Ten post został napisany wspólnie z Pramodem Nayakiem, LakshmiKanthem Mannem i Vivekiem Aggarwalem z grupy Low Latency Group LSEG.
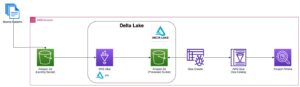
Analiza kosztów transakcyjnych (TCA) jest powszechnie stosowana przez traderów, zarządzających portfelami i brokerów do analiz przed i potransakcyjnych. Pomaga im mierzyć i optymalizować koszty transakcyjne oraz skuteczność ich strategii handlowych. W tym poście analizujemy spready kupna-sprzedaży opcji z Historia zaznaczeń LSEG – PCAP zbiór danych za pomocą Amazon Athena dla Apache Spark. Pokażemy Ci, jak uzyskać dostęp do danych, zdefiniować niestandardowe funkcje do zastosowania na danych, wykonać zapytania i filtrować zbiór danych oraz wizualizować wyniki analizy, a wszystko to bez konieczności martwienia się o konfigurowanie infrastruktury lub konfigurowanie Sparka, nawet w przypadku dużych zbiorów danych.
Tło
Urząd ds. raportowania cen opcji (OPRA) pełni rolę kluczowego podmiotu przetwarzającego informacje o papierach wartościowych, gromadzącego, konsolidującego i rozpowszechniającego raporty z ostatniej sprzedaży, notowania i istotne informacje dotyczące opcji amerykańskich. Dzięki 18 aktywnym giełdom opcji amerykańskich i ponad 1.5 milionowi kwalifikujących się kontraktów, OPRA odgrywa kluczową rolę w dostarczaniu kompleksowych danych rynkowych.
5 lutego 2024 r. firma Securities Industry Automation Corporation (SIAC) ma zamiar zmodernizować kanał OPRA z 48 do 96 kanałów multiemisji. To ulepszenie ma na celu optymalizację dystrybucji symboli i wykorzystania przepustowości linii w odpowiedzi na rosnącą aktywność handlową i zmienność na amerykańskim rynku opcji. SIAC zalecił firmom przygotowanie się na szczytowe prędkości transmisji danych do 37.3 GBitów na sekundę.
Mimo że aktualizacja nie zmienia od razu całkowitej ilości publikowanych danych, umożliwia OPRA rozpowszechnianie danych w znacznie szybszym tempie. To przejście ma kluczowe znaczenie dla zaspokojenia potrzeb rynku opcji dynamicznych.
OPRA wyróżnia się jako jeden z najbardziej obszernych kanałów, ze szczytem wynoszącym 150.4 miliarda wiadomości dziennie w trzecim kwartale 3 r. i zapotrzebowaniem na pojemność wynoszącym 2023 miliardów wiadomości w ciągu jednego dnia. Przechwycenie każdej pojedynczej wiadomości ma kluczowe znaczenie dla analizy kosztów transakcji, monitorowania płynności rynku, oceny strategii handlowej i badań rynku.
O danych
Historia zaznaczeń LSEG – PCAP to repozytorium w chmurze, o pojemności przekraczającej 30 PB, zawierające ultrawysokiej jakości dane z rynku światowego. Dane te są skrupulatnie przechwytywane bezpośrednio w centrach danych wymiany, przy wykorzystaniu redundantnych procesów przechwytywania, strategicznie rozmieszczonych w głównych głównych i zapasowych centrach danych wymiany danych na całym świecie. Technologia przechwytywania LSEG zapewnia bezstratne przechwytywanie danych i wykorzystuje źródło czasu GPS w celu uzyskania nanosekundowej precyzji znacznika czasu. Ponadto stosowane są zaawansowane techniki arbitrażu danych, aby płynnie wypełnić wszelkie luki w danych. Po przechwyceniu dane poddawane są skrupulatnemu przetwarzaniu i arbitrażowi, a następnie normalizowane do formatu Parquet Ultra Direct firmy LSEG w czasie rzeczywistym (RTUD) zajmujące się obsługą pasz.
Proces normalizacji, który jest integralną częścią przygotowania danych do analizy, generuje do 6 TB skompresowanych plików Parquet dziennie. Ogromną ilość danych przypisuje się wszechstronnemu charakterowi OPRA, obejmującemu wiele giełd i obejmującemu liczne kontrakty opcyjne charakteryzujące się różnorodnymi atrybutami. Zwiększona zmienność rynku i działalność animatora rynku na giełdach opcji dodatkowo przyczyniają się do wolumenu danych publikowanych w OPRA.
