Wprowadzenie
W szybko rozwijającym się krajobrazie generatywnej sztucznej inteligencji kluczowa rola wektorowych baz danych staje się coraz bardziej widoczna. W tym artykule szczegółowo opisano dynamiczną synergię między wektorowymi bazami danych a generatywnymi rozwiązaniami AI, badając, w jaki sposób te podstawy technologiczne kształtują przyszłość kreatywności sztucznej inteligencji. Dołącz do nas w podróży przez zawiłości tego potężnego sojuszu, odblokowując wgląd w transformacyjny wpływ, jaki wektorowe bazy danych wnoszą na czoło innowacyjnych rozwiązań AI.
Cele kształcenia
Ten artykuł pomoże Ci zrozumieć poniższe aspekty Bazy Danych Wektorowych.
- Znaczenie wektorowych baz danych i ich kluczowych komponentów
- Szczegółowe badanie porównania baz danych Vector z tradycyjną bazą danych
- Eksploracja osadzania wektorów z punktu widzenia aplikacji
- Tworzenie wektorowych baz danych przy użyciu Pincone
- Implementacja bazy danych Pinecone Vector z wykorzystaniem modelu langchain LLM
Ten artykuł został opublikowany jako część Blogathon nauki o danych.
Spis treści
Co to jest baza danych wektorowych?
Baza danych wektorowych jest formą gromadzenia danych przechowywanych w przestrzeni. Mimo to w tym przypadku są one przechowywane w reprezentacjach matematycznych, ponieważ format przechowywany w bazach danych ułatwia otwartym modelom sztucznej inteligencji zapamiętywanie danych wejściowych i pozwala naszej otwartej aplikacji AI na korzystanie z wyszukiwania poznawczego, rekomendacji i generowania tekstu do różnych przypadków użycia w branże poddane transformacji cyfrowej. Przechowywanie i pobieranie danych nazywa się „Osadzaniem wektorowym” lub „Osadzaniem”. Co więcej, jest to reprezentowane w formacie tablicy numerycznej. Wyszukiwanie jest znacznie łatwiejsze niż w przypadku tradycyjnych baz danych wykorzystywanych do celów sztucznej inteligencji i oferujących ogromne, indeksowane możliwości.
Charakterystyka wektorowych baz danych
- Wykorzystuje moc osadzania wektorów, prowadząc do indeksowania i przeszukiwania ogromnego zbioru danych.
- Możliwość kompaktowania ze wszystkimi formatami danych (obrazy, tekst lub dane).
- Ponieważ dostosowuje techniki osadzania i wysoce indeksowane funkcje, może zaoferować kompletne rozwiązanie do zarządzania danymi i danymi wejściowymi dla danego problemu.
- Baza danych wektorowych organizuje dane za pomocą wektorów wielowymiarowych zawierających setki wymiarów. Możemy je bardzo szybko skonfigurować.
- Każdy wymiar odpowiada określonej funkcji lub właściwości obiektu danych, który reprezentuje.
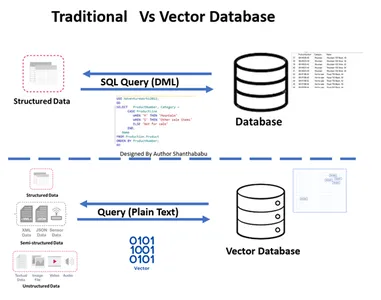
Tradycyjne vs. Baza danych wektorowych
- Zdjęcie przedstawia tradycyjny i wektorowy przepływ pracy na wysokim poziomie bazy danych
- Formalne interakcje z bazami danych zachodzą poprzez SQL wyciągi i dane przechowywane w formacie wierszowym i tabelarycznym.
- W bazie danych Vector interakcje odbywają się za pomocą zwykłego tekstu (np. w języku angielskim) i danych przechowywanych w postaci matematycznej.
