) /3)} + sufit (COL_ID/3). Dla komórki (5,7) 6 = 3x(podłoga(5-1 ))/3) + sufit (8/3) = 3×1 + 3 = 3+3.
Serce układanki
Aby znaleźć jedną wartość całkowitą od 1 do 9 dla każdej nieznanej komórki, tak aby liczby całkowite od 1 do 9 zostały użyte raz i tylko raz dla każdej kolumny, każdego wiersza i każdego pola.
Spójrzmy na komórkę (1,3), która jest pusta. Wiersz 1 ma już wartości 2 i 7. Nie są one dozwolone w tej komórce. Kolumna 3 ma już wartości 3, 5,6, 7,9. Nie są one dozwolone. W polu 1 (żółtym) znajdują się wartości 2, 3 i 8. Są one niedozwolone. Następujące wartości są niedozwolone (2,7); (3, 5, 6, 7, 9); (2, 3, 8). Niedozwolone unikalne wartości to (2, 3, 5, 6, 7, 8, 9). Jedynymi wartościami kandydującymi są (1,4).
Rozwiązaniem byłoby tymczasowe przypisanie 1 do komórki (1,3), a następnie próba znalezienia wartości kandydujących dla innej komórki.
Rozwiązanie polegające na wycofywaniu się: uruchamianie komponentów
Struktura tablicowa
Punktem wyjścia jest wybranie struktury tablicowej, w której będzie przechowywany problem źródłowy i który będzie wspierał wyszukiwanie. Tabela 3 ma tę strukturę tablicową. Kolumna 1 to unikalny identyfikator całkowity dla każdej komórki. Wartości mieszczą się w zakresie od 1 do 81. Kolumna 2 to identyfikator wiersza komórki. Kolumna 3 to identyfikator kolumny komórki. Kolumna 4 to identyfikator skrzynki. Kolumna 5 zawiera wartość w komórce. Obserwuj, że komórka bez wartości otrzymuje wartość zero zamiast pustej lub null. Dzięki temu jest to „tablica zawierająca wyłącznie liczby całkowite” – znacznie lepsza pod względem wydajności.

W APL ta tablica byłaby przechowywana w dwuwymiarowej tablicy, której kształt wynosi 2 na 81. Załóżmy, że elementy tabeli 5 są przechowywane w zmiennej MAT. Przykładowe funkcje to:
Polecenie MAT[1 2 3;] pobiera pierwsze 3 wiersze MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MATA[1 2 3; 4 5] zabezpiecza rzędy 1, 2, 3 i tylko kolumny 4 i 5
1 2
1 0
1 0
(MAT[;5]=0)/MAT[;1] wyszukuje wszystkie komórki, które potrzebują wartości.
WSTAW TABELI 3
Kontrola poczytalności: duplikaty
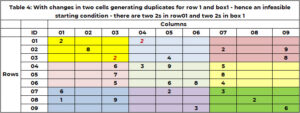
Przed rozpoczęciem poszukiwań niezwykle ważne jest sprawdzenie zdrowego rozsądku! To jest możliwe rozwiązanie wyjściowe. Czy jest to wykonalne w Sudoku, czy w dowolnym wierszu, kolumnie lub polu znajdują się teraz duplikaty? Obecne rozwiązanie początkowe, na przykład 1, jest wykonalne. Tabela 4 zawiera przykład, w którym roztwór wyjściowy ma duplikaty. Wiersz 1 ma dwie wartości 2. Obszar 1 ma dwie wartości 2. Funkcja „SANITY_DUPE” obsługuje tę logikę.
