AWS Lim Studio er et grafisk grensesnitt som gjør det enkelt å opprette, kjøre og overvåke ekstrahere, transformere og laste (ETL) jobber i AWS Lim. Den lar deg komponere datatransformasjonsarbeidsflyter visuelt ved hjelp av noder som representerer forskjellige datahåndteringstrinn, som senere konverteres automatisk til kode for å kjøre.
AWS Lim Studio Nylig utgitt 10 flere visuelle transformasjoner for å tillate å skape mer avanserte jobber på en visuell måte uten kodeferdigheter. I dette innlegget diskuterer vi potensielle brukstilfeller som gjenspeiler vanlige ETL-behov.
De nye transformasjonene som vil bli demonstrert i dette innlegget er: Sammenknytt, Del streng, Array til kolonner, Legg til gjeldende tidsstempel, Pivot rader til kolonner, Unpivot kolonner til rader, oppslag, eksploder matrise eller kart inn i kolonner, avledet kolonne og autobalanseringsbehandling .
Løsningsoversikt
I dette tilfellet har vi noen JSON-filer med aksjeopsjonsoperasjoner. Vi ønsker å gjøre noen transformasjoner før vi lagrer dataene for å gjøre det lettere å analysere, og vi ønsker også å lage et eget datasettsammendrag.
I dette datasettet representerer hver rad en handel med opsjonskontrakter. Opsjoner er finansielle instrumenter som gir rett – men ikke plikt – til å kjøpe eller selge aksjer til en fast pris (kalt streikepris) før en definert utløpsdato.
Inndata
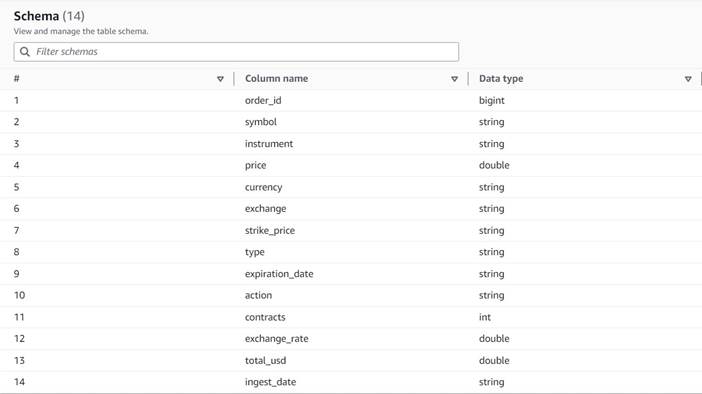
Dataene følger følgende skjema:
- Bestillings ID – En unik ID
- symbol – En kode som vanligvis er basert på noen få bokstaver for å identifisere selskapet som sender ut de underliggende aksjeaksjene
- instrument – Navnet som identifiserer det spesifikke alternativet som kjøpes eller selges
- valuta – ISO-valutakoden som prisen er uttrykt i
- pris – Beløpet som ble betalt for kjøp av hver opsjonskontrakt (på de fleste børser lar én kontrakt deg kjøpe eller selge 100 aksjer)
- utveksling – Koden til byttesenteret eller stedet der opsjonen ble handlet
- solgt – En liste over antall kontrakter som ble tildelt for å fylle salgsordren når dette er en salgshandel
- kjøpt – En liste over antall kontrakter som ble tildelt for å fylle kjøpsordren når dette er kjøpshandel
Følgende er et eksempel på de syntetiske dataene som er generert for dette innlegget:
ETL krav
Disse dataene har en rekke unike egenskaper, som ofte finnes på eldre systemer, som gjør dataene vanskeligere å bruke.
Følgende er ETL-kravene:
- Instrumentnavnet har verdifull informasjon som er ment for mennesker å forstå; vi ønsker å normalisere den i separate kolonner for enklere analyse.
- Attributtene
boughtogsoldutelukker hverandre; vi kan konsolidere dem i en enkelt kolonne med kontraktnumrene og ha en annen kolonne som indikerer om kontraktene ble kjøpt eller solgt i denne rekkefølgen. - Vi ønsker å beholde informasjonen om de individuelle kontraktstildelingene, men som individuelle rader i stedet for å tvinge brukere til å forholde seg til en rekke tall. Vi kunne legge sammen tallene, men vi ville miste informasjon om hvordan ordren ble fylt (som indikerer markedslikviditet). I stedet velger vi å denormalisere tabellen slik at hver rad har et enkelt antall kontrakter, og deler opp ordre med flere tall i separate rader. I et komprimert kolonneformat er den ekstra datasettstørrelsen for denne repetisjonen ofte liten når komprimering brukes, så det er akseptabelt å gjøre datasettet enklere å spørre etter.
- Vi ønsker å generere en oppsummeringstabell over volum for hver opsjonstype (call and put) for hver aksje. Dette gir en indikasjon på markedssentimentet for hver aksje og markedet generelt (grådighet vs. frykt).
