Osadzanie odgrywa kluczową rolę w przetwarzaniu języka naturalnego (NLP) i uczeniu maszynowym (ML). Osadzanie tekstu odnosi się do procesu przekształcania tekstu na reprezentacje numeryczne znajdujące się w wielowymiarowej przestrzeni wektorowej. Technikę tę osiąga się poprzez zastosowanie algorytmów ML, które umożliwiają zrozumienie znaczenia i kontekstu danych (relacje semantyczne) oraz uczenie się złożonych relacji i wzorców w danych (relacje syntaktyczne). Otrzymane reprezentacje wektorowe można wykorzystać w szerokim zakresie zastosowań, takich jak wyszukiwanie informacji, klasyfikacja tekstu, przetwarzanie języka naturalnego i wiele innych.
Osadzanie tekstu Amazon Titan to model osadzania tekstu, który konwertuje tekst w języku naturalnym — składający się z pojedynczych słów, fraz, a nawet dużych dokumentów — na reprezentacje numeryczne, które można wykorzystać do wspomagania zastosowań, takich jak wyszukiwanie, personalizacja i grupowanie w oparciu o podobieństwo semantyczne.
W tym poście omawiamy model Amazon Titan Text Embeddings, jego funkcje i przykładowe przypadki użycia.
Niektóre kluczowe pojęcia obejmują:
- Numeryczna reprezentacja tekstu (wektory) oddaje semantykę i relacje między słowami
- Do porównania podobieństwa tekstu można zastosować bogate osadzenie
- Wielojęzyczne osadzanie tekstu może identyfikować znaczenie w różnych językach
Jak fragment tekstu jest konwertowany na wektor?
Istnieje wiele technik konwersji zdania na wektor. Jedną z popularnych metod jest użycie algorytmów osadzania słów, takich jak Word2Vec, GloVe lub FastText, a następnie agregowanie osadzania słów w celu utworzenia reprezentacji wektorowej na poziomie zdania.
Innym powszechnym podejściem jest użycie dużych modeli językowych (LLM), takich jak BERT lub GPT, które mogą zapewnić kontekstowe osadzanie całych zdań. Modele te opierają się na architekturach głębokiego uczenia się, takich jak Transformers, które mogą skuteczniej przechwytywać informacje kontekstowe i relacje między słowami w zdaniu.
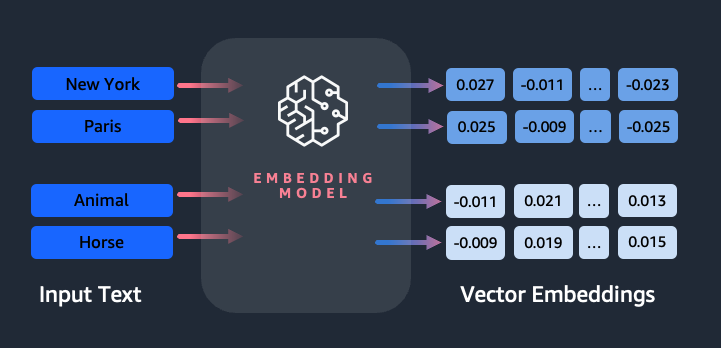
Dlaczego potrzebujemy modelu osadzania?
Osadzanie wektorów ma fundamentalne znaczenie dla LLM, ponieważ pozwala zrozumieć semantyczne stopnie języka, a także umożliwia LLM dobre wykonywanie dalszych zadań NLP, takich jak analiza tonacji, rozpoznawanie nazwanych jednostek i klasyfikacja tekstu.
Oprócz wyszukiwania semantycznego możesz używać osadzania, aby zwiększyć liczbę podpowiedzi i uzyskać dokładniejsze wyniki za pomocą generowania rozszerzonego wyszukiwania (RAG), ale aby z nich skorzystać, musisz przechowywać je w bazie danych z możliwością obsługi wektorów.