Atrybuty Tick History – PCAP umożliwiają firmom przeprowadzanie różnych analiz, w tym następujących:
- Analiza przedtransakcyjna – Oceń potencjalny wpływ handlu i zbadaj różne strategie realizacji w oparciu o dane historyczne
- Ocena potransakcyjna – Mierz rzeczywiste koszty realizacji w porównaniu z punktami odniesienia, aby ocenić skuteczność strategii realizacji
- Zoptymalizowany egzekucja – Dostosuj strategie realizacji w oparciu o historyczne wzorce rynkowe, aby zminimalizować wpływ na rynek i zmniejszyć ogólne koszty transakcyjne
- Zarządzanie ryzykiem – Identyfikuj wzorce poślizgów, identyfikuj wartości odstające i proaktywnie zarządzaj ryzykiem związanym z działalnością handlową
- Atrybucja wyników – Analizując wyniki portfela, należy oddzielić wpływ decyzji handlowych od decyzji inwestycyjnych
Historia kleszczy LSEG – zbiór danych PCAP jest dostępny w Wymiana danych AWS i można uzyskać do nich dostęp Rynek AWS. Z Wymiana danych AWS dla Amazon S3, możesz uzyskać dostęp do danych PCAP bezpośrednio z LSEG Usługa Amazon Simple Storage (Amazon S3), eliminując potrzebę przechowywania przez firmy własnych kopii danych. Takie podejście usprawnia zarządzanie i przechowywanie danych, zapewniając klientom natychmiastowy dostęp do wysokiej jakości danych PCAP lub znormalizowanych, z łatwością użycia, integracji i znaczne oszczędności w zakresie przechowywania danych.
Atena dla Apache Spark
Do prac analitycznych Atena dla Apache Spark oferuje uproszczoną obsługę notebooka dostępną za pośrednictwem konsoli Athena lub interfejsów API Athena, umożliwiając tworzenie interaktywnych aplikacji Apache Spark. Dzięki zoptymalizowanemu środowisku wykonawczemu Spark, Athena pomaga w analizie petabajtów danych poprzez dynamiczne skalowanie liczby silników Spark w czasie krótszym niż sekunda. Co więcej, popularne biblioteki Pythona, takie jak pandas i NumPy, są płynnie zintegrowane, co pozwala na tworzenie skomplikowanej logiki aplikacji. Elastyczność obejmuje import niestandardowych bibliotek do użytku w notatnikach. Athena for Spark obsługuje większość formatów otwartych danych i jest płynnie zintegrowana z platformą Klej AWS Katalog danych.
Dataset
Do tej analizy wykorzystaliśmy zbiór danych LSEG Tick History – PCAP OPRA z 17 maja 2023 r. Ten zbiór danych składa się z następujących elementów:
- Najlepsza oferta i oferta (BBO) – Raportuje najwyższą ofertę i najniższą ofertę zabezpieczenia na danej giełdzie
- Najlepsza krajowa oferta i oferta (NBBO) – Zgłasza najwyższą ofertę i najniższą prośbę o zabezpieczenie na wszystkich giełdach
- Transakcje – Rejestruje zakończone transakcje na wszystkich giełdach
Zbiór danych obejmuje następujące woluminy danych:
- Transakcje – 160 MB rozproszone w około 60 skompresowanych plikach Parquet
- BBO – 2.4 TB rozdzielone na około 300 skompresowanych plików Parquet
- NBBO – 2.8 TB rozdzielone na około 200 skompresowanych plików Parquet
Przegląd analizy
Analizowanie danych historii zaznaczeń OPRA na potrzeby analizy kosztów transakcji (TCA) obejmuje analizę notowań rynkowych i transakcji związanych z konkretnym wydarzeniem handlowym. W ramach tego badania wykorzystujemy następujące wskaźniki:
- Notowany spread (QS) – Obliczane jako różnica między zapytaniem BBO a ofertą BBO
- Efektywny spread (ES) – Obliczana jako różnica między ceną transakcyjną a środkiem BBO (oferta BBO + (zapytanie BBO – oferta BBO)/2)
- Efektywny/kwotowany spread (EQF) – Obliczane jako (ES / QS) * 100
Obliczamy te spready przed transakcją i dodatkowo w czterech odstępach czasu po transakcji (tuż po, 1 sekunda, 10 sekund i 60 sekund po transakcji).