- For å aktivere overordnede handelssammendrag ønsker vi å gi totalsummen for hver operasjon og standardisere valutaen til amerikanske dollar ved å bruke en omtrentlig konverteringsreferanse.
- Vi ønsker å legge til datoen da disse transformasjonene fant sted. Dette kan for eksempel være nyttig for å ha en referanse på når valutaomregningen ble foretatt.
Basert på disse kravene vil jobben produsere to utganger:
- En CSV-fil med en oppsummering av antall kontrakter for hvert symbol og type
- En katalogtabell for å holde en historikk over bestillingen, etter å ha utført de angitte transformasjonene
Forutsetninger
Du trenger din egen S3-bøtte for å følge med denne brukssaken. For å lage en ny bøtte, se Å lage en bøtte.
Generer syntetiske data
For å følge med på dette innlegget (eller eksperimentere med denne typen data på egen hånd), kan du generere dette datasettet syntetisk. Følgende Python-skript kan kjøres på et Python-miljø med Boto3 installert og tilgang til Amazon enkel lagringstjeneste (Amazon S3).
For å generere data, fullfør følgende trinn:
- På AWS Glue Studio oppretter du en ny jobb med alternativet Python shell script editor.
- Gi jobben et navn og på Jobbdetaljer fanen, velg en passende rolle og et navn for Python-skriptet.
- på Jobbdetaljer seksjon, utvide Avanserte egenskaper og bla ned til Jobbparametere.
- Skriv inn en parameter kalt
--bucketog tilordne som verdi navnet på bøtten du vil bruke til å lagre eksempeldataene. - Skriv inn følgende skript i AWS Glue shell editor:
- Kjør jobben og vent til den vises som vellykket fullført på Kjør-fanen (det bør ta bare noen få sekunder).
Hver kjøring vil generere en JSON-fil med 1,000 rader under den angitte bøtten og prefikset transformsblog/inputdata/. Du kan kjøre jobben flere ganger hvis du vil teste med flere inndatafiler.
Hver linje i de syntetiske dataene er en datarad som representerer et JSON-objekt som følgende:
Lag AWS Glue visuell jobb
For å lage den visuelle AWS Glue-jobben, fullfør følgende trinn:
- Gå til AWS Glue Studio og opprett en jobb ved å bruke alternativet Visuelt med et tomt lerret.
- Rediger
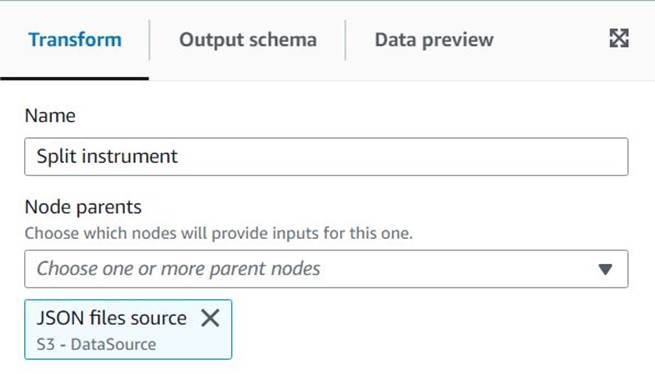
Untitled jobå gi den et navn og tildele en rolle som passer for AWS Glue på Jobbdetaljer fanen. - Legg til en S3-datakilde (du kan navngi den
JSON files source) og skriv inn S3-URLen som filene er lagret under (f.eks.s3://<your bucket name>/transformsblog/inputdata/), velg deretter JSON som dataformat. - Plukke ut Utlede skjema så det setter utdataskjemaet basert på dataene.
Fra denne kildenoden vil du fortsette å lenke transformasjoner. Når du legger til hver transformasjon, sørg for at den valgte noden er den siste som er lagt til, slik at den blir tildelt som overordnet, med mindre annet er angitt i instruksjonene.
Hvis du ikke valgte riktig forelder, kan du alltid redigere forelderen ved å velge den og velge en annen forelder i konfigurasjonsruten.
For hver node som legges til, vil du gi den et spesifikt navn (slik at formålet med noden vises i grafen) og konfigurasjon på Transform fanen.
Hver gang en transformasjon endrer skjemaet (for eksempel legge til en ny kolonne), må utdataskjemaet oppdateres slik at det er synlig for nedstrømstransformasjonene. Du kan redigere utdataskjemaet manuelt, men det er mer praktisk og tryggere å gjøre det ved å bruke forhåndsvisningen av data.
I tillegg kan du på den måten bekrefte at transformasjonen fungerer så langt som forventet. For å gjøre det, åpne Forhåndsvisning av data fanen med transformasjonen valgt og start en forhåndsvisningsøkt. Etter at du har bekreftet at de transformerte dataene ser ut som forventet, går du til Utdataskjema fanen og velg Bruk dataforhåndsvisningsskjema for å oppdatere skjemaet automatisk.
