Amazon SageMaker Studio gir en fullstendig administrert løsning for dataforskere for interaktivt å bygge, trene og distribuere maskinlæringsmodeller (ML). Amazon SageMaker bærbare jobber tillate dataforskere å kjøre sine bærbare datamaskiner på forespørsel eller etter en tidsplan med noen få klikk i SageMaker Studio. Med denne lanseringen kan du programmert kjøre notatblokker som jobber ved å bruke APIer levert av Amazon SageMaker-rørledninger, ML arbeidsflyt orkestreringsfunksjonen til Amazon SageMaker. Videre kan du lage en flertrinns ML-arbeidsflyt med flere avhengige notatbøker ved å bruke disse API-ene.
SageMaker Pipelines er et naturlig orkestreringsverktøy for arbeidsflyt for å bygge ML-pipelines som drar fordel av direkte SageMaker-integrasjon. Hver SageMaker-rørledning er sammensatt av trinn, som tilsvarer individuelle oppgaver som behandling, opplæring eller databehandling ved hjelp av Amazon EMR. SageMaker bærbare jobber er nå tilgjengelige som en innebygd trinntype i SageMaker-rørledninger. Du kan bruke dette notatbokjobbtrinnet til å enkelt kjøre notatblokker som jobber med bare noen få linjer med kode ved å bruke Amazon SageMaker Python SDK. I tillegg kan du sy sammen flere avhengige notatbøker for å lage en arbeidsflyt i form av Directed Acyclic Graphs (DAGs). Du kan deretter kjøre disse notatbokjobbene eller DAG-ene, og administrere og visualisere dem ved hjelp av SageMaker Studio.
Dataforskere bruker for tiden SageMaker Studio til interaktivt å utvikle Jupyter-notatbøkene og bruker deretter SageMaker-notatbokjobber til å kjøre disse notatbøkene som planlagte jobber. Disse jobbene kan kjøres umiddelbart eller på en tilbakevendende tidsplan uten behov for dataarbeidere til å refaktorisere kode som Python-moduler. Noen vanlige brukstilfeller for å gjøre dette inkluderer:
- Kjører lange løpende notatbøker i bakgrunnen
- Regelmessig kjørende modellslutning for å generere rapporter
- Oppskalering fra å utarbeide små prøvedatasett til å jobbe med store data i petabyte-skala
- Omskolering og distribusjon av modeller på noen tråkkfrekvens
- Planlegging av jobber for modellkvalitet eller datadriftsovervåking
- Utforsker parameterplassen for bedre modeller
Selv om denne funksjonaliteten gjør det enkelt for dataarbeidere å automatisere frittstående bærbare datamaskiner, består ML-arbeidsflyter ofte av flere bærbare datamaskiner, som hver utfører en spesifikk oppgave med komplekse avhengigheter. For eksempel bør en bærbar PC som overvåker modelldatadrift ha et forhåndstrinn som tillater ekstrahering, transformasjon og lasting (ETL) og prosessering av nye data og et ettertrinn med modelloppdatering og opplæring i tilfelle en betydelig drift blir lagt merke til . Videre kan dataforskere kanskje ønske å utløse hele denne arbeidsflyten på en tilbakevendende tidsplan for å oppdatere modellen basert på nye data. For at du enkelt skal kunne automatisere notatbøkene og lage slike komplekse arbeidsflyter, er SageMaker notatbokjobber nå tilgjengelige som et trinn i SageMaker Pipelines. I dette innlegget viser vi hvordan du kan løse følgende brukstilfeller med noen få linjer med kode:
- Kjør en frittstående notatbok programmatisk umiddelbart eller etter en regelmessig tidsplan
- Lag flertrinns arbeidsflyter av bærbare datamaskiner som DAG-er for kontinuerlig integrasjon og kontinuerlig levering (CI/CD) som kan administreres via SageMaker Studio UI
Løsningsoversikt
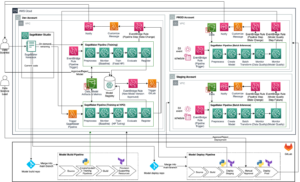
Følgende diagram illustrerer løsningsarkitekturen vår. Du kan bruke SageMaker Python SDK til å kjøre en enkelt bærbar jobb eller en arbeidsflyt. Denne funksjonen oppretter en SageMaker-treningsjobb for å kjøre den bærbare datamaskinen.
