Ten post został napisany wspólnie z Gregiem Bensonem, głównym naukowcem; Aaron Kesler, starszy menedżer produktu; oraz Rich Dill, architekt rozwiązań dla przedsiębiorstw w SnapLogic.
Wielu klientów tworzy generatywne aplikacje AI Amazońska skała macierzysta i Zaklinacz kodów Amazon do tworzenia artefaktów kodu w oparciu o język naturalny. Ten przypadek użycia pokazuje, jak duże modele językowe (LLM) mogą stać się tłumaczami między językami ludzkimi (angielski, hiszpański, arabski i inne) a językami interpretowanymi maszynowo (Python, Java, Scala, SQL itd.) wraz z wyrafinowanymi wewnętrzne rozumowanie. Ta pojawiająca się umiejętność w LLM zmusiła twórców oprogramowania do wykorzystania LLM jako narzędzia do automatyzacji i ulepszania UX, które przekształca język naturalny w język specyficzny dla domeny (DSL): instrukcje systemowe, żądania API, artefakty kodu i nie tylko. W tym poście pokażemy Ci, jak to zrobić SnapLogic, klient AWS, użył Amazon Bedrock do zasilania swojego SnapGPT produktu poprzez automatyczne tworzenie tych złożonych artefaktów DSL na podstawie ludzkiego języka.
Kiedy klienci tworzą obiekty DSL z LLM, wynikowy DSL jest albo dokładną repliką, albo pochodną istniejących danych i schematu interfejsu, który tworzy umowę między interfejsem użytkownika a logiką biznesową w usłudze wspierającej. Ten wzorzec jest szczególnie popularny wśród niezależnych dostawców oprogramowania (ISV) i dostawców oprogramowania jako usługi (SaaS) ze względu na ich unikalny sposób przedstawiania konfiguracji za pomocą kodu i chęć uproszczenia doświadczenia użytkownika dla swoich klientów. Przykładowe przypadki użycia obejmują:
Najprostszym sposobem tworzenia i skalowania aplikacji do przetwarzania tekstu na potok za pomocą LLM na AWS jest użycie Amazon Bedrock. Amazon Bedrock to najłatwiejszy sposób tworzenia i skalowania generatywnych aplikacji AI za pomocą modeli podstawowych (FM). Jest to w pełni zarządzana usługa, która oferuje dostęp do szerokiej gamy wysokowydajnych podstawowych FM od wiodących AI za pośrednictwem jednego API, wraz z szerokim zestawem funkcji potrzebnych do tworzenia generatywnych aplikacji AI zapewniających prywatność i bezpieczeństwo. Anthropic, laboratorium zajmujące się bezpieczeństwem i badaniami nad sztuczną inteligencją, które buduje niezawodne, interpretowalne i sterowalne systemy sztucznej inteligencji, jest jedną z wiodących firm zajmujących się sztuczną inteligencją, która oferuje dostęp do najnowocześniejszego LLM, Claude, na Amazon Bedrock. Claude to LLM, który wyróżnia się w szerokim zakresie zadań, od przemyślanego dialogu, tworzenia treści, złożonego rozumowania, kreatywności i kodowania. Anthropic oferuje zarówno modele Claude, jak i Claude Instant, z których wszystkie są dostępne za pośrednictwem Amazon Bedrock. Claude szybko zyskał popularność w zastosowaniach związanych z przetwarzaniem tekstu na potok ze względu na lepszą zdolność rozumowania, która pozwala mu wyróżniać się w rozwiązywaniu niejednoznacznych problemów technicznych. Claude 2 na Amazon Bedrock obsługuje okno kontekstowe zawierające 100,000 200 tokenów, co odpowiada około XNUMX stronom tekstu w języku angielskim. Jest to szczególnie ważna funkcja, na której można polegać podczas tworzenia aplikacji przetwarzających tekst na potok, które wymagają złożonego rozumowania, szczegółowych instrukcji i wyczerpujących przykładów.
Tło SnapLogic
SnapLogic jest klientem AWS, którego misją jest udostępnienie światu automatyzacji przedsiębiorstw. Inteligentna platforma integracyjna SnapLogic (IIP) umożliwia organizacjom realizację automatyzacji w całym przedsiębiorstwie poprzez połączenie całego ekosystemu aplikacji, baz danych, dużych zbiorów danych, maszyn i urządzeń, interfejsów API i innych elementów za pomocą wstępnie zbudowanych, inteligentnych łączników zwanych Snaps. SnapLogic udostępnił niedawno funkcję o nazwie SnapGPT, który zapewnia interfejs tekstowy, w którym możesz wpisać żądany potok integracji, który chcesz utworzyć, prostym, ludzkim językiem. SnapGPT wykorzystuje model Claude firmy Anthropic za pośrednictwem Amazon Bedrock do automatyzacji tworzenia potoków integracyjnych w postaci kodu, który jest następnie wykorzystywany przez flagowe rozwiązanie integracyjne SnapLogic. Jednak podróż SnapLogic do SnapGPT była zwieńczeniem wielu lat działania w przestrzeni AI.
Podróż SnapLogic ze sztuczną inteligencją
W dziedzinie platform integracyjnych SnapLogic niezmiennie przoduje, wykorzystując transformacyjną moc sztucznej inteligencji. Z biegiem lat zaangażowanie firmy we wprowadzanie innowacji w zakresie sztucznej inteligencji stało się oczywiste, zwłaszcza gdy prześledzimy drogę od Irys do Automatyczne łączenie.
Skromne początki z Iris
W 2017 roku firma SnapLogic zaprezentowała Iris, pierwszego w branży asystenta integracji opartego na sztucznej inteligencji. Iris został zaprojektowany tak, aby wykorzystywać algorytmy uczenia maszynowego (ML) do przewidywania kolejnych kroków w budowaniu potoku danych. Analizując miliony elementów metadanych i przepływów danych, Iris może przedstawiać użytkownikom inteligentne sugestie, demokratyzując integrację danych i umożliwiając nawet osobom nieposiadającym głębokiej wiedzy technicznej tworzenie złożonych przepływów pracy.
AutoLink: budowanie dynamiki
Bazując na sukcesie i wnioskach wyciągniętych z Iris, SnapLogic wprowadził AutoLink, funkcję mającą na celu dalsze uproszczenie procesu mapowania danych. Żmudne zadanie ręcznego mapowania pól pomiędzy systemami źródłowymi i docelowymi stało się proste dzięki AutoLink. Korzystając ze sztucznej inteligencji, AutoLink automatycznie identyfikował i sugerował potencjalne dopasowania. Integracje, które kiedyś zajmowały wiele godzin, można przeprowadzić w ciągu zaledwie kilku minut.
