
Bilde laget med DALL-E3
Kunstig intelligens har vært en fullstendig revolusjon i teknologiverdenen.
Dens evne til å etterligne menneskelig intelligens og utføre oppgaver som en gang ble ansett som kun menneskelige domener, forbløffer fortsatt de fleste av oss.
Uansett hvor gode disse sene AI-spranget har vært, er det alltid rom for forbedring.
Og det er nettopp her prompte ingeniørarbeid starter!
Gå inn i dette feltet som kan forbedre produktiviteten til AI-modeller betydelig.
La oss oppdage alt sammen!
Prompt engineering er et raskt voksende domene innen AI som fokuserer på å forbedre effektiviteten og effektiviteten til språkmodeller. Det handler om å lage perfekte spørsmål for å veilede AI-modeller for å produsere de ønskede resultatene.
Tenk på det som å lære å gi bedre instruksjoner til noen for å sikre at de forstår og utfører en oppgave riktig.
Hvorfor prompt engineering er viktig
- Forbedret produktivitet: Ved å bruke meldinger av høy kvalitet kan AI-modeller generere mer nøyaktige og relevante svar. Dette betyr mindre tid brukt på korreksjoner og mer tid på å utnytte AIs evner.
- Kostnadseffektivitet: Trening av AI-modeller er ressurskrevende. Rask ingeniørarbeid kan redusere behovet for omskolering ved å optimalisere modellytelsen gjennom bedre meldinger.
- allsidighet: Et godt utformet spørsmål kan gjøre AI-modeller mer allsidige, slik at de kan takle et bredere spekter av oppgaver og utfordringer.
Før vi dykker inn i de mest avanserte teknikkene, la oss huske to av de mest nyttige (og grunnleggende) raske ingeniørteknikkene.
Sekvensiell tenkning med "La oss tenke steg for steg"
I dag er det velkjent at LLM-modellers nøyaktighet er betydelig forbedret når man legger til ordsekvensen "La oss tenke steg for steg".
Hvorfor... spør du kanskje?
Vel, dette er fordi vi tvinger modellen til å dele opp enhver oppgave i flere trinn, og dermed sørge for at modellen har nok tid til å behandle hver av dem.
For eksempel kan jeg utfordre GPT3.5 med følgende ledetekst:
Hvis John har 5 pærer, spiser 2, kjøper 5 til og gir 3 til vennen sin, hvor mange pærer har han?
Modellen vil gi meg svar med en gang. Men hvis jeg legger til det siste "La oss tenke trinn for trinn", tvinger jeg modellen til å generere en tenkeprosess med flere trinn.
Spørre om få skudd
Mens Zero-shot-spørringen refererer til å be modellen om å utføre en oppgave uten å gi noen kontekst eller forkunnskap, innebærer få-shot-promptteknikken at vi presenterer LLM med noen eksempler på ønsket utgang sammen med et spesifikt spørsmål.
For eksempel, hvis vi ønsker å komme opp med en modell som definerer et hvilket som helst begrep ved å bruke en poetisk tone, kan det være ganske vanskelig å forklare. Ikke sant?
Vi kan imidlertid bruke følgende få-shot-instruksjoner for å styre modellen i den retningen vi ønsker.
Din oppgave er å svare i en konsistent stil tilpasset følgende stil.
: Lær meg om motstandskraft.
: Spenst er som et tre som bøyer seg med vinden, men som aldri knekker.
Det er evnen til å komme tilbake fra motgang og fortsette å bevege seg fremover.
: Innspillet ditt her.
Hvis du ikke har prøvd det ut ennå, kan du utfordre GPT.
Men siden jeg er ganske sikker på at de fleste av dere allerede kan disse grunnleggende teknikkene, vil jeg prøve å utfordre dere med noen avanserte teknikker.
1. Tankekjede (CoT) Spørring
Introdusert av Google i 2022, innebærer denne metoden å instruere modellen til å gjennomgå flere resonnementstadier før den leverer den endelige responsen.