Kontrola poprawności: Opcje dla komórek bez wartości
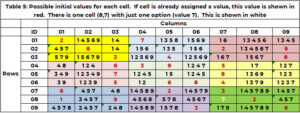
Bardzo przydatną informacją są wszystkie możliwe wartości komórki bez wartości. Jeżeli nie ma kandydatów, to tej zagadki nie da się rozwiązać. Komórka nie może przyjąć wartości, która została już zadeklarowana przez jej sąsiada. Używając tabeli 1 dla komórki (1,3,'1' – ostatnia 1 to boxid), jej sąsiadami są wiersz 1, kolumna 3 i pole 1. Wiersz 1 ma wartości (2,7); kolumna 3 zawiera wartości (3,5,6,7,9); pole 1 ma wartości (2,3,8). Komórka (1,3.1) nie może przyjmować następujących wartości (2,3,5,6,7,8,9). Jedyne opcje dla komórki (1,3,1) to (1,4). W przypadku komórki (4,1,2) wartości 1, 2, 3, 5, 6, 7, 9 są już użyte w wierszu 4, kolumnie 1 i/lub ramce 4. Jedynymi wartościami kandydującymi są (4,8) . Funkcja „SANITY_CAND” obsługuje tę logikę.
Tabela 5 przedstawia kandydatów, np. 1 na początku procesu wyszukiwania. Jeżeli w warunkach startowych do komórki została już przypisana wartość (tabela 1), to wartość ta jest powtarzana i pokazywana na czerwono. Jeśli komórka wymagająca wartości ma tylko jedną opcję, jest ona wyświetlana na biało. Komórka (8,7,9) ma pojedynczą wartość 7 w kolorze białym. (2,5,8,4,3) są zajęte przez sąsiednią kolumnę 7. (1, 2, 9) przez wiersz 8. (3,2,6) przez pole 9. Tylko wartość 7 nie jest zajęta.
Kontrola poczytalności: szukanie konfliktów
Informacje identyfikujące wszystkie opcje komórek wymagających wartości (zamieszczone w tabeli 4) pozwalają nam zidentyfikować konflikt przed rozpoczęciem procesu wyszukiwania. Konflikt występuje, gdy dwie komórki wymagające wartości mają tylko jednego kandydata, wartość kandydująca jest taka sama, a obie komórki są sąsiadami. Z tabeli 4 wiemy, że jedyną komórką, która potrzebuje wartości i ma tylko jednego kandydata, jest komórka (8,7,9). Na przykład 1 nie ma konfliktu.
Jaki byłby konflikt? Jeśli jedyną możliwą wartością komórki (3,7,3) było 7 (zamiast 1, 6, 7), wówczas występuje konflikt. Komórka (8,7) i komórka (3,7) są sąsiadami – ta sama kolumna. Jeśli jednak jedyną możliwą wartością komórki (4,9,2) byłoby 7 (zamiast 1, 2, 7), nie byłby to konflikt. Komórki te nie są sąsiadami.
Podsumowanie kontroli poczytalności
- Jeśli występują duplikaty, rozwiązanie początkowe nie jest możliwe.
- Jeśli komórka potrzebująca wartości nie ma żadnych kandydatów, to nie ma możliwości rozwiązania tej zagadki. Listę wartości kandydujących dla każdej komórki można wykorzystać do zmniejszenia przestrzeni poszukiwań – zarówno w celu wycofywania się, jak i optymalizacji.
- Możliwość znalezienia konfliktów identyfikuje zagadkę, która nie jest możliwa – nie ma rozwiązania – bez procesu wyszukiwania. Dodatkowo identyfikuje „komórki problemowe”.
Rozwiązanie polegające na wycofywaniu się: proces wyszukiwania
Po wdrożeniu podstawowych struktur danych i sprawdzeniu poprawności zwracamy uwagę na proces wyszukiwania. Powracającym tematem jest ponownie wprowadzenie struktur danych wspierających wyszukiwanie.
Śledzenie wyszukiwania
Tablica Tracker na bieżąco śledzi wykonane zadania
- Kolumna 1 to licznik
- Col 2 to liczba opcji dostępnych do przypisania do tej komórki
- 1 oznacza dostępną 1 opcję, 2 oznacza dwie opcje itd.
- 0 oznacza – brak opcji lub reset do 0 (brak przypisanej wartości) i cofanie się
- Col 3 to komórka, której przypisano numer indeksu wartości (od 1 do 81)
- Kol. 4 to wartość przypisana do komórki w historii ścieżek
- Wartość 9999 oznacza, że ta komórka znajdowała się w momencie znalezienia ślepego zaułka
- Wartość liczby całkowitej z zakresu od 1 do 9 włącznie jest wartością przypisaną do tej komórki na tym etapie procesu wyszukiwania.
