Med bruken av generativ AI, kan dagens grunnmodeller (FM), som de store språkmodellene (LLM) Claude 2 og Llama 2, utføre en rekke generative oppgaver som spørsmålssvar, oppsummering og innholdsoppretting på tekstdata. Imidlertid eksisterer virkelige data i flere modaliteter, for eksempel tekst, bilder, video og lyd. Ta for eksempel et PowerPoint-lysbildekort. Det kan inneholde informasjon i form av tekst, eller innebygd i grafer, tabeller og bilder.
I dette innlegget presenterer vi en løsning som bruker multimodale FM-er som f.eks Amazon Titan Multimodal Embeddings modell og LLaVA 1.5 og AWS-tjenester inkludert Amazonas grunnfjell og Amazon SageMaker å utføre lignende generative oppgaver på multimodale data.
Løsningsoversikt
Løsningen gir en implementering for å svare på spørsmål ved å bruke informasjon som finnes i teksten og visuelle elementer i et lysbildekort. Designet er avhengig av konseptet Retrieval Augmented Generation (RAG). Tradisjonelt har RAG vært assosiert med tekstdata som kan behandles av LLM-er. I dette innlegget utvider vi RAG til å inkludere bilder også. Dette gir en kraftig søkefunksjon for å trekke ut kontekstuelt relevant innhold fra visuelle elementer som tabeller og grafer sammen med tekst.
Det er forskjellige måter å designe en RAG-løsning som inkluderer bilder. Vi har presentert én tilnærming her og vil følge opp med en alternativ tilnærming i det andre innlegget i denne tredelte serien.
Denne løsningen inkluderer følgende komponenter:
- Amazon Titan Multimodal Embeddings-modell – Denne FM-en brukes til å generere innebygginger for innholdet i lysbildestokken som brukes i dette innlegget. Som en multimodal modell kan denne Titan-modellen behandle tekst, bilder eller en kombinasjon som input og generere embeddings. Titan Multimodal Embeddings-modellen genererer vektorer (embeddings) med 1,024 dimensjoner og er tilgjengelig via Amazon Bedrock.
- Stor språk- og synsassistent (LLaVA) – LLaVA er en åpen kildekode multimodal modell for visuell og språkforståelse og brukes til å tolke dataene i lysbildene, inkludert visuelle elementer som grafer og tabeller. Vi bruker versjonen med 7 milliarder parametere LLaVA 1.5-7b i denne løsningen.
- Amazon SageMaker – LLaVA-modellen er distribuert på et SageMaker-endepunkt ved å bruke SageMaker-vertstjenester, og vi bruker det resulterende endepunktet til å kjøre slutninger mot LLaVA-modellen. Vi bruker også SageMaker-notatbøker til å orkestrere og demonstrere denne løsningen ende til ende.
- Amazon OpenSearch Serverless – OpenSearch Serverless er en on-demand serverløs konfigurasjon for Amazon OpenSearch-tjeneste. Vi bruker OpenSearch Serverless som en vektordatabase for lagring av embeddings generert av Titan Multimodal Embeddings-modellen. En indeks opprettet i OpenSearch Serverless-samlingen fungerer som vektorlageret for RAG-løsningen vår.
- Amazon OpenSearch Ingestion (OSI) – OSI er en fullstendig administrert, serverløs datainnsamler som leverer data til OpenSearch Service-domener og OpenSearch Serverless-samlinger. I dette innlegget bruker vi en OSI-pipeline for å levere data til OpenSearch Serverless vektorlager.
Løsningsarkitektur
Løsningsdesignet består av to deler: inntak og brukerinteraksjon. Under inntak behandler vi inngangslysbildestokken ved å konvertere hvert lysbilde til et bilde, generere innbygginger for disse bildene og deretter fylle ut vektordatalageret. Disse trinnene fullføres før trinnene for brukerinteraksjon.
I brukerinteraksjonsfasen konverteres et spørsmål fra brukeren til innbygginger og det kjøres et likhetssøk på vektordatabasen for å finne et lysbilde som potensielt kan inneholde svar på brukerspørsmål. Vi gir deretter dette lysbildet (i form av en bildefil) til LLaVA-modellen og brukerspørsmålet som en oppfordring til å generere et svar på spørringen. All koden for dette innlegget er tilgjengelig i GitHub hvile.
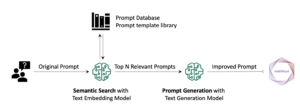
Følgende diagram illustrerer inntaksarkitekturen.