Skok generatywny dzięki SnapGPT
Najnowsze podejście SnapLogic do sztucznej inteligencji przynosi nam SnapGPT, którego celem jest jeszcze większa rewolucjonizacja integracji. Dzięki SnapGPT firma SnapLogic wprowadza pierwsze na świecie rozwiązanie do integracji generatywnej. Nie chodzi tu tylko o uproszczenie istniejących procesów, ale o całkowite przemyślenie sposobu projektowania integracji. Moc generatywnej sztucznej inteligencji pozwala tworzyć od podstaw całe potoki integracji, optymalizując przepływ pracy w oparciu o pożądany wynik i charakterystykę danych.
SnapGPT ma ogromny wpływ na klientów SnapLogic, ponieważ mogą drastycznie skrócić czas wymagany do wygenerowania pierwszego potoku SnapLogic. Tradycyjnie klienci SnapLogic musieliby spędzać dni lub tygodnie na konfigurowaniu potoków integracji od podstaw. Teraz ci klienci mogą po prostu poprosić SnapGPT, aby na przykład „utworzył potok, który przeniesie wszystkich moich aktywnych klientów SFDC do WorkDay”. Dla tego klienta automatycznie tworzony jest działający pierwszy projekt potoku, co drastycznie skraca czas programowania wymagany do stworzenia podstawy potoku integracyjnego. Dzięki temu klient końcowy może poświęcić więcej czasu na skupienie się na tym, co ma dla niego prawdziwy wpływ na działalność biznesową, zamiast pracować nad konfiguracjami potoku integracji. Poniższy przykład pokazuje, jak klient SnapLogic może wprowadzić opis do funkcji SnapGPT, aby szybko wygenerować potok przy użyciu języka naturalnego.
![]()
AWS i SnapLogic ściśle współpracowały podczas tworzenia produktu i wiele się po drodze nauczyły. Pozostała część tego posta skupi się na wiedzy technicznej, jaką AWS i SnapLogic zdobyły w związku z używaniem LLM w zastosowaniach związanych z przetwarzaniem tekstu na potok.
Omówienie rozwiązania
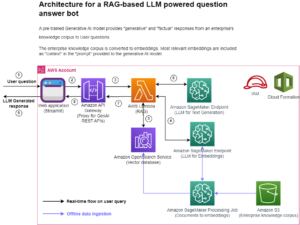
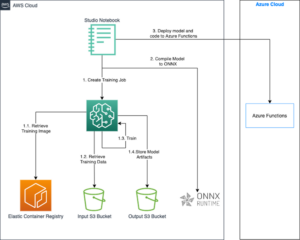
Aby rozwiązać ten problem przesyłania tekstu do potoku, AWS i SnapLogic zaprojektowały kompleksowe rozwiązanie przedstawione w poniższej architekturze.
![]()
Żądanie do SnapGPT przechodzi następujący proces:
- Użytkownik przesyła opis do aplikacji.
- SnapLogic wykorzystuje metodę Retrieval Augmented Generation (RAG) do pobierania odpowiednich przykładów potoków SnapLogic, które są podobne do żądań użytkownika.
- Wyodrębnione, istotne przykłady są łączone z danymi wprowadzanymi przez użytkownika i przechodzą wstępne przetwarzanie tekstu, zanim zostaną wysłane do Claude’a na Amazon Bedrock.
- Claude tworzy artefakt JSON reprezentujący potok SnapLogic.
- Artefakt JSON jest bezpośrednio zintegrowany z podstawową platformą integracyjną SnapLogic.
- Potok SnapLogic jest wyświetlany użytkownikowi w przyjazny wizualnie sposób.
Dzięki różnym eksperymentom pomiędzy AWS i SnapLogic odkryliśmy, że szybki etap projektowania diagramu rozwiązania jest niezwykle ważny dla generowania wysokiej jakości wyników dla tych wyników przesyłania tekstu do potoku. Następna sekcja omawia szczegółowo niektóre specyficzne techniki stosowane z Claudem w tej przestrzeni.
Szybkie eksperymentowanie
W fazie rozwoju SnapGPT firmy AWS i SnapLogic odkryły, że szybka iteracja monitów wysyłanych do Claude'a była kluczowym zadaniem programistycznym mającym na celu poprawę dokładności i trafności wyników zamiany tekstu na potok w wynikach SnapLogic. Używając Studio Amazon SageMaker interaktywnych notatnikach, zespół AWS i SnapLogic mógł szybko przeglądać różne wersje podpowiedzi, korzystając z narzędzia Połączenie Boto3 SDK z Amazon Bedrock. Rozwój oparty na notatnikach umożliwił zespołom szybkie tworzenie połączeń po stronie klienta z Amazon Bedrock, dołączanie opisów tekstowych do kodu Pythona w celu wysyłania podpowiedzi do Amazon Bedrock oraz organizowanie wspólnych sesji inżynieryjnych, podczas których szybko wykonywano iteracje między wieloma osobami.
Antropiczne metody inżynieryjne Claude'a
W tej sekcji opisujemy niektóre techniki iteracyjne, których użyliśmy do stworzenia wydajnego podpowiedzi na podstawie przykładowego żądania użytkownika: „Utwórz potok korzystający z bazy danych Przykładfirmy, która pobiera wszystkich aktywnych klientów”. Należy pamiętać, że ten przykład nie jest schematem, na którym działa SnapGPT i jest używany wyłącznie do zilustrowania aplikacji zamiany tekstu na potok.
Aby określić podstawę naszej szybkiej inżynierii, używamy następującego oryginalnego podpowiedzi:
Utwórz potok korzystający z bazy danych PrzykładFirma, która pobiera wszystkich aktywnych klientów
Oczekiwany wynik jest następujący:
{ "database": "ExampleCompany", "query": "SELECT * FROM ec_prod.customers WHERE status = 'active'" }
Ulepszenie nr 1: Korzystanie z adnotacji Człowieka i Asystenta
Procedura szkoleniowa Claude'a uczy FM rozumieć dialog pomiędzy człowiekiem a asystentem w swojej szybkiej strukturze. Użytkownicy Claude mogą skorzystać z tej struktury, kończąc monit w Asystencie:, co spowoduje, że Claude zacznie generować odpowiedź na zapytanie w oparciu o to, co powiedział człowiek. Pamiętaj, że ponieważ Claude będzie nadal generował tekst, dopóki nie zostanie poproszony o zatrzymanie, upewnij się, że używasz sekwencji zatrzymującej nnHuman: w żądaniu API do Amazon Bedrock podczas korzystania z Claude. Dzięki temu otrzymasz odpowiedź wyłącznie od asystenta, a nie przewidywaną następną odpowiedź od osoby w łańcuchu dialogu. Wskaźniki nnHuman i nnAssistant nie tylko pomagają ograniczyć reakcję Claude'a na istotne informacje, ale także pomagają w zapewnieniu jasnego rozgraniczenia pomiędzy głównymi działaniami człowieka a odpowiedziami asystenta wynikającymi z innych interakcji. Jest to szczególnie przydatne w przypadku ustawienia podpowiedzi z kilkoma strzałami, w którym można mieć wiele zapytań i odpowiedzi z zapytaniami oznaczonymi tagiem nnHuman i poprzednimi odpowiedziami oznaczonymi tagiem nnAssistant. Przyjrzyjmy się ulepszonemu monitowi i powiązanemu z nim ilustracyjnemu wywołaniu API do Amazon Bedrock za pośrednictwem zestawu SDK Boto3.