Skonfiguruj usługę Athena dla Apache Spark
Aby skonfigurować usługę Athena dla Apache Spark, wykonaj następujące kroki:
- Na konsoli Athena, pod Rozpocznij, Wybierz Analizuj swoje dane za pomocą PySpark i Spark SQL.
- Jeśli po raz pierwszy korzystasz z Athena Spark, wybierz Utwórz grupę roboczą.

- W razie zamówieenia projektu Nazwa grupy roboczej¸ wprowadź nazwę grupy roboczej, np
tca-analysis. - W Silnik analityczny sekcja, wybierz Apache Spark.
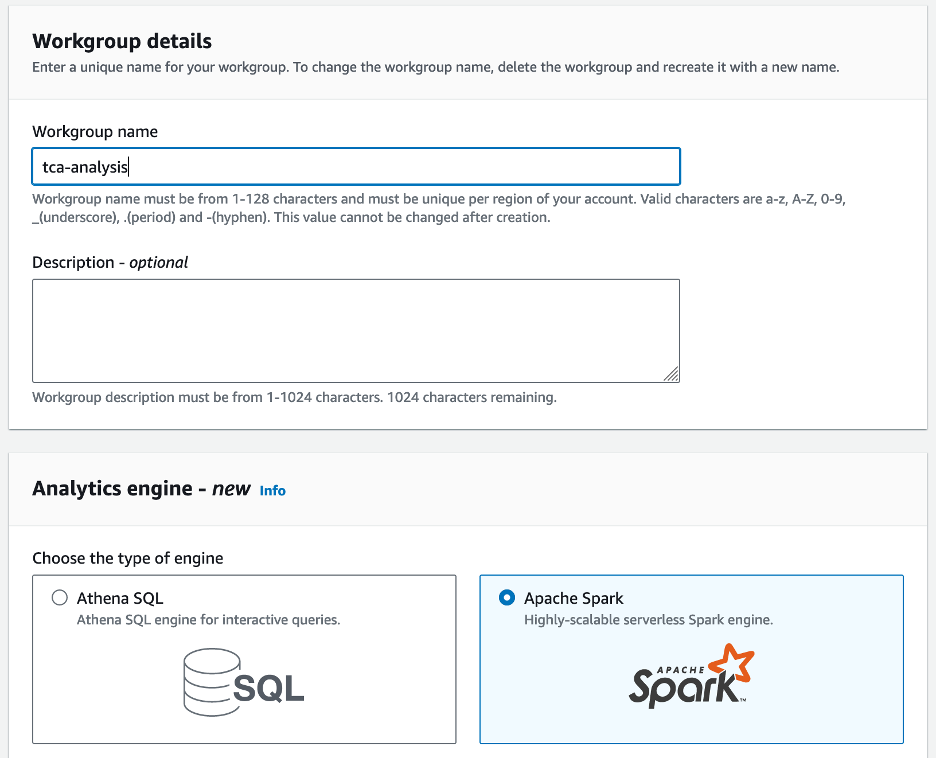
- W Dodatkowe konfiguracje sekcję, możesz wybrać Użyj ustawień domyślnych lub podaj zwyczaj AWS Zarządzanie tożsamością i dostępem (IAM) i lokalizacja Amazon S3 dla wyników obliczeń.
- Dodaj Utwórz grupę roboczą.
- Po utworzeniu grupy roboczej przejdź do Notebooki kartę i wybierz Utwórz notatnik.
- Wprowadź nazwę swojego notesu, np
tca-analysis-with-tick-history. - Dodaj Stwórz aby stworzyć swój notatnik.
Uruchom swój notatnik
Jeśli utworzyłeś już grupę roboczą Spark, wybierz Uruchom edytor notatników dla Rozpocznij.
![]()
Po utworzeniu notatnika zostaniesz przekierowany do interaktywnego edytora notatników.
![]()
Teraz możemy dodać i uruchomić następujący kod w naszym notatniku.
