Bilde av forfatter
Det er mange kurs og ressurser tilgjengelig om maskinlæring og datavitenskap, men svært få om datateknikk. Dette reiser noen spørsmål. Er det et vanskelig felt? Tilbyr det lav lønn? Betraktes det ikke som like spennende som andre techroller? Realiteten er imidlertid at mange selskaper aktivt søker dataingeniørtalent og tilbyr betydelige lønninger, noen ganger over 200,000 XNUMX USD. Dataingeniører spiller en avgjørende rolle som arkitektene for dataplattformer, og designer og bygger de grunnleggende systemene som gjør det mulig for dataforskere og maskinlæringseksperter å fungere effektivt.
For å adressere dette bransjegapet har DataTalkClub introdusert en transformativ og gratis bootcamp, "Datateknikk Zoomcamp". Dette kurset er utviklet for å styrke nybegynnere eller profesjonelle som ønsker å bytte karriere, med viktige ferdigheter og praktisk erfaring innen datateknikk.
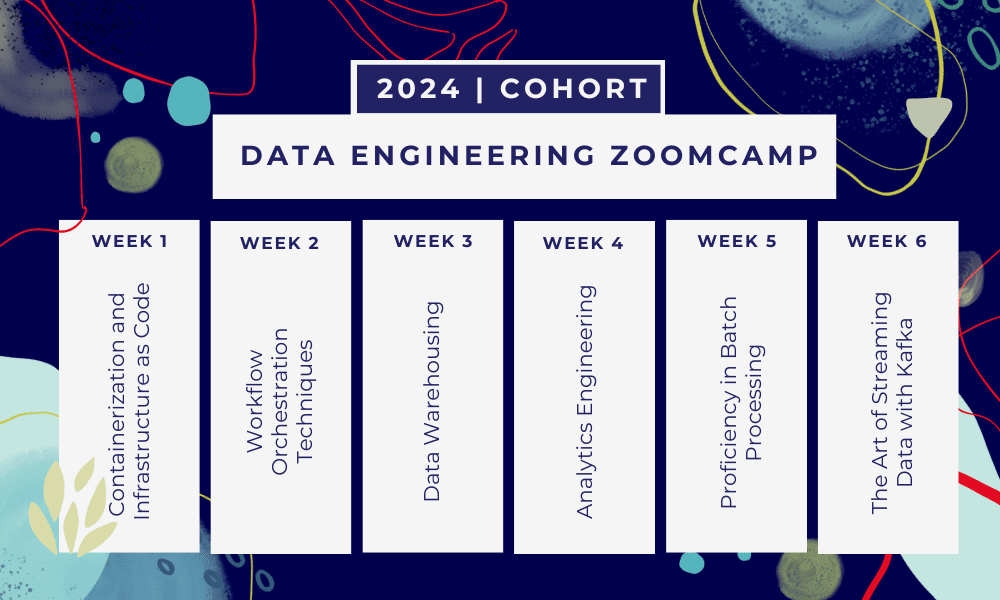
Dette er en 6 ukers bootcamp hvor du vil lære gjennom flere kurs, lesemateriell, workshops og prosjekter. På slutten av hver modul vil du få lekser for å øve på det du har lært.
- Uke 1: Introduksjon til GCP, Docker, Postgres, Terraform og miljøoppsett.
- Uke 2: Arbeidsflytorkestrering med Mage.
- Uke 3: Datavarehus med BigQuery og maskinlæring med BigQuery.
- Uke 4: Analytisk ingeniør med dbt, Google Data Studio og Metabase.
- Uke 5: Batchbehandling med Spark.
- Uke 6: Streamer med Kafka.
Bilde fra DataTalksClub/data-engineering-zoomcamp
Pensum inneholder 6 moduler, 2 workshops og et prosjekt som dekker alt som trengs for å bli en profesjonell dataingeniør.