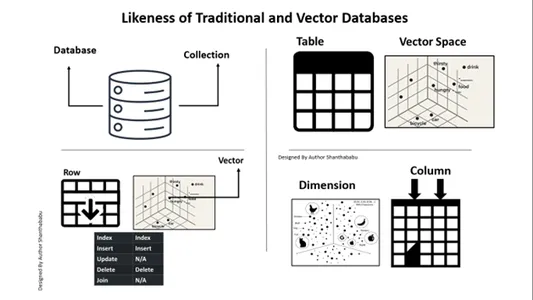
Podobieństwo baz danych tradycyjnych i wektorowych
Musimy rozważyć, czym bazy danych Vector różnią się od tradycyjnych. Omówmy to tutaj. Jedną szybką różnicę, jaką mogę podać, jest to, że w konwencjonalnych bazach danych. Dane są przechowywane dokładnie w niezmienionym stanie; moglibyśmy dodać logikę biznesową, aby dostroić dane i połączyć lub podzielić dane w oparciu o wymagania lub wymagania biznesowe. Jednak baza danych wektorów przeszła ogromną transformację, a dane stają się złożoną reprezentacją wektorową.
Oto mapa, dzięki której możesz zrozumieć i zachować przejrzystość perspektywy relacyjne bazy danych względem wektorowych baz danych. Poniższy rysunek jest oczywisty i pozwala na zrozumienie wektorowych baz danych z tradycyjnymi bazami danych. Krótko mówiąc, możemy wykonywać wstawienia i usunięcia do wektorowych baz danych, a nie aktualizować instrukcje.
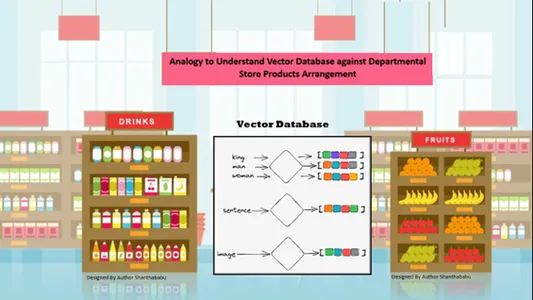
Prosta analogia do zrozumienia wektorowych baz danych
Dane są automatycznie układane przestrzennie według podobieństwa treści przechowywanych informacji. Rozważmy więc dom towarowy dla analogii do wektorowych baz danych; wszystkie produkty są ułożone na półce według charakteru, przeznaczenia, produkcji, zastosowania i ilości. W podobnym zachowaniu dane są
automatycznie uporządkowane w bazie danych wektorów według podobnego sortowania, nawet jeśli gatunek nie został dobrze zdefiniowany podczas przechowywania danych lub uzyskiwania do nich dostępu.
Wektorowe bazy danych umożliwiają wyraźną szczegółowość i wymiary konkretnych podobieństw, dzięki czemu klient wyszukuje żądany produkt, producenta i ilość, a następnie zatrzymuje przedmiot w koszyku. Baza danych wektorowych przechowuje wszystkie dane w doskonałej strukturze przechowywania; w tym przypadku inżynierowie uczenia maszynowego i sztucznej inteligencji nie muszą ręcznie etykietować ani oznaczać przechowywanych treści.
Podstawowe teorie dotyczące wektorowych baz danych
- Osadzanie wektorów i ich zakres
- Wymagania dotyczące indeksowania
- Zrozumienie wyszukiwania semantycznego i podobieństwa
Osadzanie wektorów i ich zakres
Osadzanie wektorów to reprezentacja wektorów w postaci wartości liczbowych. W skompresowanym formacie osadzenia przechwytują nieodłączne właściwości i powiązania oryginalnych danych, dzięki czemu stają się podstawą w przypadkach użycia sztucznej inteligencji i uczenia maszynowego. Projektowanie osadzania w celu zakodowania odpowiednich informacji o oryginalnych danych w przestrzeni o niższych wymiarach zapewnia dużą prędkość wyszukiwania, wydajność obliczeniową i wydajne przechowywanie.
Uchwycenie istoty danych w bardziej identyczny sposób to proces osadzania wektorów, tworzący „model osadzania”. Ostatecznie modele te uwzględniają wszystkie obiekty danych, wyodrębniają znaczące wzorce i relacje w źródle danych oraz przekształcają je w osadzanie wektorów . Następnie algorytmy wykorzystują osadzanie wektorów do wykonywania różnych zadań. Liczne, wysoce zaawansowane modele osadzania, dostępne online jako bezpłatne lub płatne, ułatwiają osadzanie wektorów.