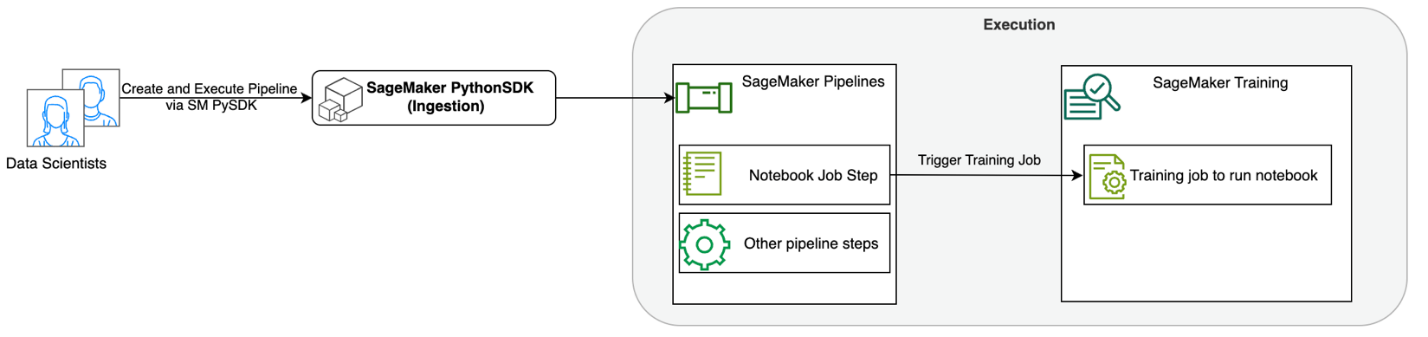
I de følgende delene går vi gjennom et eksempel på ML-bruk og viser frem fremgangsmåten for å lage en arbeidsflyt med bærbare jobber, sende parametere mellom forskjellige trinn for bærbare datamaskiner, planlegge arbeidsflyten din og overvåke den via SageMaker Studio.
For ML-problemet vårt i dette eksemplet bygger vi en sentimentanalysemodell, som er en type tekstklassifiseringsoppgave. De vanligste bruksområdene for sentimentanalyse inkluderer overvåking av sosiale medier, kundestøtteadministrasjon og analyse av tilbakemeldinger fra kunder. Datasettet som brukes i dette eksemplet er Stanford Sentiment Treebank (SST2) datasettet, som består av filmanmeldelser sammen med et heltall (0 eller 1) som indikerer den positive eller negative følelsen til anmeldelsen.
Følgende er et eksempel på en data.csv fil som tilsvarer SST2-datasettet, og viser verdier i de to første kolonnene. Merk at filen ikke skal ha noen overskrift.
| Kolonne 1 | Kolonne 2 |
| 0 | skjule nye sekreter fra foreldreenhetene |
| 0 | inneholder ingen vidd, bare anstrengte gags |
| 1 | som elsker karakterene sine og formidler noe ganske vakkert om menneskets natur |
| 0 | forblir helt fornøyd med å forbli den samme hele veien |
| 0 | på de verste hevn-of-the-nerds-klisjeene filmskaperne kunne mudre opp |
| 0 | det er altfor tragisk til å fortjene en slik overfladisk behandling |
| 1 | demonstrerer at regissøren av slike Hollywood-blockbustere som patriot-spill fortsatt kan lage en liten, personlig film med en følelsesladet bølge. |
I dette ML-eksemplet må vi utføre flere oppgaver:
- Utfør funksjonsteknikk for å forberede dette datasettet i et format som modellen vår kan forstå.
- Etter-funksjonsteknikk, kjør et opplæringstrinn som bruker Transformers.
- Sett opp gruppeslutninger med den finjusterte modellen for å hjelpe med å forutsi stemningen for nye anmeldelser som kommer inn.
- Sett opp et dataovervåkingstrinn slik at vi regelmessig kan overvåke de nye dataene våre for eventuelle kvalitetsavvik som kan kreve at vi trener modellvektene på nytt.
Med denne lanseringen av en bærbar jobb som et trinn i SageMaker-pipelines, kan vi orkestrere denne arbeidsflyten, som består av tre forskjellige trinn. Hvert trinn i arbeidsflyten er utviklet i en annen notatbok, som deretter konverteres til uavhengige trinn for notatbokjobber og kobles til som en pipeline:
- forbehandling – Last ned det offentlige SST2-datasettet fra Amazon enkel lagringstjeneste (Amazon S3) og lag en CSV-fil som notatboken i trinn 2 kan kjøre. SST2-datasettet er et tekstklassifiseringsdatasett med to etiketter (0 og 1) og en kolonne med tekst for å kategorisere.
