SmugMug obsługuje dwie bardzo duże internetowe platformy fotograficzne, SmugMug i Flickr, umożliwiając ponad 100 milionom klientów bezpieczne przechowywanie, wyszukiwanie, udostępnianie i sprzedaż dziesiątek miliardów zdjęć. Klienci przesyłający i przeszukujący zdjęcia od kilkudziesięciu lat pomogli przekształcić wyszukiwanie w infrastrukturę krytyczną, która stale rośnie od czasu pierwszego użycia SmugMug Amazon CloudSearch w 2012, a następnie Usługa Amazon OpenSearch od 2018 r., po osiągnięciu miliardów dokumentów i terabajtów przestrzeni wyszukiwania.
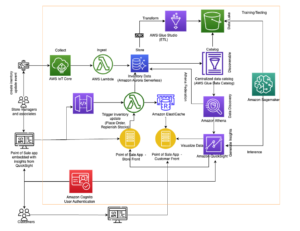
W tym miejscu Lee Shepherd, inżynier personelu SmugMug, dzieli się architekturą wyszukiwania SmugMug używaną do publikowania, uzupełniania i odzwierciedlania ruchu na żywo w wielu klastrach. SmugMug wykorzystuje te potoki do testów porównawczych, sprawdzania poprawności i migracji do nowych konfiguracji, w tym instancji r6gd.2xlarge opartych na Graviton z i3.2xlarge, wraz z testowaniem Amazon OpenSearch bez serwera. Omawiamy trzy potoki używane do publikowania, wypełniania kopii zapasowych i wykonywania zapytań bez wprowadzania kolczastych, nierealistycznych wzorców ruchu i bez żadnego wpływu na usługi produkcyjne.
Istnieją dwa główne elementy architektoniczne krytyczne dla tego procesu:
- Trwałe źródło prawdy dla danych indeksowych. To najlepsza praktyka i część naszej strategii tworzenia kopii zapasowych, polegającej na posiadaniu trwałego sklepu poza indeksem OpenSearch, oraz Amazon DynamoDB zapewnia skalowalność i integrację z AWS Lambda to upraszcza wiele procesów. Używamy DynamoDB do innych usług niezwiązanych z wyszukiwaniem, więc było to naturalne dopasowanie.