Utwórz analizę
Aby utworzyć analizę, wykonaj następujące kroki:
- Importuj wspólne biblioteki:
- Utwórz nasze ramki danych dla BBO, NBBO i transakcji:
- Teraz możemy zidentyfikować branżę do wykorzystania w analizie kosztów transakcyjnych:
Otrzymujemy następujący wynik:
Używamy wyróżnionych informacji handlowych w przyszłości dla produktu handlowego (tp), ceny handlowej (tpr) i czasu transakcji (tt).
- Tutaj tworzymy szereg funkcji pomocniczych do naszej analizy
- W poniższej funkcji tworzymy zbiór danych zawierający wszystkie notowania przed i po transakcji. Athena Spark automatycznie określa, ile DPU należy uruchomić w celu przetworzenia naszego zbioru danych.
- Wywołajmy teraz funkcję analizy TCA z informacjami z naszej wybranej transakcji:
Wizualizuj wyniki analizy
Utwórzmy teraz ramki danych, których będziemy używać do naszej wizualizacji. Każda ramka danych zawiera cytaty dla jednego z pięciu przedziałów czasowych dla każdego źródła danych (BBO, NBBO):
W poniższych sekcjach podajemy przykładowy kod umożliwiający tworzenie różnych wizualizacji.
Wykreśl QS i NBBO przed transakcją
Użyj poniższego kodu, aby wykreślić notowany spread i NBBO przed transakcją:
![]()
Wykreśl QS dla każdego rynku i NBBO po transakcji
Użyj poniższego kodu, aby wykreślić notowany spread dla każdego rynku i NBBO bezpośrednio po transakcji:
![]()
Wykreśl QS dla każdego przedziału czasowego i każdego rynku dla BBO
Użyj poniższego kodu, aby wykreślić podany spread dla każdego przedziału czasowego i każdego rynku dla BBO:
![]()
Wykreśl ES dla każdego przedziału czasowego i rynku dla BBO
Użyj poniższego kodu, aby wykreślić efektywny spread dla każdego przedziału czasowego i rynku dla BBO:
Narysuj EQF dla każdego przedziału czasowego i rynku dla BBO
Użyj poniższego kodu, aby wykreślić efektywny/kwotowany spread dla każdego przedziału czasowego i rynku dla BBO:
Wydajność obliczeń Athena Spark
Po uruchomieniu bloku kodu Athena Spark automatycznie określa, ile jednostek DPU wymaga do ukończenia obliczeń. W ostatnim bloku kodu, w którym wywołujemy metodę tca_analysis funkcji, tak naprawdę instruujemy Sparka, aby przetworzył dane, a następnie konwertujemy powstałe ramki danych Spark na ramki danych Pandy. Stanowi to najbardziej intensywną część analizy w zakresie przetwarzania, a kiedy Athena Spark uruchamia ten blok, pokazuje pasek postępu, upływający czas i liczbę DPU aktualnie przetwarzających dane. Na przykład w poniższym obliczeniu Athena Spark wykorzystuje 18 jednostek DPU.
![]()
Podczas konfigurowania notebooka Athena Spark masz możliwość ustawienia maksymalnej liczby jednostek DPU, z których może korzystać. Wartość domyślna to 20 DPU, ale przetestowaliśmy to obliczenie z 10, 20 i 40 DPU, aby zademonstrować, w jaki sposób Athena Spark automatycznie skaluje się w celu przeprowadzenia naszej analizy. Zaobserwowaliśmy, że Athena Spark skaluje się liniowo i zajmuje 15 minut i 21 sekund, gdy notebook został skonfigurowany z maksymalnie 10 jednostkami DPU, 8 minut i 23 sekundy, gdy notebook został skonfigurowany z 20 jednostkami DPU oraz 4 minuty i 44 sekundy, gdy notebook został skonfigurowany skonfigurowany z 40 jednostkami DPU. Ponieważ Athena Spark pobiera opłaty w oparciu o wykorzystanie DPU, z dokładnością do sekundy, koszt tych obliczeń jest podobny, ale jeśli ustawisz wyższą maksymalną wartość DPU, Athena Spark może zwrócić wynik analizy znacznie szybciej. Aby uzyskać więcej informacji na temat cennika Athena Spark, kliknij tutaj.