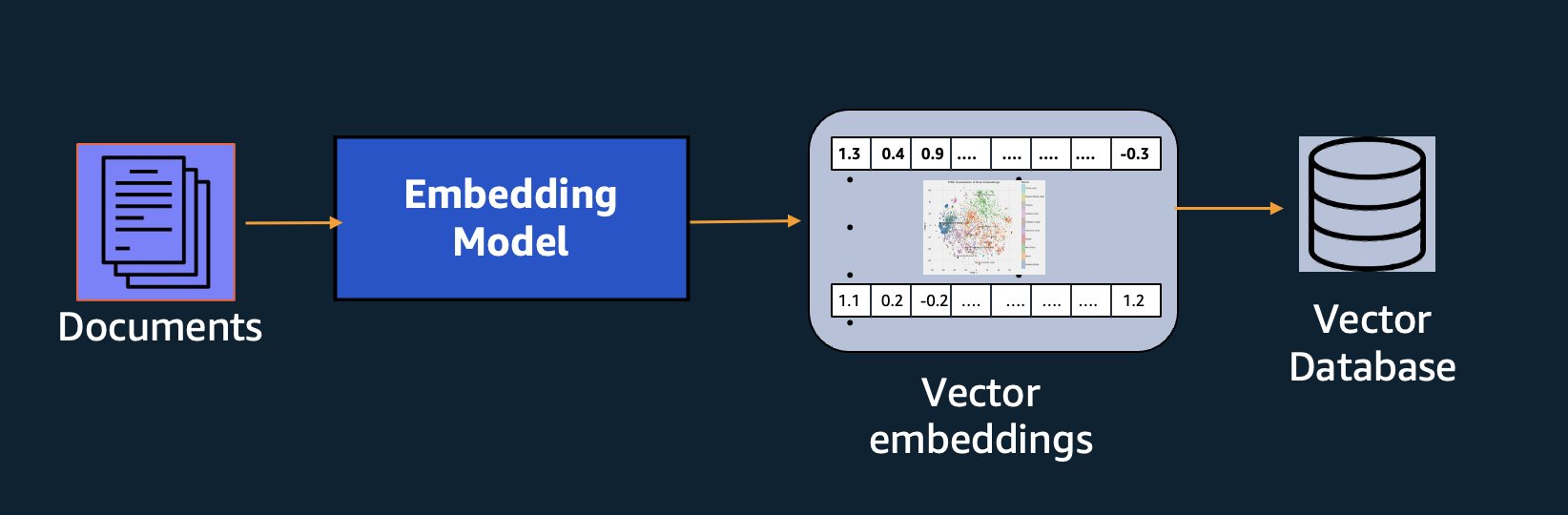
Model Amazon Titan Text Embeddings jest zoptymalizowany pod kątem wyszukiwania tekstu, aby umożliwić użycie RAG. Umożliwia najpierw konwersję danych tekstowych na reprezentacje numeryczne lub wektory, a następnie użycie tych wektorów do dokładnego wyszukiwania odpowiednich fragmentów z bazy danych wektorów, co pozwala w pełni wykorzystać zastrzeżone dane w połączeniu z innymi modelami podstawowymi.
Ponieważ Amazon Titan Text Embeddings to model zarządzany Amazońska skała macierzysta, jest oferowany jako rozwiązanie całkowicie bezserwerowe. Można go używać za pośrednictwem Amazon Bedrock REST API lub pakiet AWS SDK. Wymagane parametry to tekst, dla którego chcesz wygenerować osadzenie oraz modelID parametr, który reprezentuje nazwę modelu Amazon Titan Text Embeddings. Poniższy kod jest przykładem użycia pakietu AWS SDK dla Pythona (Boto3):
Dane wyjściowe będą wyglądać mniej więcej tak:
Odnosić się do Konfiguracja Amazon Bedrock boto3 aby uzyskać więcej informacji na temat instalowania wymaganych pakietów, połącz się z Amazon Bedrock i wywołaj modele.
