Zdjęcie autora
Gdy zaczynasz korzystać z uczenia maszynowego, regresja logistyczna jest jednym z pierwszych algorytmów, które dodasz do swojego zestawu narzędzi. Jest to prosty i solidny algorytm, powszechnie używany do zadań klasyfikacji binarnej.
Rozważmy problem klasyfikacji binarnej z klasami 0 i 1. Regresja logistyczna dopasowuje funkcję logistyczną lub sigmoidalną do danych wejściowych i przewiduje prawdopodobieństwo, że punkt danych zapytania będzie należał do klasy 1. Ciekawe, prawda?
W tym samouczku nauczymy się od podstaw regresji logistycznej, obejmując:
- Funkcja logistyczna (lub sigmoidalna).
- Jak przechodzimy od regresji liniowej do regresji logistycznej
- Jak działa regresja logistyczna
Na koniec zbudujemy prosty model regresji logistycznej klasyfikować sygnały radarowe z jonosfery.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

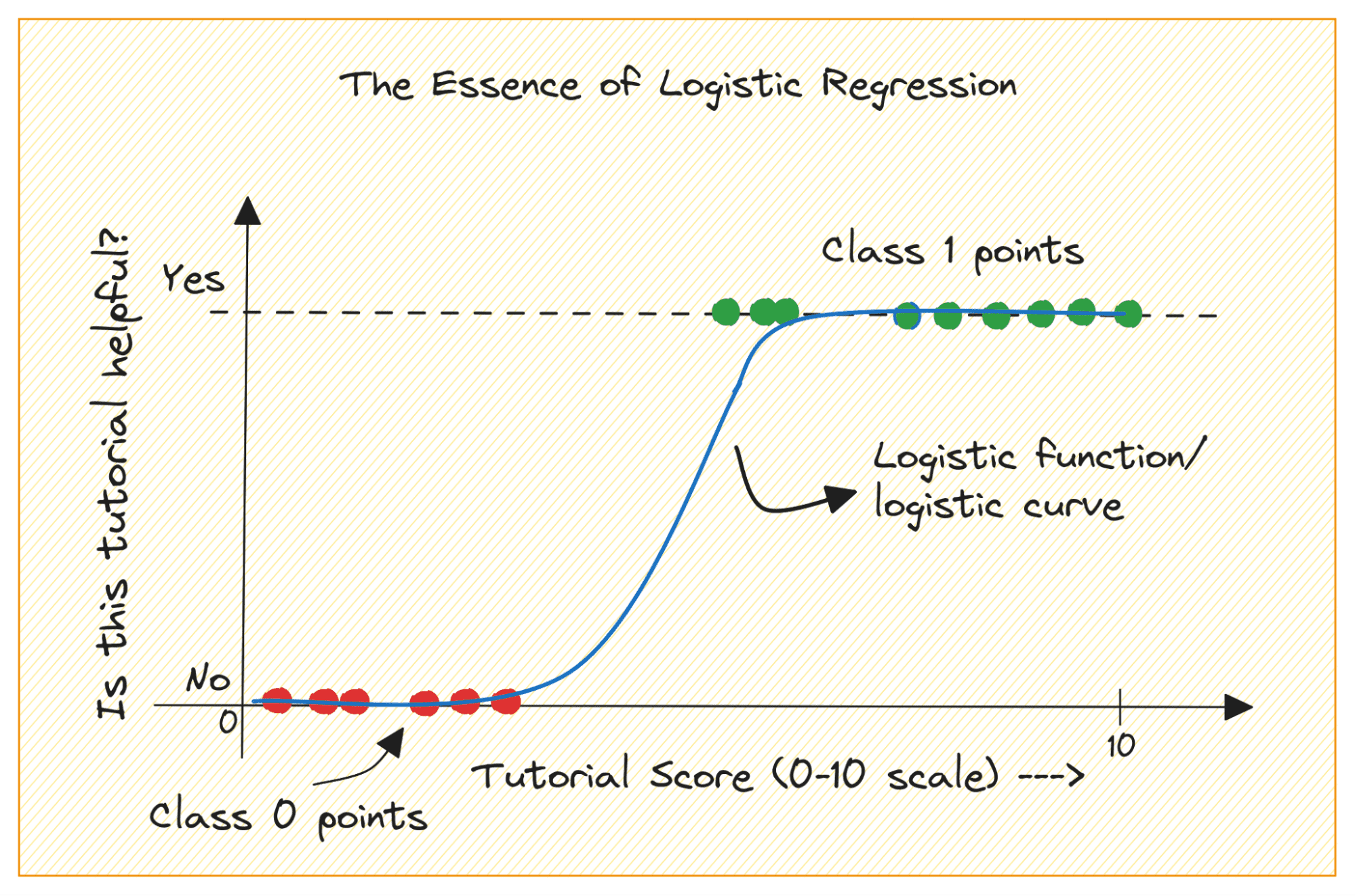
Kiedy narysujesz funkcję sigmoidalną, będzie ona wyglądać następująco:
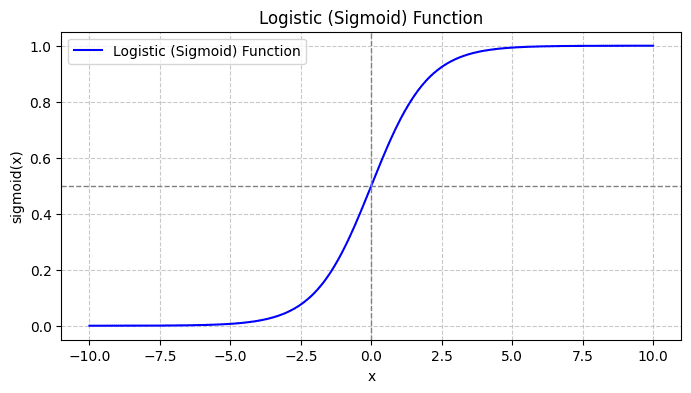
Z fabuły widzimy, że:
- Gdy x = 0, σ(x) przyjmuje wartość 0.5.
- Kiedy x zbliża się do +∞, σ(x) zbliża się do 1.
- Kiedy x zbliża się do -∞, σ(x) zbliża się do 0.
Zatem dla wszystkich rzeczywistych danych wejściowych funkcja sigmoidalna zgniata je, aby przyjąć wartości z zakresu [0, 1].
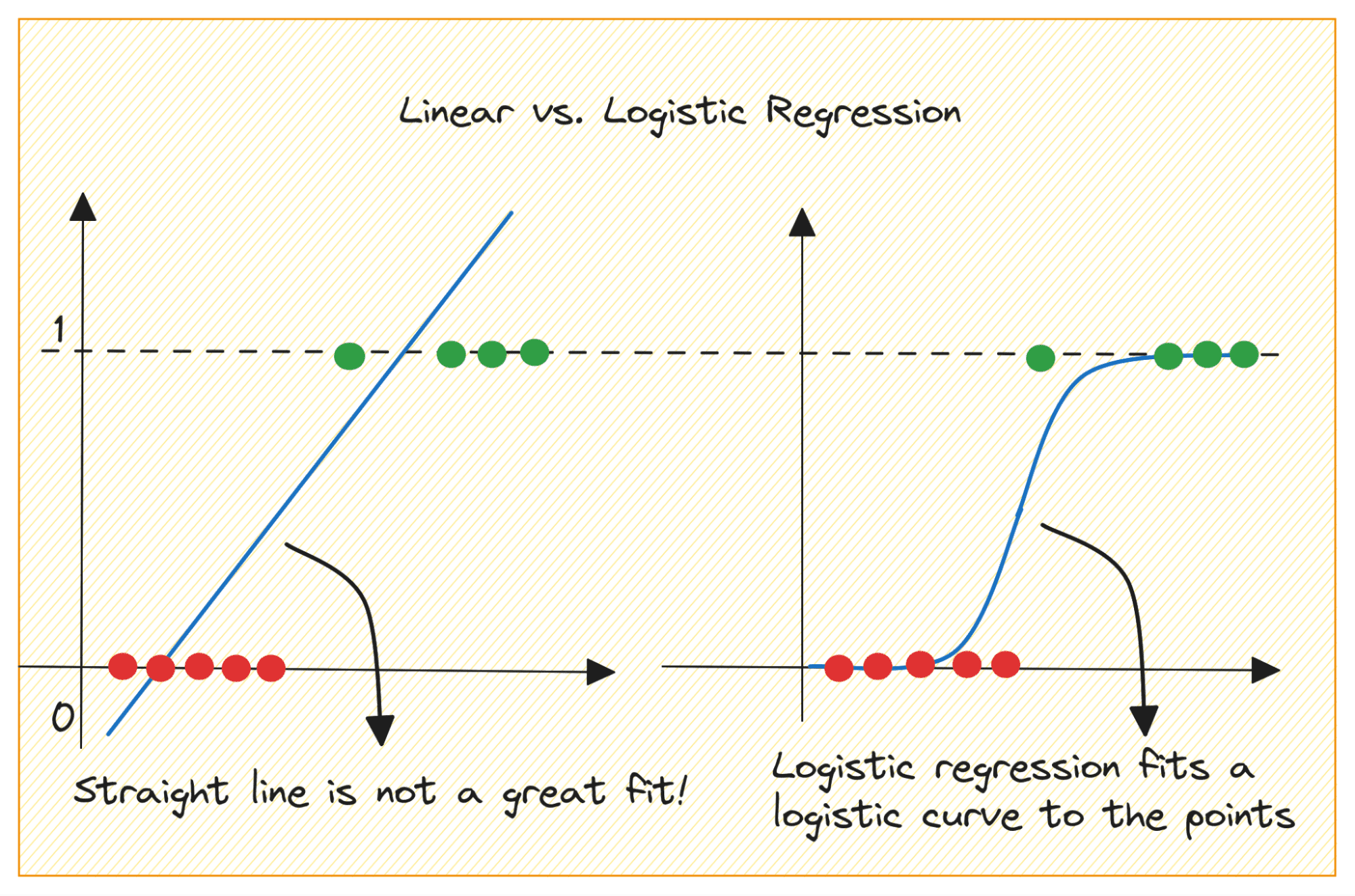
Omówmy najpierw, dlaczego nie możemy zastosować regresji liniowej w przypadku problemu klasyfikacji binarnej.
In a binary classification problem, the output is categorical label (0 or 1). Because linear regression predicts continuous-valued outputs which can be less than 0 or greater than 1, it does not make sense for the problem at hand.
Ponadto linia prosta może nie być najlepszym rozwiązaniem, jeśli etykiety wyjściowe należą do jednej z dwóch kategorii.
Zdjęcie autora
Jak zatem przejść od regresji liniowej do regresji logistycznej? W regresji liniowej przewidywany wynik jest określony wzorem:
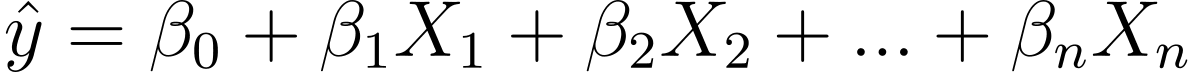
