Agenci podsumowujący wyobrażeni przez narzędzie do generowania obrazów AI Dall-E.
Czy należysz do populacji, która zostawia recenzje na mapach Google za każdym razem, gdy odwiedzasz nową restaurację?
A może jesteś typem, który dzieli się swoją opinią na temat zakupów na Amazonie, zwłaszcza gdy skusi Cię produkt niskiej jakości?
Nie martw się, nie obwiniam cię — wszyscy mamy swoje chwile!
W dzisiejszym świecie danych wszyscy przyczyniamy się do zalewu danych na wiele sposobów. Jednym z typów danych, który uważam za szczególnie interesujący ze względu na jego różnorodność i trudność w interpretacji, są dane tekstowe, takie jak niezliczone recenzje publikowane codziennie w Internecie. Czy kiedykolwiek zastanawiałeś się nad znaczeniem standaryzacji i kondensacji danych tekstowych? Witamy w świecie agentów podsumowujących!
Agenci podsumowujący bezproblemowo zintegrowali się z naszym codziennym życiem, kondensując informacje i zapewniając szybki dostęp do odpowiednich treści w wielu aplikacjach i platformach.
W tym artykule zbadamy wykorzystanie ChatGPT jako potężnego agenta podsumowującego dla naszych niestandardowych aplikacji. Dzięki zdolności Large Language Models (LLM) do przetwarzania i rozumienia tekstów, mogą pomóc w czytaniu tekstów i generowaniu dokładnych podsumowań lub standaryzacji informacji. Jednak ważne jest, aby wiedzieć, jak wydobyć ich potencjał w wykonywaniu takiego zadania, a także znać ich ograniczenia.
Największe ograniczenie podsumowań? LLM często zawodzą, jeśli chodzi o przestrzeganie określonych ograniczeń dotyczących znaków lub słów w ich podsumowaniach.
Przyjrzyjmy się najlepszym praktykom generowania podsumowań za pomocą ChatGPT dla naszej niestandardowej aplikacji, a także przyczyny jej ograniczeń i sposoby ich przezwyciężenia!
Agenty podsumowujące są używane w całym Internecie. Na przykład strony internetowe używają agentów podsumowujących, aby oferować zwięzłe streszczenia artykułów, umożliwiając użytkownikom szybki przegląd wiadomości bez zagłębiania się w całą treść. Robią to również platformy mediów społecznościowych i wyszukiwarki.
Od agregatorów wiadomości i platform mediów społecznościowych po witryny e-commerce, agenci podsumowujący stali się integralną częścią naszego cyfrowego krajobrazu. Wraz ze wzrostem liczby LLM niektórzy z tych agentów używają teraz sztucznej inteligencji w celu uzyskania bardziej efektywnych wyników podsumowania.
ChatGPT może być dobrym sprzymierzeńcem przy budowaniu aplikacji z wykorzystaniem agentów podsumowujących do przyspieszania zadań czytania i klasyfikowania tekstów. Na przykład wyobraź sobie, że prowadzimy działalność e-commerce i jesteśmy zainteresowani przetwarzaniem wszystkich recenzji naszych klientów. ChatGPT może nam pomóc w podsumowaniu dowolnej recenzji w kilku zdaniach, ujednoliceniu jej do ogólnego formatu, określeniu sentyment recenzji i klasyfikację to odpowiednio.
Chociaż prawdą jest, że moglibyśmy po prostu przesłać recenzję do ChatGPT, istnieje lista najlepszych praktyk — i rzeczy, których należy unikać — wykorzystać moc ChatGPT w tym konkretnym zadaniu.
Zbadajmy opcje, wprowadzając ten przykład w życie!
Przykład: Recenzje e-commerce
Gif własnej roboty.