Funkcje osadzania tekstu Amazon Titan
Dzięki osadzaniu tekstu Amazon Titan możesz wprowadzić do 8,000 tokenów, dzięki czemu doskonale nadaje się do pracy z pojedynczymi słowami, frazami lub całymi dokumentami w zależności od przypadku użycia. Amazon Titan zwraca wektory wyjściowe o wymiarze 1536, co zapewnia wysoki stopień dokładności, a jednocześnie optymalizuje pod kątem niskich opóźnień i opłacalnych wyników.
Usługa Amazon Titan Text Embeddings obsługuje tworzenie i wysyłanie zapytań do osadzonych tekstów w ponad 25 różnych językach. Oznacza to, że możesz zastosować model do swoich przypadków użycia bez konieczności tworzenia i utrzymywania oddzielnych modeli dla każdego języka, który chcesz obsługiwać.
Posiadanie jednego modelu osadzania przeszkolonego w wielu językach zapewnia następujące kluczowe korzyści:
- Szerszy zasięg – Dzięki standardowej obsłudze ponad 25 języków możesz rozszerzyć zasięg swoich aplikacji na użytkowników i treści na wielu rynkach międzynarodowych.
- Stała wydajność – Dzięki ujednoliconemu modelowi obejmującemu wiele języków można uzyskać spójne wyniki we wszystkich językach, zamiast optymalizować oddzielnie dla każdego języka. Model jest szkolony całościowo, dzięki czemu zyskujesz przewagę w różnych językach.
- Wielojęzyczna obsługa zapytań – Amazon Titan Text Embeddings umożliwia wysyłanie zapytań o osadzanie tekstu w dowolnym z obsługiwanych języków. Zapewnia to elastyczność wyszukiwania semantycznie podobnych treści w różnych językach, bez ograniczania się do jednego języka. Można tworzyć aplikacje, które wysyłają zapytania i analizują dane wielojęzyczne, korzystając z tej samej, ujednoliconej przestrzeni do osadzania.
W chwili pisania tego tekstu obsługiwane są następujące języki:
- Arabowie
- Chiński (uproszczony)
- Chiński (tradycyjny)
- Czeski
- holenderski
- Angielski
- francuski
- niemiecki
- hebrajski
- hinduski
- włoski
- Japonki
- kannada
- koreański
- malajalam
- marathi
- Polski
- portugalski
- Rosyjski
- hiszpański
- szwedzki
- filipiński tagalski
- Tamil
- telugu
- turecki
Korzystanie z osadzania tekstu Amazon Titan w LangChain
LangChain to popularna platforma open source do pracy z generatywnymi modelami AI i technologiami pomocniczymi. Zawiera: Klient BedrockEmbeddings który wygodnie otacza zestaw SDK Boto3 warstwą abstrakcji. The BedrockEmbeddings klient umożliwia bezpośrednią pracę z tekstem i osadzeniem, bez znajomości szczegółów struktur żądań lub odpowiedzi JSON. Poniżej znajduje się prosty przykład:
Możesz także użyć LangChaina BedrockEmbeddings klienta wraz z klientem Amazon Bedrock LLM, aby uprościć wdrażanie RAG, wyszukiwania semantycznego i innych wzorców związanych z osadzaniem.
Użyj przypadków do osadzania
Chociaż RAG jest obecnie najpopularniejszym przypadkiem użycia osadzania, istnieje wiele innych przypadków użycia, w których można zastosować osadzanie. Poniżej przedstawiono kilka dodatkowych scenariuszy, w których można użyć osadzania do rozwiązania określonych problemów, samodzielnie lub we współpracy z LLM:
- Pytania i odpowiedzi – Osadzanie może pomóc w obsłudze interfejsów pytań i odpowiedzi za pośrednictwem wzorca RAG. Generowanie osadzania w połączeniu z wektorową bazą danych pozwala znaleźć bliskie dopasowania między pytaniami a treścią w repozytorium wiedzy.