Zakres osadzania wektorów z punktu widzenia aplikacji
Te osadzania są kompaktowe, zawierają złożone informacje, dziedziczą relacje między danymi przechowywanymi w wektorowej bazie danych, umożliwiają wydajną analizę przetwarzania danych w celu ułatwienia zrozumienia i podejmowania decyzji oraz dynamicznie budują różne innowacyjne produkty danych w dowolnej organizacji.
Techniki osadzania wektorów są niezbędne w łączeniu luki między czytelnymi danymi a złożonymi algorytmami. Ponieważ typami danych są wektory numeryczne, byliśmy w stanie uwolnić potencjał szerokiej gamy aplikacji generatywnej sztucznej inteligencji wraz z dostępnymi modelami otwartej sztucznej inteligencji.
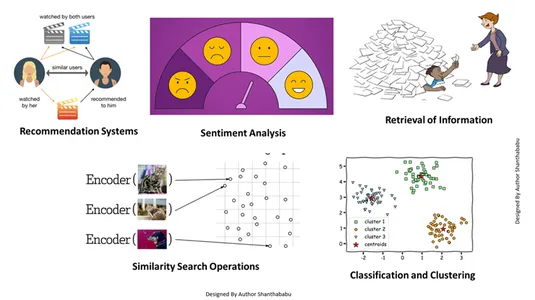
Wiele zadań z osadzaniem wektorów
To osadzanie wektorów pomaga nam wykonywać wiele zadań:
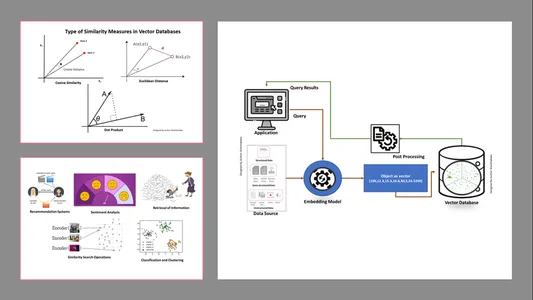
- Pobieranie informacji: Za pomocą tych potężnych technik możemy zbudować wpływowe wyszukiwarki, które pomogą nam znaleźć odpowiedzi na podstawie zapytań użytkowników z przechowywanych plików, dokumentów lub multimediów
- Operacje wyszukiwania podobieństw: Jest to dobrze zorganizowane i indeksowane; pomaga nam znaleźć podobieństwo między różnymi zdarzeniami w danych wektorowych.
- Klasyfikacja i grupowanie: Korzystając z tych technik osadzania, możemy wykonać te modele, aby wyszkolić odpowiednie algorytmy uczenia maszynowego oraz pogrupować je i sklasyfikować.
- Systemy rekomendacji: Ponieważ techniki osadzania są odpowiednio zorganizowane, prowadzi to do systemów rekomendacji dokładnie odnoszących się do produktów, mediów i artykułów w oparciu o dane historyczne.
- Analiza nastrojów: Ten model osadzania pomaga nam kategoryzować i wyprowadzać rozwiązania dotyczące nastrojów.
Wymagania dotyczące indeksowania
Jak wiemy, indeks usprawni wyszukiwanie danych z tabeli w tradycyjnych bazach danych, podobnych do wektorowych baz danych, i zapewni funkcje indeksowania.
Bazy danych wektorowych zapewniają „indeksy płaskie”, które są bezpośrednią reprezentacją osadzania wektorów. Możliwość wyszukiwania jest wszechstronna i nie korzysta z wstępnie przeszkolonych klastrów. Wykonuje wektor zapytania w każdym pojedynczym osadzeniu wektora i oblicza K odległości dla każdej pary.
- Ze względu na łatwość stosowania tego indeksu do utworzenia nowych indeksów wymagane są minimalne obliczenia.
- Rzeczywiście, płaski indeks może skutecznie obsługiwać zapytania i zapewniać szybki czas wyszukiwania.
Zrozumienie wyszukiwania semantycznego i podobieństwa
W wektorowych bazach danych przeprowadzamy dwa różne wyszukiwania: semantyczne i podobieństwo.