Høres kjent ut ikke sant? I så fall har du helt rett.
Det er som å slå sammen både Sequential Thinking og Few-Shot Prompting.
Hvordan?
I hovedsak dirigerer CoT-forespørselen LLM til å behandle informasjon sekvensielt. Dette betyr at vi eksemplifiserer hvordan vi løser et første problem med flere trinns resonnement, og deretter sender modellen vår virkelige oppgave, og forventer at den skal etterligne en sammenlignbar tankekjede når vi svarer på den faktiske spørringen vi vil at den skal løse.
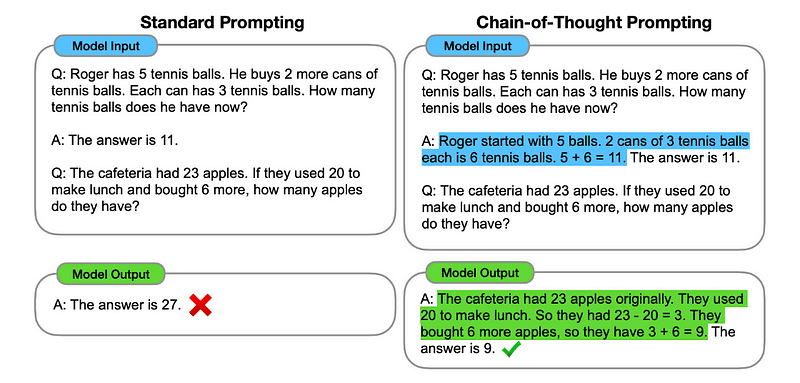
Bilde tatt fra papir.
Så, ved å følge det aller første eksemplet, kunne vi gi en melding med det første problemet og en sekvensiell forklaring på hvordan det skal løses. Deretter kan vi sende innspill og se hvordan magi skjer!
Hvis John har 5 pærer, spiser 2, kjøper 5 til og gir 3 til vennen sin, hvor mange pærer har han? La oss tenke steg for steg.
La oss gå steg for steg. John starter med 5 pærer. Han spiser 2 pærer, så han har 5–2 = 3 pærer igjen. Så kjøper han 5 pærer til. Så han har nå 3 + 5 = 8 pærer. Til slutt gir han 3 pærer til vennen sin. Derfor har han 8–3 = 5 pærer igjen. Så, etter alle disse trinnene, har John 5 pærer.
Ditt innspill her.
Imidlertid må de fleste av dere tenke... Må jeg tenke på en sekvensiell måte å løse problemer på hver gang jeg vil spørre om noe på ChatGPT?
Vel... du er ikke den første! Og dette fører oss til...
2. Automatisk tankekjede (Auto-CoT)
I 2022, Zhang og kolleger introduserte en metode for å unngå denne manuelle prosessen. Det er to hovedgrunner til å unngå manuelle oppgaver:
- Det kan være kjedelig.
- Det kan gi dårlige resultater - for eksempel når vår mentale prosess er feil.
De foreslo å bruke LLM-er kombinert med "La oss tenke steg for steg"-oppfordringen for å sekvensielt produsere resonnementskjeder for hver demonstrasjon.
Dette betyr å spørre ChatGPT hvordan man løser ethvert problem sekvensielt, og deretter bruke dette samme eksempelet for å lære det hvordan man løser et hvilket som helst annet problem.
3. Selvkonsistens
Selvkonsistens er en annen interessant prompteteknikk som tar sikte på å forbedre tankekjeden som gir mer komplekse resonnementproblemer.
Så ... hva er hovedforskjellen?
Hovedideen under Self-Consistency er å være klar over at vi kan trene modellen med et feil eksempel. Tenk deg at jeg løser det forrige problemet med en feil mental prosess:
Hvis John har 5 pærer, spiser 2, kjøper 5 til og gir 3 til vennen sin, hvor mange pærer har han? La oss tenke steg for steg.