Wnioski
W tym poście pokazaliśmy, jak można wykorzystać wysokiej jakości dane OPRA z Tick History-PCAP firmy LSEG do przeprowadzania analiz kosztów transakcji za pomocą Athena Spark. Dostępność danych OPRA w odpowiednim czasie, uzupełniona innowacjami w zakresie dostępności AWS Data Exchange dla Amazon S3, strategicznie skraca czas analiz dla firm, które chcą uzyskać praktyczne spostrzeżenia potrzebne do kluczowych decyzji handlowych. OPRA generuje każdego dnia około 7 TB znormalizowanych danych Parquet, a zarządzanie infrastrukturą w celu zapewnienia analityki opartej na danych OPRA stanowi wyzwanie.
Skalowalność rozwiązania Athena w obsłudze wielkoskalowego przetwarzania danych na potrzeby Tick History – PCAP dla danych OPRA sprawia, że jest to atrakcyjny wybór dla organizacji poszukujących szybkich i skalowalnych rozwiązań analitycznych w AWS. Ten post pokazuje płynną interakcję pomiędzy ekosystemem AWS a danymi Tick History-PCAP oraz pokazuje, w jaki sposób instytucje finansowe mogą wykorzystać tę synergię do podejmowania decyzji opartych na danych w przypadku kluczowych strategii handlowych i inwestycyjnych.
O autorach
![]() Pramoda Nayaka jest dyrektorem ds. zarządzania produktami w grupie Low Latency w LSEG. Pramod ma ponad 10-letnie doświadczenie w branży technologii finansowych, koncentrując się na tworzeniu oprogramowania, analityce i zarządzaniu danymi. Pramod to były inżynier oprogramowania, pasjonat danych rynkowych i handlu ilościowego.
Pramoda Nayaka jest dyrektorem ds. zarządzania produktami w grupie Low Latency w LSEG. Pramod ma ponad 10-letnie doświadczenie w branży technologii finansowych, koncentrując się na tworzeniu oprogramowania, analityce i zarządzaniu danymi. Pramod to były inżynier oprogramowania, pasjonat danych rynkowych i handlu ilościowego.
![]() LakshmiKanth Mannem jest menedżerem produktu w grupie Low Latency Group firmy LSEG. Koncentruje się na produktach związanych z danymi i platformami dla branży danych rynkowych o małych opóźnieniach. LakshmiKanth pomaga klientom budować najbardziej optymalne rozwiązania dla ich potrzeb w zakresie danych rynkowych.
LakshmiKanth Mannem jest menedżerem produktu w grupie Low Latency Group firmy LSEG. Koncentruje się na produktach związanych z danymi i platformami dla branży danych rynkowych o małych opóźnieniach. LakshmiKanth pomaga klientom budować najbardziej optymalne rozwiązania dla ich potrzeb w zakresie danych rynkowych.
![]() Wiwek Aggarwal jest starszym inżynierem danych w grupie małych opóźnień LSEG. Vivek pracuje nad rozwojem i utrzymaniem potoków danych do przetwarzania i dostarczania przechwyconych strumieni danych rynkowych i źródeł danych referencyjnych.
Wiwek Aggarwal jest starszym inżynierem danych w grupie małych opóźnień LSEG. Vivek pracuje nad rozwojem i utrzymaniem potoków danych do przetwarzania i dostarczania przechwyconych strumieni danych rynkowych i źródeł danych referencyjnych.
![]() Alket Memushaj jest głównym architektem w zespole rozwoju rynku usług finansowych w AWS. Alket jest odpowiedzialny za strategię techniczną, współpracując z partnerami i klientami w celu wdrożenia nawet najbardziej wymagających obciążeń rynków kapitałowych w chmurze AWS.