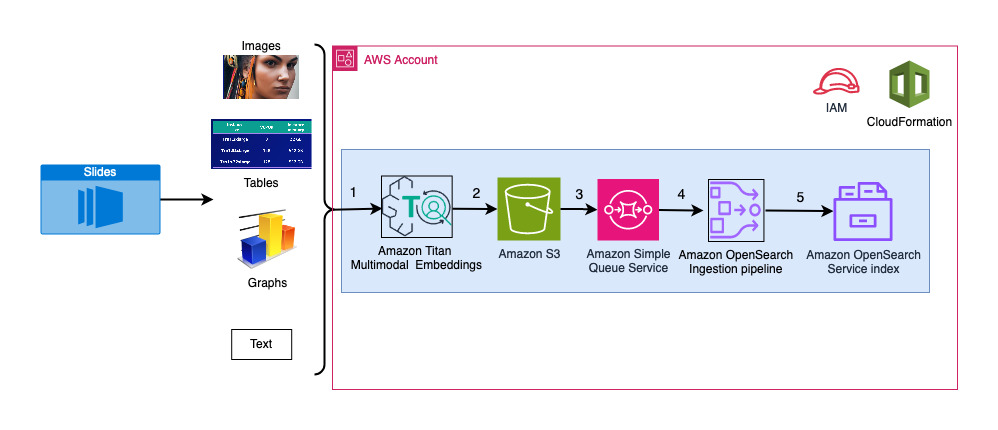
Arbeidsflyttrinnene er som følger:
- Lysbilder konverteres til bildefiler (én per lysbilde) i JPG-format og sendes til Titan Multimodal Embeddings-modellen for å generere innbygginger. I dette innlegget bruker vi lysbildestokken med tittelen Tren og distribuer stabil diffusjon ved hjelp av AWS Trainium og AWS Inferentia fra AWS Summit i Toronto, juni 2023, for å demonstrere løsningen. Prøvestokken har 31 lysbilder, så vi genererer 31 sett med vektorinnbygginger, hver med 1,024 dimensjoner. Vi legger til flere metadatafelt til disse genererte vektorinnbyggingene og lager en JSON-fil. Disse ekstra metadatafeltene kan brukes til å utføre rike søk ved å bruke OpenSearchs kraftige søkefunksjoner.
- De genererte innebyggingene settes sammen i en enkelt JSON-fil som lastes opp til Amazon enkel lagringstjeneste (Amazon S3).
- via Amazon S3 hendelsesvarsler, er en hendelse satt i en Amazon enkel køtjeneste (Amazon SQS) kø.
- Denne hendelsen i SQS-køen fungerer som en trigger for å kjøre OSI-pipelinen, som igjen henter inn dataene (JSON-filen) som dokumenter inn i OpenSearch Serverless-indeksen. Merk at OpenSearch Serverless-indeksen er konfigurert som vasken for denne pipelinen og er opprettet som en del av OpenSearch Serverless-samlingen.
Følgende diagram illustrerer brukerinteraksjonsarkitekturen.
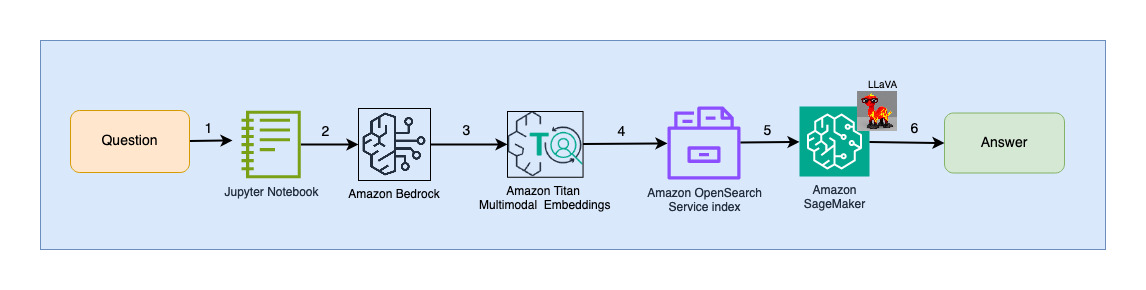
Arbeidsflyttrinnene er som følger:
- En bruker sender inn et spørsmål knyttet til lysbildestokken som har blitt inntatt.
- Brukerinndataene konverteres til innebygginger ved å bruke Titan Multimodal Embeddings-modellen tilgjengelig via Amazon Bedrock. Et OpenSearch-vektorsøk utføres ved å bruke disse innebyggingene. Vi utfører et k-nærmeste nabo-søk (k=1) for å hente den mest relevante innebyggingen som samsvarer med brukersøket. Innstilling k=1 henter det mest relevante lysbildet til brukerspørsmålet.
- Metadataene til svaret fra OpenSearch Serverless inneholder en bane til bildet som tilsvarer det mest relevante lysbildet.
- En forespørsel opprettes ved å kombinere brukerspørsmålet og bildebanen og leveres til LLaVA som er vert på SageMaker. LLaVA-modellen er i stand til å forstå brukerspørsmålet og svare på det ved å undersøke dataene i bildet.
- Resultatet av denne slutningen returneres til brukeren.
Disse trinnene diskuteres i detalj i de følgende avsnittene. Se Resultater seksjon for skjermbilder og detaljer om utdata.
Forutsetninger
For å implementere løsningen som er gitt i dette innlegget, bør du ha en AWS-konto og kjennskap til FM-er, Amazon Bedrock, SageMaker og OpenSearch Service.
Denne løsningen bruker Titan Multimodal Embeddings-modellen. Sørg for at denne modellen er aktivert for bruk i Amazon Bedrock. På Amazon Bedrock-konsollen velger du Modelltilgang i navigasjonsruten. Hvis Titan Multimodal Embeddings er aktivert, vil tilgangsstatusen oppgis Tilgang godkjent.