Używamy następującego monitu:
Człowiek: Utwórz potok korzystający z bazy danych PrzykładFirma, która pobiera wszystkich aktywnych klientów
Asystent:
Dane wyjściowe są następujące:
Oto potok MongoDB umożliwiający pobranie wszystkich aktywnych klientów z bazy danych Przykładfirmy:
pipeline = [ { '$match': { 'database': 'ExampleCompany', 'status': 'active' } } ] db.customers.aggregate(pipeline)Kluczowe kroki to:
– `$match`, aby filtrować dokumenty tylko do tych z bazy PrzykładFirma i mających status równy „aktywny”.
– `db.customers.aggregate()` uruchamia potok na kolekcji klientów i zwraca przefiltrowane wyniki.
Spowoduje to zwrócenie wszystkich dokumentów klientów z bazy danych PrzykładFirma, w której pole statusu jest ustawione na „aktywne”.
Zwróć uwagę, że w wynikach Claude tworzy odpowiedź na nasze pytanie bez żadnego kontekstu. Odpowiedź jest potencjalnie pomocna, ale nie jest specyficzna dla problemu, który próbujemy rozwiązać, ponieważ nie ma wystarczającego kontekstu. Należy również zauważyć, że Anthropic wymaga formatu człowieka i asystenta podczas korzystania z modeli Claude; jeśli nie uwzględnisz tego kroku, Amazon Bedrock zwróci błąd.
Ulepszenie nr 2: Dołącz bardzo specyficzny kontekst dla Claude'a, zanim powie mu, co ma robić
Claude radzi sobie najlepiej, gdy ma dobry kontekst dotyczący tego, co musi osiągnąć i w jaki sposób ma to zadanie wykonać. Oto kilka przykładów rzeczy, które należy uwzględnić jako kontekst dla Claude’a, zanim powierzysz mu zadanie:
- Opisz funkcję zawodową, którą chcesz, aby Claude pełnił. Robiąc to, sprawiasz, że Claude zaczyna myśleć o osobie pracującej na tym stanowisku, a raczej o kimś, kto właśnie został zatrudniony na tym konkretnym stanowisku. Pomoże to Claude’owi sformułować odpowiedź z perspektywy konkretnej roli zawodowej, redukując halucynacje i przypadkowość odpowiedzi.
- Dołącz szczegóły techniczne dotyczące formatu wyjściowego. Modele podstawowe są na ogół dobre w wykonywaniu następujących czynności, więc poproszenie Claude'a o wygenerowanie wyników w określonym formacie lub schemacie z jednym lub kilkoma przykładami pomoże Claude'owi udzielić odpowiedzi we właściwym formacie, zmniejszając potrzebę filtrowania i przetwarzania końcowego wyników. Przykład w poniższym monicie przedstawia fikcyjny schemat pasujący do oczekiwanych wyników.
Połączmy te sugestie, aby ulepszyć nasz pierwotny monit:
Człowiek: Twoim zadaniem jest pełnienie roli eksperta w zakresie potoków ETL. W szczególności Twoim zadaniem jest utworzenie reprezentacji JSON potoku ETL, która rozwiąże dostarczone żądanie użytkownika.
Dane wyjściowe JSON powinny mieć następujący format:
Oto Twoje zadanie: utwórz potok wykorzystujący bazę danych PrzykładFirma, który pobierze wszystkich aktywnych klientów
Asystent:
Dane wyjściowe są następujące:
Oto reprezentacja JSON potoku ETL do pobierania wszystkich aktywnych klientów z bazy danych PrzykładFirma:
Ten potok korzysta z bazy danych PrzykładFirma i zapytania SQL w celu wybrania wszystkich rekordów z tabeli klientów, których stan to „aktywny”.
Po dodaniu kontekstu model jest teraz w stanie w większości dotrzeć do naszej odpowiedzi. Teraz wie, jak ustrukturyzować dane wyjściowe i rozumie, że aby rozwiązać zadanie, musi napisać instrukcję SQL. Zauważysz jednak, że model nie używa poprawnie oczekiwanej przez nas nomenklatury ec_prod.customers. Miejsce na udoskonalenie! Pamiętaj też, że w praktyce konieczne będzie uwzględnienie znacznie większego kontekstu niż ten, który podaliśmy w tym przykładzie, aby uzyskać wysokiej jakości wyniki w przypadkach użycia tekstu do potoku.
Ulepszenie nr 3: Załączanie przykładów w tagach XML
Uczenie się przez kilka strzałów to popularny sposób na zwiększenie dokładności w przypadku FM, w przypadku którego masz odpowiednie przykłady, które pomogą FM w jego zadaniu. Jest to szczególnie ważne podczas pracy w aplikacjach zamiany tekstu na potok, ponieważ te bardzo specyficzne dane wyjściowe potoku zwykle nie są uwzględniane w żadnym publicznym zestawie danych, ponieważ są specyficzne dla reprezentacji danych indywidualnego klienta. Korzystając z Claude, możesz skorzystać z jego wrodzonej wiedzy na temat dowolnych znaczników XML, aby dostarczyć te przykłady w formacie kilku ujęć. W poniższym ulepszonym monicie zwróć uwagę na dodanie przykładów zawartych w Tagi XML. Możesz także używać skrótów słów „człowiek” i „asystent” za pomocą H i A, aby zapewnić Claude’owi kontekst, nie sprawiając przy tym wrażenia, że są to konkretne fragmenty dialogu, który już się odbył.
Używamy następującego monitu:
Człowiek: Twoim zadaniem jest pełnienie roli eksperta w zakresie potoków ETL. W szczególności Twoim zadaniem jest utworzenie reprezentacji JSON potoku ETL, która rozwiąże dostarczone żądanie użytkownika.
Dane wyjściowe JSON powinny mieć następujący format:
Oto kilka przykładów żądań użytkowników i powiązanych artefaktów wyjściowych JSON, które poprawnie rozwiązują podane zadanie. Jeśli korzystasz z tych samych baz danych, upewnij się, że używasz tej samej nomenklatury, która jest podana w przykładach.