Alket Memushaj jest głównym architektem w zespole rozwoju rynku usług finansowych w AWS. Alket jest odpowiedzialny za strategię techniczną, współpracując z partnerami i klientami w celu wdrożenia nawet najbardziej wymagających obciążeń rynków kapitałowych w chmurze AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- O nas
- dostęp
- dostęp
- dostępność
- dostępny
- w poprzek
- aktywny
- działalność
- rzeczywisty
- faktycznie
- Dodaj
- do tego
- adresowanie
- Korzyść
- Po
- przed
- Aggarwal
- Cele
- Wszystkie kategorie
- Pozwalać
- już
- Amazonka
- Amazonka Atena
- Amazon Web Services
- an
- analizuje
- analiza
- Analityczny
- analityka
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- każdy
- Apache
- Apache Spark
- Pszczoła
- Zastosowanie
- aplikacje
- Aplikuj
- podejście
- w przybliżeniu
- arbitraż
- arbitraż
- SĄ
- na około
- AS
- zapytać
- oszacować
- powiązany
- At
- atrybuty
- władza
- automatycznie
- Automatyzacja
- dostępność
- dostępny
- AWS
- backup
- bar
- na podstawie
- BE
- bo
- zanim
- Benchmarki
- BEST
- pomiędzy
- stawka
- Miliard
- Blokować
- brokerów
- budować
- ale
- by
- obliczać
- obliczony
- obliczenie
- wezwanie
- CAN
- Pojemność
- kapitał
- Rynki kapitałowe
- zdobyć
- Zajęte
- Przechwytywanie
- katalog
- Centra
- wyzwanie
- kanały
- charakteryzuje
- Opłaty
- wybór
- Dodaj
- klientów
- Chmura
- kod
- Zbieranie
- wspólny
- zniewalający
- kompletny
- Zakończony
- składniki
- wszechstronny
- zawiera
- Prowadzenie
- skonfigurowany
- konfigurowanie
- Konsola
- konsolidacja
- zawiera
- umowy
- przyczynić się
- konwertować
- KORPORACJA
- Koszty:
- Koszty:
- współautorem
- Stwórz
- stworzony
- tworzenie
- krytyczny
- istotny
- Obecnie
- zwyczaj
- Klientów
- myślnik
- dane
- centra danych
- inżynier danych
- Wymiana danych
- zarządzanie danymi
- analiza danych
- przechowywanie danych
- sterowane danymi
- zbiory danych
- dzień
- Podejmowanie decyzji
- Decyzje
- Domyślnie
- określić
- dostawa
- wymagający
- wymagania
- wykazać
- wykazać
- rozwijać
- detale
- określa
- rozwijanie
- oprogramowania
- zespół programistów
- różnica
- różne
- bezpośrednio
- Dyrektor
- dystrybuowane
- 分配
- inny
- Podwójna
- napęd
- dynamiczny
- dynamicznie
- dynamika
- każdy
- łatwość
- łatwość użycia
- Ekosystem
- redaktor
- Efektywne
- skuteczność
- kwalifikowalne
- eliminując
- zatrudniony
- zatrudniający
- umożliwiać
- Umożliwia
- obejmujący
- starania
- silnik
- inżynier
- silniki
- wzmocnienie
- zapewnia
- Wchodzę
- Rosnące
- Eter (ETH)
- oceniać
- ewaluację
- Parzyste
- wydarzenie
- Każdy
- przykład
- wymiana
- Wymiana
- egzekucja
- doświadczenie
- odkryj
- ekspresowy
- rozciąga się
- szybciej
- Wyposażony w
- luty
- Figa
- Akta
- wypełniać
- filtrować
- budżetowy
- Instytucje finansowe
- usługi finansowe
- technologia finansowa
- firmy
- i terminów, a
- pierwszy raz
- pięć
- Elastyczność
- koncentruje
- skupienie
- następujący
- W razie zamówieenia projektu
- format
- Dawny
- Naprzód
- cztery
- FRAME
- od
- funkcjonować
- Funkcje
- dalej
- luki
- generuje
- otrzymać
- dany
- Globalne
- rynek światowy
- Go
- będzie
- GPS
- Zarządzanie
- Prowadzenie
- Have
- mający
- he
- przedpokój
- pomaga
- wysokiej jakości
- wyższy
- Najwyższa
- Podświetlony
- historyczny
- historia
- obudowa
- W jaki sposób
- How To
- http
- HTTPS
- IAM
- zidentyfikować
- tożsamość
- if
- Natychmiastowy
- natychmiast
- Rezultat
- importować
- in
- Włącznie z
- wzrosła
- przemysł
- Informacja
- Infrastruktura
- innowacje
- spostrzeżenia
- instytucje
- integralny
- zintegrowany
- integracja
- wzajemne oddziaływanie
- interaktywne
- najnowszych
- zawiły
- inwestycja
- dotyczy
- IT
- jpg
- właśnie
- duży
- na dużą skalę
- Nazwisko
- Utajenie
- uruchomić
- mniej
- biblioteki
- Linia
- Płynność
- lokalizacja
- logika
- poszukuje
- niski
- najniższy
- utrzymanie
- poważny
- WYKONUJE
- Dokonywanie
- zarządzanie
- i konserwacjami
- kierownik
- Zarządzający
- zarządzający
- sposób
- wiele
- rynek
- Dane rynkowe
- wpływ na rynek
- badania rynku
- Zmienność rynku
- tworzenie rynku
- rynki
- masywny
- Mastering
- maksymalny
- Może..