- Spersonalizowane rekomendacje – Podobnie jak w przypadku pytań i odpowiedzi, możesz użyć osadzania, aby znaleźć miejsca na wakacje, uczelnie, pojazdy lub inne produkty w oparciu o kryteria podane przez użytkownika. Może to mieć formę prostej listy dopasowań lub można następnie użyć LLM do przetworzenia każdej rekomendacji i wyjaśnienia, w jaki sposób spełnia ona kryteria użytkownika. Możesz także zastosować to podejście do wygenerowania niestandardowych „10 najlepszych” artykułów dla użytkownika na podstawie jego konkretnych potrzeb.
- Zarządzanie danymi – Jeśli masz źródła danych, które nie są ze sobą jednoznacznie powiązane, ale masz treść tekstową opisującą rekord danych, możesz użyć osadzania, aby zidentyfikować potencjalne duplikaty rekordów. Można na przykład użyć osadzania, aby zidentyfikować zduplikowanych kandydatów, którzy mogą używać innego formatowania, skrótów lub nawet mieć przetłumaczone nazwy.
- Racjonalizacja portfela aplikacji – Kiedy chcemy ujednolicić portfolio aplikacji w spółce dominującej i w ramach przejęcia, nie zawsze jest oczywiste, od czego zacząć wyszukiwanie potencjalnego nakładania się rozwiązań. Jakość danych do zarządzania konfiguracją może być czynnikiem ograniczającym, a koordynacja działań między zespołami w celu zrozumienia krajobrazu aplikacji może być trudna. Używając dopasowania semantycznego z osadzeniem, możemy przeprowadzić szybką analizę portfeli aplikacji, aby zidentyfikować aplikacje kandydujące do racjonalizacji o wysokim potencjale.
- Grupowanie treści – Możesz użyć osadzania, aby ułatwić grupowanie podobnych treści w kategorie, o których możesz nie wiedzieć wcześniej. Załóżmy na przykład, że masz zbiór e-maili od klientów lub recenzji produktów online. Możesz utworzyć osadzenie dla każdego elementu, a następnie uruchomić je k-średnie grupowanie w celu zidentyfikowania logicznych grup obaw klientów, pochwał lub skarg dotyczących produktu lub innych tematów. Następnie możesz wygenerować ukierunkowane podsumowania na podstawie treści tych grup za pomocą LLM.
Przykład wyszukiwania semantycznego
W naszym przykład na GitHubie, demonstrujemy prostą aplikację do wyszukiwania osadzania za pomocą Amazon Titan Text Embeddings, LangChain i Streamlit.
Przykład dopasowuje zapytanie użytkownika do najbliższych wpisów w wektorowej bazie danych znajdującej się w pamięci. Następnie wyświetlamy te dopasowania bezpośrednio w interfejsie użytkownika. Może to być przydatne, jeśli chcesz rozwiązać problemy z aplikacją RAG lub bezpośrednio ocenić model osadzania.
Dla uproszczenia używamy metody in-memory FAISS baza danych do przechowywania i wyszukiwania wektorów osadzania. W rzeczywistym scenariuszu na dużą skalę prawdopodobnie będziesz chciał użyć trwałego magazynu danych, takiego jak silnik wektorowy dla Amazon OpenSearch Serverless albo pgwektor rozszerzenie dla PostgreSQL.
Wypróbuj kilka podpowiedzi z aplikacji internetowej w różnych językach, na przykład:
- Jak mogę monitorować swoje wykorzystanie?
- Jak mogę dostosować modele?
- Z jakich języków programowania mogę korzystać?
- Skomentuj mes données sont-elles sécurisées ?
- Czy to możliwe?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- W welchen Regionen ist Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Należy pamiętać, że mimo że materiał źródłowy był w języku angielskim, zapytania w innych językach zostały dopasowane do odpowiednich haseł.