H: zapytaj bazę danych firmy Przykładowa firma o aktywne zamówienia dla klienta nr 1234
A:
Powodem tego zapytania jest to, że klient nr 1234 jest filtrowany i przeszukujemy tabelę „zamówienia” pod kątem istniejących rekordów po „aktywnym” filtrze.
H: usuń wszystkich klientów z bazy PrzykładFirma, którzy nie byli aktywni w ostatnim miesiącu
A:
Powodem tego zapytania jest to, że tabela „ec_prod.customers” jest jedyną tabelą w bazie danych Przykładfirmy, która zawiera rekordy klientów.
Oto Twoje zadanie: utwórz potok wykorzystujący bazę danych PrzykładFirma, który pobierze wszystkich aktywnych klientów.
Asystent:
Dane wyjściowe są następujące:
Oto reprezentacja JSON dla potoku ETL w celu pobrania wszystkich aktywnych klientów z bazy danych PrzykładFirma:
Rozumowanie jest następujące:
Jako baza danych, która ma być używana, określono bazę danych exampleCompany
Tabela ec_prod.customers zawiera dane klientów
Pole stanu wskazuje, czy klient jest aktywny, dlatego zapytanie filtruje tylko aktywnych klientów
To powinno pobrać wszystkie aktywne rekordy klientów z bazy danych Przykładfirmy. Daj mi znać, jeśli potrzebujesz wyjaśnień lub masz dodatkowe wymagania dotyczące rurociągu ETL!
Dane wyjściowe JSON mają teraz poprawną nomenklaturę bazy danych, z której Claude mógł skorzystać dzięki podanym przez nas przykładom. Połączenie wskaźników ludzkich i asystentów ze znacznikami XML ułatwia Claude'owi zrozumienie, jakie jest zadanie i jaka była odpowiedź w podobnych przykładach z bardzo wyraźnym oddzieleniem wielu kilku-ujęciowych przykładów. Im łatwiej będzie to zrozumieć Claude'owi, tym lepsza i trafniejsza będzie odpowiedź, co jeszcze bardziej zmniejsza ryzyko halucynacji modela i udzielania przypadkowych, nieistotnych odpowiedzi.
Ulepszenie nr 4: Wyzwalanie Claude'a w celu rozpoczęcia generowania JSON ze znacznikami XML
Małym wyzwaniem w przypadku aplikacji zamiany tekstu na potok korzystających z FM jest konieczność dokładnego przeanalizowania danych wyjściowych z wynikowego tekstu, aby można było je zinterpretować jako kod w aplikacji znajdującej się dalej. Jednym ze sposobów rozwiązania tego problemu za pomocą Claude jest wykorzystanie zrozumienia znaczników XML i połączenie tego z niestandardową sekwencją zatrzymania. W następnym wierszu poinstruowaliśmy Claude'a, aby załączył dane wyjściowe w Tagi XML. Następnie dodaliśmy znacznik na końcu zachęty. Dzięki temu pierwszy tekst wychodzący z Claude będzie początkiem wyniku JSON. Jeśli tego nie zrobisz, Claude często odpowiada tekstem konwersacyjnym, a następnie prawdziwą odpowiedzią w postaci kodu. Instruując Claude'a, aby natychmiast zaczął generować dane wyjściowe, możesz łatwo zatrzymać generowanie, gdy zobaczysz zamknięcie etykietka. Jest to pokazane w zaktualizowanym wywołaniu API Boto3. Korzyści z tej techniki są dwojakie. Po pierwsze, możesz dokładnie przeanalizować odpowiedź kodu od Claude'a. Po drugie, możesz obniżyć koszty, ponieważ Claude generuje tylko wyniki kodu i bez dodatkowego tekstu. Zmniejsza to koszty Amazon Bedrock, ponieważ pobierana jest opłata za każdy token wyprodukowany jako wynik ze wszystkich FM.
Używamy następującego monitu:
Człowiek: Twoim zadaniem jest pełnienie roli eksperta w zakresie potoków ETL. W szczególności Twoim zadaniem jest utworzenie reprezentacji JSON potoku ETL, która rozwiąże dostarczone żądanie użytkownika.
Dane wyjściowe JSON powinny mieć następujący format:
Oto kilka przykładów żądań użytkowników i powiązanych artefaktów wyjściowych JSON, które poprawnie rozwiązują podane zadanie. Jeśli korzystasz z tych samych baz danych, upewnij się, że używasz tej samej nomenklatury, która jest podana w przykładach.
H: zapytaj bazę danych firmy Przykładowa firma o aktywne zamówienia dla klienta nr 1234
A:
Powodem tego zapytania jest to, że klient nr 1234 jest filtrowany i przeszukujemy tabelę „zamówienia” pod kątem istniejących rekordów po „aktywnym” filtrze.
H: usuń wszystkich klientów z bazy PrzykładFirma, którzy nie byli aktywni w ostatnim miesiącu
A:
Powodem tego zapytania jest to, że tabela „ec_prod.customers” jest jedyną tabelą w bazie danych Przykładfirmy, która zawiera rekordy klientów.
Zawsze pamiętaj o dołączeniu danych wyjściowych JSON tagi.
Oto Twoje zadanie: utwórz potok wykorzystujący bazę danych PrzykładFirma, który pobierze wszystkich aktywnych klientów.
Asystent:
Używamy następującego kodu:
body = json.dumps({"prompt": prompt, "stop_sequences": ['nnHuman:', '</json>']})
response = bedrock.invoke_model(
body=body,
modelId='anthropic.claude-v2'
)Dane wyjściowe są następujące:
{ "database": "ExampleCompany", "query": "SELECT * FROM ec_prod.customers WHERE status = 'active'" }
Teraz dotarliśmy do oczekiwanego wyniku, zwracając jedynie obiekt JSON! Stosując tę metodę, jesteśmy w stanie wygenerować artefakt techniczny nadający się do natychmiastowego użycia, a także obniżyć koszt generacji poprzez redukcję żetonów wyjściowych.
Wnioski
Aby rozpocząć już dziś korzystanie ze SnapGPT, poproś o bezpłatna wersja próbna SnapLogic or poproś o demonstrację produktu. Jeśli już dziś chciałbyś wykorzystać te koncepcje do tworzenia aplikacji, to polecamy eksperymentując ręcznie z sekcją dotyczącą szybkiej inżynierii w tym poście, używając tego samego przepływu w przypadku użycia innej generacji DSL, który pasuje do Twojej firmy i zagłębiając się w Funkcje RAG dostępne za pośrednictwem Amazon Bedrock.