Når du legger til nye typer transformasjoner, kan forhåndsvisningen vise en melding om en manglende avhengighet. Når dette skjer, velg Avslutt sesjonen og start en ny, så forhåndsvisningen fanger opp den nye typen node.
Trekk ut instrumentinformasjon
La oss starte med å behandle informasjonen om instrumentnavnet for å normalisere det til kolonner som er lettere å få tilgang til i den resulterende utdatatabellen.
- legge en Delt streng node og navngi den
Split instrument, som vil tokenisere instrumentkolonnen ved å bruke et regeluttrykk for mellomrom:s+(en enkelt plass ville gjøre i dette tilfellet, men denne måten er mer fleksibel og visuelt klarere). - Vi ønsker å beholde den originale instrumentinformasjonen som den er, så skriv inn et nytt kolonnenavn for den delte arrayen:
instrument_arr.
- Legg til en Array til kolonner node og navngi den
Instrument columnsfor å konvertere array-kolonnen som nettopp er opprettet til nye felt, bortsett frasymbol, som vi allerede har en kolonne for. - Velg kolonnen
instrument_arr, hopp over det første tokenet og be det trekke ut utdatakolonnenemonth, day, year, strike_price, typeved hjelp av indekser2, 3, 4, 5, 6(mellomrommene etter kommaene er for lesbarhet, de påvirker ikke konfigurasjonen).
Årstallet som trekkes ut uttrykkes kun med to sifre; la oss sette et stopp for å anta at det er i dette århundret hvis de bare bruker to sifre.
- legge en Avledet kolonne node og navngi den
Four digits year. - Enter
yearsom den avledede kolonnen slik at den overstyrer den, og skriv inn følgende SQL-uttrykk:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
For enkelhets skyld bygger vi en expiration_date felt som en bruker kan ha som referanse for siste dato opsjonen kan utøves.
- legge en Slå sammen kolonner node og navngi den
Build expiration date. - Gi den nye kolonnen et navn
expiration_date, velg kolonneneyear,monthogday(i den rekkefølgen), og en bindestrek som spacer.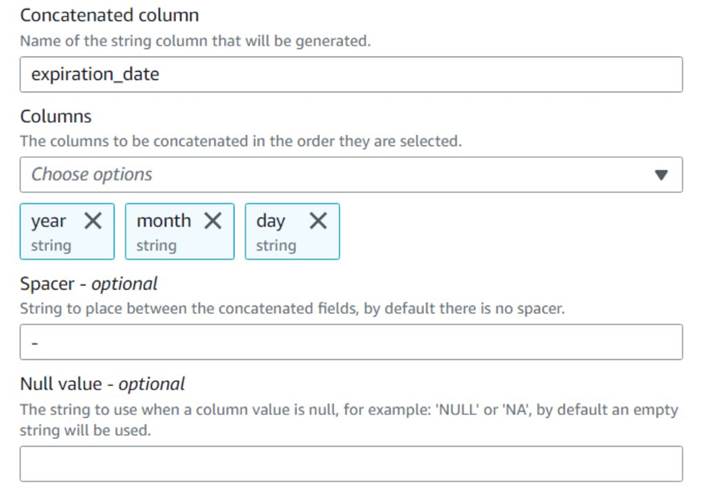
Diagrammet så langt skal se ut som følgende eksempel.
![]()
Dataforhåndsvisningen av de nye kolonnene så langt skal se ut som følgende skjermbilde.
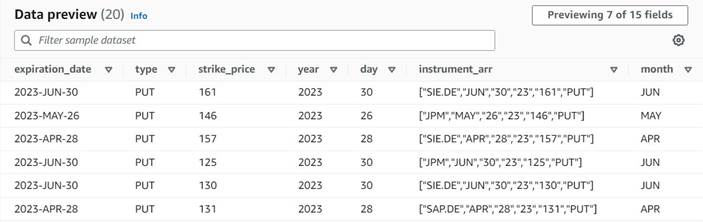
Normaliser antall kontrakter
Hver av radene i dataene indikerer antall kontrakter for hver opsjon som ble kjøpt eller solgt og batchene som ordrene ble fylt på. Uten å miste informasjonen om de enkelte partiene, ønsker vi å ha hvert beløp på en enkelt rad med en enkelt beløpsverdi, mens resten av informasjonen replikeres i hver produserte rad.
La oss først slå sammen beløpene til en enkelt kolonne.