- Funkcja Lambda do publikowania danych ze źródła prawdy w OpenSearch. Za pomocą aliasy funkcji pomaga uruchomić wiele konfiguracji tej samej funkcji Lambda w tym samym czasie i jest kluczem do synchronizacji danych.
Wydawniczy
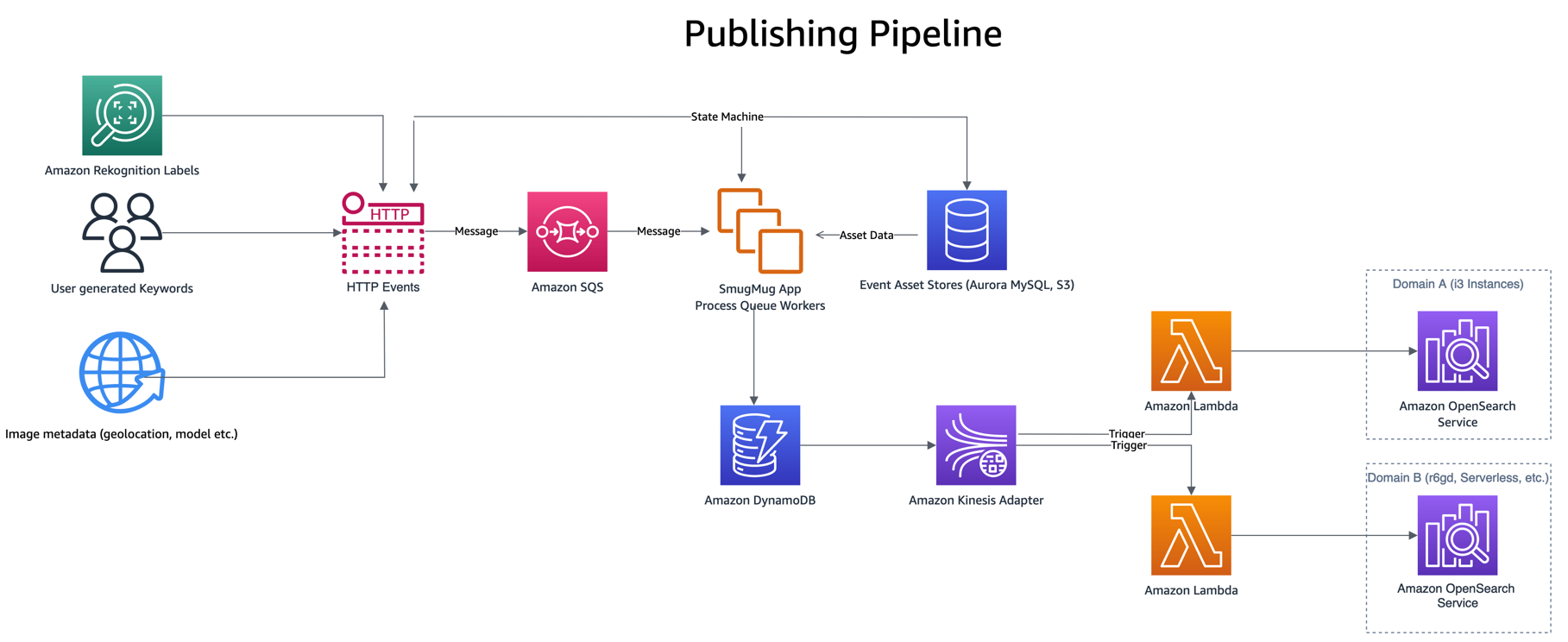
Proces publikowania opiera się na zdarzeniach, takich jak wprowadzenie przez użytkownika słów kluczowych lub podpisów, nowe przesłane treści lub wykrycie etykiety Amazon Rekognition. Zdarzenia te są przetwarzane poprzez połączenie danych z kilku innych magazynów aktywów, takich jak Wersja kompatybilna z Amazon Aurora MySQL i Usługa Amazon Simple Storage (Amazon S3), przed zapisaniem pojedynczego elementu w DynamoDB.
Zapisywanie w DynamoDB wywołuje funkcję publikowania Lambda za pośrednictwem pliku Adapter kinezy strumieni DynamoDB, który pobiera partię zaktualizowanych elementów z DynamoDB i indeksuje je w OpenSearch. Korzystanie z adaptera kinezy strumieni DynamoDB ma inne zalety, takie jak zmniejszenie liczby wymaganych jednoczesnych lambd.
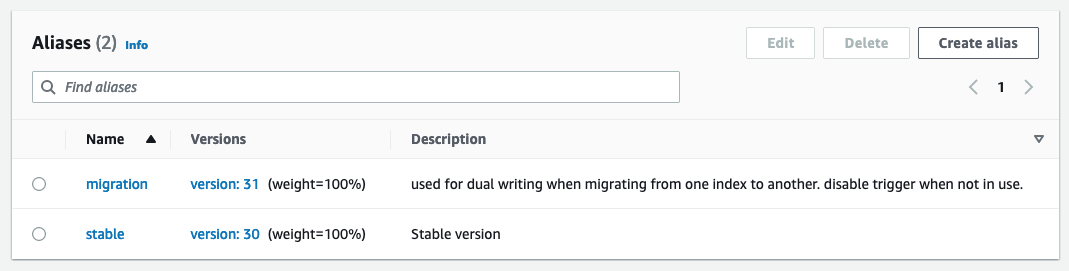
Funkcja Lambda publikowania używa zmiennych środowiskowych do określenia domeny i indeksu OpenSearch, w którym należy publikować. Alias produkcyjny jest skonfigurowany do zapisu w produkcyjnej domenie OpenSearch poza tabelą DynamoDB lub strumieniem Kinesis
Podczas testowania nowych konfiguracji lub migracji alias migracji jest konfigurowany tak, aby zapisywał w nowej domenie OpenSearch, ale korzystał z tego samego wyzwalacza, co alias produkcyjny. Umożliwia to podwójne indeksowanie danych jednocześnie w obu domenach usługi OpenSearch.
Oto przykład schematu tabeli DynamoDB:
Wartość „LastUpdated” jest używana jako wersja dokumentu podczas indeksowania, co pozwala OpenSearch na odrzucenie wszelkich aktualizacji spoza kolejności.