- Kurs – Ta den formede CSV-filen og kjør finjustering med BERT for tekstklassifisering ved å bruke Transformers-biblioteker. Vi bruker en notisbok for forberedelse av testdata som en del av dette trinnet, som er en avhengighet for trinnet for finjustering og batchslutning. Når finjusteringen er fullført, kjøres denne notatboken ved hjelp av run magic og forbereder et testdatasett for prøveslutning med den finjusterte modellen.
- Transformer og overvåk – Utfør batch-inferens og sett opp datakvalitet med modellovervåking for å få et forslag til grunnleggende datasett.
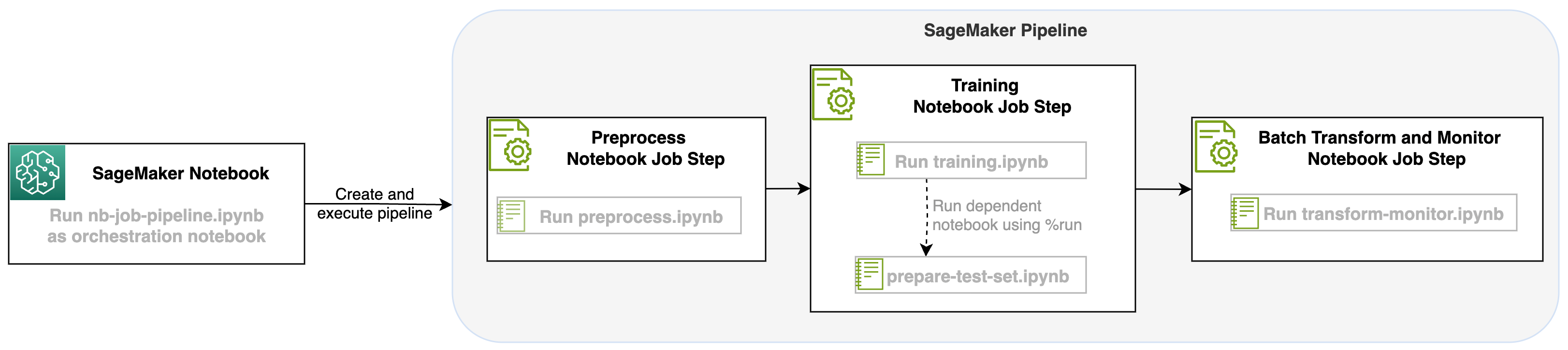
Kjør notatbøkene
Eksempelkoden for denne løsningen er tilgjengelig på GitHub.
Å lage et SageMaker notatbok-jobbtrinn ligner på å lage andre SageMaker Pipeline-trinn. I dette notatbokeksemplet bruker vi SageMaker Python SDK for å orkestrere arbeidsflyten. For å lage et notatboktrinn i SageMaker Pipelines, kan du definere følgende parametere:
- Skriv inn notatbok – Navnet på notatboken som dette notatboktrinnet skal orkestrere. Her kan du passere i den lokale stien til inndatablokken. Hvis denne notatboken har andre bærbare datamaskiner den kjører, kan du eventuelt sende disse i
AdditionalDependenciesparameter for trinnet for den bærbare jobben. - Bilde-URI – Docker-bildet bak trinnet for den bærbare jobben. Dette kan være de forhåndsdefinerte bildene som SageMaker allerede gir, eller et tilpasset bilde som du har definert og presset til Amazon Elastic Container Registry (Amazon ECR). Se avsnittet om vurderinger på slutten av dette innlegget for støttede bilder.
- Kjernenavn – Navnet på kjernen du bruker på SageMaker Studio. Denne kjernespesifikasjonen er registrert i bildet du har oppgitt.
- Forekomsttype (valgfritt) - Det Amazon Elastic Compute Cloud (Amazon EC2) forekomsttype bak den bærbare jobben som du har definert og skal kjøre.
- Parametere (valgfritt) – Parametre du kan sende inn som vil være tilgjengelig for den bærbare datamaskinen. Disse kan defineres i nøkkelverdi-par. I tillegg kan disse parameterne endres mellom ulike bærbare jobbkjøringer eller pipelinekjøringer.