Wnioski
Możliwości generowania tekstu w modelach podstawowych są bardzo ekscytujące, ale należy pamiętać, że zrozumienie tekstu, znajdowanie odpowiednich treści w zasobach wiedzy i tworzenie powiązań między fragmentami mają kluczowe znaczenie dla osiągnięcia pełnej wartości generatywnej sztucznej inteligencji. W miarę ciągłego udoskonalania tych modeli w nadchodzących latach będziemy nadal obserwować nowe i interesujące przypadki użycia osadzania.
Następne kroki
Dodatkowe przykłady osadzania w postaci notatników lub aplikacji demonstracyjnych można znaleźć na następujących warsztatach:
O autorach
 Jasona Stehle’a jest starszym architektem rozwiązań w AWS z siedzibą w Nowej Anglii. Współpracuje z klientami, aby dostosować możliwości AWS do ich największych wyzwań biznesowych. Poza pracą spędza czas na budowaniu różnych obiektów i oglądaniu z rodziną filmów komiksowych.
Jasona Stehle’a jest starszym architektem rozwiązań w AWS z siedzibą w Nowej Anglii. Współpracuje z klientami, aby dostosować możliwości AWS do ich największych wyzwań biznesowych. Poza pracą spędza czas na budowaniu różnych obiektów i oglądaniu z rodziną filmów komiksowych.
 Nitin Euzebiusz jest starszym architektem rozwiązań dla przedsiębiorstw w AWS, ma doświadczenie w inżynierii oprogramowania, architekturze korporacyjnej i sztucznej inteligencji/ML. Jego pasją jest odkrywanie możliwości generatywnej sztucznej inteligencji. Współpracuje z klientami, pomagając im budować dobrze zaprojektowane aplikacje na platformie AWS, a także poświęca się rozwiązywaniu wyzwań technologicznych i pomaganiu w ich podróży do chmury.
Nitin Euzebiusz jest starszym architektem rozwiązań dla przedsiębiorstw w AWS, ma doświadczenie w inżynierii oprogramowania, architekturze korporacyjnej i sztucznej inteligencji/ML. Jego pasją jest odkrywanie możliwości generatywnej sztucznej inteligencji. Współpracuje z klientami, pomagając im budować dobrze zaprojektowane aplikacje na platformie AWS, a także poświęca się rozwiązywaniu wyzwań technologicznych i pomaganiu w ich podróży do chmury.
 Raj Pathak jest głównym architektem rozwiązań i doradcą technicznym dużych firm z listy Fortune 50 oraz średnich instytucji świadczących usługi finansowe (FSI) w Kanadzie i Stanach Zjednoczonych. Specjalizuje się w aplikacjach uczenia maszynowego, takich jak generatywna sztuczna inteligencja, przetwarzanie języka naturalnego, inteligentne przetwarzanie dokumentów i MLOps.
Raj Pathak jest głównym architektem rozwiązań i doradcą technicznym dużych firm z listy Fortune 50 oraz średnich instytucji świadczących usługi finansowe (FSI) w Kanadzie i Stanach Zjednoczonych. Specjalizuje się w aplikacjach uczenia maszynowego, takich jak generatywna sztuczna inteligencja, przetwarzanie języka naturalnego, inteligentne przetwarzanie dokumentów i MLOps.
 Mani Chanuja jest Tech Lead – Generative AI Specialists, autorką książki – Applied Machine Learning and High Performance Computing on AWS oraz członkiem Rady Dyrektorów Fundacji ds. Kobiet w Edukacji Produkcyjnej. Prowadzi projekty uczenia maszynowego (ML) w różnych dziedzinach, takich jak widzenie komputerowe, przetwarzanie języka naturalnego i generatywna sztuczna inteligencja. Pomaga klientom budować, szkolić i wdrażać duże modele uczenia maszynowego na dużą skalę. Występuje na konferencjach wewnętrznych i zewnętrznych takich jak: Invent, Women in Manufacturing West, webinarach na YouTube i GHC 23. W wolnym czasie lubi długie biegi po plaży.