Zasypywanie
Teraz, gdy zmiany są już publikowane w obu domenach, nowa domena (indeks) wymaga uzupełnienia danymi historycznymi. Aby uzupełnić nowo utworzony indeks, należy zastosować kombinację Usługa prostej kolejki Amazon (Amazon SQS) i używany jest DynamoDB. Skrypt zapełnia kolejkę SQS komunikatami zawierającymi instrukcje dotyczące skanowanie równoległe segment tabeli DynamoDB.
Kolejka SQS uruchamia funkcję Lambda, która odczytuje instrukcje komunikatu, pobiera partię elementów z odpowiedniego segmentu tabeli DynamoDB i zapisuje je do indeksu OpenSearch. Nowe komunikaty są zapisywane w kolejce SQS w celu śledzenia postępu w segmencie. Po zakończeniu segmentu w kolejce SQS nie są już zapisywane żadne komunikaty, a proces się zatrzymuje.
Współbieżność jest określana na podstawie liczby segmentów, z dodatkową kontrolą zapewnianą przez skalowanie współbieżności Lambda. SmugMug jest w stanie zaindeksować ponad 1 miliard dokumentów na godzinę w konfiguracji OpenSearch, nie powodując przy tym żadnego wpływu na domenę produkcyjną.
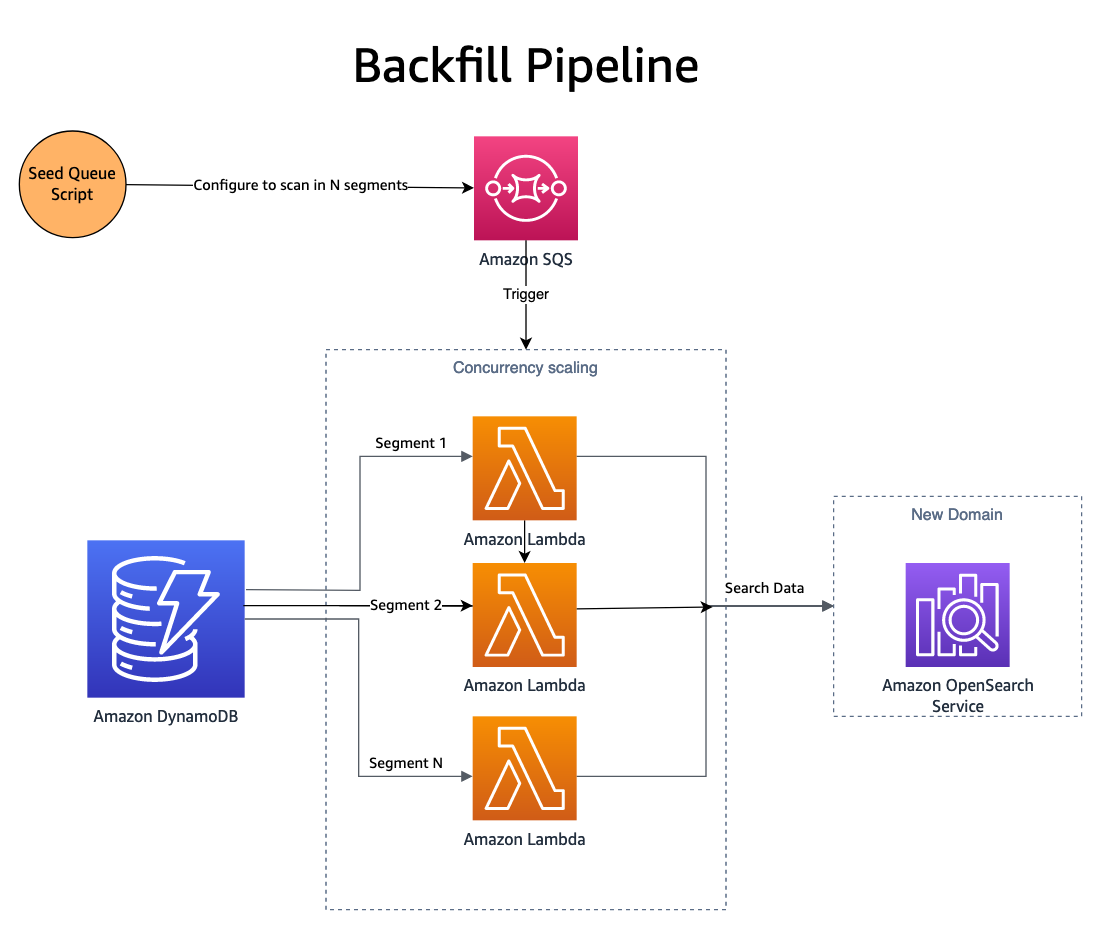
Do inicjowania kolejki SQS używany jest skrypt oparty na NodeJS AWS-SDK. Oto fragment opcji skryptu konfiguracyjnego SQS:
Wraz z formatem wynikowego komunikatu SQS:
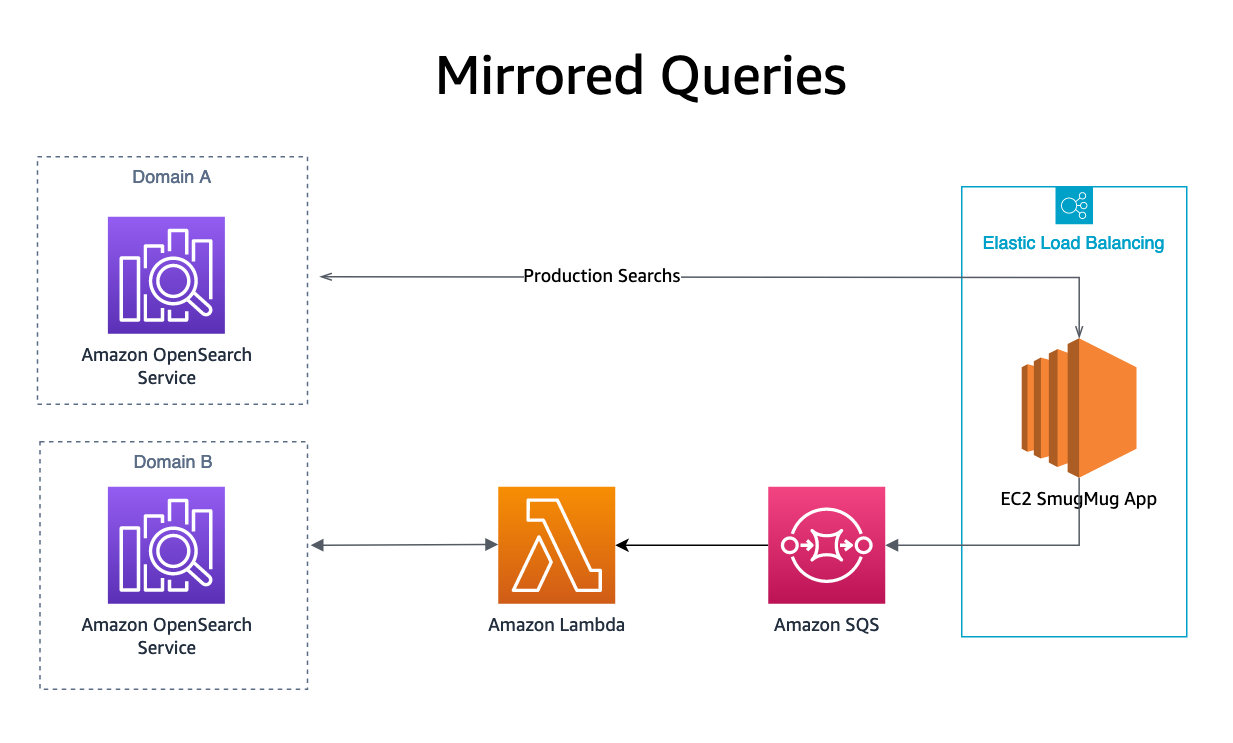
Lustrzane odbicie
Ostatni, nasz lustrzane zapytanie wyszukiwania wyniki są uruchamiane poprzez wysłanie zapytania OpenSearch do kolejki SQS, oprócz naszej domeny produkcyjnej. Kolejka SQS uruchamia funkcję Lambda, która odtwarza zapytanie do domeny repliki. Wyniki wyszukiwania z tych żądań nie są wysyłane do żadnego użytkownika, ale umożliwiają replikację obciążenia produkcyjnego w testowanej usłudze OpenSearch bez wpływu na systemy produkcyjne lub klientów.
Wnioski
Podczas oceniania nowej domeny lub konfiguracji OpenSearch głównymi wskaźnikami, które nas interesują, są wydajność opóźnień zapytań, a mianowicie opóźnienia wzięte (opóźnienia na czas) i, co najważniejsze, opóźnienia wyszukiwania. Po przejściu na Graviton R6gd zaobserwowaliśmy około 40 procent mniejsze opóźnienia P50-P99, wraz z podobnym wzrostem wykorzystania procesora w porównaniu do i3 (pomijając niższe koszty Graviton). Kolejną mile widzianą korzyścią było bardziej przewidywalne i monitorowalne obciążenie pamięci JVM wraz ze zmianami w usuwaniu elementów bezużytecznych po dodaniu G1GC na R6gd i innych nowych instancjach.