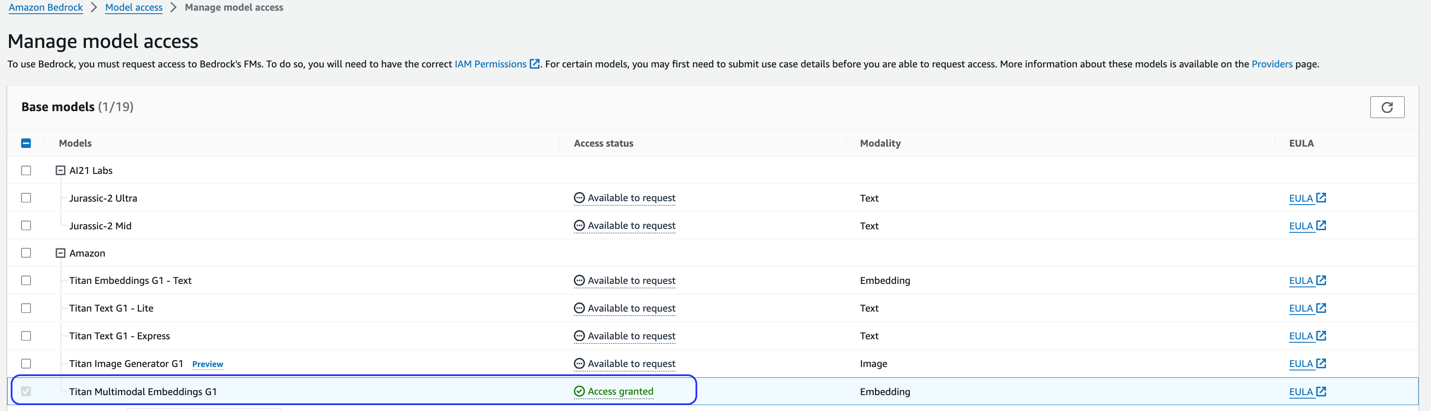
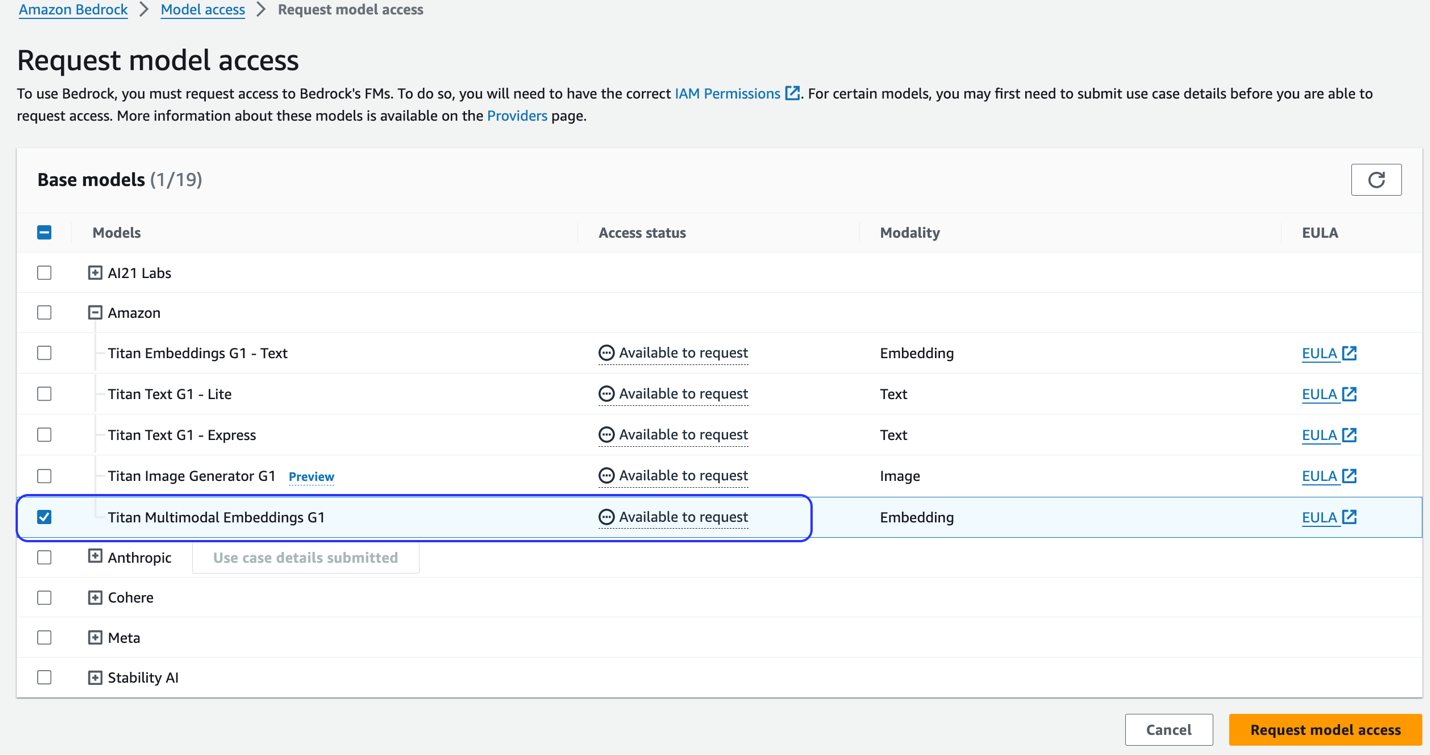
Hvis modellen ikke er tilgjengelig, aktiver tilgang til modellen ved å velge Administrer modelltilgang, velge Titan Multimodal Embeddings G1, og velge Be om modelltilgang. Modellen er aktivert for bruk umiddelbart.