- Wyszukiwanie semantyczne: Wyszukując informacje, zamiast szukać ich po słowach kluczowych, możesz je znaleźć w oparciu o sensowną metodologię konwersacji. Szybka inżynieria odgrywa kluczową rolę w przekazywaniu danych wejściowych do systemu. To wyszukiwanie niewątpliwie umożliwia wyszukiwanie i wyniki o wyższej jakości, które można wykorzystać w innowacyjnych aplikacjach, SEO, generowaniu tekstu i podsumowaniach.
- Wyszukiwanie podobieństw: Zawsze w analizie danych wyszukiwanie podobieństw pozwala na uzyskanie nieustrukturyzowanych, znacznie lepiej danych zbiorów danych. Jeśli chodzi o wektorowe bazy danych, musimy ustalić bliskość dwóch wektorów i to, jak są do siebie podobne: tabele, tekst, dokumenty, obrazy, słowa i pliki audio. W procesie rozumienia podobieństwo wektorów ujawnia się jako podobieństwo obiektów danych w danym zbiorze danych. To ćwiczenie pomaga nam zrozumieć interakcje, zidentyfikować wzorce, wyciągnąć wnioski i podejmować decyzje z perspektywy aplikacji. Wyszukiwanie semantyczne i podobieństwo pomoże nam w tworzeniu poniższych aplikacji z korzyścią dla branży.
- Wyszukiwanie informacji: Wykorzystując otwartą sztuczną inteligencję i bazy danych wektorowych, budowalibyśmy wyszukiwarki do wyszukiwania informacji na podstawie zapytań użytkowników biznesowych lub końcowych oraz indeksowanych dokumentów w wektorowej bazie danych.
- Klasyfikacja i grupowanie:Klasyfikacja lub grupowanie podobnych punktów danych lub grup obiektów polega na przypisywaniu ich do wielu kategorii w oparciu o wspólne cechy.
- Wykrywanie anomalii: Odkrywanie nieprawidłowości w stosunku do zwykłych wzorców poprzez pomiar podobieństwa punktów danych i wykrywanie nieprawidłowości.
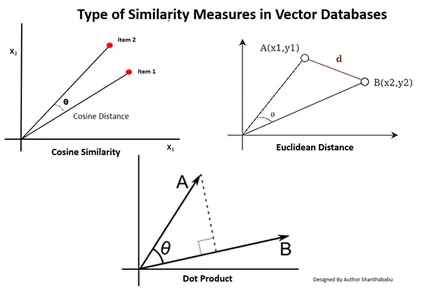
Rodzaje miar podobieństwa w wektorowych bazach danych
Metody pomiaru zależą od charakteru danych i specyfiki aplikacji. Zwykle stosuje się trzy metody pomiaru podobieństwa i znajomości uczenia maszynowego.
Odległość euklidesowa
Mówiąc najprościej, odległość między dwoma wektorami to odległość w linii prostej między dwoma punktami wektorowymi mierzącymi st.
Produkt w kropki
Pomaga nam to zrozumieć wyrównanie dwóch wektorów, wskazując, czy są one skierowane w tym samym kierunku, w przeciwnych kierunkach, czy też są do siebie prostopadłe.
Podobieństwo cosinusowe
Ocenia podobieństwo dwóch wektorów na podstawie kąta między nimi, jak pokazano na rysunku. W tym przypadku wartości i wielkość wektorów są nieistotne i nie wpływają na wyniki; w obliczeniach uwzględniany jest tylko kąt.
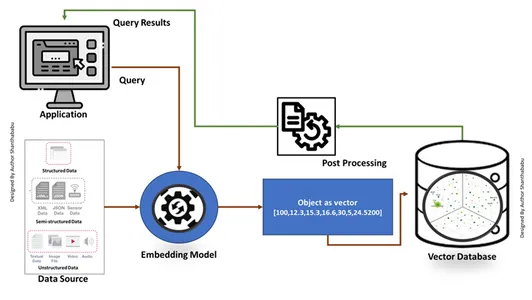
Tradycyjne bazy danych Szukaj dokładnych dopasowań instrukcji SQL i pobieraj dane w formacie tabelarycznym. Jednocześnie zajmujemy się wektorowymi bazami danych poszukującymi wektora najbardziej podobnego do zapytania wejściowego w prostym języku angielskim z wykorzystaniem technik Prompt Engineering. Baza danych wykorzystuje algorytm wyszukiwania przybliżonego najbliższego sąsiada (ANN) w celu znalezienia podobnych danych. Zawsze dostarczaj w miarę dokładne wyniki przy wysokiej wydajności, dokładności i czasie reakcji.
