Wraz z pojawieniem się generatywnej sztucznej inteligencji dzisiejsze podstawowe modele (FM), takie jak duże modele językowe (LLM) Claude 2 i Llama 2, mogą wykonywać szereg zadań generatywnych, takich jak odpowiadanie na pytania, podsumowywanie i tworzenie treści na danych tekstowych. Jednak dane ze świata rzeczywistego istnieją w wielu postaciach, takich jak tekst, obrazy, wideo i audio. Weźmy na przykład prezentację slajdów programu PowerPoint. Może zawierać informacje w formie tekstu lub osadzone na wykresach, tabelach i obrazach.
W tym poście przedstawiamy rozwiązanie wykorzystujące multimodalne FM takie jak Multimodalne osadzania Amazon Titan model i LLaVA 1.5 i usługi AWS, w tym Amazońska skała macierzysta i Amazon Sage Maker do wykonywania podobnych zadań generatywnych na danych multimodalnych.
Omówienie rozwiązania
Rozwiązanie zapewnia implementację odpowiadania na pytania z wykorzystaniem informacji zawartych w elementach tekstowych i wizualnych slidera. Projekt opiera się na koncepcji generacji rozszerzonej odzyskiwania (RAG). Tradycyjnie RAG kojarzono z danymi tekstowymi, które mogą być przetwarzane przez LLM. W tym poście rozszerzamy RAG o również obrazy. Zapewnia to zaawansowane możliwości wyszukiwania w celu wyodrębnienia treści odpowiednich kontekstowo z elementów wizualnych, takich jak tabele i wykresy, wraz z tekstem.
Istnieją różne sposoby projektowania rozwiązania RAG zawierającego obrazy. Zaprezentowaliśmy tutaj jedno podejście, a w drugim poście z tej trzyczęściowej serii przedstawimy alternatywne podejście.
To rozwiązanie zawiera następujące elementy:
- Model osadzania multimodalnego Amazon Titan – Ten FM służy do generowania osadzania treści w talii slajdów użytej w tym poście. Jako model multimodalny, ten model Titan może przetwarzać tekst, obrazy lub ich kombinację jako dane wejściowe i generować osadzania. Model Titan Multimodal Embeddings generuje wektory (osadzenia) o 1,024 wymiarach i jest dostępny za pośrednictwem Amazon Bedrock.
- Duży asystent językowy i wzrokowy (LLaVA) – LLaVA to multimodalny model open source do zrozumienia wizualnego i językowego, używany do interpretacji danych na slajdach, w tym elementów wizualnych, takich jak wykresy i tabele. Używamy wersji z 7 miliardami parametrów LLaVA 1.5-7b w tym rozwiązaniu.
- Amazon Sage Maker – Model LLaVA jest wdrażany na punkcie końcowym SageMaker przy użyciu usług hostingowych SageMaker, a uzyskany punkt końcowy wykorzystujemy do wyciągania wniosków na podstawie modelu LLaVA. Do koordynowania i demonstrowania kompleksowego rozwiązania używamy także notatników SageMaker.
- Amazon OpenSearch bez serwera – OpenSearch Serverless to bezserwerowa konfiguracja na żądanie dla Usługa Amazon OpenSearch. Używamy OpenSearch Serverless jako wektorowej bazy danych do przechowywania osadzań generowanych przez model Titan Multimodal Embeddings. Indeks utworzony w kolekcji OpenSearch Serverless służy jako magazyn wektorów dla naszego rozwiązania RAG.
- Przetwarzanie Amazon OpenSearch (OSI) – OSI to w pełni zarządzany, bezserwerowy moduł gromadzący dane, który dostarcza dane do domen usługi OpenSearch i kolekcji OpenSearch Serverless. W tym poście używamy potoku OSI do dostarczania danych do magazynu wektorów OpenSearch Serverless.
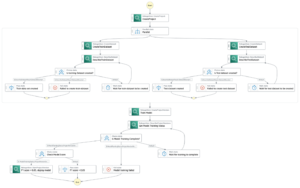
Architektura rozwiązania
Projekt rozwiązania składa się z dwóch części: pozyskiwania i interakcji z użytkownikiem. Podczas przetwarzania przetwarzamy wejściowy zestaw slajdów, konwertując każdy slajd na obraz, generując elementy osadzone dla tych obrazów, a następnie wypełniając magazyn danych wektorowych. Te kroki są wykonywane przed etapami interakcji z użytkownikiem.
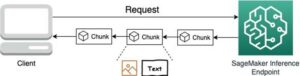
Na etapie interakcji z użytkownikiem pytanie użytkownika jest konwertowane na elementy osadzone, a w bazie danych wektorów przeprowadzane jest wyszukiwanie podobieństw w celu znalezienia slajdu, który może potencjalnie zawierać odpowiedzi na pytanie użytkownika. Następnie dostarczamy ten slajd (w formie pliku obrazu) do modelu LLaVA i pytanie użytkownika jako zachętę do wygenerowania odpowiedzi na zapytanie. Cały kod tego wpisu jest dostępny w pliku GitHub repozytorium.
Poniższy diagram ilustruje architekturę pozyskiwania.
