Usługa Amazon OpenSearch niedawno wprowadzone Multi-AZ z trybem gotowości, opcję wdrożenia zaprojektowaną w celu zapewnienia firmom zwiększonej dostępności i stałej wydajności w przypadku krytycznych obciążeń. Dzięki tej funkcji zarządzane klastry mogą osiągnąć dostępność na poziomie 99.99%, zachowując jednocześnie odporność na awarie infrastruktury strefowej.
W tym poście badamy, jak wyszukiwanie i indeksowanie działa w Multi-AZ z trybem gotowości i zagłębiamy się w podstawowe mechanizmy, które przyczyniają się do jego niezawodności, prostoty i odporności na błędy.
Tło
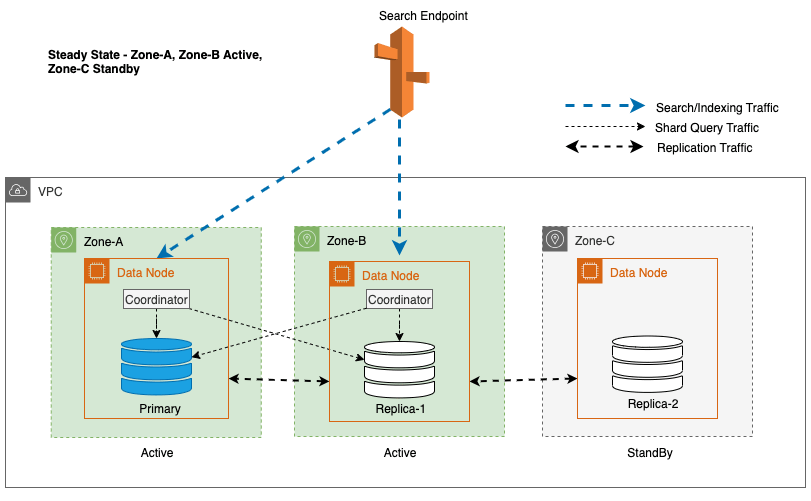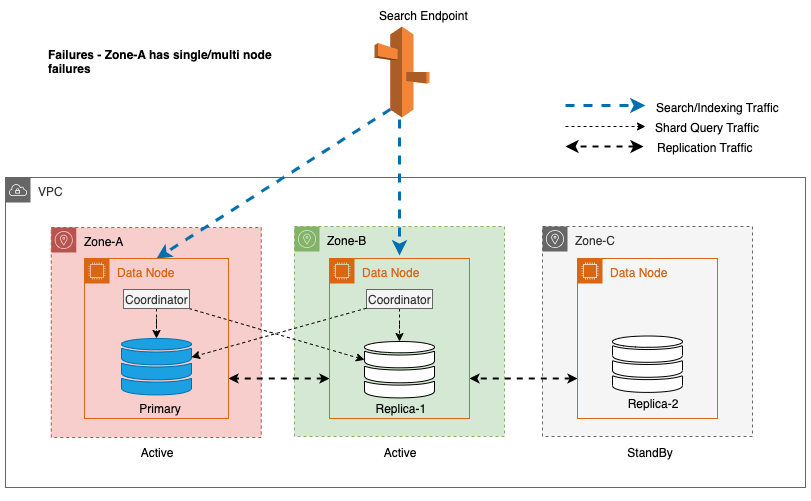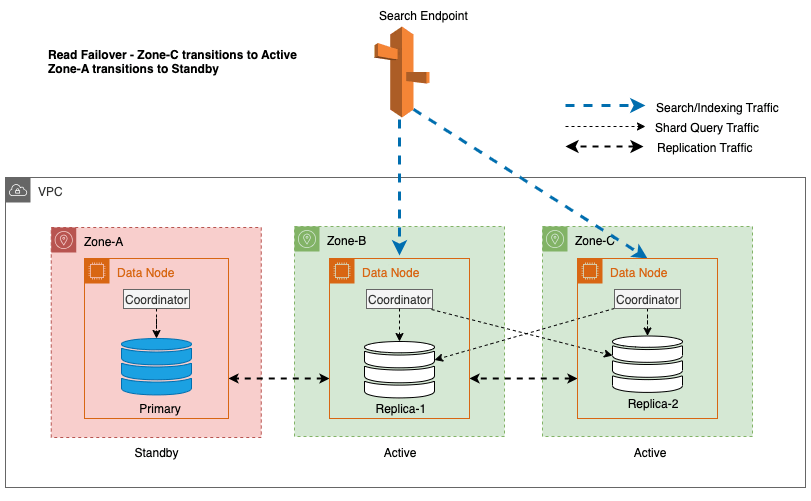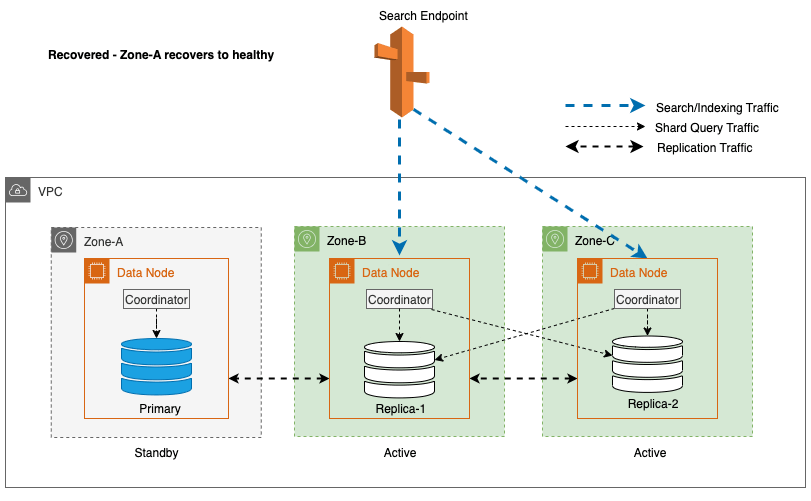
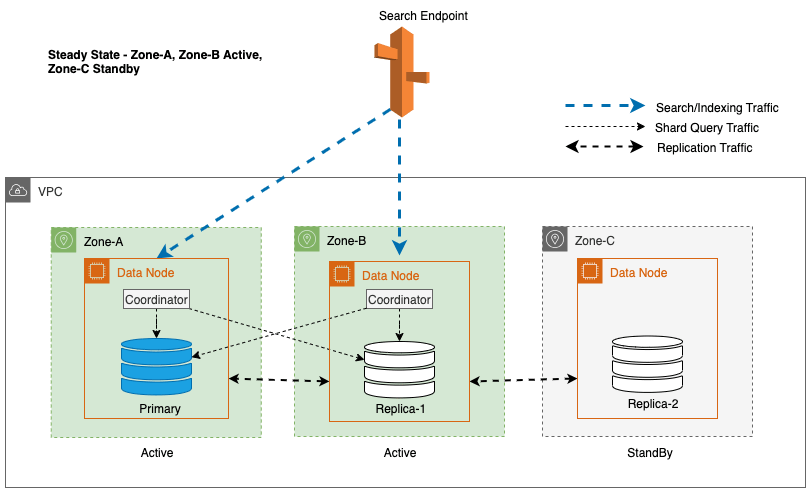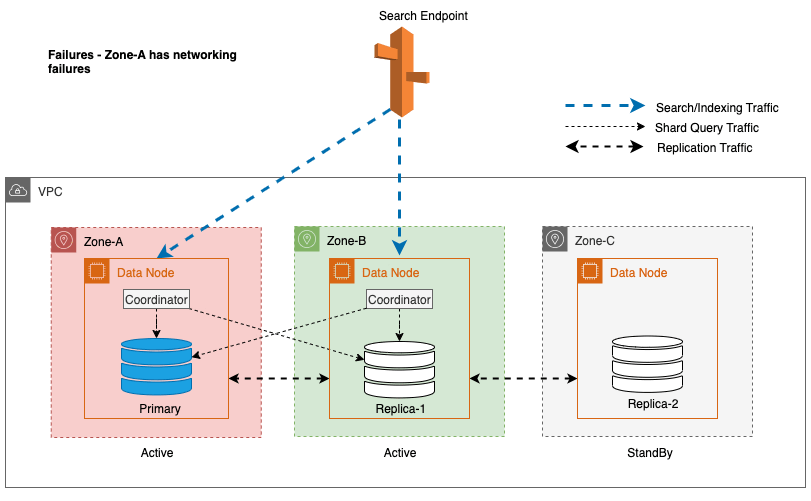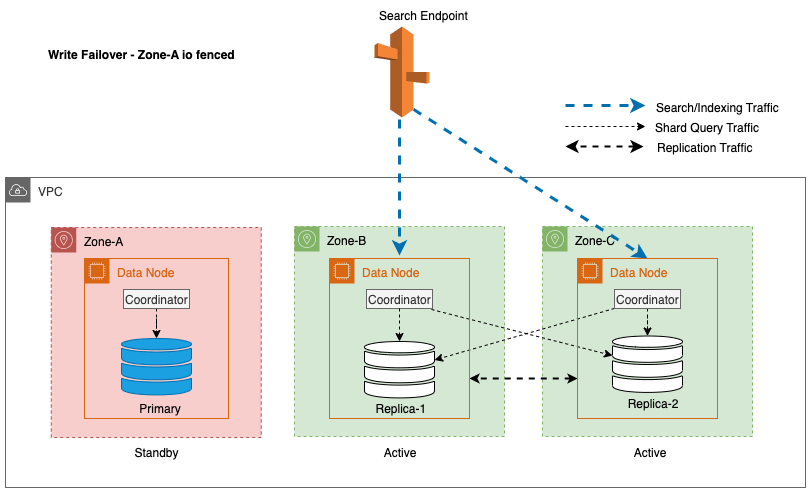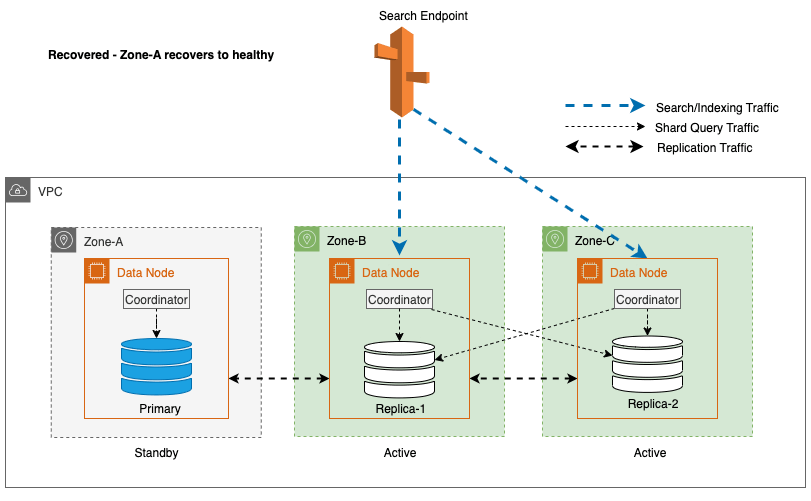
Multi-AZ z trybem gotowości wdraża instancje domeny usługi OpenSearch Service w trzech Strefach Dostępności, przy czym dwie strefy są oznaczone jako aktywne, a jedna jako rezerwowa. Taka konfiguracja zapewnia stałą wydajność, nawet w przypadku awarii strefowych, poprzez utrzymanie tej samej