Gdzie βs to współczynniki, a X_is to predyktory (lub cechy).
Bez utraty ogólności załóżmy, że X_0 = 1:

Możemy więc zastosować bardziej zwięzłe wyrażenie:
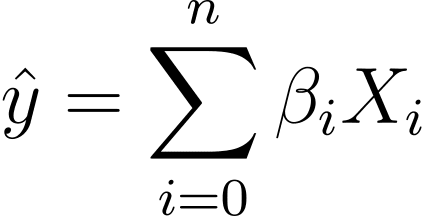
In logistic regression, we need the predicted probability p_i in the [0,1] interval. We know that the logistic function squishes inputs so that they take on values in the [0,1] interval.
Zatem podstawiając to wyrażenie do funkcji logistycznej, mamy przewidywane prawdopodobieństwo jako:
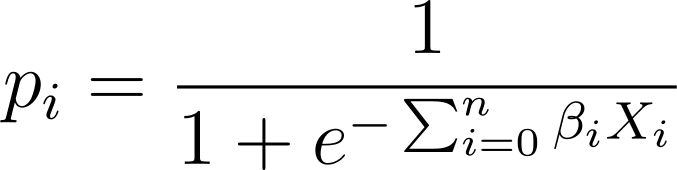
Jak zatem znaleźć najlepiej dopasowaną krzywą logistyczną dla danego zbioru danych? Aby odpowiedzieć na to pytanie, przyjrzyjmy się estymacji największej wiarygodności.
Oszacowanie maksymalnego prawdopodobieństwa (MLE) służy do estymacji parametrów modelu regresji logistycznej poprzez maksymalizację funkcji wiarygodności. Rozłóżmy proces MLE w regresji logistycznej i jak formułuje się funkcję kosztu w celu optymalizacji przy użyciu opadania gradientu.