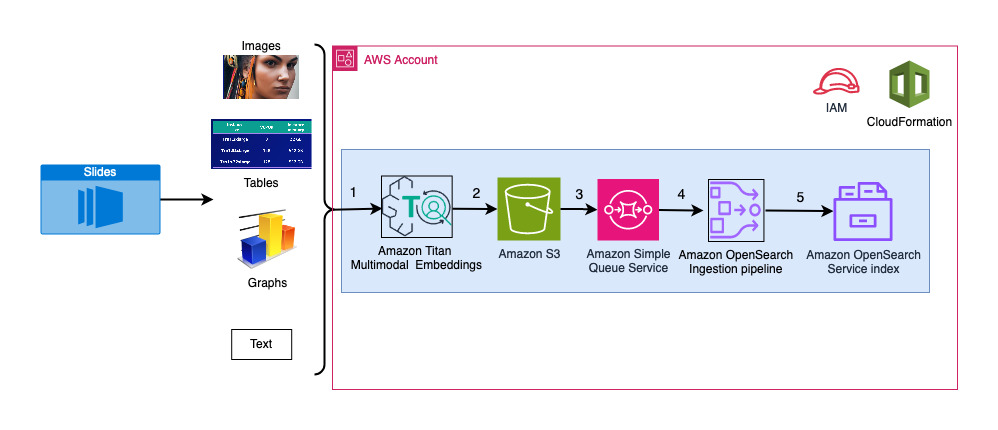
Kroki przepływu pracy są następujące:
- Slajdy są konwertowane na pliki obrazów (po jednym na slajd) w formacie JPG i przekazywane do modelu Titan Multimodal Embeddings w celu wygenerowania osadów. W tym poście używamy talii slajdów zatytułowanej Trenuj i wdrażaj Stable Diffusion przy użyciu AWS Trainium i AWS Inferentia ze szczytu AWS w Toronto w czerwcu 2023 r., aby zademonstrować rozwiązanie. Przykładowa talia zawiera 31 slajdów, więc generujemy 31 zestawów osadzania wektorów, każdy o 1,024 wymiarach. Do wygenerowanych osadzań wektorowych dodajemy dodatkowe pola metadanych i tworzymy plik JSON. Tych dodatkowych pól metadanych można używać do wykonywania rozbudowanych zapytań wyszukiwania, korzystając z potężnych możliwości wyszukiwania OpenSearch.
- Wygenerowane osadzania są gromadzone w jednym pliku JSON, który jest przesyłany do Usługa Amazon Simple Storage (Amazonka S3).
- Przez Powiadomienia o wydarzeniach Amazon S3, wydarzenie jest umieszczane w pliku Usługa Amazon Simple Queue (Amazon SQS) kolejka.
- To zdarzenie w kolejce SQS działa jako wyzwalacz uruchomienia potoku OSI, który z kolei pobiera dane (plik JSON) jako dokumenty do indeksu OpenSearch Serverless. Należy zauważyć, że indeks OpenSearch Serverless jest skonfigurowany jako ujście tego potoku i jest tworzony jako część kolekcji OpenSearch Serverless.
Poniższy diagram ilustruje architekturę interakcji użytkownika.
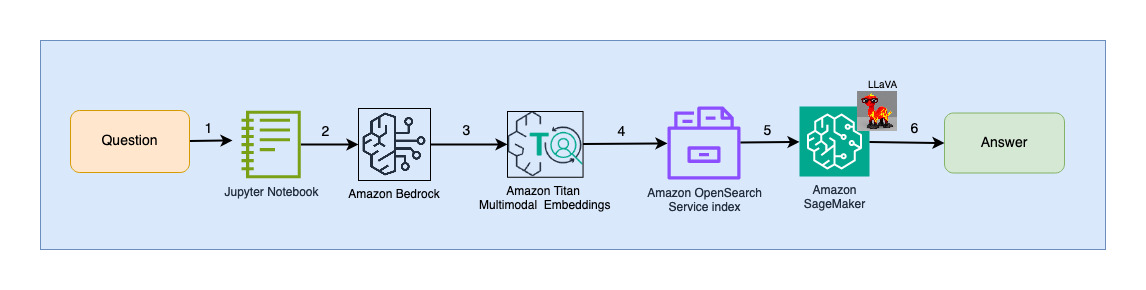
Kroki przepływu pracy są następujące:
- Użytkownik przesyła pytanie dotyczące przetworzonego zestawu slajdów.
- Dane wejściowe użytkownika są konwertowane na osady przy użyciu modelu Titan Multimodal Embeddings, do którego można uzyskać dostęp za pośrednictwem Amazon Bedrock. Wyszukiwanie wektorowe OpenSearch odbywa się przy użyciu tych osadzania. Wykonujemy wyszukiwanie k-najbliższego sąsiada (k=1), aby uzyskać najbardziej odpowiednie osadzenie pasujące do zapytania użytkownika. Ustawienie k=1 powoduje pobranie slajdu najbardziej odpowiedniego do pytania użytkownika.