Start med 5 pærer. John spiser 2 pærer. Deretter gir han 3 pærer til vennen sin. Disse handlingene kan kombineres: 2 (spist) + 3 (gitt) = 5 pærer totalt påvirket. Trekk nå det totale antallet pærer som er berørt fra de første 5 pærene: 5 (initielle) – 5 (berørte) = 0 pærer igjen.
Da vil enhver annen oppgave jeg sender til modellen være feil.
Dette er grunnen til at Self-Consistency involverer prøvetaking fra ulike resonnementbaner, hver av dem inneholder en tankekjede, og deretter la LLM velge den beste og mest konsistente veien for å løse problemet.
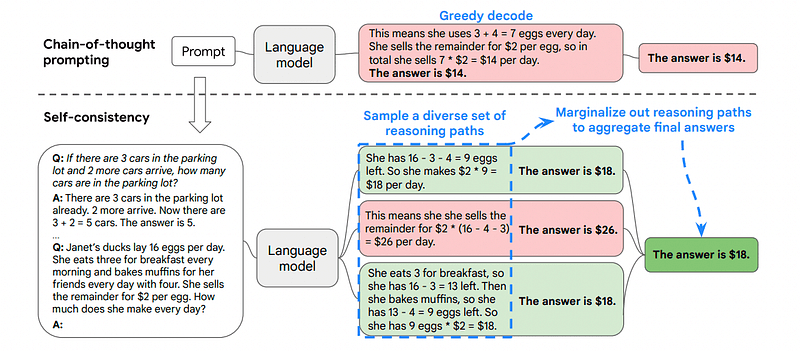
Bilde tatt fra papir
I dette tilfellet, og etter det aller første eksemplet igjen, kan vi vise modellen forskjellige måter å løse problemet på.
Hvis John har 5 pærer, spiser 2, kjøper 5 til og gir 3 til vennen sin, hvor mange pærer har han?
Start med 5 pærer. John spiser 2 pærer, og etterlater ham med 5–2 = 3 pærer. Han kjøper 5 pærer til, noe som bringer totalen til 3 + 5 = 8 pærer. Til slutt gir han 3 pærer til vennen sin, så han har 8–3 = 5 pærer igjen.
Hvis John har 5 pærer, spiser 2, kjøper 5 til og gir 3 til vennen sin, hvor mange pærer har han?
Start med 5 pærer. Deretter kjøper han 5 pærer til. John spiser 2 pærer nå. Disse handlingene kan kombineres: 2 (spist) + 5 (kjøpt) = 7 pærer totalt. Trekk pæren som Jon har spist fra den totale mengden pærer 7 (total mengde) – 2 (spist) = 5 pærer igjen.
Ditt innspill her.
Og her kommer den siste teknikken.
4. Generell kunnskapsforespørsel
En vanlig praksis for prompt engineering er å forsterke en spørring med ytterligere kunnskap før den endelige API-kallingen sendes til GPT-3 eller GPT-4.
Ifølge Jiacheng Liu og Co, vi kan alltid legge til litt kunnskap til enhver forespørsel slik at LLM vet bedre om spørsmålet.
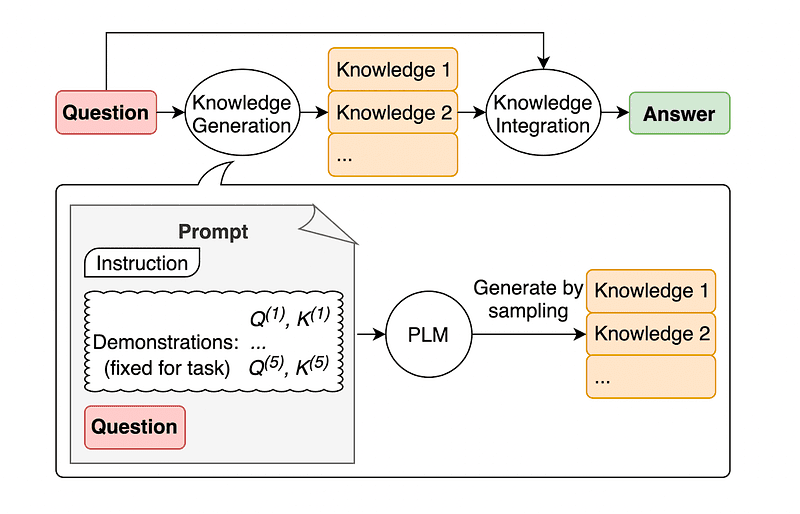
Bilde tatt fra papir.