- Legg til en Løsne kolonner i rader node og navngi den
Unpivot actions. - Velg kolonnene
boughtogsoldfor å oppheve og lagre navnene og verdiene i navngitte kolonneractionogcontractsHhv.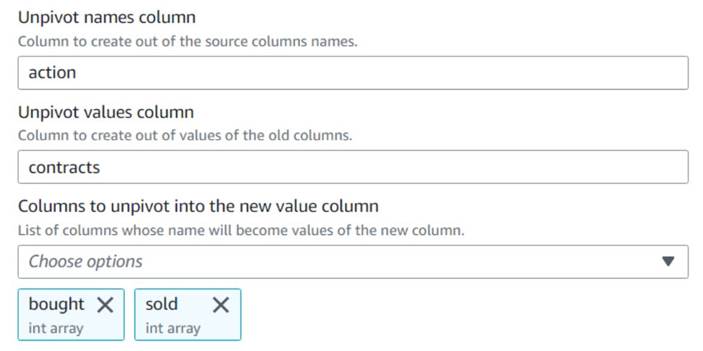
Legg merke til i forhåndsvisningen at den nye kolonnencontractser fortsatt en rekke tall etter denne transformasjonen.
- Legg til en Eksploder array eller kart i rader rad navngitt
Explode contracts. - Velg
contractskolonne og skriv inncontractssom den nye kolonnen for å overstyre den (vi trenger ikke å beholde den opprinnelige matrisen).
Forhåndsvisningen viser nå at hver rad har en singel contracts beløp, og resten av feltene er de samme.
Dette betyr også at order_id er ikke lenger en unik nøkkel. For dine egne brukstilfeller må du bestemme hvordan du skal modellere dataene dine og om du vil denormalisere eller ikke.
Følgende skjermbilde er et eksempel på hvordan de nye kolonnene ser ut etter transformasjonene så langt.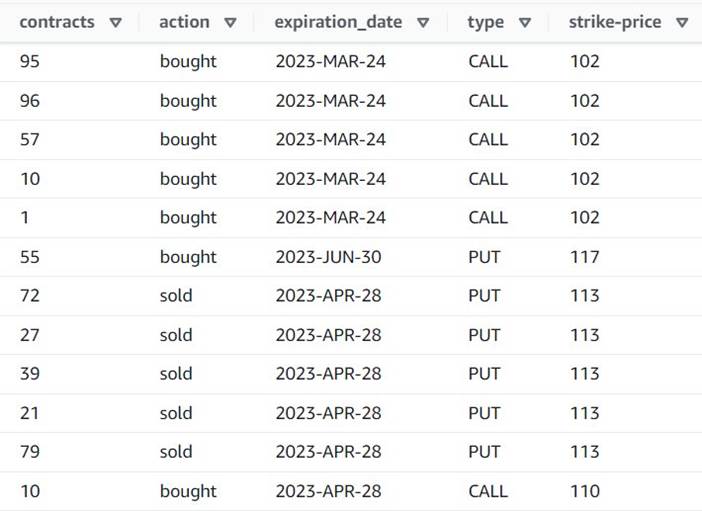
Lag en sammendragstabell
Nå lager du en oppsummeringstabell med antall kontrakter omsatt for hver type og hvert aksjesymbol.
La oss anta for illustrasjonsformål at filene som behandles tilhører en enkelt dag, så dette sammendraget gir bedriftsbrukerne informasjon om hva markedsinteressen og sentimentet er den dagen.
- legge en Velg felt node og velg følgende kolonner for å beholde for sammendraget:
symbol,typeogcontracts.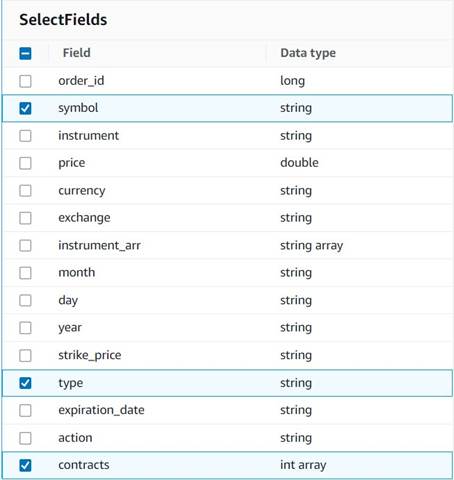
- legge en Pivoter rader til kolonner node og navngi den
Pivot summary. - Samle på
contractskolonne ved hjelp avsumog velg å konverteretypekolonne.
Normalt vil du lagre det på en ekstern database eller fil for referanse; i dette eksemplet lagrer vi den som en CSV-fil på Amazon S3.
- Legg til en Autobalansebehandling node og navngi den
Single output file. - Selv om den transformasjonstypen vanligvis brukes til å optimalisere parallelliteten, bruker vi den her til å redusere utdataene til en enkelt fil. Gå derfor inn
1i antall partisjoner konfigurasjon.
- Legg til et S3-mål og navngi det
CSV Contract summary. - Velg CSV som dataformat og angi en S3-bane der jobbrollen har lov til å lagre filer.
Den siste delen av jobben skal nå se ut som følgende eksempel.![]()
- Lagre og kjør jobben. Bruke Kjører fanen for å sjekke når den er fullført.