wydajności we wszystkich strefach. Co ważne, ta strefa gotowości następuje po: statycznie stabilna konstrukcja, eliminując potrzebę zapewniania pojemności lub przenoszenia danych w przypadku awarii.
Podczas zwykłych operacji aktywna strefa obsługuje ruch koordynatora zarówno w przypadku żądań odczytu i zapisu, jak i ruchu zapytań fragmentowych. Z drugiej strony strefa gotowości odbiera tylko ruch związany z replikacją. Usługa OpenSearch wykorzystuje protokół replikacji synchronicznej dla żądań zapisu. Umożliwia to usłudze szybkie podniesienie strefy gotowości do stanu aktywnego w przypadku awarii (średni czas do przełączenia awaryjnego <= 1 minuta), tzw. strefowe przełączanie awaryjne. Strefa wcześniej aktywna zostaje następnie przeniesiona do trybu gotowości i rozpoczynają się operacje przywracania jej prawidłowego stanu.
Kierowanie ruchu wyszukiwania i przełączanie awaryjne w celu zagwarantowania wysokiej dostępności
W domenie usługi OpenSearch a koordynator to dowolny węzeł obsługujący żądania HTTP(S), zwłaszcza żądania indeksowania i wyszukiwania. W domenie Multi-AZ z rezerwą węzły danych w aktywnej strefie pełnią rolę koordynatorów żądań wyszukiwania.