Mechanizm pracy
- Wektorowe bazy danych najpierw konwertują dane na wektory osadzające, przechowują je w wektorowych bazach danych i tworzą indeksowanie w celu szybszego wyszukiwania.
- Zapytanie z aplikacji będzie wchodziło w interakcję z wektorem osadzającym, wyszukując najbliższego sąsiada lub podobne dane w bazie wektorów za pomocą indeksu i pobierając wyniki przekazane do aplikacji.
- W zależności od wymagań biznesowych pobrane dane zostaną dostrojone, sformatowane i wyświetlone użytkownikowi końcowemu lub w kanale zapytań lub działań.
Tworzenie bazy danych wektorowych
Połączmy się z Pinecone.
Możesz połączyć się z Pinecone za pomocą Google, GitHub lub Microsoft ID.
Utwórz nowy login użytkownika do swojego użytku.
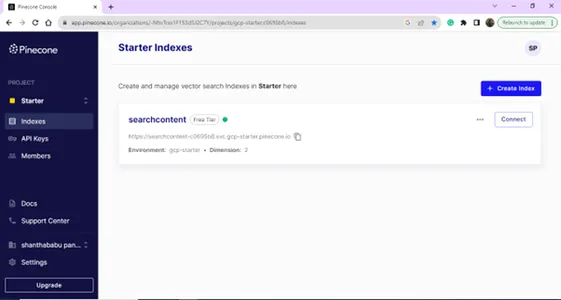
Po pomyślnym zalogowaniu wylądujesz na stronie Indeks; możesz utworzyć indeks na potrzeby swojej bazy danych wektorowych. Kliknij przycisk Utwórz indeks.
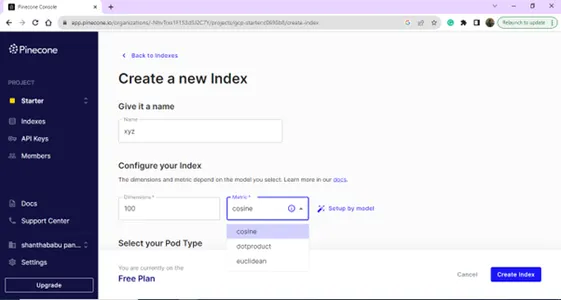
Utwórz nowy indeks, podając nazwę i wymiary.
strona z listą indeksów,
Szczegóły indeksu – nazwa, region i środowisko – potrzebujemy wszystkich tych szczegółów, aby połączyć naszą wektorową bazę danych z kodem budowy modelu.
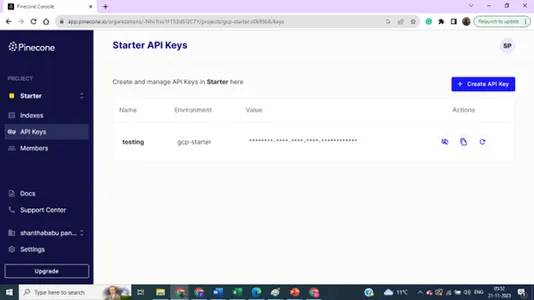
Szczegóły ustawień projektu,
Możesz uaktualnić swoje preferencje dotyczące wielu indeksów i kluczy na potrzeby projektu.
Do tej pory omówiliśmy tworzenie indeksu i ustawień bazy danych wektorów w Pinecone.
Implementacja wektorowej bazy danych przy użyciu języka Python
Zróbmy teraz trochę kodowania.
Importowanie bibliotek
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIUdostępnienie klucza API dla bazy danych OpenAI i Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Inicjowanie LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Inicjowanie Pinecone
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Ładowanie pliku .csv do budowy bazy danych wektorów
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Podziel tekst na kawałki
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Znajdowanie tekstu w Text_chunk
text_chunksWydajność
[Dokument(page_content='name: 100% Brannmfr: Nntype: Cnkalorie: 70nbiałko: 4ntłuszcz: 1nsod: 130nfiber: 10ncarbo: 5nscukry: 6npotass: 280nwitaminy: 25npółka: 3nwaga: 1nckubki: 0.33nrating: 68.402973 100nrekomendacja: Dzieci, metadane={ „źródło”: „0% Bran”, „wiersz”: XNUMX}), , …..