Du finner en fil under den banen som er en CSV, til tross for at du ikke har den utvidelsen. Du må sannsynligvis legge til utvidelsen etter at du har lastet den ned for å åpne den.
På et verktøy som kan lese CSV-en, skal sammendraget se omtrent ut som følgende eksempel.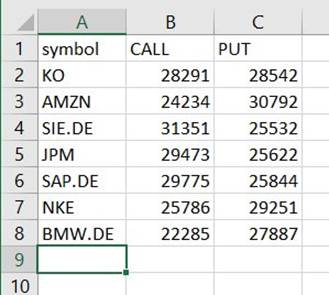
Rydd opp i midlertidige kolonner
Som forberedelse til å lagre bestillingene i en historisk tabell for fremtidig analyse, la oss rydde opp i noen midlertidige kolonner som ble opprettet underveis.
- legge en Slipp felt node med
Explode contractsnode valgt som overordnet (vi forgrener datarørledningen for å generere en separat utgang). - Velg feltene som skal slettes:
instrument_arr,month,dayogyear.
Resten ønsker vi å beholde slik at de blir lagret i den historiske tabellen vi lager senere.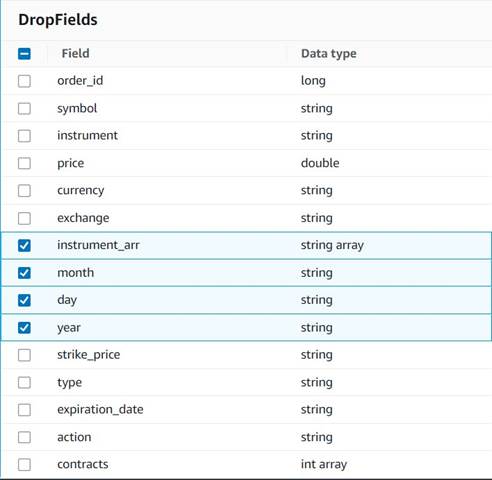
Valutastandardisering
Disse syntetiske dataene inneholder fiktive operasjoner på to valutaer, men i et ekte system kan du få valutaer fra markeder over hele verden. Det er nyttig å standardisere valutaene som håndteres til én enkelt referansevaluta, slik at de enkelt kan sammenlignes og aggregeres for rapportering og analyse.
Vi bruker Amazonas Athena å simulere en tabell med omtrentlige valutaomregninger som oppdateres med jevne mellomrom (her antar vi at vi behandler bestillingene i tide nok til at konverteringen er en rimelig representant for sammenligningsformål).
- Åpne Athena-konsollen i samme region der du bruker AWS Glue.
- Kjør følgende spørring for å lage tabellen ved å angi en S3-plassering der både Athena- og AWS Glue-rollene dine kan lese og skrive. Det kan også være lurt å lagre tabellen i en annen database enn
default(hvis du gjør det, oppdater det tabellkvalifiserte navnet tilsvarende i eksemplene som er gitt). - Skriv inn noen eksempler på konverteringer i tabellen:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Du skal nå kunne se tabellen med følgende spørring:
SELECT * FROM default.exchange_rates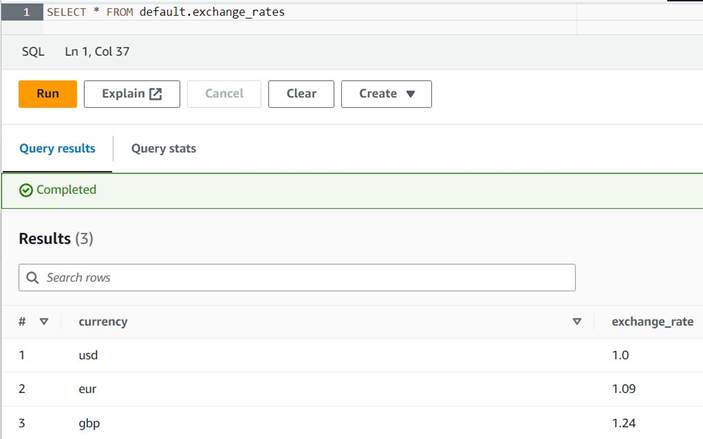
- Tilbake på AWS Glue visuell jobb, legg til en Oppslag node (som et barn av
Drop Fields) og nevne detExchange rate. - Skriv inn det kvalifiserte navnet på tabellen du nettopp opprettet ved å bruke
currencysom tast og velgexchange_ratefelt å bruke.