SnapLogic i AWS były w stanie skutecznie współpracować przy tworzeniu zaawansowanego tłumacza między językiem ludzkim a złożonym schematem potoków integracji SnapLogic obsługiwanych przez Amazon Bedrock. Podczas tej podróży widzieliśmy, jak dane wyjściowe generowane za pomocą Claude można ulepszyć w zastosowaniach zamiany tekstu na potok przy użyciu określonych technik szybkiego inżynierii. AWS i SnapLogic są podekscytowane możliwością kontynuowania partnerstwa w zakresie generatywnej sztucznej inteligencji i nie mogą się doczekać przyszłej współpracy i innowacji w tej szybko zmieniającej się przestrzeni.
O autorach
![]() Grega Bensona jest profesorem informatyki na Uniwersytecie w San Francisco i głównym naukowcem w SnapLogic. Dołączył do Wydziału Informatyki USF w 1998 roku i prowadził kursy licencjackie i magisterskie dotyczące systemów operacyjnych, architektury komputerów, języków programowania, systemów rozproszonych i programowania wprowadzającego. Greg opublikował badania w dziedzinie systemów operacyjnych, obliczeń równoległych i systemów rozproszonych. Od czasu dołączenia do SnapLogic w 2010 roku Greg pomógł zaprojektować i wdrożyć kilka kluczowych funkcji platformy, w tym przetwarzanie klastrowe, przetwarzanie dużych zbiorów danych, architekturę chmury i uczenie maszynowe. Obecnie pracuje nad Generative AI do integracji danych.
Grega Bensona jest profesorem informatyki na Uniwersytecie w San Francisco i głównym naukowcem w SnapLogic. Dołączył do Wydziału Informatyki USF w 1998 roku i prowadził kursy licencjackie i magisterskie dotyczące systemów operacyjnych, architektury komputerów, języków programowania, systemów rozproszonych i programowania wprowadzającego. Greg opublikował badania w dziedzinie systemów operacyjnych, obliczeń równoległych i systemów rozproszonych. Od czasu dołączenia do SnapLogic w 2010 roku Greg pomógł zaprojektować i wdrożyć kilka kluczowych funkcji platformy, w tym przetwarzanie klastrowe, przetwarzanie dużych zbiorów danych, architekturę chmury i uczenie maszynowe. Obecnie pracuje nad Generative AI do integracji danych.
![]() Aarona Keslera jest starszym menedżerem produktu ds. produktów i usług AI w SnapLogic. Aaron wykorzystuje ponad dziesięcioletnie doświadczenie w zarządzaniu produktami, aby być pionierem w opracowywaniu produktów AI/ML i ewangelizacji usług w całej organizacji. Jest autorem nadchodzącej książki „Jaki jest Twój problem?” którego celem jest prowadzenie nowych menedżerów produktu przez karierę menedżera produktu. Jego przygoda z przedsiębiorczością rozpoczęła się od studenckiego start-upu STAK, który później został przejęty przez Carvertise, a Aaron znacząco przyczynił się do uznania tej firmy za technologiczny start-up roku 2015 w Delaware. Poza zajęciami zawodowymi Aaron znajduje radość w grze w golfa z ojcem, odkrywaniu nowych kultur i potraw podczas podróży oraz ćwiczeniu gry na ukulele.
Aarona Keslera jest starszym menedżerem produktu ds. produktów i usług AI w SnapLogic. Aaron wykorzystuje ponad dziesięcioletnie doświadczenie w zarządzaniu produktami, aby być pionierem w opracowywaniu produktów AI/ML i ewangelizacji usług w całej organizacji. Jest autorem nadchodzącej książki „Jaki jest Twój problem?” którego celem jest prowadzenie nowych menedżerów produktu przez karierę menedżera produktu. Jego przygoda z przedsiębiorczością rozpoczęła się od studenckiego start-upu STAK, który później został przejęty przez Carvertise, a Aaron znacząco przyczynił się do uznania tej firmy za technologiczny start-up roku 2015 w Delaware. Poza zajęciami zawodowymi Aaron znajduje radość w grze w golfa z ojcem, odkrywaniu nowych kultur i potraw podczas podróży oraz ćwiczeniu gry na ukulele.
![]() Bogaty Koper jest głównym architektem rozwiązań z doświadczeniem obejmującym wiele obszarów specjalizacji. Historia sukcesów obejmująca wieloplatformowe oprogramowanie dla przedsiębiorstw i SaaS. Dobrze znany z przekształcania rzecznictwa klientów (służenia jako głos klienta) w nowe funkcje i produkty generujące przychody. Sprawdzona umiejętność wprowadzania najnowocześniejszych produktów na rynek i kończenia projektów zgodnie z harmonogramem i w ramach budżetu w dynamicznych środowiskach lądowych i morskich. Można mnie opisać w prosty sposób: umysł naukowca, serce odkrywcy i dusza artysty.
Bogaty Koper jest głównym architektem rozwiązań z doświadczeniem obejmującym wiele obszarów specjalizacji. Historia sukcesów obejmująca wieloplatformowe oprogramowanie dla przedsiębiorstw i SaaS. Dobrze znany z przekształcania rzecznictwa klientów (służenia jako głos klienta) w nowe funkcje i produkty generujące przychody. Sprawdzona umiejętność wprowadzania najnowocześniejszych produktów na rynek i kończenia projektów zgodnie z harmonogramem i w ramach budżetu w dynamicznych środowiskach lądowych i morskich. Można mnie opisać w prosty sposób: umysł naukowca, serce odkrywcy i dusza artysty.
![]() Claya Elmore'a jest architektem rozwiązań specjalistycznych AI/ML w AWS. Po spędzeniu wielu godzin w laboratorium badań materiałów jego doświadczenie w inżynierii chemicznej szybko zostało porzucone, aby zająć się uczeniem maszynowym. Pracował nad aplikacjami ML w wielu różnych branżach, od handlu energią po marketing hotelarski. Obecna praca Claya w AWS koncentruje się na pomaganiu klientom we wdrażaniu praktyk tworzenia oprogramowania do obciążeń ML i generatywnej sztucznej inteligencji, umożliwiając klientom tworzenie powtarzalnych, skalowalnych rozwiązań w tych złożonych środowiskach. W wolnym czasie Clay lubi jeździć na nartach, układać kostki Rubika, czytać i gotować.
Claya Elmore'a jest architektem rozwiązań specjalistycznych AI/ML w AWS. Po spędzeniu wielu godzin w laboratorium badań materiałów jego doświadczenie w inżynierii chemicznej szybko zostało porzucone, aby zająć się uczeniem maszynowym. Pracował nad aplikacjami ML w wielu różnych branżach, od handlu energią po marketing hotelarski. Obecna praca Claya w AWS koncentruje się na pomaganiu klientom we wdrażaniu praktyk tworzenia oprogramowania do obciążeń ML i generatywnej sztucznej inteligencji, umożliwiając klientom tworzenie powtarzalnych, skalowalnych rozwiązań w tych złożonych środowiskach. W wolnym czasie Clay lubi jeździć na nartach, układać kostki Rubika, czytać i gotować.