Mani Chanuja jest Tech Lead – Generative AI Specialists, autorką książki – Applied Machine Learning and High Performance Computing on AWS oraz członkiem Rady Dyrektorów Fundacji ds. Kobiet w Edukacji Produkcyjnej. Prowadzi projekty uczenia maszynowego (ML) w różnych dziedzinach, takich jak widzenie komputerowe, przetwarzanie języka naturalnego i generatywna sztuczna inteligencja. Pomaga klientom budować, szkolić i wdrażać duże modele uczenia maszynowego na dużą skalę. Występuje na konferencjach wewnętrznych i zewnętrznych takich jak: Invent, Women in Manufacturing West, webinarach na YouTube i GHC 23. W wolnym czasie lubi długie biegi po plaży.
 Marka Roya jest głównym architektem uczenia maszynowego dla AWS, pomagając klientom projektować i budować rozwiązania AI/ML. Praca Marka obejmuje szeroki zakres przypadków użycia ML, ze szczególnym uwzględnieniem widzenia komputerowego, głębokiego uczenia się i skalowania ML w całym przedsiębiorstwie. Pomógł firmom z wielu branż, w tym ubezpieczeń, usług finansowych, mediów i rozrywki, opieki zdrowotnej, usług użyteczności publicznej i produkcji. Mark posiada sześć certyfikatów AWS, w tym certyfikat specjalizacji ML. Przed dołączeniem do AWS Mark był architektem, programistą i liderem technologii przez ponad 25 lat, w tym 19 lat w usługach finansowych.
Marka Roya jest głównym architektem uczenia maszynowego dla AWS, pomagając klientom projektować i budować rozwiązania AI/ML. Praca Marka obejmuje szeroki zakres przypadków użycia ML, ze szczególnym uwzględnieniem widzenia komputerowego, głębokiego uczenia się i skalowania ML w całym przedsiębiorstwie. Pomógł firmom z wielu branż, w tym ubezpieczeń, usług finansowych, mediów i rozrywki, opieki zdrowotnej, usług użyteczności publicznej i produkcji. Mark posiada sześć certyfikatów AWS, w tym certyfikat specjalizacji ML. Przed dołączeniem do AWS Mark był architektem, programistą i liderem technologii przez ponad 25 lat, w tym 19 lat w usługach finansowych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- O nas
- abstrakcja
- Akceptuj
- precyzja
- dokładny
- dokładnie
- osiągnięty
- osiągnięcia
- nabycie
- w poprzek
- dodatek
- Dodatkowy
- Korzyść
- doradca
- przed
- AI
- Modele AI
- AI / ML
- Algorytmy
- wyrównać
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- wzdłuż
- wzdłuż
- również
- zawsze
- Amazonka
- Amazon Web Services
- an
- analiza
- w czasie rzeczywistym sprawiają,
- i
- odpowiedź
- każdy
- Zastosowanie
- aplikacje
- stosowany
- Aplikuj
- podejście
- architektura
- architektur
- SĄ
- POWIERZCHNIA
- towary
- AS
- pomoc
- At
- zwiększać
- zwiększona
- autor
- dostępny
- AWS
- na podstawie
- BE
- Plaża
- jest
- Korzyści
- pomiędzy
- deska
- Rada dyrektorów
- ciało
- książka
- Pudełko
- budować
- Budowanie
- biznes
- ale
- by
- CAN
- Kanada
- kandydat
- kandydatów
- możliwości
- zdobyć
- przechwytuje
- walizka
- Etui
- kategorie
- Certyfikacja
- certyfikaty
- wyzwania