- Wartość 0 oznacza, że ta komórka wymaga przypisania
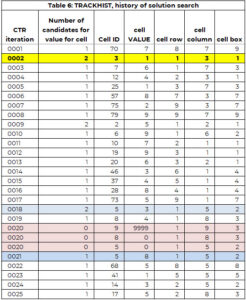
Tablica trackerów służy do wspierania procesu wyszukiwania. Tablica HISTORIA UTWORÓW ma taką samą strukturę jak moduł śledzący, ale przechowuje historię całego procesu wyszukiwania. Tabela 6 zawiera część TRACKHIST, na przykład 1. Jest to wyjaśnione bardziej szczegółowo w dalszej części.
Dodatkowo tablica PAW (wektor wektora), śledzi wcześniej przypisane wartości do tej komórki. Dzięki temu nie będziemy wracać do nieudanego rozwiązania – podobnie jak w przypadku TABU.
Istnieje opcjonalny proces dziennika, w którym proces wyszukiwania zapisuje każdy krok.
Rozpoczęcie wyszukiwania
Po zakończeniu księgowości i sprawdzeniu poprawności możemy teraz rozpocząć proces wyszukiwania. Kroki są następujące:
- Czy pozostały jeszcze jakieś komórki wymagające wartości? – jeśli nie, to koniec.
- Dla każdej komórki wymagającej wartości znajdź wszystkie możliwe opcje dla każdej komórki. Tabela 4 zawiera te wartości na początku procesu rozwiązywania. Przy każdej iteracji jest to aktualizowane, aby uwzględnić wartości przypisane do komórek.
- Oceń opcje w tej kolejności.
- Jeśli komórka ma opcje ZERO, wprowadź wycofywanie
- Znajdź wszystkie komórki z jedną opcją, wybierz jedną z tych komórek, wykonaj to przypisanie,
- i zaktualizuj tabelę śledzenia, bieżące rozwiązanie i PAV.
- Jeśli wszystkie komórki mają więcej niż jedną opcję, wybierz jedną komórkę i jedną wartość, a następnie zaktualizuj
- i zaktualizuj tabelę śledzenia, bieżące rozwiązanie i PAV
Do zilustrowania każdego kroku użyjemy Tabeli 6, która stanowi część historii procesu rozwiązania (zwanej TRACKHIST).
W pierwszej iteracji (CTR=1) wybierana jest komórka 70 (wiersz 8, kolumna 7, pole 9) w celu przypisania wartości. Jest tylko kandydat (7) i ta wartość jest przypisana do komórki 70. Dodatkowo wartość 7 jest dodawana do wektora wcześniej przypisanych wartości (PAV) dla komórki 70.
W drugiej iteracji komórce 30 przypisano wartość 1. Komórce tej przypisano dwie wartości kandydujące. Do komórki przypisana jest najmniejsza wartość kandydująca (jest to tylko dowolna reguła ułatwiająca przestrzeganie logiki).
Proces identyfikowania komórki wymagającej wartości i przypisywania jej działa prawidłowo aż do iteracji (CTR) 20. Komórka 9 potrzebuje wartości, ale liczba kandydatów wynosi ZERO. Istnieją dwie opcje:
- Nie ma rozwiązania tej zagadki.
- Cofamy (cofujemy) część przypisań i wybieramy inną ścieżkę.
Szukaliśmy przypisania komórki najbliższego temu, gdzie istniała więcej niż jedna opcja. W tym przykładzie miało to miejsce w 18. iteracji, gdzie komórce 5 przypisano wartość 3, ale istniały dwie wartości kandydujące do komórki 5 – wartości 3 i 8.
Pomiędzy komórką 5 (CTR = 18) a komórką 9 (CTR = 20) komórka 8 ma przypisaną wartość 4 (CTR = 19). Komórki 8 i 5 ponownie umieszczamy na liście „potrzebujemy wartości”. Jest to ujęte w drugim i trzecim wpisie CTR=20, gdzie wartość jest ustawiona na 0. Wartość 3 jest przechowywana w wektorze PAV dla komórki 5. Oznacza to, że wyszukiwarka nie może przypisać wartości 3 do komórki 5.
