W dążeniu do bardziej wydajnych, szybszych, mniejszych i zużywających mniej energii systemów, prawo Moore'a zapewniło oprogramowaniu darmową jazdę przez ponad 30 lat wyłącznie w oparciu o ewolucję procesów półprzewodnikowych. Sprzęt obliczeniowy co roku zapewniał lepsze wskaźniki wydajności/obszaru/mocy, umożliwiając zwiększanie złożoności oprogramowania i zapewnianie większych możliwości bez wad. Potem łatwe zwycięstwa stały się mniej łatwe. Bardziej zaawansowane procesy w dalszym ciągu zapewniały większą liczbę bramek na jednostkę powierzchni, ale wzrost wydajności i mocy zaczął się wyrównywać. Ponieważ nasze oczekiwania dotyczące innowacji nie ustały, postęp w architekturze sprzętowej stał się ważniejszy w nadrabianiu zaległości.

Sterowniki zwiększające liczbę rdzeni
We wczesnym kroku w tym kierunku wykorzystano wielordzeniowe procesory do przyspieszenia całkowitej przepustowości poprzez wielowątkowość lub wirtualizację mieszanki współbieżnych zadań między rdzeniami, redukując w razie potrzeby moc poprzez pozostawienie na biegu jałowym lub wyłączenie nieaktywnych rdzeni. Wielordzeniowość jest dziś standardem, a trend w wielordzeniowości (jeszcze więcej procesorów w chipie) jest już widoczny w opcjach instancji serwerowych dostępnych na platformach chmurowych od AWS, Azure, Alibaba i innych.
Architektury wielo-/wielordzeniowe są krokiem naprzód, ale równoległość klastrów procesorów jest gruboziarnista i ma swoje własne ograniczenia wydajności i mocy, dzięki prawu Amdahla. Architektury stały się bardziej heterogeniczne, dodając akceleratory obrazu, dźwięku i innych specjalistycznych potrzeb. Akceleratory AI również popchnęły drobnoziarnistą równoległość, przechodząc do tablic skurczowych i innych technik specyficznych dla danej dziedziny. Który działał całkiem nieźle, dopóki nie pojawił się ChatGPT ze 175 miliardami parametrów, a GPT-3 ewoluował w GPT-4 ze 100 bilionami parametrów – o rzędy wielkości bardziej złożonymi niż dzisiejsze systemy AI – wymuszając jeszcze bardziej wyspecjalizowane funkcje przyspieszania w akceleratorach AI.
Z drugiej strony systemy wieloczujnikowe w zastosowaniach motoryzacyjnych integrują się obecnie w pojedyncze układy SoC w celu poprawy świadomości ekologicznej i ulepszonego PPA. W tym przypadku nowy poziom autonomii w motoryzacji zależy od łączenia sygnałów wejściowych z wielu typów czujników w jednym urządzeniu, w podsystemach replikujących się 2X, 4X lub 8X.
Według Michała Siwińskiego (CMO w Arteris) próbka miesięcznych dyskusji z wieloma zespołami projektowymi dotyczącymi szerokiego zakresu zastosowań sugeruje, że zespoły te aktywnie zwracają się ku większej liczbie rdzeni, aby osiągnąć cele w zakresie możliwości, wydajności i mocy. Mówi mi, że oni również widzą przyspieszenie tej tendencji. Postęp w procesie w dalszym ciągu pomaga w liczeniu bramek SoC, ale odpowiedzialność za osiągnięcie celów w zakresie wydajności i mocy spoczywa teraz w rękach architektów.
Więcej rdzeni, więcej wzajemnych połączeń
Więcej rdzeni w chipie oznacza więcej połączeń danych między tymi rdzeniami. W akceleratorze pomiędzy sąsiednimi elementami przetwarzającymi, do lokalnej pamięci podręcznej, do akceleratorów dla rzadkiej macierzy i innej specjalistycznej obsługi. Dodaj hierarchiczną łączność między płytkami akceleratorów i magistralami na poziomie systemu. Dodaj łączność do przechowywania wagi na chipie, dekompresji, transmisji, gromadzenia i ponownej kompresji. Dodaj łączność HBM dla działającej pamięci podręcznej. W razie potrzeby dodaj silnik fuzyjny.
Klaster kontrolny oparty na procesorze musi łączyć się z każdym z tych replikowanych podsystemów i ze wszystkimi typowymi funkcjami – kodekami, zarządzaniem pamięcią, wyspą bezpieczeństwa i rootem zaufania, jeśli to konieczne, UCIe w przypadku implementacji wielochipletowej, PCIe dla wejść/wyjść o dużej przepustowości oraz Ethernet lub światłowód do tworzenia sieci.
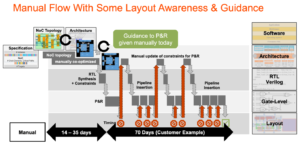
To dużo połączeń, co ma bezpośrednie konsekwencje dla atrakcyjności rynkowej produktu. W procesach poniżej 16 nm infrastruktura NoC stanowi obecnie 10–12% powierzchni. Co ważniejsze, jako autostrada komunikacyjna między rdzeniami, może mieć znaczący wpływ na wydajność i moc. Istnieje realne niebezpieczeństwo, że nieoptymalna implementacja zaprzepaści oczekiwaną wydajność architektury i przyrost mocy lub, co gorsza, doprowadzi do zbieżności wielu pętli przeprojektowania. Jednak znalezienie dobrej implementacji w złożonym planie SoC nadal zależy od powolnych optymalizacji metodą prób i błędów w i tak już napiętych harmonogramach projektowania. Musimy przejść do projektowania NoC świadomego fizycznie, aby zagwarantować pełną wydajność i wsparcie zasilania ze złożonych hierarchii NoC, a także musimy przyspieszyć te optymalizacje.