- klasyfikacja
- klient
- Zamknij
- Chmura
- klastrowanie
- kod
- kolekcja
- Uczelnie
- połączenie
- wspólny
- Firmy
- sukcesy firma
- porównać
- skarg
- kompleks
- komputer
- Wizja komputerowa
- computing
- Koncepcje
- Obawy
- konferencje
- systemu
- Skontaktuj się
- połączenie
- połączenia
- zgodny
- zawartość
- kontekst
- kontekstowy
- kontynuować
- dogodnie
- konwertować
- przeliczone
- współpraca
- koordynacja
- opłacalne
- mógłby
- pokrycie
- obejmuje
- Stwórz
- Tworzenie
- Kryteria
- istotny
- Obecnie
- zwyczaj
- klient
- Klientów
- dostosować
- dane
- Baza danych
- de
- dedykowane
- głęboko
- głęboka nauka
- głęboko
- określić
- Stopień
- Demo
- wykazać
- rozwijać
- opisuje
- Wnętrze
- Cele podróży
- detale
- Deweloper
- różne
- trudny
- Wymiary
- bezpośrednio
- Dyrektorzy
- dyskutować
- Wyświetlacz
- do
- dokument
- dokumenty
- domeny
- nie
- każdy
- Edukacja
- faktycznie
- bądź
- e-maile
- osadzanie
- wyłaniać się
- umożliwiać
- Umożliwia
- silnik
- Inżynieria
- Anglia
- Angielski
- Enterprise
- Enterprise Solutions
- rozrywka
- Cały
- całkowicie
- jednostka
- Eter (ETH)
- oceniać
- Parzyste
- przykład
- przykłady
- ekscytujący
- Rozszerzać
- doświadczenie
- doświadczony
- Wyjaśniać
- Exploring
- rozbudowa
- zewnętrzny
- ułatwiać
- czynnik
- członków Twojej rodziny
- Korzyści
- kilka
- budżetowy
- usługi finansowe
- Znajdź
- znalezieniu
- i terminów, a
- Elastyczność
- koncentruje
- następujący
- W razie zamówieenia projektu
- Nasz formularz
- Majątek
- Fundacja
- Framework
- Darmowy
- od
- pełny
- fundamentalny
- Generować
- generacja
- generatywny
- generatywna sztuczna inteligencja
- otrzymać
- miejsce
- Dający
- rękawica
- Go
- Największym
- miał
- Have
- he
- opieki zdrowotnej
- pomoc
- pomógł
- pomoc
- pomaga
- jej
- Wysoki
- High Performance Computing
- jego
- posiada
- W jaki sposób
- How To
- HTML
- HTTPS
- i
- zidentyfikować
- if
- wykonawczych
- importować
- ważny
- podnieść
- in
- W innych
- zawierać
- obejmuje
- Włącznie z
- przemysłowa
- Informacja
- wkład
- zainstalować
- zamiast
- instytucje
- ubezpieczenie
- Inteligentny
- Inteligentne przetwarzanie dokumentów
- odsetki
- ciekawy
- Interfejs
- interfejsy
- wewnętrzny
- na świecie
- najnowszych
- IT
- JEGO
- łączący
- podróż
- jpg
- json
- Klawisz
- Wiedzieć
- Wiedząc
- wiedza
- krajobraz
- język
- Języki
- duży
- warstwa
- prowadzić
- lider
- Wyprowadzenia
- nauka
- niech
- lubić
- Prawdopodobnie
- lubi
- ograniczenie
- Lista
- llm
- logiczny
- długo
- Popatrz
- poszukuje
- maszyna
- uczenie maszynowe
- utrzymać
- robić
- Dokonywanie
- zarządzane
- i konserwacjami
- produkcja
- wiele
- mapa
- znak
- Znaki
- rynki
- dopasowane
- zapałki
- dopasowywanie
- materiał
- me
- znaczenie
- znaczy
- Media
- członek
- metoda
- może
- ML
- Algorytmy ML
- MLOps
- model
- modele
- monitor
- jeszcze
- większość
- Najbardziej popularne posty
- Kino
- wielokrotność
- my
- Nazwa
- O imieniu