Podział oszacowania maksymalnego prawdopodobieństwa
Jak już wspomniano, modelujemy prawdopodobieństwo wystąpienia wyniku binarnego jako funkcję jednej lub większej liczby zmiennych predykcyjnych (lub cech):
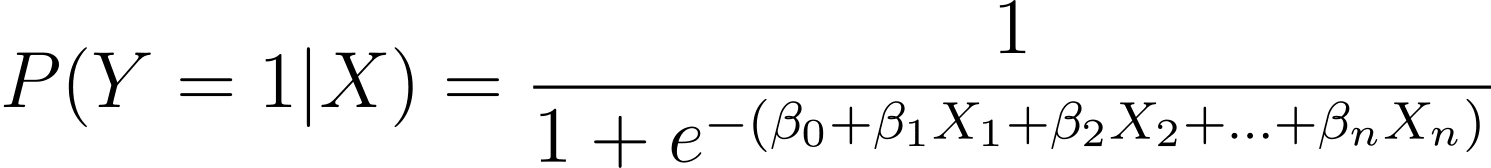
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
Celem MLE jest znalezienie wartości β, które maksymalizują prawdopodobieństwo zaobserwowanych danych. Funkcja wiarygodności, oznaczona jako L(β), reprezentuje prawdopodobieństwo zaobserwowania danych wyników dla danych wartości predyktorów w modelu regresji logistycznej.
Formułowanie funkcji logarytmicznej wiarygodności
Aby uprościć proces optymalizacji, często korzysta się z funkcji logarytmicznej wiarygodności. Ponieważ przekształca iloczyny prawdopodobieństw na sumy logarytmów prawdopodobieństw.
Funkcję logarytmiczną wiarygodności dla regresji logistycznej podaje wzór:
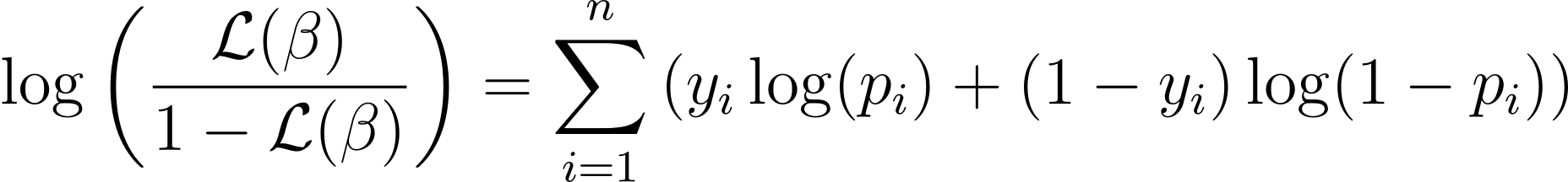
Teraz, gdy znamy istotę logarytmu wiarygodności, przejdźmy do formułowania funkcji kosztu dla regresji logistycznej, a następnie opadania gradientowego w celu znalezienia najlepszych parametrów modelu
Funkcja kosztu dla regresji logistycznej
Aby zoptymalizować model regresji logistycznej, musimy zmaksymalizować logarytm wiarygodności. Możemy więc użyć ujemnego logarytmu wiarygodności jako funkcji kosztu, którą minimalizujemy podczas uczenia. Ujemny log wiarygodności, często nazywany stratą logistyczną, definiuje się jako:
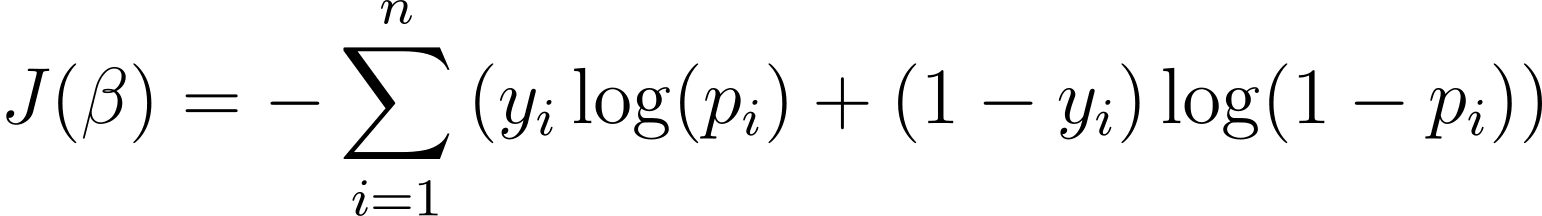
Celem algorytmu uczenia się jest zatem znalezienie wartości ? które minimalizują tę funkcję kosztu. Zejście gradientowe jest powszechnie używanym algorytmem optymalizacyjnym do znajdowania minimum tej funkcji kosztu.