- Metadane odpowiedzi z OpenSearch Serverless zawierają ścieżkę do obrazu odpowiadającego najodpowiedniejszemu slajdowi.
- Podpowiedź tworzona jest poprzez połączenie pytania użytkownika i ścieżki obrazu i dostarczana do LLaVA hostowanej w SageMaker. Model LLaVA jest w stanie zrozumieć pytanie użytkownika i odpowiedzieć na nie, badając dane na obrazie.
- Wynik tego wnioskowania jest zwracany użytkownikowi.
Kroki te omówiono szczegółowo w poniższych sekcjach. Zobacz Efekt sekcja zawierająca zrzuty ekranu i szczegółowe informacje na temat wyników.
Wymagania wstępne
Aby wdrożyć rozwiązanie podane w tym poście, powinieneś mieć plik Konto AWS oraz znajomość FM, Amazon Bedrock, SageMaker i OpenSearch Service.
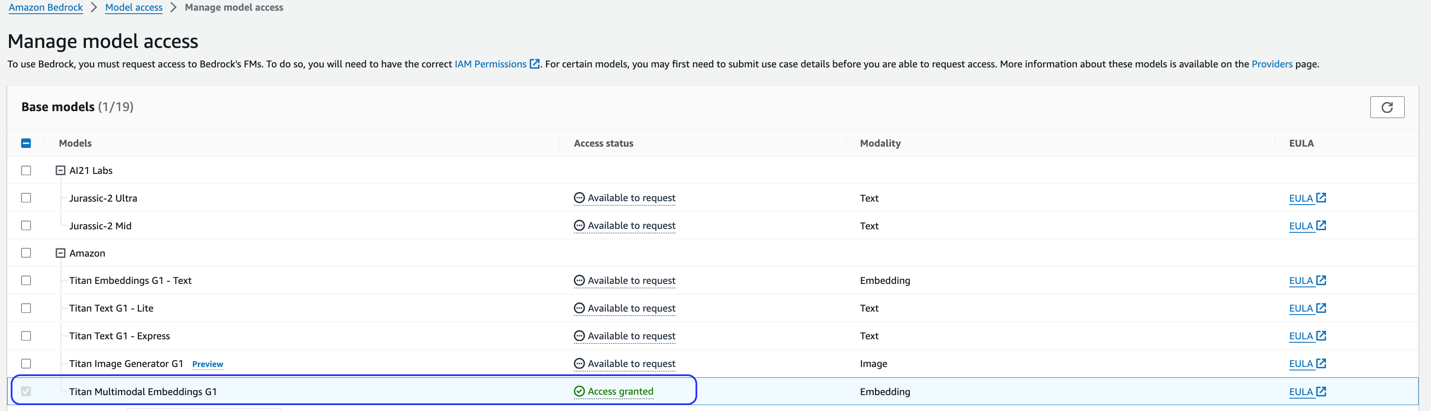
W rozwiązaniu tym zastosowano model Titan Multimodal Embeddings. Upewnij się, że ten model jest włączony do użytku w Amazon Bedrock. Na konsoli Amazon Bedrock wybierz Dostęp do modelu w panelu nawigacji. Jeśli włączona jest funkcja Titan Multimodal Embeddings, zostanie wyświetlony status dostępu Dostęp przyznany.
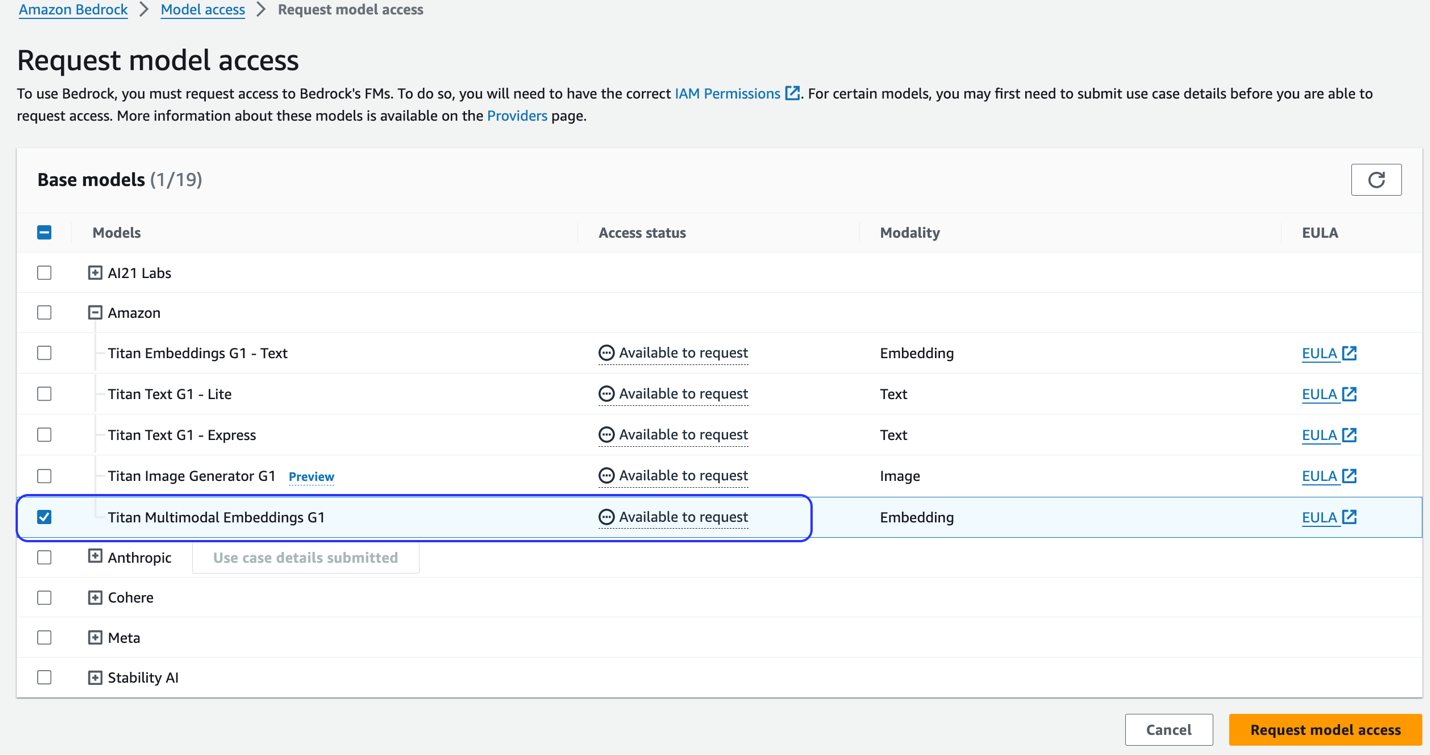
Jeśli model nie jest dostępny, włącz dostęp do modelu, wybierając Zarządzaj dostępem do modelu, wybierając Multimodalne osadzanie Titan G1i wybór Poproś o dostęp do modelu. Model jest natychmiast udostępniany do użytku.
Użyj szablonu AWS CloudFormation, aby utworzyć stos rozwiązań
Użyj jednego z poniższych Tworzenie chmury AWS szablony (w zależności od regionu), aby uruchomić zasoby rozwiązania.
| Region AWS | Połączyć |
|---|---|
us-east-1 |
|
us-west-2 |
Po pomyślnym utworzeniu stosu przejdź do stosu Wyjścia tab w konsoli AWS CloudFormation i zanotuj wartość MultimodalCollectionEndpoint, z którego korzystamy w kolejnych krokach.
Szablon CloudFormation tworzy następujące zasoby:
- Role IAM - Następujące AWS Zarządzanie tożsamością i dostępem Tworzone są role (IAM). Zaktualizuj te role, aby je zastosować uprawnienia o najniższych uprawnieniach.