- zmierzyć
- wiadomość
- wiadomości
- skrupulatny
- skrupulatnie
- Metryka
- milion
- zminimalizować
- minuty
- monitorowanie
- jeszcze
- Ponadto
- większość
- dużo
- wielokrotność
- Nazwa
- Natura
- Nawigacja
- Potrzebować
- wymagania
- żaden
- notatnik
- laptopy
- numer
- liczny
- tępy
- zauważony
- of
- oferta
- Oferty
- on
- ONE
- Optymalny
- Optymalizacja
- zoptymalizowane
- Option
- Opcje
- or
- organizacji
- ludzkiej,
- na zewnątrz
- wydajność
- koniec
- ogólny
- własny
- pandy
- część
- wzmacniacz
- namiętny
- wzory
- Szczyt
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- kluczowy
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- odgrywa
- Proszę
- działka
- teczka
- menedżerowie portfela
- ustawione
- Post
- post-transakcyjny
- potencjał
- Detaliczność
- Przygotować
- przygotowanie
- Cena
- wycena
- pierwotny
- Główny
- wygląda tak
- procesów
- przetwarzanie
- Procesor
- Produkt
- zarządzanie produktem
- product manager
- Produkty
- Postęp
- zapewniać
- że
- opublikowany
- Python
- Q3
- ilościowy
- ilość
- pytanie
- cytaty
- Kurs
- ceny
- Czytaj
- real
- w czasie rzeczywistym
- Zalecana
- dokumentacja
- Czerwony
- zmniejszyć
- zmniejsza
- odniesienie
- ref
- Raportowanie
- Raporty
- składnica
- wymaganie
- Wymaga
- Badania naukowe
- odpowiedź
- odpowiedzialny
- dalsze
- wynikły
- Efekt
- powrót
- ryzyko
- Rola
- run
- działa
- sprzedaż
- Skalowalność
- skalowalny
- waga
- skalowaniem
- bezszwowy
- płynnie
- druga
- sekund
- Sekcja
- działy
- Papiery wartościowe
- bezpieczeństwo
- poszukuje
- wybierać
- wybrany
- senior
- oddzielny
- służy
- Usługi
- zestaw
- ustawienie
- pokazać
- Targi
- znacznie
- podobny
- Prosty
- uproszczony
- pojedynczy
- poślizg
- Tworzenie
- rozwoju oprogramowania
- Software Engineer
- Rozwiązania
- wyrafinowany
- napięcie
- Iskra
- specyficzny
- rozpiętość
- Spready
- stojaki
- Cel
- przechowywanie
- sklep
- Strategicznie
- strategie
- Strategia
- usprawnień
- Badanie
- kolejny
- taki
- SWIFT
- symbol
- synergia
- Brać
- biorąc
- zespół
- Techniczny
- Techniki
- Technologia
- przetestowany
- niż
- że
- Połączenia
- Informacje
- ich
- Im
- następnie
- Te
- to
- Przez
- kleszcz
- czas
- aktualny
- znak czasu
- Tytuł
- do
- Kwota produktów:
- tp
- TPR
- handel
- Handlowcy
- Transakcje
- Handel
- Strategie handlowe
- strategii handlowej
- transakcja
- koszty transakcji
- transformatorowy
- przejście
- Ultra
- dla
- przechodzi
- uaktualnienie
- us
- Stosowanie
- posługiwać się
- używany
- zastosowania
- za pomocą
- Wykorzystując
- wartość
- różnorodny
- wyobrażanie sobie
- wyobrażać sobie
- Zmienność
- Tom
- kłęby
- była
- we
- sieć
- usługi internetowe
- jeśli chodzi o komunikację i motywację
- który
- szeroko
- będzie
- w
- w ciągu
- bez
- Workgroup
- pracujący
- działa
- na calym swiecie
- martwić się
- X
- lat
- ty
- Twój
- zefirnet