Rozważmy powyższy przykład, w którym jesteśmy zainteresowani przetwarzaniem wszystkich recenzji dla danego produktu w naszym serwisie e-commerce. Bylibyśmy zainteresowani przetwarzaniem recenzji, takich jak ta na temat naszego produktu-gwiazdy: pierwszy komputer dla dzieci!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
W takim przypadku chcielibyśmy, aby ChatGPT:
Podziel recenzję na pozytywną lub negatywną.
Podaj podsumowanie recenzji składające się z 20 słów.
Wygeneruj odpowiedź z konkretną strukturą, aby ujednolicić wszystkie recenzje w jednym formacie.
Uwagi dotyczące implementacji
Oto podstawowa struktura kodu, której moglibyśmy użyć do monitowania ChatGPT z naszej niestandardowej aplikacji. Podaję również link do Notebook Jupyter ze wszystkimi przykładami użytymi w tym artykule.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
Funkcja get_completion() wywołuje API ChatGPT z podanym podpowiedź. Jeśli monit zawiera dodatkowe tekst użytkownika, jak w naszym przypadku sama recenzja, jest oddzielona od reszty kodu potrójnymi cudzysłowami.
Użyjmy get_completion() funkcja, aby monitować ChatGPT!
Oto monit spełniający wymagania opisane powyżej:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Jak możemy zauważyć na podstawie wyników, recenzja jest jednak dokładna i dobrze ustrukturyzowana brakuje w nim pewnych informacji, które mogłyby nas zainteresować jako właścicieli e-commerce, takie jak informacje o dostawie produktu.
Podsumuj, koncentrując się na
Możemy iteracyjnie ulepszać nasz monit, prosząc ChatGPT o skupienie się na pewnych rzeczach w podsumowaniu. W takim przypadku interesują nas wszelkie podane szczegóły dotyczące wysyłki i dostawy:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Tym razem odpowiedź ChatGPT jest następująca:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Teraz recenzja jest znacznie bardziej kompletna. Podanie szczegółowych informacji na temat ważnego celu pierwotnej recenzji jest kluczowe, aby uniknąć pominięcia przez ChatGPT niektórych informacji, które mogą być cenne w naszym przypadku użycia.
Czy zauważyłeś, że chociaż ta druga próba zawiera informacje o dostawie, pominęła jedyny negatywny aspekt oryginalnej recenzji?
Naprawmy to!
„Wyodrębnij” zamiast „Podsumuj”
Dowiedziałem się o tym, badając zadania podsumowujące podsumowanie może być trudnym zadaniem dla LLM, jeśli monit użytkownika nie jest wystarczająco dokładny.
Prosząc ChatGPT o przedstawienie streszczenia danego tekstu, może pominąć informacje, które mogą być dla nas istotne — jak niedawno doświadczyliśmy — lub nadaje taką samą wagę wszystkim tematom w tekście, przedstawiając jedynie przegląd głównych punktów.
Eksperci w LLM używają tego terminu wyciąg i dodatkowe informacje na ich temat zamiast streszczać przy wykonywaniu takich zadań przy pomocy tego typu modeli.
Podczas gdy podsumowanie ma na celu przedstawienie zwięzłego przeglądu głównych punktów tekstu, w tym tematów niezwiązanych z tematem, na którym się skupiamy, ekstrakcja informacji koncentruje się na wyszukiwaniu konkretnych szczegółów i może dać nam to, czego dokładnie szukamy. Spróbujmy więc z ekstrakcją!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
W tym przypadku, korzystając z ekstrakcji, uzyskujemy tylko informacje na temat naszego zainteresowania: Shipping: Arrived a day earlier than expected.
Automatyzacja
Ten system działa dla jednej recenzji. Niemniej jednak, projektując monit dla konkretnej aplikacji, ważne jest, aby przetestować go w serii przykładów, abyśmy mogli wychwycić wszelkie wartości odstające lub niewłaściwe zachowanie w modelu.