Fizycznie świadome projekty NoC utrzymują prawo Moore'a na właściwej drodze
Prawo Moore'a może nie jest martwe, ale postęp w wydajności i mocy wynika obecnie z architektury i połączeń wzajemnych NoC, a nie z procesów. Architektura wymusza większą liczbę rdzeni akceleratorów, więcej akceleratorów w akceleratorach i większą replikację podsystemów w chipie. Wszystkie zwiększają złożoność połączeń wzajemnych na chipie. Ponieważ projekty zwiększają liczbę rdzeni i przechodzą na geometrię procesów przy 16 nm i poniżej, liczne połączenia NoC obejmujące SoC i jego podsystemy mogą wspierać pełny potencjał tych złożonych projektów tylko wtedy, gdy zostaną optymalnie wdrożone wbrew ograniczeniom fizycznym i czasowym – poprzez fizycznie świadomą sieć na temat projektowania chipów.
Jeśli i Ty martwisz się tymi trendami, być może zechcesz dowiedzieć się więcej o technologii Arteris FlexNoC 5 IP TUTAJ.
Udostępnij ten post przez:
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :Jest
- $W GÓRĘ
- 100
- a
- O nas
- przyśpieszyć
- przyspieszenie
- przyśpieszenie
- akcelerator
- akceleratory
- w poprzek
- aktywnie
- zaawansowany
- zaliczki
- przed
- AI
- Systemy SI
- Alibaba
- Wszystkie kategorie
- Pozwalać
- już
- i
- pojawił się
- aplikacje
- właściwy
- architektura
- SĄ
- POWIERZCHNIA
- AS
- At
- audio
- motoryzacyjny
- dostępny
- świadomość
- AWS
- Lazur
- przepustowość
- BE
- stają się
- poniżej
- pomiędzy
- Miliard
- nadawanie
- autobusy
- by
- Pamięć podręczna
- CAN
- zdolny
- ChatGPT
- żeton
- Chmura
- Grupa
- CMO
- jak
- Komunikacja
- kompleks
- kompleksowość
- obliczać
- równoległy
- Skontaktuj się
- połączenia
- Łączność
- Konsekwencje
- Ograniczenia
- nadal
- kontrola
- zbieżny
- rdzeń
- CPU
- ZAGROŻENIE
- dane
- martwy
- dostarczyć
- dostarczona
- zależy
- Wnętrze
- projekty
- urządzenie
- różne
- kierować
- kierunek
- dyskusje
- na dół
- wady
- każdy
- Wcześnie
- Elementy
- silnik
- Środowisko
- Parzyste
- Każdy
- ewolucja
- ewoluuje
- Rozszerzać
- oczekiwania
- spodziewany
- szybciej
- Korzyści
- znalezieniu
- mocno
- W razie zamówieenia projektu
- Naprzód
- Darmowy
- od
- z przodu
- pełny
- Funkcje
- fuzja
- Zyski
- Gole
- dobry
- gwarancja
- Prowadzenie
- siła robocza
- sprzęt komputerowy
- Have
- pomoc
- tutaj
- Wysoki
- wyższy
- Autostrada
- HTTPS
- obraz
- Rezultat
- realizacja
- realizowane
- ważny
- ulepszony
- in
- nieaktywny
- Zwiększać
- wzrastający
- Infrastruktura
- Innowacja
- przykład
- Integracja
- IP
- wyspa
- IT
- JEGO
- skok
- Prawo
- UCZYĆ SIĘ
- poziom
- poziomy
- Limity
- miejscowy
- Partia
- robić
- i konserwacjami
- March
- Matrix
- Maksymalna szerokość
- Poznaj nasz
- Spotkanie
- Pamięć
- Metryka
- może
- Miesiąc
- jeszcze
- ruch
- przeniesienie
- wielokrotność
- Potrzebować
- potrzebne
- wymagania
- sieć
- sieci
- Nowości
- liczny
- of
- on
- Opcje
- Zlecenia
- Inne
- Pozostałe
- własny
- parametry
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- fizyczny
- Fizycznie
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Post
- potencjał
- power
- Zasilanie
- bardzo
- wygląda tak
- procesów
- przetwarzanie
- Produkt
- czysto
- popychany
- Popychanie
- zasięg
- raczej
- real
- redukcja
- replikowane
- replikacja
- odpowiedzialność
- dalsze
- zmarszczka
- korzeń
- Bezpieczeństwo
- Semiconductor
- znaczący
- ponieważ
- pojedynczy
- luźny
- powolny
- mniejszy
- So
- Tworzenie
- rzadka macierz
- wyspecjalizowanym
- reflektor
- standard
- rozpoczęty
- Ewolucja krok po kroku
- Nadal
- Stop
- przechowywanie
- Wskazuje
- wsparcie
- system
- systemy
- zadania
- Zespoły
- Techniki
- Technologia
- mówi
- że
- Połączenia
- Te
- Przez
- wydajność
- wyczucie czasu
- do
- już dziś
- dzisiaj
- Kwota produktów:
- Trend
- Trendy
- Trylion
- Zaufaj
- Obrócenie
- typy
- dla
- jednostka
- przez
- waga
- DOBRZE
- który
- szeroki
- Szeroki zasięg
- będzie
- Zwycięstwa
- w
- w ciągu
- pracujący
- rok
- lat
- zefirnet