Podczas fazy zapytania żądania wyszukiwania koordynator określa fragmenty, które mają być objęte zapytaniem, i wysyła żądanie do węzła danych przechowującego kopię fragmentu. Zapytanie jest uruchamiane lokalnie na każdym fragmencie, a dopasowane dokumenty są zwracane do węzła koordynatora. Węzeł koordynujący odpowiedzialny za wysyłanie żądania do węzłów zawierających kopie fragmentów przebiega proces dwuetapowo. Najpierw tworzy iterator, który definiuje kolejność, w jakiej należy odpytywać węzły o kopię fragmentu, tak aby ruch był równomiernie rozłożony w kopiach fragmentu. Następnie żądanie jest wysyłane do odpowiednich węzłów.
Aby utworzyć uporządkowaną listę węzłów, do których należy odpytywać kopię fragmentu, węzeł koordynujący wykorzystuje różne algorytmy. Algorytmy te obejmują wybór okrężny, adaptacyjny wybór replik, routing fragmentów w oparciu o preferencje i ważona runda z każdym.
W przypadku Multi-AZ z trybem gotowości do wyboru kopii fragmentu używany jest ważony algorytm działania okrężnego. W tym podejściu aktywnym strefom przypisuje się wagę 1, a strefie gotowości przypisuje się wagę 0. Dzięki temu żaden ruch odczytu nie jest wysyłany do węzłów danych w rezerwowej Strefie Dostępności.