Så for eksempel, når du spør ChatGPT om en del av golf prøver å få et høyere poengsum enn andre, vil det validere oss. Men hovedmålet med golf er det motsatte. Dette er grunnen til at vi kan legge til litt tidligere kunnskap og fortelle det "Spilleren med den laveste poengsummen vinner".

Så.. hva er det morsomme hvis vi forteller modellen nøyaktig svaret?
I dette tilfellet brukes denne teknikken for å forbedre måten LLM samhandler med oss på.
Så i stedet for å trekke supplerende kontekst fra en ekstern database, anbefaler artikkelforfatterne at LLM produserer sin egen kunnskap. Denne egengenererte kunnskapen blir deretter integrert i spørsmålet for å styrke sunn fornuft og gi bedre resultater.
Så dette er hvordan LLM-er kan forbedres uten å øke opplæringsdatasettet!
Rask engineering har dukket opp som en sentral teknikk for å forbedre mulighetene til LLM. Ved å iterere og forbedre forespørsler kan vi kommunisere på en mer direkte måte til AI-modeller og dermed oppnå mer nøyaktige og kontekstuelt relevante utdata, noe som sparer både tid og ressurser.
Både for teknologientusiaster, dataforskere og innholdsskapere kan det å forstå og mestre prompte engineering være en verdifull ressurs for å utnytte det fulle potensialet til AI.
Ved å kombinere nøye utformede inputspørringer med disse mer avanserte teknikkene, vil det å ha ferdighetene med rask ingeniørkunst utvilsomt gi deg en fordel i de kommende årene.
Josep Ferrer er en analyseingeniør fra Barcelona. Han ble uteksaminert i fysikkingeniør og jobber for tiden i Data Science-feltet brukt på menneskelig mobilitet. Han er en deltidsinnholdsskaper med fokus på datavitenskap og teknologi. Du kan kontakte ham på Linkedin, Twitter or Medium.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- evne
- Om oss
- nøyaktighet
- nøyaktig
- handlinger
- faktiske
- legge til
- legge
- Ytterligere
- avansert
- Etter
- en gang til
- AI
- AI-modeller
- mål
- justert
- alike
- Alle
- tillate
- langs
- allerede
- alltid
- am
- beløp
- an
- analytics
- og
- En annen
- besvare
- noen
- api
- anvendt
- ER
- AS
- spør
- spør
- eiendel
- forfattere
- Automatisk
- unngå
- klar
- borte
- tilbake
- dårlig
- barcelona
- grunnleggende
- BE
- fordi
- vært
- før du
- være
- BEST
- Bedre
- styrke
- øke
- Kjedelig
- både
- kjøpt
- Sprette
- Break
- pauser
- Bringer
- bredere
- men
- buys
- by
- ring
- CAN
- evner
- nøye
- saken
- kjede
- kjeder
- utfordre
- utfordringer
- ChatGPT
- Velg
- kollegaer
- kombinert
- kombinere
- Kom
- kommer
- kommer
- Felles
- kommunisere
- sammenlign
- fullføre
- komplekse
- ansett
- konsistent
- kontakt
- innhold
- innholdsskapere
- kontekst
- Korreksjoner
- riktig
- kunne
- opprettet
- skaperen
- skaperne
- I dag
- dato
- datavitenskap
- Database
- definerer
- levere
- designet
- ønsket
- forskjell
- forskjellig
- direkte
- retning
- oppdage
- dykking
- do
- gjør
- domene
- domener
- ned
- hver enkelt
- Edge
- effektivitet
- effektivitet
- dukket
- ingeniør
- Ingeniørarbeid
- forbedre
- styrke
- nok
- sikre
- entusiaster
- nøyaktig
- eksempel
- eksempler
- henrette
- venter
- Forklar
- forklaring
- kjent
- Noen få
- felt
- slutt~~POS=TRUNC
- Endelig
- Først
- fokuserte
- fokuserer
- etter
- Til
- tvang
- Forward
- venn
- fra
- fullt
- morsomt
- general
- generere
- få
- Gi
- gitt
- gir
- Go
- mål
- golf
- god
- veilede
- Hard
- Utnyttelse
- Ha
- å ha
- he
- her.