W przypadku przetwarzania wielu recenzji, oto przykładowa struktura kodu Pythona, która może pomóc.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Oto streszczenia naszej partii recenzji:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Zauważ, że chociaż ograniczenie słów w naszych podsumowaniach było wystarczająco jasne w naszych monitach, możemy łatwo zauważyć, że to ograniczenie słów nie jest realizowane w żadnej z iteracji.
Ta niezgodność w liczeniu słów ma miejsce, ponieważ LLM nie mają dokładnego zrozumienia liczby słów lub znaków. Powodem tego jest jeden z głównych ważnych elementów ich architektury: tokenizator.
Tokenizator
LLM, takie jak ChatGPT, są zaprojektowane do generowania tekstu w oparciu o wzorce statystyczne wyuczone z ogromnych ilości danych językowych. Chociaż są bardzo skuteczne w generowaniu płynnego i spójnego tekstu, brakuje im precyzyjnej kontroli nad liczbą słów.
W powyższych przykładach, gdy podaliśmy instrukcje dotyczące bardzo dokładnej liczby słów, ChatGPT miał trudności ze spełnieniem tych wymagań. Zamiast tego wygenerował tekst, który jest w rzeczywistości krótszy niż określona liczba słów.
W innych przypadkach może generować dłuższe teksty lub po prostu tekst, który jest zbyt rozwlekły lub pozbawiony szczegółów. Dodatkowo, ChatGPT może przedkładać inne czynniki, takie jak spójność i trafność, nad ścisłe przestrzeganie liczby słów. Może to skutkować tekstem o wysokiej jakości pod względem treści i spójności, ale niedokładnie spełniającym wymagania dotyczące liczby słów.
Kluczowym elementem w architekturze ChatGPT jest tokenizer, który wyraźnie wpływa na ilość słów w generowanym wyjściu.
Gif własnej roboty.
Architektura tokenizera
Tokenizer to pierwszy krok w procesie generowania tekstu. Odpowiada za rozbicie fragmentu tekstu, który wprowadzamy do ChatGPT na poszczególne elementy — żetony —, które są następnie przetwarzane przez model językowy w celu wygenerowania nowego tekstu.
Kiedy tokenizator dzieli fragment tekstu na tokeny, robi to w oparciu o zestaw reguł, które mają na celu identyfikację znaczących jednostek języka docelowego. Jednak te zasady nie zawsze są doskonałe i mogą wystąpić przypadki, w których tokenizer dzieli lub scala tokeny w sposób, który wpływa na ogólną liczbę słów w tekście.
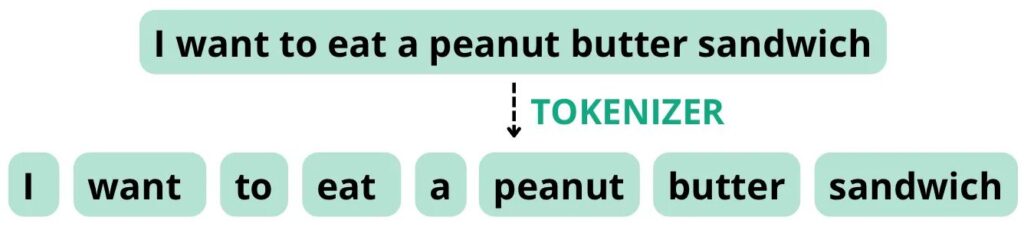
Rozważmy na przykład następujące zdanie: „Chcę zjeść kanapkę z masłem orzechowym”. Jeśli tokenizer jest skonfigurowany do dzielenia tokenów na podstawie spacji i znaków interpunkcyjnych, może podzielić to zdanie na następujące tokeny o łącznej liczbie słów równej 8, równej liczbie tokenów.
Obraz własnej roboty.
Jeśli jednak tokenizer jest skonfigurowany do leczenia "masło orzechowe" jako słowo złożone może podzielić zdanie na następujące tokeny, z całkowitą liczbą słów 8, ale liczbą żetonów 7.