Wagi są przechowywane w metadanych stanu klastra jako obiekt JSON:
Jak pokazano na poniższym zrzucie ekranu, us-east-1b Region posiada status strefy jako StandBy, co oznacza, że węzły danych w tej Strefie dostępności znajdują się w stanie gotowości i nie otrzymują żądań wyszukiwania ani indeksowania z modułu równoważenia obciążenia.

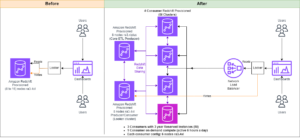
Aby utrzymać stabilne działanie, rezerwowa Strefa Dostępności zmienia się co 30 minut, zapewniając pokrycie wszystkich części sieci w Strefach Dostępności. To proaktywne podejście weryfikuje dostępność ścieżek odczytu, jeszcze bardziej zwiększając odporność systemu na potencjalne awarie. Poniższy diagram ilustruje tę architekturę.
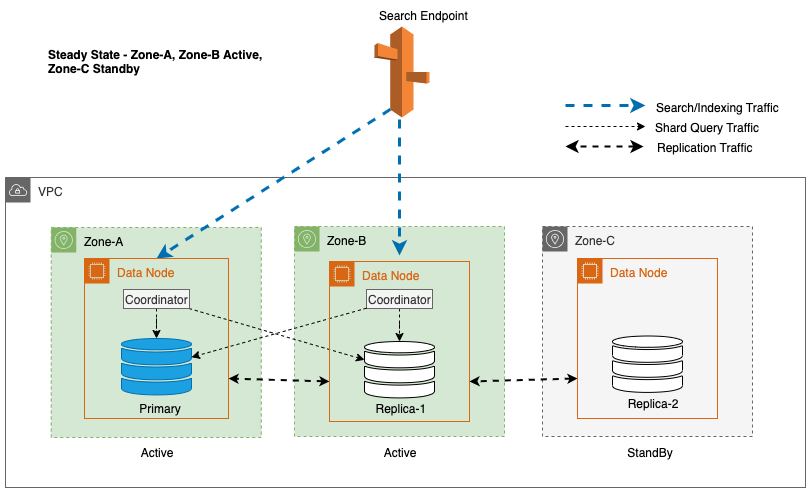
Na powyższym diagramie strefa C ma ważoną wagę okrężną ustawioną na zero. Dzięki temu węzły danych w strefie gotowości nie będą odbierać żadnego ruchu związanego z indeksowaniem ani wyszukiwaniem. Kiedy koordynator wysyła zapytanie do węzłów danych o kopie fragmentów, stosuje ważoną wagę okrężną, aby zdecydować o kolejności, w jakiej węzły mają być odpytywane. Ponieważ waga strefy dostępności w stanie gotowości wynosi zero, żądania koordynatora nie są wysyłane.
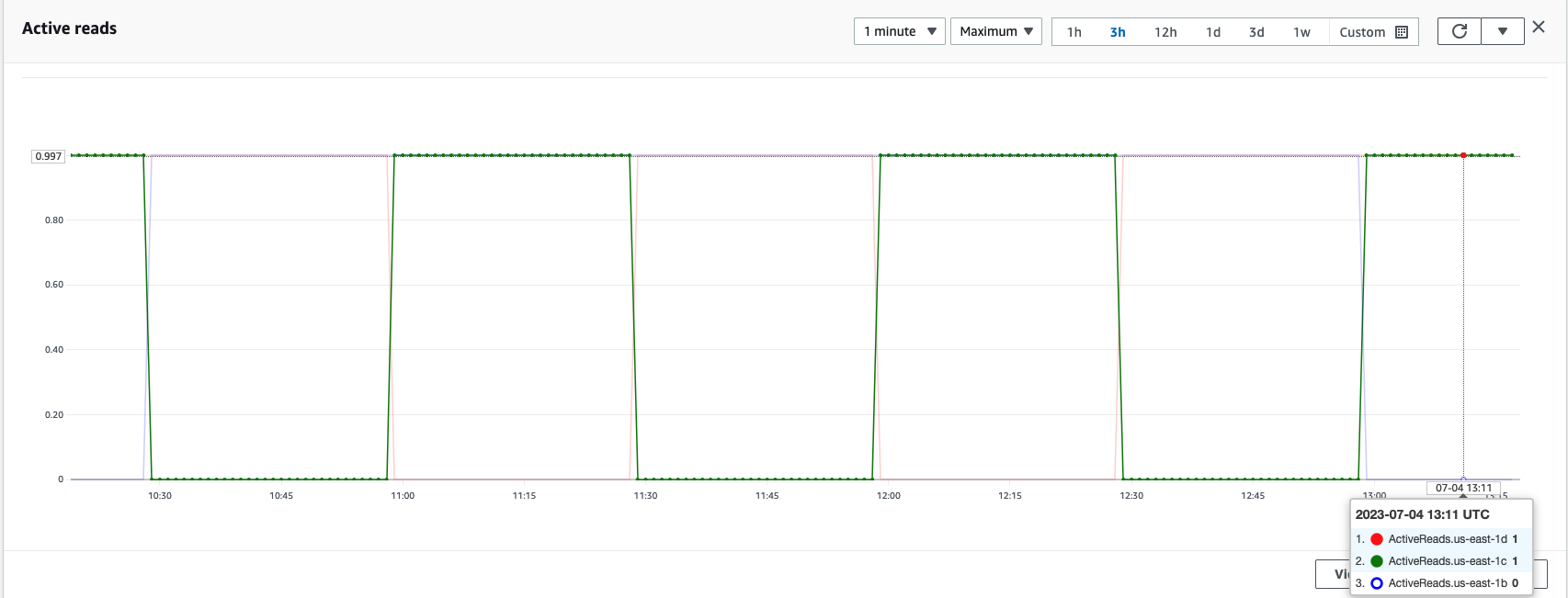
W klastrze usługi OpenSearch strefy aktywne i rezerwowe można sprawdzić w dowolnym momencie za pomocą wskaźników rotacji stref dostępności, jak pokazano na poniższym zrzucie ekranu.