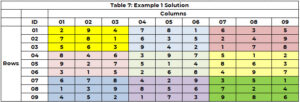
Wyszukiwarka uruchamia się ponownie, aby zidentyfikować wartość komórki 5 (przy czym 3 nie jest już opcją) i przypisuje wartość 8 komórce 5 (CTR=21). Trwa to do momentu, aż wszystkie komórki będą miały wartość lub pojawi się komórka bez opcji i nie będzie ścieżki cofania. Rozwiązanie przedstawiono w tabeli 7.
Zauważ, że tam, gdzie jest więcej niż jeden kandydat na komórkę, jest to szansa na przetwarzanie równoległe.
Porównanie z rozwiązaniem optymalizacyjnym MILP
Na poziomie powierzchni reprezentacja Sudoku jest diametralnie inna. Podejście AI wykorzystuje liczby całkowite i pod każdym względem jest ściślejszą i bardziej intuicyjną reprezentacją. Dodatkowo testy zdrowego rozsądku dostarczają przydatnych informacji pozwalających na stworzenie silniejszego preparatu. Reprezentacja MILP nie ma końca pliki binarne (0/1). Jednak pliki binarne są potężnymi reprezentacjami, biorąc pod uwagę siłę nowoczesnych solwerów MILP.
Jednak wewnętrznie moduł MILP nie przechowuje plików binarnych, ale używa metody rzadkiej tablicy, aby wyeliminować przechowywanie wszystkich zer. Ponadto algorytmy rozwiązywania plików binarnych pojawiły się dopiero w latach 1980. i 1990. XX wieku. W artykule z 1983 r Crowdera, Johnsona i Padberga donosi o jednym z pierwszych praktycznych rozwiązań optymalizacji za pomocą plików binarnych. Zauważają znaczenie sprytnego przetwarzania wstępnego oraz metod rozgałęziania i wiązania, które mają kluczowe znaczenie dla pomyślnego rozwiązania.
Niedawna eksplozja wykorzystania programowania z ograniczeniami i oprogramowania, takiego jak lokalny rozwiązujący wyjaśniło znaczenie stosowania metod sztucznej inteligencji z oryginalnymi metodami optymalizacyjnymi, takimi jak programowanie liniowe i metoda najmniejszych kwadratów.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- zdolność
- pomieścić
- w dodatku
- dodatek
- Dodatkowy
- do tego
- zaawansowany
- ponownie
- AI
- algorytm
- Algorytmy
- Wszystkie kategorie
- dozwolony
- już
- również
- zawsze
- Amazonka
- an
- i
- Inne
- każdy
- zjawić się
- podejście
- arbitralny
- SĄ
- POWIERZCHNIA
- Szyk
- sztuczny
- sztuczna inteligencja
- Sztuczna inteligencja (AI)
- AS
- przydzielony
- założyć
- At
- Uwaga
- dostępny
- z powrotem
- BE
- być
- zanim
- należący
- należy
- pomiędzy
- pusty
- Blog
- deska
- obie
- związany
- Pudełko
- Skrzynki
- Oddział
- ale
- by
- nazywa
- CAN
- kandydat
- kandydatów
- nie może
- Zajęte
- sufit
- Uroczystość
- komórka
- Komórki
- wyzwania
- szansa
- ZOBACZ
- kontrola
- twierdził,
- jasny
- kolor
- Kolumna
- kolumny
- powszechnie
- Zakończony
- kompleks
- Warunki
- konflikt
- konflikty
- zawiera
- treść
- ciągły
- rdzeń
- kamień węgielny
- stworzony
- krytyczny
- Aktualny
- dane
- dzień
- martwy
- zdecydować
- opis
- detal
- szczegółowe
- detale
- ustalona
- różne
- cyfry
- do
- robi
- dominujący
- zrobić
- nie
- dramatycznie
- duplikaty
- każdy
- łatwo
- bądź
- Elementy
- wyeliminować
- wyłaniać się
- Umożliwia
- obejmuje
- zakończenia