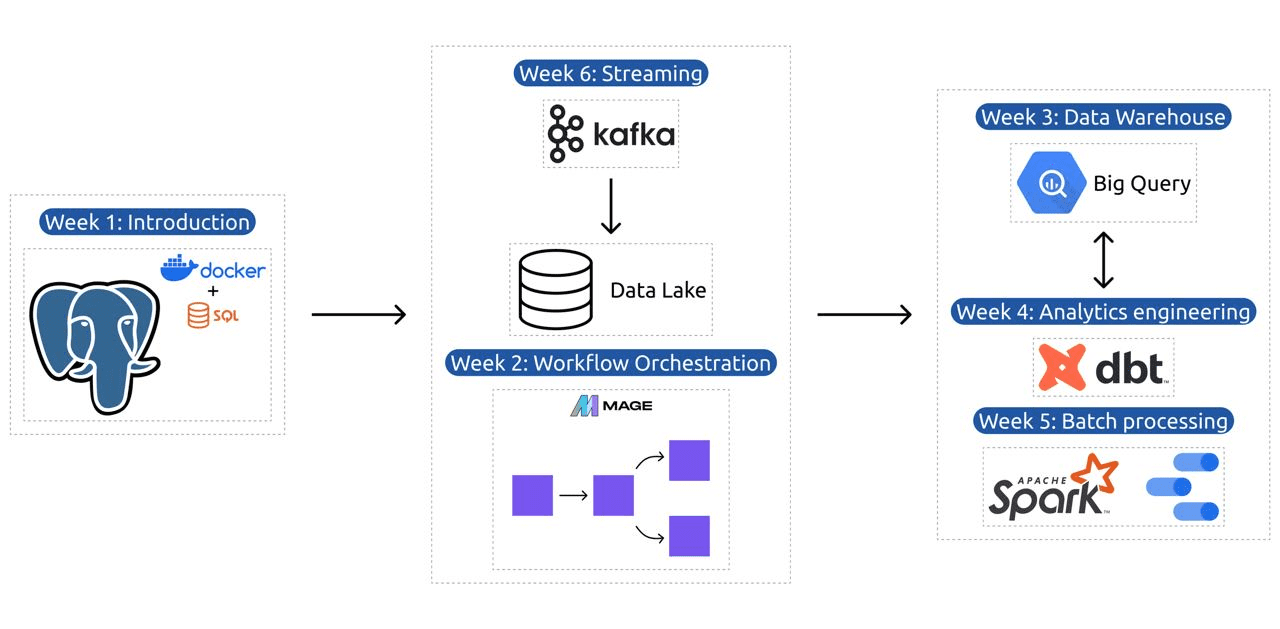
Modul 1: Mestring av containerisering og infrastruktur som kode
I denne modulen lærer du om Docker og Postgres, starter med det grunnleggende og går videre gjennom detaljerte veiledninger om å lage datapipelines, kjøre Postgres med Docker og mer.
Modulen dekker også viktige verktøy som pgAdmin, Docker-compose og SQL-oppfriskningsemner, med valgfritt innhold på Docker-nettverk og en spesiell gjennomgang for Windows-undersystem Linux-brukere. Til slutt introduserer kurset deg til GCP og Terraform, og gir en helhetlig forståelse av containerisering og infrastruktur som en kode, avgjørende for moderne skybaserte miljøer.
Modul 2: Workflow Orchestration-teknikker
Modulen tilbyr en dyptgående utforskning av Mage, et innovativt hybridrammeverk med åpen kildekode for datatransformasjon og integrasjon. Denne modulen begynner med det grunnleggende om arbeidsflyt-orkestrering, og går videre til praktiske øvelser med Mage, inkludert å sette den opp via Docker og bygge ETL-pipelines fra API til Postgres og Google Cloud Storage (GCS), og deretter til BigQuery.
Modulens blanding av videoer, ressurser og praktiske oppgaver sikrer en omfattende læringsopplevelse, og utstyrer elevene med ferdighetene til å administrere sofistikerte dataarbeidsflyter ved hjelp av Mage.
Workshop 1: Strategier for datainntak
I den første workshopen vil du mestre å bygge effektive rørledninger for datainntak. Workshopen fokuserer på essensielle ferdigheter som å trekke ut data fra APIer og filer, normalisering og lasting av data og inkrementelle lastingsteknikker. Etter å ha fullført denne workshopen, vil du være i stand til å lage effektive datapipelines som en senior dataingeniør.
Modul 3: Datavarehus
Modulen er en dyptgående utforskning av datalagring og -analyse, med fokus på datavarehus ved bruk av BigQuery. Den dekker nøkkelbegreper som partisjonering og klynging, og dykker ned i BigQuerys beste fremgangsmåter. Modulen går videre til avanserte emner, spesielt integreringen av Machine Learning (ML) med BigQuery, fremhever bruken av SQL for ML, og gir ressurser om hyperparameterinnstilling, funksjonsforbehandling og modelldistribusjon.
Modul 4: Analytics Engineering
Analysemodulen fokuserer på å bygge et prosjekt ved hjelp av dbt (Data Build Tool) med et eksisterende datavarehus, enten BigQuery eller PostgreSQL.
Modulen dekker oppsett av dbt i både sky- og lokale miljøer, introduserer analytiske ingeniørkonsepter, ETL vs ELT, og datamodellering. Den dekker også avanserte dbt-funksjoner som inkrementelle modeller, tagger, kroker og øyeblikksbilder.