Podczas przestojów strefowych rezerwowa Strefa Dostępności płynnie przełącza się w tryb awaryjnego otwierania dla żądań wyszukiwania. Oznacza to, że ruch zapytań fragmentu jest kierowany do wszystkich stref dostępności, nawet tych znajdujących się w trybie gotowości, gdy zdrowa kopia fragmentu jest niedostępna w aktywnej strefie dostępności. To podejście typu „fail-open” zabezpiecza żądania wyszukiwania przed zakłóceniami w przypadku awarii, zapewniając ciągłość usług. Poniższy diagram ilustruje tę architekturę.
Na powyższym diagramie w stanie ustalonym ruch związany z zapytaniami fragmentu jest wysyłany do węzła danych w aktywnych strefach dostępności (strefa A i strefa B). Z powodu awarii węzłów w Strefie-A, rezerwowa Strefa Dostępności (Strefa-C) nie jest otwarta, aby przejąć ruch zapytań fragmentowych, więc nie ma to żadnego wpływu na żądania wyszukiwania. Ostatecznie strefa A zostanie wykryta jako niezdrowa, a przełączenie awaryjne odczytu przełączy tryb gotowości do Strefy A.
Jak tryb awaryjny zapewnia wysoką dostępność podczas utraty wartości zapisu
Model replikacji usługi OpenSearch opiera się na podstawowym modelu tworzenia kopii zapasowych, charakteryzującym się synchronicznym charakterem, w którym konieczne jest potwierdzenie ze wszystkich kopii fragmentów, zanim będzie można potwierdzić żądanie zapisu skierowane do użytkownika. Istotną wadą tego modelu replikacji jest jego podatność na spowolnienia w przypadku jakiegokolwiek zakłócenia ścieżki zapisu. Systemy te polegają na aktywnym węźle wiodącym, który identyfikuje awarie lub opóźnienia, a następnie transmituje te informacje do wszystkich węzłów. Czas potrzebny na wykrycie tych problemów (średni czas na wykrycie) i późniejsze ich rozwiązanie (średni czas na naprawę) w dużej mierze determinuje, jak długo system będzie działał w stanie uszkodzonym. Ponadto każde zdarzenie sieciowe wpływające na komunikację między strefami może znacząco utrudniać żądania zapisu ze względu na synchroniczny charakter replikacji.
Usługa OpenSearch wykorzystuje wewnętrzny protokół komunikacji między węzłami w celu replikowania ruchu zapisu i koordynowania aktualizacji metadanych za pośrednictwem wybranego lidera. W związku z tym przełączenie strefy doświadczającej stresu w tryb gotowości nie rozwiązałoby skutecznie problemu utraty wartości zapisu.
Strefowe przełączanie awaryjne zapisu: odcięcie ruchu związanego z replikacją między strefami
W przypadku Multi-AZ z trybem gotowości, aby złagodzić potencjalne problemy z wydajnością spowodowane nieprzewidzianymi zdarzeniami, takimi jak awarie strefowe i zdarzenia sieciowe, skutecznym podejściem jest strefowe przełączanie awaryjne zapisu. Podejście to polega na płynnym usuwaniu węzłów w dotkniętej strefie z klastra, skutecznie odcinając ruch przychodzący i wychodzący pomiędzy strefami. Odcinając ruch związany z replikacją między strefami, wpływ awarii strefowych można ograniczyć w dotkniętej strefie. Zapewnia to klientom bardziej przewidywalne doświadczenia i gwarantuje, że system będzie nadal działać niezawodnie.