SMExecutionRolez pełnym dostępem do Amazon S3, SageMaker, OpenSearch Service i Bedrock.OSPipelineExecutionRolez dostępem do konkretnych działań Amazon SQS i OSI.
- Notatnik SageMakera – Cały kod tego posta jest uruchamiany za pośrednictwem tego notatnika.
- Bezserwerowa kolekcja OpenSearch – Jest to baza danych wektorów służąca do przechowywania i wyszukiwania osadzonych elementów.
- Rurociąg OSI – To jest potok pozyskiwania danych do OpenSearch Serverless.
- Wiadro S3 – Wszystkie dane dla tego wpisu są przechowywane w tym zasobniku.
- Kolejka do SQS – W tej kolejce umieszczane są zdarzenia wyzwalające uruchomienie potoku OSI.
Szablon CloudFormation konfiguruje potok OSI z przetwarzaniem Amazon S3 i Amazon SQS jako źródłem oraz indeksem OpenSearch Serverless jako ujściem. Wszelkie obiekty utworzone w określonym segmencie S3 i przedrostku (multimodal/osi-embeddings-json) wyzwoli powiadomienia SQS, które są wykorzystywane przez potok OSI do pozyskiwania danych do OpenSearch Serverless.
Tworzy się również szablon CloudFormation sieć, szyfrowanie, dostęp do danych zasady wymagane dla kolekcji OpenSearch Serverless. Zaktualizuj te zasady, aby zastosować uprawnienia o najniższych uprawnieniach.
Należy pamiętać, że w notatnikach SageMaker znajduje się odwołanie do nazwy szablonu CloudFormation. Jeśli domyślna nazwa szablonu zostanie zmieniona, pamiętaj o zaktualizowaniu tej samej nazwy w globals.py
Przetestuj rozwiązanie
Po wykonaniu wymaganych kroków i pomyślnym utworzeniu stosu CloudFormation możesz teraz przetestować rozwiązanie:
- W konsoli SageMaker wybierz Notebooki w okienku nawigacji.
- Wybierz
MultimodalNotebookInstanceinstancję notatnika i wybierz Otwórz JupyterLab.
- In Przeglądarka plików, przejdź do folderu notesów, aby wyświetlić notesy i pliki pomocnicze.
Zeszyty są ponumerowane w kolejności, w jakiej są prowadzone. Instrukcje i komentarze w każdym notatniku opisują działania wykonywane przez ten notatnik. Prowadzimy te notesy jeden po drugim.