- Nazwy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Potrzebować
- potrzeba
- wymagania
- Nowości
- Następny
- nlp
- laptopy
- oczywista
- of
- oferowany
- on
- ONE
- Online
- koncepcja
- open source
- zoptymalizowane
- optymalizacji
- or
- zamówienie
- Inne
- Pozostałe
- ludzkiej,
- na zewnątrz
- wydajność
- zewnętrzne
- koniec
- własny
- Pakiety
- sparowany
- parametr
- parametry
- Przedsiębiorstwo macierzyste
- fragmenty
- namiętny
- Wzór
- wzory
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- personalizacja
- Zwroty
- kawałek
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- Proszę
- Popularny
- BY
- teczka
- portfele
- możliwości
- Post
- postgresql
- potencjał
- power
- pierwotny
- Główny
- Wcześniejszy
- problemy
- wygląda tak
- przetwarzanie
- Produkt
- Recenzje produktu
- Produkty
- Programowanie
- języki programowania
- projektowanie
- monity
- własność
- zapewniać
- pod warunkiem,
- zapewnia
- Python
- jakość
- zapytania
- pytanie
- pytanie
- pytania
- Szybki
- szmata
- zasięg
- RE
- dosięgnąć
- Prawdziwy świat
- uznanie
- Rekomendacja
- zalecenia
- rekord
- dokumentacja
- odnosi
- Relacje
- pamiętać
- składnica
- reprezentacja
- reprezentuje
- zażądać
- wymagany
- odpowiedź
- REST
- ograniczony
- wynikły
- Efekt
- wyszukiwanie
- powraca
- Recenzje
- Rola
- run
- działa
- s
- taki sam
- powiedzieć
- Skala
- skalowaniem
- scenariusz
- scenariusze
- Sdk
- Szukaj
- widzieć
- semantyczny
- semantyka
- senior
- wyrok
- sentyment
- oddzielny
- Bezserwerowe
- Usługi
- ona
- podobny
- Prosty
- prostota
- uproszczony
- upraszczać
- pojedynczy
- SIX
- So
- Tworzenie
- Inżynieria oprogramowania
- Rozwiązania
- ROZWIĄZANIA
- Rozwiązywanie
- kilka
- coś
- Źródło
- Źródła
- Typ przestrzeni
- Mówi
- Specjaliści
- specjalizuje się
- Specjalność
- specyficzny
- początek
- rozpoczęty
- Zjednoczone
- sklep
- Struktury
- taki
- wsparcie
- Utrzymany
- Wspierający
- podpory
- Brać
- zadania
- Zespoły
- tech
- Techniczny
- technika
- Techniki
- Technologies
- Technologia
- powiedzieć
- XNUMX
- Klasyfikacja tekstu
- generowanie tekstu
- że
- Połączenia
- Źródło
- ich
- Im
- motywy
- następnie
- Tam.
- Te
- rzeczy
- to
- tych
- chociaż?
- Przez
- czas
- tytan
- do
- Żetony
- tradycyjny
- Pociąg
- przeszkolony
- Transformatory
- transformatorowy
- zrozumieć
- zrozumienie
- Ujednolicony
- Zjednoczony
- United States
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- użyteczny
- Użytkownik
- Interfejs użytkownika
- Użytkownicy
- za pomocą
- Użytkowe
- wakacje
- wartość
- różnorodny
- Pojazdy
- początku.
- przez
- wizja
- chcieć
- była
- oglądania
- we
- sieć
- Aplikacja internetowa
- usługi internetowe
- Seminaria
- DOBRZE
- były
- Zachód
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- szeroki
- Szeroki zasięg
- będzie
- w
- w ciągu
- bez
- Kobieta
- słowo
- słowa
- Praca
- pracujący
- działa
- warsztaty
- by
- napisać
- pisanie
- lat
- ty
- Twój
- youtube
- zefirnet