Zejście gradientowe w regresji logistycznej
Spadek gradientu jest iteracyjnym algorytmem optymalizacji, który aktualizuje parametry modelu β w kierunku przeciwnym do gradientu funkcji kosztu względem β. Reguła aktualizacji w kroku t+1 dla regresji logistycznej z wykorzystaniem opadania gradientowego jest następująca:
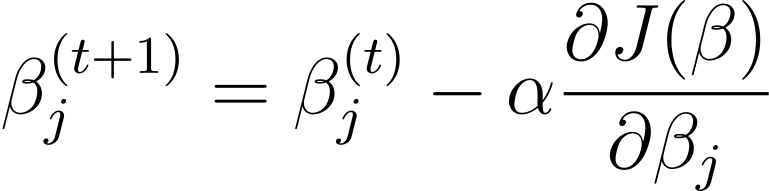
Gdzie α jest szybkością uczenia się.
Pochodne cząstkowe można obliczyć za pomocą reguły łańcuchowej. Zniżanie gradientowe iteracyjnie aktualizuje parametry aż do osiągnięcia zbieżności, mając na celu zminimalizowanie strat logistycznych. W miarę zbieżności znajduje optymalne wartości β, które maksymalizują prawdopodobieństwo zaobserwowanych danych.
Teraz, gdy wiesz, jak działa regresja logistyczna, zbudujmy model predykcyjny, korzystając z biblioteki scikit-learn.
Użyjemy zbiór danych jonosfery z repozytorium uczenia maszynowego UCI dla tego samouczka. Zbiór danych składa się z 34 cech numerycznych. Dane wyjściowe są binarne, „dobre” lub „złe” (oznaczone jako „g” lub „b”). Etykieta wyjściowa „dobry” odnosi się do sygnałów RADARowych, które wykryły pewną strukturę w jonosferze.
Krok 1 – Ładowanie zbioru danych
Najpierw pobierz zestaw danych i wczytaj go do ramki danych pandy:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Krok 2 – Eksploracja zbioru danych
Przyjrzyjmy się kilku pierwszym wierszom ramki danych:
# Display the first few rows of the DataFrame
df.head()
Obcięte wyjście df.head()
Zdobądźmy trochę informacji o zbiorze danych: liczbie wartości innych niż null i typach danych każdej z kolumn:
# Get information about the dataset
print(df.info())
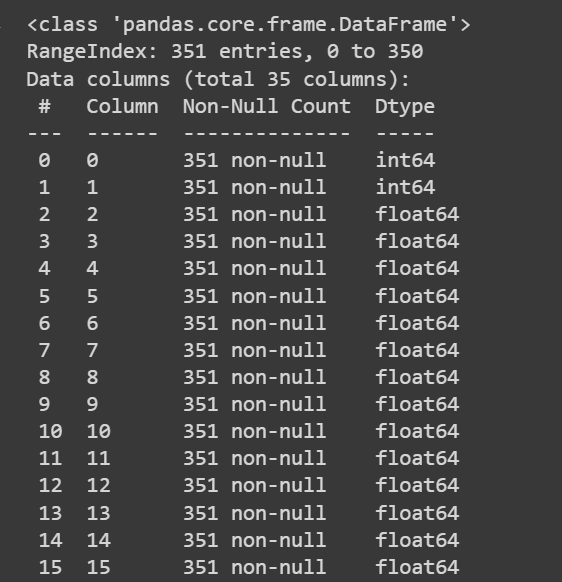 Obcięte wyjście df.info()
Obcięte wyjście df.info()
Ponieważ mamy wszystkie funkcje numeryczne, możemy również uzyskać statystyki opisowe za pomocą describe() metoda na ramce danych:
# Get descriptive statistics of the dataset
print(df.describe())
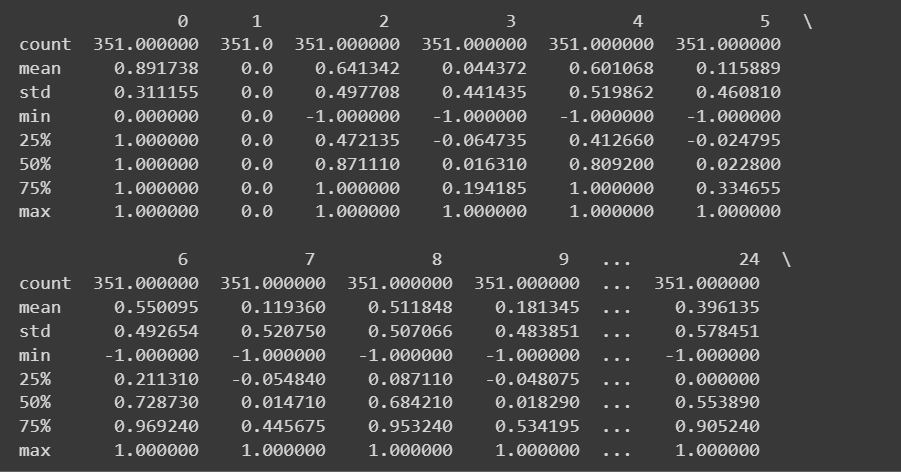
Obcięte wyjście df.describe()
Nazwy kolumn mają obecnie wartość od 0 do 34 — łącznie z etykietą. Ponieważ zbiór danych nie zapewnia opisowych nazw kolumn, odnosi się do nich po prostu jako atrybut_1 do atrybut_34, jeśli chcesz zmienić nazwy kolumn ramki danych, jak pokazano:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Uwaga: ten krok jest całkowicie opcjonalny. Jeśli wolisz, możesz kontynuować z domyślnymi nazwami kolumn.
# Display the first few rows of the DataFrame
df.head()
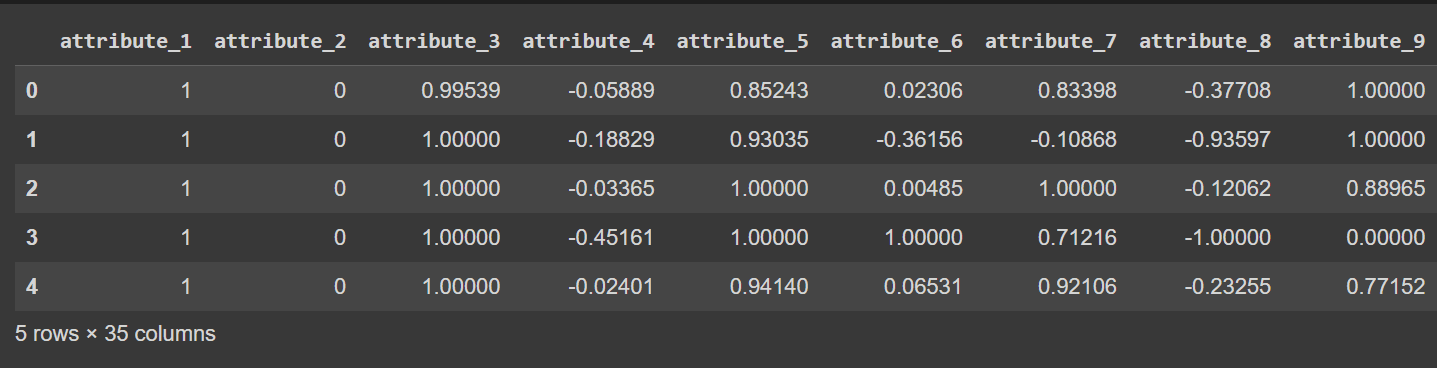
Obcięte wyjście df.head() [po zmianie nazwy kolumn]
Krok 3 – Zmiana nazw etykiet klas i wizualizacja rozkładu klas
Ponieważ etykietami klas wyjściowych są „g” i „b”, musimy zmapować je odpowiednio na 1 i 0 . Można to zrobić za pomocą map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Zwizualizujmy także rozkład etykiet klas:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
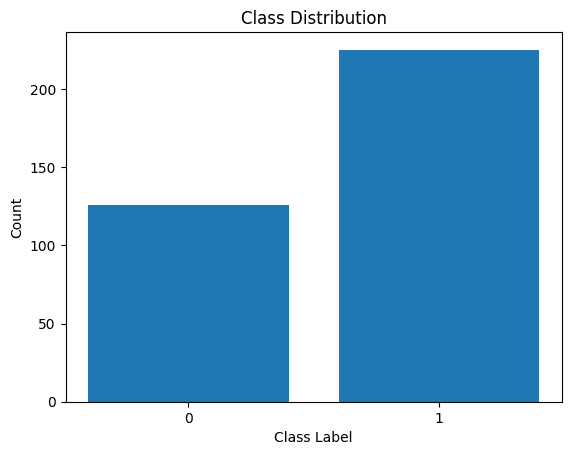
Dystrybucja etykiet klasowych
Widzimy, że istnieje nierównowaga w dystrybucji. Jest więcej rekordów należących do klasy 1 niż do klasy 0. Tą nierównowagą klas zajmiemy się podczas budowania modelu regresji logistycznej.