Eksemplet vårt har totalt fem notatbøker:
- nb-job-pipeline.ipynb – Dette er hovednotisboken vår der vi definerer vår pipeline og arbeidsflyt.
- preprocess.ipynb – Denne notatboken er det første trinnet i arbeidsflyten vår og inneholder koden som vil trekke det offentlige AWS-datasettet og lage en CSV-fil ut av det.
- training.ipynb – Denne notatboken er det andre trinnet i arbeidsflyten vår og inneholder kode for å ta CSV-en fra forrige trinn og gjennomføre lokal opplæring og finjustering. Dette trinnet er også avhengig av
prepare-test-set.ipynbnotebook for å trekke ned et testdatasett for prøveslutning med den finjusterte modellen. - prepare-test-set.ipynb – Denne notatboken lager et testdatasett som opplæringsnotatboken vår vil bruke i det andre pipeline-trinnet og bruke for prøveslutning med den finjusterte modellen.
- transform-monitor.ipynb – Denne bærbare er det tredje trinnet i arbeidsflyten vår og tar basis BERT-modellen og kjører en SageMaker batch-transformeringsjobb, samtidig som den setter opp datakvalitet med modellovervåking.
Deretter går vi gjennom hovednotisboken nb-job-pipeline.ipynb, som kombinerer alle undernotatbøkene til en pipeline og kjører ende-til-ende arbeidsflyten. Merk at selv om følgende eksempel bare kjører den bærbare datamaskinen én gang, kan du også planlegge pipelinen til å kjøre den gjentatte ganger. Referere til SageMaker-dokumentasjon for detaljerte instruksjoner.
For vårt første jobbtrinn for bærbar PC sender vi inn en parameter med en standard S3-bøtte. Vi kan bruke denne bøtten til å dumpe alle gjenstander vi vil ha tilgjengelig for våre andre rørledningstrinn. For den første notatboken (preprocess.ipynb), trekker vi ned AWS offentlige SST2-togdatasett og lager en opplærings-CSV-fil av det som vi skyver til denne S3-bøtten. Se følgende kode:
Vi kan deretter konvertere denne notatboken til en NotebookJobStep med følgende kode i hovednotatboken vår:
Nå som vi har en eksempel-CSV-fil, kan vi begynne å trene modellen vår i treningsnotisboken vår. Treningsnotisboken vår tar inn den samme parameteren med S3-bøtten og trekker ned treningsdatasettet fra det stedet. Deretter utfører vi finjustering ved å bruke Transformers-trenerobjektet med følgende kodebit:
Etter finjustering ønsker vi å kjøre en batch-slutning for å se hvordan modellen presterer. Dette gjøres ved hjelp av en egen notatbok (prepare-test-set.ipynb) i den samme lokale banen som oppretter et testdatasett for å utføre slutninger om bruk av vår trente modell. Vi kan kjøre den ekstra notatboken i treningsnotisboken vår med følgende magiske celle:
Vi definerer denne ekstra bærbare avhengigheten i AdditionalDependencies parameter i vårt andre bærbare jobbtrinn:
Vi må også spesifisere at trinnet for treningsnotatbokjobben (trinn 2) avhenger av trinnet for forhåndsbehandle notatbokjobben (trinn 1) ved å bruke add_depends_on API-kall som følger:
Vårt siste trinn vil ta BERT-modellen til å kjøre en SageMaker Batch Transform, samtidig som vi setter opp datafangst og kvalitet via SageMaker Model Monitor. Merk at dette er forskjellig fra å bruke den innebygde Transform or Capture trinn via Pipelines. Notatboken vår for dette trinnet vil kjøre de samme APIene, men vil spores som et Notebook Job Step. Dette trinnet er avhengig av Training Job Step som vi tidligere har definert, så vi fanger også det med avhengig_på-flagget.
Etter at de ulike trinnene i arbeidsflyten vår er definert, kan vi opprette og kjøre ende-til-ende-rørledningen:
Overvåk rørføringen
Du kan spore og overvåke trinnkjøringene for den bærbare datamaskinen via SageMaker Pipelines DAG, som vist i følgende skjermbilde.