Zatem sposób konfiguracji tokenizatora może wpływać na ogólną liczbę słów w tekście, co może mieć wpływ na zdolność LLM do wykonywania instrukcji dotyczących dokładnej liczby słów. Chociaż niektóre tokenizatory oferują opcje dostosowania sposobu tokenizacji tekstu, nie zawsze jest to wystarczające, aby zapewnić dokładne przestrzeganie wymagań dotyczących liczby słów. W przypadku ChatGPT w tym przypadku nie możemy kontrolować tej części jego architektury.
To sprawia, że ChatGPT nie jest tak dobry w osiąganiu ograniczeń dotyczących znaków lub słów, ale zamiast tego można spróbować ze zdaniami, ponieważ tokenizer nie wpływa na liczba zdań, ale ich długość.
Świadomość tego ograniczenia może pomóc w zbudowaniu najlepszego podpowiedzi dla Twojej aplikacji. Mając tę wiedzę o tym, jak działa liczenie słów w ChatGPT, wykonajmy ostateczną iterację z naszym monitem dla aplikacji e-commerce!
Podsumowanie: Recenzje e-commerce
Połączmy nasze wnioski z tego artykułu w ostateczną zachętę! W takim przypadku poprosimy o wyniki w HTML format dla ładniejszego wyjścia:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
A oto ostateczny wynik z ChatGPT:
Własnoręcznie zrobiony zrzut ekranu z Notebook Jupyter z przykładami użytymi w tym artykule.
Podsumowanie
W tym artykule omówiliśmy najlepsze praktyki korzystania z ChatGPT jako agenta podsumowującego dla naszej niestandardowej aplikacji.
Widzieliśmy, że podczas tworzenia aplikacji niezwykle trudno jest wymyślić idealny monit, który odpowiada wymaganiom aplikacji w pierwszej wersji próbnej. Myślę, że miła wiadomość na wynos jest do pomyśl o podpowiadaniu jako o procesie iteracyjnym gdzie udoskonalasz i modelujesz swój monit, aż uzyskasz dokładnie pożądane wyniki.
Udoskonalając iteracyjnie monit i stosując go do partii przykładów przed wdrożeniem go w środowisku produkcyjnym, możesz mieć pewność, że dane wyjściowe są spójne w wielu przykładach i obejmują odpowiedzi odstające. W naszym przykładzie może się zdarzyć, że zamiast recenzji ktoś poda losowy tekst. Możemy poinstruować ChatGPT, aby miał również standardowe dane wyjściowe, aby wykluczyć te odstające odpowiedzi.
Ponadto, gdy używamy ChatGPT do określonego zadania, dobrą praktyką jest również zapoznanie się z zaletami i wadami używania LLM do naszego docelowego zadania. W ten sposób przekonaliśmy się, że zadania wydobywania są bardziej efektywne niż podsumowanie, gdy chcemy uzyskać wspólne, przypominające człowieka podsumowanie tekstu wejściowego. Nauczyliśmy się również, że skupienie się na podsumowaniu może być game-changer dotyczące generowanej treści.
Wreszcie, chociaż LLM mogą być bardzo skuteczne w generowaniu tekstu, nie są idealne do wykonywania dokładnych instrukcji dotyczących liczby słów lub innych specyficznych wymagań dotyczących formatowania. Aby osiągnąć te cele, może być konieczne trzymanie się liczenia zdań lub użycie innych narzędzi lub metod, takich jak ręczna edycja lub bardziej specjalistyczne oprogramowanie.
Ten artykuł został pierwotnie opublikowany w W kierunku nauki o danych i ponownie opublikowane w TOPBOTS za zgodą autora.
Podoba ci się ten artykuł? Zarejestruj się, aby otrzymywać więcej aktualizacji badań AI.
Damy Ci znać, gdy wydamy więcej artykułów podsumowujących takich jak ten.