Krok 5 – Wstępne przetwarzanie zbioru danych
Zbierzmy funkcje i etykiety wyjściowe w następujący sposób:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Po podzieleniu zbioru danych na zbiory pociągowe i testowe musimy wstępnie przetworzyć zbiór danych.
Gdy istnieje wiele cech numerycznych — każda w potencjalnie innej skali — musimy je wstępnie przetworzyć. Powszechną metodą jest przekształcanie ich w taki sposób, aby odpowiadały rozkładowi o zerowej średniej i jednostkowej wariancji.
Połączenia StandardScaler z modułu przetwarzania wstępnego scikit-learn pomaga nam to osiągnąć.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Krok 6 – Budowa modelu regresji logistycznej
Teraz możemy utworzyć instancję klasyfikatora regresji logistycznej. The LogisticRegression class jest częścią modułu linear_model scikit-learn.
Zauważ, że ustawiliśmy class_weight parameter to ‘balanced’. This will help us account for the class imbalance. By assigning weights to each class—inversely proportional to the number of records in the classes.
Po utworzeniu instancji klasy możemy dopasować model do zbioru danych szkoleniowych:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Krok 7 – Ocena modelu regresji logistycznej
Możesz zadzwonić predict() metoda uzyskania przewidywań modelu.
Oprócz wyniku dokładności możemy również uzyskać raport klasyfikacyjny z takimi wskaźnikami, jak precyzja, zapamiętywanie i wynik F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
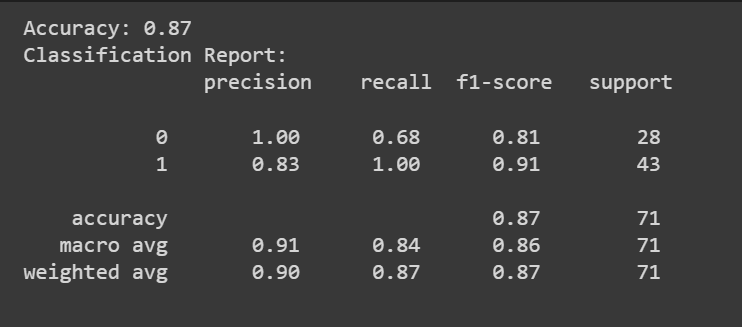
Gratulacje, zakodowałeś swój pierwszy model regresji logistycznej!
W tym samouczku szczegółowo poznaliśmy regresję logistyczną: od teorii i matematyki po kodowanie klasyfikatora regresji logistycznej.
As a next step, try building a logistic regression model for a suitable dataset of your choice.
Zbiór danych Jonosfery jest objęty licencją na podstawie a Creative Commons Uznanie autorstwa 4.0 Międzynarodowy (CC BY 4.0) licencja:
Sigillito, V., Wing, S., Hutton, L. i Baker, K.. (1989). Jonosfera. Repozytorium uczenia maszynowego UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C jest deweloperem i pisarzem technicznym z Indii. Lubi pracować na styku matematyki, programowania, data science i tworzenia treści. Jej obszary zainteresowań i wiedzy obejmują DevOps, data science i przetwarzanie języka naturalnego. Lubi czytać, pisać, kodować i kawę! Obecnie pracuje nad zdobywaniem wiedzy i dzieleniem się nią ze społecznością programistów, tworząc samouczki, poradniki, opinie i nie tylko.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :Jest
- :nie
- $W GÓRĘ
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- O nas
- Konto
- precyzja
- Osiągać
- Dodaj
- dodatek
- Po
- Cele
- algorytm
- Algorytmy
- Wszystkie kategorie
- również
- an
- i
- odpowiedź
- awanse
- SĄ
- obszary
- AS
- założyć
- At
- autoring
- b
- piekarz
- zrównoważony
- bar
- BE
- bo
- należący
- BEST
- przerwa
- budować
- Budowanie
- by
- wezwanie
- CAN
- nie może
- kategorie
- łańcuch
- wybór
- klasa
- Klasy
- klasyfikacja
- kodowane
- Kodowanie
- zbierać
- Kolumna
- kolumny
- wspólny
- powszechnie
- Lud
- społeczność