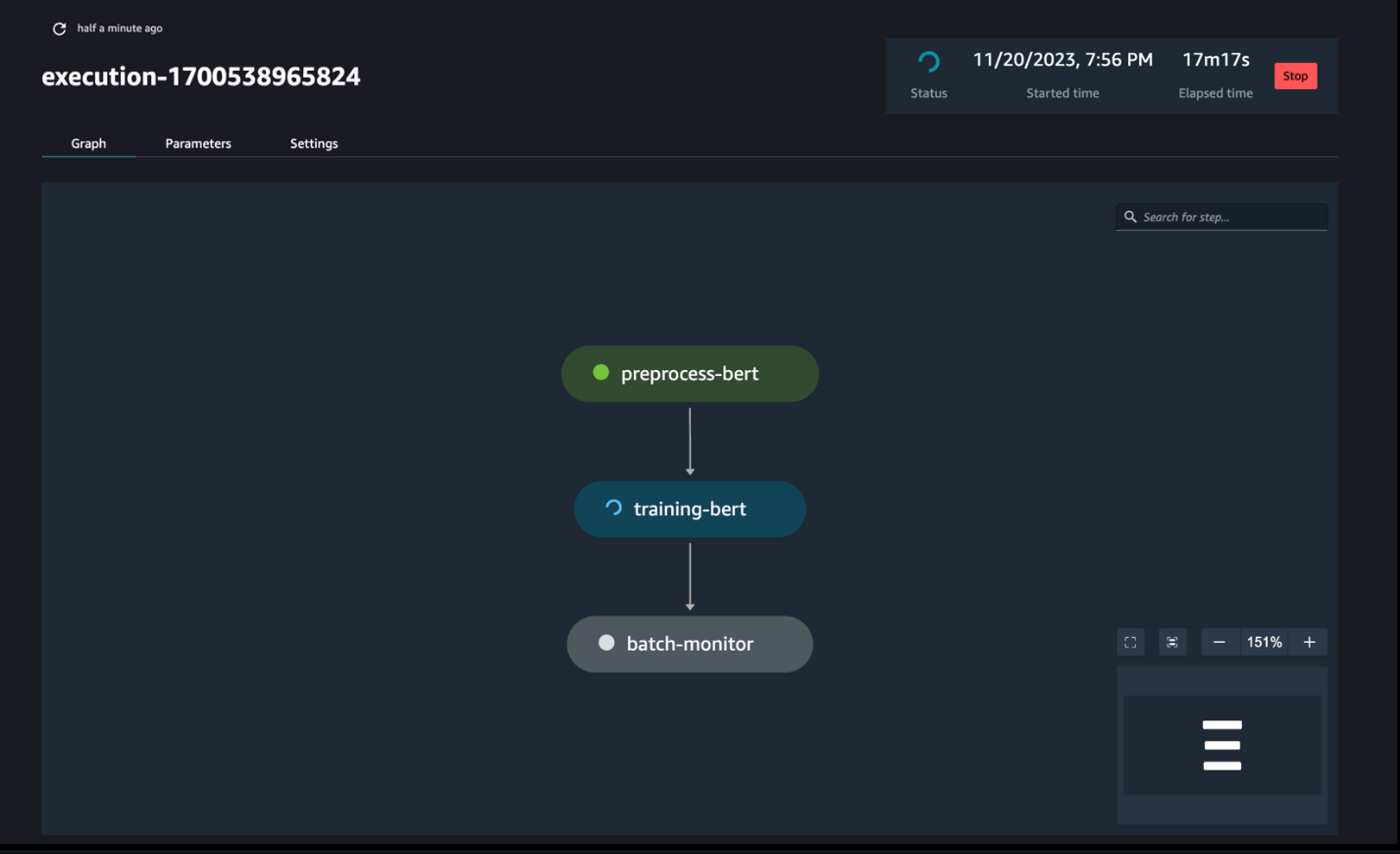
Du kan også valgfritt overvåke de individuelle kjøringene av den bærbare datamaskinen på dashbordet for den bærbare jobben og veksle mellom utdatafilene som er opprettet via SageMaker Studio-grensesnittet. Når du bruker denne funksjonaliteten utenfor SageMaker Studio, kan du definere brukerne som kan spore kjørestatusen på den bærbare jobbdashbordet ved å bruke tagger. For mer informasjon om tagger som skal inkluderes, se Se den bærbare jobben og last ned utdataene i Studio UI-dashbordet.