Til slutt introduserer modulen teknikker for å visualisere transformerte data ved hjelp av verktøy som Google Data Studio og Metabase, og den gir ressurser for feilsøking og effektiv datainnlasting.
Modul 5: Ferdighet i batchbehandling
Denne modulen dekker batchbehandling med Apache Spark, og starter med introduksjoner til batchbehandling og Spark, sammen med installasjonsinstruksjoner for Windows, Linux og MacOS.
Det inkluderer å utforske Spark SQL og DataFrames, forberede data, utføre SQL-operasjoner og forstå Spark internals. Til slutt avsluttes det med å kjøre Spark i skyen og integrere Spark med BigQuery.
Modul 6: Kunsten å strømme data med Kafka
Modulen begynner med en introduksjon til strømbehandlingskonsepter, etterfulgt av en grundig utforskning av Kafka, inkludert dets grunnleggende, integrasjon med Confluent Cloud og praktiske applikasjoner som involverer produsenter og forbrukere.
Modulen dekker også Kafka-konfigurasjon og strømmer, og tar for seg emner som strømtilknytning, testing, vindusvisning og bruk av Kafka ksqldb & Connect. I tillegg utvider det fokuset til Python- og JVM-miljøer, med Faust for Python-strømbehandling, Pyspark – Structured Streaming og Scala-eksempler for Kafka Streams.
Workshop 2: Strømbehandling med SQL
Du vil lære å behandle og administrere strømmedata med RisingWave, som gir en kostnadseffektiv løsning med en opplevelse i PostgreSQL-stil for å styrke strømbehandlingsapplikasjonene dine.
Prosjekt: Real-World Data Engineering Application
Målet med dette prosjektet er å implementere alle konseptene vi har lært i dette kurset for å konstruere en ende-til-ende datapipeline. Du skal lage et dashbord som består av to fliser ved å velge et datasett, bygge en pipeline for å behandle dataene og lagre dem i en datainnsjø, bygge en pipeline for å overføre de behandlede dataene fra datasjøen til et datavarehus, transformere dataene i datavarehuset og forberede dem for dashbordet, og til slutt bygge et dashbord for å presentere dataene visuelt.
2024 Kohortdetaljer
- Registrering: Meld deg på nå
- Startdato: 15. januar 2024, kl. 17:00 CET
- Læring i eget tempo med veiledet støtte
- Kohortmappe med lekser og frister
- interaktiv Slakk fellesskap for kollegalæring
Forutsetninger
- Grunnleggende koding og kommandolinjeferdigheter
- Foundation i SQL
- Python: gunstig, men ikke obligatorisk
Erfarne instruktører som leder reisen din
- Ankush Khanna
- Victoria Perez Mola
- Alexey Grigorev
- --Matt Palmer
- Luis Oliveira
- Michael skomaker
Bli med i 2024-kohorten vår og begynn å lære med et fantastisk dataingeniørfellesskap. Med ekspertledet opplæring, praktisk erfaring og en læreplan som er skreddersydd for bransjens behov, utstyrer denne bootcampen deg ikke bare med de nødvendige ferdighetene, men plasserer deg også i forkant av en lukrativ og etterspurt karrierevei. Registrer deg i dag og forvandle ambisjonene dine til virkelighet!