- Dodaj 0_deploy_llava.ipynb aby otworzyć go w JupyterLab.
- Na run menu, wybierz Uruchom wszystkie komórki aby uruchomić kod w tym notatniku.
Ten notatnik wdraża model LLaVA-v1.5-7B w punkcie końcowym SageMaker. W tym notatniku pobieramy model LLaVA-v1.5-7B z HuggingFace Hub, zamieniamy skrypt inference.py na llava_inference.pyi utwórz plik model.tar.gz dla tego modelu. Plik model.tar.gz jest przesyłany do Amazon S3 i używany do wdrażania modelu na punkcie końcowym SageMaker. The llava_inference.py skrypt posiada dodatkowy kod umożliwiający odczytanie pliku obrazu z Amazon S3 i uruchomienie na nim wnioskowania.
- Dodaj 1_data_prep.ipynb aby otworzyć go w JupyterLab.
- Na run menu, wybierz Uruchom wszystkie komórki aby uruchomić kod w tym notatniku.
Ten notatnik pobiera plik zjeżdżalnia, konwertuje każdy slajd do formatu pliku JPG i przesyła go do zasobnika S3 użytego w tym poście.
- Dodaj 2_data_ingestion.ipynb aby otworzyć go w JupyterLab.
- Na run menu, wybierz Uruchom wszystkie komórki aby uruchomić kod w tym notatniku.
W tym notatniku wykonujemy następujące czynności:
- Tworzymy indeks w kolekcji OpenSearch Serverless. Ten indeks przechowuje dane osadzenia dla talii slajdów. Zobacz następujący kod:
- Używamy modelu Titan Multimodal Embeddings do konwersji obrazów JPG utworzonych w poprzednim notatniku na osadzania wektorowe. Te osadzenia i dodatkowe metadane (takie jak ścieżka S3 pliku obrazu) są przechowywane w pliku JSON i przesyłane do Amazon S3. Należy pamiętać, że tworzony jest pojedynczy plik JSON, który zawiera dokumenty dla wszystkich slajdów (obrazów) przekonwertowanych na elementy osadzone. Poniższy fragment kodu pokazuje, jak obraz (w postaci ciągu zakodowanego w formacie Base64) jest konwertowany na elementy osadzone:
- Ta akcja uruchamia potok pozyskiwania OpenSearch, który przetwarza plik i pobiera go do indeksu OpenSearch Serverless. Poniżej znajduje się przykład utworzonego pliku JSON. (W przykładowym kodzie pokazano wektor z czterema wymiarami. Model Titan Multimodal Embeddings generuje 1,024 wymiary.)
- Dodaj 3_rag_inference.ipynb aby otworzyć go w JupyterLab.
- Na run menu, wybierz Uruchom wszystkie komórki aby uruchomić kod w tym notatniku.
W tym notatniku zastosowano rozwiązanie RAG: konwertujemy pytanie użytkownika na osadzanie, znajdujemy podobny obraz (slajd) z bazy danych wektorowych i dostarczamy pobrany obraz do LLaVA w celu wygenerowania odpowiedzi na pytanie użytkownika. Używamy następującego szablonu podpowiedzi:
Poniższy fragment kodu przedstawia przepływ pracy RAG:
Efekt
Poniżej znajduje się zestawienie niektórych pytań i odpowiedzi użytkowników wygenerowanych przez naszą implementację. The Question kolumna zawiera pytanie użytkownika, a Odpowiedź kolumna to odpowiedź tekstowa wygenerowana przez LLaVA. Obraz to k-najbliższe (k=1) dopasowanie slajdu zwrócone przez wyszukiwanie wektorowe OpenSearch Serverless. Ten slajd jest interpretowany przez LLaVA w celu dostarczenia odpowiedzi.