Osadzanie budynków
embeddings = OpenAIEmbeddings()Utwórz instancję Pinecone dla bazy danych wektorowych z „danych”
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Utwórz retriever do wysyłania zapytań do bazy danych wektorów.
retriever = vectordb.as_retriever(score_threshold = 0.7)Pobieranie danych z bazy wektorów
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsKorzystanie z podpowiedzi i pobieranie danych
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Zapytajmy o dane.
chain('Can you please provide cereal recommendation for Kids?')Dane wyjściowe z zapytania
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Wnioski
Mam nadzieję, że rozumiesz, jak działają wektorowe bazy danych, ich komponenty, architekturę i cechy wektorowych baz danych w rozwiązaniach generatywnej sztucznej inteligencji. Zrozum, czym wektorowa baza danych różni się od tradycyjnej bazy danych i porównaj ją z konwencjonalnymi elementami bazy danych. Rzeczywiście, analogia pomaga lepiej zrozumieć bazę danych wektorów. Baza danych wektorów Pinecone i kroki indeksowania pomogą w utworzeniu bazy danych wektorów i zapewnieniu klucza do poniższej implementacji kodu.
Na wynos
- Możliwość kompaktowania danych ustrukturyzowanych, nieustrukturyzowanych i częściowo ustrukturyzowanych.
- Dostosowuje techniki osadzania i wysoce indeksowane funkcje.
- Interakcje odbywają się za pomocą zwykłego tekstu z podpowiedziami (np. w języku angielskim). Oraz dane przechowywane w reprezentacjach matematycznych.
- Podobieństwo kalibruje się w wektorowych bazach danych za pomocą – odległości euklidesowej, podobieństwa cosinusowego i iloczynu skalarnego.
Często Zadawane Pytania
A. Wektorowa baza danych przechowuje zbiór danych w przestrzeni. Przechowuje dane w postaci matematycznej. ponieważ format przechowywany w bazach danych ułatwia otwartym modelom sztucznej inteligencji zapamiętywanie poprzednich danych wejściowych i umożliwia naszej otwartej aplikacji AI korzystanie z wyszukiwania kognitywnego, rekomendacji i precyzyjnego generowania tekstu do różnych zastosowań w branżach przekształconych cyfrowo.
A. Oto niektóre cechy: 1. Wykorzystuje moc osadzania wektorów, prowadząc do indeksowania i przeszukiwania ogromnego zbioru danych. 2. Możliwość kompaktowania danych ustrukturyzowanych, nieustrukturyzowanych i częściowo ustrukturyzowanych. 3. Baza danych wektorowych organizuje dane za pomocą wektorów wielowymiarowych zawierających setki wymiarów
A. Baza danych ==> Kolekcje
Tabela==> Przestrzeń wektorowa
Rząd==>Cector
Kolumna==>Wymiar
Wstawianie i usuwanie możliwe jest w bazach Vector, podobnie jak w tradycyjnej bazie danych.
Aktualizuj i Dołącz nie wchodzą w zakres.
– Szybkie pobieranie informacji w celu szybkiego gromadzenia masowych danych.
– Operacje wyszukiwania semantycznego i podobieństwa w dokumentach o dużych rozmiarach.
– Zastosowanie do klasyfikacji i grupowania.
– Systemy Rekomendacji i Analizy Sentymentów.
A5: Poniżej znajdują się trzy metody pomiaru podobieństwa:
– Odległość euklidesowa
– Podobieństwo cosinusowe
– Produkt kropkowy
Media pokazane w tym artykule nie są własnością Analytics Vidhya i są wykorzystywane według uznania Autora.