Płynne przełączanie awaryjne zapisu
Organizacja awaryjnego przełączania zapisu w ramach usługi OpenSearch jest przeprowadzana przez wybranego węzeł lidera za pomocą dobrze zdefiniowanego mechanizmu. Mechanizm ten obejmuje protokół konsensusu w sprawie publikacji stanu klastra, zapewniający jednomyślność wszystkich węzłów w sprawie wyznaczenia jednej strefy (zawsze) do likwidacji. Co ważne, metadane dotyczące dotkniętej strefy są replikowane we wszystkich węzłach, aby zapewnić ich trwałość, nawet podczas pełnego restartu w przypadku awarii.
Co więcej, węzeł wiodący zapewnia płynne i płynne przejście, początkowo umieszczając węzły w dotkniętych strefach w trybie gotowości na 5 minut przed zainicjowaniem zabezpieczania wejść/wyjść. To celowe podejście zapobiega kierowaniu nowego ruchu koordynatorów lub ruchu zapytań fragmentowych do węzłów w strefie, której dotyczy problem. To z kolei umożliwia tym węzłom sprawne wykonywanie bieżących zadań i stopniową obsługę wszelkich żądań w locie, zanim zostaną wycofane z eksploatacji. Poniższy diagram ilustruje tę architekturę.
W procesie wdrażania awaryjnego przełączania zapisu dla węzła lidera usługa OpenSearch Service wykonuje następujące kluczowe kroki:
- Abdykacja przywódcy – Jeśli zdarzy się, że węzeł wiodący znajduje się w strefie, w której zaplanowano przełączanie awaryjne zapisu, system zapewnia, że węzeł wiodący dobrowolnie zrezygnuje ze swojej roli lidera. Zrzeczenie się to odbywa się w sposób kontrolowany, a cały proces przekazywany jest innemu kwalifikującemu się węzłowi, który następnie przejmuje wymagane działania.
- Zapobiegaj ponownemu wyborowi przywódcy, który ma zostać odwołany – Aby zapobiec ponownemu wyborowi lidera ze strefy oznaczonej do przełączania awaryjnego zapisu, gdy uprawniony węzeł wiodący inicjuje akcję przełączania awaryjnego zapisu, podejmuje środki w celu zapewnienia, że węzły liderów, które mają zostać wycofane z eksploatacji, nie będą uczestniczyć w żadnych dalszych wyborach. Osiąga się to poprzez wykluczenie węzła lidera przeznaczonego do likwidacji z konfiguracji głosowania, skutecznie uniemożliwiając mu głosowanie w jakiejkolwiek krytycznej fazie działania klastra.
Metadane związane ze strefą przełączania awaryjnego zapisu są przechowywane w stanie klastra, a informacje te są publikowane we wszystkich węzłach rozproszonego klastra usługi OpenSearch Service w następujący sposób:
Poniższy zrzut ekranu przedstawia, że podczas spowolnienia sieci w strefie przełączenie awaryjne zapisu pomaga odzyskać dostępność.
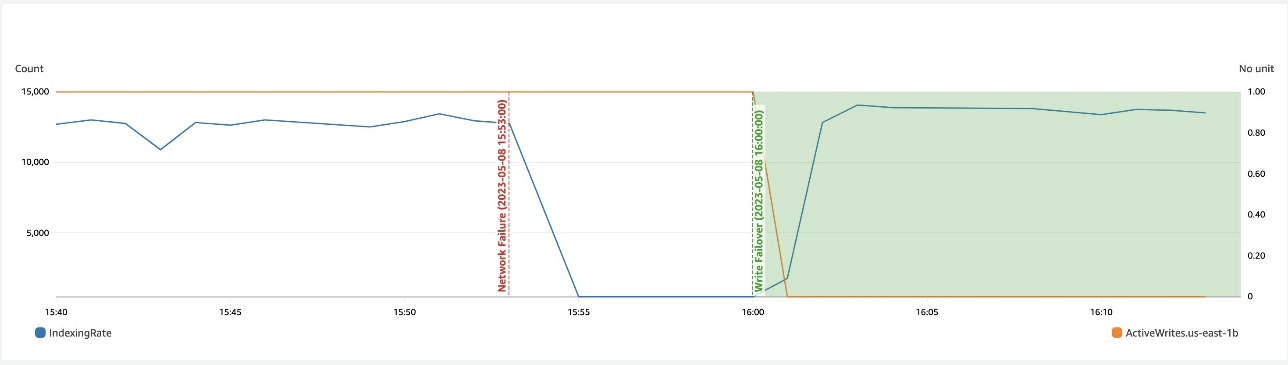
Odzyskiwanie strefowe po przełączeniu awaryjnym zapisu
Proces ponownego uruchomienia strefy odgrywa kluczową rolę w fazie odzyskiwania po przełączeniu awaryjnym zapisu strefowego. Po przywróceniu dotkniętej strefy i uznaniu jej za stabilną węzły, które zostały wcześniej wycofane z eksploatacji, ponownie dołączą do klastra. Ponowne uruchomienie zwykle następuje w ciągu 2 minut od ponownego uruchomienia strefy.