Bruk en AWS CloudFormation-mal for å lage løsningsstabelen
Bruk ett av følgende AWS skyformasjon maler (avhengig av din region) for å lansere løsningsressursene.
| AWS-regionen | link |
|---|---|
us-east-1 |
|
us-west-2 |
Etter at stabelen er opprettet, navigerer du til stabelens Utganger fanen på AWS CloudFormation-konsollen og noter verdien for MultimodalCollectionEndpoint, som vi bruker i påfølgende trinn.
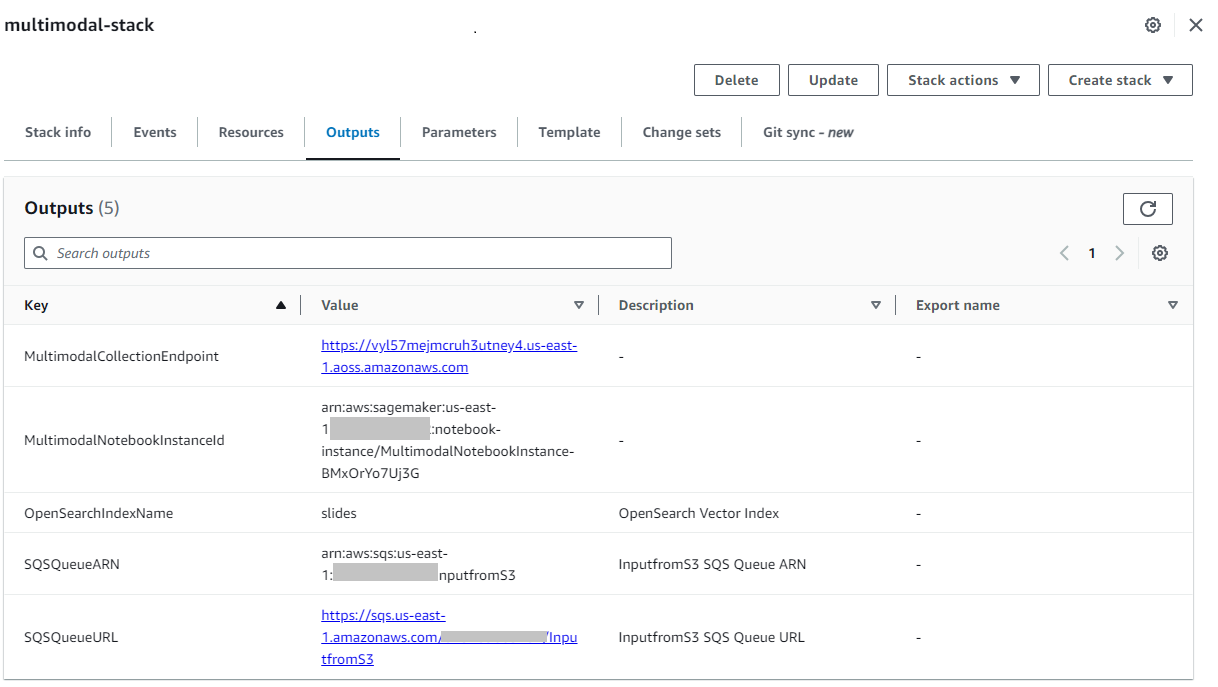
CloudFormation-malen oppretter følgende ressurser:
- IAM-roller - Følgende AWS identitets- og tilgangsadministrasjon (IAM)-roller opprettes. Oppdater disse rollene for å søke minst privilegerte tillatelser.
SMExecutionRolemed Amazon S3, SageMaker, OpenSearch Service og Bedrock full tilgang.OSPipelineExecutionRolemed tilgang til spesifikke Amazon SQS og OSI-handlinger.
- SageMaker-notatbok – All koden for dette innlegget kjøres via denne notatboken.
- OpenSearch Serverless-samling – Dette er vektordatabasen for lagring og henting av innebygginger.
- OSI rørledning – Dette er rørledningen for inntak av data til OpenSearch Serverless.
- S3 bøtte – Alle data for dette innlegget er lagret i denne bøtten.
- SQS-kø – Hendelsene for utløsning av OSI-rørledningen settes i denne køen.
CloudFormation-malen konfigurerer OSI-rørledningen med Amazon S3- og Amazon SQS-behandling som kilde og en OpenSearch Serverless-indeks som sink. Eventuelle objekter opprettet i den angitte S3-bøtten og prefikset (multimodal/osi-embeddings-json) vil utløse SQS-varsler, som brukes av OSI-pipelinen for å innta data til OpenSearch Serverless.
CloudFormation-malen lager også nettverk, krypteringog data tilgang retningslinjer som kreves for OpenSearch Serverless-samlingen. Oppdater disse retningslinjene for å bruke tillatelser med minste privilegier.