Związane z
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Zdolny
- O nas
- Dostęp
- precyzja
- dokładny
- dokładnie
- w poprzek
- dostosowuje się
- Dodaj
- oddziaływać
- AI
- Modele AI
- algorytm
- Algorytmy
- wyrównanie
- Wszystkie kategorie
- Alians
- dopuszczać
- pozwala
- wzdłuż
- zawsze
- wśród
- an
- analiza
- analityka
- Analityka Widhja
- i
- odpowiedź
- każdy
- api
- pozorny
- Zastosowanie
- specyficzne dla aplikacji
- aplikacje
- przybliżony
- architektura
- SĄ
- ułożone
- Szyk
- artykuł
- towary
- sztuczny
- sztuczna inteligencja
- Sztuczna inteligencja i uczenie maszynowe
- AS
- aspekty
- ocenia
- stowarzyszenia
- At
- audio
- automatycznie
- dostępny
- na podstawie
- BE
- stają się
- staje się
- zachowanie
- za
- jest
- poniżej
- Korzyści
- Ulepsz Swój
- pomiędzy
- blogaton
- przynieść
- budować
- Budowanie
- biznes
- przycisk
- by
- obliczony
- obliczenie
- nazywa
- CAN
- możliwości
- zdolność
- zdobyć
- walizka
- Etui
- kategorie
- łańcuch
- więzy
- Charakterystyka
- klarowność
- klasyfikacja
- Klasyfikuj
- kliknij
- klastrowanie
- kod
- Kodowanie
- poznawczy
- kolekcja
- powszechnie
- kompaktowy
- porównać
- porównanie
- kompletny
- kompleks
- składniki
- wszechstronny
- obliczenia
- obliczeniowy
- Skontaktuj się
- Podłączanie
- Rozważać
- za
- zawierać
- zawartość
- kontekst
- Konwencjonalny
- Rozmowa
- konwertować
- odpowiada
- mógłby
- Stwórz
- Tworzenie
- kreatywność
- klient
- dane
- analiza danych
- punkty danych
- analiza danych
- Baza danych
- Bazy danych
- zbiory danych
- sprawa
- Podejmowanie decyzji
- Decyzje
- wymagania
- czerpać
- projektowanie
- życzenia
- detale
- Wykrywanie
- rozwinięty
- różnić się
- różnica
- różne
- cyfrowo
- Wymiary
- Wymiary
- kierować
- kierunek
- kierunki
- odkrywanie
- dyskrecja
- dyskutować
- omówione
- wystawiany
- dystans
- do
- dokumenty
- robi
- darowizna
- DOT
- dynamiczny
- dynamicznie
- e
- każdy
- łatwość
- łatwiej
- faktycznie
- efektywność
- wydajny
- bądź
- Elementy
- osadzanie
- umożliwiać
- zakończenia
- Inżynieria
- Inżynierowie
- silniki
- Angielski
- zapewnia
- Środowisko
- istota
- niezbędny
- Eter (ETH)
- Parzyste
- ewoluuje
- wykonać
- Ćwiczenie
- Exploring
- wyciąg
- ułatwiać
- Znajomość
- daleko
- Cecha
- Korzyści
- nakarmiony
- Postać
- filet
- Akta
- Znajdź
- i terminów, a
- mieszkanie
- następujący
- W razie zamówieenia projektu
- czoło
- Nasz formularz
- format
- Darmowy
- od
- przyszłość
- szczelina
- Generować
- generacja
- generatywny
- generatywna sztuczna inteligencja
- rodzaj
- GitHub
- Dać
- dany
- Zarządzanie
- Grupy
- uchwyt
- zdarzyć
- Have
- pomoc
- pomaga
- tutaj
- Wysoki
- na wysokim szczeblu
- wysoko
- historyczny
- W jaki sposób
- Jednak
- HTTPS
- olbrzymi
- Setki
- i
- ID
- zidentyfikować
- if
- zdjęcia
- Rezultat
- realizacja
- importować
- podnieść
- in
- coraz bardziej
- wskaźnik
- zindeksowane
- indeksy
- wskazując,
- Indeksy
- przemysłowa
- przemysł
- Wpływowy
- Informacja
- nieodłączny
- Innowacyjny
- wkład
- Wejścia
- Wkłady
- wewnątrz
- spostrzeżenia
- przykład
- zamiast
- Inteligencja
- interakcji
- wzajemne oddziaływanie
- Interakcje
- najnowszych
- zawiłości