Fordi feltet heter det samme i både dataene og oppslagstabellen, kan vi bare skrive inn navnetcurrencyog trenger ikke å definere en kartlegging.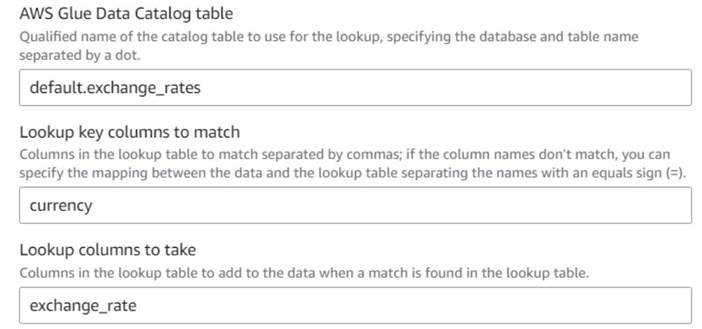
Når dette skrives, støttes ikke oppslagstransformasjonen i dataforhåndsvisningen, og den vil vise en feil om at tabellen ikke eksisterer. Dette er kun for forhåndsvisningen av data og forhindrer ikke at jobben kjører riktig. De få gjenværende trinnene i innlegget krever ikke at du oppdaterer skjemaet. Hvis du trenger å kjøre en forhåndsvisning av data på andre noder, kan du fjerne oppslagsnoden midlertidig og deretter sette den tilbake. - legge en Avledet kolonne node og navngi den
Total in usd. - Gi navn til den avledede kolonnen
total_usdog bruk følgende SQL-uttrykk:round(contracts * price * exchange_rate, 2)
- legge en Legg til gjeldende tidsstempel node og navngi kolonnen
ingest_date. - Bruk formatet
%Y-%m-%dfor tidsstemplet ditt (for demonstrasjonsformål bruker vi bare datoen; du kan gjøre den mer presis hvis du vil).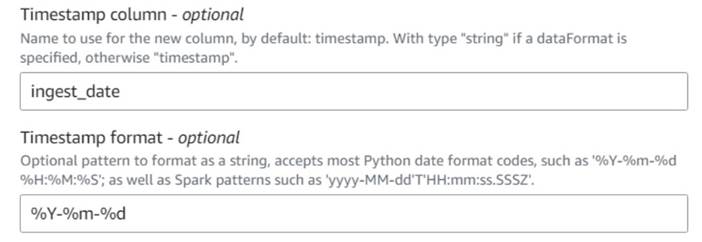
Lagre den historiske ordretabellen
For å lagre den historiske ordretabellen, fullfør følgende trinn:
- Legg til en S3-målnode og navngi den
Orders table. - Konfigurer Parkett-format med rask komprimering, og gi en S3-målbane som du kan lagre resultatene under (atskilt fra sammendraget).
- Plukke ut Opprett en tabell i datakatalogen og ved påfølgende kjøringer, oppdater skjemaet og legg til nye partisjoner.
- Skriv inn en måldatabase og et navn for den nye tabellen, for eksempel:
option_orders.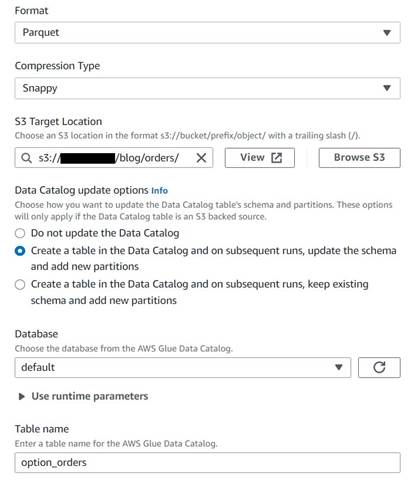
Den siste delen av diagrammet skal nå se ut som det følgende, med to grener for de to separate utgangene.![]()
Etter at du har kjørt jobben, kan du bruke et verktøy som Athena til å se gjennom dataene jobben har produsert ved å spørre etter den nye tabellen. Du kan finne tabellen på Athena-listen og velge Forhåndsvisningstabell eller bare kjør en SELECT-spørring (oppdaterer tabellnavnet til navnet og katalogen du brukte):
SELECT * FROM default.option_orders limit 10
Tabellinnholdet ditt skal se ut som det følgende skjermbildet.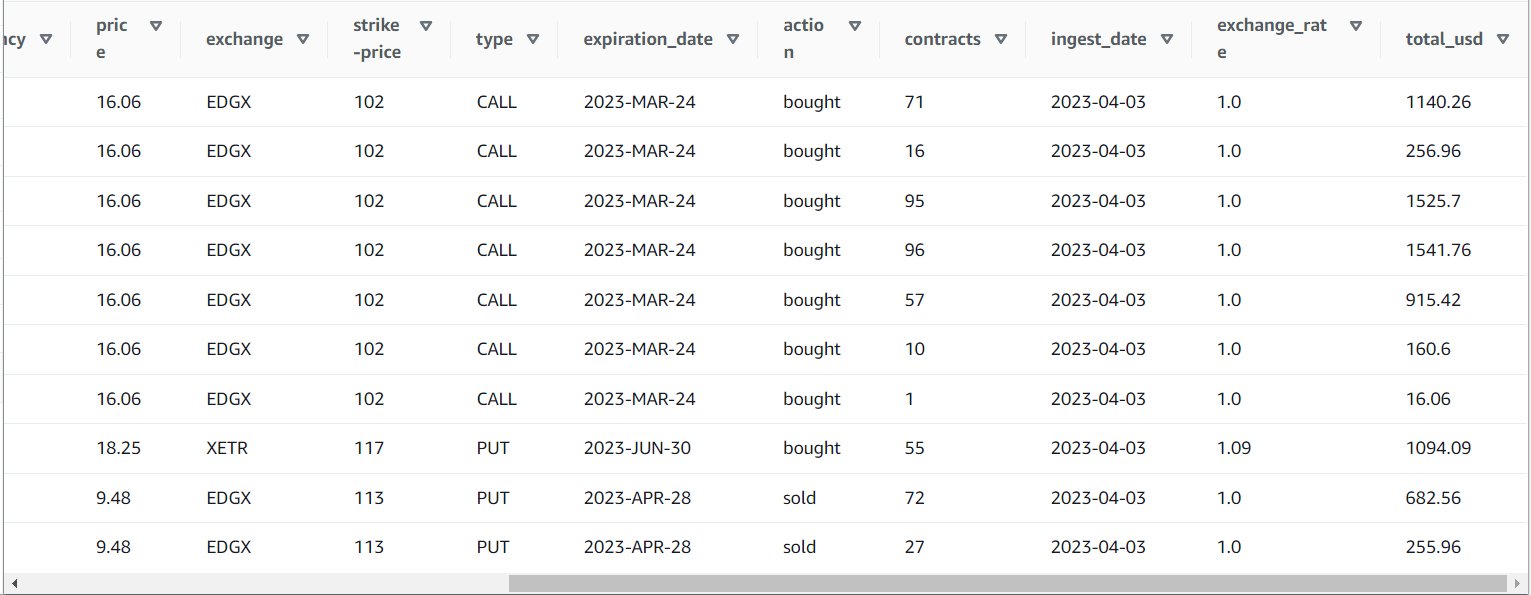
Rydd opp
Hvis du ikke vil beholde dette eksemplet, sletter du de to jobbene du opprettet, de to tabellene i Athena og S3-banene der inn- og utdatafilene ble lagret.
konklusjonen