Merk at CloudFormation-malnavnet er referert til i SageMaker-notatbøker. Hvis standard malnavn er endret, må du sørge for at du oppdaterer det samme i globals.py
Test løsningen
Etter at de nødvendige trinnene er fullført og CloudFormation-stakken har blitt opprettet, er du nå klar til å teste løsningen:
- Velg på SageMaker-konsollen Notatbøker i navigasjonsruten.
- Velg
MultimodalNotebookInstancenotatbokforekomst og velg Åpne JupyterLab.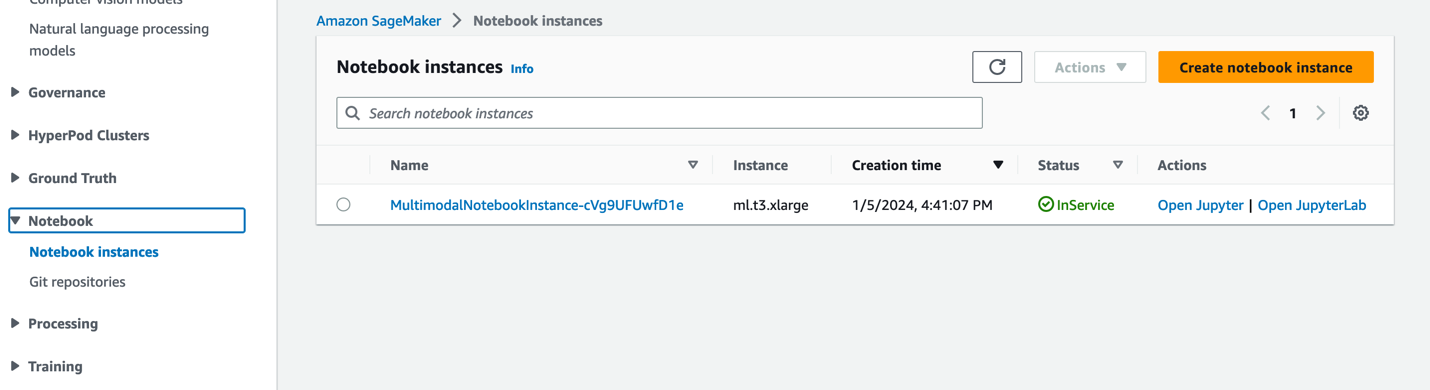
- In Fil utforsker, gå til Notebooks-mappen for å se notatbøkene og støttefilene.
Notatbøkene er nummerert i rekkefølgen de kjøres i. Instruksjoner og kommentarer i hver notatbok beskriver handlingene som utføres av den notatboken. Vi kjører disse notatbøkene én etter én.
- Velg 0_deploy_llava.ipynb for å åpne den i JupyterLab.
- På Kjør meny, velg Kjør alle celler for å kjøre koden i denne notatboken.
Denne bærbare datamaskinen distribuerer LLaVA-v1.5-7B-modellen til et SageMaker-endepunkt. I denne notatboken laster vi ned LLaVA-v1.5-7B-modellen fra HuggingFace Hub, erstatter inference.py-skriptet med llava_inference.py, og lag en model.tar.gz-fil for denne modellen. Model.tar.gz-filen lastes opp til Amazon S3 og brukes til å distribuere modellen på SageMaker-endepunktet. De llava_inference.py skriptet har tilleggskode for å tillate å lese en bildefil fra Amazon S3 og kjøre slutning om den.
- Velg 1_data_prep.ipynb for å åpne den i JupyterLab.
- På Kjør meny, velg Kjør alle celler for å kjøre koden i denne notatboken.
Denne notatboken laster ned Lysbilde, konverterer hvert lysbilde til JPG-filformat, og laster disse opp til S3-bøtta som brukes til dette innlegget.
- Velg 2_data_ingestion.ipynb for å åpne den i JupyterLab.
- På Kjør meny, velg Kjør alle celler for å kjøre koden i denne notatboken.
Vi gjør følgende i denne notatboken:
- Vi lager en indeks i OpenSearch Serverless-samlingen. Denne indeksen lagrer innebyggingsdataene for lysbildet. Se følgende kode:
- Vi bruker Titan Multimodal Embeddings-modellen for å konvertere JPG-bildene som ble opprettet i den forrige notatboken, til vektorinnbygginger. Disse innebyggingene og tilleggsmetadataene (som S3-banen til bildefilen) lagres i en JSON-fil og lastes opp til Amazon S3. Legg merke til at det opprettes en enkelt JSON-fil, som inneholder dokumenter for alle lysbildene (bildene) som er konvertert til innebygging. Følgende kodebit viser hvordan et bilde (i form av en Base64-kodet streng) konverteres til innebygging:
- Denne handlingen utløser OpenSearch Ingestion-pipeline, som behandler filen og tar den inn i OpenSearch Serverless-indeksen. Følgende er et eksempel på JSON-filen som er opprettet. (En vektor med fire dimensjoner er vist i eksempelkoden. Titan Multimodal Embeddings-modellen genererer 1,024 dimensjoner.)
- Velg 3_rag_inference.ipynb for å åpne den i JupyterLab.
- På Kjør meny, velg Kjør alle celler for å kjøre koden i denne notatboken.