![]() Sinę Sojoodi jest dyrektorem ds. technologii, inżynierem systemów, liderem produktu, byłym założycielem i doradcą startupów. Dołączył do AWS w marcu 2021 roku jako główny architekt rozwiązań. Sina jest obecnie głównym architektem rozwiązań ISV na obszarze USA-Zachód. Współpracuje z firmami zajmującymi się oprogramowaniem SaaS i B2B, aby budować i rozwijać ich biznesy na platformie AWS. Przed objęciem stanowiska w Amazon Sina był dyrektorem ds. technologii w VMware i Pivotal Software (IPO w 2018 r., fuzje i przejęcia VMware w 2020 r.) oraz pełnił wiele funkcji kierowniczych, w tym inżyniera założyciela w Xtreme Labs (przejęcie Pivotal w 2013 r.). Sina poświęcił ostatnie 15 lat swojego doświadczenia zawodowego na budowanie platform oprogramowania i praktyk dla przedsiębiorstw, firm zajmujących się oprogramowaniem i sektora publicznego. Jest liderem branży z pasją do innowacji. Sina posiada tytuł licencjata uzyskany na Uniwersytecie Waterloo, gdzie studiował elektrotechnikę i psychologię.
Sinę Sojoodi jest dyrektorem ds. technologii, inżynierem systemów, liderem produktu, byłym założycielem i doradcą startupów. Dołączył do AWS w marcu 2021 roku jako główny architekt rozwiązań. Sina jest obecnie głównym architektem rozwiązań ISV na obszarze USA-Zachód. Współpracuje z firmami zajmującymi się oprogramowaniem SaaS i B2B, aby budować i rozwijać ich biznesy na platformie AWS. Przed objęciem stanowiska w Amazon Sina był dyrektorem ds. technologii w VMware i Pivotal Software (IPO w 2018 r., fuzje i przejęcia VMware w 2020 r.) oraz pełnił wiele funkcji kierowniczych, w tym inżyniera założyciela w Xtreme Labs (przejęcie Pivotal w 2013 r.). Sina poświęcił ostatnie 15 lat swojego doświadczenia zawodowego na budowanie platform oprogramowania i praktyk dla przedsiębiorstw, firm zajmujących się oprogramowaniem i sektora publicznego. Jest liderem branży z pasją do innowacji. Sina posiada tytuł licencjata uzyskany na Uniwersytecie Waterloo, gdzie studiował elektrotechnikę i psychologię.
![]() Sandeep Rohilla jest starszym architektem rozwiązań w AWS i wspiera klientów niezależnych dostawców oprogramowania w zachodnim regionie Stanów Zjednoczonych. Koncentruje się na pomaganiu klientom w projektowaniu rozwiązań wykorzystujących kontenery i generatywną sztuczną inteligencję w chmurze AWS. Sandeep pasjonuje się zrozumieniem problemów biznesowych klientów i pomaganiem im w osiąganiu celów za pomocą technologii. Dołączył do AWS po ponad dziesięciu latach pracy jako architekt rozwiązań, wykorzystując swoje 17-letnie doświadczenie. Sandeep posiada tytuł magistra. uzyskał tytuł inżyniera oprogramowania na Uniwersytecie Zachodniej Anglii w Bristolu w Wielkiej Brytanii.
Sandeep Rohilla jest starszym architektem rozwiązań w AWS i wspiera klientów niezależnych dostawców oprogramowania w zachodnim regionie Stanów Zjednoczonych. Koncentruje się na pomaganiu klientom w projektowaniu rozwiązań wykorzystujących kontenery i generatywną sztuczną inteligencję w chmurze AWS. Sandeep pasjonuje się zrozumieniem problemów biznesowych klientów i pomaganiem im w osiąganiu celów za pomocą technologii. Dołączył do AWS po ponad dziesięciu latach pracy jako architekt rozwiązań, wykorzystując swoje 17-letnie doświadczenie. Sandeep posiada tytuł magistra. uzyskał tytuł inżyniera oprogramowania na Uniwersytecie Zachodniej Anglii w Bristolu w Wielkiej Brytanii.
![]() Doktor Farooq Sabir jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego w AWS. Posiada tytuł doktora i magistra inżynierii elektrycznej uzyskany na University of Texas w Austin oraz tytuł magistra informatyki uzyskany na Georgia Institute of Technology. Ma ponad 15-letnie doświadczenie zawodowe, a także lubi uczyć i mentorować studentów. W AWS pomaga klientom formułować i rozwiązywać ich problemy biznesowe w zakresie nauki o danych, uczenia maszynowego, wizji komputerowej, sztucznej inteligencji, optymalizacji numerycznej i pokrewnych dziedzin. Mieszka w Dallas w Teksasie i wraz z rodziną uwielbia podróżować i wyruszać w długie podróże.