Abid Ali Awan (@1abidaliawan) er en sertifisert dataforsker som elsker å bygge maskinlæringsmodeller. For tiden fokuserer han på innholdsskaping og skriver tekniske blogger om maskinlæring og datavitenskapsteknologier. Abid har en mastergrad i teknologiledelse og en bachelorgrad i telekommunikasjonsteknikk. Hans visjon er å bygge et AI-produkt ved å bruke et grafisk nevralt nettverk for studenter som sliter med psykiske lidelser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 1
- 15%
- 17
- 2024
- a
- I stand
- Om oss
- aktivt
- I tillegg
- adressering
- avansert
- Advancing
- Etter
- AI
- Alle
- langs
- også
- utrolig
- an
- analyse
- Analytisk
- analytics
- og
- og infrastruktur
- Apache
- Apache Spark
- api
- APIer
- søknader
- arkitekter
- ER
- Kunst
- AS
- At
- tilgjengelig
- Grunnleggende
- BE
- bli
- bli
- nybegynnere
- gunstig
- BEST
- beste praksis
- BigQuery
- Blend
- blogger
- både
- bygge
- Bygning
- men
- by
- Karriere
- karrierer
- Sertifisert
- Cloud
- sky lagring
- gruppering
- kode
- Koding
- Cohort
- samfunnet
- Selskaper
- fullført
- omfattende
- konsepter
- konkluderer
- Konfigurasjon
- kryss
- Koble
- ansett
- Består
- konstruere
- Forbrukere
- inneholder
- innhold
- innholdsskaping
- kurs
- kurs
- dekker
- skape
- Opprette
- skaperverket
- avgjørende
- I dag
- Curriculum
- dashbord
- dato
- dataingeniør
- Data Lake
- datavitenskap
- dataforsker
- datalagring
- datalager
- Dato
- Grad
- distribusjon
- designet
- utforme
- detaljert
- vanskelig
- Docker
- hver enkelt
- effektivt
- effektiv
- enten
- bemyndige
- muliggjøre
- slutt
- ende til ende
- ingeniør
- Ingeniørarbeid
- Ingeniører
- melde
- sikrer
- Miljø
- miljøer
- avgjørende
- Eter (ETH)
- alt
- eksempler
- spennende
- eksisterende
- erfaring
- eksperter
- leting
- Utforske
- strekker
- Trekk
- Egenskaper
- Featuring
- Noen få
- felt
- Filer
- Endelig
- Først
- Fokus
- fokuserer
- fokusering
- fulgt
- Til
- teten
- grunn
- Rammeverk
- Gratis
- fra
- funksjon
- Fundamentals
- mellomrom
- GCP
- gitt
- Google Cloud
- graf
- Graf Neural Network
- guidet
- hands-on
- Ha
- he
- utheving
- hans
- holder
- helhetlig
- hjemmelekser
- kroker
- Men
- HTTPS
- Hybrid
- Innstilling av hyperparameter
- sykdom
- iverksette
- in
- dyptgående
- inkluderer
- Inkludert
- inkrementell
- industri
- Infrastruktur
- innovative
- installasjon
- instruksjoner
- Integrering
- integrering
- inn
- introdusert
- Introduserer
- innføre
- Introduksjon
- introduksjoner
- involverer
- IT
- DET ER
- Januar
- tiltrer
- Kafka
- KDnuggets
- nøkkel
- innsjø
- ledende
- LÆRE
- lært
- elever
- læring
- i likhet med
- linje
- linux
- lasting
- lokal
- ser
- elsker
- Lav
- lukrative
- maskin
- maskinlæring
- MacOS
- administrer
- ledelse
- obligatorisk
- mange
- Master
- Maste
- materialer
- mental
- Mentalt syk
- ML
- modell
- modellering
- modeller
- Moderne
- moduler
- Moduler
- mer
- flere
- nødvendig
- Trenger
- nødvendig
- behov
- nettverk
- nettverk
- neural
- nevrale nettverket
- Målet
- of
- tilby
- Tilbud
- on
- bare
- åpen kildekode
- Drift
- or
- orkestre
- Annen
- vår
- Palmer
- spesielt
- banen
- Betale
- likemann
- utfører
- rørledning
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- stillinger
- postgresql
- Praktisk
- praktiske anvendelser
- praksis
- praksis
- forbereder
- presentere
- prosess
- behandlet
- prosessering
- Produsentene
- Produkt
- profesjonell
- fagfolk
- framdrift
- prosjekt
- prosjekter
- gir
- gi
- Python
- spørsmål
- hever
- Lesning
- virkelige verden
- Reality
- Ressurser
- Rolle
- roller
- rennende
- s
- lønn
- Skala
- Vitenskap
- Forsker
- forskere
- søker
- velge
- senior
- innstilling
- oppsett
- ferdigheter
- slakk
- løsning
- noen
- noen ganger
- sofistikert
- Spark
- spesiell
- SQL
- Begynn
- Start
- lagring
- stream
- streaming
- bekker
- strukturert
- Sliter
- Studenter
- studio
- betydelig
- slik
- støtte
- Bytte om
- Systemer
- skreddersydd
- Talent
- oppgaver
- tech
- Teknisk
- teknikker
- Technologies
- Teknologi
- telekommunikasjon
- terra
- Testing
- Det
- De
- Grunnleggende
- deretter
- denne
- Gjennom
- til
- i dag
- verktøy
- verktøy
- temaer
- Kurs
- Overføre
- Transform
- Transformation
- transformative
- forvandlet
- transformere
- tutorials
- to
- forståelse
- USD
- bruke
- Brukere
- ved hjelp av
- Ve
- veldig
- av
- videoer
- syn
- visuelt
- vs
- Warehouse
- lager
- we
- Hva
- hvilken
- HVEM
- vil
- vinduer
- med
- arbeidsflyt
- arbeidsflyt
- verksted
- Verksteder
- skriving
- du
- Din
- zephyrnet