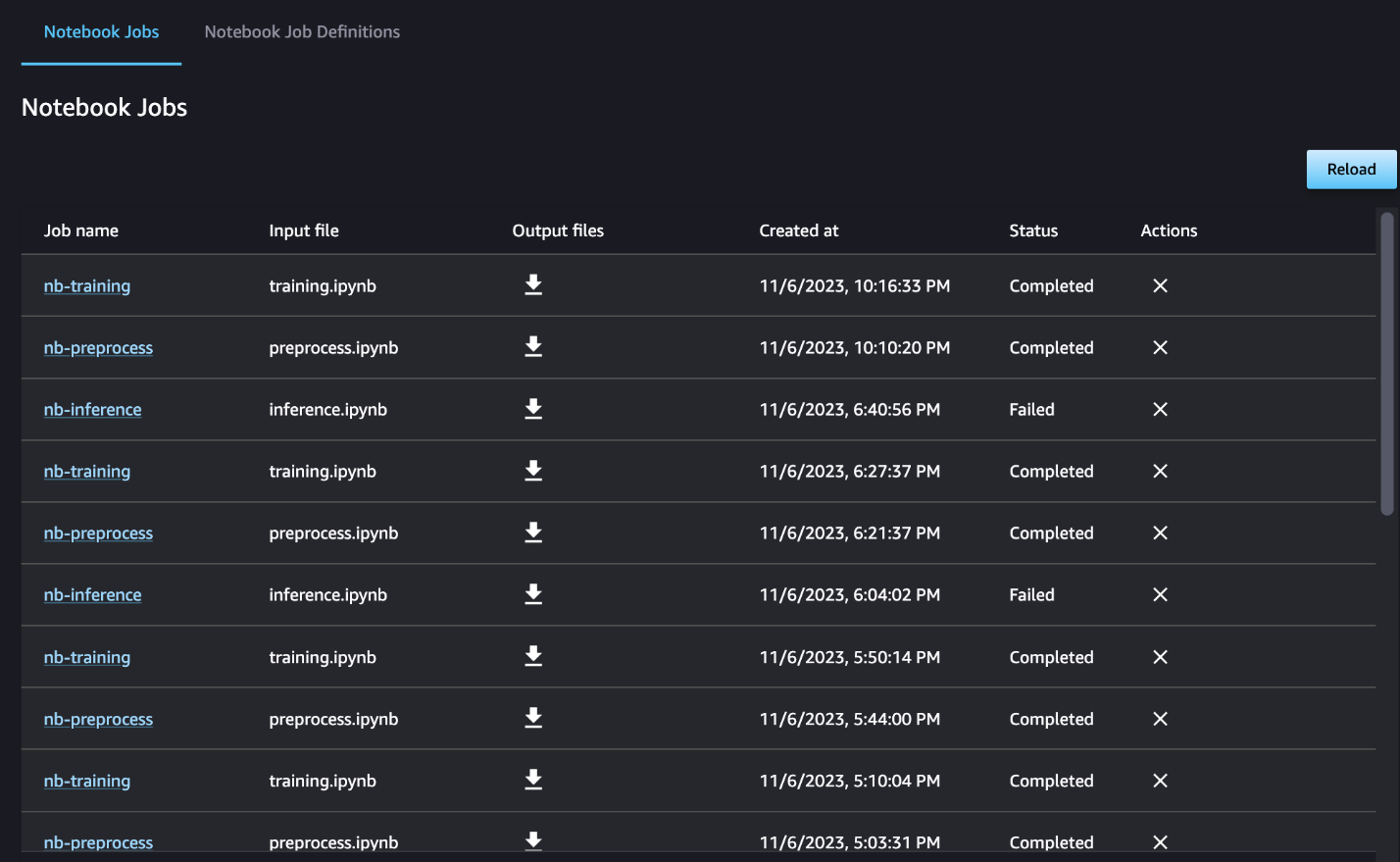
For dette eksemplet sender vi de resulterende notatbokjobbene til en katalog kalt outputs i din lokale bane med pipeline-kjøringskoden. Som vist i det følgende skjermbildet, her kan du se utdataene fra inndatablokken din og også alle parametere du definerte for det trinnet.
Rydd opp
Hvis du fulgte med eksemplet vårt, sørg for å slette den opprettede pipelinen, notatbokjobbene og s3-dataene som ble lastet ned av eksempelnotatbøkene.
betraktninger
Følgende er noen viktige hensyn for denne funksjonen:
- SDK-begrensninger – Notebook-jobbtrinnet kan bare opprettes via SageMaker Python SDK.