Doktor Farooq Sabir jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego w AWS. Posiada tytuł doktora i magistra inżynierii elektrycznej uzyskany na University of Texas w Austin oraz tytuł magistra informatyki uzyskany na Georgia Institute of Technology. Ma ponad 15-letnie doświadczenie zawodowe, a także lubi uczyć i mentorować studentów. W AWS pomaga klientom formułować i rozwiązywać ich problemy biznesowe w zakresie nauki o danych, uczenia maszynowego, wizji komputerowej, sztucznej inteligencji, optymalizacji numerycznej i pokrewnych dziedzin. Mieszka w Dallas w Teksasie i wraz z rodziną uwielbia podróżować i wyruszać w długie podróże.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/how-snaplogic-built-a-text-to-pipeline-application-with-amazon-bedrock-to-translate-business-intent-into-action/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 10
- 100
- 121
- 14
- 15 roku
- 15%
- 150
- 17
- 1998
- 200
- 2010
- 2013
- 2015
- 2017
- 2018
- 2020
- 2021
- 31
- 33
- 7
- 8
- 9
- a
- Aaron
- zdolność
- Zdolny
- O nas
- dostęp
- wykonać
- precyzja
- Osiągać
- nabyty
- nabycie
- w poprzek
- działać
- Działania
- działania
- aktywny
- w dodatku
- dodatek
- Dodatkowy
- zaawansowany
- Korzyść
- doradca
- rzecznictwo
- Po
- AI
- Systemy SI
- Zasilany AI
- AI / ML
- wymierzony
- Cele
- Algorytmy
- Wszystkie kategorie
- dozwolony
- Pozwalać
- pozwala
- wzdłuż
- wzdłuż
- już
- również
- Amazonka
- Amazon Web Services
- ilość
- an
- Analizując
- i
- odpowiedź
- odpowiedzi
- Antropiczny
- każdy
- api
- Pszczoła
- Zastosowanie
- aplikacje
- dotyczy
- podejście
- mobilne i webowe
- arabski
- architektura
- SĄ
- POWIERZCHNIA
- obszary
- na około
- przybył
- Sztuka
- sztuczny
- sztuczna inteligencja
- Sztuczna inteligencja i uczenie maszynowe
- artysta
- AS
- zapytać
- pytanie
- Asystent
- powiązany
- At
- zwiększona
- Austin
- autor
- zautomatyzować
- zautomatyzowane
- automatycznie
- Automatyzacja
- dostępny
- AWS
- Klient AWS
- B2B
- tło
- poparcie
- baza
- na podstawie
- Baseline
- BE
- Niedźwiedź
- stał
- bo
- stają się
- być
- zanim
- rozpoczął
- rozpocząć
- za
- jest
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- Duży
- Big Data
- książka
- obie
- przynieść
- Bringing
- Przynosi
- bristol
- szeroki
- szeroko
- budżet
- budować
- Budowanie
- Buduje
- wybudowany
- biznes
- wpływ na biznes
- biznes
- ale
- by
- wezwanie
- nazywa
- CAN
- możliwości
- Kariera
- walizka
- Etui
- Centra
- łańcuch
- wyzwanie
- szansa
- Charakterystyka
- naładowany
- chemiczny
- szef
- wybór
- jasny
- dokładnie
- zamknięcie
- Chmura
- Grupa
- kod
- Kodowanie
- współpracował
- współpraca
- kolekcja
- Studentki
- połączyć
- połączony
- byliśmy spójni, od początku
- zobowiązanie
- Firmy
- Firma
- zmuszony
- ukończenia
- kompleks
- wszechstronny
- komputer
- Computer Science
- Wizja komputerowa
- computing
- Koncepcje
- konfigurowanie
- Podłączanie
- połączenie
- połączenia
- konsekwentnie
- Pojemniki
- zawiera
- zawartość
- Tworzenie treści
- kontekst
- kontynuować
- umowa
- przyczyniając
- konwersacyjny
- gotowanie
- rdzeń
- skorygowania
- prawidłowo
- Koszty:
- mógłby
- kursy
- Stwórz
- stworzony
- tworzenie
- kreatywność
- krytyczny
- Aktualny
- Obecnie
- zwyczaj
- klient
- Klientów
- tnący
- pionierski nowatorski
- Dallas
- dane
- integracja danych
- analiza danych
- nauka danych
- Baza danych
- Bazy danych
- Dni
- dekada
- spadek
- dedykowane
- głęboko
- głębiej
- Delaware
- Demo
- Demokratyzować
- Departament
- pochodna
- opisać
- opis
- Wnętrze
- zaprojektowany
- pragnienie
- życzenia
- szczegółowe
- detale
- deweloperzy
- oprogramowania
- urządzenia
- Dialog
- różne
- bezpośrednio
- dystrybuowane
- systemy rozproszone
- nurkowanie
- do
- dokumenty
- Nie
- robi
- domeny
- nie
- na dół
- projekt
- drastycznie
- napęd
- z powodu
- każdy
- łatwiej
- Najprostszym
- z łatwością
- Ekosystem
- faktycznie
- bądź
- Inżynieria elektryczna
- Elementy
- Umożliwia
- zakończenia
- kończący się
- energia
- inżynier
- Inżynieria
- Anglia
- Angielski
- wzmocnienie
- dość
- zapewnić
- zapewnia
- Wchodzę
- Enterprise
- oprogramowanie firmowe
- Enterprise Solutions
- przedsiębiorstwa
- Cały
- całkowicie
- przedsiębiorczy
- środowiska
- równy
- Równoważny
- błąd
- szczególnie
- Eter (ETH)
- Parzyste
- oczywisty
- dokładnie
- przykład
- przykłady
- przewyższać
- podniecony
- wykonawczy
- Przede wszystkim system został opracowany
- spodziewany
- oczekując
- doświadczenie
- ekspert
- ekspertyza
- badacz
- Exploring
- dodatkowy
- niezwykle
- członków Twojej rodziny
- Szybki ruch
- w szybkim tempie
- Cecha
- Korzyści
- kilka
- pole
- Łąka
- filtrować
- filtracja
- filtry
- znajduje
- i terminów, a
- flagowy
- pływ
- Przepływy
- Skupiać
- koncentruje
- skupienie
- obserwuj
- następujący
- następujący sposób
- żywność
- W razie zamówieenia projektu
- Najazd
- czoło
- format
- formularze
- Naprzód
- znaleziono
- Fundacja
- założenie
- Francisco
- przyjazny
- od
- Spełnić
- w pełni
- funkcjonować
- dalej
- przyszłość
- zdobyte
- ogólnie
- Generować
- wygenerowane
- generuje
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- Georgia Institute of Technology
- otrzymać
- gif
- dany
- Go
- Gole
- Goes
- dobry
- absolwent
- Rosnąć
- poprowadzi
- miał
- ręka
- Wykorzystywanie
- Have
- he
- Serce
- pomoc
- pomógł
- pomocny
- pomoc
- pomaga
- tutaj
- wydajny
- wysokiej jakości
- pasemka
- jego
- przytrzymaj
- posiada
- gościnność
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- człowiek
- pokorny
- zidentyfikowane
- if
- zilustrować
- natychmiast
- Rezultat
- wpływowy
- wdrożenia
- ważny
- podnieść
- ulepszony
- poprawy
- in
- zawierać
- włączony
- Włącznie z
- Zwiększać
- niezależny
- wskazuje
- wskaźniki
- indywidualny
- przemysłowa
- przemysł
- lider w branży przemysłowej
- Informacja
- wrodzony
- innowacyjne
- Innowacja
- wkład
- Wejścia
- natychmiastowy
- zamiast
- Instytut
- instrukcje
- zintegrowany
- integracja
- integracje
- Inteligencja
- Inteligentny
- zamiar
- Interakcje
- interaktywne
- odsetki
- Interfejs
- wewnętrzny
- najnowszych
- wprowadzono
- Przedstawia
- wprowadzający
- IPO
- isv
- IT
- iteracja
- iteracje
- JEGO
- Java
- Praca
- Dołączył
- łączący
- połączenie
- podróż
- radość
- jpg
- json
- właśnie
- Klawisz
- Wiedzieć
- wiedza
- znany
- wie
- laboratorium
- Labs
- język
- Języki
- duży
- Nazwisko
- później
- firmy
- prowadzić
- lider
- Przywództwo
- prowadzący
- Skakać
- dowiedziałem
- nauka
- lewo
- niech
- lewarowanie
- lubić
- lubi
- logika
- długo
- Popatrz
- Partia
- miłość
- MAMA
- maszyna
- uczenie maszynowe
- maszyny
- zrobiony
- robić
- WYKONUJE
- Dokonywanie
- zarządzane
- i konserwacjami
- kierownik
- Zarządzający
- sposób
- ręcznie
- wiele
- mapowanie
- March
- rynek
- Marketing
- zapałki
- materiały
- me
- mentor
- sam
- Metadane
- metoda
- miliony
- nic
- minuty
- Misja
- ML
- model
- modele
- MongoDB
- jeszcze
- większość
- ruch
- MS
- Wieloplatformowy
- wielokrotność
- my
- Nazwa
- Naturalny
- Język naturalny
- Potrzebować
- wymagania
- Nowości
- Nowe funkcje
- nowy produkt
- Następny
- Nie
- noty
- laptopy
- Zauważyć..