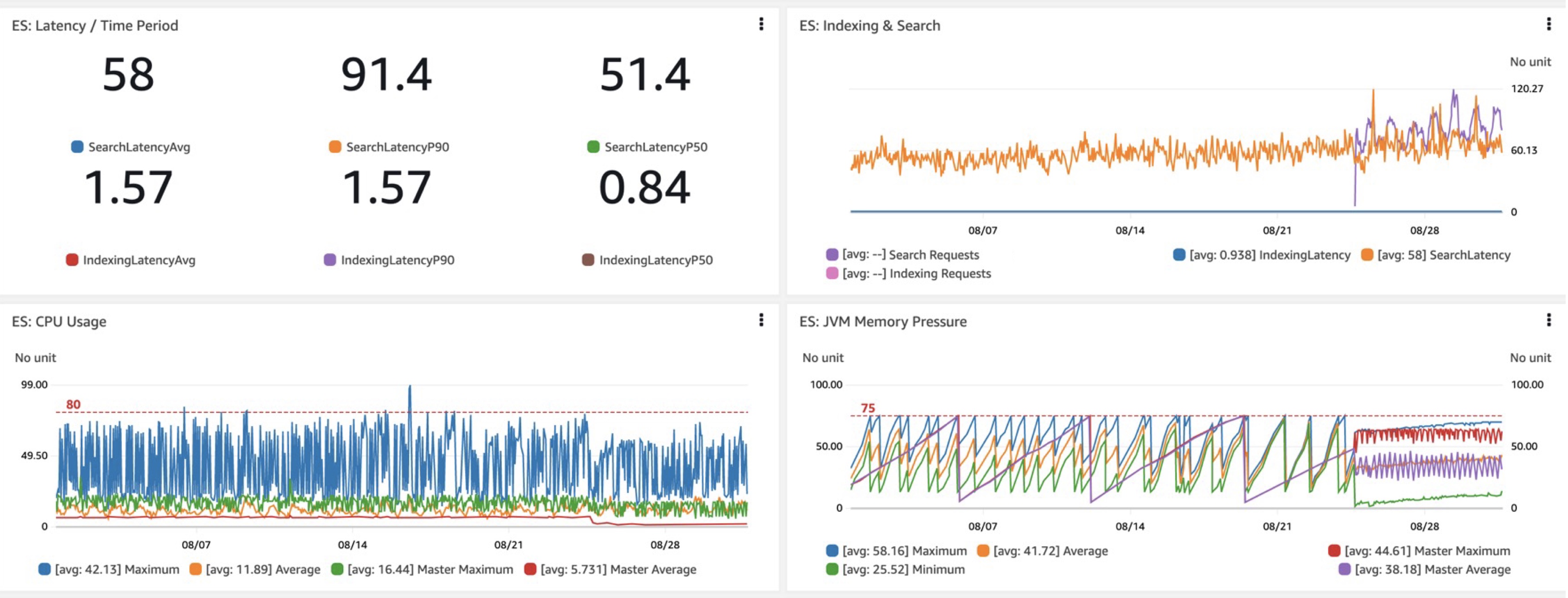
Korzystając z tego potoku, testujemy także OpenSearch Serverless i znajdujemy jego najlepsze przypadki użycia. Jesteśmy podekscytowani tą usługą i mamy zamiar z czasem mieć architekturę całkowicie bezserwerową. Bądź na bieżąco z wynikami.