Umożliwia im to synchronizację z węzłami równorzędnymi i inicjuje proces odzyskiwania fragmentów replik, skutecznie przywracając klaster do pożądanego stanu.
Wnioski
Wprowadzenie usługi OpenSearch Service Multi-AZ z trybem gotowości zapewnia firmom potężne rozwiązanie umożliwiające osiągnięcie wysokiej dostępności i stałej wydajności w przypadku krytycznych obciążeń. Dzięki tej opcji wdrożenia firmy mogą zwiększyć odporność swojej infrastruktury, uprościć konfigurację klastra i zarządzanie nim oraz wdrożyć najlepsze praktyki. Dzięki funkcjom takim jak ważony wybór kopii fragmentu w trybie okrężnym, proaktywne mechanizmy przełączania awaryjnego i strefy dostępności w trybie gotowości w trybie awaryjnym, usługa OpenSearch Multi-AZ z trybem gotowości zapewnia niezawodne i wydajne wyszukiwanie w wymagających środowiskach korporacyjnych.
Więcej informacji na temat Multi-AZ z trybem gotowości można znaleźć w artykule Usługa Amazon OpenSearch pod maską: Multi-AZ z trybem gotowości.
O autorze
 Anshu Agarwala jest starszym inżynierem oprogramowania pracującym nad AWS OpenSearch w Amazon Web Services. Pasjonuje się rozwiązywaniem problemów związanych z budowaniem skalowalnych i wysoce niezawodnych systemów.
Anshu Agarwala jest starszym inżynierem oprogramowania pracującym nad AWS OpenSearch w Amazon Web Services. Pasjonuje się rozwiązywaniem problemów związanych z budowaniem skalowalnych i wysoce niezawodnych systemów.
 Rishab Nahata jest inżynierem oprogramowania pracującym nad OpenSearch w Amazon Web Services. Fascynuje go rozwiązywanie problemów w systemach rozproszonych. Jest aktywnym współpracownikiem OpenSearch.
Rishab Nahata jest inżynierem oprogramowania pracującym nad OpenSearch w Amazon Web Services. Fascynuje go rozwiązywanie problemów w systemach rozproszonych. Jest aktywnym współpracownikiem OpenSearch.
 Bukhtawar Chan jest głównym inżynierem pracującym nad usługą Amazon OpenSearch. Interesują go systemy rozproszone i autonomiczne. Jest aktywnym współpracownikiem OpenSearch.
Bukhtawar Chan jest głównym inżynierem pracującym nad usługą Amazon OpenSearch. Interesują go systemy rozproszone i autonomiczne. Jest aktywnym współpracownikiem OpenSearch.
 Ranjitha Ramachandry jest inżynierem pracującym nad usługą Amazon OpenSearch w Amazon Web Services.
Ranjitha Ramachandry jest inżynierem pracującym nad usługą Amazon OpenSearch w Amazon Web Services.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :ma
- :Jest
- :nie
- :Gdzie
- 1
- 10
- 100
- 12
- 30
- 501
- a
- O nas
- Osiągać
- osiągnięty
- przyznał
- w poprzek
- działać
- Działania
- działania
- aktywny
- adaptive
- do tego
- adres
- afektowany
- Po
- Umowa
- algorytm
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- Amazonka
- Amazon Web Services
- wśród
- an
- i
- Inne
- każdy
- podejście
- architektura
- SĄ
- AS
- przydzielony
- At
- autonomiczny
- systemy autonomiczne
- dostępność
- świadomość
- AWS
- backup
- stabilizator
- BE
- bo
- być
- zanim
- jest
- BEST
- Najlepsze praktyki
- pomiędzy
- obie
- nadawanie
- Budowanie
- biznes
- by
- CAN
- Pojemność
- prowadzone
- powodowany
- charakteryzuje
- opłata
- w kratę
- Grupa
- Komunikacja
- Komunikacja
- kompletny
- systemu
- Zgoda
- w konsekwencji
- za
- zgodny
- Konsola
- zawarte
- ciągły
- ciągły
- przyczynić się
- współpracownik
- kontrolowanych
- koordynacja
- Koordynator
- koordynatorzy
- kopie
- pokryty
- Stwórz
- tworzy
- krytyczny
- istotny
- Klientów
- tnący
- dane
- zdecydować
- głęboko
- głębokie nurkowanie
- Definiuje
- opóźnienia
- sięgać
- wymagający
- Wdrożenie
- wdraża się
- wyznaczony
- zaprojektowany
- życzenia
- wykryć
- wykryte
- określa
- skierowany
- Zakłócenie
- dystrybuowane
- systemy rozproszone