Denne notatboken implementerer RAG-løsningen: vi konverterer brukerspørsmålet til innebygging, finner et lignende bilde (lysbilde) fra vektordatabasen, og gir det hentede bildet til LLaVA for å generere et svar på brukerspørsmålet. Vi bruker følgende forespørselsmal:
Følgende kodebit gir RAG-arbeidsflyten:
Resultater
Følgende er en sammenstilling av noen brukerspørsmål og svar generert av implementeringen vår. De Spørsmål kolonnen fanger opp brukerspørsmålet, og Svar kolonnen er tekstresponsen generert av LLaVA. Bilde er det k-nærmeste (k=1) lysbildetreffet som returneres av OpenSearch Serverless vektorsøk. Dette lysbildet er tolket av LLaVA for å gi svaret.
Multimodale RAG-resultater
| Spørsmål | Svar | Bilde |
|---|---|---|
| Hvordan sammenligner Inf2 i ytelse med sammenlignbare EC2-forekomster? Jeg trenger tall. | I følge lysbildestokken tilbyr Inf2-forekomster av AWS Inferentia2 opptil 4x høyere gjennomstrømning og 10x lavere ventetid sammenlignet med sammenlignbare EC2-forekomster. |  |
| Hva gir AWS AI/ML-tjenestene i henhold til AI/ML-svinghjulet? | AWS AI/ML-tjenestene gir bedre $/perfer-evner, nye evner og investering i innovasjon. | 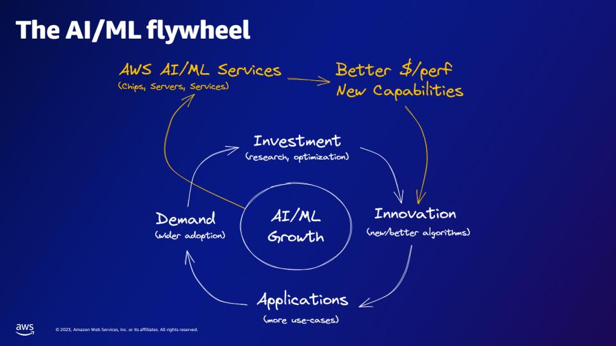 |
| Sammenlignet med GPT-2, hvor mange flere parametere har GPT-3? Hva er den numeriske forskjellen mellom parameterstørrelsen til GPT-2 og GPT-3? | I følge lysbildet har GPT-3 175 milliarder parametere, mens GPT-2 har 1.5 milliarder parametere. Den numeriske forskjellen mellom parameterstørrelsen til GPT-2 og GPT-3 er 173.5 milliarder. | 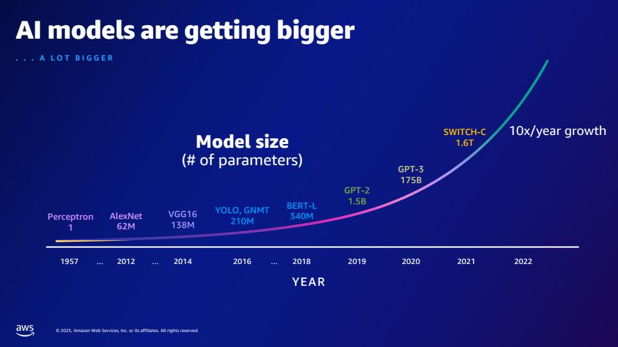 |
| Hva er kvarker i partikkelfysikk? | Jeg fant ikke svaret på dette spørsmålet i lysbildestokken. |  |
Utvid gjerne denne løsningen til dine skyvedekk. Bare oppdater SLIDE_DECK-variabelen i globals.py med en URL til lysbildestokken din og kjør inntakstrinnene beskrevet i forrige seksjon.
Tips
Du kan bruke OpenSearch Dashboards til å samhandle med OpenSearch API for å kjøre raske tester på indeksen og inntatte data. Følgende skjermbilde viser et GET-eksempel på OpenSearch-dashbordet.
Rydd opp
Slett ressursene du opprettet for å unngå fremtidige kostnader. Du kan gjøre dette ved å slette stabelen via CloudFormation-konsollen.

Slett i tillegg SageMaker-slutningsendepunktet som er opprettet for LLaVA-slutning. Du kan gjøre dette ved å fjerne kommentaren til oppryddingstrinnet 3_rag_inference.ipynb og kjøre cellen, eller ved å slette endepunktet via SageMaker-konsollen: velg slutning og endepunkter i navigasjonsruten, velg endepunktet og slett det.
konklusjonen
Bedrifter genererer nytt innhold hele tiden, og lysbildestokker er en vanlig mekanisme som brukes til å dele og formidle informasjon internt med organisasjonen og eksternt med kunder eller på konferanser. Over tid kan rik informasjon forbli begravd og skjult i ikke-tekstmodaliteter som grafer og tabeller i disse lysbildestokkene. Du kan bruke denne løsningen og kraften til multimodale FM-er som Titan Multimodal Embeddings-modellen og LLaVA til å oppdage ny informasjon eller avdekke nye perspektiver på innhold i lysbildestokker.