Wyniki multimodalnych RAG
| Question | Odpowiedź | Obraz |
|---|---|---|
| Jak Inf2 wypada w porównaniu z porównywalnymi instancjami EC2? Potrzebuję numerów. | Zgodnie z prezentacją, instancje Inf2 firmy AWS Inferentia2 oferują do 4x wyższą przepustowość i 10x mniejsze opóźnienia w porównaniu do porównywalnych instancji EC2. |  |
| Co według koła zamachowego AI/ML zapewniają usługi AWS AI/ML? | Usługi AWS AI/ML zapewniają lepsze możliwości $/perfer, nowe możliwości i inwestycje w innowacje. | 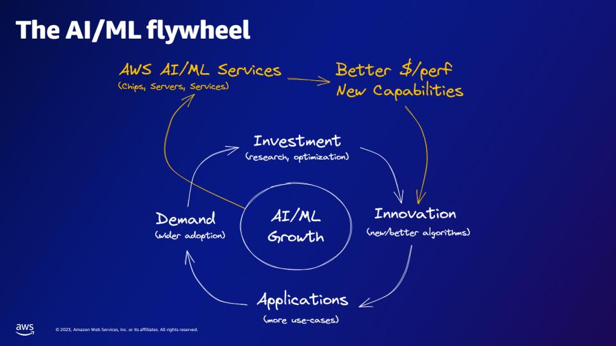 |
| O ile więcej parametrów ma GPT-2 w porównaniu do GPT-3? Jaka jest różnica liczbowa między rozmiarem parametru GPT-2 i GPT-3? | Według slajdu GPT-3 ma 175 miliardów parametrów, podczas gdy GPT-2 ma 1.5 miliarda parametrów. Liczbowa różnica między wielkością parametrów GPT-2 i GPT-3 wynosi 173.5 miliarda. | 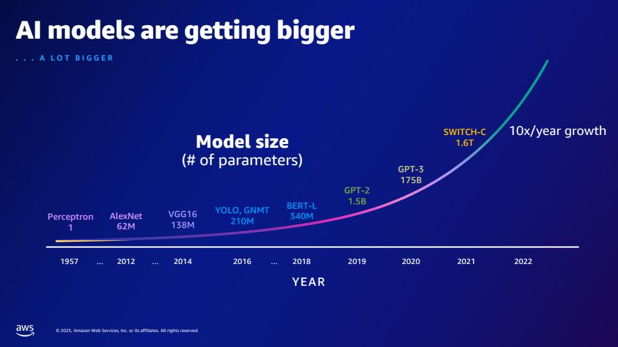 |
| Czym są kwarki w fizyce cząstek elementarnych? | Na slajdzie nie znalazłem odpowiedzi na to pytanie. |  |
Możesz rozszerzyć to rozwiązanie na swoje slajdy. Po prostu zaktualizuj zmienną SLIDE_DECK w globals.py adresem URL prezentacji slajdów i wykonaj kroki przetwarzania opisane w poprzedniej sekcji.
Wskazówka
Pulpitów nawigacyjnych OpenSearch można używać do interakcji z interfejsem API OpenSearch w celu przeprowadzania szybkich testów indeksu i pozyskanych danych. Poniższy zrzut ekranu przedstawia przykład GET panelu OpenSearch.
Sprzątać
Aby uniknąć przyszłych opłat, usuń utworzone zasoby. Możesz to zrobić, usuwając stos za pomocą konsoli CloudFormation.

Dodatkowo usuń punkt końcowy wnioskowania SageMaker utworzony na potrzeby wnioskowania LLaVA. Możesz to zrobić, odkomentując krok czyszczenia 3_rag_inference.ipynb i uruchamiając komórkę lub usuwając punkt końcowy za pomocą konsoli SageMaker: wybierz Wnioskowanie i Punkty końcowe w panelu nawigacji, a następnie wybierz punkt końcowy i usuń go.
Wnioski
Przedsiębiorstwa cały czas generują nowe treści, a slajdy to powszechny mechanizm używany do udostępniania i rozpowszechniania informacji wewnątrz organizacji i na zewnątrz z klientami lub na konferencjach. Z czasem bogate informacje mogą pozostać ukryte w formach nietekstowych, takich jak wykresy i tabele na tych slajdach. Możesz wykorzystać to rozwiązanie i moc multimodalnych FM, takich jak model Titan Multimodal Embeddings i LLaVA, aby odkryć nowe informacje lub odkryć nowe perspektywy dotyczące treści na slajdach.
Zachęcamy do dowiedzenia się więcej poprzez eksplorację Amazon SageMaker JumpStart, Modele Amazon Titan, Amazon Bedrock i OpenSearch Service oraz zbudowanie rozwiązania przy użyciu przykładowej implementacji przedstawionej w tym poście.
Zwróć uwagę na dwa dodatkowe posty w ramach tej serii. Część 2 opisuje inne podejście, które możesz zastosować, aby porozmawiać ze swoją platformą slajdów. Podejście to generuje i przechowuje wnioski LLaVA oraz wykorzystuje te przechowywane wnioski do odpowiadania na zapytania użytkowników. Część 3 porównuje oba podejścia.
O autorach
 Amit Arora jest architektem specjalizującym się w AI i ML w Amazon Web Services, pomagając klientom korporacyjnym w korzystaniu z usług uczenia maszynowego opartych na chmurze w celu szybkiego skalowania ich innowacji. Jest także adiunktem w programie MS Data Science and Analytics na Uniwersytecie Georgetown w Waszyngtonie
Amit Arora jest architektem specjalizującym się w AI i ML w Amazon Web Services, pomagając klientom korporacyjnym w korzystaniu z usług uczenia maszynowego opartych na chmurze w celu szybkiego skalowania ich innowacji. Jest także adiunktem w programie MS Data Science and Analytics na Uniwersytecie Georgetown w Waszyngtonie
 Manju Prasad jest starszym architektem rozwiązań w dziale klientów strategicznych w Amazon Web Services. Koncentruje się na zapewnianiu wskazówek technicznych w różnych dziedzinach, w tym AI/ML, klientowi z branży M&E. Przed dołączeniem do AWS projektowała i budowała rozwiązania dla firm z sektora usług finansowych, a także dla startupu.
Manju Prasad jest starszym architektem rozwiązań w dziale klientów strategicznych w Amazon Web Services. Koncentruje się na zapewnianiu wskazówek technicznych w różnych dziedzinach, w tym AI/ML, klientowi z branży M&E. Przed dołączeniem do AWS projektowała i budowała rozwiązania dla firm z sektora usług finansowych, a także dla startupu.