- nurkować
- do
- dokumenty
- domena
- domeny
- nie
- na dół
- z powodu
- czas trwania
- podczas
- każdy
- Efektywne
- faktycznie
- wydajny
- wybrany
- Wybory
- kwalifikowalne
- eliminując
- włączony
- Umożliwia
- egzekwować
- inżynier
- Inżynieria
- wzmacniać
- wzmocnione
- wzmocnienie
- zapewnić
- zapewnia
- zapewnienie
- Enterprise
- Cały
- środowiska
- szczególnie
- Eter (ETH)
- Parzyste
- wydarzenie
- wydarzenia
- ostatecznie
- Każdy
- z pominięciem
- doświadczenie
- doświadczać
- odkryj
- nie
- Brak
- Awarie
- Cecha
- Korzyści
- ogrodzenie
- i terminów, a
- następujący
- następujący sposób
- W razie zamówieenia projektu
- FRAME
- od
- pełny
- dalej
- gif
- Wdzięczny
- stopniowo
- gwarancja
- ręka
- uchwyt
- Uchwyty
- dzieje
- he
- zdrowy
- pomaga
- Wysoki
- wysoko
- kaptur
- Hosting
- W jaki sposób
- http
- HTTPS
- zidentyfikować
- if
- ilustruje
- Rezultat
- wpływ
- osłabienie
- wykonawczych
- co ważne
- in
- zawierać
- wskazując,
- Informacja
- Infrastruktura
- początkowo
- Inicjuje
- inicjowanie
- instancje
- zainteresowany
- wewnętrzny
- najnowszych
- wprowadzono
- Wprowadzenie
- dotyczy
- problem
- problemy
- IT
- JEGO
- jpg
- json
- Klawisz
- znany
- w dużej mierze
- lider
- Przywództwo
- lubić
- Lista
- załadować
- lokalnie
- usytuowany
- długo
- utrzymać
- utrzymanie
- zarządzane
- i konserwacjami
- kierownik
- sposób
- wyraźny
- dopasowane
- oznaczać
- znaczy
- środków
- mechanizm
- Mechanizmy
- Metadane
- Metryka
- chwila
- minuty
- Złagodzić
- Moda
- model
- jeszcze
- ruch
- Natura
- niezbędny
- Potrzebować
- sieć
- sieci
- Nowości
- Nie
- węzeł
- węzły
- dostojnik
- przedmiot
- of
- poza
- on
- ONE
- trwający
- tylko
- koncepcja
- działać
- działanie
- operacje
- Option
- or
- orkiestracja
- zamówienie
- Inne
- na zewnątrz
- przerwa
- Awarie
- koniec
- uczestniczyć
- strony
- namiętny
- ścieżka
- ścieżki
- par
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uporczywość
- faza
- wprowadzanie
- plato
- Analiza danych Platona
- PlatoDane
- odgrywa
- Post
- potencjał
- mocny
- praktyki
- poprzedzający
- Możliwy do przewidzenia
- zapobiec
- zapobieganie
- zapobiega
- poprzednio
- pierwotny
- Główny
- Proaktywne
- problemy
- wygląda tak
- promować
- protokół
- zapewniać
- zapewnia
- Publikacja
- opublikowany
- Putting
- zapytania
- Czytaj
- otrzymać
- otrzymuje
- niedawno
- Recover
- odzyskiwanie
- regeneracja
- odnosić się
- region
- regularny
- związane z
- niezawodność
- rzetelny
- polegać
- pozostały
- usuwanie
- naprawa
- odpowiedzieć
- replikowane
- replikacja
- zażądać
- wywołań
- wymagany
- sprężystość
- sprężysty
- rozwiązać
- odpowiedzialny
- przywracać
- przywrócone
- przywrócenie
- Rola
- Routing
- run
- działa
- s
- zabezpieczenia
- taki sam
- skalowalny
- zaplanowane
- płynnie
- Szukaj
- wybór
- wysyłanie
- wysyła
- senior
- wysłany
- usługa
- Usługi
- zestaw
- ona
- pokazane
- znacznie
- prostota
- upraszczać
- pojedynczy
- Zwolnij
- spowolnienia
- gładki
- So
- Tworzenie
- Software Engineer
- rozwiązanie
- Rozwiązywanie
- stabilny
- Stan
- Rynek
- stały
- Cel
- przechowywany
- stres
- Następnie
- udany
- podatność
- system
- systemy
- Brać
- Zadania
- trwa
- zadania
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- Te
- to
- tych
- trzy
- Przez
- czas
- czasy
- do
- tolerancja
- ruch drogowy
- przejście
- SKRĘCAĆ
- drugiej
- zazwyczaj
- dla
- zasadniczy
- nieprzewidziany
- Nowości
- używany
- Użytkownik
- zastosowania
- za pomocą
- wykorzystuje
- różnorodny
- dobrowolnie
- Głosowanie
- we
- sieć
- usługi internetowe
- waga
- DOBRZE
- dobrze zdefiniowane
- były
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- będzie
- w
- w ciągu
- pracujący
- działa
- napisać
- zefirnet
- zero
- Strefy