I dette innlegget viste vi hvordan de nye transformasjonene i AWS Glue Studio kan hjelpe deg med å gjøre mer avansert transformasjon med minimum konfigurasjon. Dette betyr at du kan implementere flere ETL-brukssaker uten å måtte skrive og vedlikeholde noen kode. De nye transformasjonene er allerede tilgjengelige på AWS Glue Studio, så du kan bruke de nye transformasjonene i dag i dine visuelle jobber.
Om forfatteren
![]() Gonzalo Herreros er senior Big Data Architect på AWS Glue-teamet.
Gonzalo Herreros er senior Big Data Architect på AWS Glue-teamet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- I stand
- Om oss
- akseptabelt
- adgang
- tilsvar
- legge til
- la til
- legge
- avansert
- Etter
- Alle
- allokert
- bevilgninger
- tillate
- tillater
- langs
- allerede
- også
- alltid
- Amazon
- beløp
- beløp
- an
- analyse
- analysere
- og
- En annen
- noen
- anvendt
- tilnærmet
- april
- ER
- argument
- Array
- AS
- tildelt
- At
- attributter
- automatisk
- tilgjengelig
- AWS
- AWS Lim
- tilbake
- basert
- BE
- før du
- være
- Stor
- Store data
- blank
- BMW
- både
- kjøpt
- grener
- bygge
- virksomhet
- men
- kjøpe
- by
- ring
- CAN
- saken
- saker
- katalog
- sentrum
- Århundre
- Endringer
- egenskaper
- sjekk
- barn
- Velg
- velge
- tydeligere
- kode
- Koding
- Kolonne
- kolonner
- Felles
- sammenlignet
- sammenligning
- fullføre
- Terminado
- Konfigurasjon
- Konsoll
- konsolidere
- inneholder
- innhold
- kontrakt
- kontrakter
- bekvemmelighet
- Konvertering
- konverteringer
- konvertere
- konvertert
- SELSKAP
- kunne
- skape
- opprettet
- Opprette
- valutaer
- valuta
- Gjeldende
- DAG
- dato
- Database
- Dato
- datoer
- dato tid
- dag
- avtale
- håndtering
- bestemme
- Misligholde
- definert
- demonstrert
- Avhengighet
- Avledet
- Til tross for
- detaljer
- forskjellig
- sifre
- diskutere
- do
- ikke
- gjør
- dollar
- ikke
- dobbelt
- ned
- Drop
- droppet
- hver enkelt
- enklere
- lett
- lett
- redaktør
- muliggjøre
- nok
- Enter
- Miljø
- feil
- Eter (ETH)
- EUR
- eksempel
- eksempler
- Unntatt
- utveksling
- Børser
- Eksklusiv
- eksisterer
- Expand
- forventet
- eksperiment
- utløp
- uttrykte
- forlengelse
- utvendig
- ekstra
- trekke ut
- langt
- frykt
- Noen få
- fiktiv
- felt
- Felt
- filet
- Filer
- fyll
- fylt
- finansiell
- Finansielle instrumenter
- Finn
- Først
- fikset
- fleksibel
- følge
- etter
- følger
- Til
- format
- funnet
- fra
- framtid
- GBP
- general
- generelt
- generere
- generert
- få
- Gi
- gir
- Go
- graf
- Grådighet
- Håndtering
- skjer
- Ha
- å ha
- hjelpe
- her.