 Archana Inapudi jest starszym architektem rozwiązań w AWS obsługującym klientów strategicznych. Ma ponad dziesięcioletnie doświadczenie w pomaganiu klientom w projektowaniu i budowaniu rozwiązań do analityki danych i baz danych. Pasjonuje się wykorzystaniem technologii w celu zapewnienia wartości klientom i osiągnięcia wyników biznesowych.
Archana Inapudi jest starszym architektem rozwiązań w AWS obsługującym klientów strategicznych. Ma ponad dziesięcioletnie doświadczenie w pomaganiu klientom w projektowaniu i budowaniu rozwiązań do analityki danych i baz danych. Pasjonuje się wykorzystaniem technologii w celu zapewnienia wartości klientom i osiągnięcia wyników biznesowych.
 Antara Raisa jest architektem rozwiązań AI i ML w Amazon Web Services obsługującym klientów strategicznych z siedzibą w Dallas w Teksasie. Ma także doświadczenie w pracy z dużymi partnerami korporacyjnymi w AWS, gdzie pracowała jako architekt rozwiązań Partner Success Solutions dla klientów z branży cyfrowej.
Antara Raisa jest architektem rozwiązań AI i ML w Amazon Web Services obsługującym klientów strategicznych z siedzibą w Dallas w Teksasie. Ma także doświadczenie w pracy z dużymi partnerami korporacyjnymi w AWS, gdzie pracowała jako architekt rozwiązań Partner Success Solutions dla klientów z branży cyfrowej.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Zdolny
- O nas
- dostęp
- dostęp
- Konta
- Osiągać
- Działania
- działania
- Dzieje Apostolskie
- Dodaj
- Dodatkowy
- dodatek
- nadejście
- przed
- AI
- AI / ML
- Wszystkie kategorie
- dopuszczać
- wzdłuż
- również
- Amazonka
- Amazon Sage Maker
- Amazon Web Services
- an
- analityka
- i
- Inne
- odpowiedź
- sekretarka
- odpowiedzi
- każdy
- api
- Aplikuj
- podejście
- awanse
- architektura
- SĄ
- AS
- zapytać
- Asystent
- powiązany
- At
- audio
- zwiększona
- Auth
- dostępny
- uniknąć
- AWS
- Tworzenie chmury AWS
- na podstawie
- BE
- być
- Ulepsz Swój
- pomiędzy
- Miliard
- ciało
- budować
- Budowanie
- wybudowany
- biznes
- by
- CAN
- możliwości
- zdolność
- przechwytuje
- komórka
- zmieniony
- Opłaty
- Dodaj
- Wybierając
- klient
- kod
- kolekcja
- kolekcje
- kolektor
- Kolumna
- połączenie
- łączenie
- komentarze
- wspólny
- Firmy
- porównywalny
- porównać
- w porównaniu
- kompletny
- Zakończony
- składniki
- pojęcie
- konferencje
- systemu
- skonfigurowany
- składa się
- Konsola
- zawierać
- zawarte
- zawiera
- zawartość
- Tworzenie treści
- konwertować
- przeliczone
- 轉換
- Odpowiedni
- mógłby
- obejmuje
- Stwórz
- stworzony
- tworzy
- Tworzenie
- tworzenie
- Listy uwierzytelniające
- klient
- Klientów
- Dallas
- tablica rozdzielcza
- Deski rozdzielcze
- dane
- Analityka danych
- nauka danych
- Baza danych
- dekada
- pokład
- Domyślnie
- dostarczyć
- dostarcza
- wykazać
- W zależności
- rozwijać
- wdrażane
- wdrażanie
- wdraża się
- opisać
- Wnętrze
- zaprojektowany
- detal
- szczegółowe
- detale
- schemat
- DICT
- ZROBIŁ
- różnica
- różne
- Transmitowanie
- cyfrowy
- Wymiary
- Wymiary
- odkryj
- omówione
- Wyświetlacz
- do
- dokumenty
- robi
- domeny
- pobieranie
- pliki do pobrania
- podczas
- e
- każdy
- Elementy
- osadzone
- osadzanie
- umożliwiać
- włączony
- zakodowany
- zachęcać
- zakończenia
- Punkt końcowy
- silnik
- zapewnić
- Enterprise
- klienci korporacyjni
- błąd
- Eter (ETH)
- wydarzenie
- wydarzenia
- Badanie
- przykład
- Z wyjątkiem
- wyjątek
- istnieje
- doświadczenie
- Exploring
- rozciągać się
- zewnętrznie
- wyciąg
- Znajomość
- Łąka
- filet
- Akta
- budżetowy
- usługi finansowe
- Znajdź
- koncentruje
- obserwuj
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Nasz formularz
- format
- Fundacja
- cztery
- Darmowy
- od
- pełny
- w pełni
- przyszłość
- Generować
- wygenerowane
- generuje
- generacja
- generatywny