- Bildebegrensninger – Den bærbare jobbtrinnet støtter følgende bilder:
konklusjonen
Med denne lanseringen kan dataarbeidere nå programmert kjøre bærbare datamaskiner med noen få linjer med kode ved å bruke SageMaker Python SDK. I tillegg kan du lage komplekse flertrinns arbeidsflyter ved å bruke bærbare datamaskiner, noe som reduserer tiden det tar å gå fra en bærbar PC til en CI/CD-pipeline betraktelig. Etter å ha opprettet rørledningen, kan du bruke SageMaker Studio til å vise og kjøre DAG-er for rørledningene dine og administrere og sammenligne kjøringene. Enten du planlegger ende-til-ende ML-arbeidsflyter eller en del av det, oppfordrer vi deg til å prøve notatbokbaserte arbeidsflyter.
Om forfatterne
 Anchit Gupta er senior produktsjef for Amazon SageMaker Studio. Hun fokuserer på å aktivere interaktive datavitenskap og dataingeniørarbeidsflyter fra SageMaker Studio IDE. På fritiden liker hun å lage mat, spille brett-/kortspill og lese.
Anchit Gupta er senior produktsjef for Amazon SageMaker Studio. Hun fokuserer på å aktivere interaktive datavitenskap og dataingeniørarbeidsflyter fra SageMaker Studio IDE. På fritiden liker hun å lage mat, spille brett-/kortspill og lese.
 Ram Vegiraju er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å bygge og optimalisere sine AI/ML-løsninger på Amazon SageMaker. På fritiden elsker han å reise og skrive.
Ram Vegiraju er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å bygge og optimalisere sine AI/ML-løsninger på Amazon SageMaker. På fritiden elsker han å reise og skrive.
 Edward Sun er en senior SDE som jobber for SageMaker Studio hos Amazon Web Services. Han er fokusert på å bygge interaktiv ML-løsning og forenkle kundeopplevelsen for å integrere SageMaker Studio med populære teknologier innen datateknikk og ML-økosystem. På fritiden er Edward stor fan av camping, fotturer og fiske, og liker å tilbringe tiden med familien.
Edward Sun er en senior SDE som jobber for SageMaker Studio hos Amazon Web Services. Han er fokusert på å bygge interaktiv ML-løsning og forenkle kundeopplevelsen for å integrere SageMaker Studio med populære teknologier innen datateknikk og ML-økosystem. På fritiden er Edward stor fan av camping, fotturer og fiske, og liker å tilbringe tiden med familien.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- : har
- :er
- :hvor
- $OPP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Om oss
- tilgjengelig
- asyklisk
- Ytterligere
- I tillegg
- Fordel
- Etter
- AI / ML
- Alle
- tillater
- langs
- allerede
- også
- Selv
- Amazon
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analyse
- analyserer
- og
- noen
- api
- APIer
- søknader
- arkitektur
- ER
- AS
- At
- automatisere
- tilgjengelig
- AWS
- basen
- basert
- Baseline
- BE
- vakker
- vært
- bak
- være
- Bedre
- mellom
- Stor
- bygge
- Bygning
- innebygd
- men
- by
- ring
- som heter
- camping
- CAN
- fangst
- saken
- saker
- celle
- tegn
- klassifisering
- kode
- Kolonne
- kolonner
- skurtreskerne
- Kom
- Felles
- sammenligne
- fullføre
- komplekse
- komponert
- Omfattet
- Beregn
- Gjennomføre
- tilkoblet
- betraktninger
- består
- Container
- inneholder
- kontinuerlig
- konvertere
- konvertert
- matlaging
- Tilsvarende
- kunne
- skape
- opprettet
- skaper
- Opprette
- I dag
- skikk
- kunde
- kundeopplevelse
- Kundeservice
- Kunder
- DAG
- dashbord
- dato
- dataovervåking
- Dataklargjøring
- databehandling
- datakvalitet
- datavitenskap
- datasett
- Misligholde
- definere
- definert
- levering
- Etterspørsel
- avhengig
- Avhengighet
- avhengig
- avhenger
- utplassere
- utplasserings
- detaljert
- detaljer
- utvikle
- utviklet
- forskjellig
- direkte
- regissert
- Regissør
- distinkt
- Docker
- gjør
- gjort
- ned
- nedlasting
- dumpe
- hver enkelt
- lett
- økosystem
- Edward
- muliggjøre
- muliggjør
- oppmuntre
- slutt
- ende til ende
- Ingeniørarbeid
- Hele
- epoke
- Eter (ETH)
- eksempel
- henrette
- gjennomføring
- erfaring
- ekstra
- trekke ut
- familie
- vifte
- langt
- Trekk
- tilbakemelding
- Noen få
- filet
- Filer
- Film
- filmskapere
- Først
- fiske
- fem
- fokuserte
- fokuserer
- fulgt
- etter
- følger
- Til
- skjema
- format
- fra
- fullt
- funksjonalitet
- Dess
- Games
- generere
- grafer
- Ha
- he
- hjelpe
- hjelpe
- her
- her.