Vi oppfordrer deg til å lære mer ved å utforske Amazon SageMaker JumpStart, Amazon Titan-modeller, Amazon Bedrock og OpenSearch Service, og bygge en løsning ved å bruke eksempelimplementeringen gitt i dette innlegget.
Se opp for to ekstra innlegg som en del av denne serien. Del 2 dekker en annen tilnærming du kan bruke for å snakke med lysbildestokken din. Denne tilnærmingen genererer og lagrer LLaVA-slutninger og bruker de lagrede slutningene for å svare på brukerforespørsler. Del 3 sammenligner de to tilnærmingene.
Om forfatterne
 Amit Arora er en AI- og ML-spesialistarkitekt hos Amazon Web Services, og hjelper bedriftskunder å bruke skybaserte maskinlæringstjenester for raskt å skalere innovasjonene sine. Han er også adjunkt i MS data science and analytics-programmet ved Georgetown University i Washington DC
Amit Arora er en AI- og ML-spesialistarkitekt hos Amazon Web Services, og hjelper bedriftskunder å bruke skybaserte maskinlæringstjenester for raskt å skalere innovasjonene sine. Han er også adjunkt i MS data science and analytics-programmet ved Georgetown University i Washington DC
 Manju Prasad er en senior løsningsarkitekt innen strategiske kontoer hos Amazon Web Services. Hun fokuserer på å gi teknisk veiledning i en rekke domener, inkludert AI/ML til en M&E-kunde. Før hun begynte i AWS, designet og bygde hun løsninger for selskaper i finanssektoren og også for en startup.
Manju Prasad er en senior løsningsarkitekt innen strategiske kontoer hos Amazon Web Services. Hun fokuserer på å gi teknisk veiledning i en rekke domener, inkludert AI/ML til en M&E-kunde. Før hun begynte i AWS, designet og bygde hun løsninger for selskaper i finanssektoren og også for en startup.
 Archana Inapudi er en senior løsningsarkitekt hos AWS som støtter strategiske kunder. Hun har over ti års erfaring med å hjelpe kunder med å designe og bygge dataanalyse og databaseløsninger. Hun brenner for å bruke teknologi for å gi verdi til kunder og oppnå forretningsresultater.
Archana Inapudi er en senior løsningsarkitekt hos AWS som støtter strategiske kunder. Hun har over ti års erfaring med å hjelpe kunder med å designe og bygge dataanalyse og databaseløsninger. Hun brenner for å bruke teknologi for å gi verdi til kunder og oppnå forretningsresultater.
 Antara Raisa er en AI og ML Solutions Architect hos Amazon Web Services som støtter strategiske kunder basert fra Dallas, Texas. Hun har også tidligere erfaring med å jobbe med store bedriftspartnere hos AWS, hvor hun jobbet som Partner Success Solutions Architect for digitale innfødte kunder.
Antara Raisa er en AI og ML Solutions Architect hos Amazon Web Services som støtter strategiske kunder basert fra Dallas, Texas. Hun har også tidligere erfaring med å jobbe med store bedriftspartnere hos AWS, hvor hun jobbet som Partner Success Solutions Architect for digitale innfødte kunder.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- I stand
- Om oss
- adgang
- aksesseres
- kontoer
- Oppnå
- Handling
- handlinger
- handlinger
- legge til
- Ytterligere
- adjunkt
- advent
- mot
- AI
- AI / ML
- Alle
- tillate
- langs
- også
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analytics
- og
- En annen
- besvare
- besvare
- svar
- noen
- api
- Påfør
- tilnærming
- tilnærminger
- arkitektur
- ER
- AS
- spør
- Assistent
- assosiert
- At
- lyd
- augmented
- Auth
- tilgjengelig
- unngå
- AWS
- AWS skyformasjon
- basert
- BE
- vært
- Bedre
- mellom
- Milliarder
- kroppen
- bygge
- Bygning
- bygget
- virksomhet
- by
- CAN
- evner
- evne
- fanger
- celle
- endret
- avgifter
- Velg
- velge
- kunde
- kode
- samling
- samlinger
- oppsamler
- Kolonne
- kombinasjon
- kombinere
- kommentarer
- Felles
- Selskaper
- sammenlign
- sammenligne
- sammenlignet
- fullføre
- Terminado
- komponenter
- konsept
- konferanser
- Konfigurasjon
- konfigurert
- består
- Konsoll
- inneholde
- inneholdt
- inneholder
- innhold
- innholdsskaping
- konvertere
- konvertert
- konvertering
- Tilsvarende
- kunne
- dekker
- skape
- opprettet
- skaper
- Opprette
- skaperverket
- Credentials
- kunde
- Kunder
- Dallas
- dashbord
- oversikter
- dato
- Data Analytics
- datavitenskap
- Database
- tiår
- dekk
- Misligholde
- leverer
- leverer
- demonstrere
- avhengig
- utplassere
- utplassert
- utplasserings
- Distribueres
- beskrive
- utforming
- designet
- detalj
- detaljert
- detaljer
- diagram
- DIKT
- gJORDE
- forskjell
- forskjellig
- kringkasting
- digitalt
- Dimensjon
- dimensjoner
- oppdage
- diskutert
- Vise
- do
- dokumenter
- gjør
- domener
- nedlasting
- nedlastinger
- under
- e
- hver enkelt
- elementer
- innebygd
- embedding
- muliggjøre
- aktivert
- kodet
- oppmuntre
- slutt
- Endpoint
- Motor
- sikre
- Enterprise
- bedriftskunder
- feil
- Eter (ETH)
- Event
- hendelser
- undersøke
- eksempel
- Unntatt
- unntak
- finnes
- erfaring
- Utforske
- utvide
- eksternt
- trekke ut
- Familiær
- Felt
- filet
- Filer
- finansiell
- finansielle tjenester
- Finn
- fokuserer
- følge
- etter
- følger
- Til
- skjema
- format
- Fundament
- fire
- Gratis
- fra
- fullt
- fullt
- framtid
- generere
- generert
- genererer
- generasjonen
- generative
- Generativ AI
- Georgetown
- få
- GitHub
- skal
- grafer
- veiledning
- Ha
- he
- nyttig
- hjelpe
- her.