O autorach
Lee Shepherda jest inżynierem oprogramowania SmugMug
Aydna Bekirova jest głównym technicznym menedżerem klienta Amazon Web Services
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/
- :Jest
- :nie
- 1
- 100
- 12
- 14
- 20
- 2012
- 2018
- 40
- 7
- 9
- a
- Zdolny
- O nas
- Konto
- w dodatku
- dodatek
- Dodatkowy
- Po
- dopuszczać
- Pozwalać
- wzdłuż
- również
- Amazonka
- Amazon Web Services
- an
- i
- Inne
- każdy
- architektoniczny
- architektura
- SĄ
- AS
- kapitał
- At
- jutrzenka
- AWS
- backup
- na podstawie
- BE
- zanim
- jest
- Benchmark
- korzyści
- Korzyści
- BEST
- Poza
- Miliard
- miliardy
- obie
- ale
- by
- podpisy
- Zmiany
- kolekcja
- połączenie
- łączenie
- w porównaniu
- zgodny
- Ukończył
- równoległy
- systemu
- skonfigurowany
- zawierać
- kontroli
- Odpowiedni
- Koszty:
- pokrywa
- CPU
- stworzony
- krytyczny
- Infrastruktura krytyczna
- Klientów
- dane
- lat
- Wykrywanie
- Ustalać
- ustalona
- dokument
- dokumenty
- domena
- domeny
- napędzany
- każdy
- Umożliwia
- umożliwiając
- Punkt końcowy
- inżynier
- wprowadzenie
- całkowicie
- Środowisko
- Eter (ETH)
- oceny
- wydarzenia
- przykład
- podniecony
- kilka
- Łąka
- znalezieniu
- i terminów, a
- dopasować
- następnie
- W razie zamówieenia projektu
- format
- od
- w pełni
- funkcjonować
- Zyski
- Rozwój
- Have
- wysokość
- pomógł
- pomaga
- historyczny
- godzina
- HTML
- http
- HTTPS
- i
- i3
- ID
- Rezultat
- co ważne
- in
- Włącznie z
- wskaźnik
- indeksy
- Infrastruktura
- instancje
- instrukcje
- integracja
- Zamierzam
- zainteresowany
- najnowszych
- wprowadzenie
- inwokuje
- szt
- iteracja
- JEGO
- samo
- jpg
- Trzymać
- konserwacja
- Klawisz
- słowa kluczowe
- Etykieta
- duży
- Utajenie
- uruchamia
- Lee
- lubić
- relacja na żywo
- załadować
- Partia
- niższy
- Główny
- Pamięć
- wiadomość
- wiadomości
- Metryka
- migrować
- migracja
- migracja
- milion
- milionów klientów
- lustro
- jeszcze
- większość
- ruch
- wielokrotność
- MySQL
- Nazwa
- mianowicie
- Naturalny
- wymagania
- Nowości
- nowo
- Następny
- Nie
- numer
- of
- poza
- on
- Online
- działa
- Opcje
- Opcje
- or
- Inne
- ludzkiej,
- Parallel
- część
- wzory
- dla
- procent
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- ZDJĘCIA
- sztuk
- rurociąg
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Możliwy do przewidzenia
- nacisk
- poprzedni
- Główny
- wygląda tak
- obrobiony
- Produkcja
- Postęp
- pod warunkiem,
- zapewnia
- publikować
- opublikowany
- Wydawniczy
- osiągnięcie
- redukcja
- odpowiedzieć
- wywołań
- wymagany
- wynikły
- Efekt
- run
- bezpiecznie
- taki sam
- zobaczył
- Skalowalność
- skalowaniem
- scenariusz
- Szukaj
- poszukiwania
- nasienie
- segment
- Segmenty
- sprzedać
- wysyłanie
- wysłany
- Bezserwerowe
- usługa
- Usługi
- Share
- Akcje
- podobny
- Prosty
- jednocześnie
- ponieważ
- pojedynczy
- skrawek
- So
- Tworzenie
- Źródło
- Personel
- pobyt
- stale
- Zatrzymuje
- przechowywanie
- sklep
- sklep
- Strategia
- Strumienie
- taki
- systemy
- stół
- trwa
- Techniczny
- kilkadziesiąt
- test
- Testowanie
- niż
- że
- Połączenia
- Źródło
- ich
- Im
- Tam.
- Te
- to
- trzy
- Przez
- czas
- do
- wziął
- śledzić
- ruch drogowy
- wyzwalać
- Prawda
- SKRĘCAĆ
- drugiej
- dla
- zaktualizowane
- Nowości
- Uploading
- URL
- Stosowanie
- posługiwać się
- przypadków użycia
- używany
- Użytkownik
- zastosowania
- za pomocą
- UPRAWOMOCNIĆ
- wartość
- wersja
- początku.
- była
- we
- sieć
- usługi internetowe
- powitanie
- Co
- jeśli chodzi o komunikację i motywację
- Podczas
- w
- bez
- napisać
- pisanie
- napisany
- zefirnet
- zero