- Nieskończony
- silnik
- silniki
- zapewnia
- Cały
- itp
- przykład
- wyjaśnione
- eksplozja
- Failed
- daleko
- wykonalny
- wypełniać
- Znajdź
- znajduje
- w porządku
- i terminów, a
- poprawki
- koncentruje
- obserwuj
- następujący
- W razie zamówieenia projektu
- formuła
- sformułowanie
- znaleziono
- od
- zabawa
- funkcjonować
- Funkcje
- miejsce
- dany
- Krata
- miał
- Uchwyty
- Have
- Serce
- pomocny
- historia
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- ID
- identyfikuje
- zidentyfikować
- identyfikacja
- if
- zilustrować
- realizowane
- znaczenie
- in
- Włącznie
- wskaźnik
- wskazany
- wskazując,
- indywidualny
- Informacja
- informuje
- wewnątrz
- zamiast
- Instytut
- Inteligencja
- wewnętrznie
- intuicyjny
- IT
- iteracja
- JEGO
- Johnson
- jpg
- właśnie
- Trzymać
- trzymane
- Wiedzieć
- język
- Nazwisko
- później
- łacina
- nauka
- najmniej
- lewo
- poziom
- liniowy
- Lista
- log
- logika
- dłużej
- Popatrz
- wyglądał
- poszukuje
- maszyna
- uczenie maszynowe
- zrobiony
- robić
- Maksymalna szerokość
- Może..
- znaczy
- zmierzyć
- metoda
- metody
- Nowoczesne technologie
- jeszcze
- narodowy
- Potrzebować
- wymagania
- sąsiedzi
- dziewięć
- Nie
- noty
- już dziś
- numer
- cel
- obserwować
- miejsce
- of
- on
- pewnego razu
- ONE
- tylko
- optymalizacja
- Option
- Opcje
- or
- zamówienie
- oryginalny
- ludzkiej,
- na zewnątrz
- Papier
- Parallel
- część
- ścieżka
- doskonały
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- kawałek
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- gra
- punkt
- Popularny
- możliwy
- napisali
- mocny
- Praktyczny
- poprzednio
- Problem
- wygląda tak
- przetwarzanie
- Programowanie
- zapewniać
- zapewnia
- położyć
- puzzle
- Puzzle
- Rage
- zasięg
- niedawny
- powtarzające się
- Czerwony
- zmniejszyć
- regiony
- regresja
- uczenie się wzmacniania
- powtórzony
- Raporty
- reprezentacja
- RZĄD
- Zasada
- taki sam
- szeregowanie
- Szukaj
- Wyszukiwarka
- druga
- Sekcja
- Zabezpiecza
- widzieć
- wybierać
- wybrany
- zestaw
- Shape
- pokazane
- Targi
- podobny
- pojedynczy
- So
- Tworzenie
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- Źródło
- Typ przestrzeni
- Kwadratowa
- kwadraty
- początek
- Startowy
- rozpocznie
- Ewolucja krok po kroku
- Cel
- Nadal
- sklep
- przechowywany
- jest determinacja.
- silniejszy
- Struktura
- Struktury
- udany
- taki
- przełożony
- wsparcie
- Powierzchnia
- stół
- sprzęt
- Brać
- niż
- że
- Połączenia
- Źródło
- motyw
- następnie
- Tam.
- Te
- one
- Trzeci
- to
- mocniej
- czasy
- do
- Kwota produktów:
- śledzić
- Śledzenie
- próbować
- SKRĘCAĆ
- włącza
- Dwa razy
- drugiej
- rodzaj
- zazwyczaj
- wyjątkowy
- nieznany
- aż do
- Aktualizacja
- zaktualizowane
- us
- posługiwać się
- używany
- zastosowania
- za pomocą
- wartość
- Wartości
- zmienna
- początku.
- była
- we
- były
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- który
- biały
- szeroki
- Szeroki zasięg
- Wikipedia
- będzie
- w
- bez
- działa
- by
- lat
- z żółtymi
- zefirnet
- zero