- skjult
- høyere
- Hits
- vert
- vert
- Hosting
- Vertskapet
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hub
- Klem ansikt
- i
- IAM
- Identitet
- if
- illustrerer
- bilde
- bilder
- umiddelbart
- iverksette
- gjennomføring
- redskaper
- in
- inkludere
- inkluderer
- Inkludert
- indeks
- Indekser
- informasjon
- Innovasjon
- innovasjoner
- inngang
- f.eks
- forekomster
- instruksjoner
- samhandle
- interaksjon
- internt
- inn
- investering
- IT
- sammenføyning
- jpg
- JSON
- juni
- Språk
- stor
- Ventetid
- lansere
- LÆRE
- læring
- foreleser
- i likhet med
- LINK
- Llama
- lokal
- lavere
- maskin
- maskinlæring
- gjøre
- administrer
- fikk til
- mange
- Match
- matchende
- mekanisme
- Meny
- metadata
- metode
- ML
- modaliteter
- modell
- modeller
- mer
- mest
- MS
- flere
- navn
- innfødt
- Naviger
- Navigasjon
- Trenger
- Ny
- none
- note
- bærbare
- notatbøker
- varslinger
- nå
- nummerert
- tall
- gjenstander
- of
- tilby
- on
- På etterspørsel
- ONE
- bare
- åpen
- åpen kildekode
- or
- organisasjon
- OS
- vår
- ut
- utfall
- produksjon
- enn
- brød
- parameter
- parametere
- del
- partikkel~~POS=TRUNC
- partner
- partnere
- deler
- bestått
- lidenskapelig
- banen
- for
- utføre
- ytelse
- utført
- tillatelser
- prospektet
- fase
- Fysikk
- Bilder
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- Post
- innlegg
- potensielt
- makt
- kraftig
- Predictor
- presentere
- presentert
- forrige
- Før
- prosess
- behandlet
- Prosesser
- prosessering
- program
- egenskaper
- gi
- forutsatt
- gir
- gi
- sette
- kvarker
- spørsmål
- spørring
- spørsmål
- spørsmål
- Rask
- fille
- område
- raskt
- Lesning
- klar
- virkelige verden
- mottatt
- refererte
- region
- i slekt
- relevant
- forbli
- erstatte
- anmode
- påkrevd
- Ressurser
- Svare
- svar
- svar
- resultere
- resulterende
- Resultater
- gjenfinning
- retur
- Rich
- roller
- Kjør
- rennende
- sagemaker
- SageMaker Inference
- samme
- sier
- Skala
- Vitenskap
- skjermbilder
- script
- Søk
- Sekund
- Seksjon
- seksjoner
- sektor
- se
- velg
- velge
- senior
- Sequence
- Serien
- server~~POS=TRUNC
- serverer
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- innstillinger
- Del
- hun
- bør
- vist
- Viser
- lignende
- Enkelt
- ganske enkelt
- enkelt
- Størrelse
- Skyv
- Lysbilder
- tekstutdrag
- So
- løsning
- Solutions
- noen
- kilde
- spesialist
- spesifikk
- spesifisert
- stabil
- stable
- oppstart
- Tilstand
- status
- Trinn
- Steps
- lagring
- oppbevare
- lagret
- butikker
- Strategisk
- String
- senere
- suksess
- vellykket
- slik
- Summit
- Støtte
- sikker
- bord
- Ta
- Snakk
- oppgaver
- Teknisk
- Teknologi
- mal
- maler
- test
- tester
- texas
- tekst
- tekstlig
- Det
- De
- informasjonen
- deres
- deretter
- Disse
- denne
- De
- gjennomstrømning
- tid
- titan
- tittelen
- til
- dagens
- sammen
- toronto
- tradisjonelt
- traversere
- utløse
- utløsende
- sant
- prøve
- SVING
- to
- typen
- avdekke
- forstå
- forståelse
- universitet
- Oppdater
- lastet opp
- URL
- bruke
- brukt
- Bruker
- bruker
- ved hjelp av
- verdi
- variabel
- variasjon
- versjon
- av
- video
- Se
- syn
- visuell
- washington
- måter
- we
- web
- webtjenester
- VI VIL
- Hva
- Hva er
- hvilken
- mens
- vil
- med
- innenfor
- arbeidet
- arbeidsflyt
- arbeid
- du
- Din
- zephyrnet