- już dziś
- przedmiot
- obiekty
- miejsce
- of
- Oferty
- często
- on
- pewnego razu
- ONE
- tylko
- operacyjny
- system operacyjny
- optymalizacja
- optymalizacji
- or
- zamówienie
- Zlecenia
- organizacja
- organizacji
- oryginalny
- Inne
- ludzkiej,
- na zewnątrz
- Wynik
- wydajność
- Wyjścia
- koniec
- stron
- Parallel
- szczególnie
- partnerem
- Współpraca
- pasja
- namiętny
- Przeszłość
- Wzór
- wykonuje
- perspektywa
- faza
- PhD
- sztuk
- pionier
- rurociąg
- kluczowy
- Miejsce
- Platforma
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Popularny
- popularność
- Post
- potencjał
- potencjalnie
- power
- powered
- praktyka
- praktyki
- przewidzieć
- Przewiduje
- poprzedni
- pierwotny
- Główny
- prywatność
- Prywatność i bezpieczeństwo
- Problem
- problemy
- procedura
- wygląda tak
- procesów
- przetwarzanie
- Wytworzony
- produkuje
- Produkt
- rozwój produktów
- zarządzanie produktem
- product manager
- Produkty
- Produkty i usługi
- profesjonalny
- Profesor
- Programowanie
- języki programowania
- projektowanie
- monity
- Sprawdzony
- zapewniać
- pod warunkiem,
- zapewnia
- że
- Psychologia
- publiczny
- opublikowany
- Opublikowane badania
- kontynuować
- Python
- zapytania
- pytanie
- szybko
- przypadkowy
- przypadkowość
- zasięg
- nośny
- szybki
- Czytający
- zrealizować
- królestwo
- otrzymać
- niedawno
- uznanie
- polecić
- rekord
- dokumentacja
- zmniejszyć
- zmniejsza
- redukcja
- w sprawie
- region
- reimagining
- związane z
- wydany
- rzetelny
- polegać
- pamiętać
- usunąć
- renderowane
- powtarzalne
- odpowiedzieć
- reprezentacja
- reprezentowanie
- reprezentuje
- zażądać
- wywołań
- wymagać
- wymagany
- wymagania
- Wymaga
- Badania naukowe
- odpowiedź
- Odpowiedzi
- REST
- wynikły
- Efekt
- powrót
- powraca
- zrewolucjonizować
- Bogaty
- prawo
- droga
- Rola
- role
- Pokój
- run
- działa
- SaaS
- Bezpieczeństwo
- sagemaker
- Powiedział
- taki sam
- San
- San Francisco
- Scala
- skalowalny
- Skala
- rozkład
- nauka
- Naukowiec
- zadraśnięcie
- Sdk
- poszukiwania
- druga
- Sekcja
- sektor
- bezpieczeństwo
- widzieć
- widziany
- wybierać
- wysyłanie
- senior
- wysłany
- Sekwencja
- służył
- usługa
- Usługi
- służąc
- Sesje
- zestaw
- ustawienie
- kilka
- powinien
- pokazać
- pokazane
- Targi
- znacznie
- podobny
- Prosty
- upraszczać
- upraszczanie
- po prostu
- ponieważ
- pojedynczy
- mały
- So
- Tworzenie
- Oprogramowanie jako usługa
- Software Developers
- rozwoju oprogramowania
- Inżynieria oprogramowania
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Rozwiązywanie
- kilka
- Ktoś
- wyrafinowany
- Dusza
- Źródło
- Typ przestrzeni
- hiszpański
- napięcie
- specjalista
- specyficzny
- swoiście
- określony
- wydać
- Spędzanie
- SQL
- początek
- rozpoczęty
- startup
- Zestawienie sprzedaży
- Rynek
- Ewolucja krok po kroku
- Cel
- Stop
- bezpośredni
- Struktura
- Studenci
- Studiował
- sukces
- Wspierający
- podpory
- domniemany
- pewnie
- system
- systemy
- stół
- TAG
- Brać
- cel
- Zadanie
- zadania
- nauczony
- zespół
- Zespoły
- tech
- uruchomienie technologiczne
- Techniczny
- technika
- Techniki
- Technologia
- powiedzieć
- dziesięć
- texas
- XNUMX
- niż
- że
- Połączenia
- Zachód
- świat
- ich
- Im
- następnie
- Te
- one
- rzeczy
- myśleć
- to
- tych
- Przez
- poprzez
- czas
- do
- już dziś
- żeton
- Żetony
- powiedział
- wziął
- narzędzie
- wyśledzić
- śledzić
- Handel
- tradycyjnie
- Trening
- transformacyjny
- transformacje
- tłumaczyć
- podróżować
- podróże
- trendy
- próba
- wyzwalać
- wyzwalanie
- prawdziwy
- Prawdziwy kod
- stara
- Obrócenie
- rodzaj
- ui
- Uk
- dla
- zrozumieć
- zrozumienie
- rozumie
- wyjątkowy
- uniwersytet
- aż do
- odsłonięty
- zbliżających
- zaktualizowane
- na
- us
- nadający się do użytku
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Doświadczenie użytkownika
- Użytkownicy
- zastosowania
- za pomocą
- zazwyczaj
- ux
- różnorodny
- sprzedawców
- początku.
- przez
- wizja
- wizualny
- vmware
- Głos
- chcieć
- była
- Droga..
- we
- sieć
- usługi internetowe
- tygodni
- DOBRZE
- były
- Zachód
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- który
- szeroki
- Szeroki zasięg
- będzie
- okno
- w
- bez
- Praca
- pracował
- workflow
- przepływów pracy
- pracujący
- działa
- świat
- świat
- by
- napisać
- XML
- rok
- lat
- ty
- Twój
- youtube
- zefirnet