- generatywna sztuczna inteligencja
- Georgetown
- otrzymać
- GitHub
- będzie
- wykresy
- poradnictwo
- Have
- he
- pomocny
- pomoc
- tutaj
- Ukryty
- wyższy
- Odsłon
- gospodarz
- hostowane
- Hosting
- gospodarze
- W jaki sposób
- Jednak
- HTML
- http
- HTTPS
- Piasta
- Przytulanie twarzy
- i
- IAM
- tożsamość
- if
- ilustruje
- obraz
- zdjęcia
- natychmiast
- wdrożenia
- realizacja
- narzędzia
- in
- zawierać
- obejmuje
- Włącznie z
- wskaźnik
- Indeksy
- Informacja
- Innowacja
- innowacje
- wkład
- przykład
- instancje
- instrukcje
- interakcji
- wzajemne oddziaływanie
- wewnętrznie
- najnowszych
- inwestycja
- IT
- łączący
- jpg
- json
- czerwiec
- język
- duży
- Utajenie
- uruchomić
- UCZYĆ SIĘ
- nauka
- wykładowca
- lubić
- LINK
- Lama
- miejscowy
- niższy
- maszyna
- uczenie maszynowe
- robić
- zarządzanie
- zarządzane
- wiele
- Mecz
- dopasowywanie
- mechanizm
- Menu
- Metadane
- metoda
- ML
- modalności
- model
- modele
- jeszcze
- większość
- MS
- wielokrotność
- Nazwa
- rodzimy
- Nawigacja
- Nawigacja
- Potrzebować
- Nowości
- żaden
- noty
- notatnik
- laptopy
- Powiadomienia
- już dziś
- numerowane
- z naszej
- obiekty
- of
- oferta
- on
- Na żądanie
- ONE
- tylko
- koncepcja
- open source
- or
- organizacja
- OS
- ludzkiej,
- na zewnątrz
- wyniki
- wydajność
- koniec
- chleb
- parametr
- parametry
- część
- cząstka
- partnerem
- wzmacniacz
- strony
- minęło
- namiętny
- ścieżka
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- uprawnienia
- perspektywy
- faza
- Fizyka
- Zdjęcia
- rurociąg
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- Post
- Wiadomości
- potencjalnie
- power
- mocny
- Urządzenie prognozujące
- teraźniejszość
- przedstawione
- poprzedni
- Wcześniejszy
- wygląda tak
- obrobiony
- procesów
- przetwarzanie
- Program
- niska zabudowa
- zapewniać
- pod warunkiem,
- zapewnia
- że
- położyć
- kwarki
- zapytania
- pytanie
- pytanie
- pytania
- Szybki
- szmata
- zasięg
- szybko
- Czytający
- gotowy
- Prawdziwy świat
- Odebrane
- odwołanie
- region
- związane z
- pozostawać
- obsługi produkcji rolnej, która zastąpiła
- zażądać
- wymagany
- Zasoby
- Odpowiadać
- odpowiedź
- Odpowiedzi
- dalsze
- wynikły
- Efekt
- wyszukiwanie
- powrót
- Bogaty
- role
- run
- bieganie
- sagemaker
- Wnioskowanie SageMakera
- taki sam
- powiedzieć
- Skala
- nauka
- screeny
- scenariusz
- Szukaj
- druga
- Sekcja
- działy
- sektor
- widzieć
- wybierać
- wybierając
- senior
- Sekwencja
- Serie
- Bezserwerowe
- służy
- usługa
- Usługi
- Sesja
- Zestawy
- ustawienie
- w panelu ustawień
- Share
- ona
- powinien
- pokazane
- Targi
- podobny
- Prosty
- po prostu
- pojedynczy
- Rozmiar
- suwak
- slajdy
- skrawek
- So
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- specjalista
- specyficzny
- określony
- stabilny
- stos
- startup
- Stan
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- przechowywany
- sklep
- Strategiczny
- sznur
- kolejny
- sukces
- Z powodzeniem
- taki
- Szczyt
- Wspierający
- pewnie
- stół
- Brać
- Mówić
- zadania
- Techniczny
- Technologia
- szablon
- Szablony
- test
- Testy
- texas
- XNUMX
- tekstowy
- że
- Połączenia
- Informacje
- ich
- następnie
- Te
- to
- tych
- wydajność
- czas
- tytan
- pod tytulem
- do
- dzisiaj
- razem
- Toronto
- tradycyjnie
- poligon
- wyzwalać
- wyzwalanie
- prawdziwy
- próbować
- SKRĘCAĆ
- drugiej
- rodzaj
- odkryć
- zrozumieć
- zrozumienie
- uniwersytet
- Aktualizacja
- przesłanych
- URL
- posługiwać się
- używany
- Użytkownik
- zastosowania
- za pomocą
- wartość
- zmienna
- różnorodność
- wersja
- przez
- Wideo
- Zobacz i wysłuchaj
- wizja
- wizualny
- Waszyngton
- sposoby
- we
- sieć
- usługi internetowe
- DOBRZE
- Co
- Co to jest
- który
- Podczas
- będzie
- w
- w ciągu
- pracował
- workflow
- pracujący
- ty
- Twój
- zefirnet