- zawiera
- zwięzły
- zawartość
- Tworzenie treści
- konwertować
- Koszty:
- pokrycie
- Stwórz
- tworzenie
- Obecnie
- krzywa
- dane
- punkty danych
- nauka danych
- zbiór danych
- Domyślnie
- zdefiniowane
- Pochodne
- detal
- wykryte
- Deweloper
- DevOps
- różne
- kierunek
- dyskutować
- omówione
- Wyświetlacz
- 分配
- do
- robi
- na dół
- pobieranie
- podczas
- każdy
- istota
- oszacowanie
- oceny
- ekspertyza
- Exploring
- wyrażenie
- Korzyści
- kilka
- Znajdź
- znalezieniu
- znajduje
- i terminów, a
- dopasować
- obserwuj
- następujący sposób
- W razie zamówieenia projektu
- FRAME
- od
- funkcjonować
- otrzymać
- miejsce
- dany
- Go
- cel
- większy
- Ziemia
- Przewodniki
- ręka
- uchwyt
- Have
- pomoc
- pomaga
- jej
- W jaki sposób
- HTTPS
- ICS
- if
- brak równowagi
- importować
- in
- zawierać
- wskaźnik
- Indie
- Indeksy
- Informacja
- wkład
- Wejścia
- odsetki
- ciekawy
- skrzyżowanie
- najnowszych
- IT
- właśnie
- Knuggety
- Wiedzieć
- wiedza
- Etykieta
- Etykiety
- język
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- mniej
- niech
- Biblioteka
- Licencja
- Upoważniony
- lubić
- prawdopodobieństwo
- lubi
- Linia
- załadunek
- log
- Popatrz
- wygląda jak
- od
- maszyna
- uczenie maszynowe
- robić
- wiele
- mapa
- matematyka
- matplotlib
- Maksymalizuj
- maksymalizacji
- maksymalny
- Może..
- oznaczać
- metoda
- Metryka
- zminimalizować
- minimum
- model
- modele
- moduł
- jeszcze
- ruch
- Nazwy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Potrzebować
- ujemny
- Następny
- numer
- zauważony
- of
- często
- on
- ONE
- Opinia
- naprzeciwko
- Optymalny
- optymalizacja
- Optymalizacja
- or
- Wynik
- wyniki
- wydajność
- Wyjścia
- pandy
- parametr
- parametry
- część
- sztuk
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- potencjalnie
- Detaliczność
- Przewiduje
- Przewidywania
- proroczy
- Urządzenie prognozujące
- Prognozy
- woleć
- prawdopodobieństwo
- Problem
- kontynuować
- wygląda tak
- przetwarzanie
- Produkty
- Programowanie
- zapewniać
- czysto
- Python
- radar
- zasięg
- Kurs
- Czytaj
- Czytający
- real
- dokumentacja
- , o którym mowa
- odnosi
- regresja
- raport
- składnica
- reprezentuje
- zażądać
- poszanowanie
- odpowiednio
- powraca
- przeglądu
- krzepki
- Zasada
- s
- nauka
- nauka-scikit
- wynik
- widzieć
- rozsądek
- zestaw
- Zestawy
- dzielenie
- ona
- pokazane
- Prosty
- upraszczać
- So
- kilka
- dzielić
- rozpoczęty
- statystyka
- Ewolucja krok po kroku
- proste
- Struktura
- Następnie
- taki
- odpowiedni
- sumy
- Brać
- trwa
- cel
- zadania
- Techniczny
- test
- Testowanie
- niż
- że
- Połączenia
- Im
- teoria
- Tam.
- w związku z tym
- one
- to
- Przez
- do
- Toolbox
- Pociąg
- przeszkolony
- Trening
- Przekształcać
- transformacje
- próbować
- Tutorial
- tutoriale
- drugiej
- typy
- dla
- zrozumieć
- jednostka
- Aktualizacja
- Nowości
- URL
- us
- konto USA
- posługiwać się
- używany
- za pomocą
- wartość
- Wartości
- wyobrażać sobie
- we
- jeśli chodzi o komunikację i motywację
- który
- dlaczego
- Wikipedia
- będzie
- Skrzydło
- w
- Praca
- pracujący
- działa
- by
- pisarz
- pisanie
- X
- tak
- ty
- Twój
- zefirnet
- zero