- vandreturer
- hans
- Hollywood
- Hvordan
- HTML
- http
- HTTPS
- menneskelig
- if
- illustrerer
- bilde
- bilder
- umiddelbart
- importere
- viktig
- in
- inkludere
- uavhengig
- indikerer
- individuelt
- inngang
- f.eks
- instruksjoner
- integrere
- integrering
- interaktiv
- inn
- IT
- DET ER
- Jobb
- Jobb
- jpg
- bare
- Etiketten
- etiketter
- Siste
- lansere
- læring
- bibliotekene
- linje
- linjer
- laste
- lokal
- plassering
- Lang
- elsker
- maskin
- maskinlæring
- magi
- Hoved
- GJØR AT
- administrer
- fikk til
- ledelse
- leder
- Media
- Bragd
- kunne
- ML
- modell
- modeller
- modifisert
- Moduler
- Overvåke
- overvåking
- skjermer
- mer
- mest
- flytte
- film
- flere
- må
- navn
- innfødt
- Trenger
- nødvendig
- negativ
- Ny
- Nei.
- note
- bærbare
- notatbøker
- nå
- objekt
- of
- ofte
- on
- ONE
- bare
- Optimalisere
- or
- orkestre
- Annen
- vår
- ut
- produksjon
- utganger
- utenfor
- par
- parameter
- parametere
- del
- passere
- Passerer
- banen
- utføre
- utfører
- personlig
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Populær
- positiv
- Post
- forutsi
- forberedelse
- Forbered
- forbereder
- forbereder
- forrige
- tidligere
- Problem
- prosessering
- Produkt
- Produktsjef
- gi
- forutsatt
- gir
- offentlig
- Trekker
- formål
- Skyv
- presset
- Python
- kvalitet
- raskere
- R
- heller
- Lese
- Lesning
- gjentakende
- redusere
- Refaktor
- referere
- registrert
- regelmessig
- forbli
- GJENTATTE GANGER
- krever
- resulterende
- anmeldelse
- Anmeldelser
- Kjør
- rennende
- går
- sagemaker
- SageMaker-rørledninger
- samme
- fornøyd
- planlegge
- planlagt
- Planlagte jobber
- planlegging
- Vitenskap
- forskere
- SDK
- Sekund
- Seksjon
- seksjoner
- se
- sett
- senior
- sentiment
- separat
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- flere
- formet
- hun
- bør
- Vis
- presentere
- vist
- Viser
- signifikant
- betydelig
- lignende
- Enkelt
- forenkle
- enkelt
- liten
- mindre
- tekstutdrag
- So
- selskap
- sosiale medier
- løsning
- Solutions
- LØSE
- noen
- noe
- Rom
- spesifikk
- utgifter
- stående
- stanford
- Begynn
- status
- Trinn
- Steps
- Still
- lagring
- rett fram
- studio
- slik
- Sol
- støtte
- Støttes
- Støtter
- sikker
- Ta
- tar
- Oppgave
- oppgaver
- lag
- Technologies
- test
- tekst
- Tekstklassifisering
- Det
- De
- deres
- Dem
- deretter
- Disse
- Tredje
- denne
- De
- tre
- Gjennom
- tid
- til
- sammen
- også
- verktøy
- Totalt
- spor
- Tog
- trent
- Kurs
- Transform
- transformers
- Traveling
- utløse
- SVING
- to
- typen
- ui
- forstå
- Oppdater
- us
- bruke
- bruk sak
- brukt
- Brukere
- bruker
- ved hjelp av
- utnytte
- Verdier
- ulike
- av
- Se
- visualisere
- gå
- ønsker
- we
- web
- webtjenester
- når
- om
- hvilken
- mens
- HVEM
- vil
- med
- innenfor
- uten
- arbeidere
- arbeidsflyt
- arbeidsflyt
- arbeid
- verste
- skriving
- du
- Din
- zephyrnet