- historisk
- historie
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- Mennesker
- i
- identifiserer
- identifisere
- if
- Påvirkning
- iverksette
- importere
- in
- indekser
- indikert
- indikerer
- indikerer
- indikasjon
- individuelt
- informasjon
- inngang
- f.eks
- i stedet
- instruksjoner
- instrument
- instrumenter
- interesse
- Interface
- inn
- ISO
- IT
- DET ER
- Jobb
- Jobb
- jpg
- JSON
- bare
- Hold
- nøkkel
- Type
- Siste
- seinere
- i likhet med
- BEGRENSE
- linje
- Likviditet
- Liste
- laste
- plassering
- lenger
- Se
- ser ut som
- UTSEENDE
- oppslag
- taper
- å miste
- laget
- vedlikeholde
- gjøre
- GJØR AT
- manuelt
- kart
- kartlegging
- marked
- markedssentiment
- Markets
- Kan..
- midler
- Flett
- melding
- kunne
- minimum
- mangler
- modell
- Overvåke
- mer
- mest
- flere
- gjensidig
- navn
- oppkalt
- navn
- Trenger
- behov
- Ny
- Nei.
- node
- noder
- normalt
- nå
- Antall
- tall
- objekt
- of
- ofte
- on
- ONE
- bare
- åpen
- drift
- Drift
- Optimalisere
- Alternativ
- alternativer
- or
- rekkefølge
- ordrer
- original
- Annen
- ellers
- produksjon
- enn
- samlet
- overstyring
- egen
- betalt
- brød
- parameter
- del
- banen
- Picks
- rørledning
- Pivot
- Sted
- plato
- Platon Data Intelligence
- PlatonData
- Post
- potensiell
- Praktisk
- presis
- forebygge
- Forhåndsvisning
- pris
- sannsynligvis
- prosess
- prosessering
- produsere
- produsert
- gi
- forutsatt
- gir
- Kjøp
- formål
- formål
- sette
- Python
- kvalifisert
- heve
- tilfeldig
- Lese
- ekte
- rimelig
- redusere
- reflektere
- region
- gjenværende
- fjerne
- replikert
- Rapportering
- representere
- representant
- representerer
- representerer
- krever
- Krav
- Krever
- henholdsvis
- REST
- resulterende
- Resultater
- anmeldelse
- Rolle
- roller
- RAD
- Kjør
- rennende
- sikrere
- samme
- sap
- Spar
- besparende
- bla
- sekunder
- valgt
- velge
- selger
- senior
- sentiment
- separat
- Session
- sett
- innstilling
- Aksjer
- Shell
- bør
- Vis
- Viser
- lignende
- Enkelt
- enkelt
- Størrelse
- ferdigheter
- liten
- So
- så langt
- solgt
- noen
- noe
- kilde
- Rom
- mellomrom
- spesifikk
- spesifisert
- splittet
- regneark
- SQL
- Begynn
- Steps
- Still
- lager
- lagring
- oppbevare
- lagret
- String
- studio
- senere
- vellykket
- egnet
- SAMMENDRAG
- Støttes
- symbol
- syntetisk
- syntetiske data
- syntetisk
- system
- Systemer
- bord
- Ta
- Target
- lag
- fortelle
- midlertidig
- ti
- test
- enn
- Det
- De
- Grafen
- informasjonen
- verden
- Dem
- deretter
- derfor
- Disse
- de
- denne
- De
- tid
- ganger
- tidsstempel
- til
- i dag
- token
- symbolisere
- tok
- verktøy
- Totalt
- handel
- handles
- Transform
- Transformation
- transformasjoner
- forvandlet
- to
- typen
- etter
- underliggende
- forstå
- unik
- til
- Oppdater
- oppdatert
- oppdatering
- URL
- us
- US Dollar
- USD
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- ved hjelp av
- Verdifull
- Verdifull informasjon
- verdi
- Verdier
- Venue
- verifisert
- verifisere
- Se
- synlig
- volum
- vs
- vente
- ønsker
- var
- Vei..
- we
- var
- Hva
- når
- hvilken
- mens
- vil
- med
- uten
- arbeidsflyt
- arbeid
- verden
- ville
- skrive
- skriving
- år
- du
- Din
- zephyrnet