- dotyczy
- IT
- JEGO
- Oferty pracy
- przystąpić
- Dołącz do nas
- podróż
- właśnie
- Klawisz
- Klawisze
- słowa kluczowe
- dzieci
- Wiedzieć
- Etykieta
- Kraj
- krajobraz
- duży
- prowadzący
- Wyprowadzenia
- nauka
- Dźwignia
- wykorzystuje
- lubić
- Lista
- ładowarka
- logika
- Zaloguj Się
- maszyna
- uczenie maszynowe
- poważny
- robić
- WYKONUJE
- Dokonywanie
- zarządzający
- sposób
- ręcznie
- Producent
- mapa
- masywny
- zapałki
- matematyczny
- wymowny
- zmierzyć
- środków
- zmierzenie
- mechanizm
- Media
- Łączyć
- Metodologia
- metody
- Microsoft
- minimalny
- model
- modele
- jeszcze
- Ponadto
- większość
- dużo
- wielokrotność
- musi
- Nazwa
- Natura
- Potrzebować
- Nowości
- już dziś
- liczny
- przedmiot
- obiekty
- of
- oferta
- on
- ONE
- te
- Online
- tylko
- koncepcja
- OpenAI
- operacje
- naprzeciwko
- or
- organizacja
- Zorganizowany
- organizuje
- oryginalny
- OS
- Inne
- ludzkiej,
- własność
- strona
- đôi
- część
- minęło
- Przechodzący
- wzory
- doskonały
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- wykonuje
- perspektywa
- perspektywy
- obraz
- kluczowy
- Równina
- plato
- Analiza danych Platona
- PlatoDane
- odgrywa
- Proszę
- punkt
- zwrotnica
- możliwy
- potencjał
- power
- mocny
- Praktyczny
- Praktyczne zastosowania
- precyzyjny
- precyzyjnie
- preferencje
- poprzedni
- Problem
- wygląda tak
- Produkt
- Produkty
- projekt
- wybitny
- monity
- prawidłowo
- niska zabudowa
- własność
- zapewniać
- że
- zaopatrzenie
- opublikowany
- kłęby
- cel
- cele
- ilość
- zapytania
- pytanie
- Szybki
- szybciej
- szybko
- szybko
- Rekomendacja
- zalecenia
- w sprawie
- region
- relacje
- Relacje
- reprezentacja
- reprezentowane
- reprezentuje
- wymagany
- wymagania
- odpowiedź
- Odpowiedzi
- dalsze
- Efekt
- Ujawnił
- Rola
- RZĄD
- s
- taki sam
- nauka
- zakres
- Szukaj
- Wyszukiwarki
- wyszukiwania
- poszukiwania
- sentyment
- seo
- w panelu ustawień
- Shape
- modelacja
- shared
- Półka
- Short
- pokazane
- Targi
- bok
- podobny
- podobieństwa
- Prosty
- ponieważ
- pojedynczy
- Rozmiar
- So
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Typ przestrzeni
- specyficzny
- prędkość
- dzielić
- plamienie
- SQL
- Stan
- Zestawienie sprzedaży
- oświadczenia
- Cel
- Nadal
- przechowywanie
- sklep
- przechowywany
- sklep
- Struktura
- zbudowany
- Badanie
- Następnie
- udany
- synergia
- system
- systemy
- T
- stół
- TAG
- zadania
- Techniki
- techniczny
- REGULAMIN
- XNUMX
- generowanie tekstu
- niż
- że
- Połączenia
- Przyszłość
- ich
- Im
- Te
- one
- to
- trzy
- Przez
- czas
- czasy
- do
- tradycyjny
- Pociąg
- Przekształcać
- Transformacja
- transformacyjny
- przekształcony
- próbować
- drugiej
- typy
- Ostatecznie
- zrozumieć
- zrozumienie
- niewątpliwie
- odblokować
- odblokowywanie
- Aktualizacja
- uaktualnienie
- us
- Stosowanie
- posługiwać się
- używany
- Użytkownik
- zastosowania
- za pomocą
- zwykły
- Wartości
- różnorodność
- różnorodny
- początku.
- istotny
- vs
- była
- we
- webp
- dobrze zdefiniowane
- były
- Co
- Co to jest
- czy
- który
- Podczas
- będzie
- w
- w ciągu
- słowa
- Praca
- pracujący
- by
- ty
- Twój
- zefirnet