- høykvalitets
- høyere
- ham
- hans
- Hvordan
- Hvordan
- Men
- HTTPS
- menneskelig
- menneskelig intelligens
- i
- Tanken
- if
- forestille
- forbedre
- forbedret
- forbedring
- bedre
- in
- økende
- informasjon
- innledende
- inngang
- f.eks
- instruksjoner
- integrert
- Intelligens
- interaktiv
- interessant
- inn
- introdusert
- innebærer
- IT
- DET ER
- John
- jon
- bare
- KDnuggets
- Hold
- sparke
- Kicks
- Vet
- kunnskap
- vet
- Språk
- Siste
- Late
- Fører
- Hoppe
- læring
- forlater
- venstre
- mindre
- la
- utleie
- utnytte
- i likhet med
- lavere
- magi
- Hoved
- gjøre
- Making
- måte
- håndbok
- mange
- Maste
- Saken
- me
- midler
- mental
- sammenslåing
- metode
- kunne
- mobilitet
- modell
- modeller
- mer
- mest
- flytting
- flere
- må
- Trenger
- aldri
- Nei.
- nå
- få
- of
- on
- gang
- motsatt
- optimalisere
- or
- Annen
- andre
- vår
- ut
- produksjon
- utganger
- utenfor
- egen
- Papir
- del
- banen
- perfekt
- utføre
- ytelse
- Fysikk
- sentral
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Point
- potensiell
- praksis
- nettopp
- presentere
- pen
- forrige
- Problem
- problemer
- prosess
- produsere
- produktivitet
- gi
- gi
- trekke
- spørsmål
- ganske
- område
- heller
- ekte
- grunner
- anbefaler
- redusere
- refererer
- relevant
- anmode
- resiliens
- ressurskrevende
- Ressurser
- svare
- svar
- svar
- Resultater
- omskolering
- Revolution
- ikke sant
- rom
- s
- samme
- besparende
- Vitenskap
- Vitenskap og teknologi
- forskere
- Resultat
- se
- send
- sending
- Sequence
- sett
- flere
- Vis
- betydelig
- ferdighet
- So
- utelukkende
- LØSE
- løse
- noen
- Noen
- noe
- spesifikk
- brukt
- stadier
- Begynn
- starter
- styre
- Trinn
- Steps
- Still
- stil
- sikker
- takle
- tatt
- Oppgave
- oppgaver
- tech
- teknikk
- teknikker
- Teknologi
- fortelle
- begrep
- enn
- Det
- De
- Dem
- deretter
- Der.
- derfor
- Disse
- de
- tror
- tenker
- denne
- trodde
- Gjennom
- Dermed
- tid
- til
- TONE
- Totalt
- HELT KLART
- Tog
- Kurs
- Treet
- prøvd
- prøve
- prøver
- to
- ultimate
- etter
- gjennomgå
- forstå
- forståelse
- utvilsomt
- us
- bruke
- brukt
- ved hjelp av
- VALIDERE
- Verdifull
- ulike
- allsidig
- veldig
- ønsker
- Vei..
- måter
- we
- velkjent
- var
- når
- hvilken
- hvorfor
- vil
- vind
- med
- innenfor
- uten
- ord
- arbeid
- verden
- Feil
- år
- ennå
- Utbytte
- du
- Din
- zephyrnet







